本文是深入理解 Redis 常用数据类型源码及底层实现系列的第6篇~前5篇可移步( ̄∇ ̄)/
【Redis】深入理解 Redis 常用数据类型源码及底层实现(1.结构与源码概述)-CSDN博客
【Redis】深入理解 Redis 常用数据类型源码及底层实现(2.版本区别+dictEntry & redisObject详解)-CSDN博客
【Redis】深入理解 Redis 常用数据类型源码及底层实现(3.详解String数据结构)-CSDN博客
【Redis】深入理解 Redis 常用数据类型源码及底层实现(4.详解Hash数据结构)_查看 hash-max-ziplist-entries 命令-CSDN博客
【Redis】深入理解 Redis 常用数据类型源码及底层实现(5.详解List数据结构)-CSDN博客
本文目录
Set数据结构
ZSet数据结构
t_zset.c
skiplist
Set数据结构
Set数据结构相对其他的数据结构比较简单,因为从Redis 6到Redis 7都没变~底层都是哈希表+整数数组,即使用intset和hashtable存储set的,如果元素都是整数类型就使用intset,如果不是则使用hashtable(数组+链表,key是元素值,value是null)
我们看下当执行命令sadd时,Redis底层到底做了些什么

在方法setTypeCreate()中,我们可以看到当集合元素都是LongLong类型并且集合元素个数<=server.set_max_intset_entries时,就采用intset的编码方式,不能同时满足上面两个条件的话则判断集合元素是否<=server.set_max_listpack_entrie,如果满足则采用listpack的编码方式(Redis 7),不满足则调用方法createSetObject()

方法createSetObject()中则采用hashtable的编码方式

上面源码中的参数server.set_max_intset_entries和server.set_max_listpack_entrie声明于文件server.h中

我们按照注释到redis.conf中就可以看到默认配置啦

我们总结下,对于Set数据结构,Redis 6 和Redis 7的底层都是intset和hashtable,当添加的数据是LongLong类型并且集合元素数<=512(默认配置,一般不作修改)时,就会使用intset的编码方式,反之则使用hashtable的编码方式。
ZSet数据结构
ZSet有两种编码格式,并且跟之前介绍的Hash数据结构类似,Redis 6是ziplist和skiptable而Redis 7是listpack和skiptable,我们先来看下不同版本基本配置信息的区别:
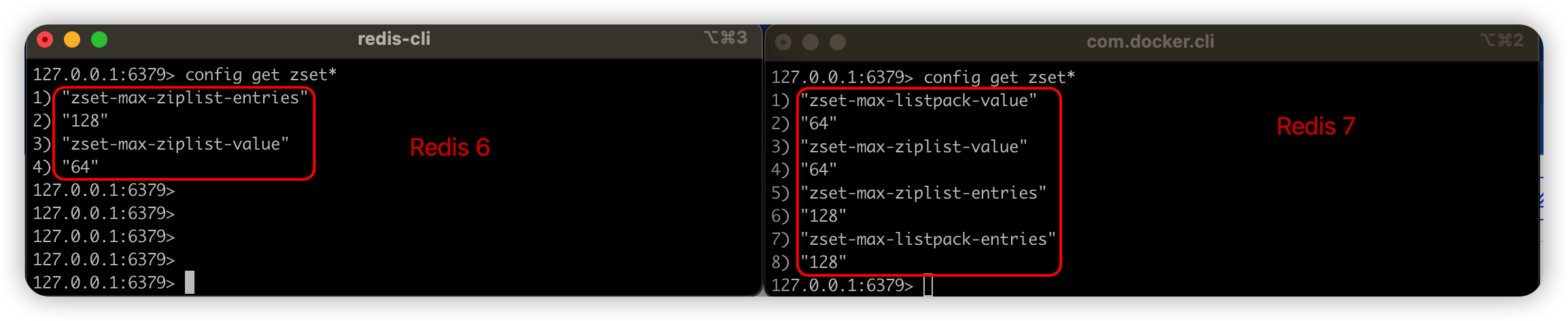
我们分别介绍下这些配置参数的含义:
- zset-max-ziplist-entries:使用压缩列表保存数据时,zset有序集合中最大的元素个数(默认128)
- zset-max-ziplist-value:使用压缩列表保存数据时,zset有序集合中单个元素的最大长度(默认64)
-
- 单位byte:一个英文字母一个byte
- zset-max-listpack-entries:使用紧凑列表保存数据时,zset有序集合中最大的元素个数(同样默认128)
- zset-max-listpack-value:使用紧凑列表保存数据时,zset有序集合中单个元素的最大长度(默认64)
Redis 7兼容ziplist,当我们修改zset-max-listpack-entries和zset-max-listpack-value时,对应的zset-max-ziplist-entries和zset-max-ziplist-value也会被修改:

反之,当修改zset-max-ziplist-entries和zset-max-ziplist-value时,对应的zset-max-listpack-entries和zset-max-listpack-value也会被修改:

