温馨提示:本文基于 Kafka 2.3.1 版本。
一、Kafka Producer 原理图
生产者的 API 使用还是比较简单,创建一个 ProducerRecord 对象(这个对象包含目标主题和要发送的内容,当然还可以指定键以及分区),然后调用 send 方法就把消息发送出去了。
talk is cheap,show me the code。先来看一段创建 Producer 的代码:
public class KafkaProducerDemo {public static void main(String[] args) {KafkaProducer<String,String> producer = createProducer();//指定topic,key,valueProducerRecord<String,String> record = new ProducerRecord<>("topic1","key1","value1");//异步发送producer.send(record);//同步发送//producer.send(record).get();producer.close();System.out.println("发送完成");}public static KafkaProducer<String,String> createProducer() {Properties props = new Properties();//bootstrap.servers 必须设置props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.239.131:9092");// key.serializer 必须设置props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// value.serializer 必须设置props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());//client.idprops.put(ProducerConfig.CLIENT_ID_CONFIG, "client-0");//retriesprops.put(ProducerConfig.RETRIES_CONFIG, 3);//acksprops.put(ProducerConfig.ACKS_CONFIG, "all");//max.in.flight.requests.per.connectionprops.put(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION, 1);//linger.msprops.put(ProducerConfig.LINGER_MS_CONFIG, 100);//batch.sizeprops.put(ProducerConfig.BATCH_SIZE_CONFIG, 10240);//buffer.memoryprops.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 10240);return new KafkaProducer<>(props);}
}在深入源码之前,先给出一张源码分析图,方便大家理解
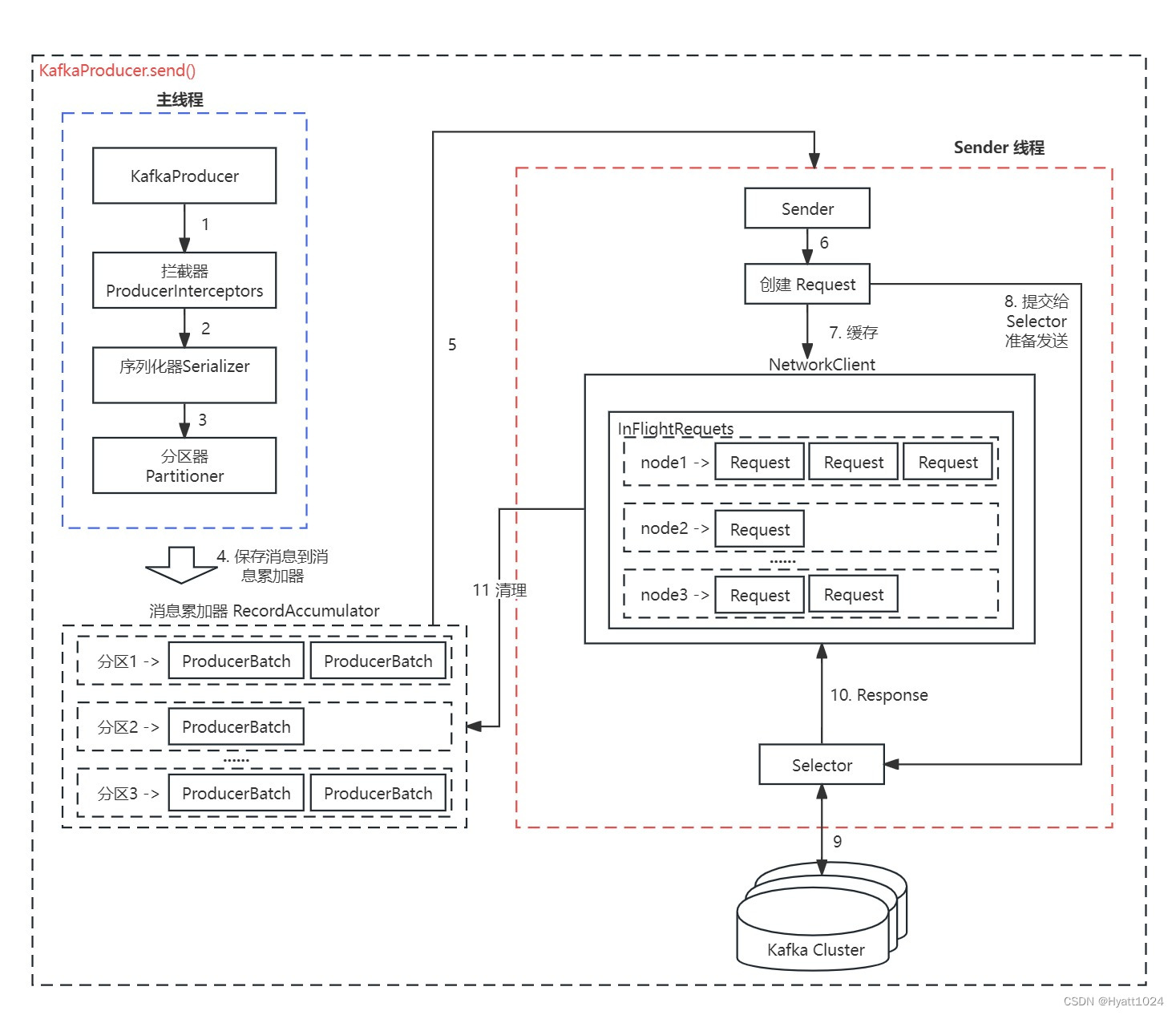
简要说明:
-
new KafkaProducer() 后创建一个后台线程 KafkaThread (实际运行线程是 Sender,KafkaThread 是对 Sender 的封装) ,扫描 RecordAccumulator 中是否有消息。
-
调用 KafkaProducer.send() 发送消息,在经过拦截器处理,key/value 序列化处理后,实际是将消息保存到 消息累加器 RecordAccumulator 中,实际上就是保存到一个 Map 中 (ConcurrentMap<TopicPartition, Deque<ProducerBatch>>),这条消息会被记录到同一个记录批次 (相同主题相同分区算同一个批次) 里面,这个批次的所有消息会被发送到相同的主题和分区上。
-
后台的独立线程 Sender 扫描到 消息累加器 RecordAccumulator 中有消息后,会将消息发送到 Kafka 集群中 (不是一有消息就发送,而是要看消息是否 ready)。其中 InFlightRequests 保存着已发送或正在发送但尚未收到响应的请求集。
-
如果发送成功 (消息成功写入 Kafka),就返回一个 RecordMetaData 对象,它包含了主题和分区信息,以及记录在分区里的偏移量。
-
如果写入失败,就会返回一个错误,生产者在收到错误之后会尝试重新发送消息 (如果允许的话,此时会将消息再保存到 RecordAccumulator 中),几次之后如果还是失败就返回错误消息。
二、源码分析
2.1 后台线程的创建
this.sender = newSender(logContext, kafkaClient, this.metadata);
String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();上面的代码就是创建 KafkaProducer 实例时的核心逻辑,它会在后台创建并启动一个名为 Sender 的异步线程,该 Sender 线程在开始运行时首先会创建与 Broker 的 TCP 连接。
KafkaProducer#newSender() 源码如下:
Sender newSender(LogContext logContext, KafkaClient kafkaClient, ProducerMetadata metadata) {int maxInflightRequests = configureInflightRequests(producerConfig, transactionManager != null);int requestTimeoutMs = producerConfig.getInt(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG);ChannelBuilder channelBuilder = ClientUtils.createChannelBuilder(producerConfig, time);ProducerMetrics metricsRegistry = new ProducerMetrics(this.metrics);Sensor throttleTimeSensor = Sender.throttleTimeSensor(metricsRegistry.senderMetrics);// 用于异步请求响应网络 io 的网络客户端。这是一个内部类,用于实现面向用户的生产者和消费者客户端。此类不是线程安全的!KafkaClient client = kafkaClient != null ? kafkaClient : new NetworkClient(// 一个 nioSelector 接口,用于执行非阻塞多连接网络 IO。new Selector(producerConfig.getLong(ProducerConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG),this.metrics, time, "producer", channelBuilder, logContext),metadata,clientId,maxInflightRequests,producerConfig.getLong(ProducerConfig.RECONNECT_BACKOFF_MS_CONFIG),producerConfig.getLong(ProducerConfig.RECONNECT_BACKOFF_MAX_MS_CONFIG),producerConfig.getInt(ProducerConfig.SEND_BUFFER_CONFIG),producerConfig.getInt(ProducerConfig.RECEIVE_BUFFER_CONFIG),requestTimeoutMs,ClientDnsLookup.forConfig(producerConfig.getString(ProducerConfig.CLIENT_DNS_LOOKUP_CONFIG)),time,true,apiVersions,throttleTimeSensor,logContext);int retries = configureRetries(producerConfig, transactionManager != null, log);short acks = configureAcks(producerConfig, transactionManager != null, log);return new Sender(logContext,client,metadata,this.accumulator,maxInflightRequests == 1,producerConfig.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG),acks,retries,metricsRegistry.senderMetrics,time,requestTimeoutMs,producerConfig.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG),this.transactionManager,apiVersions);
}new Selector() 核心源码如下:
public Selector(int maxReceiveSize,long connectionMaxIdleMs,int failedAuthenticationDelayMs,Metrics metrics,Time time,String metricGrpPrefix,Map<String, String> metricTags,boolean metricsPerConnection,boolean recordTimePerConnection,ChannelBuilder channelBuilder,MemoryPool memoryPool,LogContext logContext) {try {this.nioSelector = java.nio.channels.Selector.open();} catch (IOException e) {throw new KafkaException(e);}this.maxReceiveSize = maxReceiveSize;......
}Kafka 社区决定采用 TCP 而不是 HTTP 作为所有请求通行的底层协议的原因:在开发客户端时,人们能够利用 TCP 本身提供的一些高级功能,比如多路复用请求以及同时轮询多个连接的能力。
生产者何时创建与 Broker 的 TCP 连接?
- 在创建 KafkaProducer 实例时会建立连接
- 在更新元数据后
- 在消息发送时
生产者何时关闭与 Broker 的 TCP 连接?
- 用户主动关闭。即用户主动调用 producer.close() 方法。
- Kafka 自动关闭。TCP 连接是在 Broker 端被关闭的,在 connections.max.idle.ms 分钟(默认是 9 分钟)内没有任何请求,则 Kafka Brocker 会主动帮你关闭该 TCP 连接。
2.2 发送消息到消息累加器 RecordAccumulator
KafkaProducer<String,String> producer = createProducer();//指定topic,key,value
ProducerRecord<String,String> record = new ProducerRecord<>("topic1","key1","value1");//异步发送
producer.send(record);
//同步发送
//producer.send(record).get();发送消息有同步发送以及异步发送两种方式,我们一般不使用同步发送,毕竟太过于耗时,使用异步发送的时候可以指定回调函数,当消息发送完成的时候 (成功或者失败) 会通过回调通知生产者。
发送消息实际上是将消息缓存起来,KafkaProducer#doSend() 核心代码如下:
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {TopicPartition tp = null;try {throwIfProducerClosed();// first make sure the metadata for the topic is availableClusterAndWaitTime clusterAndWaitTime;try {clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs);} catch (KafkaException e) {if (metadata.isClosed())throw new KafkaException("Producer closed while send in progress", e);throw e;}long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);Cluster cluster = clusterAndWaitTime.cluster;byte[] serializedKey;try {serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());} catch (ClassCastException cce) {throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +" specified in key.serializer", cce);}byte[] serializedValue;try {serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());} catch (ClassCastException cce) {throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +" specified in value.serializer", cce);}int partition = partition(record, serializedKey, serializedValue, cluster);tp = new TopicPartition(record.topic(), partition);setReadOnly(record.headers());Header[] headers = record.headers().toArray();int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),compressionType, serializedKey, serializedValue, headers);ensureValidRecordSize(serializedSize);long timestamp = record.timestamp() == null ? time.milliseconds() : record.timestamp();log.trace("Sending record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);// producer callback will make sure to call both 'callback' and interceptor callbackCallback interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);if (transactionManager != null && transactionManager.isTransactional())transactionManager.maybeAddPartitionToTransaction(tp);// 将消息缓存到消息累加器中RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,serializedValue, headers, interceptCallback, remainingWaitMs);if (result.batchIsFull || result.newBatchCreated) {log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);this.sender.wakeup();}return result.future;// handling exceptions and record the errors;// for API exceptions return them in the future,// for other exceptions throw directly} catch (ApiException e) {log.debug("Exception occurred during message send:", e);if (callback != null)callback.onCompletion(null, e);this.errors.record();this.interceptors.onSendError(record, tp, e);return new FutureFailure(e);} catch (InterruptedException e) {this.errors.record();this.interceptors.onSendError(record, tp, e);throw new InterruptException(e);} catch (BufferExhaustedException e) {this.errors.record();this.metrics.sensor("buffer-exhausted-records").record();this.interceptors.onSendError(record, tp, e);throw e;} catch (KafkaException e) {this.errors.record();this.interceptors.onSendError(record, tp, e);throw e;} catch (Exception e) {// we notify interceptor about all exceptions, since onSend is called before anything else in this methodthis.interceptors.onSendError(record, tp, e);throw e;}
}doSend() 大致流程分为如下的几个步骤:
- 确认数据要发送到的 topic 的 metadata 是可用的(如果该 partition 的 leader 存在则是可用的,如果开启权限时,client 有相应的权限),如果没有 topic 的 metadata 信息,就需要获取相应的 metadata;
- 序列化 record 的 key 和 value;
- 获取该 record 要发送到的 partition(key指定,也可以根据算法计算,参考2.4 分区算法章节);
- 校验消息的大小是否超过最大值(默认是 1M);
- 给每一个消息都绑定回调函数;
- 向 accumulator 中追加 record 数据,数据会先进行缓存(默认 32M);
- 如果追加完数据后,对应的 RecordBatch 已经达到了 batch.size 的大小(或者 batch 的剩余空间不足以添加下一条 Record),则唤醒 sender 线程发送数据。
RecordAccumulator 的核心数据结构是 ConcurrentMap<TopicPartition, Deque<ProducerBatch>>,会将相同主题相同 Partition 的数据放到一个 Deque (双向队列) 中,这也是我们之前提到的同一个记录批次里面的消息会发送到同一个主题和分区的意思。RecordAccumulator#append() 方法的核心源码如下:
/*** Add a record to the accumulator, return the append result* <p>* The append result will contain the future metadata, and flag for whether the appended batch is full or a new batch is created* <p>** @param tp The topic/partition to which this record is being sent* @param timestamp The timestamp of the record* @param key The key for the record* @param value The value for the record* @param headers the Headers for the record* @param callback The user-supplied callback to execute when the request is complete* @param maxTimeToBlock The maximum time in milliseconds to block for buffer memory to be available*/
public RecordAppendResult append(TopicPartition tp,long timestamp,byte[] key,byte[] value,Header[] headers,Callback callback,long maxTimeToBlock) throws InterruptedException {// We keep track of the number of appending thread to make sure we do not miss batches in// abortIncompleteBatches().appendsInProgress.incrementAndGet();ByteBuffer buffer = null;if (headers == null) headers = Record.EMPTY_HEADERS;try {// check if we have an in-progress batch// 从ConcurrentMap<TopicPartition, Deque<ProducerBatch>> batches中根据主题分区获取对应的队列,如果没有则new ArrayDeque<>()返回Deque<ProducerBatch> dq = getOrCreateDeque(tp);synchronized (dq) {if (closed)throw new KafkaException("Producer closed while send in progress");RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);if (appendResult != null)return appendResult;}// we don't have an in-progress record batch try to allocate a new batchbyte maxUsableMagic = apiVersions.maxUsableProduceMagic();// 计算同一个记录批次占用空间大小,batchSize根据batch.size参数决定int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));log.trace("Allocating a new {} byte message buffer for topic {} partition {}", size, tp.topic(), tp.partition());// 为同一个topic,partition分配buffer,如果同一个记录批次的内存不足,那么会阻塞maxTimeToBlock(max.block.ms参数)这么长时间buffer = free.allocate(size, maxTimeToBlock);synchronized (dq) {// Need to check if producer is closed again after grabbing the dequeue lock.if (closed)throw new KafkaException("Producer closed while send in progress");RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);if (appendResult != null) {// Somebody else found us a batch, return the one we waited for! Hopefully this doesn't happen often...return appendResult;}// 创建MemoryRecordBuilder,通过buffer初始化appendStream(DataOutputStream)属性MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic);ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, time.milliseconds());// 将key,value写入到MemoryRecordsBuilder中的appendStream(DataOutputStream)中FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, headers, callback, time.milliseconds()));// 将需要发送的消息放入到队列中dq.addLast(batch);incomplete.add(batch);// Don't deallocate this buffer in the finally block as it's being used in the record batchbuffer = null;return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true);}} finally {if (buffer != null)free.deallocate(buffer);appendsInProgress.decrementAndGet();}
