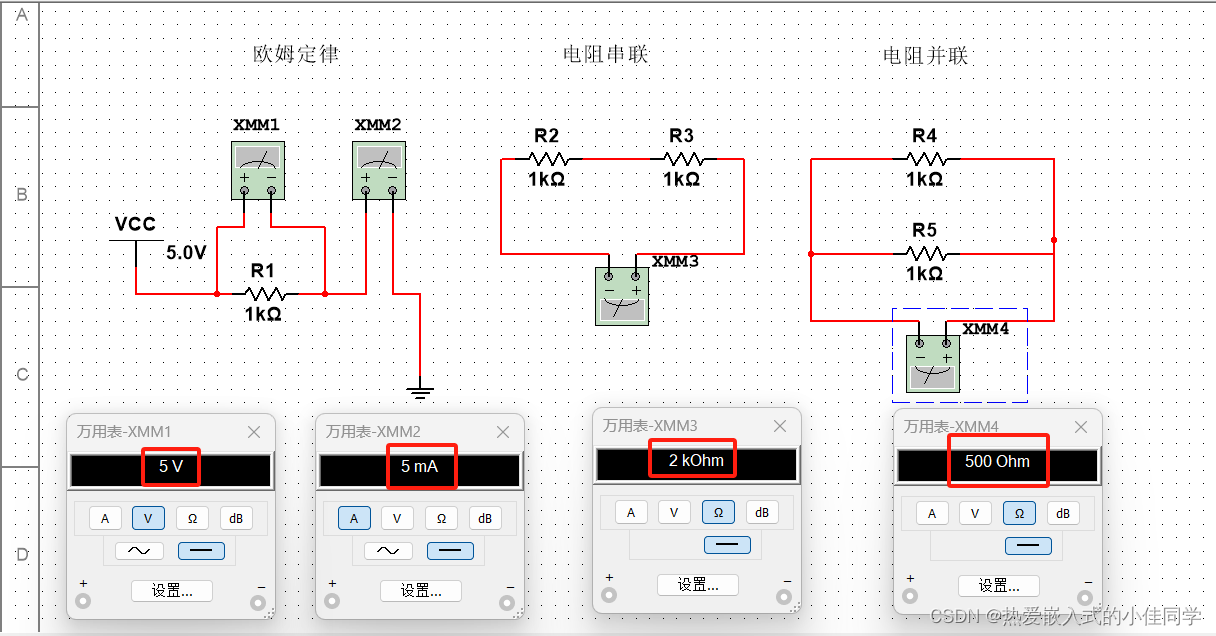
Paper Card
论文标题:Learning Interactive Real-World Simulators
论文作者:Mengjiao Yang, Yilun Du, Kamyar Ghasemipour, Jonathan Tompson, Leslie Kaelbling, Dale Schuurmans, Pieter Abbeel
作者单位:UC Berkeley, Google DeepMind, MIT, University of Alberta
论文原文:https://arxiv.org/abs/2310.06114
论文出处:ICLR 2024 oral
论文被引:7(03/03/2024)
项目主页:https://universal-simulator.github.io/unisim/
论文代码:–
研究问题:通过生成建模学习现实世界交互通用模拟器的可能性。
面临挑战:建立这种模拟器的一个障碍在于数据集——不同的数据集涵盖不同的信息,必须将这些信息整合在一起才能模拟出逼真的体验。
主要贡献:
- 我们将不同维度(如物体,场景,动作,运动,语言和运动控制)的各种数据集整合到一个统一的动作输入视频输出(action-in-video-out)生成框架中,从而迈出了构建通用真实世界交互模拟器的第一步。
- 我们将动作输入视频输出框架表述为以有限历史为条件,以视频扩散模型为参数的观察预测模型(observation prediction model)。我们说明了观察预测模型可以自回归方式推出,从而获得一致的长视距视频。
- 我们说明了模拟器如何使高层次语言策略,低层次控制策略和视频描述模型在纯粹的模拟训练中推广到现实世界,从而弥合模拟与现实之间的差距(sim-to-real gap)。
方法概述:我们将现实世界的模拟器定义为这样一个模型:在给定世界的某种状态(如图像帧)的情况下,它可以将某种动作作为输入,并将该动作的视觉结果(以视频的形式)作为输出。提出了处理每种类型数据的具体策略,以统一动作空间,并将不同长度的视频与动作对齐。有了统一的动作空间,我们就可以在第 2.2 节中训练一个以动作为条件的视频生成模型,通过一个将动作与视频相关联的通用接口来融合不同数据集的信息。
主要结论:
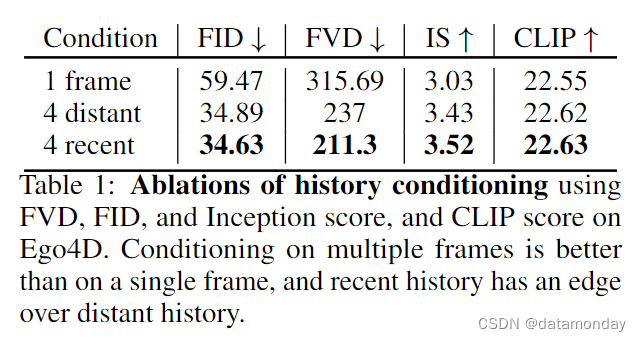
- 以 4 个帧为条件比以单个帧为条件更好,但以过去太远的历史为条件(距离呈指数增长的 4 个帧)会影响性能。在 Ego4D 上,增加 4 帧以上的条件帧数并不能进一步提高性能,但对于需要记忆遥远过去的应用(如导航检索)来说,这可能会有所帮助。
- 在对 UniSim 进行多样化数据联合训练的过程中,我们发现将大小差异较大的数据集进行简单组合会导致低数据域的生成质量较低。虽然我们可以在训练过程中增加这些域在数据混合物中的权重,但我们发现,将域标识符(如数据集名称)附加到动作条件中,可以提高低数据域的生成质量。
- UniSim 可以为其他机器学习子问题生成训练数据。这在自然数据稀少或难以收集的情况下(如犯罪或事故录像)尤其有用。
- UniSim 可以作为有效的数据生成器,用于改进更广泛的视觉语言模型。
- 以几帧近期历史为条件的模拟器无法捕捉长期记忆(例如,如果把苹果放进抽屉不是条件的一部分,那么抽屉打开后抽屉里的苹果就可能消失)。
- 我们的模拟器并不适用于那些不会引起视觉观察变化的操作环境(例如,抓握静态杯子时的不同力量)。真正的通用模拟器应能捕捉到视觉体验之外世界的方方面面(如声音,感官等)。
Abstract
基于互联网数据训练的生成模型(Generative models)已经彻底改变了文本,图像和视频内容的创建方式。生成模型的下一个里程碑或许是模拟人类,机器人和其他交互Agent所采取的行动(Actions)所带来的真实体验。真实世界模拟器(Real-World Simulator)的应用范围很广,从游戏和电影中的可控内容创建,到纯粹在模拟中训练可直接部署在真实世界中的具身智能体(Embodied Agent)。我们探讨了通过生成建模学习现实世界交互通用模拟器的可能性。我们首先提出了一个重要的观点:可用于学习现实世界模拟器的自然数据集通常在不同维度上都很丰富(例如,图像数据中的丰富物体,机器人数据中的密集采样动作以及导航数据中的各种运动)。通过对不同数据集(每个数据集都提供了整体体验的不同方面)的精心安排,我们可以从静态场景和物体中模拟出 “打开抽屉” 等高层次指令(high-level instructions)和 “通过 ∆x, ∆y 移动” 等低层次控制(low-level controls)的视觉结果。我们利用模拟器来训练高层次视觉语言策略和低层次强化学习策略,每种策略都可以在模拟训练后在现实世界中零样本(zero-shot)部署。我们还展示了其他类型的智能,如视频描述模型,也能从模拟经验的训练中获益,从而开拓更广泛的应用。视频演示请访问 universal-simulator.github.io。
