目录
一、主机规划
二、环境准备
1. 启动 NTP 时钟同步
2. 修改 hosts 文件
3. 配置所有主机间 ssh 免密
4. 修改用户可打开文件数与进程数(可选)
三、安装 JDK
四、安装部署 Zookeeper 集群
1. 解压、配置环境变量
2. 创建配置文件
3. 创建新的空 ZooKeeper 数据目录和事务日志目录
4. 添加 myid 配置
5. 设置 Zookeeper 使用的 JVM 堆内存
6. 启动 ZooKeeper
7. 查看 ZooKeeper 状态
8. 简单测试 ZooKeeper 命令
五、安装配置 Hadoop HA 集群
1. 解压、配置环境变量(node1 执行)
2. HDFS 高可用配置
(1)创建存储目录
(2)修改核心模块配置
(3)修改 hdfs 文件系统模块配置
(4)修改 $HADOOP_HOME/etc/hadoop/workers
3. YARN ResourceManager 高可用配置
(1)修改 yarn 模块配置
(2)修改 MapReduce 模块配置
4. 分发配置文件其它节点
5. 启动 HDFS 相关服务
6. 添加环境变量
7. 启动 YARN 相关服务
8. 启动 YARN
9. 启动 MapReduce 任务历史服务
五、Hadoop HA 测试验证
1. HDFS NameNode HA 验证
(1)查看 NameNode 节点状态,任一节点执行
(2)故障模拟
(3)查看节点状态,任一节点执行
(4)故障恢复
(5)查看节点状态,任一节点执行
(6)再次测试自动切换
2. YARN ResourceManager HA 验证
(1)查看 ResourceManager 节点状态,任一节点执行
(2)故障模拟
(3)查看节点状态,任一节点执行
(4)故障恢复
(5)查看节点状态,任一节点执行
(6)再次测试自动切换
参考:
一、主机规划
使用以下四台虚拟机搭建测试环境,保证网络连通,禁用防火墙。
- IP/主机名:
172.18.4.126 node1
172.18.4.188 node2
172.18.4.71 node3
172.18.4.86 node4
- 资源配置:
CPU:4核超线程;内存:8GB;Swap:4GB;硬盘:200GB。
- 操作系统:
CentOS Linux release 7.9.2009 (Core)
- 所需安装包:
jdk-8u202
Zookeeper-3.9.1
Hadoop-3.3.6
下表描述了四个节点上分别将会运行的相关进程。简便起见,安装部署过程中所用的命令都使用操作系统的 root 用户执行。
| 节点 进程 | node1 | node2 | node3 | node4 |
| Zookeeper | * | * | * | |
| NameNode | * | * | ||
| DataNode | * | * | * | |
| ZKFC | * | * | ||
| JournalNode | * | * | * | |
| ResourceManager | * | * | ||
| NodeManager | * | * | * | |
| JobHistoryServer | * |
二、环境准备
在全部四台机器执行以下步骤。
1. 启动 NTP 时钟同步
略。可参考 Greenplum 6 安装配置详解_greenplum6安装-CSDN博客
2. 修改 hosts 文件
# 编辑 /etc/hosts 文件
vim /etc/hosts# 添加主机名
172.18.4.126 node1
172.18.4.188 node2
172.18.4.71 node3
172.18.4.86 node43. 配置所有主机间 ssh 免密
# 生成秘钥
ssh-keygen# 复制公钥
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
ssh-copy-id node4
# 验证ssh node1 date
ssh node2 date
ssh node3 date
ssh node4 date4. 修改用户可打开文件数与进程数(可选)
# 查看
ulimit -a# 设置,编辑 /etc/security/limits.conf 文件
vim /etc/security/limits.conf# 添加下面两行
* soft nofile 512000
* hard nofile 512000三、安装 JDK
分别在 node1 - node4 四台上机器执行:
# 安装
rpm -ivh jdk-8u202-linux-x64.rpm
# 确认版本
java -version输出:
[root@vvml-yz-hbase-test~]#java -version
java version "1.8.0_202"
Java(TM) SE Runtime Environment (build 1.8.0_202-b08)
Java HotSpot(TM) 64-Bit Server VM (build 25.202-b08, mixed mode)
[root@vvml-yz-hbase-test~]#四、安装部署 Zookeeper 集群
分别在 node1 - node3 三台机器执行以下步骤。
1. 解压、配置环境变量
# 解压
tar -zxvf apache-zookeeper-3.9.1-bin.tar.gz# 编辑 /etc/profile 文件
vim /etc/profile# 添加下面两行
export ZOOKEEPER_HOME=/root/apache-zookeeper-3.9.1-bin/
export PATH=$ZOOKEEPER_HOME/bin:$PATH# 加载生效
source /etc/profile2. 创建配置文件
# 备份
cp $ZOOKEEPER_HOME/conf/zoo_sample.cfg $ZOOKEEPER_HOME/conf/zoo.cfgvim $ZOOKEEPER_HOME/conf/zoo.cfg# 编辑 zoo.cfg 文件内容如下:# ZooKeeper 使用的毫秒为单位的时间单元,用于进行心跳,最小会话超时将是 tickTime 的两倍。
tickTime=2000
# 存储内存中数据库快照的位置。
dataDir=/var/lib/zookeeper/data
# 数据库更新的事务日志所在目录。
dataLogDir=/var/lib/zookeeper/log
# 监听客户端连接的端口。
clientPort=2181
