随着数字化时代的到来,数据管理和应用架构变得越来越重要。数据平台作为一个集中管理和利用数据的架构,为组织提供了促进数据驱动决策和业务创新的能力。本文通过一幅图表,将数据平台技术栈的组成部分清晰呈现,助您深入了解数据中台的全面数据管理与应用架构。
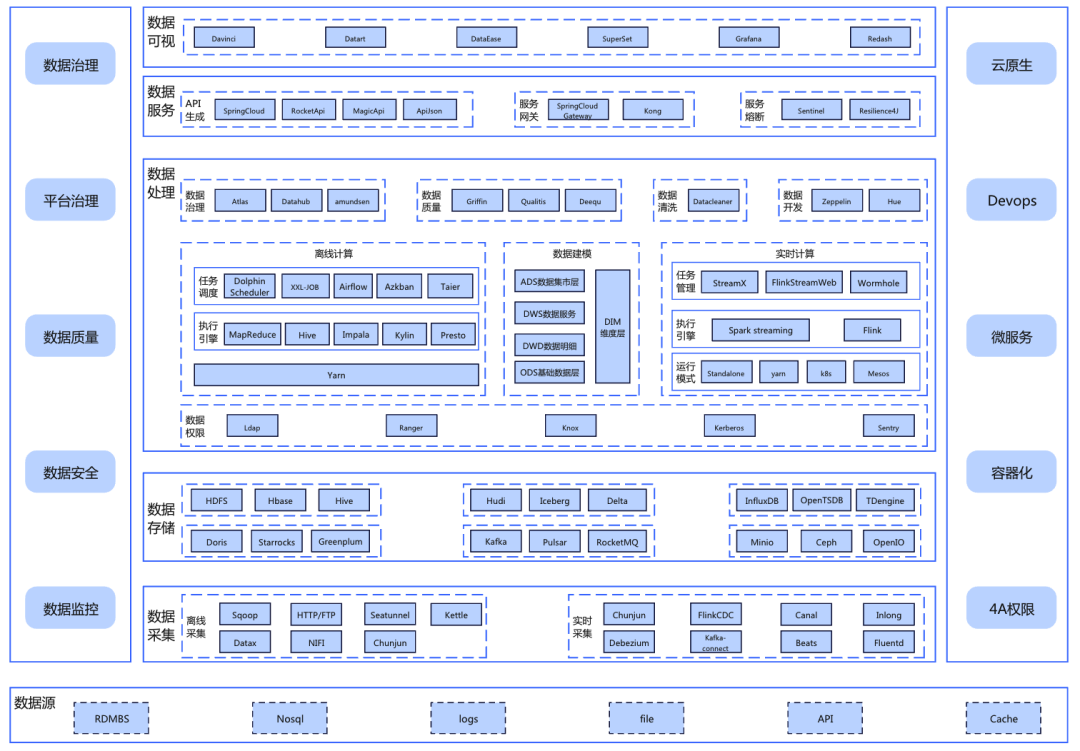
1 数据采集
在数据平台技术栈中,首要任务是从各种数据源(如数据库、传感器、日志文件等)中采集数据。这一步骤通常使用数据抽取、转换和加载(ETL)工具来完成,以确保数据的准确性和一致性。其中包括实时采集和离线采集两种方式。
1.1 离线采集
1.1.1 sqoop
Sqoop(SQL to Hadoop)是一款用于将关系型数据库(RDBMS)与Hadoop生态系统(如Hadoop HDFS和Hive)进行数据传输的工具。它能够在关系数据库和Hadoop集群之间进行数据的导入和导出。Sqoop可以将数据库中的数据转换成Hadoop中的文件格式,也可以将Hadoop中的数据导入到关系数据库中。通过Sqoop,你可以轻松地将数据从数据库迁移到Hadoop,从而利用Hadoop的分布式计算能力进行数据分析和处理。
Sqoop:
Sqoop的工作原理是通过MapReduce来实现数据的传输。
1、导入数据:将关系数据库中的数据导入到Hadoop集群中,以便进行分析和处理。
2、导出数据:将Hadoop集群中的数据导出到关系数据库中。
3、批量导入导出:支持高效地批量导入和导出数据。
4、并行导入导出:可以使用多个并行的Map任务来进行数据传输,提高效率。
5、数据转换:可以将关系数据库中的数据转换成Hadoop支持的文件格式,如Avro、Parquet等。
1.1.2 ftp/http
FTP(File Transfer Protocol)是一种用于在计算机网络之间传输文件的标准协议。它允许用户通过FTP客户端与FTP服务器建立连接,并进行文件的上传、下载以及删除等操作。
FTP具有以下特点和功能:
1、文件传输:FTP主要用于文件传输,可以方便地将文件从客户端上传到服务器,或从服务器下载到客户端。
2、目录操作:FTP支持对文件和目录进行操作,可以查看、创建、删除和重命名目录。
3、权限控制:FTP提供了用户验证和权限控制机制,可以限制用户对服务器上文件和目录的操作权限。
4、多文件传输:FTP支持同时传输多个文件,可以提高传输效率。
5、断点续传:FTP支持文件的断点续传,即在传输过程中出现中断后可以从中断的地方继续传输,提高传输的可靠性。
需要注意的是,由于FTP是基于明文传输的协议,所以安全性较差。为了增加数据传输的安全性,可以采用FTP协议的安全加强版——FTPS或者使用SFTP(SSH File Transfer Protocol)。
1.1.3 Datax
DataX是阿里巴巴集团开源的一款支持离线、增量、实时的数据同步工具。它可以在不同的数据源之间进行高效的数据同步和迁移。
DataX的特点和功能包括:
1、多种数据源的支持:DataX支持各种常见的数据源,包括关系型数据库(如MySQL、Oracle、SQL Server等)、NoSQL数据库(如MongoDB、Redis等)、HDFS、Hive、HBase等。
2、灵活的同步方式:DataX支持离线、增量和实时的数据同步。离线同步适用于大规模数据迁移,增量同步适用于有新数据产生的场景,实时同步适用于对数据的实时交互和处理。
3、高可靠性和高性能:DataX采用分布式架构和多线程并发机制,能够实现高可靠的数据同步和迁移,并且具有良好的扩展性和性能。
4、灵活的配置和扩展:DataX的配置文件采用JSON格式,用户可以根据具体的需求进行灵活的配置和扩展,满足不同场景下的数据同步需求。
5、良好的生态系统:DataX在阿里巴巴内部得到广泛应用,已经形成了完善的生态系统,并且得到了社区的积极参与和贡献。
1.1.4 kettle
Kettle(也称为Pentaho Data Integration)是一款开源的数据集成工具,由Pentaho公司开发和维护。它提供了一个可视化的界面,用于构建和管理数据集成和转换流程。Kettle可以帮助用户从各种不同的数据源抽取数据,并对其进行清洗、转换和加载(ETL)到目标系统中。
Kettle支持多种数据源和格式,包括关系型数据库(如MySQL、Oracle、SQL Server等)、文本文件、XML、JSON和大数据技术(如Hadoop、Hive等)。它还提供了丰富的转换和处理功能,用户可以通过直观的界面配置数据处理步骤,例如字段映射、数据过滤、排序、聚合、连接等。同时,Kettle还支持任务调度和并行处理,以提高数据处理的效率。
Kettle的优点之一是其易用性。它提供了一个直观的图形用户界面,用户可以通过拖放和连接组件来快速构建数据集成流程,而不需要编写复杂的代码。此外,Kettle还提供了丰富的文档和社区支持,用户可以通过官方文档、论坛和邮件列表获取帮助和分享经验。
总结来说,Kettle是一款功能强大、易用的数据集成工具,适用于各种数据集成和转换场景。它可以帮助用户实现数据的抽取、清洗、转换和加载,并提供了丰富的功能和灵活的配置选项。
1.1.5 chujun
Chunjun离线同步工具的简介:Chunjun是一个开源的离线同步工具,用于在不同设备之间同步文件和数据。它的主要功能是将文件从一个设备同步到另一个设备,确保数据的一致性和完整性。
Chunjun具有以下特点和功能:
1、灵活性:Chunjun支持在不同操作系统(如Windows、Mac、Linux等)和设备(如PC、手机、平板等)之间进行同步。用户可以根据自己的需求选择合适的设备和操作系统进行同步。
2、多种同步方式:Chunjun提供了多种同步方式,包括局域网同步、云同步和本地同步等。用户可以根据实际情况选择合适的同步方式,并且可以自定义同步规则和设置。
3、快速和安全:Chunjun采用高效的传输算法和安全的加密机制,确保文件在同步过程中的快速和安全。同时,Chunjun还支持断点续传和增量同步,节省用户的时间和网络流量。
4、用户友好的界面:Chunjun提供了直观和用户友好的界面,使用户可以轻松地设置和管理同步任务。同时,Chunjun还提供了日志记录和错误处理功能,方便用户查看同步过程中的详细信息和处理同步中可能出现的错误。
Chunjun离线同步工具可以帮助用户在不同设备之间实现文件和数据的同步,提高工作和生活的效率。它是一个方便实用的工具,适用于个人用户和企业用户。
1.2 实时采集
1.2.1 FlinkCDC
Flink CDC是一个基于Apache Flink的实时数据采集工具。CDC是Change Data Capture的缩写,它用于捕获和解析数据库中的增量变更数据,并将其实时推送到其他系统或数据湖中。
使用Flink CDC,你可以实时捕获和同步数据库中的数据变更。它能够自动识别和解析数据库中的新增、更新和删除操作,并将这些变更数据转换为流数据,以便进行后续的处理和分析。
Flink CDC具有以下特点:
1、实时性:它能够实时捕获和推送数据库中的增量变更数据,并几乎与数据库操作同时进行同步。
2、灵活性:它支持多种主流的关系型数据库,如MySQL、PostgreSQL等,并具有可扩展性,可以适应大规模的数据变更。
3、同步精度:它能够保证数据同步的准确性和一致性,确保变更数据的完整性和正确性。
4、高性能:它基于Flink框架,具有优秀的并发性能和水平扩展能力。
总之,Flink CDC是一个强大的实时数据采集工具,可以帮助你在数据变更发生时实时捕获和同步数据库中的数据,以支持实时分析和应用需求。
1.2.2 Canal
Canal是一种开源的实时数据库变更数据捕获工具,主要用于捕获MySQL和阿里云RDS数据库的增量数据变更。它可以将数据库中的数据变更事件实时推送到消息队列(如Kafka)或其他消费者进行后续处理。