1 Introduction
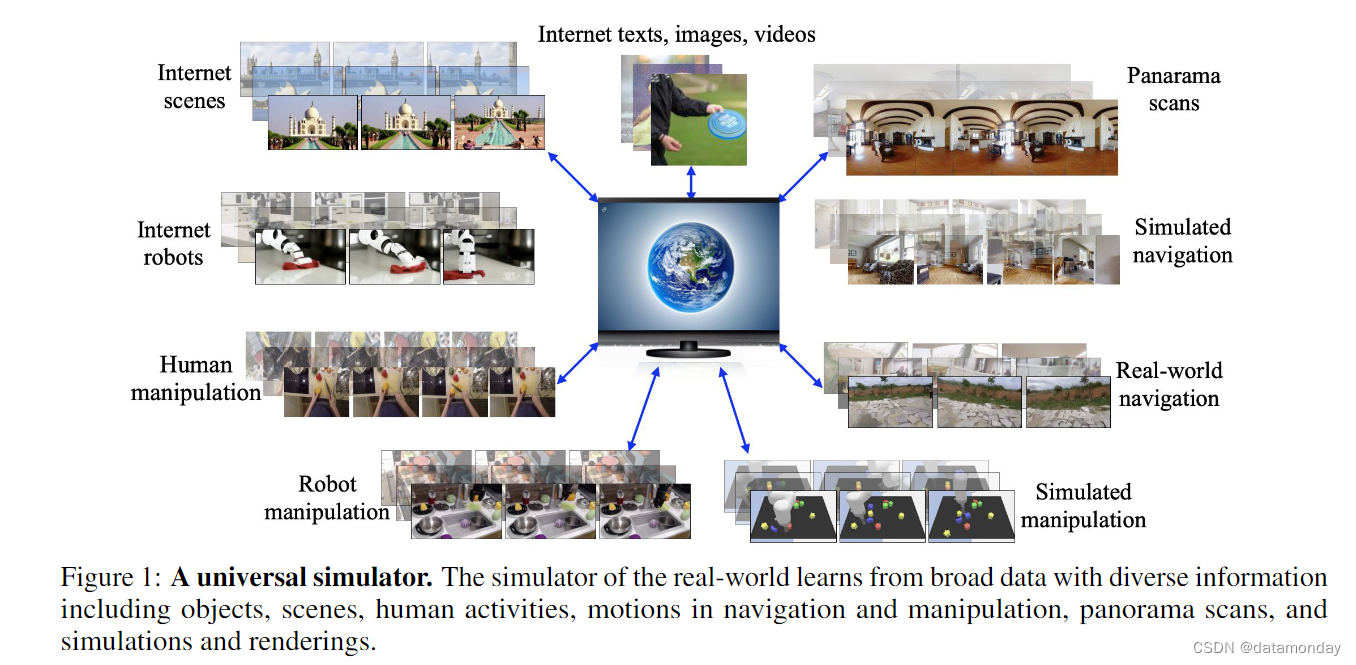
基于互联网数据训练的生成模型现在可以生成高度逼真的文本[1],图像[2]和视频[3]。或许,生成模型的最终目标是能够模拟各种行为的视觉效果,从汽车如何在街道上行驶,到家具和饭菜是如何准备的。有了真实世界模拟器,人类就能与各种场景和物体交互(interact),机器人就能从模拟经验中学习,而不必冒身体受损的风险,同时还能模拟大量类似真实世界的数据,以训练其他类型的机器智能。
建立这种模拟器的一个障碍在于数据集——不同的数据集涵盖不同的信息,必须将这些信息整合在一起才能模拟出逼真的体验。例如,来自互联网的文本-图像配对数据包含丰富的场景和物体,但动作却很少[4, 5];视频描述和问答数据包含丰富的高层次描述,但低层次动作细节却很少[6, 7];人类活动数据包含丰富的人类动作,但机械动作却很少[8, 9];机器人数据包含丰富的机器人动作,但数量有限[10, 11]。由于不同的数据集是由不同的行业或研究团体出于不同的目的策划的,因此信息的差异是自然的,也是难以克服的,这给试图捕捉世界所有视觉方面的真实世界模拟器带来了困难。
在这项工作中,我们建议在条件视频生成框架中结合大量数据,实例化一个通用模拟器(universal simulator)。在统一的动作-视频-输出(action-in-video-out)接口(interface)下,该模拟器可通过对静态场景和物体的细粒度运动控制实现丰富的交互。为了支持长视距(long-horizon)重复交互,我们将模拟器设计为一个观测预测模型(observation prediction model),该模型可以自回归方式推出,以支持跨视频生成边界的一致模拟。
“通用” 的意思是模型可以通过动作和视频的统一接口来模拟,而不是能够模拟一切。例如,声音没有被模拟。
虽然模拟器的潜在应用范围很广,但我们展示了三个具体的使用案例。
- 首先,我们展示了模拟器如何通过对模拟经验的事后重新标注(hindsight relabeling),使视觉语言策略能够执行长视距目标条件任务[12]。除了学习高层次视觉语言策略,我们还说明了模拟器如何利用基于模型的强化学习(RL)[13] 来学习低层次控制策略。
- 高层次视觉语言策略和低层次控制策略虽然纯粹是在模拟中训练出来的,但可以推广到真实的机器人环境中。通过使用在视觉上与真实世界几乎无差别的模拟器,可以实现这一点,从而在消除具身学习中模拟与真实之间的差距方面迈出了一步[14]。
- 此外,我们还可以模拟数据收集成本高昂或危险的罕见事件(如自动驾驶汽车的碰撞)。这些模拟视频可用于改进其他机器智能,如罕见事件检测器(rare event detectors),这表明通用模拟器在具身学习之外也有广泛的应用。
主要贡献可归纳如下:
- 我们将不同维度(如物体,场景,动作,运动,语言和运动控制)的各种数据集整合到一个统一的动作输入视频输出(action-in-video-out)生成框架中,从而迈出了构建通用真实世界交互模拟器的第一步。
- 我们将动作输入视频输出框架表述为以有限历史为条件,以视频扩散模型为参数的观察预测模型(observation prediction model)。我们说明了观察预测模型可以自回归方式推出,从而获得一致的长视距视频。
- 我们说明了模拟器如何使高层次语言策略,低层次控制策略和视频描述模型在纯粹的模拟训练中推广到现实世界,从而弥合模拟与现实之间的差距(sim-to-real gap)。
2 Learning an Interactive Real-World Simulator
我们将现实世界的模拟器定义为这样一个模型:在给定世界的某种状态(如图像帧)的情况下,它可以将某种动作作为输入,并将该动作的视觉结果(以视频的形式)作为输出。学习这样的模拟器非常困难,因为不同的动作有不同的格式(如语言指令,机器人控制,摄像机动作),视频也有不同的帧频。不过,我们在第 2.1 节中提出了处理每种类型数据的具体策略,以统一动作空间,并将不同长度的视频与动作对齐。有了统一的动作空间,我们就可以在第 2.2 节中训练一个以动作为条件的视频生成模型,通过一个将动作与视频相关联的通用接口来融合不同数据集的信息。
2.1 Orchestrating Diverse Datasets
下面,我们将重点介绍不同数据集中的各种信息,并提出将行动处理为通用格式的方法(见附录 9 中用于训练 UniSim 的所有数据集)。
Simulated execution and renderings.
