在自然语言处理领域,大型语言模型(LLM)在自然语言处理领域的应用越来越广泛。然而,随着模型规模的增大,计算和存储资源的需求也急剧增加。为了降低计算和存储开销,同时保持模型的性能,LLM大模型的量化技术应运而生
1. 量化的技术原理
LLM大模型的量化技术主要是通过对模型参数进行压缩和量化,从而降低模型的存储和计算复杂度。具体来说如下:
- 参数压缩
通过将模型中的浮点数参数转换为低精度的整数参数,量化技术可以实现参数的压缩。这不仅可以减少模型所需的存储空间,还可以降低模型加载的时间。 - 计算加速
由于低精度整数运算的速度远快于浮点数运算,量化技术还可以通过降低计算复杂度来实现计算加速。这可以在保证模型性能的同时,提高模型的推理速度。
量化技术的三个主要目的:节省显存、加速计算、降低通讯量。它们往往不会同时在场,不同的应用场景下应当对症下药
1.1. 神经网络中的数据类型
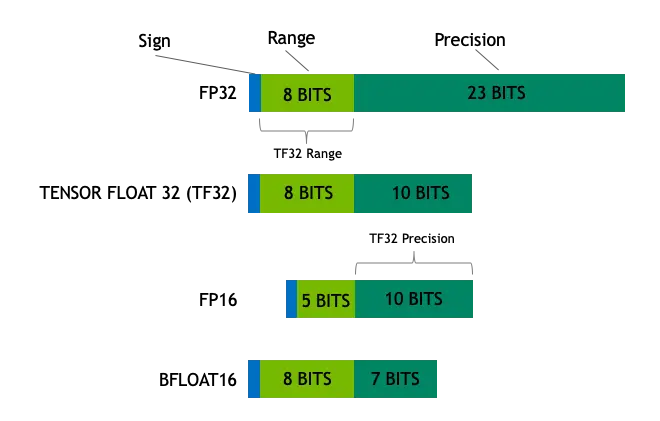
- FP32:在深度学习中,单精度浮点数格式FP32是一种广泛使用的数据格式,其可以表示很大的实数范围,足够深度学习训练和推理中使用。这种格式使用4个bytes(32bits)表示。
- Tensor Float 32: Tensor Float 32是Tensor Core支持新的数值类型,从NVIDIA A100中开始支持。A100的普通FP32的峰值计算速度为19.5TOPs,而TF32的峰值计算速度为156TOPs,提升了非常多
在深度学习中,其实我们对浮点数的表示范围比较看重,而有效数字不是那么重要。在这个前提下,TF直接就把FP32中23个分数值截短为10bits,而指数位仍为8bits,总长度为19(=1+8+10)bits。至于为什么是10bits 就够了,那是因为FP16就只有10bits用来表示分数值。而在实际测试中,FP16的精度水平已经足够应对深度学习负载,只是表示的范围不够广而已 - FP16: FP16是一种半精度浮点格式,深度学习有使用FP16而不是FP32的趋势,因为较低精度的计算对于神经网络来说似乎并不重要。额外的精度没有任何作用,同时速度较慢,需要更多内存并降低通信速度。
- BFLOAT16: 由Google开发的16位浮点格式称为“Brain Floating Point Format”,简称“bfloat16”。这个名字来源于“Google Brain”,这是谷歌的一个人工智能研究小组。
FP16设计时并未考虑深度学习应用,其动态范围太窄。BFLOAT16解决了这个问题,提供与FP32相同的动态范围。其可以认为是直接将FP32的前16位截取获得的,现在似乎也有取代FP16的趋势。
1.2. 量化是如何缩小模型的?