}2.3 发送消息到 Kafka Broker
上面已经将消息存储 RecordAccumulator 中去了,现在看看怎么发送消息。上面我们提到了创建 KafkaProducer 的时候会启动一个异步线程去从 RecordAccumulator 中取得消息然后发送到 Kafka,发送消息的核心代码是 Sender,它实现了 Runnable 接口并在后台一直运行处理发送请求并将消息发送到合适的节点,直到 KafkaProducer 被关闭。
/*** The background thread that handles the sending of produce requests to the Kafka cluster. This thread makes metadata* requests to renew its view of the cluster and then sends produce requests to the appropriate nodes.*/
public class Sender implements Runnable {/*** The main run loop for the sender thread*/public void run() {log.debug("Starting Kafka producer I/O thread.");// 一直运行直到kafkaProducer.close()方法被调用// main loop, runs until close is calledwhile (running) {try {runOnce();} catch (Exception e) {log.error("Uncaught error in kafka producer I/O thread: ", e);}}log.debug("Beginning shutdown of Kafka producer I/O thread, sending remaining records.");// 好的,我们停止接受请求,但事务管理器、累加器中可能仍有请求或等待确认,等到这些请求完成。// okay we stopped accepting requests but there may still be// requests in the transaction manager, accumulator or waiting for acknowledgment,// wait until these are completed.while (!forceClose && ((this.accumulator.hasUndrained() || this.client.inFlightRequestCount() > 0) || hasPendingTransactionalRequests())) {try {runOnce();} catch (Exception e) {log.error("Uncaught error in kafka producer I/O thread: ", e);}}// 如果任何提交或中止未通过事务管理器的队列,则中止事务// Abort the transaction if any commit or abort didn't go through the transaction manager's queuewhile (!forceClose && transactionManager != null && transactionManager.hasOngoingTransaction()) {if (!transactionManager.isCompleting()) {log.info("Aborting incomplete transaction due to shutdown");transactionManager.beginAbort();}try {runOnce();} catch (Exception e) {log.error("Uncaught error in kafka producer I/O thread: ", e);}}if (forceClose) {// We need to fail all the incomplete transactional requests and batches and wake up the threads waiting on// the futures.if (transactionManager != null) {log.debug("Aborting incomplete transactional requests due to forced shutdown");transactionManager.close();}log.debug("Aborting incomplete batches due to forced shutdown");// 如果是强制关闭,且还有未发送完毕的消息,则取消发送并抛出一个异常new KafkaException("Producer is closed forcefully.")this.accumulator.abortIncompleteBatches();}try {this.client.close();} catch (Exception e) {log.error("Failed to close network client", e);}log.debug("Shutdown of Kafka producer I/O thread has completed.");}}KafkaProducer 的关闭方法有 2 个,close() 以及 close(long timeout,TimeUnit timUnit),其中 timeout 参数的意思是等待生产者完成任何待处理请求的最长时间,第一种方式的 timeout 为 Long.MAX_VALUE 毫秒,如果采用第二种方式关闭,当 timeout=0 的时候则表示强制关闭,直接关闭 Sender (设置 running=false)。
接下来,我们看下 Sender#runOnce() 方法的源码实现,先跳过对 transactionManager 的处理,源码核心如下:
void runOnce() {if (transactionManager != null) {......}long currentTimeMs = time.milliseconds();//将记录批次转移到每个节点的生产请求列表中long pollTimeout = sendProducerData(currentTimeMs);//轮询进行消息发送client.poll(pollTimeout, currentTimeMs);
}首先查看 sendProducerData() 方法:
private long sendProducerData(long now) {Cluster cluster = metadata.fetch();// get the list of partitions with data ready to sendRecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);// if there are any partitions whose leaders are not known yet, force metadata updateif (!result.unknownLeaderTopics.isEmpty()) {// The set of topics with unknown leader contains topics with leader election pending as well as// topics which may have expired. Add the topic again to metadata to ensure it is included// and request metadata update, since there are messages to send to the topic.for (String topic : result.unknownLeaderTopics)this.metadata.add(topic);log.debug("Requesting metadata update due to unknown leader topics from the batched records: {}",result.unknownLeaderTopics);this.metadata.requestUpdate();}// remove any nodes we aren't ready to send toIterator<Node> iter = result.readyNodes.iterator();long notReadyTimeout = Long.MAX_VALUE;while (iter.hasNext()) {Node node = iter.next();if (!this.client.ready(node, now)) {iter.remove();notReadyTimeout = Math.min(notReadyTimeout, this.client.pollDelayMs(node, now));}}// create produce requestsMap<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes, this.maxRequestSize, now);addToInflightBatches(batches);if (guaranteeMessageOrder) {// Mute all the partitions drainedfor (List<ProducerBatch> batchList : batches.values()) {for (ProducerBatch batch : batchList)this.accumulator.mutePartition(batch.topicPartition);}}accumulator.resetNextBatchExpiryTime();List<ProducerBatch> expiredInflightBatches = getExpiredInflightBatches(now);List<ProducerBatch> expiredBatches = this.accumulator.expiredBatches(now);expiredBatches.addAll(expiredInflightBatches);// Reset the producer id if an expired batch has previously been sent to the broker. Also update the metrics// for expired batches. see the documentation of @TransactionState.resetProducerId to understand why// we need to reset the producer id here.if (!expiredBatches.isEmpty())log.trace("Expired {} batches in accumulator", expiredBatches.size());for (ProducerBatch expiredBatch : expiredBatches) {String errorMessage = "Expiring " + expiredBatch.recordCount + " record(s) for " + expiredBatch.topicPartition+ ":" + (now - expiredBatch.createdMs) + " ms has passed since batch creation";failBatch(expiredBatch, -1, NO_TIMESTAMP, new TimeoutException(errorMessage), false);if (transactionManager != null && expiredBatch.inRetry()) {// This ensures that no new batches are drained until the current in flight batches are fully resolved.transactionManager.markSequenceUnresolved(expiredBatch.topicPartition);}}sensors.updateProduceRequestMetrics(batches);// If we have any nodes that are ready to send + have sendable data, poll with 0 timeout so this can immediately// loop and try sending more data. Otherwise, the