使用Canal,你可以实时监测和捕获数据库中的数据变更操作,包括插入、更新和删除等操作。它通过解析数据库的binlog日志来获取增量变更数据,并将这些数据转化为结构化的格式方便后续消费者处理。
Canal具有以下特点:
1、实时性:它能够几乎实时地捕获和推送数据库中的增量数据变更,以满足实时处理和分析的需求。
2、可扩展性:它支持高可扩展性,可以同时监控多个数据库实例,并提供水平扩展能力,适应大规模数据变更的情况。
3、灵活性:Canal支持多种消息队列(如Kafka)作为数据输出,也支持自定义消费端进行数据处理和分析。
4、容错性:Canal具备容错机制,可以保证在数据库或Canal服务器故障情况下数据不丢失。
1.2.3 Flume
Flume是一个分布式、可靠且可扩展的实时数据采集工具,用于将日志和事件数据从各种源头(如Web服务器、应用程序和传感器)传输到Hadoop生态系统中的数据存储(如HDFS、HBase)或其他数据处理引擎(如Spark、Kafka)。它提供了简单而强大的机制来收集、聚合和移动大量数据,并且能够水平扩展,以适应不断增长的数据规模。
Flume的工作原理基于数据流,包括三个主要组件:Source、Channel和Sink。Source负责收集数据,可以从各种数据源中读取数据;Channel用于暂存数据以便后续处理;Sink将数据发送到目标存储或处理系统。Flume还提供了一些内置的Source、Channel和Sink,同时也支持自定义插件。
除了基本的数据收集功能,Flume还提供了一些其他特性,比如事件的可靠传输、数据的分片和细粒度的数据过滤。同时,Flume可配置性强,可以根据具体需求进行灵活的配置和扩展。
总之,Flume是一个功能强大的实时数据采集工具,可以帮助用户高效、可靠地收集和传输大规模的数据。
2 数据存储
2.1 Hbase
HBase(Hadoop Database)是一个基于Hadoop的分布式、可伸缩的非关系型数据库,它是Google的Bigtable论文的开源实现。HBase在Hadoop生态系统中作为一种存储和处理大数据的解决方案,被广泛应用于海量数据的存储和实时查询场景。
HBase的特点如下:
1、分布式架构:HBase是基于分布式文件系统HDFS构建的,数据存储在分布式集群的各个节点上,可以水平扩展以满足大规模数据存储需求。
2、高可靠性:HBase通过数据在集群中的多个副本进行冗余存储,提供了高可靠性和容错能力。
3、高性能:HBase的底层存储是基于HDFS的,可以利用Hadoop的并行计算框架来进行高效的数据处理和查询。
4、列存储:HBase是一种列存储的数据库,数据按列族存储,可以灵活地添加和修改列。
5、强一致性:HBase保证了数据的强一致性,在写入和读取数据的过程中可以保持数据的一致性。
2.2 Hdfs
HDFS(Hadoop Distributed File System)是Apache Hadoop框架中的分布式文件系统。它被设计用于存储和处理大规模数据集,并提供了高可靠性、高吞吐量和容错能力。
HDFS采用了一种分布式存储模型,将大文件划分成多个块,并将这些块分布在集群中的不同机器上。每个块都会有多个副本,这些副本会在集群的不同节点上进行备份以提供容错能力。这种方式可以实现数据的并行存储和并行访问,以提高数据的处理效率。
HDFS的特点包括:
1、可扩展性:HDFS可以存储和处理超大规模的数据集,集群规模可以随着数据量的增长而进行扩展。
2、容错性:HDFS通过数据冗余和自动故障恢复机制来提供高可靠性。每个数据块都进行多份备份存储,一旦某个节点发生故障,可以从其他副本中获取数据。
3、高吞吐量:HDFS通过将数据并行地存储和读取来实现高吞吐量。它适用于大批量的数据写入和读取操作。
4、数据可访问性:HDFS支持随机访问和流式访问两种方式。对于大规模的数据批量处理任务,流式访问可以提供更好的性能。
总之,HDFS是一个在大数据环境下常用的分布式文件系统,它提供了高容量、高吞吐量、可靠性、可扩展性等特点,使得它成为大规模数据存储和处理的重要工具。
2.3 Doris
Doris(原名为Palo)是一款开源的大规模实时数据仓库,由阿里巴巴集团开发并于2016年开源。它旨在提供高效、易用和可扩展的数据仓库解决方案,用于存储、管理和分析大规模的结构化数据。
Doris具有以下特点:
1、分布式架构:Doris采用分布式的存储和计算架构,可以水平扩展,处理大规模数据集。它使用多个节点进行数据存储和计算,并通过数据分片和并行计算来提高性能。
2、列式存储:Doris使用列式存储方式,将每列数据存储在一起。这种存储方式在大规模数据分析和聚合查询中具有更好的性能,可以减少I/O操作和内存使用。
3、实时数据同步:Doris支持实时的数据同步和更新,可以灵活地处理实时数据的插入、更新和删除操作。它提供了多种数据写入方式,如批量导入、流式写入和实时同步等。
4、高性能查询:Doris提供了丰富的查询语法和优化器,可以快速执行复杂的查询操作。它支持多维分析、钻取、排序、聚合等功能,并提供了快速索引和数据预处理机制,以提高查询性能。
5、可靠性和容错性:Doris具有高可用性和容错性,它通过数据冗余和自动故障恢复机制来提供数据的可靠性。如果某个节点发生故障,系统可以自动将数据从其他节点中恢复。
总的来说,Doris是一款强大的大规模实时数据仓库,适用于大数据分析和实时查询场景。它具备高性能、可靠性和可扩展性等优点,为用户提供了强大的数据存储和分析能力。
2.4 Starrocks
Starrocks是一款开源的大规模实时数据仓库,也是一种高性能的在线分析处理(OLAP)引擎。它是由众多互联网企业在海量数据分析领域的实践经验基础上,结合并改进了Apache Hadoop以及Google Dremel的技术而来。Starrocks具有分布式架构、列式存储、实时数据同步以及高性能查询等特点。
Starrocks采用的是类似于Hadoop的Master/Worker架构,其中Master节点负责元数据管理和查询优化等任务,而Worker节点则承担数据存储和计算任务。它的列式存储方式使得Starrocks在处理大规模数据时具有出色的性能和扩展性。
Starrocks还支持实时数据同步,可以通过内置的数据同步工具将数据从Kafka、MySQL等数据源实时导入到Starrocks,保证数据的及时性和准确性。
在查询性能方面,Starrocks通过高效的查询优化和并行计算,可以在秒级别甚至更短的时间内完成复杂的数据分析查询,提供给用户实时的分析结果。
总体而言,Starrocks是一个功能强大、易于使用的大规模实时数据仓库,广泛用于各种类型的数据存储、处理和分析的需求。它能够帮助企业快速构建和部署数据仓库,实现高性能的数据分析和查询。
2.5 Greenplum
Greenplum是一款开源的大规模并行处理(MPP)数据库,专注于高性能的数据存储和分析。它是由Greenplum公司开发的,在2010年后被Pivotal公司收购。Greenplum的设计目标是解决海量数据处理和高并发查询的挑战。
Greenplum采用了共享存储和并行查询的架构,具有强大的横向扩展能力。它支持在多个计算节点上并行处理数据,以实现快速的数据加载、查询和分析。Greenplum使用基于PostgreSQL的SQL语言作为查询语言,并在其之上进行了优化和扩展,提供了更高效、更强大的查询功能。
Greenplum使用分布式存储方式,将数据分布在多个计算节点上,以提高数据的并发读写性能。它还支持数据切片(Data Partitioning),将数据分为多个片段并均匀分布在各个节点上,以实现更好的负载均衡和查询性能。
Greenplum还提供了高级的数据分析功能,如并行数据聚合、复杂查询、窗口函数等,可以满足各种复杂的数据分析需求。同时,Greenplum还与其他大数据工具和框架(如Hadoop、Spark)集成,以便更好地处理和分析海量数据。