# LF 初始通信时限,即集群中的 follower 服务器(F)与 leader 服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。
initLimit=5
# LF 同步通信时限,即集群中的 follower 服务器(F)与 leader 服务器(L)之间请求和应答之间能容忍的最多心跳数(tickTime的数量)。
syncLimit=2
# 集群配置 server.服务器ID=服务器IP地址:服务器之间通信端口:服务器之间投票选举端口。当服务器启动时,通过在数据目录中查找文件 myid 来知道它是哪台服务器。
server.1=172.18.4.126:2888:3888
server.2=172.18.4.188:2888:3888
server.3=172.18.4.71:2888:3888
# 指定自动清理事务日志和快照文件的频率,单位是小时。
autopurge.purgeInterval=13. 创建新的空 ZooKeeper 数据目录和事务日志目录
mkdir -p /var/lib/zookeeper/data
mkdir -p /var/lib/zookeeper/log4. 添加 myid 配置
# node1 上
echo 1 > /var/lib/zookeeper/data/myid
# node2 上
echo 2 > /var/lib/zookeeper/data/myid
# node3 上
echo 3 > /var/lib/zookeeper/data/myid5. 设置 Zookeeper 使用的 JVM 堆内存
vim $ZOOKEEPER_HOME/bin/zkEnv.sh# 修改 zkEnv.sh 文件中的ZK_SERVER_HEAP值,缺省为1000,单位是MB,修改为2048。# default heap for zookeeper server
ZK_SERVER_HEAP="${ZK_SERVER_HEAP:-2048}"6. 启动 ZooKeeper
zkServer.sh start日志记录在安装目录下的 logs 目录中,如本例中的 /root/apache-zookeeper-3.9.1-bin/logs。用 jps 可以看到 QuorumPeerMain 进程:
[root@vvml-yz-hbase-test~]#jps
5316 QuorumPeerMain
5373 Jps
[root@vvml-yz-hbase-test~]#7. 查看 ZooKeeper 状态
zkServer.sh statusnode1 输出:
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /root/apache-zookeeper-3.9.1-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: followernode2 输出:
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /root/apache-zookeeper-3.9.1-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leadernode3 输出:
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /root/apache-zookeeper-3.9.1-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: followernode2 为 leader,node1、node3 为 follower。
8. 简单测试 ZooKeeper 命令
# 连接ZooKeeper
zkCli.sh -server node1:2181# 控制台输出
/usr/bin/java
Connecting to node1:2181
...
Welcome to ZooKeeper!
...
JLine support is enabled
...
[zk: node1:2181(CONNECTED) 0] help
ZooKeeper -server host:port -client-configuration properties-file cmd args
...
Command not found: Command not found help
[zk: node1:2181(CONNECTED) 1] ls /
[zookeeper]
[zk: node1:2181(CONNECTED) 2] create /zk_test my_data
Created /zk_test
[zk: node1:2181(CONNECTED) 3] ls /
[zk_test, zookeeper]
[zk: node1:2181(CONNECTED) 4] get /zk_test
my_data
[zk: node1:2181(CONNECTED) 5] set /zk_test junk
[zk: node1:2181(CONNECTED) 6] get /zk_test
junk
[zk: node1:2181(CONNECTED) 7] delete /zk_test
[zk: node1:2181(CONNECTED) 8] ls /
[zookeeper]
[zk: node1:2181(CONNECTED) 9] quitWATCHER::WatchedEvent state:Closed type:None path:null zxid: -1
2024-03-05 10:18:32,189 [myid:] - INFO [main:o.a.z.ZooKeeper@1232] - Session: 0x100421ce5c90000 closed
2024-03-05 10:18:32,190 [myid:] - INFO [main-EventThread:o.a.z.ClientCnxn$EventThread@553] - EventThread shut down for session: 0x100421ce5c90000
2024-03-05 10:18:32,193 [myid:] - INFO [main:o.a.z.u.ServiceUtils@45] - Exiting JVM with code 0
[root@vvml-yz-hbase-test~]#五、安装配置 Hadoop HA 集群
