概述
作为ELK技术栈一员,Logstash用于将数据采集到ES,通过简单配置就能把各种外部数据采集到索引中进行保存,可提高数据采集的效率。
原理
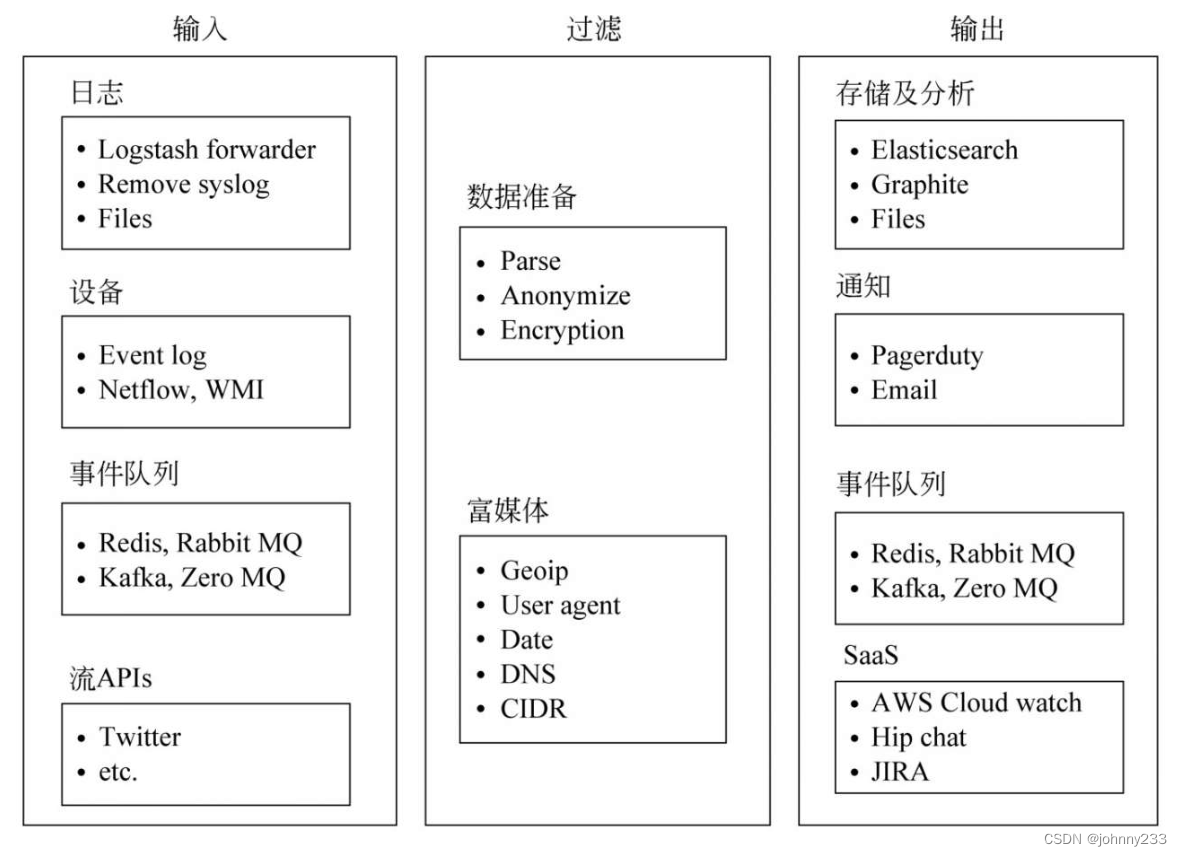
数据源提供的数据进入Logstash的管道后需要经过3个阶段:
- input:负责抽取数据源的数据,这个过程一般需要包含数据源的连接方式、通信协议和抽取间隔等信息,目的是将原始数据源源不断地接入数据管道。
- filter:将抽取到数据管道的数据按照业务逻辑的需要进行数据转换,例如添加或删除部分字段、修改部分字段的数据内容等。
- output:将过滤后的数据写入数据的目的地,在大多数情况下,数据会被写入ES索引,也可把数据写入文件或其他地方。
安装
从官网下载解压即可使用,找到bin目录下的脚本文件,双击即可完成安装。
目录
以版本为例,目录如下:
- bin:包含各种二进制形式的可执行脚本,如Logstash的启动脚本、插件脚本
- config:各种配置文件
- data:Logstash脚本执行时默认的数据目录
- lib:Logstash运行时的库文件
- logs:Logstash运行时产生的日志文件
- logstash-core:包含Logstash的关键组件
- logstash-core-plugin-api:包含Logstash的插件API
- modules:包含Logstash拥有的模块文件
- tools:包含Logstash运行时可用的工具组件
- vendor:包含Logstash运行时依赖的Ruby环境
- x-pack:包含Logstash的X-Pack插件扩展内容
配置
logstash.yml
命令行启动会覆盖logstash.yml里的配置:
| 配置 | 说明 |
|---|---|
path.data | 配置Logstash运行时产生的临时数据目录,默认为data目录 |
pipeline.workers | 从临时队列中消费数据进行过滤处理的线程数 |
pipeline.batch.size | 单个线程能够多从队列中一次性消费的事件数目,默认值125 |
pipeline.ordered | 控制数据流是否有序输出,若为talse则不能保证数据有序向外输出;若为true则只启用一个工作线程进行消费,保证数据有序。默认值为auto,只有在工作线程数设置为1时才保证有序 |
path.config | 指定启动的数据采集脚本的目录 |
config.reload.automatic | 若为true,则自动检查并加載最新的采集脚本,修改采集脚本后可以避免重启Logstash实例;若为talse,则采集脚本修改后需重启Logstash才能生效 |
queue.type | 用于设置缓冲队列的类型,默认队列保存在内存中,若设置为persisted则会将队列数据持久化地存储到磁盘上 |
