如何评估召回系统的好坏?如何评估检索系统是否有提升?在任何人面前,空口无凭。
我们需要一把尺子来衡量。我们需要一个高质量的测试数据集合。每次都在相同的测试数据集上,进行评测。本篇文章介绍一个高质量的应为的测试数据集——MS MARCO。
当你关注召回的效果的时候,一定需要有自己的测试数据集合。
如果你是做rag的,那一定会关注到数据的召回效果。
一、MS MARCO 简介

MS MARCO(Microsoft Machine Reading Comprehension)是由微软提供的一个数据集,旨在推动机器阅读理解和问答系统的研究和发展。该数据集主要聚焦于真实世界的信息检索场景,包括文档检索和检索式对话。
1.1 MS MARCO 数据集来源
该数据集由1,010,916个匿名问题组成——从Bing的搜索查询日志中取样——每个问题都有一个人工生成的答案和182,669个完全人工重写生成的答案。此外,该数据集包含8841823段——从Bing检索的3563535个网络文档中提取,为管理自然语言答案所需的信息。MARCO数据集中的一个问题可能有多个答案,或者根本没有答案。使用这个数据集,我们提出三个不同的任务与不同程度的难度: (i)预测如果一个问题是回答给定一组上下文段落,并提取和合成答案作为人类(ii)生成一个良好的答案(如果可能的话)基于上下文段落可以理解问题和段落上下文,最后(iii)排名一组检索段落给定一个问题。
1.2 MS MARCO 数据集主要包含两个部分:
-
MS MARCO Passage Ranking:这个部分包含了一系列的查询和与之相关的网页段落(passages)。任务是根据给定的查询,对相关的网页段落进行排序,以便于提供最相关的结果。
