目录
一、LRUCache
1.概念
2.实现:哈希表+双向链表
3.JDK中类似LRUCahe的数据结构LinkedHashMap
🔥4.OJ练习
二、并查集
1. 并查集原理
2.并查集代码实现
3.并查集OJ
一、LRUCache
1.概念
最近最少使用的,一直Cache替换算法
LRU是Least Recently Used的缩写,意思是最近最少使用,它是一种Cache替换算法。 什么是Cache?狭义的Cache指的是位于CPU和主存间的快速RAM, 通常它不像系统主存那样使用DRAM技术,而使用昂贵但较快速的SRAM技术。 广义上的Cache指的是位于速度相差较大的两种硬件之间, 用于协调两者数据传输速度差异的结构。除了CPU与主存之间有Cache, 内存与硬盘之间也有Cache,乃至在硬盘与网络之间也有某种意义上的Cache── 称为Internet临时文件夹或网络内容缓存等。
Cache的容量有限,因此当Cache的容量用完后,而又有新的内容需要添加进来时, 就需要挑选并舍弃原有的部分内容,从而腾出空间来放新内容。LRU Cache 的替换原则就是将最近最少使用的内容替换掉。其实, LRU译成最久未使用会更形象, 因为该算法每次替换掉的就是一段时间内最久没有使用过的内容
2.实现:哈希表+双向链表

- 哈希表:查找速度快O(1)
- 双向链表:插入和删除的时间复杂度比较快O(1)
- head
- tail
3.JDK中类似LRUCahe的数据结构LinkedHashMap
- initialCapacity:初始容量大小
- loadFactor 加载因子
- accessOrder
- true:基于访问顺序 (把最常用的放到尾巴)
- false:基于插入顺序
(1)当accessOrder的值为false的时候:
public static void main(String[] args) {Map<String, String> map = new LinkedHashMap<>(16,0.75f,false);map.put("1", "a");map.put("2", "b");map.put("4", "e");map.put("3", "c");System.out.println(map);
}输出结果:
{1=a, 2=b, 4=e, 3=c}
以上结果按照插入顺序进行打印
(2) 当accessOrder的值为true的时候
public static void main(String[] args) {Map<String, String> map = new LinkedHashMap<>(16,0.75f,true);map.put("1", "a");map.put("2", "b");map.put("4", "e");map.put("3", "c");map.get("1");map.get("2");System.out.println(map);
}输出结果:
{4=e, 3=c, 1=a, 2=b}
每次使用get方法,访问数据后,会把数据放到当前双向链表的最后。
当accessOrder为true时,get方法和put方法都会调用recordAccess方法使得最近使用的Entry移到双向链表的末尾;当accessOrder为默认值false时,从源码中可以看出recordAccess方法什么也不会做
🔥4.OJ练习
https://leetcode-cn.com/problems/lru-cache/
解法一:自己实现链表(最新在头/尾都可)
(1)get方法:存在否->存在需refresh
(2)put方法:是否存在->覆盖/创建
创建->还有空间否?
(3)refresh:删除+放到链表头部/尾部(注意:步骤4一定得在步骤1的后面)
(4)delete:删除的是指定节点
class LRUCache {class DLinkNode {public int key;public int val;public DLinkNode prev;public DLinkNode next;public DLinkNode(int key,int val) {this.key = key;this.val = val;}}public DLinkNode head;public DLinkNode tail;public Map<Integer,DLinkNode> map;public int n;public LRUCache(int capacity) {this.head = new DLinkNode(-1,-1);this.tail = new DLinkNode(-1,-1);head.next = tail;tail.prev = head;map = new HashMap<>();this.n = capacity;}public int get(int key) {if(map.containsKey(key)) {DLinkNode node = map.get(key);refresh(node);return node.val;}return -1;}public void put(int key, int value) {DLinkNode node = null;if(map.containsKey(key)) {//存在->覆盖node = map.get(key); //直接在node上改,因为要refreshnode.val = value;} else {//还有空间否if(map.size() == n) {DLinkNode del = tail.prev;map.remove(del.key);delete(del);}//放入mapnode = new DLinkNode(key,value);map.put(key,node);}refresh(node);}//放到链表头部(删除+放置)public void refresh(DLinkNode node) {delete(node);//删除指定节点node.next = head.next;head.next.prev = node;node.prev = head;//这个步骤4一定得在1的后面head.next = node;}//删除指定节点public void delete(DLinkNode node) {if(node.prev != null ) {DLinkNode pre = node.prev;pre.next = node.next;node.next.prev = pre;}}
}/*** Your LRUCache object will be instantiated and called as such:* LRUCache obj = new LRUCache(capacity);* int param_1 = obj.get(key);* obj.put(key,value);*/解法二:
class LRUCache extends LinkedHashMap<Integer, Integer>{
private int capacity;public LRUCache(int capacity) {/**第3个参数的意思:当accessOrder设置为false时,会按照插入顺序进行排序,当accessOrder为true是,会按照访问顺 序(也就是插入和访问都会将当前节点放置到尾部,尾部代表的是最近访问的数据,这和JDK1.6是反过来 的,jdk1.6头部是最近访问的)。*/super(capacity,0.75F,true);this.capacity = capacity;
} //此时的get方法一定会,返回最近访问的数据
public int get(int key) {return super.getOrDefault(key, -1);
}public void put(int key, int value) {super.put(key, value);
} //必须重写这个方法,默认是false。此时根据
@Override
protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {
return size() > capacity;}
}
public class TestDemo {public static void main(String[] args) {LRUCache lruCache = new LRUCache(3);//尾插法插入lruCache.put(2,1);lruCache.put(3,1);lruCache.put(4,1);System.out.println(lruCache);//{2=1, 3=1, 4=1}System.out.println(lruCache.get(2));//1 并且放到链表的尾巴System.out.println(lruCache);//{ 3=1, 4=1,2=1}}
} /**
* Your LRUCache object will be instantiated and called as such:
* LRUCache* obj = new LRUCache(capacity);
* int param_1 = obj->get(key);
* obj->put(key,value);
*/二、并查集
1. 并查集原理
(1)解决的问题
- 将n个不同的元素划分成一些不相交的集合,开始时,每个元素自己都是单元素集合,然后按照一定的规律将归于同一组元素的集合合并
- 这个过程需要反复用到查询某个元素归属哪个集合的运算
(2)具体例子理解
- 初始状态