总体而言,Greenplum是一款功能强大、可扩展性好的大规模并行处理数据库,适用于处理大规模数据集并进行复杂数据分析的场景。它在诸多企业和组织中广泛应用于数据仓库、商业智能和大数据分析等领域。
2.6 Hudi
Hudi(Hadoop Upserts Deletes and Incrementals)是由Apache Hudi项目开发的一种开源数据湖解决方案。它旨在简化数据湖的构建和管理,并提供了增量更新、删除和查询功能。
Hudi采用了基于时间的数据划分和列式存储来优化数据湖的存储和查询性能。它支持将数据以不可变的方式存储在数据湖中,并提供了一组API和工具来实现数据的增量更新和删除操作。这使得数据的更新和删除不再需要全量重写,从而提高了数据湖的运行效率。
此外,Hudi还提供了支持查询的索引和Apache Spark的集成,使得用户可以通过SQL或Spark DataFrame等方式方便地对数据湖中的数据进行查询和分析。同时,Hudi还支持多版本管理和数据恢复,使得数据湖具备了更好的数据可靠性和灵活性。
2.7 Iceberg
Iceberg是一个开源的表格格式和分层存储的数据湖解决方案,由Netflix开发并于2019年开源。它旨在解决传统数据湖存在的一些问题,例如数据一致性、表格模式演进、数据查询效率等。
Iceberg采用了一种称为"table format"的数据组织方式,它能够支持大规模数据存储和高效查询。Iceberg将数据表分割成多个数据文件,并支持列式存储和数据压缩,以提高数据查询性能和存储效率。同时,Iceberg还提供了一套强大的运营工具,如元数据管理、事务性写入、数据版本控制、数据分区和数据快照等,以更好地管理和维护数据湖。
另一个重要的特性是Iceberg支持表格模式的演进。它引入了架构演化的概念,允许用户对数据表的模式进行修改和演进,而无需对整个数据表进行全量更新。这使得数据表的结构变更更加容易和高效,有助于提高数据湖的灵活性和适应性。
此外,Iceberg还支持许多主流大数据处理引擎,如Apache Spark、Presto和Apache Hive等,使得用户可以使用这些引擎对Iceberg中的数据进行查询和分析。
综上所述,Iceberg是一个开源的表格格式和分层存储的数据湖解决方案,它强调数据一致性、表格模式演进和高效查询。Iceberg在大数据领域被广泛应用于构建和管理数据湖,并且得到了社区的积极贡献和支持。
2.8 Delta
Delta是一种开源的数据湖解决方案,由Databricks开发和维护。它提供了一种高性能、可靠和可伸缩的数据存储和处理引擎,专为大规模数据湖环境而设计。
Delta是基于Apache Parquet和Apache Spark构建的,它扩展了这两个开源项目,为数据湖提供了更丰富的功能和更好的性能。它具有以下几个主要特点:
1、事务性写入:Delta采用了事务日志的机制来保证数据写入的原子性,确保在数据写入过程中出现故障时,数据不会被破坏或丢失。
2、时间旅行查询:Delta支持对数据进行时间旅行查询,可以在不同的时间点上访问数据的不同版本。这对于数据版本控制、回滚和审计非常有用。
3、数据合并和变更管理:Delta提供了强大的合并操作和变更管理功能,可以轻松地将新数据与现有数据合并,实现增量更新和变更跟踪。
4、数据一致性和可靠性:Delta使用了写前日志和快照隔离等技术来保证数据的一致性和可靠性。它能够处理并发写入和读取操作,并且保证数据的一致性视图。
Delta可以用于各种数据湖场景,包括数据仓库、大数据分析、实时数据处理和机器学习等。它提供了简单易用的API和命令行工具,使用户可以方便地对数据进行操作和管理。
2.9 kafka
Kafka是一个分布式的消息队列系统,由Apache软件基金会开发和维护。它被设计用来处理高速的、大规模的实时数据流,提供了高吞吐量、持久化存储和容错性等特性。
Kafka的核心概念是消息和主题。消息是指被发布到Kafka集群的数据记录,它可以是任意形式的数据。而主题是消息的类别或者类型,Kafka中的消息被组织成一个个主题,消费者可以根据主题来订阅感兴趣的消息。
Kafka的架构采用了分布式、分区和复制的方式来实现高可用性和容错性。它将消息分为多个分区,每个分区都被复制到多个Broker节点上,实现了数据的冗余备份和负载均衡。同时,Kafka还支持水平扩展,可以根据需求增加或减少节点来提高吞吐量和容量。
Kafka提供了持久化的消息存储,并且对写入的消息进行顺序写入,以提供高吞吐量的数据处理能力。它还支持消息的发布和订阅模式,可以根据订阅者的需求和速度进行灵活的数据消费。
Kafka广泛应用于实时数据处理、日志收集、事件驱动架构等场景。它与大数据生态系统和流处理框架的集成良好,例如,Spark、Flink和Storm等都提供了对Kafka的直接支持。
2.10 RocketMQ
RocketMQ是阿里巴巴开源的一款分布式消息中间件。它是一个高可用的、无状态的消息队列系统,设计目标是支持超大规模的消息并发和可靠传输。RocketMQ具有高吞吐量、低延迟、可靠性和强大的伸缩性等特点,适用于企业级的大规模消息通信场景。
RocketMQ的架构设计灵感来自Kafka和ActiveMQ,它采用了分布式、可靠、高性能的设计理念。RocketMQ的消息模型是基于主题(topic)的,生产者(producer)通过将消息发送到主题,并将消息分区(partition)到不同的消息队列(queue)。消费者(consumer)通过订阅主题的消息队列来消费消息。
RocketMQ提供了丰富的特性,包括消息顺序、事务消息、广播消费等。同时,它还提供了可视化的管理控制台,方便管理员监控和管理消息队列的运行状态。
RocketMQ被广泛应用于分布式系统中的异步消息传递、解耦、削峰填谷、数据流处理等场景,能够满足高性能、高并发、可靠性要求较高的企业级应用需求。
2.11 InfluxDB
InfluxDB是一种开源的时间序列数据库,是专门用于处理大规模时间序列数据的高性能数据库。它被设计用于存储、查询和分析时间相关数据,如监控指标、日志数据、传感器数据等。
InfluxDB具有以下特点:
1、时间序列数据存储:InfluxDB专注于处理时间序列数据,它使用灵活的数据模型来存储和组织数据,能够高效地处理大量时间序列数据。
2、高性能和水平可扩展性:InfluxDB采用了高性能的写入和查询引擎,支持水平扩展,可以轻松处理高并发和大规模的数据写入和查询。
3、查询语言和函数:InfluxDB提供了类似SQL的查询语言,支持对时间序列数据进行复杂的查询和聚合操作。它还提供了丰富的内置函数来处理和操作时间序列数据。
4、数据保留策略:InfluxDB支持按照时间进行数据的自动过期和删除,你可以设置不同的数据保留策略来控制数据的存储时间。
5、插件生态系统:InfluxDB具有丰富的插件生态系统,支持与多种其他数据源和工具进行集成,如Grafana、Telegraf等,方便数据的可视化和监控。
2.12 OpenTSDB
OpenTSDB(Open Time Series Database)是一种开源的时间序列数据库,用于高效存储和分析大规模时间序列数据。它是在HBase之上构建的,可以提供快速的写入和查询性能。OpenTSDB的设计目标是以最小的存储空间来存储大量的时间序列数据,并快速地对这些数据进行聚合和查询。
OpenTSDB的主要特点包括:
1、高性能写入:OpenTSDB能够支持每秒上万次的数据写入,且具有水平扩展性,可以处理大规模的时间序列数据流。
2、灵活的数据模型:OpenTSDB支持灵活的标签(tag)机制,可以用于对时间序列数据进行分类和过滤。
3、强大的查询功能:OpenTSDB提供了广泛的查询功能,包括按时间范围、标签、聚合等进行查询和分析。
4、可视化和监控:OpenTSDB可以与Grafana等监控工具集成,方便用户对时间序列数据进行实时监控和可视化展示。
5、可扩展性:OpenTSDB可以通过增加节点来实现水平扩展,以满足不断增长的数据存储需求。