path.logs | 配置Logstash运行时产生日志的目录,默认是安装目录中的logs目录 |
dead_letter_queue.enable | 配置是否开启死亡消息队列功能,默认不开启。如果开启,则会把处理失败的数据持久化地存储到磁盘上以便将来有机会重新执行 |
jvm.options
jvm.options文件主要用于调整Logstash的JVM堆内存大小,默认值为1GB。通常这个值应该配置为4GB~8GB,最好不要超过机器物理内存大小的一半。性能调优时,可动态调整此配置并观察数据抽取速度与内存使用率,在两者之间取得平衡。
pipelines.yml
在一个Logstash进程中运行多个数据管道,即同时执行多个采集脚本,有两种方法:
pipelines.yml配置文件,指明每个数据管道的配置参数,没有声明的配置,则使用logstash.yml中配置:
- pipeline.id: testpipeline.workers: 1pipeline.batch.size: 1path.config: "a.config"
- pipeline.id: another_testqueue.type: persistedpath.config: "/tmp/logstash/*.config"
- 在命令行中指定不同的数据目录来执行脚本:
.\bin\logstash -f .\a.conf --path.data=.\data1
.\bin\logstash -f .\b.conf --path.data=.\data2
组件
input
包括如下插件:
- stdin:表示在命令行接收用户的输入
- file:读取文件
- generator:产生指定的或随机的数据流
- jdbc:从数据库读取数据,需配置JDBC几个要素,如渠道包路径,驱动类全路径名,数据库链接URL(用户名和密码可单独配置)
filter
包括如下插件:
- grok:使用模式匹配的数据抽取
- date:从字段中解析时间戳等
- mutate:
- geoip:通过来访者的IP能定位其地理位置等信息
- kv:键值对
output
包括如下插件:
- stdout:打印输出到控制台。rubydebug是一个编解码器,常用于开发者观察和调试数据管道中的各个字段内容
- file:输出到文件
- elasticsearch:存储到ES
除了上面几种,还支持通知类:
- pagerduty:警报系统工具
- nagios:开源的网络监视工具
- zabbix:提供分布式系统监视以及网络监视功能
- email:告警邮件
实战
配置文件由输入->过滤->输出三部分组成,每部分都是由插件构成,每个插件负责处理日志的不同过程:
input {...
}
filter {...
}
output {...