某公司今年校招全国总共招生10人,西安招4人,成都招3人,武汉招3人,10个人来自不同的学校,起先互不相识,每个学生都是一个独立的小团体,现给这些学生进行编号 - 集合树形表示

西安学生小分队s1={0,6,7,8},成都学生小分队s2={1,4,9},武汉学生小分队s3={2,3,5}就相互认识了,10个人形成了三个小团体。假设右三个群主0,1,2担任队长 - 并查集表示

- 数组的下标:表示对应集合中元素的编号
- 数组元素如果是负数:负数代表根节点,数字代表这个集合中元素的个数
- 数组如果是非负数:代表该元素的双亲在数组中的下标
- 合并1和8

在公司工作一段时间后,西安小分队中8号同学与成都小分队1号同学奇迹般的走到了一起,两个小圈子的学生相互介绍,最后成为了一个小圈子:
(3)小结:并查集解决的问题
- 查找元素属于哪个集合
沿着数组表示树形关系以上一直找到根(即:树中中元素为负数的位置) - 查看两个元素是否属于同一个集合
沿着数组表示的树形关系往上一直找到树的根,如果根相同表明在同一个集合,否则不在 - 将两个集合归并成一个集合
将一个集合加入另一个集合 ,同时数组的下标也需要修改 - 集合的个数
数组中元素为负数的个数即为集合的个数
2.并查集代码实现
- (1)查找x元素的根节点

- (2)查询x1和x2是不是同一个集合

- (3)合并x1和x2的根节点的两个集合(x2并入x1)

- (4)当前集合的个数(不是元素的个数)

3.并查集OJ
- 省份数量
-
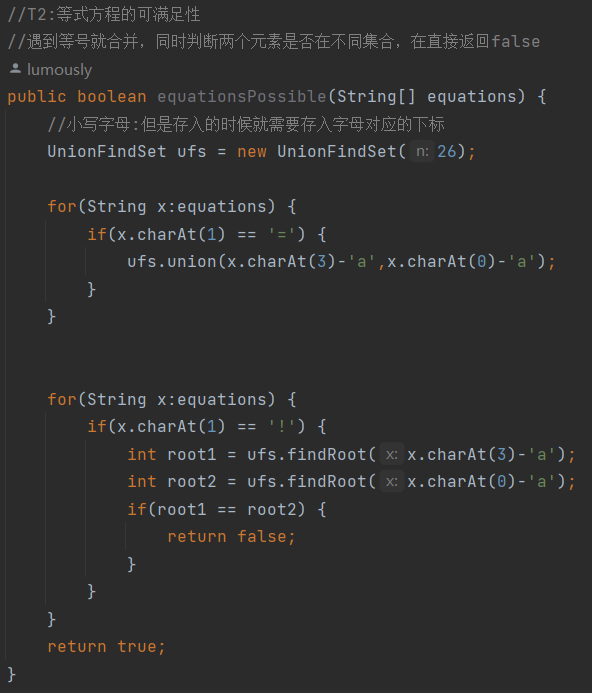
- 等式方程的可满足性
-