为真实世界的视频添加动作注释的成本很高,而 Habitat [15] 等模拟引擎可以呈现各种各样的动作。我们使用以前从这些模拟器中收集的数据集,即使用 HM3D 的 Habitat 物体导航 [16]和 [17] 的Language Table数据来训练 UniSim。我们提取文本描述作为可用的动作。对于模拟的连续控制动作,我们通过语言嵌入对其进行编码,并将文本嵌入与离散控制值连接起来。
Real robot data.
越来越多的真实机器人执行视频数据与任务描述(如 Bridge Data [18] 以及支持 RT-1 和 RT-2 [19]的数据)相匹配。尽管不同机器人的底层控制动作往往不同,但任务描述可以作为 UniSim 中的高层动作。在有类似模拟机器人数据的情况下,我们会进一步将连续控制动作离散化。
Human activity videos.
丰富的人类活动数据,如 Ego4D [9],EPIC-KITCHENS [20] 和 Something-Something V2 [21] 等,已经被整理出来。与低层次的机器人控制不同,这些活动是人类与世界交互的高层次行为。但这些动作通常作为标签提供给视频分类或活动识别任务[21]。在这种情况下,我们将视频标签(video labels)转换为文本动作(text actions)。此外,我们还对视频进行子采样,以捕捉有意义动作的帧率(frame rate)构建观察片段(chunks of observations)。
Panorama scans.
Matterport3D [22] 等3D扫描技术非常丰富。这些静态扫描不包含动作。我们通过截断全景扫描(truncating panorama scans)来构建动作(如左转),并利用两幅图像之间的相机姿势信息。
Internet text-image data.
成对的文本图像数据集(如 LAION [23])包含各种物体的静态图像,没有任何动作。然而,描述通常包含运动信息,如 “一个人在走路”。为了在 UniSim 中使用图像数据,我们将单张图像视为单帧视频,将图像描述视为动作。
对于每个数据集,我们使用 T5 语言模型嵌入 [24] 将文本标记(text tokens)处理为连续表示,并与诸如机器人控制等低层次动作(low-level actions)连接(concatenated)起来。这就是我们模拟器的最终统一动作空间。
[24] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
2.2 Simulating Long-Horizon Interactions through Observation Prediction
通过将不同环境中的观察结果转换为视频,以及将不同格式的动作转换为连续嵌入,我们可以将与许多真实世界环境的交互表述为与通用模拟器的交互。然后,我们将通用模拟器表述为一个观察预测模型,该模型可根据动作和先前的观察结果预测观察结果,如图 2 所示。最后,我们将展示这一观察预测模型可以通过视频扩散(video diffusion)进行参数化。
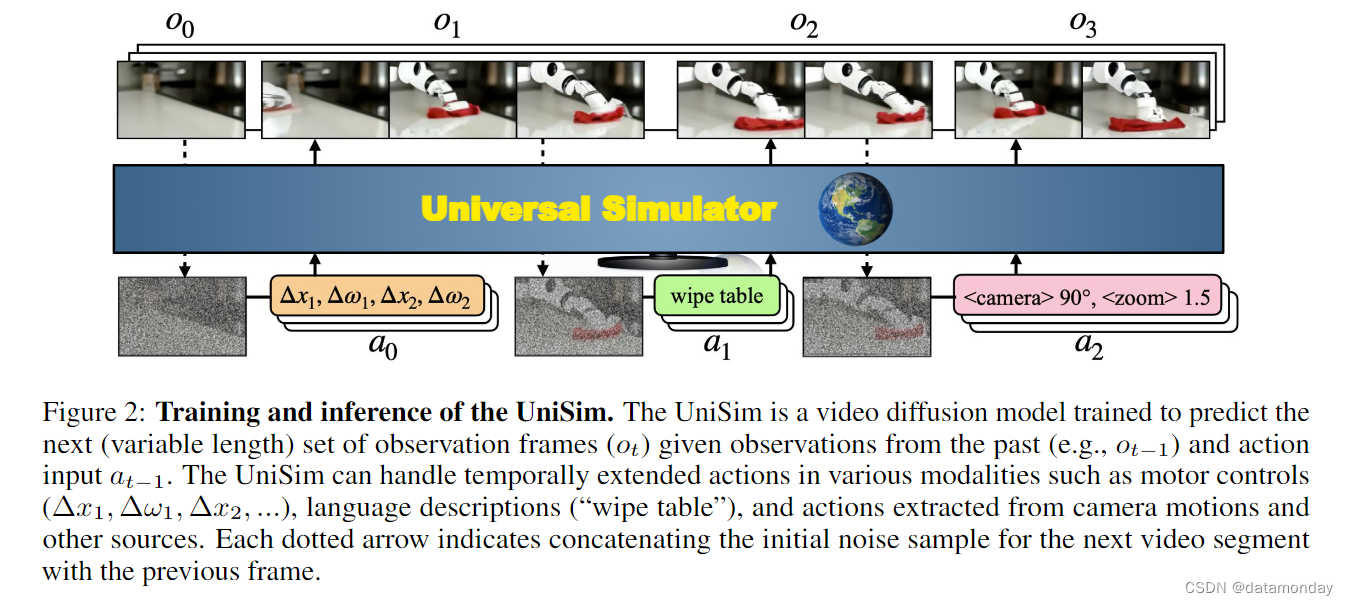
UniSim 是一个视频扩散模型,经过训练,可以根据过去的观察(例如 ot-1)和−1 处的动作输入来预测下一个(可变长度)观察帧(ot)。UniSim 可以处理各种模态的时间扩展动作,如运动控制(∆x1,∆ω1,∆x2,…),语言描述 (“wipe table”) 以及从相机运动和其他来源中提取的动作。每个虚线箭头表示将下一个视频片段的初始噪声样本与前一帧连接起来。
Simulating Real-World Interactions.
我们定义了一个观察空间 O 和一个行动空间 A,它们捕捉了第 2.1 节中描述的视频和行动。在一个特定的交互步骤 t 中,Agent在观察到一组历史帧 ht-1∈ O 后,决定采取一些时间上扩展的行动 at-1∈ A,这些行动可以分解为一系列低层次机器人指令,在现实世界中执行。在执行过程中,下一组视频帧 ot∈ O 将从真实世界中捕获。模拟器的目标是根据 ht-1 和 at-1 预测 ot。我们可以把这个预测问题表述为学习一个观测预测模型 p(ot|ht-1,at-1)。理想的预测模型应该以过去的所有信息为条件,即(o0, a0 … , at-2, ot-1),并通过一些循环状态,但我们发现,以有限的帧集(例如,最近一次交互的帧集:ot-1)为条件极大地简化了建模问题。为了模拟长时间的交互,我们可以从观测预测模型 p(ot|ht-1,at-1) 中采样,并以之前采样的观测结果为条件进行自回归。这种观测预测模型的一个优点是,模拟器在所有任务中都保持不变,可以与任何奖励函数结合使用,而奖励函数可以单独学习。正如我们将在第 4.1 节和第 4.2 节中说明的那样,学习到的奖励函数可用于使用规划和 RL 等现有决策算法优化策略 π(at|ht)。
Parametrizing and Training the Simulator.
我们使用扩散模型(diffusion models)[25, 26] 作为图 2 所示 UniSim 的实例,对 p(ot|ht-1,at-1)进行参数化。具体来说,反向过程学习去噪模型 ε θ ( o t ( k ) , k ∣ h t − 1 , a t − 1 ) ε_θ (o^{(k)}_t , k|h_{t-1}, a_{t-1}) εθ(ot(k),k∣ht−1,at−1) ,该模型以历史记录为条件,通过 K 个去噪步骤从初始噪声样本中生成下一个观测值。在实际应用中,我们只使用以前的视频帧,而省略以前的动作作为历史记录,并将以前的视频帧与初始噪声样本 o t ( K ) ∼ N ( 0 , I ) o^{(K)}_t ∼ \mathcal{N}(0, I) ot(K)∼N(0,I) 按通道串联(concatenate)起来,作为去噪模型的条件输入。为了对动作 at-1 进行条件化,我们利用了 classifier-free diffusion guidance [27]。最终 T (ot|ht-1, at-1) 由方差表参数化:

Architecture and Training.