timeout will be the smaller value between next batch expiry// time, and the delay time for checking data availability. Note that the nodes may have data that isn't yet// sendable due to lingering, backing off, etc. This specifically does not include nodes with sendable data// that aren't ready to send since they would cause busy looping.long pollTimeout = Math.min(result.nextReadyCheckDelayMs, notReadyTimeout);pollTimeout = Math.min(pollTimeout, this.accumulator.nextExpiryTimeMs() - now);pollTimeout = Math.max(pollTimeout, 0);if (!result.readyNodes.isEmpty()) {log.trace("Nodes with data ready to send: {}", result.readyNodes);// if some partitions are already ready to be sent, the select time would be 0;// otherwise if some partition already has some data accumulated but not ready yet,// the select time will be the time difference between now and its linger expiry time;// otherwise the select time will be the time difference between now and the metadata expiry time;pollTimeout = 0;}sendProduceRequests(batches, now);return pollTimeout;
}它的核心逻辑在 sendProduceRequest() 方法
private void sendProduceRequests(Map<Integer, List<ProducerBatch>> collated, long now) {for (Map.Entry<Integer, List<ProducerBatch>> entry : collated.entrySet())sendProduceRequest(now, entry.getKey(), acks, requestTimeoutMs, entry.getValue());
}private void sendProduceRequest(long now, int destination, short acks, int timeout, List<ProducerBatch> batches) {if (batches.isEmpty())return;Map<TopicPartition, MemoryRecords> produceRecordsByPartition = new HashMap<>(batches.size());final Map<TopicPartition, ProducerBatch> recordsByPartition = new HashMap<>(batches.size());// find the minimum magic version used when creating the record setsbyte minUsedMagic = apiVersions.maxUsableProduceMagic();for (ProducerBatch batch : batches) {if (batch.magic() < minUsedMagic)minUsedMagic = batch.magic();}for (ProducerBatch batch : batches) {TopicPartition tp = batch.topicPartition;// 将ProducerBatch中MemoryRecordsBuilder转换为MemoryRecords(发送的数据就在这里面)MemoryRecords records = batch.records();// down convert if necessary to the minimum magic used. In general, there can be a delay between the time// that the producer starts building the batch and the time that we send the request, and we may have// chosen the message format based on out-dated metadata. In the worst case, we optimistically chose to use// the new message format, but found that the broker didn't support it, so we need to down-convert on the// client before sending. This is intended to handle edge cases around cluster upgrades where brokers may// not all support the same message format version. For example, if a partition migrates from a broker// which is supporting the new magic version to one which doesn't, then we will need to convert.if (!records.hasMatchingMagic(minUsedMagic))records = batch.records().downConvert(minUsedMagic, 0, time).records();produceRecordsByPartition.put(tp, records);recordsByPartition.put(tp, batch);}String transactionalId = null;if (transactionManager != null && transactionManager.isTransactional()) {transactionalId = transactionManager.transactionalId();}ProduceRequest.Builder requestBuilder = ProduceRequest.Builder.forMagic(minUsedMagic, acks, timeout,produceRecordsByPartition, transactionalId);// 消息发送完成时的回调RequestCompletionHandler callback = new RequestCompletionHandler() {public void onComplete(ClientResponse response) {// 处理响应消息handleProduceResponse(response, recordsByPartition, time.milliseconds());}};String nodeId = Integer.toString(destination);// 根据参数构造ClientRequest,此时需要发送的消息在requestBuilder中ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0,requestTimeoutMs, callback);// 将clientRequest转换成Send对象(Send.java,包含了需要发送数据的buffer),给KafkaChannel设置该对象// 记住这里还没有发送数据client.send(clientRequest, now);log.trace("Sent produce request to {}: {}", nodeId, requestBuilder);
}上面的 client.send() 方法最终会定位到 NetworkClient.doSend() 方法,所有的请求 (无论是 producer 发送消息的请求还是获取 metadata 的请求) 都是通过该方法设置对应的 Send 对象。所支持的请求在 ApiKeys.java 中都有定义,这里面可以看到每个请求的 request 以及 response 对应的数据结构。
跟一下 NetworkClient.doSend() 的源码:
/*** 发送请求到队列中* Queue up the given request for sending. Requests can only be sent out to ready nodes.* @param request The request* @param now The current timestamp*/
@Override
public void send(ClientRequest request, long now) {doSend(request, false, now);
}private void doSend(ClientRequest clientRequest, boolean isInternalRequest, long now) {ensureActive();String nodeId = clientRequest.destination();if (!isInternalRequest) {// If this request came from outside the NetworkClient, validate// that we can send data. If the request is internal, we trust// that internal code has done this validation. Validation// will be slightly different for some internal requests (for// example, ApiVersionsRequests can be sent prior to being in// READY state.)if (!canSendRequest(nodeId, now))throw new IllegalStateException("Attempt to send a request to node " + nodeId + " which is not ready.");}AbstractRequest.Builder<?> builder = clientRequest.requestBuilder();try {NodeApiVersions versionInfo = apiVersions.get(nodeId);short version;// Note: if versionInfo is null, we have no server version information. This would be// the case when sending the initial ApiVersionRequest which fetches the version// information itself. It is also the case when discoverBrokerVersions is set to false.if (versionInfo == null) {version = builder.latestAllowedVersion();if (discoverBrokerVersions && log.isTraceEnabled())log.trace("No version information found when sending {} with correlation id {} to node {}. " +"Assuming version {}.", clientRequest.apiKey(), clientRequest.correlationId(), nodeId, version);} else {version = versionInfo.latestUsableVersion(clientRequest.apiKey(), builder.oldestAllowedVersion(),builder.latestAllowedVersion());}// The call to build may also throw UnsupportedVersionException, if there are essential// fields that cannot be represented in the chosen version.doSend(clientRequest, isInternalRequest, now, builder.build(version));} catch (UnsupportedVersionException unsupportedVersionException) {// If the version is not supported, skip sending the request over the wire.// Instead, simply add it to the local queue of aborted requests.log.debug("Version mismatch when attempting to send {} with correlation id {} to {}", builder,clientRequest.correlationId(), clientRequest.destination(), unsupportedVersionException);ClientResponse clientResponse = new ClientResponse(clientRequest.makeHeader(builder.latestAllowedVersion()),clientRequest.callback(), clientRequest.destination(), now, now,false, unsupportedVersionException, null, null);abortedSends.add(clientResponse);if (isInternalRequest && clientRequest.apiKey() == ApiKeys.METADATA)metadataUpdater.handleFatalException(unsupportedVersionException);}
