15 实战:Kaggle房价预测 + 课程竞赛:加州2020年房价预测【李沐动手学深度学习课程笔记】 https://zhuanlan.zhihu.com/p/685343754
https://zhuanlan.zhihu.com/p/685343754
写在前面:这里格式很乱,代码直接去知乎copy
1 实战Kaggle比赛:预测房价
1.1 实现几个函数来下载数据
import hashlib import os import tarfile import zipfile import requests #@save DATA_HUB = dict() DATA_URL = 'http://d2l-data.s3-accelerate.amazonaws.com/' def download(name, cache_dir=os.path.join('..', 'data')): #@save """下载一个DATA_HUB中的文件,返回本地文件名""" assert name in DATA_HUB, f"{name} 不存在于 {DATA_HUB}" url, sha1_hash = DATA_HUB[name] os.makedirs(cache_dir, exist_ok=True) fname = os.path.join(cache_dir, url.split('/')[-1]) if os.path.exists(fname): sha1 = hashlib.sha1() with open(fname, 'rb') as f: while True: data = f.read(1048576) if not data: break sha1.update(data) if sha1.hexdigest() == sha1_hash: return fname # 命中缓存 print(f'正在从{url}下载{fname}...') r = requests.get(url, stream=True, verify=True) with open(fname, 'wb') as f: f.write(r.content) return fname
1.2 使用pandas读入并处理数据
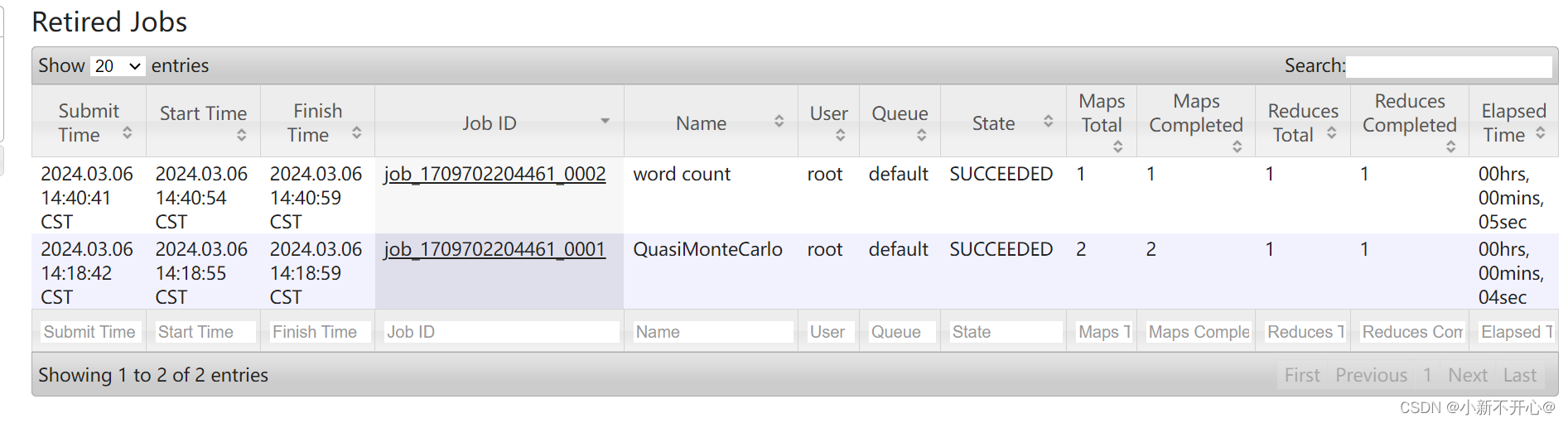
# 如果没有安装pandas,请取消下一行的注释 # !pip install pandas %matplotlib inline import numpy as np import pandas as pd import torch from torch import nn from d2l import torch as d2l DATA_HUB['kaggle_house_train'] = ( #@save DATA_URL + 'kaggle_house_pred_train.csv', '585e9cc93e70b39160e7921475f9bcd7d31219ce') DATA_HUB['kaggle_house_test'] = ( #@save DATA_URL + 'kaggle_house_pred_test.csv', 'fa19780a7b011d9b009e8bff8e99922a8ee2eb90') train_data = pd.read_csv(download('kaggle_house_train')) test_data = pd.read_csv(download('kaggle_house_test')) print(train_data.shape) print(test_data.shape) print(train_data.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]]) all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:]))
1.3 数据预处理
# 若无法获得测试数据,则可根据训练数据计算均值和标准差 numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index all_features[numeric_features] = all_features[numeric_features].apply( lambda x: (x - x.mean()) / (x.std())) # 在标准化数据之后,所有均值消失,因此我们可以将缺失值设置为0 all_features[numeric_features] = all_features[numeric_features].fillna(0) # “Dummy_na=True”将“na”(缺失值)视为有效的特征值,并为其创建指示符特征 all_features = pd.get_dummies(all_features, dummy_na=True) all_features.shape n_train = train_data.shape[0] train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float32) test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float32) train_labels = torch.tensor( train_data.SalePrice.values.reshape(-1, 1), dtype=torch.float32)
1.4 训练
首先,我们训练一个带有损失平方的线性模型。 显然线性模型很难让我们在竞赛中获胜,但线性模型提供了一种健全性检查, 以查看数据中是否存在有意义的信息。 如果我们在这里不能做得比随机猜测更好,那么我们很可能存在数据处理错误。 如果一切顺利,线性模型将作为基线(baseline)模型, 让我们直观地知道最好的模型有超出简单的模型多少。
