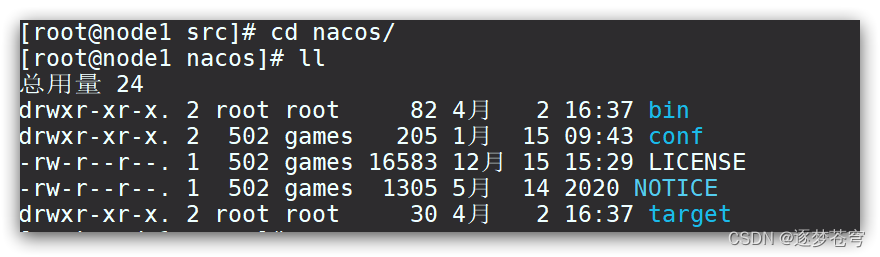
一、YOLO数据集格式分布
在YOLO中,数据集的分布如图,在dataset文件夹下有imags(图片)和labels(标签)。在images和labels文件夹下又分别存放三个文件夹,分别对应测试集、训练集、验证集:
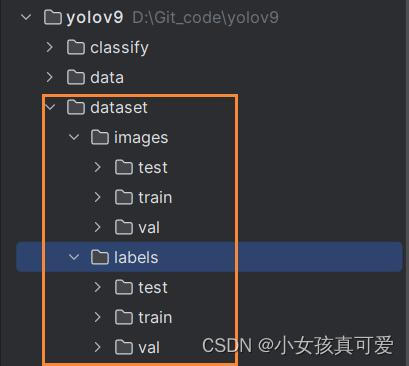
在images文件夹下面存放的是图片,在label文件夹下面存放的是TXT文件,每一个txt文件里面都是标注的信息。以下图为例,文件里面有三行,代表这张图片在标注的时候画了三个框。其中每一行数值代表意思是:类别、物体左上角坐标(x1,y1),右下角坐标(x2,y2)

二、数据集制作
首先安装labelimg库,然后使用labelimg进行标注,标注好之后会生成xml文件(不详细叙述)。然后就是读取xml文件来获取标注的信息,再将这些信息存入txt文件中。