OpenTSDB的应用场景广泛,包括物联网、日志分析、监控系统等。它在大规模时间序列数据的存储和分析方面表现出色,为用户提供了强大的工具和功能来处理和利用时间序列数据。
2.13 TDengine
TDengine是一种开源的时序数据库,专用于高效处理和存储大规模时序数据。它具有快速的写入和查询性能,可以在海量数据和高并发环境下进行有效的数据处理和分析。
TDengine的主要特点包括:
1、高性能写入:TDengine能够支持高达百万级别的每秒写入速度,保证了在高频率数据产生的场景下的高效存储。
2、实时查询和分析:TDengine支持快速的实时查询和分析,通过使用多维索引和数据压缩算法,可以在大规模数据集上快速执行复杂的SQL查询。
3、数据一致性和可靠性:TDengine采用了时序数据模型,保证了数据在时间轴上的排序和一致性。同时,它提供了高可用性和灾备机制,确保数据的可靠性和持久性。
4、灵活的数据模型:TDengine支持灵活的标签(tag)和属性(attribute)机制,可以用于对时序数据进行分类和过滤,并支持用户自定义扩展。
5、易于扩展和部署:TDengine的架构设计具有良好的可扩展性,可以根据数据增长的需求灵活添加节点和扩展存储容量。
2.14 Minio
Minio是一种开源的对象存储服务,旨在实现云原生环境下的存储需求。它兼容Amazon S3 API,可以轻松地与现有的S3应用程序集成,同时也支持在私有云或公共云上部署。
Minio提供了可靠的数据持久性,数据会被分片和分布在多个独立的服务器上,以提供高可用性和容错能力。它还采用了分布式的存储架构,可以在多个节点上存储数据,这样可以实现高性能和可扩展性。
Minio的特点还包括易用性和灵活性。它有简洁的API和命令行工具,使用户可以轻松地管理和操作存储桶和对象。此外,Minio还支持多种存储后端,包括本地磁盘、分布式文件系统和云存储服务,用户可以根据自己的需求选择适合的后端。
2.15 Ceph
Ceph是一种开源的分布式存储系统,旨在提供高性能、可靠性和可扩展性的存储解决方案。它采用了分布式对象存储、块存储和文件系统,可以运行在普通硬件上,构建出一个强大的分布式存储集群。
Ceph的设计理念是基于可扩展性和自修复能力。它将数据划分为对象,并将这些对象分布在多个存储节点上。每个对象都有唯一的标识符,并使用CRUSH算法(Controlled Replication Under Scalable Hashing)确定存储位置,以实现负载均衡和数据冗余。如果某个节点或磁盘发生故障,Ceph能够自动地恢复和重平衡数据,保证数据的可靠性和可用性。
Ceph还提供了多种接口,包括对象存储接口(RADOS)用于存储和访问对象、块设备接口(RBD)用于提供虚拟磁盘、以及文件系统接口(CephFS)用于提供分布式文件系统。这些接口使得Ceph可以适应不同的应用场景,并与现有的应用程序和系统集成。
2.16 OpenIO
OpenIO是一种开源的对象存储软件,旨在提供高性能、可扩展和经济高效的存储解决方案。它的设计目标是为了应对海量数据和大规模存储需求,并提供易于管理和操作的接口。
OpenIO采用了分布式对象存储架构,数据被划分为对象,这些对象分布在多个存储节点上。每个存储节点都是自主的,拥有自己的计算和存储资源。这种分布式的架构使得OpenIO能够实现高性能的数据存储和访问,并提供了高可用性和容错能力。
OpenIO还支持多种接口,包括S3、Swift和NFS等。这使得OpenIO可以与现有的应用程序和系统无缝集成,并提供统一的数据访问和管理接口。同时,OpenIO还具有自动化的数据迁移和平衡功能,可以根据数据的使用模式和访问需求自动调整数据的位置和存储策略,以提高性能和效率。
另外,OpenIO还强调了经济高效性,采用了节约资源和能耗的设计理念,可以在廉价硬件上构建存储集群,降低了总体成本。这使得OpenIO成为适用于各种规模和预算的存储解决方案。
3 数据权限
3.1 Ranger
Ranger是一个用于访问控制和权限管理的开源项目。它被广泛用于保护大规模的分布式系统和数据资源,如Hadoop、Apache Hive、Apache Kafka等。Ranger提供了细粒度的权限控制,可以根据用户、组、角色等进行访问控制,并支持多种认证和授权方式。此外,Ranger还支持审计和日志记录,可以跟踪和监控用户的访问行为,以及及时检测潜在的安全问题。总的来说,Ranger可以帮助组织建立起安全可控的数据访问环境,提高系统的安全性和合规性。
3.2 Knox
Knox是一个开源的网关应用程序,主要用于提供安全的远程访问和身份验证服务。它被广泛用于保护大规模的集群环境,如Hadoop和其他基于Web服务的应用程序。Knox可以作为一个代理服务器,将用户的请求转发到后端的服务节点,并提供访问控制、认证和授权等功能。
Knox的主要特点包括:
1、访问控制:Knox可以配置为仅允许特定的用户或组访问受保护的服务。它可以基于用户的身份、IP地址、角色等进行细粒度的访问控制。
2、身份验证和单点登录:Knox集成了多种身份验证机制,包括LDAP、Kerberos和OAuth等。它还支持单点登录(SSO),用户只需通过一次身份验证,即可访问多个受保护的服务。
3、数据加密和安全传输:Knox支持HTTPS和TLS/SSL加密,确保数据在传输过程中的安全性。
4、审计和日志记录:Knox可以记录用户的访问行为,并生成审计日志,用于跟踪和监控系统的安全性。
3.3 Kerberos
Kerberos是一个网络认证协议,用于实现安全的身份验证和访问控制。它最初是由麻省理工学院(MIT)开发的,现在已成为网络安全的标准之一。Kerberos的目标是提供一个可信的身份验证机制,允许用户在网络上的不同计算机之间进行安全的通信。
Kerberos的工作原理如下:
1、认证服务器(AS):用户在客户端输入用户名和密码后,客户端将密码哈希值发送给认证服务器。认证服务器将通过验证用户的信息,并颁发一个称为票据授权票(Ticket Granting Ticket,TGT)的加密令牌给客户端。
2、票据授予服务器(TGS):客户端将TGT发送给TGS,请求访问某个服务。TGS将对客户端进行身份验证,并向客户端颁发一个访问票据。该票据只能提供给指定的服务。
3、服务服务器:客户端将访问票据发送给服务服务器,服务服务器通过解密票据确认客户端的身份,并提供所请求的服务。
Kerberos的优势包括:
1、安全性:Kerberos使用加密技术保护用户的密码和传输中的数据,防止中间人攻击和数据泄露。
2、单点登录(SSO):一旦用户通过Kerberos身份验证,他们可以在整个网络上访问多个受保护的服务,而无需再次输入密码。
3、中央身份管理:Kerberos将用户的身份信息集中存储在一个认证服务器中,简化了身份管理和维护。
3.4 Sentry
Sentry是一种开源的错误追踪(error tracking)工具,它可以帮助开发者监控和解决应用程序中的错误。Sentry提供了实时的报错通知和详细的错误信息,让开发者能够快速定位和解决问题。
Sentry可以集成到各种编程语言和框架中,包括Python、Java、JavaScript等,使开发者能够捕获应用程序中的异常和错误。当错误发生时,Sentry会收集关键的错误信息,如堆栈跟踪、环境变量、HTTP请求等,并将这些信息发送给开发团队。
除了错误追踪,Sentry还提供了其他一些功能,如性能监控、事件日志等。开发团队可以通过Sentry来监控应用程序的性能指标,以便快速发现和解决性能问题。此外,Sentry还支持自定义事件日志,并且可以通过集成其他工具和服务来扩展其功能。
4 离线任务调度
4.1 Dolphin Scheduler
Dolphin Scheduler是一款开源的分布式任务调度系统,它能够帮助用户管理和调度各种类型的任务。Dolphin Scheduler提供了丰富的调度功能和易于使用的界面,使用户能够轻松地创建、调度和监控任务。
