关于HBM那份纪要的其他反馈
上篇文章发了一篇HBM纪要小部分内容(星球更新了另一部分),收到很多业内大佬们的反馈,包括颗粒计算、封装订单划分等等,以及是不是某通某电的一个专家。其中倒是出现一个非共识的说法,引用下:
“XX现在其实还做不出,或者说技术还落后,技术底子还是差了点。反而另一家YY的HBM和DRAM进展不错在one厂完成了小规模量产,third期除了GKJ其他可以实现100%国产。两家给了国产几大设备厂大量研发攻坚任务,尤其是TSV高深宽比和孔内镀膜,技术难度和价值量最大。”
某家Broker sales评论美股
2月份的科技资金流入由PANW和NVDA引领,这两家公司成为我们客户当月买入最多的单一股票。此外,在被动投资科技方面非常活跃,因为QQQ达到了多年来的月度流入高点,我们客户的流入量也达到2021年9月以来最高。M7继续带领标普500的上涨是否可持续?在2023年的前三个季度,SPX的上涨(+11.7%)中94%来自M7的推动(+11.0%),这意味着剩下的493只股票基本每涨。但自2023年10月以来,M7的贡献下降到了35%,M7上涨了25.3%,为SPX的反弹贡献了6.4%,而剩下的493只股票上涨了16.1%,为SPX的反弹贡献了12.0%。从产业角度,现在可能是AI行情的初期,可以想想1990年代初的早期互联网时代、以及1990年代末的dot.com时代,每个阶段都持续了多年。实际上,围绕M7的乐观情绪有助于改善整体市场情绪,就比如最近的上涨已经扩大到M7之外的科技股。从资金看,美国共同基金在2月转为流入,SPX前50股票在2月至今的每一天都是positive call skew,意味着个人投资者的乐观情绪,在为看涨期权支付溢价。此外个人投资者在16个月连续卖出之后1月转为买入,2月继续呈现买入,且他们自2022年5月以来的95周中有93周都在积累现金,总计9660亿美元,如果利率开始下降,有很大的空间将资金转移到股票。但另一方面,不确定来自FOMC 3月20日的下一次会议。
MS拍的世芯Alchip的收入拆分
说实话,如果你去考古比如2010年前Wallstreet对谷歌meta apple之类的预测模型,和今天实际对比下,会发现错得离谱,为啥,线性预测,你我本能的思维方式,但大家也知道,事物的发展一定是非线性的。因此你说AWS给500、750、然后到25年可能的确小年放个800,再然后呢?从scaling law本身指数型算力需求+推理占比提升+自制需求提升+未来某一天cowos放量,我不太买账这种线性外推拍出来的数(虽然我心里也没个准...),但隐约感觉大方向是继续上调。何况你也不知道有什么新增客户后面会冒出来,这些都不可预测。有时候得接受预测的无能...

戴尔电话会透露英伟达B200
戴尔CFO替英伟达“非官方”披露了B200发布时间为2025年(如下图)。按照H100和H200的时间差也差不多(H100 是22年GTC H200是 23年11月)这也不算什么惊喜,市场对B200也有预期,只不过这是第一次被产业链公司公开提及。另一个重点是提到B200功耗会在1000W以上(H100是700W),且CFO来了句“你真的不需要直接液冷来达到这种能量密度”。Tom' Hardware刚刚发了文章对此做了分析,按照散热的普遍系数,芯片面积的散热通常最高约为每平方毫米 1W,而B系列双芯片设计,面积妥妥上1500平方毫米了,因为3nm,可能再打个折,1000W-1500W之间。但按照CFO下面的话,直接浸润式液冷也不是必须,综合考虑前后成本投入和技术成熟度,估计B系列上冷板、风冷也还会持续一段时间。虽然一定是未来,但也需要给产业点时间。另一位大佬说B100会降频控在700W。

