概述
昇腾(Ascend)是华为推出的人工智能处理器品牌,其系列产品包括昇腾910和昇腾310芯片等。
生态情况
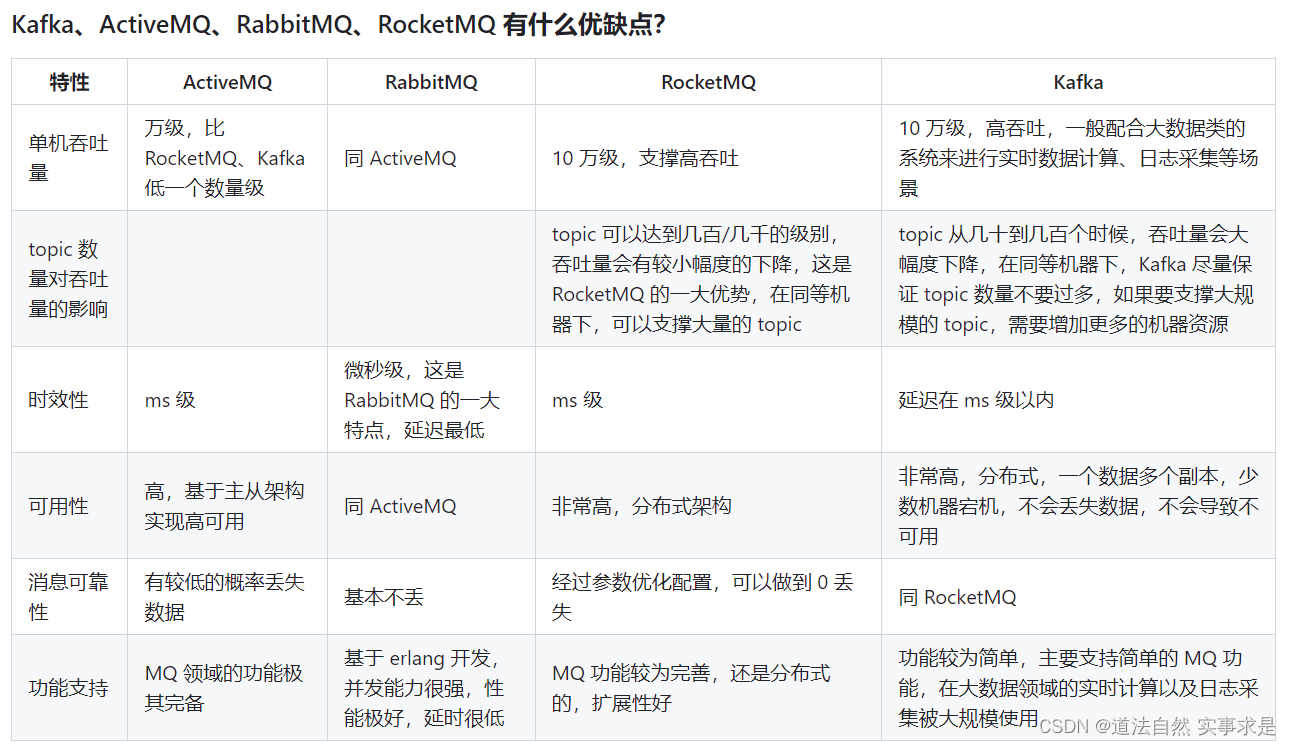
众所周知,华为昇腾存在的意义就是替代英伟达的GPU。从事AI开发的小伙伴,应该明白这个替代,不仅仅是 Ascend-910加速卡的算力 达到了Nvidia-A100的算力,而是需要整个AI开发生态的替代。下面简单列一下,昇腾生态与英伟达生态的一些对标项。
| Ascend | Nvidia | |
| 加速卡 | Ascend-910、Ascend-310 | Nvidia-A100、Nvidia-H100... |
| 服务器 | Atlas 800 训练服务器 | NVIDIA DGX |
| 计算架构 | CANN | CUDA cuDNN NVCC |
| 集合通信库 | HCCL | NCCL |
入门使用
假设原有基于GPU运行代码如下:
# 引入模块
import time
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import torchvision# 初始化运行device
device = torch.device('cuda:0') # 定义模型网络
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.net = nn.Sequential(# 卷积层nn.Conv2d(in_channels=1, out_channels=16,kernel_size=(3, 3),stride=(1, 1),padding=1),# 池化层nn.MaxPool2d(kernel_size=2),# 卷积层nn.Conv2d(16, 32, 3, 1, 1),# 池化层nn.MaxPool2d(2),# 将多维输入一维化nn.Flatten(),nn.Linear(32*7*7, 16),# 激活函数nn.ReLU(),nn.Linear(16, 10))def forward(self, x):return self.net(x)# 下载数据集
train_data = torchvision.datasets.MNIST(root='mnist',download=True,train=True,transform=torchvision.transforms.ToTensor()
)# 定义训练相关参数
batch_size = 64
model = CNN().to(device) # 定义模型
train_dataloader = DataLoader(train_data, batch_size=batch_size) # 定义DataLoader
loss_func = nn.CrossEntropyLoss().to(device) # 定义损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=0.1) # 定义优化器
epochs = 10 # 设置循环次数# 设置循环
for epoch in range(epochs):for imgs, labels in train_dataloader:start_time = time.time() # 记录训练开始时间imgs = imgs.to(device) # 把img数据放到指定NPU上labels = labels.to(device) # 把label数据放到指定NPU上outputs = model(imgs) # 前向计算loss = loss_func(outputs, labels) # 损失函数计算optimizer.zero_grad()loss.backward() # 损失函数反向计算optimizer.step() # 更新优化器# 定义保存模型
torch.save({'epoch': 10,'arch': CNN,'state_dict': model.state_dict(),'optimizer' : optimizer.state_dict(),},'checkpoint.pth.tar')参考华为官方文档快速体验-PyTorch 网络模型迁移和训练-模型开发(PyTorch)-...-文档首页-昇腾社区 (hiascend.com)