1. 解压、配置环境变量(node1 执行)
# 解压
tar -zvxf hadoop-3.3.6.tar.gz# 编辑 /etc/profile 文件
vim /etc/profile# 添加如下两行
export HADOOP_HOME=/root/hadoop-3.3.6/
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH# 加载生效
source /etc/profile# 编辑 $HADOOP_HOME/etc/hadoop/hadoop-env.sh 文件设置 Hadoop 运行环境
vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh# 在文件末尾添加
export JAVA_HOME=/usr/java/jdk1.8.0_202-amd64
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HADOOP_PID_DIR=/root/hadoop-3.3.62. HDFS 高可用配置
(1)创建存储目录
mkdir -p $HADOOP_HOME/data/namenode
mkdir -p $HADOOP_HOME/data/journalnode(2)修改核心模块配置
# 编辑 $HADOOP_HOME/etc/hadoop/core-site.xml 文件
vim $HADOOP_HOME/etc/hadoop/core-site.xml# 配置如下
<configuration><!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 --><property><name>fs.defaultFS</name><value>hdfs://mycluster</value><final>true</final></property><property><name>io.file.buffer.szie</name><value>131072</value></property><!-- 设置Hadoop本地保存数据路径 --><property><name>hadoop.tmp.dir</name><value>/root/hadoop-3.3.6/data/namenode</value></property><!-- 指定zookeeper地址 --><property><name>ha.zookeeper.quorum</name><value>node1:2181,node2:2181,node3:2181</value></property><!-- 设置HDFS web UI用户身份 --><property><name>hadoop.http.staticuser.user</name><value>root</value></property><!-- 配置该root允许通过代理访问的主机节点 --><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><!-- 配置该root允许代理的用户所属组 --><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property><!-- 配置该root允许代理的用户 --><property><name>hadoop.proxyuser.root.users</name><value>*</value></property><!-- 对于每个<root>用户,hosts必须进行配置,而groups和users至少需要配置一个。--><!-- 文件系统垃圾桶保存时间 --><property><name>fs.trash.interval</name><value>1440</value></property></configuration>(3)修改 hdfs 文件系统模块配置
# 编辑 $HADOOP_HOME/etc/hadoop/hdfs-site.xml 文件
vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml# 配置如下
<configuration><!-- 为namenode集群定义一个services name,默认值:null --><property><name>dfs.nameservices</name><value>mycluster</value></property><!-- 说明:nameservice 包含哪些namenode,为各个namenode起名,默认值:null,比如这里设置的nn1, nn2 --><property><name>dfs.ha.namenodes.mycluster</name><value>nn1,nn2</value></property><!-- 说明:名为nn1的namenode 的rpc地址和端口号,rpc用来和datanode通讯,默认值:9000,local-168-182-110为节点hostname--><property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>node1:8082</value></property><!-- 说明:名为nn2的namenode 的rpc地址和端口号,rpc用来和datanode通讯,默认值:9000,local-168-182-113为节点hostname--><property><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>node4:8082</value></property><!-- 说明:名为nn1的namenode 的http地址和端口号,web客户端 --><property><name>dfs.namenode.http-address.mycluster.nn1</name><value>node1:9870</value></property><!-- 说明:名为nn2的namenode 的http地址和端口号,web客户端 --><property><name>dfs.namenode.http-address.mycluster.nn2</name><value>node4:9870</value></property><!