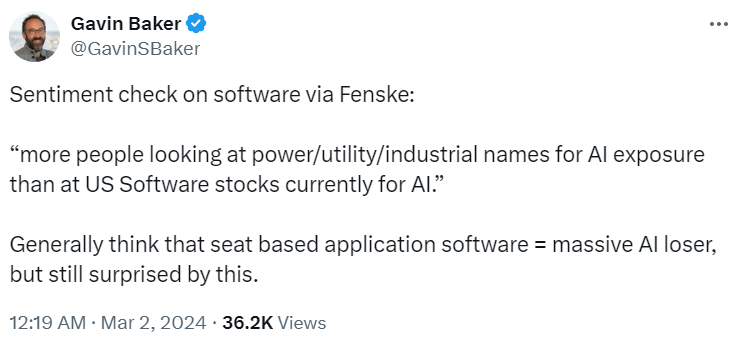
退一步看目前的市场,现在叙事的确朝着马斯克之前的暴论方向走,“现在是算力紧缺,未来是电力紧缺(PUE)”,step down transformer、cooling、IDC租赁、存储、甚至可能蔓延到IDC相关的各种基础设施。也就是Gavin Baker说的,“相比于软件,更多对AI的追逐转向了Power、utility、industrials等等” 2月份软件指数+2%,而SOX+15%(from F姐)。
Altimeter Jamin Ball 谈软件复苏
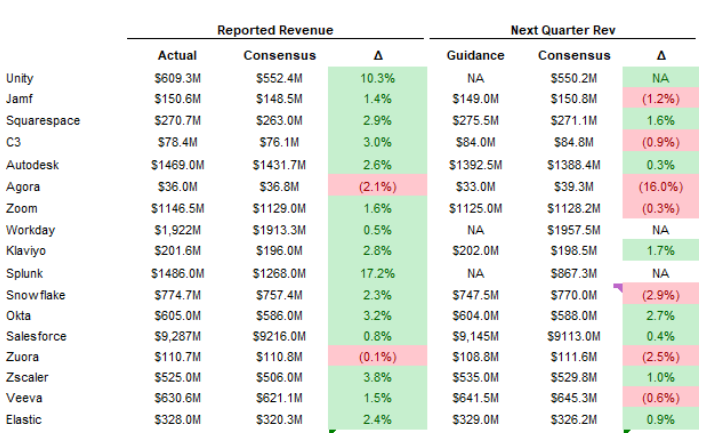
第四季度的ARR净新增创新高,从一些已经发报的公司earning上得到了验证,开始看到宏观逆风的减弱。从业绩和股价反应来看,FOMO的情绪在Software一点不比semi和hardware差,除了业绩miss太多的(SNOW),以及突然来个惊吓的(PANW)...但你看PANW之后修复,所以你说SNOW会怎么走?

关于推理芯片的一篇长文,提炼下干货:
OpenAI把复杂精细的算法管理变成了Self Attention这种简单算法+硬件暴力堆料的方式搞成了,直接O(n^2)的方式算上下文关联度就完事儿了,于是实现AGI的问题很大一部分简化成了芯片和系统设计的Scaling问题了,而芯片行业恰恰是人类所有工业体系里面Scaling技能点最牛逼的,等上下文长度Scaling起来又能把AGI涌现到什么程度我都不敢想。
注:1.解释了芯片在这次AGI淘金中的价值;2. 部分解释了为什么说scaling law可以通往AGI
未来长远来看,MOE和KV稀疏化是加速AGI Scaling从算法层面最有效的途径,其实也是从粗放式逐渐过渡到精细化管理静态和动态权重,从而可以创造在芯片Scaling基础上进一步更快加速超长上下文和超大模型的低成本Scaling,而对于硬件的容量需求会进一步扩大,同时随着稀疏化程度提高,使得Memory Hierarchy可能重新变得在系统层级更有意义
今天的Infra层面还远没有演进到对硬件系统如此高效的程度,多模态进一步加剧复杂程度。不同模态的流量潮汐、计算特点以及计算、内存、带宽资源占用情况,都会进一步加剧整个系统对于弹性的需求。
实际上LLM的推理对Infra层面的调度设计的复杂性压根不在transformer本身,而是在“大”模型产生的各自带宽流量问题,精细化利用高速内存和带宽资源催生的潜在的算子需求也已经开始爆炸,甚至复杂度是远高于原先的朴素算子的。这些算子和调度分别是在微观层面和宏观层面对硬件资源的极致利用,在今天这种对算力、带宽、容量、互联需求全都拉爆的应用上,这种极致利用会变得更加重要。而这些复杂的软件系统对LLM系统的设计增加了巨大的难度和工作量,似乎给所有NVidia的竞争者设置一层层障碍。
所以实际上NVidia对大模型推理这种对算力、内存容量、内存带宽、互联带宽、IO带宽、灵活性、可编程性都提出了极其变态的需求的场景应对方案就是在这些维度都做到第一,以一种统一的芯片形态保证了在综合维度的竞争力,当然这也是NVidia对于所有场景的统一策略,这个策略当然没错,NVidia今天大力提升显存带宽也是为了绞杀AMD在这两个维度的短期优势。
Alex Irpan的《我们距离AGI还有多远?》 from拾象
越来越多证据表明,即使仅通过计算规模增加和使用正确数据集,也能把不成熟的技术原型转化为成熟的产品。我现在完全信仰计算的力量,并且认为要想实现AGI,计算的占比是80%,剩下20%是理论创新。
如果模型不会陷入自我复制的循环,模型进步最终将不再取决于人类的智力努力,而是取决于投入到系统中的FLOPs计算资源的数量。即使合成标签(synthetic labels)比真实标签准确度更差,但它的成本也低,能大量用于模型训练。我认为未来合成数据和模型自我监督都会投入使用,到时的场景也许是这样:人类的直接反馈仅仅被用来引导或初始化奖励模型,或者对已有的数据进行合理性检查,而不是直接被用来训练模型。其他一切都将由模型自主生成和自我监督,然后不断反馈,不再依赖于人类直接的指导或监督。
在AI领域,模型永远无法完全实现人们的所有预期,但模型的能力却在持续扩展,而且从不倒退。今天的AI技术水平将会是未来几年的低点,因为AI还会继续进化。即使所有VC都失败,LLM不再流行,我们依然拥有了目前已经训练好的模型和衍生出的思想。技术的发展是不可逆转的,我们都应该好好思考这一点。