我们使用 video U-Net 架构 [28] 通过在下采样和上采样过程中使用交错时间和空间注意力和卷积层来实现 UniSim。对于历史条件(history conditioning),我们在所有未来的帧索引中复制条件帧(conditioning frame),并将条件帧与未来每一帧的噪声样本连接起来,作为 U-Net 的输入。UniSim 模型有 5.6B 参数,需要 512 个 TPU-v3 和 20 天来训练所有数据。请参阅附录 10 中的更多细节。
[28] video diffusion models
3 Simulating Real-World Interactions
我们通过模拟人类和机器人的丰富动作和长视距交互,演示了模拟真实世界的操纵和导航环境。
3.1 Action-Rich, Long-Horizon, and Diverse Interactions+
Action-Rich Simulation.

我们首先通过自然语言操作演示了富含动作的交互。图 3 显示了从相同的初始观察(最左列)开始的人类操作和导航模拟。我们可以指示初始帧中的人执行各种厨房任务(左上),按下不同的开关(右上)或浏览场景(下)。该模型仅在一般互联网数据上进行了训练,而未在 EPIC-KITCHENS [20] 等动作丰富的操作数据上进行训练,因此无法模拟动作丰富的操作(附录 13)。
Long-Horizon Simulation.

接下来,我们在图 4 中展示了 8 个连续的交互过程。如第 2.2 节所述,我们将先前的观察结果和新的语言操作作为每次交互的模拟条件。UniSim 成功地保留了之前指令所操作的物体(例如,橙子和罐子在放入第 4,5,7,8 列的抽屉后被保留下来)。参见附录 8.1 中的其他长视距交互。
Diversity and Stochasticity in the Simulator.

UniSim 还能支持高度多样化和随机的环境转换,例如,取下上面的毛巾后会露出不同的物体(图 5 左),不同的物体颜色和位置(图 5 右中的杯子和笔)以及摄像机角度变化等真实世界的变化。扩散模型的灵活性促进了对无法通过行动控制的高度随机环境的模拟,从而使策略可以学会只控制可控部分[29]。
3.2 Ablation and Analysis
Frame Conditioning Ablations.
我们使用 Ego4D 数据集[9]的验证集,对过去帧数的选择进行了消减,该数据集包含以自我为中心的运动,需要正确处理观察历史。我们在表 1 中比较了以不同数量的过去帧为条件的 UniSim。以 4 个帧为条件比以单个帧为条件更好,但以过去太远的历史为条件(距离呈指数增长的 4 个帧)会影响性能。在 Ego4D 上,增加 4 帧以上的条件帧数并不能进一步提高性能,但对于需要记忆遥远过去的应用(如导航检索)来说,这可能会有所帮助。
Simulating Low-Data Domains.
在对 UniSim 进行多样化数据联合训练的过程中,我们发现将大小差异较大的数据集进行简单组合会导致低数据域的生成质量较低。虽然我们可以在训练过程中增加这些域在数据混合物中的权重,但我们发现,将域标识符(如数据集名称)附加到动作条件中,可以提高低数据域的生成质量,如图 6 所示。虽然这种域标识符能提高分布内的生成质量,但我们发现特定域标识符会影响对其他域的泛化,因此只有在测试域处于训练域的分布中时才应使用。

4 Applications of the UniSim
现在,我们将展示如何利用 UniSim 通过模拟高度逼真的体验来训练其他类型的机器智能,如视觉语言策略,RL Agent 和视觉语言模型。
4.1 Training Long-Horizon Vision-Language Policies through Hindsight Labeling.
语言模型和视觉语言模型(VLM)最近被用作可在基于图像或文本的观察和行动空间中运行的策略 [30, 31, 32]。学习此类Agent的一大挑战在于需要大量的语言动作标签。随着任务范围和复杂程度的增加,数据收集的劳动强度也会增加。UniSim 可以通过事后重新标注为 VLM 策略生成大量的训练数据。
Setup and Baseline.
[33] Language Conditioned Imitation Learning over Unstructured Data
我们使用 Language Table Environment [33]中的数据来学习桌子上积木的几何重新排列。我们使用 PALM-E 架构[31](参见附录 11.1 中的数据和模型详情)训练图像-目标条件 VLM 策略,以预测语言指令和起始图像与目标图像中的运动控制(参见附录 11.1 中的数据和模型详情)。对于基线,目标被设置为原始短视距轨迹的最后一帧。在每次评估运行中,我们通过修改 3-4 个区块的位置来设定长距目标,并在使用 VLM 策略执行 5 条指令后测量区块到目标状态的距离。我们将目标距离缩短度量定义为:
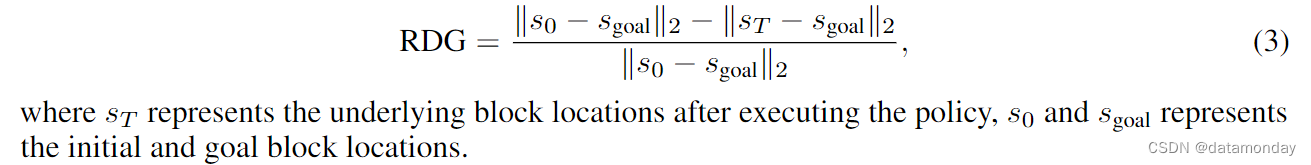
Generating Hindsight Data with the Simulator.
为了将模拟器用于长视距任务,我们从事后重标注(hindsight relabeling)[34]中汲取了灵感。具体来说,我们通过在模拟器中对每条轨迹进行 3-5 次滚动(rollouts)来创建总计 10k 条长视距轨迹,其中每次滚动对应一条脚本语言指令。然后,我们将每次长视距滚动的最终帧作为目标输入,并将脚本语言指令作为训练 VLM 策略的监督。
[34] Hindsight policy gradients
Results on Real-Robot Evaluation.
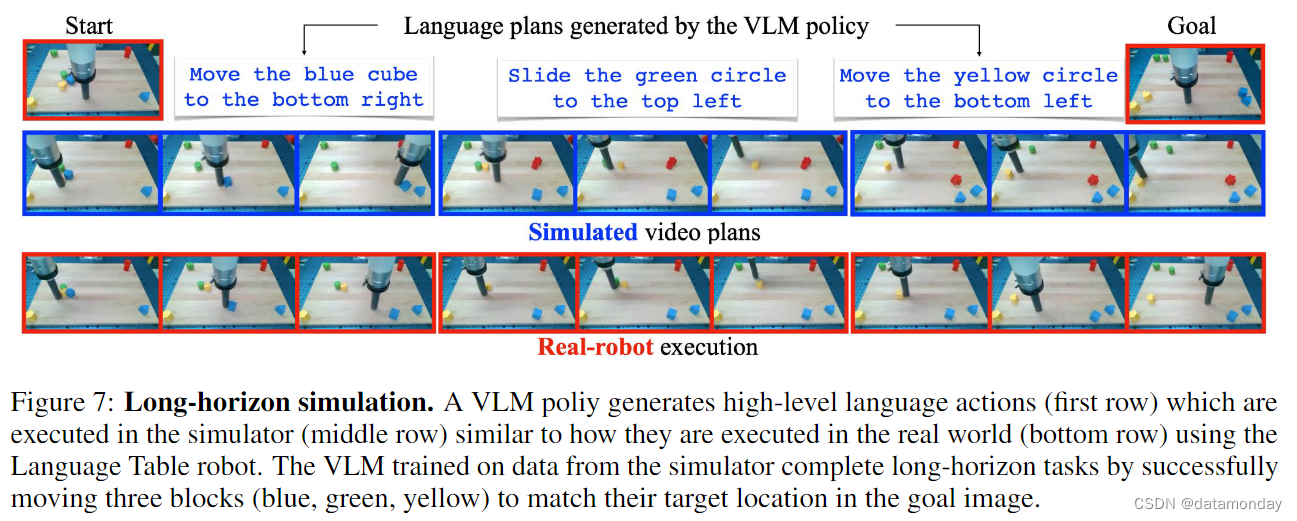
尽管 VLM 策略仅在模拟数据上进行了训练,但它仍能根据真实 Language Table 表域中的初始和目标图像生成有效的高层次语言动作,而训练模拟器的数据正是在该 Language Table 域中收集的。模拟器可以模拟来自初始真实观测数据的视频轨迹,并利用反动力学模型(inverse dynamics model)从中恢复机器人动作,然后在真实机器人上执行。图 7 显示了 VLM 生成的语言动作,模拟器根据语言动作生成的视频以及在真实机器人上的执行情况。我们可以看到,模拟视频轨迹已成功转化为真实世界中的机器人动作。附录 8.2 列出了长距 VLM 策略的其他结果。
Results on Simulated Evaluation.