-- 说明:namenode间用于共享编辑日志的journal节点列表 --><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://node1:8485;node2:8485;node3:8485/mycluster</value></property><!-- 说明:客户端连接可用状态的NameNode所用的代理类,默认值:org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider --><property><name>dfs.client.failover.proxy.provider.mycluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><!-- 说明:HDFS的HA功能的防脑裂方法。可以是内建的方法(例如shell和sshfence)或者用户定义的方法。建议使用sshfence(hadoop:9922),括号内的是用户名和端口,注意,这需要NN的2台机器之间能够免密码登陆
fences是防止脑裂的方法,保证NN中仅一个是Active的,如果2者都是Active的,新的会把旧的强制Kill--><property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><!-- 指定上述选项ssh通讯使用的密钥文件在系统中的位置 --><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value></property><!-- 说明:失效转移时使用的秘钥文件。 --><property><name>dfs.journalnode.edits.dir</name><value>/root/hadoop-3.3.6/data/journalnode</value></property><!-- 开启NameNode失败自动切换 --><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><!-- 配置失败自动切换实现方式 --><property><name>dfs.client.failover.proxy.provider.mycluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><!-- 设置数据块应该被复制的份数,也就是副本数,默认:3 --><property><name>dfs.replication</name><value>3</value></property><!-- 说明:是否开启权限检查 --><property><name>dfs.permissions.enabled</name><value>false</value></property><!-- 配合 HBase 或其他 dfs 客户端使用,表示开启短路径读,可以用来优化客户端性能 --><property><name>dfs.client.read.shortcircuit</name><value>true</value></property><property><name>dfs.domain.socket.path</name><value>/root/hadoop-3.3.6/dn_socket</value></property></configuration>(4)修改 $HADOOP_HOME/etc/hadoop/workers
将下面内容覆盖文件,默认只有 localhost,works 配置 DataNode 节点的主机名或IP,如果配置了 works 文件,并且配置 ssh 免密登录,可以使用 start-dfs.sh 启动 HDFS 集群。
# 编辑 $HADOOP_HOME/etc/hadoop/workers 文件
vim $HADOOP_HOME/etc/hadoop/workers# 内容如下
node2
node3
node43. YARN ResourceManager 高可用配置
(1)修改 yarn 模块配置
# 编辑 $HADOOP_HOME/etc/hadoop/yarn-site.xml 文件
vim $HADOOP_HOME/etc/hadoop/yarn-site.xml# 内容如下
<configuration><!--开启ResourceManager HA功能--><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><!--标志ResourceManager--><property><name>yarn.resourcemanager.cluster-id</name><value>myyarn</value></property><!--集群中ResourceManager的ID列表,后面的配置将引用该ID--><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><!-- 设置YARN集群主角色运行节点rm1--><property><name>yarn.resourcemanager.hostname.rm1</name><value>node1</value></property><!-- 设置YARN集群主角色运行节点rm2--><property><name>yarn.resourcemanager.hostname.rm2</name><value>node4</value></property><!--ResourceManager1的Web页面访问地址--><property><name>yarn.resourcemanager.webapp.address.rm1</name><value>node1:8088</value></property><!--ResourceManager2的Web页面访问地址--><property><name>yarn.resourcemanager.webapp.address.rm2</name><value>node4:8088</value></property><!--ZooKeeper集群列表--><property><name>hadoop.zk.address</name><value>node1:2181,node2:2181,node3:2181</value></property><!--启用ResouerceManager重启的功能,默认为false--><property><name>yarn.resourcemanager.recovery.enabled</name><value>true</value></property><!