目前发现不使用4字节FP32精度转而使用2字节BF16/FP16半精度可以获得几乎相同的推理结果,同时模型大小会减半。这促使开发者想进一步削减内存,如果再从2字节半精度转成仅1字节的8bits数据类型,甚至4bits类型呢?实际上,对于大模型最常见的就是8bits量化(FP8/INT8)和4bits量化(FP4/NF4/INT4)。
量化通过减少每个模型权重所需的位数,显著降低了模型的大小。模型一个典型的场景是将权重从FP16(16位浮点)减少到INT4(4位整数)。同时,在内存中传输时,也显著降低了带宽占用。这允许模型在更便宜的硬件上或以更高的速度运行。通过降低权重的精度,LLM的整体质量也会受到一些影响。
研究表明,这种影响因所使用的技术而异,较大的模型受到精度变化的影响较小。更大的型号(超过70B)即使转换为4bits也能保持其性能。一些技术,如NF4,表明对其性能没有影响。因此,对于这些较大的型号,4bits似乎是性能和大小/速度之间的最佳折衷,而对于较小的型号,8bits量化可能更好。
- 较大的模型(如超过70B)使用4bit量化其性能没有影响
- 较小的模型使用8bit量化可能更好
下面以Qwen-7B-Chat为例展示INT8和INT4量化的效果【模型效果的评估模型介绍参见附录】
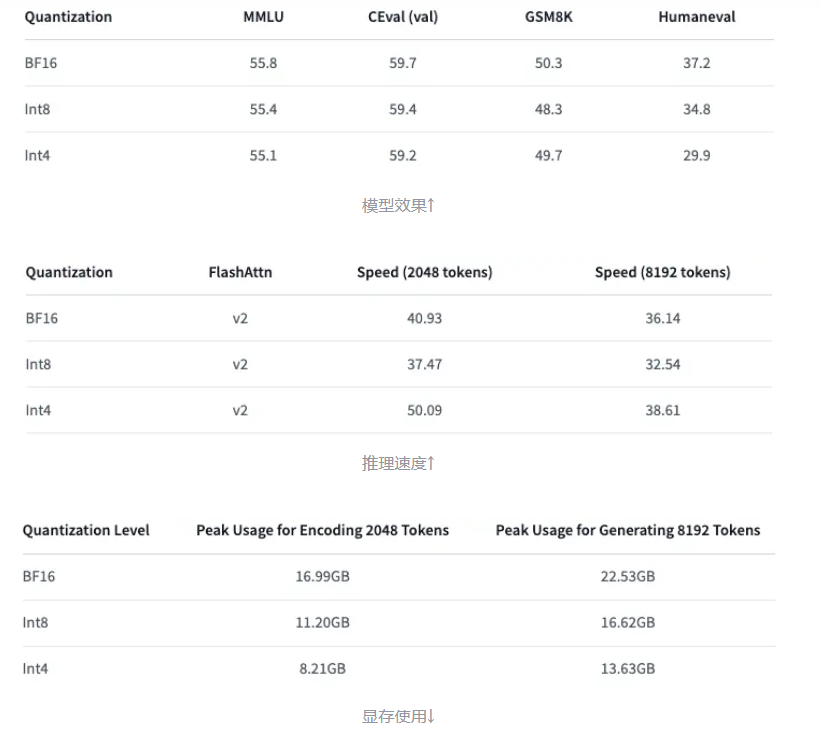
2. LLM量化的使用场景
LLM量化技术在以下场景中非常有用:
- 移动设备和边缘计算:大型语言模型通常需要大量的存储和计算资源。通过量化,可以将模型压缩到适合移动设备和边缘设备的大小,以便实现更高效的推理。
- 云端部署:在云端部署大型语言模型时,存储和计算成本也是一个重要考虑因素。量化可以帮助降低云端服务器的资源需求。
3. 为什么需要量化
- 存储空间优化:大型语言模型的参数数量庞大,存储这些参数需要大量的显存。通过量化可以显著减小模型的存储空间。
- 计算速度优化:低精度的整数运算比浮点数运算更快。量化可以加速模型的推理过程。
4. 如何量化?