}private void doSend(ClientRequest clientRequest, boolean isInternalRequest, long now, AbstractRequest request) {String destination = clientRequest.destination();RequestHeader header = clientRequest.makeHeader(request.version());if (log.isDebugEnabled()) {int latestClientVersion = clientRequest.apiKey().latestVersion();if (header.apiVersion() == latestClientVersion) {log.trace("Sending {} {} with correlation id {} to node {}", clientRequest.apiKey(), request,clientRequest.correlationId(), destination);} else {log.debug("Using older server API v{} to send {} {} with correlation id {} to node {}",header.apiVersion(), clientRequest.apiKey(), request, clientRequest.correlationId(), destination);}}// 构建 Send 对象Send send = request.toSend(destination, header);InFlightRequest inFlightRequest = new InFlightRequest(clientRequest,header,isInternalRequest,request,send,now);// 保存已发送或正在发送但尚未收到响应的请求this.inFlightRequests.add(inFlightRequest);// 将给定的请求放入队列,以便在后续的 poll(long) 方法调用中发送selector.send(send);
}再跟一下 Selector#send() 的源码:
/*** Queue the given request for sending in the subsequent {@link #poll(long)} calls* @param send The request to send*/
public void send(Send send) {String connectionId = send.destination();KafkaChannel channel = openOrClosingChannelOrFail(connectionId);if (closingChannels.containsKey(connectionId)) {// ensure notification via `disconnected`, leave channel in the state in which closing was triggeredthis.failedSends.add(connectionId);} else {try {channel.setSend(send);} catch (Exception e) {// update the state for consistency, the channel will be discarded after `close`channel.state(ChannelState.FAILED_SEND);// ensure notification via `disconnected` when `failedSends` are processed in the next pollthis.failedSends.add(connectionId);close(channel, CloseMode.DISCARD_NO_NOTIFY);if (!(e instanceof CancelledKeyException)) {log.error("Unexpected exception during send, closing connection {} and rethrowing exception {}",connectionId, e);throw e;}}}
}可以看到,到上面还只是设置了发送消息所需要准备的内容,真正发送消息的核心代码在 Selector#poll(long) 方法中,源码如下:
/*** Do whatever I/O can be done on each connection without blocking. This includes completing connections, completing* disconnections, initiating new sends, or making progress on in-progress sends or receives.** When this call is completed the user can check for completed sends, receives, connections or disconnects using* {@link #completedSends()}, {@link #completedReceives()}, {@link #connected()}, {@link #disconnected()}. These* lists will be cleared at the beginning of each `poll` call and repopulated by the call if there is* any completed I/O.** In the "Plaintext" setting, we are using socketChannel to read & write to the network. But for the "SSL" setting,* we encrypt the data before we use socketChannel to write data to the network, and decrypt before we return the responses.* This requires additional buffers to be maintained as we are reading from network, since the data on the wire is encrypted* we won't be able to read exact no.of bytes as kafka protocol requires. We read as many bytes as we can, up to SSLEngine's* application buffer size. This means we might be reading additional bytes than the requested size.* If there is no further data to read from socketChannel selector won't invoke that channel and we've have additional bytes* in the buffer. To overcome this issue we added "stagedReceives" map which contains per-channel deque. When we are* reading a channel we read as many responses as we can and store them into "stagedReceives" and pop one response during* the poll to add the completedReceives. If there are any active channels in the "stagedReceives" we set "timeout" to 0* and pop response and add to the completedReceives.** Atmost one entry is added to "completedReceives" for a channel in each poll. This is necessary to guarantee that* requests from a channel are processed on the broker in the order they are sent. Since outstanding requests added* by SocketServer to the request queue may be processed by different request handler threads, requests on each* channel must be processed one-at-a-time to guarantee ordering.** @param timeout The amount of time to wait, in milliseconds, which must be non-negative* @throws IllegalArgumentException If `timeout` is negative* @throws IllegalStateException If a send is given for which we have no existing connection or for which there is* already an in-progress send*/
// 在每个连接上执行任何 I/O 操作,而不会阻塞。
// 这包括完成连接、完成断开连接、启动新的发送或正在进行的发送或接收取得进展。
// 当此调用完成时,用户可以使用completedSends()、completedReceives()、connected()、disconnected()检查是否已完成发送、接收、连接或断开连接。
// 在“纯文本”设置中,我们使用 socketChannel 来读取和写入网络。
@Override