除了通过将视频轨迹转换为真实机器人上执行的机器人动作来测试语言指令和模拟视频外,我们还进行了基于模拟器的评估,比较了使用生成的长视距数据和使用原始短视距数据的 VLM 策略对目标距离(RDG)的减少(见表 2)。使用生成的长视距数据训练的 VLM 在完成长视距目标条件任务时的表现比使用原始数据时好 3-4 倍。

4.2 Real-World Simulator for Reinforcement Learning
强化学习(RL)在下围棋和 Atari 游戏等高难度任务上取得了超人的表现[35 , 36],但在现实世界中的应用却很有限,原因之一是缺乏逼真的环境模拟器[37]。我们研究了模拟器能否通过为Agent提供可并行访问的逼真模拟器来实现对 RL Agent的有效训练。
Setup.
我们对 PaLI 3B 视觉语言模型[38]进行了微调,利用行为克隆(BC)技术从图像观察和任务描述(如 “向右移动蓝色立方体”)中预测低层次控制动作(∆x,∆y 中的关节运动),作为低层次控制策略和基线,我们称之为视觉语言动作(VLA)策略,与[32]类似。由于 UniSim 可以将底层控制动作作为输入,因此我们可以使用 VLA 策略生成的控制动作在模拟器中直接进行基于模型的滚动(rollouts)。为了获取奖励信息,我们使用训练数据中的完成步数作为Agent奖励,训练一个将当前观察结果映射到所学奖励的模型。然后,我们使用 REINFORCE 算法[39]优化 VLA 策略,将模拟器中的滚动操作视为真实环境中的策略滚动操作,并使用所学奖励模型预测模拟滚动操作的奖励。有关 RL 训练的详情,请参阅附录 11.2。
[32] RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Results.
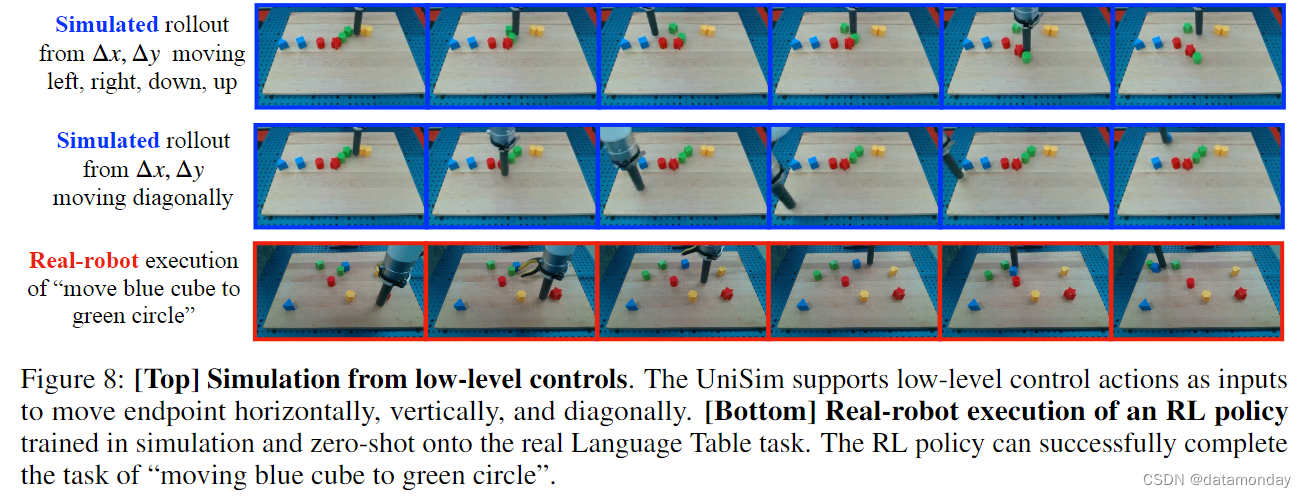
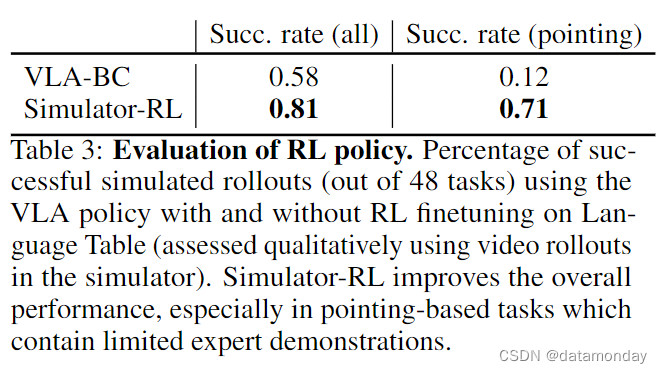
我们首先对模拟真实机器人的执行情况进行正确性检查,方法是在图 8(最上面两行)中反复应用低层次控制动作(例如,∆x = 0.05,δy = 0.05),持续 20-30 个环境步长,使端点向左,向右,向下,向上和向对角线移动。我们可以看到,模拟滚动既捕捉到了端点的移动,也捕捉到了碰撞的物理现象。为了将模拟训练的 RL 策略与 BC 策略进行比较,我们在模拟器中对模拟滚动进行了定性评估。表 3 显示,在一系列任务中,RL 训练显著提高了 VLA 策略的性能,尤其是在 "指向蓝色块 "等任务中。然后,我们将在模拟器中训练好的 RL 策略直接部署到真实机器人上,并观察到成功执行任务的情况,如图 8 所示(最下面一行)。在真实机器人上的其他结果见附录 8.3。
4.3 Realistic Simulator for Broader Vision-Language Tasks
UniSim 可以为其他机器学习子问题生成训练数据。这在自然数据稀少或难以收集的情况下(如犯罪或事故录像)尤其有用。我们在 UniSim 生成的纯数据上训练视觉语言模型,提供了这样一个概念验证,并观察到在视频描述方面的显著性能优势。
Setup.
我们对 PaLI-X 进行了微调[40],PaLI-X 是一个在大量图像,视频和语言任务中经过 55B 参数预训练的 VLM,我们使用 ActivityNet Captions 的训练部分[7]中的文本为 UniSim 生成的一组视频添加描述。我们按照与[40]相同的设置,测量了经过微调的模型在 ActivityNet Captions 测试部分以及其他描述任务上的 CIDEr 分数。参见附录 11.3 中 PaLI-X 的微调详情。
Results.