把标注得到的xml文件放到一个文件夹中,比如要搞训练集(train)的就只把train的xml文件放到一个文件夹里,不要把val和test的放进来。。
运行下面代码(路径修改为自己的),制作train、val、test的时候路径最好分开,避免弄混:
import os
import random
import xml.etree.ElementTree as ETimport numpy as npdef convert_annotation(xml_name, class_list, labels_folder):xml_path = os.path.join(XML_FOLDER, xml_name)print("xml_path:", xml_path)in_file = open(xml_path, encoding='utf-8')tree = ET.parse(in_file)root = tree.getroot()for SIZE in root.iter("size"):width = float(SIZE.find("width").text)height = float(SIZE.find("height").text)label_name = xml_name.split(".")[0]+".txt"label_path = os.path.join(labels_folder, label_name)if os.path.exists(label_path):os.remove(label_path)with open(label_path, "a", encoding="utf-8") as f:for obj in root.iter('object'):difficult = 0if obj.find('difficult') != None:difficult = obj.find('difficult').textcls = obj.find('name').textif cls not in class_list or int(difficult) == 1:continuecls_id = classes_list.index(cls)xmlbox = obj.find('bndbox')x1, y1, x2, y2 = (float(xmlbox.find('xmin').text)/width, float(xmlbox.find('ymin').text)/height,float(xmlbox.find('xmax').text)/width, float(xmlbox.find('ymax').text)/height)print("cls:", cls_id)print("box:", x1, y1, x2, y2)f.write("%s %s %s %s %s\n"%(cls_id, x1, y1, x2, y2))if __name__ == "__main__":classes_list = ["point", "circle"] # 对应类别名称XML_FOLDER = r"C:/Users/HJ/Desktop/demo/voc_format_file/xml"Labels_FOLDER = r"C:/Users/HJ/Desktop/demo/voc_format_file/labels"random.seed(0)if " " in os.path.abspath(XML_FOLDER):raise ValueError("数据集存放的文件夹路径与图片名称中不可以存在空格,否则会影响正常的模型训练,请注意修改。")# 1.读取xml文件for xml_name in os.listdir(XML_FOLDER):if xml_name.endswith(".xml"):convert_annotation(xml_name, classes_list, Labels_FOLDER)运行完之后会在生成对应的txt文件,将文件复制粘贴到yolov9的dataset文件夹的对应位置就OK了。
三、训练部分
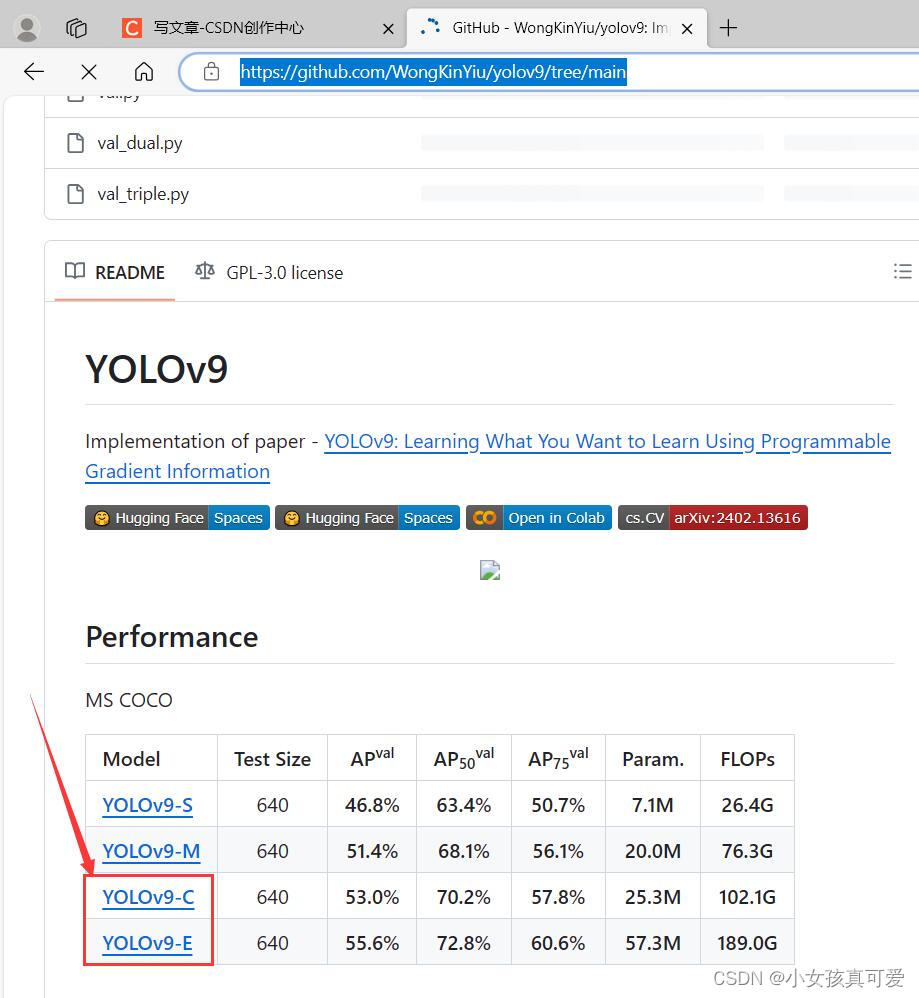
YOLOV9代码地址:https://github.com/WongKinYiu/yolov9/tree/main