}
采集Nginx日志
采集Nginx日志到ES,nginx-log.conf配置文件:
input {file {path => "D:/nginx-1.16.1/logs/access.log"start_position => "beginning"}
}
filter {Grok {match => { "message" => "%{COMBINEDAPACHELOG}" }}
}
output {stdout {codec => rubydebug}elasticsearch {hosts => ["http://localhost:9200"]index => "nginx-log"action => "index"}
}
start_position设置为beginning表示第一次从头开始读取日志文件,如果不进行此设置,则默认file-input插件只读取新增的日志记录
Grok插件,将数据流的message字段按照COMBINEDAPACHELOG的格式解析成多个结构化的字段
增量抽取表数据
要实现对数据库表数据的增量抽取,前提条件是表结构要有递增时间字段或自增长主键。每次抽取完数据,Logstash会把最后一条数据的时间或数字写入文件作为抽取标记,下次抽取时只抽取该时间或数字之后的新数据。
实例配置文件jdbc.conf:
input {jdbc {jdbc_driver_library => "D:\\bin\\mysql-connector-j-8.3.0.jar"jdbc_driver_class => "com.mysql.cj.jdbc.Driver"jdbc_connection_string => "jdbc:mysql://localhost:3305/sakila?serverTimezone=GMT%2B8"jdbc_user => "root"jdbc_password => "root"statement => "SELECT actor_id,first_name,last_name,date_format(last_update, ‘%Y-%m-%d %H:%i:%S’) as last_update from actor where last_update > :sql_last_value"record_last_run => trueuse_column_value => truetracking_column_type => "timestamp"tracking_column => "last_update"last_run_metadata_path => "./actor"schedule => "* * * * *"}
}
filter {mutate {remove_field => ["@timestamp", "@version"]}mutate {add_field => {"whole_name" => "%{first_name}-%{last_name}"}}
}
output {stdout {codec => rubydebug}elasticsearch {hosts => ["http://localhost:9200"]index => "actor"document_id => "%{actor_id}"action => "index"}
}
使用mutate过滤器,删除数据流中的两个字段@timestamp和@version,以防止它们出现在索引中。也可以新增字段whole_name表示拼接first_name和last_name。
statement里的SQL语句末尾加上where条件,表示只查询last_update字段大于最后一次抽取标记的数据。record_last_run设置为true,表示要保存抽取标记,抽取标记保存在last_run_metadata_path。tracking_column_type设置为timestamp表示抽取标记字段是时间类型的,如果选择自增长数字主键作为抽取标记,则设置为numeric。tracking_column用于指定抽取标记的列名称,use_column_value设置为true表示使用数据的内容作为抽取标记,否则使用最后一次查询的时间作为抽取标记。
加密敏感配置
上面抽取数据库表的配置里含有敏感字段如密码等,Logstash支持加密敏感配置。
执行命令:.\bin\logstash-keystore create。执行成功后,config目录下会生成密钥存储文件logstash.keystore,用于保存将要加密的变量。新建一个加密变量pwd:.\bin\logstash-keystore add pwd,输入数据库的明文密码,即root。更新配置文件:jdbc_password => "${pwd}",取代原先的明文密码。
进阶
上面的实战只能算是入门。
Logstash用{}来定义区域,支持常用数据类型。Logstash的DSL,如区域、注释、数据类型(布尔值、字符串、数值、数组、哈希)、条件判断、字段引用等,是Ruby风格的。
条件语法
在Logstash中可以用条件语法来支持不同条件做不同的处理,这种方式和其他开发语言基本一致。
用于output:
output {# Send production errors to pagerdutyif [loglevel] == "ERROR" and [deployment] == "production" {pagerduty {...}}
}
插件管理
Logstash提供多种多样,四种类型的插件。每种插件都有不同的属性和语法,需要参考官方文档。随Logstash版本升级,插件也在丰富中。插件可作为独立的软件包存在,插件管理器通过bin/logstash-plugin脚本来管理插件的整个生命周期,如:安装、卸载、升级插件:
# 列出插件
bin/logstash-plugin list
bin/logstash-plugin list --verbose
bin/logstash-plugin list '*namefragment*'
bin/logstash-plugin list --group output
# 安装插件
bin/logstash-plugin install logstash-output-kafka
# 更新插件
bin/logstash-plugin update
bin/logstash-plugin update logstash-output-kafka
# 移除插件
bin/logstash-plugin uninstall logstash-output-kafka
插件类型:
- input
- filter
- output
- codec
codec
编解码插件,主要是为了对事件进行处理改变事件的数据内容,是基本的流过滤器,可作为输入或输出的一部分。
codec可使得Logstash更方便地与其他自定义数据格式的产品共存,如graphite(开源的存储图形化展示的组件)、fluent、netflow、collectd(守护进程,是一种收集系统性能和提供各种存储方式来存储不同值的机制),以及使用msgpack、json等通用数据格式的其他产品。
codec有针对avro、cef、cloudfront、cloudtrail、collectd、compress_spooler、dots、edn、edn_lines、es_bulk、fluent、graphite、gzip_lines、json、json_lines、line、msgpack、multiline、netflow、nmap、oldlogstashjson、plain、rubydebug、s3_plain等多种数据来源的插件,可格式化相应的数据。
常用的rubydebug,使用ruby awesome print库来解析日志格式。
自定义插件
参考
- Elasticsearch数据搜索与分析实战
- Elasticsearch技术解析与实战