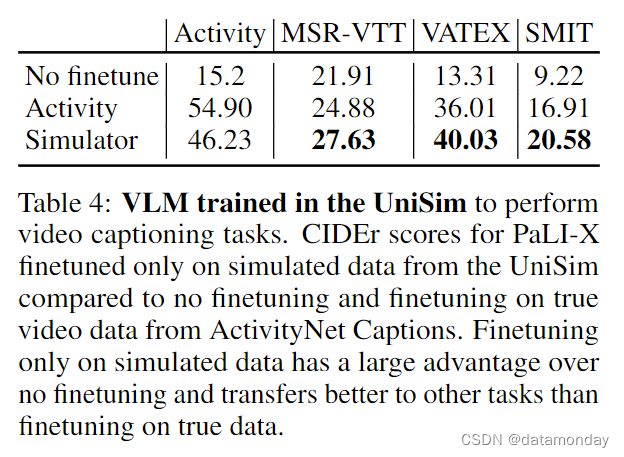
在表 4 中,我们将在纯生成视频上进行微调的 PaLI-X 与未进行微调的预训练 PaLI-X 以及在原始 ActivityNet 描述上进行微调的 PaLI-X 进行了比较。与在 ActivityNet 上完全不做微调相比,在生成的数据上进行纯微调能大幅提高描述性能(从 15.2 到 46.23),同时达到在真实数据上微调性能的 84%。此外,与在真实数据上进行微调的 PaLI-X 相比,在生成数据上进行微调的 PaLI-X 在 MSR-VTT[6],VATEX [41] 和 SMIT [42] 等其他描述任务中的应用效果更好,而在真实数据上进行微调的 PaLI-X 往往会过拟合 ActivityNet。这些结果表明,UniSim 可以作为有效的数据生成器,用于改进更广泛的视觉语言模型。
5 Related Work
Internet-Scale Generative Models.
在互联网文本上训练的语言模型在基于文本的任务上取得了成功[1 , 43],但在需要感知和控制的物理任务上却不成功。互联网规模的生成模型可以合成逼真的图像和视频[44 , 3, 45 , 46 , 47],但大多被应用于生成媒体[48],而不是授权能够进行多轮交互的复杂Agent。[49]显示视频生成可以作为策略,但策略学习的主要瓶颈往往在于对真实世界环境的访问有限[37]。我们正是通过学习真实世界的通用模拟器来解决这一瓶颈问题,从而实现现实和无限的 "环境 "访问,以交互方式训练复杂的Agent。
Learning World Models.
针对控制输入学习精确的动力学模型是系统识别[50],基于模型的强化学习[51]和优化控制[52 , 53]领域的长期挑战。大多数系统选择在低维状态空间而非像素空间学习每个系统的动力学模型 [54, 55 , 56 , 57],尽管这是一个更简单的建模问题,但却限制了系统间的知识共享。在大型Transformer架构下,学习基于图像的世界模型已变得可行[58 , 59 , 60 , 61 , 62 , 63],但主要是在游戏或模拟领域,这些领域的视觉简单且数据丰富。在视频的生成建模方面,之前的研究已经利用文本提示 [64, 65],驾驶动作 [66, 67],3D几何 [68, 69],物理模拟 [70],频率信息 [71]和用户注释 [72],将动作引入视频。不过,它们的重点是生成特定领域的视频(例如,用于自动驾驶),而不是构建一个通用模拟器,用于进一步改进其他Agent。这些现有研究对生成视频的控制也很有限,因为它们没有像我们的研究那样,将视频生成视为动态建模问题。
6 Limitations and Conclusion
我们已经证明,可以根据从文本到机器人控制等各种动作输入来学习现实世界的模拟器。UniSim 可以模拟与人类交互和训练自主Agent的视觉真实体验。我们希望 UniSim 能够激发人们对学习和应用真实世界模拟器来提高机器智能的广泛兴趣。我们的模拟器存在一些局限性,需要在今后的工作中加以改进:
Hallucination.
当一个动作在场景中不现实时(例如,给桌面机器人下达 “洗手” 的指令),我们就会观察到幻觉(例如,桌子变成了水槽,或者视线从桌面机器人身上移开,出现了一个水槽)。理想情况下,我们希望 UniSim 能够检测到无法模拟的操作,而不是产生不切实际的结果。
Limited memory.
以几帧近期历史为条件的模拟器无法捕捉长期记忆(例如,如果把苹果放进抽屉不是条件的一部分,那么抽屉打开后抽屉里的苹果就可能消失)。需要多少历史记录取决于模拟器的应用(例如,模拟器是用于近马尔科夫环境下的策略学习,还是用于需要长期记忆的问答)。
Limited out-of-domain generalization.