public void poll(long timeout) throws IOException {if (timeout < 0)throw new IllegalArgumentException("timeout should be >= 0");boolean madeReadProgressLastCall = madeReadProgressLastPoll;// 每次调用前先清空列表数据clear();boolean dataInBuffers = !keysWithBufferedRead.isEmpty();if (hasStagedReceives() || !immediatelyConnectedKeys.isEmpty() || (madeReadProgressLastCall && dataInBuffers))timeout = 0;if (!memoryPool.isOutOfMemory() && outOfMemory) {//we have recovered from memory pressure. unmute any channel not explicitly muted for other reasonslog.trace("Broker no longer low on memory - unmuting incoming sockets");for (KafkaChannel channel : channels.values()) {if (channel.isInMutableState() && !explicitlyMutedChannels.contains(channel)) {channel.maybeUnmute();}}outOfMemory = false;}/* check ready keys */long startSelect = time.nanoseconds();int numReadyKeys = select(timeout);long endSelect = time.nanoseconds();this.sensors.selectTime.record(endSelect - startSelect, time.milliseconds());if (numReadyKeys > 0 || !immediatelyConnectedKeys.isEmpty() || dataInBuffers) {Set<SelectionKey> readyKeys = this.nioSelector.selectedKeys();// Poll from channels that have buffered data (but nothing more from the underlying socket)if (dataInBuffers) {keysWithBufferedRead.removeAll(readyKeys); //so no channel gets polled twiceSet<SelectionKey> toPoll = keysWithBufferedRead;keysWithBufferedRead = new HashSet<>(); //poll() calls will repopulate if neededpollSelectionKeys(toPoll, false, endSelect);}// Poll from channels where the underlying socket has more datapollSelectionKeys(readyKeys, false, endSelect);// Clear all selected keys so that they are included in the ready count for the next selectreadyKeys.clear();pollSelectionKeys(immediatelyConnectedKeys, true, endSelect);immediatelyConnectedKeys.clear();} else {madeReadProgressLastPoll = true; //no work is also "progress"}long endIo = time.nanoseconds();this.sensors.ioTime.record(endIo - endSelect, time.milliseconds());// Close channels that were delayed and are now ready to be closedcompleteDelayedChannelClose(endIo);// we use the time at the end of select to ensure that we don't close any connections that// have just been processed in pollSelectionKeysmaybeCloseOldestConnection(endSelect);// Add to completedReceives after closing expired connections to avoid removing// channels with completed receives until all staged receives are completed.addToCompletedReceives();
}/*** handle any ready I/O on a set of selection keys* @param selectionKeys set of keys to handle* @param isImmediatelyConnected true if running over a set of keys for just-connected sockets* @param currentTimeNanos time at which set of keys was determined*/
// package-private for testing
void pollSelectionKeys(Set<SelectionKey> selectionKeys,boolean isImmediatelyConnected,long currentTimeNanos) {for (SelectionKey key : determineHandlingOrder(selectionKeys)) {KafkaChannel channel = channel(key);long channelStartTimeNanos = recordTimePerConnection ? time.nanoseconds() : 0;boolean sendFailed = false;// register all per-connection metrics at oncesensors.maybeRegisterConnectionMetrics(channel.id());if (idleExpiryManager != null)idleExpiryManager.update(channel.id(), currentTimeNanos);try {/* complete any connections that have finished their handshake (either normally or immediately) */if (isImmediatelyConnected || key.isConnectable()) {if (channel.finishConnect()) {this.connected.add(channel.id());this.sensors.connectionCreated.record();SocketChannel socketChannel = (SocketChannel) key.channel();log.debug("Created socket with SO_RCVBUF = {}, SO_SNDBUF = {}, SO_TIMEOUT = {} to node {}",socketChannel.socket().getReceiveBufferSize(),socketChannel.socket().getSendBufferSize(),socketChannel.socket().getSoTimeout(),channel.id());} else {continue;}}/* if channel is not ready finish prepare */if (channel.isConnected() && !channel.ready()) {channel.prepare();if (channel.ready()) {long readyTimeMs = time.milliseconds();boolean isReauthentication = channel.successfulAuthentications() > 1;if (isReauthentication) {sensors.successfulReauthentication.record(1.0, readyTimeMs);if (channel.reauthenticationLatencyMs() == null)log.warn("Should never happen: re-authentication latency for a re-authenticated channel was null; continuing...");elsesensors.reauthenticationLatency.record(channel.reauthenticationLatencyMs().doubleValue(), readyTimeMs);} else {sensors.successfulAuthentication.record(1.0, readyTimeMs);if (!channel.connectedClientSupportsReauthentication())sensors.successfulAuthenticationNoReauth.record(1.0, readyTimeMs);}log.debug("Successfully {}authenticated with {}", isReauthentication ?"re-" : "", channel.socketDescription());}List<NetworkReceive> responsesReceivedDuringReauthentication = channel.getAndClearResponsesReceivedDuringReauthentication();responsesReceivedDuringReauthentication.forEach(receive -> addToStagedReceives(channel, receive));}attemptRead(key, channel);if (channel.hasBytesBuffered()) {//this channel has bytes enqueued in intermediary buffers that we could not read//(possibly because no memory). it may be the case that the underlying socket will//not come up in the next poll() and so we need to remember this channel for the//next poll call otherwise data may be stuck in said buffers forever. If we attempt//to process buffered data and no progress is made, the channel buffered status is//cleared to avoid the overhead of checking every time.keysWithBufferedRead.add(key);}/* if channel is ready write to any sockets that have space in their buffer and for which we have data */if (channel.ready() && key.isWritable() && !channel.maybeBeginClientReauthentication(() -> channelStartTimeNanos != 0 ? channelStartTimeNanos : currentTimeNanos)) {Send send;try {// 真实发送数据到 Kafka Brocker,不容易。// 底层实际调用的是Java8 nio包下的 GatheringByteChannel的write方法send = channel.write();} catch (Exception e) {sendFailed = true;throw e;}if (send != null) {this.completedSends.add(send);this.sensors.recordBytesSent(channel.id(), send.size());}}/* cancel any defunct sockets */if (!key.isValid())close(channel, CloseMode.GRACEFUL);} catch (Exception e) {String desc = channel.socketDescription();if (e instanceof IOException) {log.debug("Connection with {} disconnected", desc, e);} else if (e instanceof AuthenticationException) {boolean isReauthentication = channel.successfulAuthentications() > 0;if (isReauthentication)sensors.failedReauthentication.record();elsesensors.failedAuthentication.record();String exceptionMessage = e.getMessage();if (e instanceof DelayedResponseAuthenticationException)exceptionMessage = e.getCause().getMessage();log.info("Failed {}authentication with {} ({})", isReauthentication ? "re-" : "",desc, exceptionMessage);} else {log.warn("Unexpected error from {}; closing connection", desc, e);}if (e instanceof DelayedResponseAuthenticationException)maybeDelayCloseOnAuthenticationFailure(channel);elseclose(channel, sendFailed ? CloseMode.NOTIFY_ONLY : CloseMode.GRACEFUL);} finally {maybeRecordTimePerConnection(channel, channelStartTimeNanos);}}