--用于ResouerceManager状态存储的类--><property><name>yarn.resourcemanager.store.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 是否将对容器实施物理内存限制 --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><!-- 是否将对容器实施虚拟内存限制 --><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property><!-- 开启日志聚集 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!-- 设置yarn历史服务器地址 --><property><name>yarn.log.server.url</name><value>http://node1:19888/jobhistory/logs</value></property><!-- 设置yarn历史日志保存时间 7天 --><property><name>yarn.log-aggregation.retain-seconds</name><value>604880</value></property></configuration>(2)修改 MapReduce 模块配置
# 编辑 $HADOOP_HOME/etc/hadoop/mapred-site.xml 文件
vim $HADOOP_HOME/etc/hadoop/mapred-site.xml# 内容如下
<configuration><!-- 设置MR程序默认运行模式,yarn集群模式,local本地模式 --><property><name>mapreduce.framework.name</name><value>yarn</value></property><!-- MR程序历史服务地址 --><property><name>mapreduce.jobhistory.address</name><value>node1:10020</value></property><!-- MR程序历史服务web端地址 --><property><name>mapreduce.jobhistory.webapp.address</name><value>node1:19888</value></property><!-- yarn环境变量 --><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><!-- map环境变量 --><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><!-- reduce环境变量 --><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property></configuration>4. 分发配置文件其它节点
# 设置组和属主
chown -R root:root $HADOOP_HOME# Hadoop 主目录复制到另外三个节点
scp -r $HADOOP_HOME node2:$HADOOP_HOME
scp -r $HADOOP_HOME node3:$HADOOP_HOME
scp -r $HADOOP_HOME node4:$HADOOP_HOME5. 启动 HDFS 相关服务
# 启动journalnode,在 node1、node2、node3 机器上执行
hdfs --daemon start journalnode# HDFS NameNode 数据同步,格式化(第一次配置情况下使用,已运行集群不能用),在 node1 执行
hdfs namenode -format# 启动 node1 上的 NameNode 节点
hdfs --daemon start namenode# node4 节点上同步镜像数据
hdfs namenode -bootstrapStandby# node4 节点上启动 NameNode
hdfs --daemon start namenode# zookeeper FailerController 格式化,在 node1 上执行
hdfs zkfc -formatZK# 所有节点安装 psmisc。ZKFC 远程杀死假死 SNN 使用的 killall namenode 命令属于 psmisc 软件中。建议所有节点都安装 psmisc。
yum install -y psmisc6. 添加环境变量
# 编辑 ~/.bash_profile 文件,或者在 start-dfs.sh、stop-dfs.sh(hadoop 安装目录的 sbin 里)两个文件顶部添加这些环境变量
vim ~/.bash_profile# 内容如下
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HDFS_ZKFC_USER=root# 加载生效
source ~/.bash_profile7. 启动 YARN 相关服务
# 启动 hdfs,在 node1 节点上执行
start-dfs.sh# node1 进程
[root@vvml-yz-hbase-test~]#jps
11506 NameNode
9621 QuorumPeerMain
12373 Jps
12300 DFSZKFailoverController
11023 JournalNode
[root@vvml-yz-hbase-test~]## node2 进程
[root@vvml-yz-hbase-test~]#jps
16754 DataNode
16405 JournalNode
16909 Jps
15007 QuorumPeerMain
[root@vvml-yz-hbase-test~]## node3 进程
[root@vvml-yz-hbase-test~]#jps
7026 DataNode
5316 QuorumPeerMain
6699 JournalNode
7197 Jps
[root@vvml-yz-hbase-test~]## node4 进程
[root@vvml-yz-hbase-test~]#jps
8000 Jps
7731 DataNode
7814 DFSZKFailoverController
7528 NameNode