对于训练数据中没有体现的领域,情况尤其如此。例如,模拟器主要是针对 4 种机器人形态进行训练的,因此它对未见过的机器人的泛化能力有限。进一步扩大训练数据的规模可能会有所帮助,因为训练数据与互联网上的所有视频数据相差甚远。
Visual simulation only.
我们的模拟器并不适用于那些不会引起视觉观察变化的操作环境(例如,抓握静态杯子时的不同力量)。真正的通用模拟器应能捕捉到视觉体验之外世界的方方面面(如声音,感官等)。
Appendix
在本附录中,我们还提供了在真实机器人上运行的人机交互长视距模拟(第 8.1 节),长视距 VLM 策略(第 8.2 节)和低层次 RL 策略(第 8.3 节)的定性结果。我们还在第9节中详细介绍了用于训练UniSim的数据集,在第10节中详细介绍了UniSim的模型架构和训练细节,在第11节中详细介绍了UniSim应用的三个实验设置。最后,我们提供了UniSim未在广泛数据集上联合训练时的失败示例(第13节)。视频演示可在 anonymous-papers-submissions.github.io 上找到。
8 Additional Results
8.1 Additional Long-Horizon Interaction

8.2 Additional Real-Robot Results for Long-Horizon Language Policy

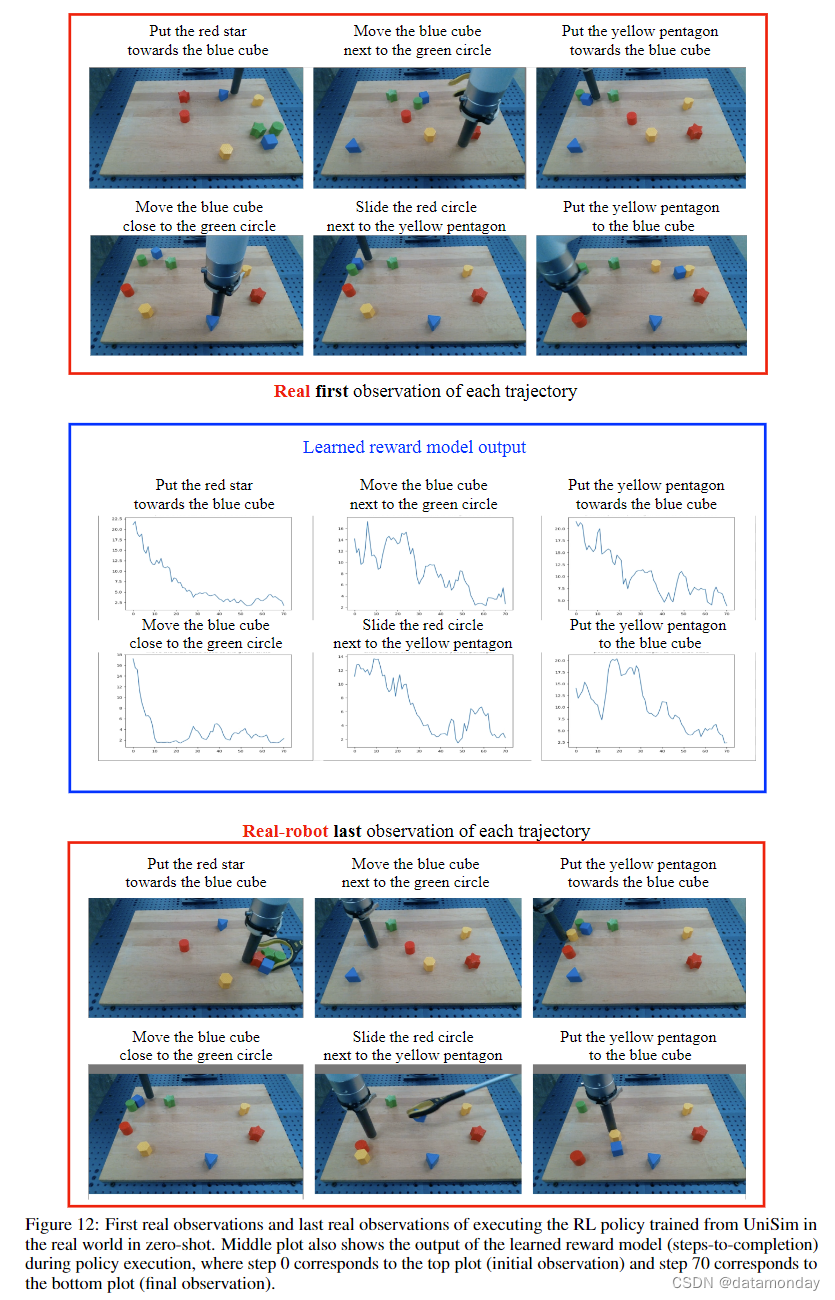
8.3 Additional Results on Learning RL Policy in UniSim

9 Datasets
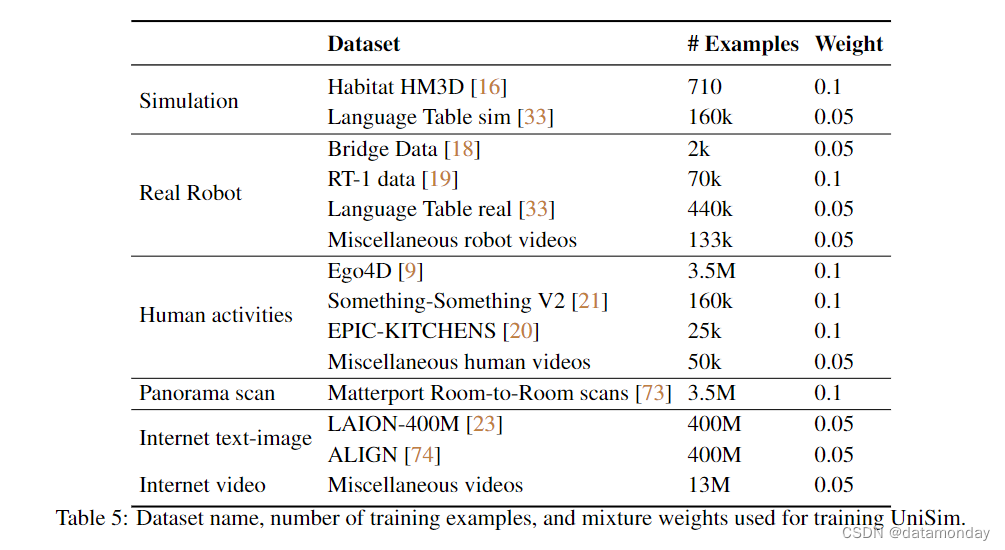
我们在下面提供了用于训练 UniSim 的数据集,包括数据集名称,训练示例数量(近似值)以及在数据混合物中的权重。Miscellaneous 数据是尚未公布的数据集的集合。其中一些数据集已处理为训练和验证两个部分,因此训练示例的数量可能与原始数据大小不同。当原始数据集中有文本时,我们使用 T5 语言模型嵌入[24]将文本预处理为连续表征。当原始数据集中可用的低级控制时,我们将它们编码为文本并进行归一化,然后将它们离散为 4096 个 bin,这些 bin 与语言嵌入(如果存在)相连接(concatenate)。混合权重选择为 0.1 或 0.05,无需仔细调整。数据混合权重如何影响模拟性能是未来工作的一个有趣方向。
10 Architecture and Training
我们使用 3D U-Net 架构 [75 , 28] 来参数化 UniSim 视频模型。与标准 3D U-Net 一样,我们先应用空间降采样通路(spatial downsampling pass),再应用空间升采样通路(spatial upsampling pass),并通过交错的 3D 卷积层和注意力层与降采样通路激活点建立跳转连接。UniSim 中的视频模型包括一个以历史条件为基础的视频预测模型和两个类似于[3]的附加空间超分辨率模型。历史条件基础模型在时间和空间分辨率[16, 24, 40]下运行,两个空间超分辨率模型分别在空间分辨率[24, 40] → [48, 80]和[48, 80] → [192, 320]下运行。为了使基础视频模型以历史数据为条件,我们从上一段视频中提取 4 个帧,并将它们按通道与输入 U-Net 的噪声样本进行串联。我们在前向模型中采用了时间注意力,以实现最大的建模灵活性,但出于与 [3] 类似的效率原因,我们在超分辨率模型中采用了时间卷积。表 6 总结了 UniSim 的模型和训练超参数。
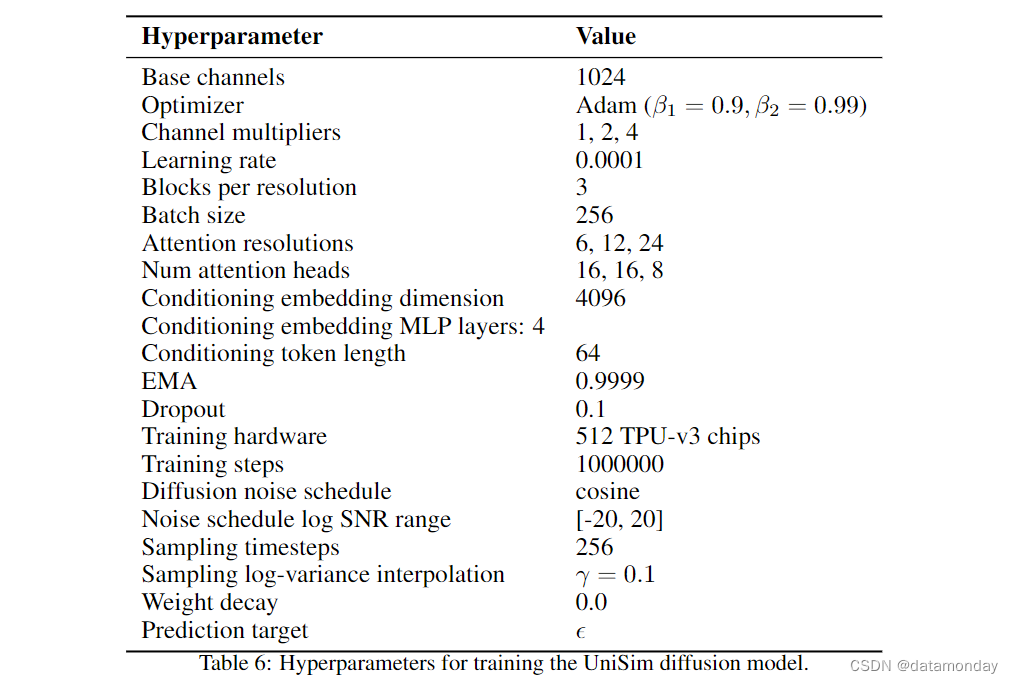
11 Details of Experimental Setups
11.1 Details of Learning Long-Horizon Policy
Language Table Dataset and environment.