Dolphin Scheduler支持多种任务类型,包括Shell脚本、Hive、Spark、MapReduce等,可以满足不同场景下的任务调度需求。用户可以通过可视化的界面来配置任务的依赖关系、调度周期和执行参数等,方便地管理任务的执行流程。此外,Dolphin Scheduler还支持任务的告警设置,当任务执行出现异常时,会及时地通知用户。
Dolphin Scheduler具有高可靠性和可扩展性。它采用分布式架构,支持多服务器部署,可以应对大规模任务调度的需求。同时,Dolphin Scheduler还提供了监控和日志功能,用户可以实时地查看任务的执行状态和日志信息,方便进行监控和故障排除。
4.2 XXL-JOB
XXL-JOB是一款开源的分布式任务调度平台,它提供了高可靠、高可扩展的任务调度和管理功能。XXL-JOB能够帮助用户实现任务的自动化调度和监控,提高工作效率和任务执行的稳定性。
XXL-JOB支持多种任务类型,包括Shell脚本、Java代码、Python脚本等,用户可以根据自己的需求选择适合的任务类型。它还提供了丰富的调度策略,包括固定间隔、固定延迟、CRON表达式等,满足不同场景下的任务调度需求。
XXL-JOB拥有可视化的任务管理界面,用户可以通过界面来创建、修改和删除任务,方便地管理任务的执行流程。同时,XXL-JOB还提供了实时的任务监控和日志查看功能,用户可以随时了解任务的执行状态和日志信息,方便进行任务的监控和排查问题。
XXL-JOB具有高可靠性和可扩展性。它采用分布式架构和集群部署方式,支持多服务器协同工作,可以应对大规模任务调度的需求。此外,XXL-JOB还支持任务的报警设置,当任务执行出现异常时,可以及时地通知用户。
4.3 Airflow
Airflow是一个以任务调度和工作流管理为核心的开源平台。它的目标是提供一个可靠且灵活的系统,用于编排、调度和监控一系列任务或工作流。Airflow提供了一个直观的用户界面,以便用户可以轻松地定义、调度和监控任务的依赖关系和执行情况。
Airflow的核心是一个基于Python编写的调度器,它允许您以编程方式定义任务之间的依赖关系和执行顺序。您可以使用Airflow内置的操作符和传感器来执行各种任务,也可以自定义操作符以满足特定需求。
Airflow提供了丰富的功能,包括任务调度、任务重试、任务失败重试、任务依赖关系管理、任务执行日志和监控、任务报告生成等。它还支持分布式任务执行,可以在多个工作节点上并行运行任务,以提高任务执行效率和可扩展性。
Airflow还提供了一个可视化的任务调度器,让用户可以方便地查看和管理任务的执行情况。您可以通过Web界面轻松地查看和操作任务的依赖关系、执行计划、执行日志和报告。
4.4 Azkban
Azkaban是一个开源的工作流调度和任务编排系统,用于管理和调度Hadoop生态系统中的任务和工作流。它提供了一个友好的UI界面,允许用户轻松地创建、调度和监控任务。
Azkaban的核心功能包括:
1、任务调度和编排:用户可以使用Azkaban创建任务和工作流,定义任务之间的依赖关系,并设置调度时间和频率。
2、可视化界面:Azkaban提供了一个直观的Web界面,用户可以通过它来管理和监控任务的执行情况,查看任务的日志和报告。
3、权限管理:Azkaban支持细粒度的权限控制,可以根据用户和角色来管理对任务和工作流的访问权限。
4、容错和恢复:Azkaban具备容错和恢复能力,可以自动处理任务执行中的错误和失败,以保证任务的稳定性和可靠性。
5、任务监控和报警:Azkaban提供实时的任务监控和报警功能,可以及时发现和处理任务执行中的异常情况。
5 执行引擎
5.1 Mapreduce
MapReduce是一种用于处理大规模数据的编程模型和框架。它最初由Google提出,用于解决大规模数据处理的问题。随后,Apache Hadoop项目将MapReduce作为其核心组件之一,并广泛应用于大数据处理领域。
MapReduce模型基于两个基本的操作:Map(映射)和Reduce(归约)。在数据处理过程中,Map阶段将输入数据集划分为各个小问题,并在每个数据块上应用相同的映射函数,生成一系列键值对。Reduce阶段将Map阶段的输出进行归约操作,通过对键值对进行分组和聚合,生成最终的输出结果。
MapReduce模型的优势之一是其高度可扩展性和并行处理能力。通过将原始数据划分为多个小块,并在每个小块上并行执行映射操作,可以充分利用集群中的计算资源,提高数据处理的效率和性能。此外,MapReduce模型还具有容错性,在计算过程中能够处理节点故障,并自动进行任务重试和数据恢复。
MapReduce的设计思想和编程模型可以广泛应用于各种大数据处理场景,例如单机多核处理、分布式计算和云计算中的数据分析和批处理任务。它提供了一种简单而强大的方式来处理大规模数据,并且可以与其他大数据处理工具和框架进行整合,形成完整的数据处理解决方案。
5.2 hive
Hive 是一个基于 Hadoop 的数据仓库基础架构,它提供了一个类似于 SQL 的查询语言,称为 HiveQL,使得在 Hadoop 上进行数据分析更加方便。Hive 将结构化的数据文件映射到一张表中,并提供了查询、汇总、过滤和转换数据的方式。
HiveQL 是一种声明性查询语言,类似于传统关系型数据库中的 SQL,它允许用户使用类 SQL 的语法进行数据查询和操作。同时,Hive 提供了对数据进行自定义函数的支持,可以通过编写 UDF(用户自定义函数)和 UDTF(用户自定义表函数)来扩展 Hive 的功能。
Hive 的底层运行引擎是 MapReduce,它将 HiveQL 查询转化为 MapReduce 作业,通过分布式计算并行处理海量数据。这使得 Hive 能够处理大数据集,并实现高性能的数据分析和查询。
Hive 的优势在于:
1、与 Hadoop 生态系统紧密集成,可以与其他 Hadoop 组件(如 HDFS、MapReduce、Spark 等)协同工作。
2、提供了类似于 SQL 的查询语言,使得习惯于 SQL 的用户可以更快地上手。
3、具有良好的可扩展性,并且能够处理大规模的数据集。
4、支持自定义函数,允许用户扩展 Hive 的功能。
5、社区活跃,有丰富的资料和插件可供使用。
需要注意的是,Hive 并不是一种实时查询工具,它更适合用于离线批处理任务和数据分析。如果需要实时查询和较低的延迟,可以考虑使用其他的工具或者技术,如Impala或Spark SQL。
5.3 Impala
Impala 是一种开源的分布式 SQL 查询引擎,专为在大数据环境下进行实时查询和分析而设计。Impala 可以直接在 Hadoop 分布式存储上进行交互式分析,无需将数据移动到独立的系统或数据仓库中。
Impala 提供了类似于传统关系型数据库的 SQL 查询语言,它使用了 MPP (Massive Parallel Processing) 架构,支持在集群中并行处理多个查询任务,从而实现了快速的查询速度和低延迟。
Impala 的特点和优势包括:
1、高性能:Impala 利用并发和分布式计算来处理查询,可以在秒级别响应查询请求,适用于实时性要求较高的场景。
2、SQL 兼容性:Impala 具备良好的 SQL 兼容性,大部分标准 SQL 查询语句都可以在 Impala 上执行。
3、实时查询:Impala 可以直接查询存储在 Hadoop 分布式文件系统(HDFS)中的数据,无需数据移动或预先转换。
4、简化架构:Impala 可以与其他 Hadoop 生态系统工具(如 Hive、HBase、Spark)无缝集成,简化了整体架构的复杂性。
5、用户友好:通过 SQL 查询接口,用户可以使用熟悉的语法进行数据分析和查询,无需学习新的查询语言。
6、开源社区:Impala 是一个开源项目,拥有活跃的社区支持和更新的发展。
需要注意的是,Impala 在处理大型数据和复杂查询时效果更好,对于小型数据集或简单查询,可能并不是最优选择。另外,Impala 不适用于有大量写操作的场景,它更适合用于读多写少的数据分析任务。