改造后,可以得到以下 用于在昇腾NPU上运行的训练代码(故意加多了全连接层的参数,以便看NPU使用情况):
# 引入模块
import time
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import torchvisionimport torch_npu
from torch_npu.npu import amp # 导入AMP模块
from torch_npu.contrib import transfer_to_npu # 使能自动迁移# 初始化运行device
device = torch.device('npu:0') # 定义模型网络
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.net = nn.Sequential(# 卷积层nn.Conv2d(in_channels=1, out_channels=16,kernel_size=(3, 3),stride=(1, 1),padding=1),# 池化层nn.MaxPool2d(kernel_size=2),# 卷积层nn.Conv2d(16, 32, 3, 1, 1),# 池化层nn.MaxPool2d(2),# 将多维输入一维化nn.Flatten(),nn.Linear(32*7*7, 4000), # 激活函数nn.ReLU(),nn.Linear(4000, 10000), nn.ReLU(),nn.Linear(10000, 10))def forward(self, x):return self.net(x)# 下载数据集
train_data = torchvision.datasets.MNIST(root='mnist',download=True,train=True,transform=torchvision.transforms.ToTensor()
)# 定义训练相关参数
# batch_size = 64
batch_size = 128
model = CNN().to(device) # 定义模型
train_dataloader = DataLoader(train_data, batch_size=batch_size) # 定义DataLoader
loss_func = nn.CrossEntropyLoss().to(device) # 定义损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=0.1) # 定义优化器scaler = amp.GradScaler() # 在模型、优化器定义之后,定义GradScalerepochs = 20 # 设置循环次数# 设置循环
for epoch in range(epochs):for imgs, labels in train_dataloader:start_time = time.time() # 记录训练开始时间imgs = imgs.to(device) # 把img数据放到指定NPU上labels = labels.to(device) # 把label数据放到指定NPU上with amp.autocast(): outputs = model(imgs) # 前向计算loss = loss_func(outputs, labels) # 损失函数计算optimizer.zero_grad()# 进行反向传播前后的loss缩放、参数更新scaler.scale(loss).backward() # loss缩放并反向转播scaler.step(optimizer) # 更新参数(自动unscaling)scaler.update() # 基于动态Loss Scale更新loss_scaling系数# 定义保存模型
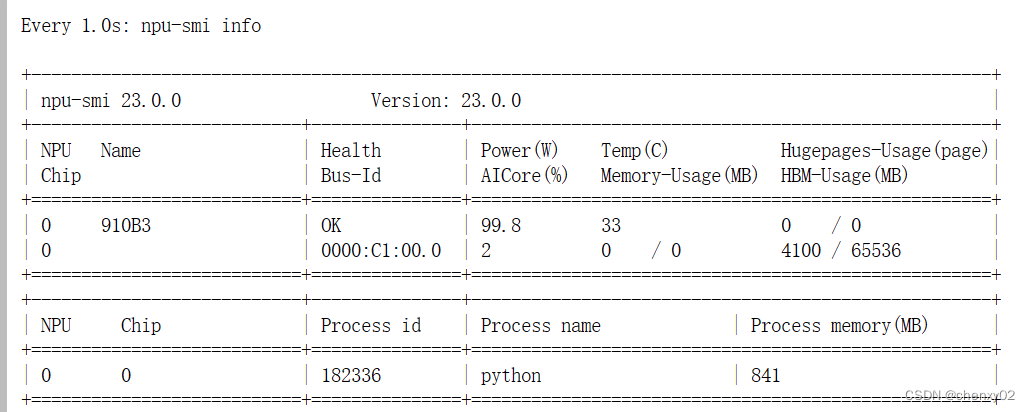
torch.save({'epoch': 10,'arch': CNN,'state_dict': model.state_dict(),'optimizer' : optimizer.state_dict(),},'checkpoint.pth.tar')使用 "python train.py" 运行代码后,我们可以通过以下命令查看昇腾NPU的使用情况:
watch -n 1 npu-smi info