Language Table Dataset [33]数据集由 16 万条模拟轨迹和 44 万条真实轨迹组成,其中每条轨迹都包含一条语言指令(如 “向右移动蓝色立方体”),一系列视觉运动控制以及与任务执行相对应的一系列图像帧。原始轨迹的视野较短(例如,只移动一个方块)。
PALM-E VLM Policy.
我们修改了最初的 PALM-E 12B Model [31],将目标图像作为额外输入条件,然后再对文本动作进行解码。VLM 在原始的短视距数据或使用 64 个 TPUv3 芯片的长视距模拟数据上进行了为期 1 天的微调。短视距基线的监督是原始数据中的单步语言指令,而长视距 UniSim 数据的监督是生成视频数据的脚本长视距语言指令链。其他模型架构和训练细节见 [31]。
Simulated evaluation.
在模拟环境中设置目标时,3-4 个区块中的一个子集(随机选择)沿 x,y 轴移动 0.05,0.1 或 0.2(随机选择)。原始观测空间的 x∈[0.15, 0.6] 和 y∈[-0.3048, 0.3048]。因此,目标位置的修改对应于有意义的区块移动。在执行根据 UniSim 数据训练的长视距 VLM 策略时,我们首先从 VLM 中采样一条语言指令,预测 16 帧视频,然后使用类似于 [49] 的单独训练的反动力学模型来恢复底层控制动作。我们总共执行了 5 条指令,并根据 Ground Truth 模拟器的状态测量了到目标的最终距离。我们使用不同的随机种子对初始状态进行采样并重置目标,共进行了 5 次评估,并在表 2 中报告了平均值和标准误差。
11.2 Details of RL Policy Training
Stage 1 (Supervised Learning) Model Architecture
在 Language Table 上训练的 PaLI 3B 模型使用视觉转换器架构 G/14 [5] 来处理图像,并使用 UL2 语言模型的编码器-解码器架构 [76] 来编码任务描述和解码标记,这些标记可以代表语言,控制动作或其他相关值(如下所述)。目标在训练的第一阶段,我们使用一个演示数据集,通过以下任务对预训练的 PaLI 3B 视觉语言模型检查点[38]进行微调:
- Behavioral Cloning:根据观察结果和任务指令,预测示范动作。Language Table域的连续动作被离散化为 “+1 -5” 的形式,并使用 PaLI 模型标记词汇表中的额外标记来表示。例如,“+1 -5” 用标记序列 (<extra_id_65>, <extra_id_1>, <extra_id_66>, <extra_id_5>) 表示。
- Timestep to Success Prediction:根据观察结果和任务指令,预测距离剧情结束(即成功)还剩多少步。与行动类似,剩余步数通过 PaLI 模型标记词汇表中的额外标记来表示。
- Instruction Prediction:给定一集的第一帧和最后一帧,预测与该集相关的任务指令。
我们使用学习率 0.001,dropout rate 0.1 和 batch size 128 对 PaLI 3B 模型进行微调,在模拟和真实Language Table数据集(类似 RT-2 [32])上进行了 300k 梯度练习和 1k 热身练习。
Stage 2 (RL Training) Reward Definition
如上所述,在第一阶段,给定观察结果和目标后,PaLI 模型会进行微调,以预测在演示情节达到成功状态之前还剩多少个时间步。我们用 d(o,g)来表示这个函数。我们在 RL 训练过程中使用的奖励定义为 r(ot, at, ot+1, g) = -[d(ot+1, g) - d(ot, g)] - C,其中 C > 0 是一个用于稳定训练的小常数(本工作中 C = 5e - 2)。直观地说,如果从时间步 t 到 t + 1,该策略更接近于实现预期目标,则会获得奖励。在开始第二阶段之前,我们会复制第一阶段的模型检查点,并将其冻结,作为 RL 训练的奖励模型。Environment Definition:为了将视频生成作为环境转换来实现,我们通过远程过程调用公开了视频生成模型的推理接口,并使用 DeepMind RL Environment API(也称为 DM Env API)[77] 将远程过程调用封装在环境的步骤函数中。当重置环境以开始新一集时,会从第一阶段使用的演示数据集中随机抽取目标指令。RL Method:我们使用阶段 1 检查点初始化经过 RL 训练的策略,如前所述,该策略也是通过行为克隆目标进行训练的。一系列角色进程在视频生成环境中执行策略滚动,并使用上文定义的奖励模型为轨迹添加奖励。使用 REINFORCE [39] 目标对策略进行更新,即
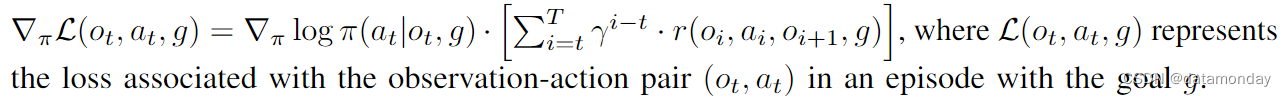
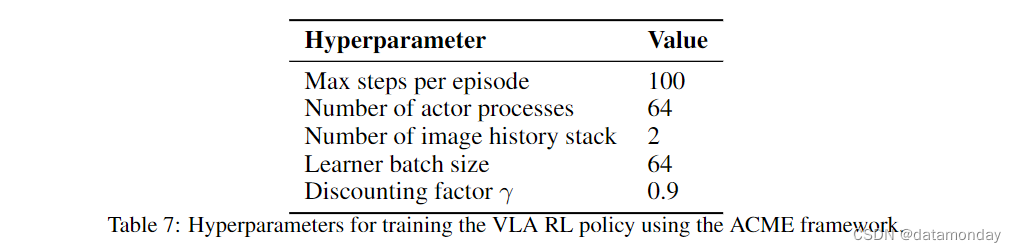
行为体的速率受到限制,以防止生成的轨迹严重偏离策略。我们在表 7 中报告了与 RL 训练相关的超参数。
11.3 Details of Video Captioning
需要注意的是,尽管 UniSim 是基于视频的模拟器,但我们可以通过输入占位帧(如白色图像)来实现纯文本调节,同时提高文本的无分类器引导(classifier-free guidance)强度。我们发现,这种方法在纯粹根据 ActivityNet Captions 的描述生成视频时效果很好。在生成用于训练 VLM 的数据时,我们采用了 ActivityNet Captions 的训练分割,其中包括 30,740 个文本-视频示例,如 [40] 中的 50/25/25% train/val1/val2 分割。对于这 30740 个文本中的每个文本,我们都从 UniSim 中生成了 4 个视频,并在微调 PaLI-X 时使用文本标签作为监督。这样,我们就拥有了 4 倍于原始训练数据的视频数量。此外,我们发现生成的视频通常比原始 ActivityNet Captions 视频的语义一致性更好,因为原始 ActivityNet Captions 视频中可能包含噪音和模糊视频,这些视频可能会被贴上不同的标签。在评估时,我们使用了[40]和[7]的Ground Truth时间建议。根据[40]和[78],我们使用 val1 分割进行验证,使用 val2 分割进行测试。
12 Additional Ablations
12.1 Ablations of Datasets
我们对 UniSim 中使用的数据集进行了消减,计算了来自测试分割的 1024 个样本的 FVD 和 CLIP 分数。我们发现,包含互联网数据以及各种活动和机器人数据的结果最佳。移除互联网数据后,FVD 明显降低,这凸显了在 UniSim 中使用互联网数据的重要性。

12.2 Ablations of Model Size
我们通过计算 1024 个测试分割样本的 FVD 和 CLIP 分数,对模型大小进行了消减。我们发现,虽然增大模型尺寸可以提高视频建模性能,但随着模型尺寸的增大,用 FVD 衡量的改进幅度会趋于平稳,这从扩展的角度来看略微令人失望。

13 Failed Simulations without Joint Training