5.4 Kylin
Kylin是一种开源的大数据分析引擎,主要用于加速OLAP(联机分析处理)查询,特别适用于在海量数据上进行快速、实时的多维分析。
Kylin被设计用于在Hadoop生态系统中构建和查询OLAP立方体。它使用了Apache HBase作为底层存储,利用了Hadoop的强大分布式计算能力。Kylin具有以下几个主要特点:
1、低延迟:Kylin使用了多维数据模型和预计算技术,可以在大规模数据上达到接近实时的查询响应速度。通过将数据预聚集到多维立方体中,Kylin可以极大地减少查询时间和计算复杂度。
2、杜绝数据倾斜:Kylin能够自动发现和处理数据倾斜问题,确保查询在每个节点上都能均匀分布和并行计算。这有助于提高查询性能和整体的可伸缩性。
3、完全兼容SQL:Kylin使用SQL作为查询语言,这使得用户可以直接使用标准的SQL查询语法进行多维分析。这也意味着对于熟悉SQL的开发人员来说,学习和使用Kylin是非常容易的。
4、灵活的数据建模:Kylin支持多维数据模型,可以轻松地对数据进行维度切割和聚合。用户可以根据自己的需求定义不同的维度和度量,从而进行个性化的数据分析。
总之,Kylin是一个强大的开源OLAP引擎,可以帮助企业在海量数据上进行高效的多维分析。它提供了低延迟的查询性能、数据倾斜处理、SQL兼容性和灵活的数据建模的优势。
5.5 Presto
Presto是一种开源的分布式SQL查询引擎,它具有高性能和灵活性,适用于在大规模数据集上进行快速实时查询和分析。
Presto最初由Facebook开发,用于支持其海量数据分析需求。后来,Facebook将其开源,成为一个受欢迎的社区项目。以下是Presto的主要特点:
1、高性能:Presto的设计目标是提供快速的查询速度。它通过使用内存计算和自动优化查询计划等技术,实现了极低的查询延迟。Presto可以在大规模的数据集上并行执行查询,并利用现代硬件的计算能力来提供高吞吐量的查询性能。
2、分布式架构:Presto是一个分布式查询引擎,可以在多个节点上并行处理查询请求,实现快速的数据分析。它使用了高度可伸缩的架构,可以根据需要轻松扩展集群规模,提供更高的并发性和处理能力。
3、SQL兼容性:Presto支持标准的SQL查询语法,这使得用户可以使用熟悉的SQL语言进行查询和分析。它实现了许多SQL的功能和特性,包括连接、聚合、排序和窗口函数等,使得开发人员可以轻松迁移现有的SQL应用程序到Presto上。
4、多数据源支持:Presto可以与各种数据存储系统进行无缝集成,包括Hadoop、关系型数据库、NoSQL数据库等。这使得用户可以在一个统一的查询引擎中访问和分析不同类型的数据源,而无需转换和复制数据。
总的来说,Presto是一个功能强大的分布式SQL查询引擎,具有高性能和灵活性。它能够快速地处理大规模数据集,在多个数据源之间实现无缝查询和分析。Presto已经在许多企业和组织中广泛应用,并受到了广泛认可。
Trino(以前称为Presto SQL)是Presto项目的一个分支。在2020年12月,Presto SQL团队宣布将继续作为一个独立的开发项目,并更名为Trino。Trino保留了Presto的核心功能和特性,并继续致力于提供快速、可扩展、分布式的SQL查询引擎。
Trino的目标是在大数据分析领域提供更好的性能、稳定性和用户体验。它广泛应用于许多组织和企业,用于处理大规模的数据分析和查询任务。因此,当提到Trino时,可以将其视为Presto的一个升级和延续。
6 实时任务管理
6.1 StreamX
StreamX是一款开源的数据流处理平台,旨在帮助用户轻松构建、部署和管理大规模的实时数据流处理应用程序。它提供了一套完整的工具和组件,使用户能够以高效和可靠的方式处理和分析实时数据。
StreamX支持各种常见的数据源和数据接收器,例如Kafka、Flume、RabbitMQ等,使用户能够方便地接入各种实时数据流。它还提供了基于图形界面的可视化开发工具,使用户可以通过简单拖放和连接操作,构建数据处理任务的流程。
StreamX采用流式计算框架,如Apache Flink和Spark Streaming,以支持高吞吐量、低延迟的实时数据处理。它还提供了容错机制和弹性伸缩能力,以应对高并发和大规模数据的处理需求。
总的来说,StreamX旨在简化实时数据流处理的开发和管理,提供高性能和稳定的数据处理能力,帮助用户更好地实现实时数据分析和业务应用。
6.2 flink-streaming-platform-web
Flink Streaming Platform Web是Apache Flink提供的一个可视化Web界面,用于监控和管理Flink实时流处理作业。它提供了一个直观的用户界面,可以查看作业的实时指标和统计信息,以及进行作业的配置和管理。
通过Flink Streaming Platform Web,您可以实时监控作业的整体运行状态、作业的吞吐量和延迟指标,以及每个任务的度量信息。您可以通过可视化的界面进行作业的启动、暂停、停止和重新启动等操作。此外,您还可以查看作业的日志和事件,并进行故障诊断和调试工作。
Flink Streaming Platform Web还提供了一些高级功能,如可视化的作业拓扑图,在图中展示作业的各个算子以及它们之间的数据流动;还可以对作业进行配置和参数调优,以提高作业的性能和效率。
总的来说,Flink Streaming Platform Web使您可以更方便地监控和管理Flink实时流处理作业,并且提供了丰富的功能来帮助您优化作业的性能和调试作业的问题。
7 实时执行引擎
7.1 Spark streaming
Spark Streaming是Apache Spark的一个模块,用于实时数据流处理。它提供了一个高级别的API,可以让开发者使用Spark的批处理模型来处理实时数据流。
Spark Streaming的工作原理是将实时数据流分解成一系列小的批处理作业,并以可配置的间隔时间连续地执行这些作业。每个批处理作业都会将数据流分割成一小段一小段的数据,并将这些数据传递给Spark引擎进行处理。这种方式可以让开发者使用相同的API和工具来处理实时数据流和离线批处理数据,从而简化了实时数据处理的开发过程。
Spark Streaming支持各种数据源,包括Kafka、Flume、HDFS、S3等,并提供了丰富的转换操作和窗口操作,以便开发者能够进行实时的数据处理、过滤、聚合等操作。此外,Spark Streaming还支持与Spark的其他模块(如Spark SQL、MLlib等)无缝集成,可以在实时处理过程中进行复杂的数据分析和机器学习任务。
总的来说,Spark Streaming是一个强大的实时数据流处理框架,通过结合Spark的批处理模型和丰富的API,使开发者能够方便地处理大规模、实时的数据流。它被广泛应用于各种实时数据处理场景,如实时数据分析、流式ETL、实时监控等。
7.2 Flink
Flink是一个开源的流处理框架,它提供了强大的、可扩展的实时数据处理能力。Flink的核心思想是将数据处理任务划分为一系列的流式操作,通过在分布式环境下执行这些操作来实现高效处理大规模数据流。Flink的任务管理使用组件是JobManager,它负责接收用户提交的任务、调度任务的执行以及监控任务的状态。Flink还提供了丰富的API和开发工具,使得开发者可以轻松地构建和部署复杂的实时数据处理应用。除此之外,Flink还支持事件时间和处理时间两种时间概念,并提供了丰富的窗口操作和状态管理机制,以便用户能够更好地处理各种类型的实时数据。总而言之,Flink是一个功能强大、灵活易用的实时数据处理框架,被广泛应用于各种大规模数据处理场景。
实时运行模式管理
7.2.1 Standalone