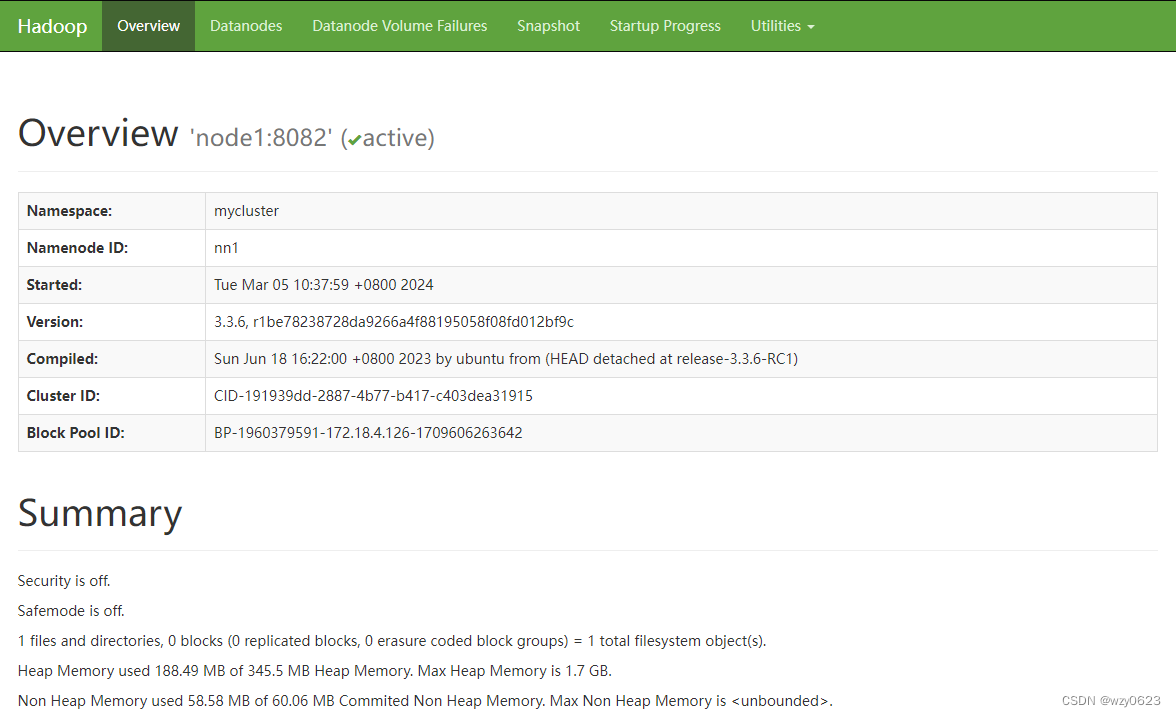
[root@vvml-yz-hbase-test~]# web地址:
http://node1:9870/
http://node4:9870/
如下图所示,node1 为 active,node4 为 standby。

8. 启动 YARN
# 在 node1 节点上执行
start-yarn.sh# node1 进程
[root@vvml-yz-hbase-test~]#jps
11506 NameNode
9621 QuorumPeerMain
13354 Jps
12300 DFSZKFailoverController
12990 ResourceManager
11023 JournalNode
[root@vvml-yz-hbase-test~]## node2 进程
[root@vvml-yz-hbase-test~]#jps
16754 DataNode
17219 NodeManager
16405 JournalNode
17350 Jps
15007 QuorumPeerMain
[root@vvml-yz-hbase-test~]## node3 进程
[root@vvml-yz-hbase-test~]#jps
7026 DataNode
5316 QuorumPeerMain
7626 Jps
6699 JournalNode
7483 NodeManager
[root@vvml-yz-hbase-test~]## node4 进程
[root@vvml-yz-hbase-test~]#jps
8256 ResourceManager
8352 NodeManager
7731 DataNode
7814 DFSZKFailoverController
7528 NameNode
8540 Jps
[root@vvml-yz-hbase-test~]# web地址:
http://node1:8088/cluster/cluster
http://node4:8088/cluster/cluster
如下图所示,node1 为 active,node4 为 standby。
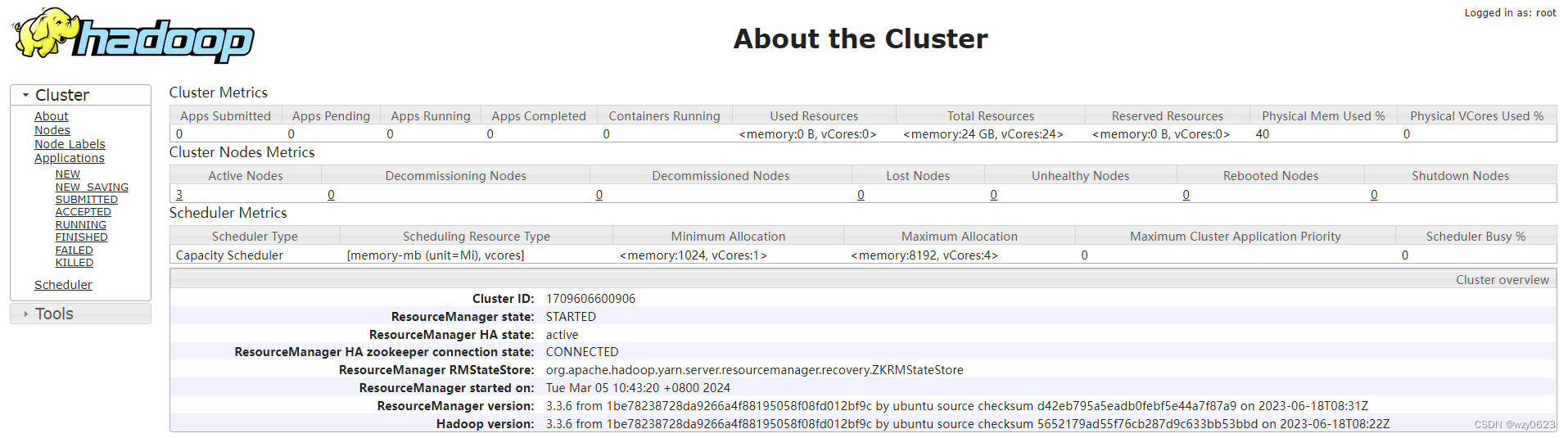
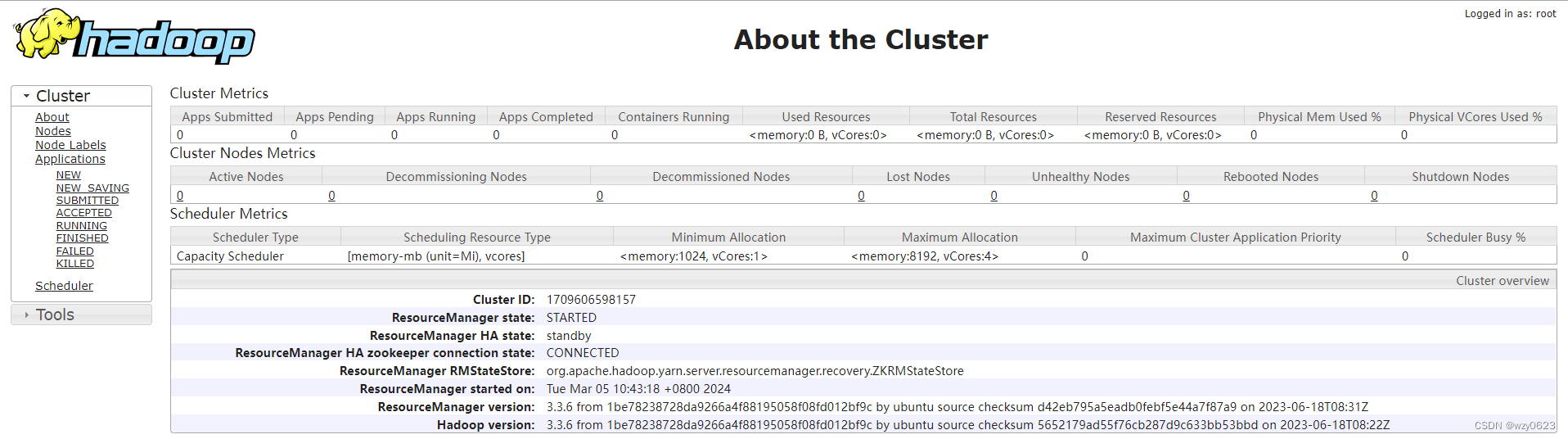
9. 启动 MapReduce 任务历史服务
# 在 node1 节点上执行
mapred --daemon start historyserver[root@vvml-yz-hbase-test~]#jps
11506 NameNode
9621 QuorumPeerMain
13704 Jps
12300 DFSZKFailoverController
13645 JobHistoryServer
12990 ResourceManager
11023 JournalNode
[root@vvml-yz-hbase-test~]#五、Hadoop HA 测试验证
1. HDFS NameNode HA 验证
(1)查看 NameNode 节点状态,任一节点执行
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2# 输出
[root@vvml-yz-hbase-test~]#hdfs haadmin -getServiceState nn1
active
[root@vvml-yz-hbase-test~]#hdfs haadmin -getServiceState nn2
standby
[root@vvml-yz-hbase-test~]#(2)故障模拟
# 在 active 的 NameNode 节点上(这里是 node1),kill 掉 NameNode 进程
jps
jps|grep NameNode|awk '{print $1}'|xargs kill -9
jps# 输出
[root@vvml-yz-hbase-test~]#jps
13904 Jps
11506 NameNode
9621 QuorumPeerMain
12300 DFSZKFailoverController
13645 JobHistoryServer
12990 ResourceManager
11023 JournalNode
[root@vvml-yz-hbase-test~]#jps|grep NameNode|awk '{print $1}'|xargs kill -9
[root@vvml-yz-hbase-test~]#jps
9621 QuorumPeerMain
12300 DFSZKFailoverController
13980 Jps
13645 JobHistoryServer
12990 ResourceManager
11023 JournalNode
[root@vvml-yz-hbase-test~]#(3)查看节点状态,任一节点执行
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
hdfs haadmin -getAllServiceState# 输出
[root@vvml-yz-hbase-test~]#hdfs haadmin -getServiceState nn1
2024-03-05 10:50:41,928 INFO ipc.Client: Retrying connect to server: node1/172.18.4.126:8082. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=1, sleepTime=1000 MILLISECONDS)
Operation failed: Call From node1/172.18.4.126 to node1:8082 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
[root@vvml-yz-hbase-test~]#hdfs haadmin -getServiceState nn2
active
[root@vvml-yz-hbase-test~]#hdfs haadmin -getAllServiceState
2024-03-05 10:50:44,276 INFO ipc.Client: Retrying connect to server: node1/172.18.4.126:8082. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=1, sleepTime=1000 MILLISECONDS)