loss = nn.MSELoss() in_features = train_features.shape[1] def get_net(): net = nn.Sequential(nn.Linear(in_features,1)) return net def log_rmse(net, features, labels): # 为了在取对数时进一步稳定该值,将小于1的值设置为1 clipped_preds = torch.clamp(net(features), 1, float('inf')) rmse = torch.sqrt(loss(torch.log(clipped_preds), torch.log(labels))) return rmse.item() def train(net, train_features, train_labels, test_features, test_labels, num_epochs, learning_rate, weight_decay, batch_size): train_ls, test_ls = [], [] train_iter = d2l.load_array((train_features, train_labels), batch_size) # 这里使用的是Adam优化算法 optimizer = torch.optim.Adam(net.parameters(), lr = learning_rate, weight_decay = weight_decay) for epoch in range(num_epochs): for X, y in train_iter: optimizer.zero_grad() l = loss(net(X), y) l.backward() optimizer.step() train_ls.append(log_rmse(net, train_features, train_labels)) if test_labels is not None: test_ls.append(log_rmse(net, test_features, test_labels)) return train_ls, test_ls
1.5 K折交叉验证
我们首先需要定义一个函数,在K折交叉验证过程中返回第i折的数据。 具体地说,它选择第i个切片作为验证数据,其余部分作为训练数据。 注意,这并不是处理数据的最有效方法,如果我们的数据集大得多,会有其他解决办法。
def get_k_fold_data(k, i, X, y): assert k > 1 fold_size = X.shape[0] // k X_train, y_train = None, None for j in range(k): idx = slice(j * fold_size, (j + 1) * fold_size) X_part, y_part = X[idx, :], y[idx] if j == i: X_valid, y_valid = X_part, y_part elif X_train is None: X_train, y_train = X_part, y_part else: X_train = torch.cat([X_train, X_part], 0) y_train = torch.cat([y_train, y_part], 0) return X_train, y_train, X_valid, y_valid def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay, batch_size): train_l_sum, valid_l_sum = 0, 0 for i in range(k): data = get_k_fold_data(k, i, X_train, y_train) net = get_net() train_ls, valid_ls = train(net, *data, num_epochs, learning_rate, weight_decay, batch_size) train_l_sum += train_ls[-1] valid_l_sum += valid_ls[-1] if i == 0: d2l.plot(list(range(1, num_epochs + 1)), [train_ls, valid_ls], xlabel='epoch', ylabel='rmse', xlim=[1, num_epochs], legend=['train', 'valid'], yscale='log') print(f'折{i + 1},训练log rmse{float(train_ls[-1]):f}, ' f'验证log rmse{float(valid_ls[-1]):f}') return train_l_sum / k, valid_l_sum / k
1.6 模型选择
k, num_epochs, lr, weight_decay, batch_size = 5, 100, 5, 0, 64 train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr, weight_decay, batch_size) print(f'{k}-折验证: 平均训练log rmse: {float(train_l):f}, ' f'平均验证log rmse: {float(valid_l):f}')
1.7 提交Kgaale预测
def train_and_pred(train_features, test_features, train_labels, test_data, num_epochs, lr, weight_decay, batch_size): net = get_net() train_ls, _ = train(net, train_features, train_labels, None, None, num_epochs, lr, weight_decay, batch_size) d2l.plot(np.arange(1, num_epochs + 1), [train_ls], xlabel='epoch', ylabel='log rmse', xlim=[1, num_epochs], yscale='log') print(f'训练log rmse:{float(train_ls[-1]):f}') # 将网络应用于测试集。 preds = net(test_features).detach().numpy() # 将其重新格式化以导出到Kaggle test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0]) submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1) submission.to_csv('submission.csv', index=False) train_and_pred(train_features, test_features, train_labels, test_data, num_epochs, lr, weight_decay, batch_size)
2. 小结