Flink的Standalone模式是Flink的一种运行模式,它是在一个独立的Flink集群中执行任务的方式。在Standalone模式下,Flink使用自带的资源管理器来管理任务的调度和资源分配。
Standalone模式适合用于本地开发和测试,以及小规模的生产环境。在Standalone模式下,你可以启动一个或多个JobManager和一个或多个TaskManager,它们可以在同一台机器上或分布在多台机器上。
JobManager是Flink的任务管理器,它负责接收和调度用户提交的任务,对任务进行分配和管理。TaskManager是Flink的任务执行器,它负责执行具体的任务逻辑,从数据源读取数据、进行操作和转换,并将结果写回到数据目的地。
Standalone模式的一个特点是它的部署和配置相对简单,使用起来比较方便。但是,它的容错性和可伸缩性相对较低,不适用于大规模的生产环境。在生产环境中,通常会使用Flink在分布式计算框架(如YARN或Kubernetes)上运行,以实现更好的容错性和可伸缩性。
7.2.2 Yarn
Flink支持在YARN上运行,这是一种常见的分布式计算框架。在YARN模式下,Flink将任务提交给YARN资源管理器,并由YARN负责任务的调度和资源分配。
在YARN模式下,Flink的运行过程如下:
1、用户将任务提交给YARN资源管理器,资源管理器根据集群中的可用资源进行调度。
2、YARN资源管理器为Flink启动一个或多个ApplicationMaster来管理任务的执行。
3、ApplicationMaster负责与资源管理器通信,并请求适量的资源来执行任务。
4、资源管理器为ApplicationMaster分配所需的资源,包括JobManager和TaskManager的实例。
5、JobManager负责接收和调度用户提交的任务,分配任务给TaskManager执行,并监控任务的执行状态。
6、TaskManager负责执行具体的任务逻辑,从数据源读取数据、进行操作和转换,并将结果写回到数据目的地。
7、JobManager和TaskManager之间通过消息传递进行通信和协调。
在YARN模式下,Flink可以有效地利用YARN的资源管理和调度能力,实现任务的高可靠性和高可伸缩性。同时,YARN还提供了一套丰富的监控和管理工具,可以方便地对任务进行监控和管理。
7.2.3 K8s
Flink可以在Kubernetes(K8s)上进行任务管理和部署,以实现在容器化环境中的弹性和可伸缩的实时数据处理。
在Kubernetes上管理Flink任务可以提供以下好处:
1、弹性伸缩:Kubernetes可以根据负载自动扩展Flink任务的实例数。它可以根据任务的需求自动调整副本数,以满足处理大量数据的需求,并在负载减少时缩减资源。
2、高可用性:Kubernetes可以管理Flink任务的高可用性。它可以自动重新启动失败的任务实例,并确保任务继续运行,以保持数据处理的连续性。
3、资源隔离:Kubernetes使用命名空间和资源配额来隔离和限制任务的资源使用。这样可以避免任务之间的资源竞争,并确保每个任务都有足够的资源来执行。
4、灵活部署:Kubernetes提供了灵活的任务部署选项。它可以根据任务的需求将任务调度到特定的节点或可用的资源上,以最大程度地提高任务的性能和效率。
要在Kubernetes上部署和管理Flink任务,需要以下组件:
1、Flink Operator:这个组件是在Kubernetes上部署和管理Flink任务的控制器。它负责创建和管理Flink任务的自定义资源,并与Kubernetes API进行通信。
2、JobManager:JobManager是Flink任务的控制节点,负责任务的启动、调度和监控。在Kubernetes上,JobManager以一个Kubernetes Pod的形式运行,并由Flink Operator进行管理。
3、TaskManager:TaskManager是Flink任务的工作节点,负责执行具体的数据处理任务。在Kubernetes上,TaskManager以一个Kubernetes Pod的形式运行,并由Flink Operator进行管理。
通过利用Kubernetes的弹性和可扩展性,以及Flink的实时数据处理能力,可以在Kubernetes上轻松部署和管理大规模的Flink任务。
8 数据治理
8.1 Atlas
Atlas是一个开源的数据管理和治理平台,旨在帮助组织管理和控制数据的整个生命周期。它提供了一个集中式的数据目录,用于注册、搜索和发现各种数据资产,包括表、数据库、文件等。Atlas还提供了一组功能强大的元数据管理和数据分类工具,用于定义、标记和管理数据的元数据,帮助用户更好地理解和利用数据。
以下是Atlas的一些主要功能和特点:
1、元数据管理:Atlas提供了一种机制来捕获和管理数据的元数据,包括表结构、数据所有者、数据类型等信息。通过定义和管理元数据,用户可以更好地了解数据的内容和所有权,并提高数据的可发现性和可操作性。
2、数据分类和标记:Atlas支持对数据进行分类和标记,将其归类到预定义的数据模型中。这样可以更好地组织和管理数据,使其更易于搜索、浏览和理解。同时,通过对数据进行标记,可以应用安全策略和访问控制规则,保护敏感数据的安全性。
3、数据血缘追踪:Atlas可以跟踪数据的血缘关系,即数据是从哪里来的、经过了什么处理和转换。这有助于用户了解数据的来源和历史,并确保数据的准确性和可信度。
4、与其他工具的集成:Atlas可以与其他数据管理和治理工具进行集成,如Ranger(访问控制)、Hive(数据仓库)、HBase(NoSQL数据库)等。通过集成其他工具,可以实现更全面和一体化的数据管理和治理解决方案。
5、扩展性和可定制性:Atlas具有良好的可扩展性和可定制性。它可以根据组织的需求进行定制,满足不同环境和应用的要求,并支持大规模数据管理。
总而言之,Atlas为组织提供了一个强大的平台,用于管理和治理数据的整个生命周期。它提供了数据目录、元数据管理、数据分类和标记、数据血缘追踪等功能,帮助用户更好地组织、管理和利用数据。
8.2 Datahub
Datahub是一种开源的数据管道(data pipeline)解决方案,由阿里巴巴集团开发和维护。它旨在为数据集成、传输和实时处理提供可扩展和可靠的平台。Datahub提供了一种简单且高效的方式来处理大规模数据,并支持高吞吐量、低延迟和高可靠性的数据处理。
具体来说,Datahub提供了以下功能:
数据发布和订阅:Datahub支持消息发布和订阅模型,可以将数据以流式方式传递给不同的消费者。
流式数据传输:Datahub提供了高吞吐量和低延迟的数据传输通道,可以实时将数据从源头传输到目的地,支持水平扩展和高可用性。
消息隔离与过滤:Datahub支持按照不同的主题(Topic)对消息进行隔离和过滤,确保数据只被需要的消费者接收。
数据可靠性保证:Datahub提供了数据冗余备份和故障自动恢复机制,确保在任何情况下数据不会丢失。
可视化监控和管理:Datahub提供了实时监控和仪表盘,可视化地展示数据传输和处理的性能和状态,方便管理员进行管理和调优。
总的来说,Datahub是一个强大的数据管道解决方案,可以帮助企业构建可靠、高效的数据传输和处理平台,支持大规模数据集成和实时分析。
8.3 Amundsen
Amundsen是一个开源的数据发现和元数据管理平台,由Lyft开发并开源。它旨在帮助数据工程师、数据科学家和分析师更好地探索、理解和协作使用数据资产。
Amundsen提供了以下功能:
数据发现:Amundsen通过搜索和浏览功能,让用户能够快速发现数据资产,包括数据表、数据集、指标等。
元数据管理:Amundsen提供了一个集中的元数据存储库,用于管理和维护与数据资产相关的元数据,如表结构、字段描述、数据质量指标等。
数据血缘追踪:Amundsen可以自动捕获和展示数据资产之间的关系和血缘,使用户能够了解数据的来源、转换和使用情况。