node1:8082 Failed to connect: Call From node1/172.18.4.126 to node1:8082 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
node4:8082 active
[root@vvml-yz-hbase-test~]#node4 状态变为 active。
(4)故障恢复
# 启动 namenode(node1 执行)
hdfs --daemon start namenode
jps# 输出
[root@vvml-yz-hbase-test~]#hdfs --daemon start namenode
[root@vvml-yz-hbase-test~]#jps
14352 NameNode
9621 QuorumPeerMain
14407 Jps
12300 DFSZKFailoverController
13645 JobHistoryServer
12990 ResourceManager
11023 JournalNode
[root@vvml-yz-hbase-test~]#(5)查看节点状态,任一节点执行
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
hdfs haadmin -getAllServiceState# 输出
[root@vvml-yz-hbase-test~]#hdfs haadmin -getServiceState nn1
standby
[root@vvml-yz-hbase-test~]#hdfs haadmin -getServiceState nn2
active
[root@vvml-yz-hbase-test~]#hdfs haadmin -getAllServiceState
node1:8082 standby
node4:8082 active
[root@vvml-yz-hbase-test~]#node1 状态变为 standby。
(6)再次测试自动切换
# node4 执行
# 模拟故障
jps|grep NameNode|awk '{print $1}'|xargs kill -9
# 确认切换
hdfs haadmin -getAllServiceState
# 故障恢复
hdfs --daemon start namenode
# 角色交换
hdfs haadmin -getAllServiceState# 输出
[root@vvml-yz-hbase-test~]#jps|grep NameNode|awk '{print $1}'|xargs kill -9
[root@vvml-yz-hbase-test~]#hdfs haadmin -getAllServiceState
node1:8082 active
2024-03-05 10:56:35,128 INFO ipc.Client: Retrying connect to server: node4/172.18.4.86:8082. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=1, sleepTime=1000 MILLISECONDS)
node4:8082 Failed to connect: Call From node4/172.18.4.86 to node4:8082 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
[root@vvml-yz-hbase-test~]#hdfs --daemon start namenode
[root@vvml-yz-hbase-test~]#hdfs haadmin -getAllServiceState
node1:8082 active
node4:8082 standby
[root@vvml-yz-hbase-test~]#2. YARN ResourceManager HA 验证
(1)查看 ResourceManager 节点状态,任一节点执行
yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm2# 输出
[root@vvml-yz-hbase-test~]#yarn rmadmin -getServiceState rm1
active
[root@vvml-yz-hbase-test~]#yarn rmadmin -getServiceState rm2
standby
[root@vvml-yz-hbase-test~]#(2)故障模拟
# 在 active 的 ResourceManager 节点上(这里是 node1),kill 掉 ResourceManager 进程:
jps
jps|grep ResourceManager|awk '{print $1}'|xargs kill -9
jps# 输出
[root@vvml-yz-hbase-test~]#jps
14352 NameNode
15122 Jps
9621 QuorumPeerMain
12300 DFSZKFailoverController
13645 JobHistoryServer
12990 ResourceManager
11023 JournalNode
[root@vvml-yz-hbase-test~]#jps|grep ResourceManager|awk '{print $1}'|xargs kill -9
[root@vvml-yz-hbase-test~]#jps
14352 NameNode
9621 QuorumPeerMain
12300 DFSZKFailoverController
15164 Jps
13645 JobHistoryServer
11023 JournalNode
[root@vvml-yz-hbase-test~]#(3)查看节点状态,任一节点执行
yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm2
yarn rmadmin -getAllServiceState# 输出
[root@vvml-yz-hbase-test~]#yarn rmadmin -getServiceState rm1