}最后,再跟一下 KafkaChannel#write() 源码:
/*** A Kafka connection either existing on a client (which could be a broker in an* inter-broker scenario) and representing the channel to a remote broker or the* reverse (existing on a broker and representing the channel to a remote* client, which could be a broker in an inter-broker scenario).* <p>* Each instance has the following:* <ul>* <li>a unique ID identifying it in the {@code KafkaClient} instance via which* the connection was made on the client-side or in the instance where it was* accepted on the server-side</li>* <li>a reference to the underlying {@link TransportLayer} to allow reading and* writing</li>* <li>an {@link Authenticator} that performs the authentication (or* re-authentication, if that feature is enabled and it applies to this* connection) by reading and writing directly from/to the same* {@link TransportLayer}.</li>* <li>a {@link MemoryPool} into which responses are read (typically the JVM* heap for clients, though smaller pools can be used for brokers and for* testing out-of-memory scenarios)</li>* <li>a {@link NetworkReceive} representing the current incomplete/in-progress* request (from the server-side perspective) or response (from the client-side* perspective) being read, if applicable; or a non-null value that has had no* data read into it yet or a null value if there is no in-progress* request/response (either could be the case)</li>* <li>a {@link Send} representing the current request (from the client-side* perspective) or response (from the server-side perspective) that is either* waiting to be sent or partially sent, if applicable, or null</li>* <li>a {@link ChannelMuteState} to document if the channel has been muted due* to memory pressure or other reasons</li>* </ul>*/
public class KafkaChannel implements AutoCloseable {public Send write() throws IOException {Send result = null;if (send != null && send(send)) {result = send;send = null;}return result;}private boolean send(Send send) throws IOException {midWrite = true;send.writeTo(transportLayer);if (send.completed()) {midWrite = false;transportLayer.removeInterestOps(SelectionKey.OP_WRITE);}return send.completed();}
}/*** A send backed by an array of byte buffers*/
public class ByteBufferSend implements Send {private final String destination;private final int size;protected final ByteBuffer[] buffers;private int remaining;private boolean pending = false;public ByteBufferSend(String destination, ByteBuffer... buffers) {this.destination = destination;this.buffers = buffers;for (ByteBuffer buffer : buffers)remaining += buffer.remaining();this.size = remaining;}@Overridepublic String destination() {return destination;}@Overridepublic boolean completed() {return remaining <= 0 && !pending;}@Overridepublic long size() {return this.size;}@Overridepublic long writeTo(GatheringByteChannel channel) throws IOException {// java.nio.channels GatheringByteChannellong written = channel.write(buffers);if (written < 0)throw new EOFException("Wrote negative bytes to channel. This shouldn't happen.");remaining -= written;pending = TransportLayers.hasPendingWrites(channel);return written;}
}就这样,我们的消息就发送到 Kafka Brocker 中了,发送流程分析完毕,这个是完美的情况,但是总会有发送失败的时候 (消息过大或者没有可用的 leader),那么发送失败后重发又是在哪里完成的呢?还记得上面的回调函数吗?没错,就是在回调函数这里设置的,先来看下回调函数 Sender#handleProduceResponse() 的源码:
private void handleProduceResponse(ClientResponse response, Map<TopicPartition, ProducerBatch> batches, long now) {RequestHeader requestHeader = response.requestHeader();long receivedTimeMs = response.receivedTimeMs();int correlationId = requestHeader.correlationId();// 如果是网络断开则构造Errors.NETWORK_EXCEPTION的响应if (response.wasDisconnected()) {log.trace("Cancelled request with header {} due to node {} being disconnected",requestHeader, response.destination());for (ProducerBatch batch : batches.values())completeBatch(batch, new ProduceResponse.PartitionResponse(Errors.NETWORK_EXCEPTION), correlationId, now, 0L);} else if (response.versionMismatch() != null) {//如果是版本不匹配,则构造Errors.UNSUPPORTED_VERSION的响应log.warn("Cancelled request {} due to a version mismatch with node {}",response, response.destination(), response.versionMismatch());for (ProducerBatch batch : batches.values())completeBatch(batch, new ProduceResponse.PartitionResponse(Errors.UNSUPPORTED_VERSION), correlationId, now, 0L);} else {log.trace("Received produce response from node {} with correlation id {}", response.destination(), correlationId);// if we have a response, parse it// 如果存在response就返回正常的responseif (response.hasResponse()) {ProduceResponse produceResponse = (ProduceResponse) response.responseBody();for (Map.Entry<TopicPartition, ProduceResponse.PartitionResponse> entry : produceResponse.responses().entrySet()) {TopicPartition tp = entry.getKey();ProduceResponse.PartitionResponse partResp = entry.getValue();ProducerBatch batch = batches.get(tp);completeBatch(batch, partResp, correlationId, now, receivedTimeMs + produceResponse.throttleTimeMs());}this.sensors.recordLatency(response.destination(), response.requestLatencyMs());} else {// this is the acks = 0 case, just complete all requests// 如果acks=0,那么则构造Errors.NONE的响应,因为这种情况只需要发送不需要响应结果for (ProducerBatch batch : batches.values()) {completeBatch(batch, new ProduceResponse.PartitionResponse(Errors.NONE), correlationId, now, 0L);}}}