将代码克隆到本地之后,在github下滑页面会看到下载预训练模型,目前只有yolov9-c何yolov9-e可以下载,以yolov9-c为例:
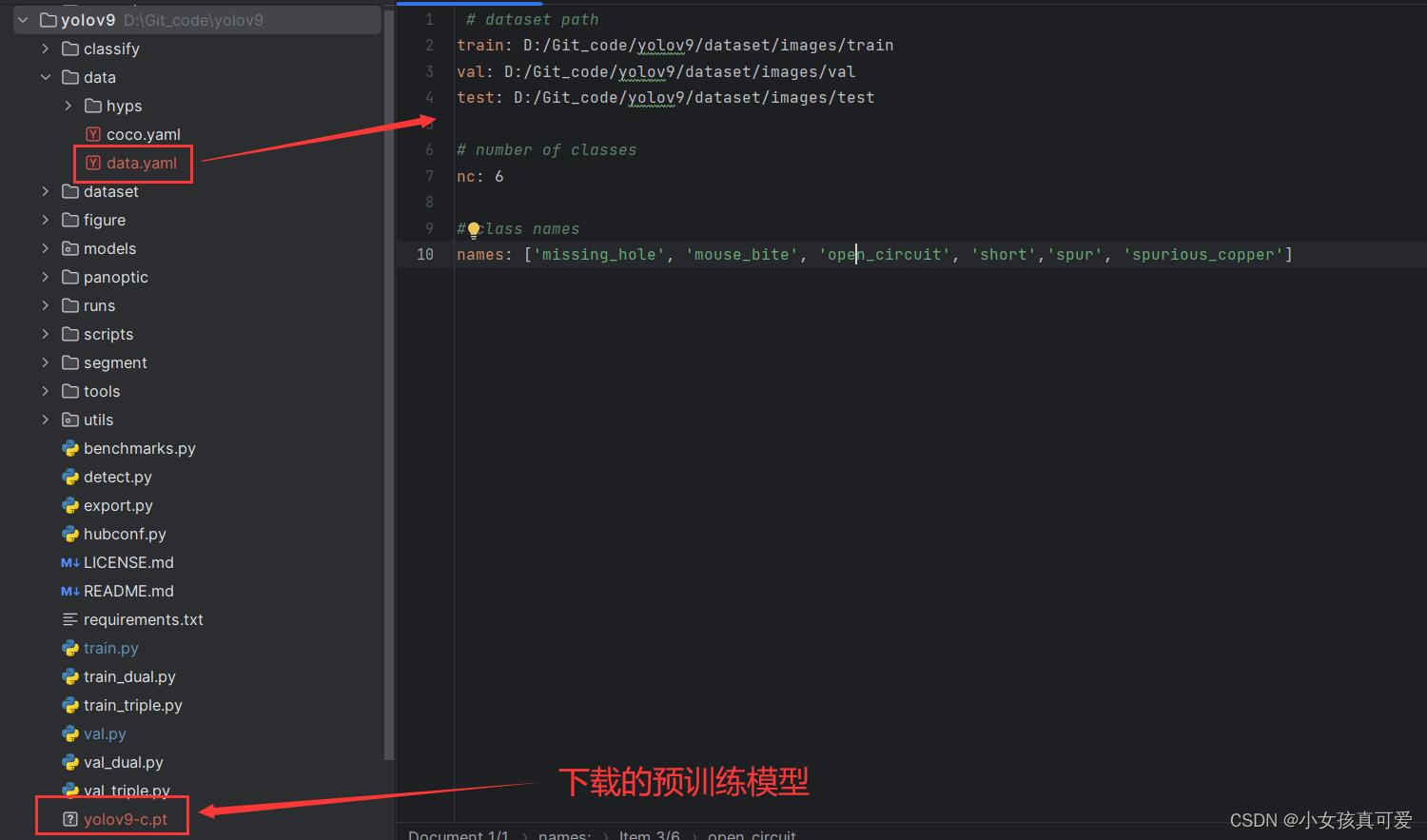
下载完预训练模型之后将预训练模型放到工程目录下(也就是yolov9下)。然后再data文件夹下创建一个data.yaml文件。yaml文件里面分别是训练数据路径、类别数量、类别名称(类别名称要和标注时的顺序一致)
弄完之后,打开train.py文件,在train.py文件下面加上一行,防止报错。
os.environ['KMP_DUPLICATE_LIB_OK']='TRUE'然后下滑找到参数配置文件,修改配置参数。参数介绍:
weights:下载的预训练模型
cfg:对应模型的参数配置文件
data:前面创建的data.yaml文件
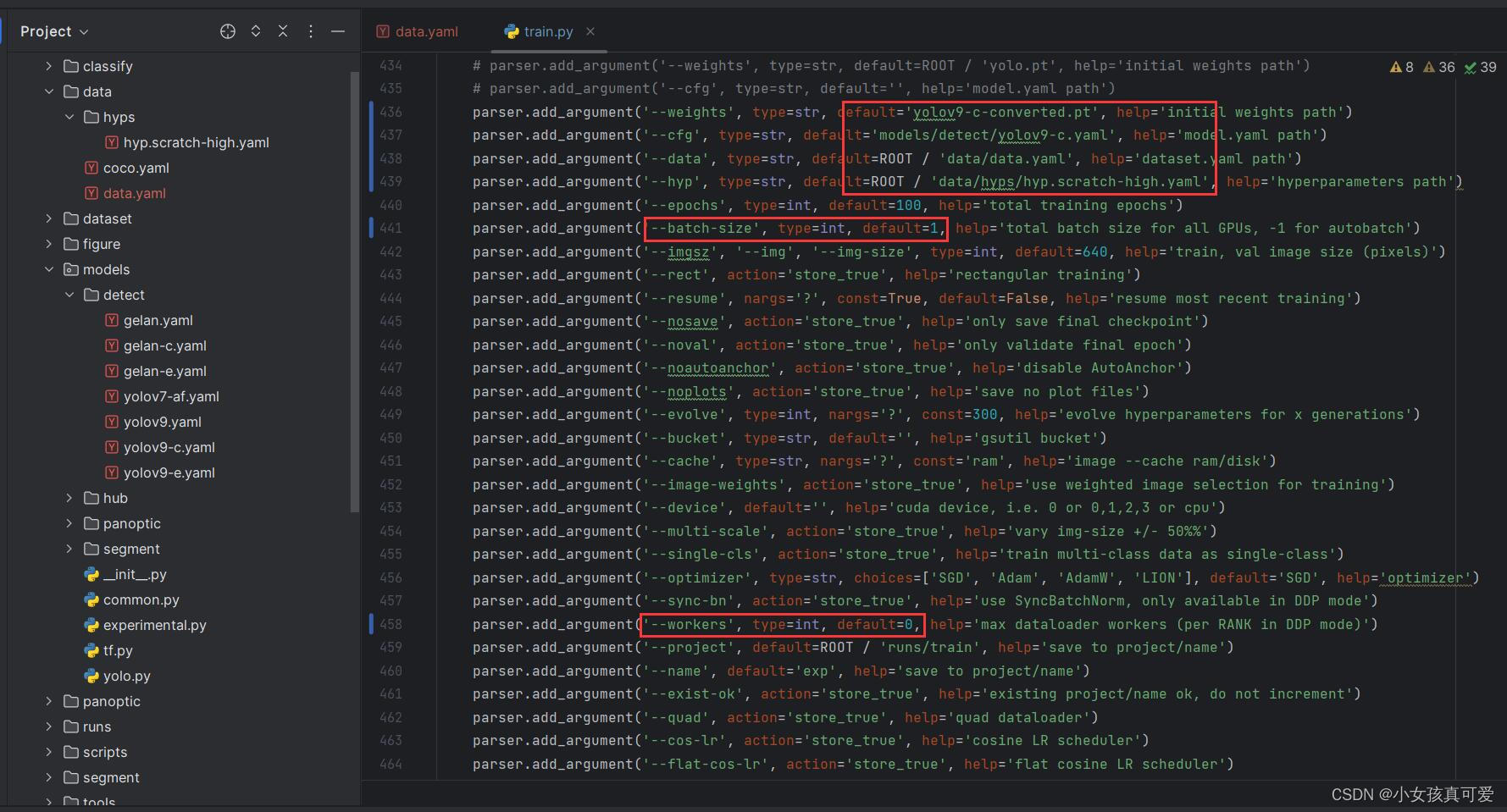