而且,当集合中的数据元素超过zset-max-ziplist-entries/zset-max-listpack-entries(不包括等于),或者元素长度大于zset-max-ziplist-value/zset-max-listpack-value时(不包括等于),底层会使用skiptable进行数据的存储,我们可以做下测试:


t_zset.c
接下来我们从源码层面看下,当执行刚才测试的添加元素的操作时,Redis底层执行的逻辑是什么。
打开t_zset.c文件(以Redis 7为示例),找到方法zsetAdd()

这里可以看到ZSet的两种编码方式OBJ_ENCODING_LISTPACK和OBJ_ENCODING_SKIPLIST
skiplist
为什么会出现skiplist跳表?
一个新的东西产生一般都是由问题导致的,原有的部分产生了问题,或者说痛点,就像原有的链表和数组,他们就各有优缺点(数组插入删除慢,链表遍历慢),于是在寻求解决方法的时候,skiplist跳表就应运而生。
其实skiplist是通过升维对链表进行优化的,就是我们非常熟悉的空间换时间(还记不记得ziplist是时间换空间?),既然链表遍历太慢,我们就给它加个(或者多个)索引,即“索引升级”,我们来看张图大家应该就明白了( ̄∇ ̄)/
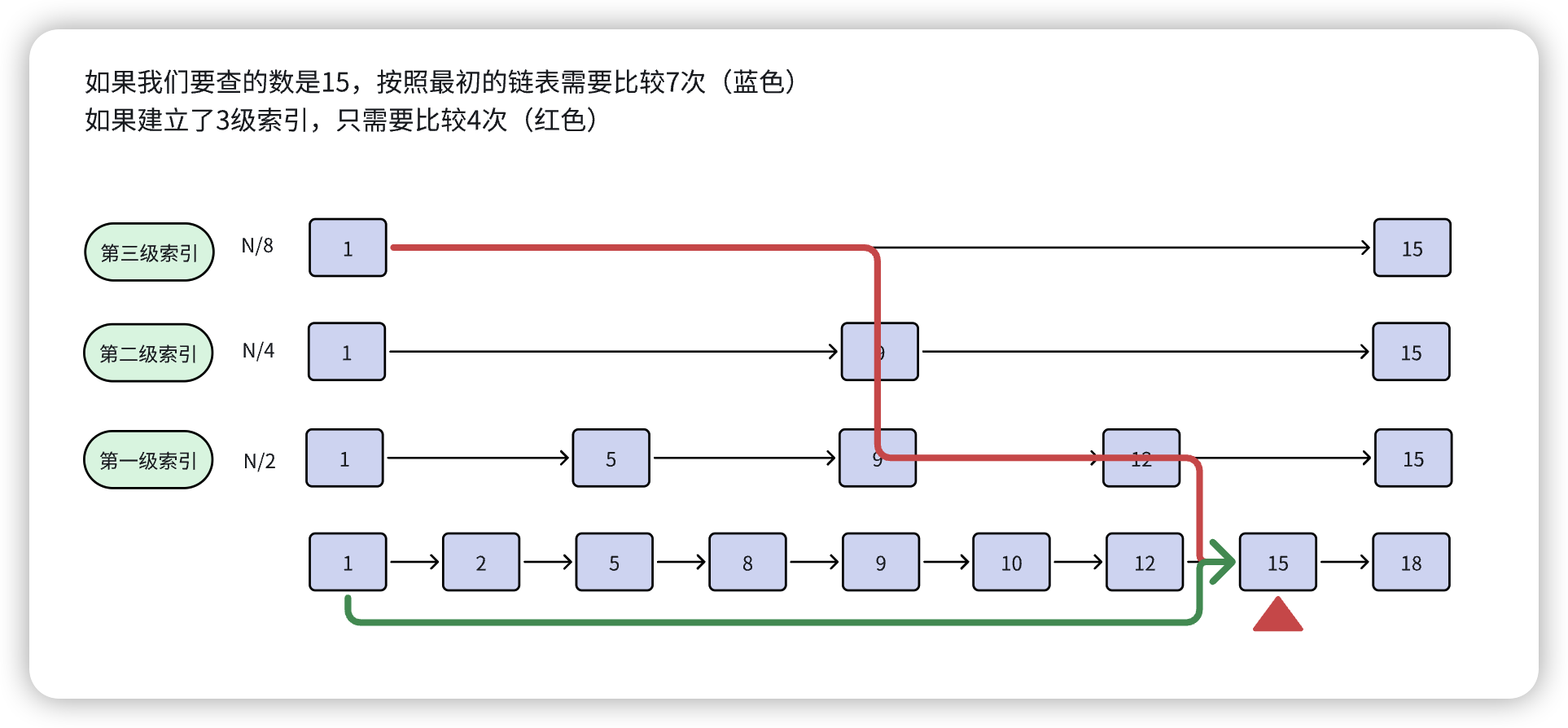
总的来说,skiplist跳表是可以实现二分查找的有序链表(跳表 = 链表 + 多级索引),是一种以空间换取时间的结构。由于链表无法进行二分查找,提取出链表中关键节点作为索引(借鉴数据库索引的思想),先在关键节点上查找,再进入下层链表查找,提取多层关键节点,就形成了跳跃表,但是索引也要占据一定空间的(索引添加的越多,空间占用的越多,空间换时间)
搞定🎉~~~~~