4.1. 量化的分类
根据量化后的目标区间
可以分为四类:
- 二值量化(1, -1)、
- 三值量化(-1, 0, 1)、
- 定点数量化(INT4, INT8),最常见的量化方式
- 2 的指数量化。
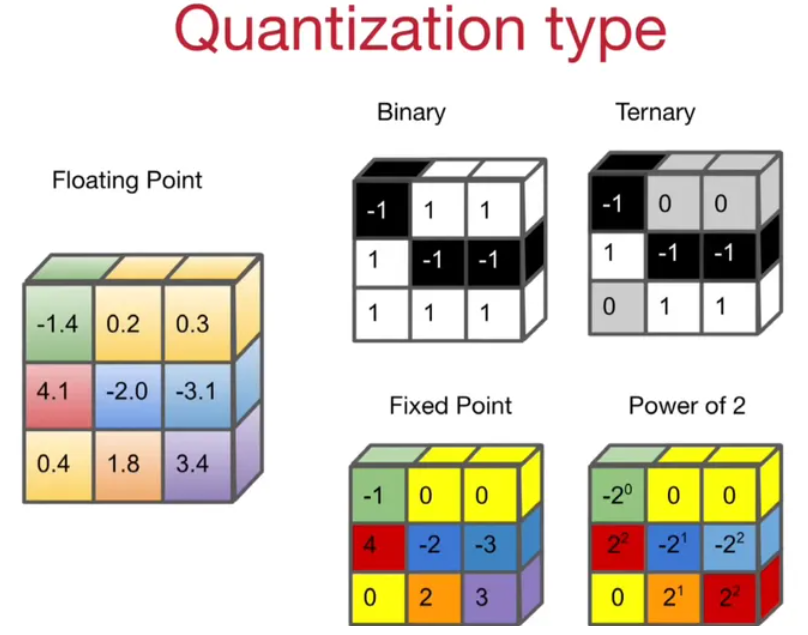
根据量化节点的分布
可以分为均匀量化和非均匀量化
非均匀量化可以根据待量化参数的概率分布计算量化节点。如果某一个区域参数取值较为密集,就多分配一些量化节点,其余部分少一些。这样量化精度较高,但计算复杂度也高。
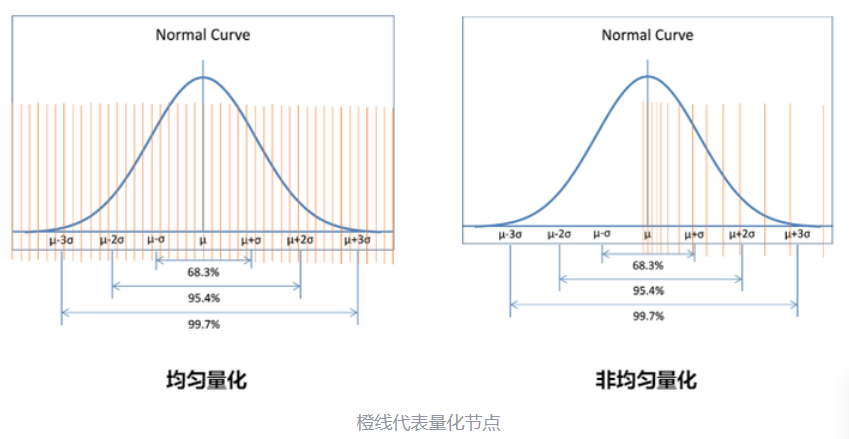
现在 LLM 主要采用的是均匀量化,它又可以分为对称量化、非对称量化。前者是后者的一种特殊情况
量化,就是要选择合适的量化系数,平衡截断误差和舍入误差。
非对称量化

对称量化
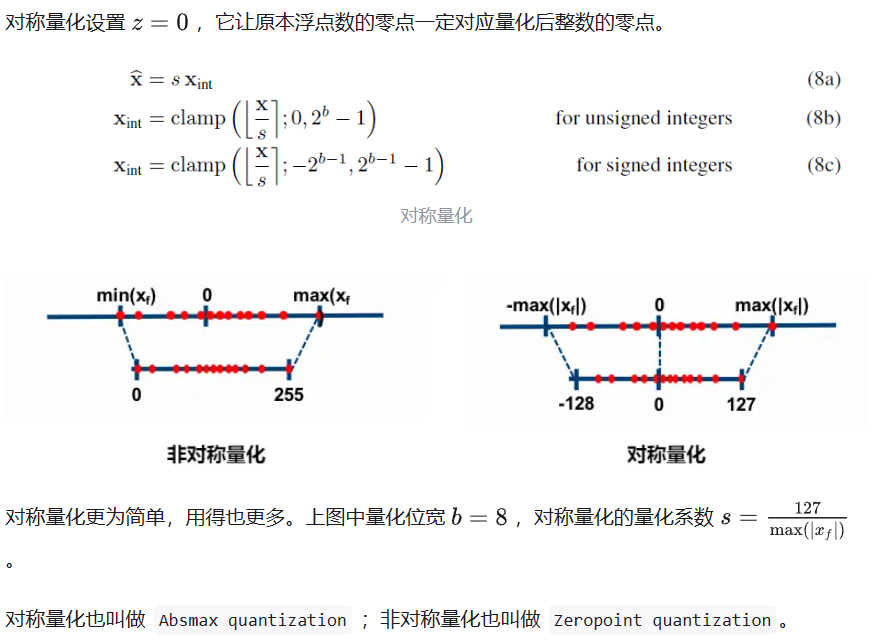
4.2 量化算法
根据量化的时机,有量化感知训练和训练后量化两条路径。
训练后量化 PTQ:
将已经训练好的模型的权重转换为较低的精度,而无需任何再训练。尽管PTQ简单易实现,但由于权重值的精度损失,它可能会略微降低模型的性能。
- 目前针对 LLM 的量化研究都集中在 Post-training quantization (PTQ)。像是 LLM.int8(), SmoothQuant, GPT-Q 都属于这一范畴
对于权重而言,我们可以在推理前事先计算好量化系数,完成量化。但是对于激活(即各层的输入),它们事先是未知的,取决于具体的推理输入,会更加棘手。根据对激活的量化,分为动态与静态量化。- 动态量化:顾名思义,这是 on-the-fly 的方式:推理过程中,实时计算激活的量化系数,对激活进行量化。
- 静态量化:与动态量化相反,静态量化在推理前就计算好激活的量化系数,在推理过程中应用即可。
量化感知训练
与PTQ不同,QAT在训练阶段集成了权重转换过程。这通常不会明显降低模型性能,但对计算的要求更高。QLoRA就是一种高度使用QAT的技术。
Quantization Aware Training (QAT) 量化感知训练:首先正常预训练模型,然后在模型中插入“伪量化节点”,继续微调。所谓“伪量化节点”,就是对权重和激活先量化,再反量化。这样引入了量化误差,让模型在训练过程中“感知”到量化操作,在优化 training loss 的同时兼顾 quantization error.
- 通过 QAT,可以减小量化误差,尝试用更低的位宽去量化模型。
- QAT 虽好,但插入“伪量化节点”后微调大大增加了计算成本,尤其是面对超大规模的 LLM。
4.3 量化粒度
量化,必然有相应的量化系数 。量化粒度指的是计算 时范围大小——用到了多少个待量化参数。这个范围越小,说明有更少的待量化参数共享同一个 ,量化误差自然也越小。