-
MS MARCO Question Answering:这个部分包含了一系列的问题和对应的答案。任务是根据给定的问题,在提供的一组网页段落中找到最相关的答案。
1.3 MS MARCO 数据集的特点包括:
- 大规模性:数据集中包含了大量的查询、网页段落和问题,具有较高的数据规模。
- 自然性:数据集中的查询和问题都来自于真实的搜索引擎日志或在线问答社区,具有较强的自然性和真实性。
- 挑战性:由于查询和问题的多样性,以及文档的复杂性,MS MARCO 数据集提供了一个挑战性的任务,促进了研究人员对于机器阅读理解和问答系统的进一步探索。
MS MARCO 数据集已经成为了评估和比较机器阅读理解和问答系统性能的重要基准之一,并且在学术界和工业界都得到了广泛的应用和关注。最近看的数十篇关于query改写召回测试的论文,基本上都有用到这个测试数据集做评测(可以看这篇文章 用十篇论文聊聊关于使用LLM做query Rewrite的问题-CSDN博客)。
二、MS MARCO
2.1 地址
更多数据介绍,请看论文地址:
https://arxiv.org/pdf/1611.09268.pdf
MS MARCO

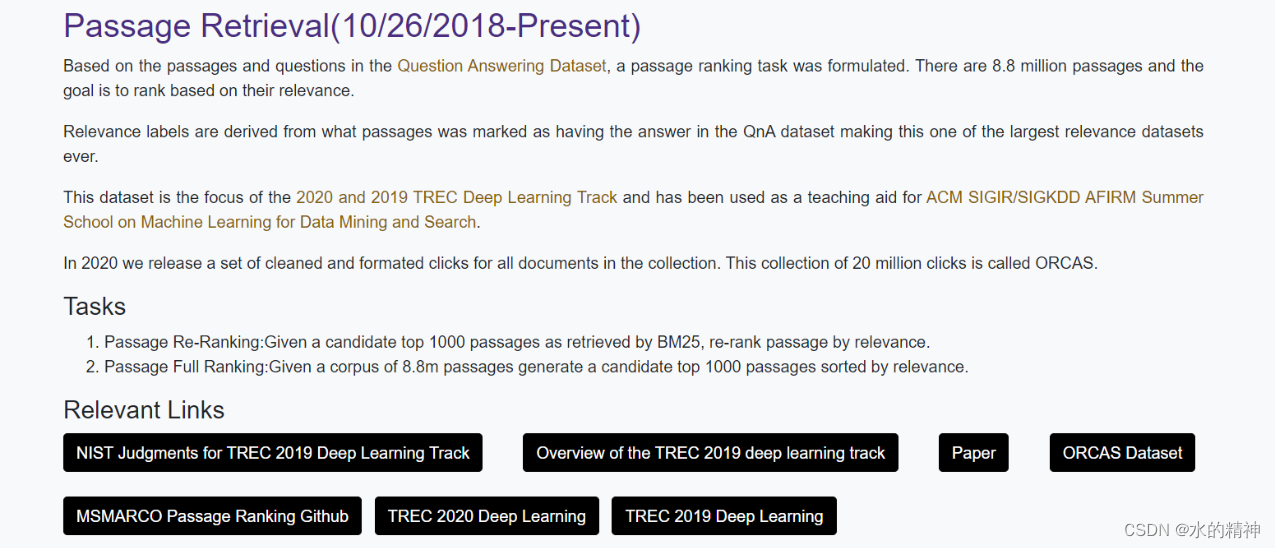
文档级别的检索召回测试
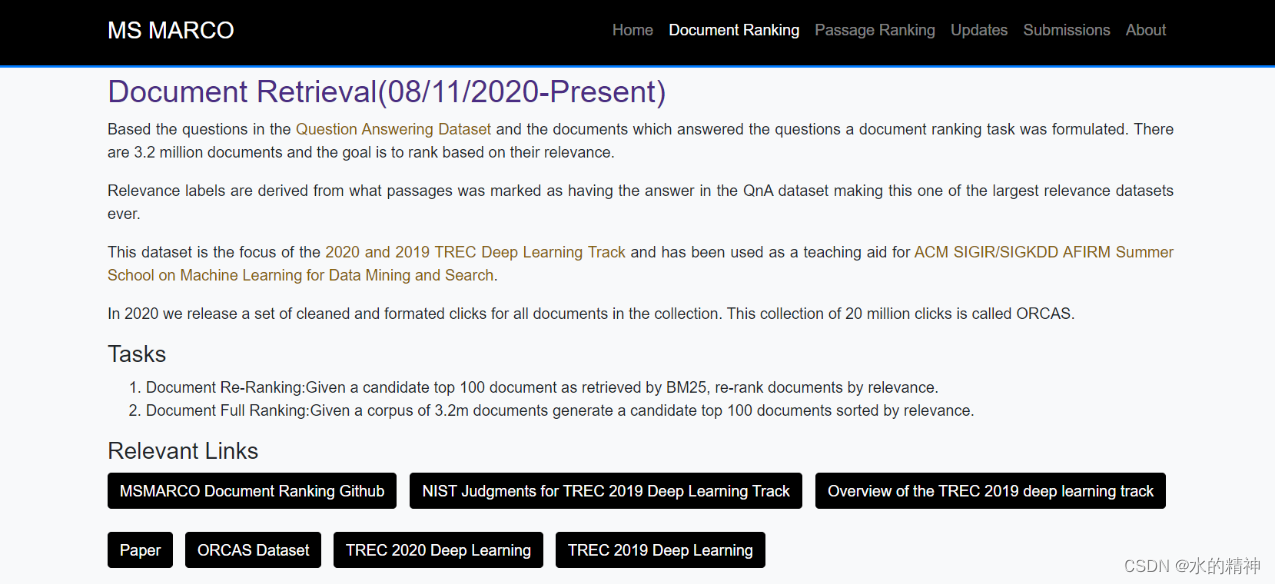
段落级召回测试数据
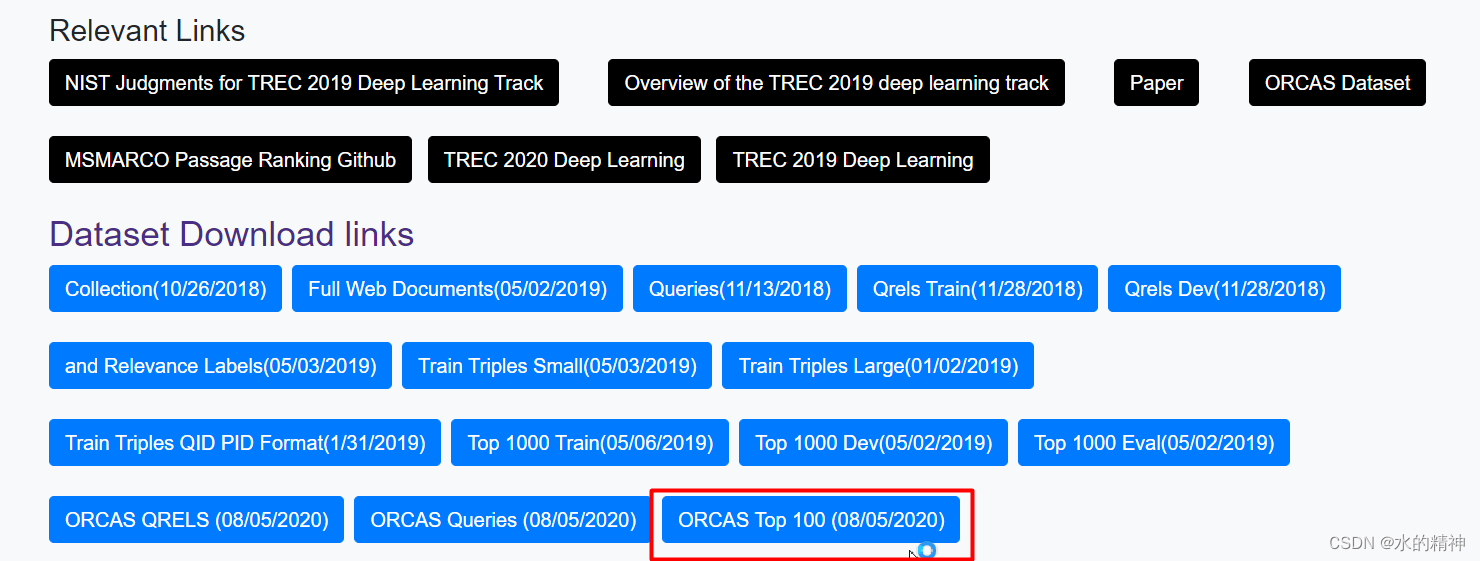
三、如何下载
在官网主页上,先点击这里
 然后就出现了蓝色的下载链接,就可以下载了
然后就出现了蓝色的下载链接,就可以下载了