显存比较小的可以把batchsize设小一点,这里设置1,电脑CPU不好的可以把wokers设为0
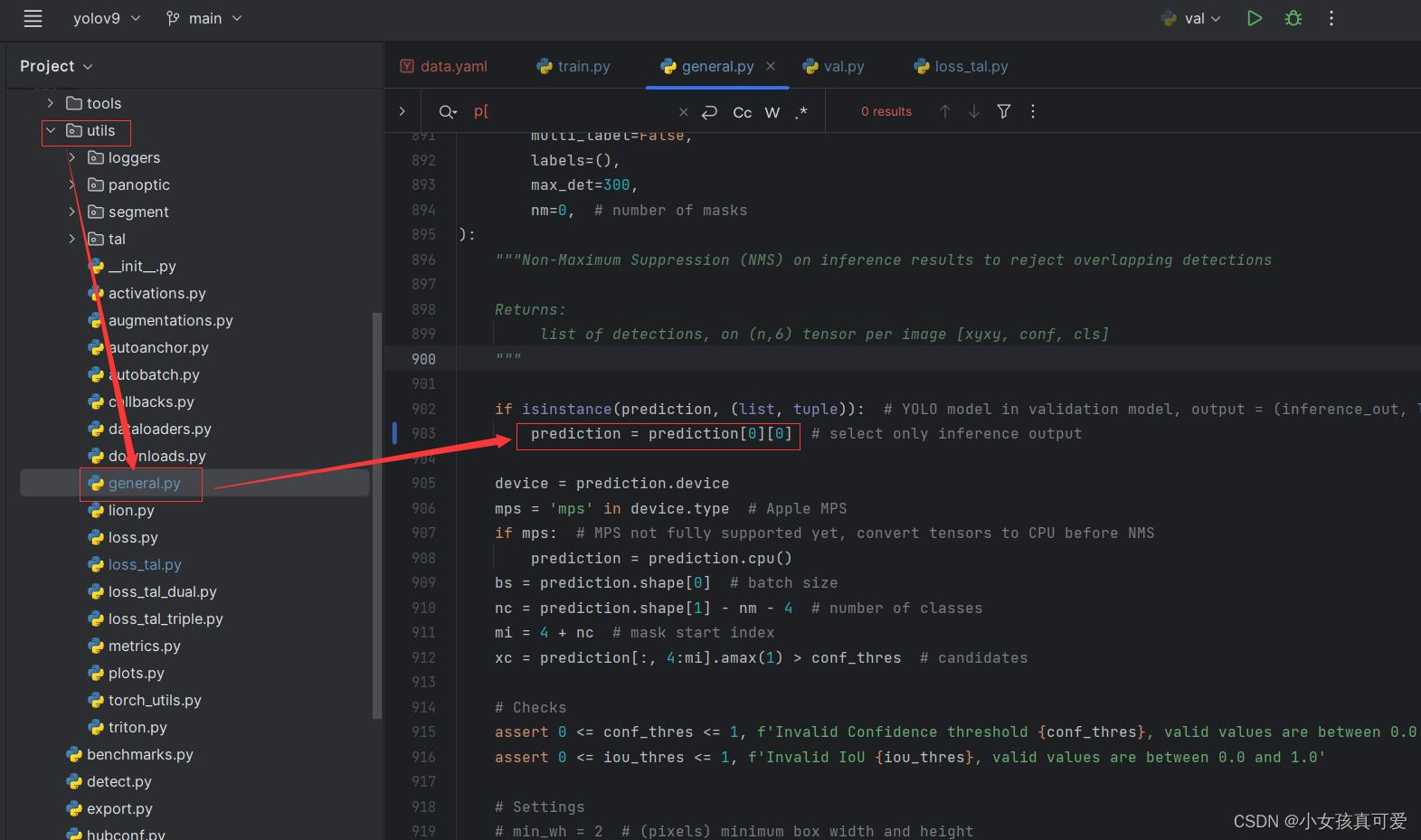
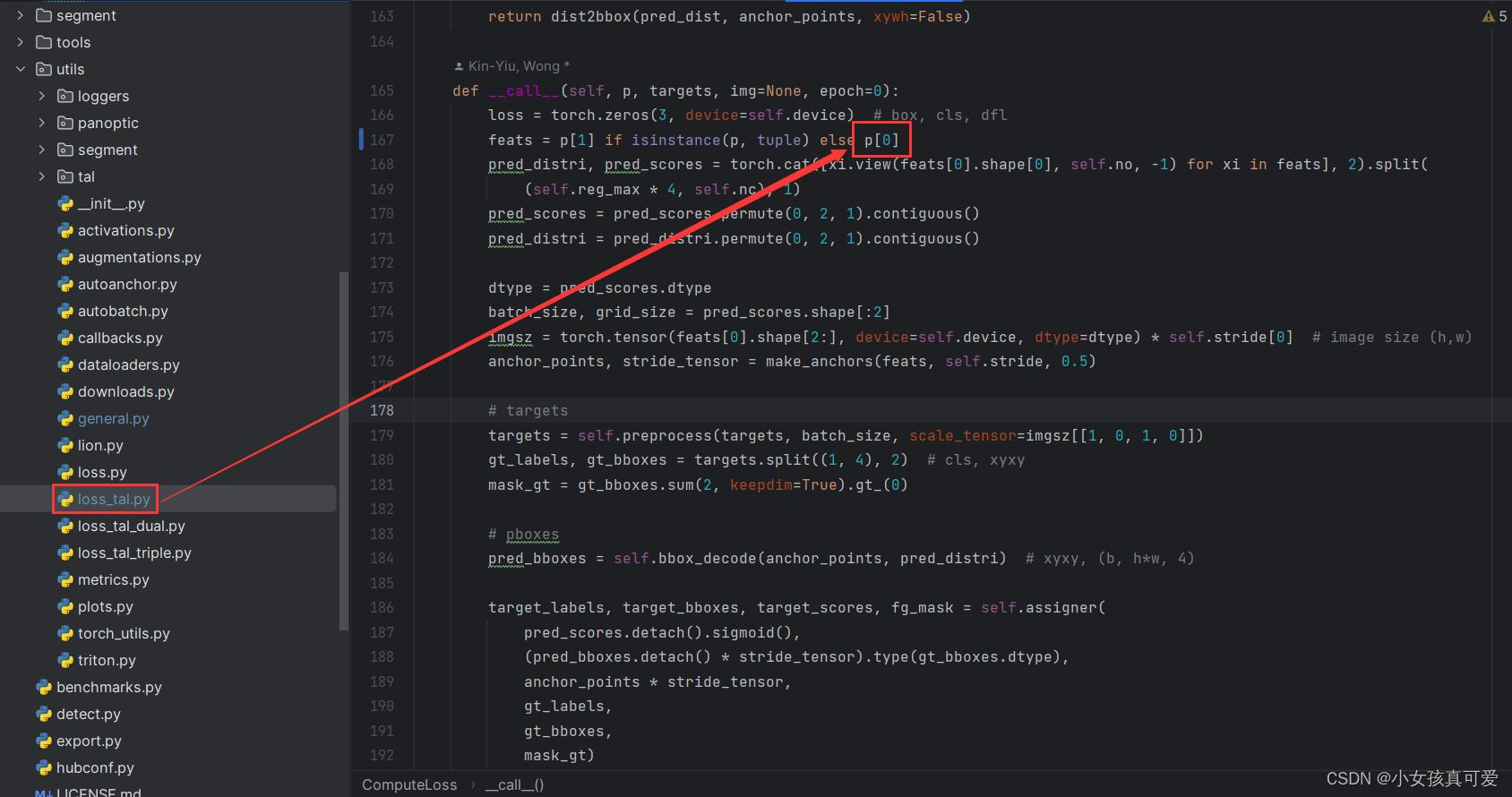
配置参数搞完之后,再修改一下代码。打开utils文件夹下面的loss_tal.py文件,修改如下参数,不修改运行会报错。修改完之后就可以直接运行train.py文件了。
四、验证部分
训练完之后模型以及训练的其他输出结果文件会保存在runs/weights里。打开val.py文件,
在import os后面加上
os.environ['KMP_DUPLICATE_LIB_OK']='TRUE'然后开始修改配置参数:
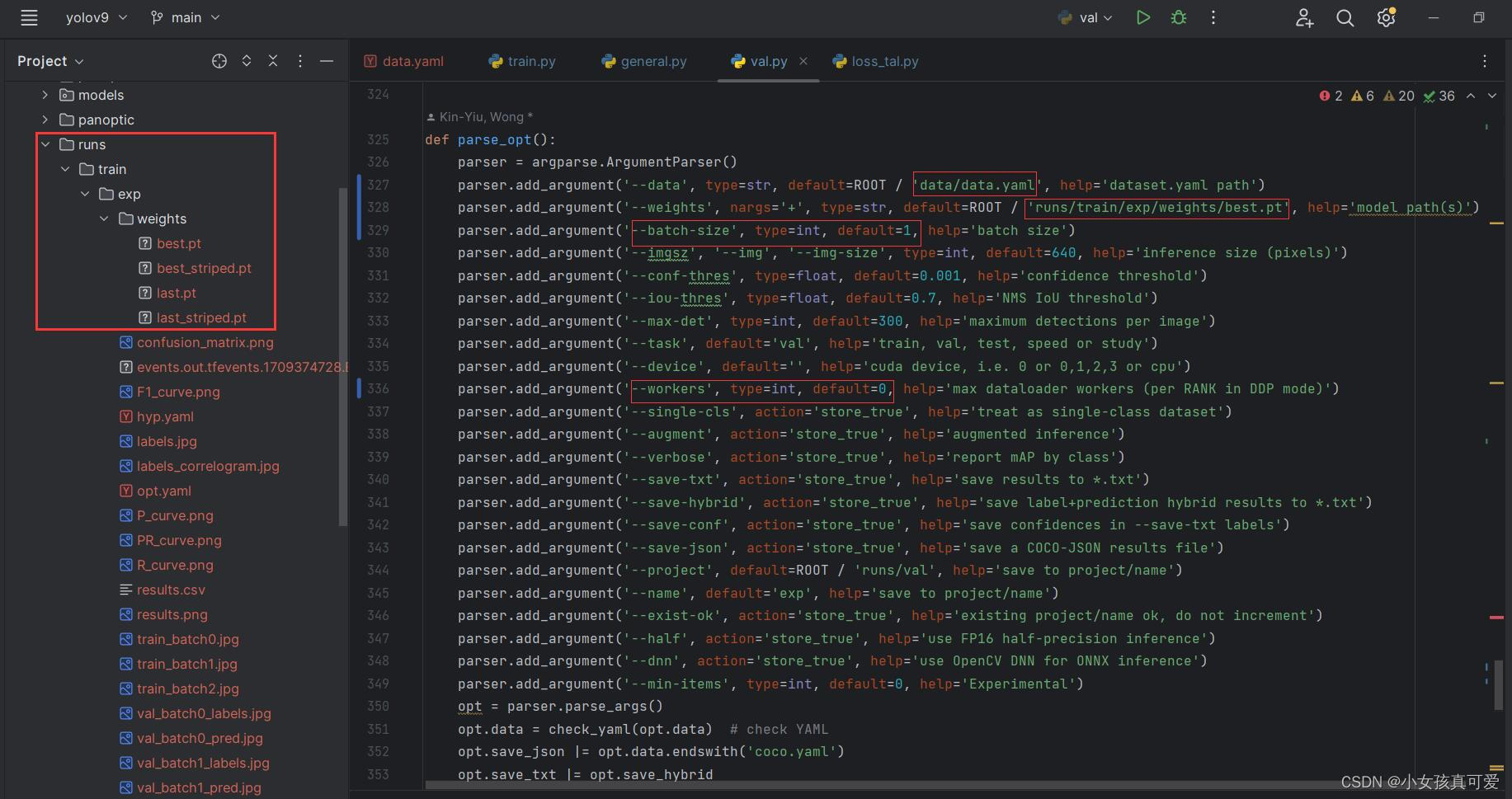
修改完之后直接运行会报错,代码有个小bug需要修改。打开utils文件夹下的general.py文件第903行修改。然后就可以直接运行val.py文件了