- per-tensor: (one scale factor) per-tensor,这是最简单的一种方式,也是范围最大的粒度——整个激活矩阵对应一个量化系数 ;对于权重矩阵也是如此。
- per-token & per-channel

- Group-wise

注意:权重和激活可以选择不同的量化粒度。譬如权重用 per-tensor,激活用 per-token。并且对于激活还有动态量化与静态量化之分。
5. 量化的影响
- 精度损失:量化技术会引入一定的精度损失,这可能导致模型性能的下降。因此,如何在保证性能的同时实现高效的量化是亟待解决的问题。
- 计算速度提升:低精度的整数运算速度更快,可以加速模型的推理过程。
- 可移植性:由于不同的硬件平台对量化技术的支持程度不同,因此模型的移植性可能会受到影响。在实际应用中,需要考虑不同硬件平台的兼容性和优化。
附录
MMLU
MMLU(Massive Multitask Language Understanding)【大规模多任务语言理解能力】是一个新的基准,用于衡量在零样本(zero-shot)和少样本(few-shot)情形下,大模型在预训练期间获得的世界知识。
这使得该基准测试更具挑战性,也更类似于我们评估人类的方式。
- 该基准涵盖 STEM、人文(humanities)、社会科学(social sciences)等领域的 57 个学科(subject)。
- 学科范围从数学和历史等传统领域到法律和伦理等更为专业的领域。
它的难度从初级到高级,既考验世界知识,又考验解决问题的能力。 学科的粒度和广度使该基准成为识别模型盲点的理想选择。
C-Eval
C-Eval 是一个全面的中文基础模型评估套件。它包含了13948个多项选择题,涵盖了52个不同的学科和四个难度级别,如下所示。您可以在 探索 中查看我们的数据集示例,或查看我们的论文了解更多细节。
GSM8K
GSM8K 数据集是由 OpenAI 发布的小学数学题数据集,项目地址
GSM8K 由 8.5K 高质量的小学数学问题组成,这些问题都是由人类写手创造的。我们将这些问题分为 7.5K 训练问题和 1K 测试问题。这些问题需要 2 到 8 个步骤来解决,解决方法主要是使用基本的算术运算(+ - / *)进行一连串的基本计算,以得出最终答案。一个聪明的中学生应该能够解决每个问题
HumanEval
HumanEval: Hand-Written Evaluation Set,是《Evaluating Large Language Models Trained on Code》中提到的一个代码评测基准。
HumanEval的评估逻辑
每一个测试问题重复实验n次,然后通过单元测试,计算平均通过率。我们可以在源码地址中看到起执行逻辑