2024-03-05 10:59:29,051 INFO ipc.Client: Retrying connect to server: node1/172.18.4.126:8033. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=1, sleepTime=1000 MILLISECONDS)
Operation failed: Call From node1/172.18.4.126 to node1:8033 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
[root@vvml-yz-hbase-test~]#yarn rmadmin -getServiceState rm2
active
[root@vvml-yz-hbase-test~]#yarn rmadmin -getAllServiceState
2024-03-05 10:59:31,328 INFO ipc.Client: Retrying connect to server: node1/172.18.4.126:8033. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=1, sleepTime=1000 MILLISECONDS)
node1:8033 Failed to connect: Call From node1/172.18.4.126 to node1:8033 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
node4:8033 active
[root@vvml-yz-hbase-test~]#node4 状态变为 active。
(4)故障恢复
# 启动 resourcemanager(node1执行)
yarn --daemon start resourcemanager
jps# 输出
[root@vvml-yz-hbase-test~]#yarn --daemon start resourcemanager
[root@vvml-yz-hbase-test~]#jps
14352 NameNode
15620 Jps
9621 QuorumPeerMain
15563 ResourceManager
12300 DFSZKFailoverController
13645 JobHistoryServer
11023 JournalNode
[root@vvml-yz-hbase-test~]#(5)查看节点状态,任一节点执行
yarn rmadmin -getAllServiceState# 输出
[root@vvml-yz-hbase-test~]#yarn rmadmin -getAllServiceState
node1:8033 standby
node4:8033 active
[root@vvml-yz-hbase-test~]#node1 状态变为 standby。
(6)再次测试自动切换
# node4 执行
# 模拟故障
jps|grep ResourceManager|awk '{print $1}'|xargs kill -9
# 确认切换
yarn rmadmin -getAllServiceState
# 故障恢复
yarn --daemon start resourcemanager
# 角色交换
yarn rmadmin -getAllServiceState# 输出
[root@vvml-yz-hbase-test~]#jps|grep ResourceManager|awk '{print $1}'|xargs kill -9
[root@vvml-yz-hbase-test~]#yarn rmadmin -getAllServiceState
node1:8033 active
2024-03-05 11:03:47,735 INFO ipc.Client: Retrying connect to server: node4/172.18.4.86:8033. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=1, sleepTime=1000 MILLISECONDS)
node4:8033 Failed to connect: Call From node4/172.18.4.86 to node4:8033 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
[root@vvml-yz-hbase-test~]#yarn --daemon start resourcemanager
[root@vvml-yz-hbase-test~]#yarn rmadmin -getAllServiceState
node1:8033 active
node4:8033 standby
[root@vvml-yz-hbase-test~]#在配置了 Automatic failover 后,可以使用 -forcemanual 参数执行手动切换主备:
# HDFS NameNode 切换,手动指定主备节点
hdfs haadmin -transitionToStandby --forcemanual nn1
hdfs haadmin -transitionToActive --forcemanual nn2# YARN ResourceManager 切换,手动指定主备节点
yarn rmadmin -transitionToStandby -forcemanual rm1
yarn rmadmin -transitionToActive -forcemanual rm2一定要谨慎使用 -forcemanual 参数,它可能引起问题,尤其是 YARN ResourceManager HA。在我的测试中,当手动指定 ResourceManager 主备节点切换后,停掉 active 节点,standby 不会变成 active,而是保持 standby 状态。再次启动停掉的节点,此时两个 ResourceManager 节点的状态都是 standby。只有重启 yarn 后才能再次正常执行自动失败切换。
参考:
- 大数据Hadoop之——Hadoop 3.3.4 HA(高可用)原理与实现(QJM)
- HDFS High Availability Using the Quorum Journal Manager
- ResourceManager High Availability