}而在 Sender#completeBatch() 方法中我们主要关注失败的逻辑处理,核心源码如下:
private void completeBatch(ProducerBatch batch, ProduceResponse.PartitionResponse response, long correlationId,long now, long throttleUntilTimeMs) {Errors error = response.error;// 如果发送的消息太大,需要重新进行分割发送if (error == Errors.MESSAGE_TOO_LARGE && batch.recordCount > 1 && !batch.isDone() &&(batch.magic() >= RecordBatch.MAGIC_VALUE_V2 || batch.isCompressed())) {// If the batch is too large, we split the batch and send the split batches again. We do not decrement// the retry attempts in this case.log.warn("Got error produce response in correlation id {} on topic-partition {}, splitting and retrying ({} attempts left). Error: {}",correlationId,batch.topicPartition,this.retries - batch.attempts(),error);if (transactionManager != null)transactionManager.removeInFlightBatch(batch);this.accumulator.splitAndReenqueue(batch);maybeRemoveAndDeallocateBatch(batch);this.sensors.recordBatchSplit();} else if (error != Errors.NONE) {// 发生了错误,如果此时可以retry(retry次数未达到限制以及产生异常是RetriableException)if (canRetry(batch, response, now)) {log.warn("Got error produce response with correlation id {} on topic-partition {}, retrying ({} attempts left). Error: {}",correlationId,batch.topicPartition,this.retries - batch.attempts() - 1,error);if (transactionManager == null) {// 把需要重试的消息放入队列中,等待重试,实际就是调用deque.addFirst(batch)reenqueueBatch(batch, now);} else if (transactionManager.hasProducerIdAndEpoch(batch.producerId(), batch.producerEpoch())) {// If idempotence is enabled only retry the request if the current producer id is the same as// the producer id of the batch.log.debug("Retrying batch to topic-partition {}. ProducerId: {}; Sequence number : {}",batch.topicPartition, batch.producerId(), batch.baseSequence());reenqueueBatch(batch, now);} else {failBatch(batch, response, new OutOfOrderSequenceException("Attempted to retry sending a " +"batch but the producer id changed from " + batch.producerId() + " to " +transactionManager.producerIdAndEpoch().producerId + " in the mean time. This batch will be dropped."), false);}} else if (error == Errors.DUPLICATE_SEQUENCE_NUMBER) {// If we have received a duplicate sequence error, it means that the sequence number has advanced beyond// the sequence of the current batch, and we haven't retained batch metadata on the broker to return// the correct offset and timestamp.//// The only thing we can do is to return success to the user and not return a valid offset and timestamp.completeBatch(batch, response);} else {final RuntimeException exception;if (error == Errors.TOPIC_AUTHORIZATION_FAILED)exception = new TopicAuthorizationException(batch.topicPartition.topic());else if (error == Errors.CLUSTER_AUTHORIZATION_FAILED)exception = new ClusterAuthorizationException("The producer is not authorized to do idempotent sends");elseexception = error.exception();// tell the user the result of their request. We only adjust sequence numbers if the batch didn't exhaust// its retries -- if it did, we don't know whether the sequence number was accepted or not, and// thus it is not safe to reassign the sequence.failBatch(batch, response, exception, batch.attempts() < this.retries);}if (error.exception() instanceof InvalidMetadataException) {if (error.exception() instanceof UnknownTopicOrPartitionException) {log.warn("Received unknown topic or partition error in produce request on partition {}. The " +"topic-partition may not exist or the user may not have Describe access to it",batch.topicPartition);} else {log.warn("Received invalid metadata error in produce request on partition {} due to {}. Going " +"to request metadata update now", batch.topicPartition, error.exception().toString());}metadata.requestUpdate();}} else {completeBatch(batch, response);}// Unmute the completed partition.if (guaranteeMessageOrder)this.accumulator.unmutePartition(batch.topicPartition, throttleUntilTimeMs);
}private void reenqueueBatch(ProducerBatch batch, long currentTimeMs) {this.accumulator.reenqueue(batch, currentTimeMs);maybeRemoveFromInflightBatches(batch);this.sensors.recordRetries(batch.topicPartition.topic(), batch.recordCount);
}至此,Producer 发送消息的流程已经分析完毕,现在回过头去看原理图会更加清晰。
2.4 分区算法
KafkaProducer#partition() 源码如下:
/*** computes partition for given record.* if the record has partition returns the value otherwise* calls configured partitioner class to compute the partition.*/
private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) {Integer partition = record.partition();return partition != null ?partition :partitioner.partition(record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
}若没有实现自定义分区器,将使用默认分区器 DefaultPartitioner 。
DefaultPartitioner#partition() 源码如下:
/*** Compute the partition for the given record.** @param topic The topic name* @param key The key to partition on (or null if no key)* @param keyBytes serialized key to partition on (or null if no key)* @param value The value to partition on or null* @param valueBytes serialized value to partition on or null* @param cluster The current cluster metadata*/
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);int numPartitions = partitions.size();if (keyBytes == null) {//如果key为null,则使用Round Robin算法int nextValue = nextValue(topic);List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);if (availablePartitions.size() > 0) {int part = Utils.toPositive(nextValue) % availablePartitions.size();return availablePartitions.get(part).partition();} else {// no partitions are available, give a non-available partitionreturn Utils.toPositive(nextValue) % numPartitions;}} else {// 根据key进行散列// hash the keyBytes to choose a partitionreturn Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;}
}DefaultPartitioner 中对于分区的算法有两种情况:
- 如果键值为 null,默认分区器将使用轮询 (Round Robin) 算法。消息将均衡地分布到各个分区上。
- 如果键不为空,默认分区器将使用散列算法。Kafka 会对键进行散列 (使用 Kafka 自己的散列算法,即使升级 Java 版本,散列值也不会发生变化),然后根据散列值把消息映射到特定的分区上。同一个键总是被映射到同一个分区上 (如果分区数量发生了变化则不能保证),映射的时候会使用主题所有的分区,而不仅仅是可用分区,所以如果写入数据分区是不可用的,那么就会发生错误,当然这种情况很少发生。