协作和社区化:Amundsen支持用户对数据资产的评论、反馈和协作,使团队能够更好地合作、分享和利用数据。
可视化和报告:Amundsen提供了可视化的界面和报表,用于展示数据资产的相关信息和指标,如数据使用情况、数据质量等。
Amundsen的目标是提供一个集中的平台,帮助用户更好地理解和管理数据资产,提高团队的数据可信度和协作效率。它已在实际生产环境中得到广泛使用,并受到了许多企业和组织的认可和采用。
9 数据质量
9.1 Griffin
Griffin是一个开源的数据质量管理框架,用于帮助用户监控、报告和解决数据质量问题。它可以帮助用户识别数据质量问题,并为其提供可视化的监控和报告,以便及时发现和解决问题。
Griffin的核心功能包括:
1、数据源连接:用户可以连接各种不同的数据源,包括关系型数据库、Hadoop生态系统中的数据存储和第三方存储等。
2、数据采样和分析:Griffin支持对数据进行采样和分析,以帮助用户理解数据的特征和质量情况。用户可以定义数据的采样策略,并执行采样任务来获取样本数据。
3、数据质量度量:Griffin提供了一系列内置的数据质量度量指标,例如字段空值比例、唯一值数量、字段格式匹配等。用户可以根据自己的需求定义和执行数据质量度量任务,并获取数据质量度量结果。
4、数据质量监控:Griffin支持实时监控数据质量指标,并生成可视化的监控报告。用户可以通过Web界面查看数据质量指标的实时状态和趋势。
5、数据质量分析:Griffin支持对数据质量问题的分析和排查,通过可视化的图表和日志,帮助用户定位和解决数据质量问题。
总之,Griffin是一个强大而灵活的数据质量管理框架,可以帮助用户监控、报告和解决数据质量问题。它提供了丰富的功能和易于使用的界面,帮助用户提高数据质量和数据分析的效果。
9.2 Qualitis
Qualitis是一个开源的数据质量管理平台,旨在帮助企业提升数据质量并提供数据驱动的决策支持。它具备以下核心功能:
1、数据质量规则管理:Qualitis提供了丰富的数据质量规则库,可以根据不同的业务需求和行业特点,自定义、管理和执行数据质量规则。
2、数据质量检测与修复:Qualitis能够对大规模数据进行质量检测,自动发现数据质量问题,并提供修复建议。用户可以通过可视化的方式对数据质量问题进行跟踪和处理。
3、数据质量报告与监控:Qualitis提供了丰富的数据质量报告和可视化监控功能,帮助用户实时了解数据质量情况,并及时采取措施修复潜在的问题。
4、数据质量评估与风险预测:Qualitis能够对数据质量进行评估,并根据数据质量历史数据进行趋势分析和风险预测,帮助用户制定数据质量改进计划和决策。
Qualitis具有良好的扩展性和可扩展性,可与各种数据存储和处理系统集成,如关系型数据库、Hadoop、Spark等。它还提供了友好的用户界面,使用户能够方便地管理和监控数据质量。通过使用Qualitis,用户可以提高数据质量、降低数据风险,从而提升业务决策的准确性和效率。
9.3 Deequ
Deequ是一个基于Spark的开源数据质量库,旨在帮助用户评估和监控数据的质量。它具备以下核心功能:
1、数据质量度量:Deequ可以针对数据集执行各种质量度量,如唯一值的数量、缺失值的数量、数据的分布和一致性等。这些度量可以帮助用户了解数据集的整体质量情况。
2、数据规则检测:Deequ允许用户定义自定义的数据规则,并在数据集中检测规则是否满足。例如,检测重复数据、空值、异常值等。通过规则检测,用户可以发现和修复数据集中的问题。
3、数据质量监控:Deequ可以实时监控数据质量,检测数据集中的改变和质量问题。用户可以设置警报和通知机制,及时发现和解决数据质量问题。
4、可视化报告和问题跟踪:Deequ提供了可视化的报告和问题跟踪功能,使用户能够更直观地了解数据质量情况和问题的发展趋势。通过这些功能,用户可以快速识别和解决数据质量问题。
Deequ具有高可扩展性和易用性,可以与Spark集群无缝集成,并通过Spark的分布式计算能力处理大规模数据。它还提供了简洁的API和友好的用户界面,使用户可以方便地定义和管理数据质量规则。通过使用Deequ,用户可以提高数据质量管理的效率和准确性,确保数据驱动的业务决策的可靠性。
10 数据清洗
10.1 DataCleaner
DataCleaner 是一个开源的数据清洗工具,旨在帮助用户处理数据质量问题和数据清洗任务。它提供了一组功能强大的工具和算法,用于发现和修复数据中的错误、缺失值、重复项等问题。DataCleaner 支持多种数据源和文件格式,可以对结构化和非结构化数据进行清洗和转换。
DataCleaner 的主要特点包括:
1、数据质量评估:DataCleaner 提供了用于评估数据质量的多种指标和度量方法,例如数据完整性、准确性、一致性等。用户可以根据需要定义自定义的质量规则和规则集。
2、自动数据清洗:DataCleaner 支持自动发现和修复数据中的一些常见问题,如缺失值、异常值、数据格式错误等。它还可以应用机器学习算法来识别和处理更复杂的问题。
3、可视化界面:DataCleaner 提供了直观易用的可视化管理界面,使用户可以轻松导入、清洗和导出数据。它还提供了数据质量报告和可视化工具,帮助用户更好地理解和分析数据质量情况。
4、扩展性和灵活性:DataCleaner 是一个基于插件架构的可扩展工具,可以方便地集成和定制。它支持各种数据集成和转换插件,可以与其他数据处理和分析工具无缝配合使用。
DataCleaner 是一个功能强大、灵活易用的数据清洗工具,可以帮助用户清理和提高数据的质量,以便更好地支持决策和分析任务。
11 数据开发
11.1 Zeppelin
Zeppelin 是一个开源的交互式数据分析和可视化平台,旨在帮助用户在一个集成的环境中进行数据探索、数据分析和协作。它提供了多种编程语言的支持,如Scala、Python、R等,使用户可以使用自己熟悉的语言进行数据操作和分析。
Zeppelin 的主要特点包括:
1、交互式数据探索:Zeppelin 提供了一个交互性强的笔记本界面,用户可以在其中使用实时代码编写和执行数据查询、数据操作和分析任务。它支持数据连接和集成,可以从各种数据源中获取数据进行分析。
2、多语言支持:Zeppelin 支持多种编程语言,用户可以自由选择使用 Scala、Python、R 等语言进行数据处理和分析。这使得用户能够利用自己熟悉的语言和工具来完成数据任务。
3、可视化分析:Zeppelin 提供了丰富的可视化工具和插件,可以帮助用户直观地展示和分析数据。用户可以通过图表、表格、地图等方式来展示数据分析结果,便于他们更好地理解和沟通数据的见解。
4、协作和分享:Zeppelin 允许用户分享和协作笔记本,多个用户可以同时编辑和执行代码,并共享结果和见解。这样可以加强团队合作和知识共享,提高团队的工作效率。
5、扩展性和集成性:Zeppelin 是一个可扩展的平台,用户可以基于自己的需求开发和集成插件。它还支持与其他数据处理和分析工具(如 Spark、Hadoop 等)的无缝集成,使用户可以借助各种工具和技术来进行更复杂的数据分析任务。
Zeppelin 是一个功能强大、灵活易用的交互式数据分析和可视化工具,它提供了丰富的功能和集成环境,帮助用户进行数据探索和分析,并支持团队内的协作和共享。
11.2Hue
Hue是一个开源的Web界面工具,可以用于进行大数据分析和可视化。它提供了一个可视化的界面,使用户可以轻松地与Hadoop和其他大数据系统进行交互。Hue支持Hadoop生态系统中的多个组件,如Hive、Impala、Spark、Pig等,并提供了简化操作和任务管理的功能。
Hue的核心功能包括:
1、查询编辑器:可以使用Hive和Impala等查询引擎编写和执行SQL查询。
2、工作流编辑器:用于创建和管理工作流,可以将各种数据处理步骤和任务组合成一个工作流,并自动执行。
3、文件浏览器:用于管理和浏览Hadoop分布式文件系统(HDFS)中的文件。
4、仪表板和报表:可以创建交互式的仪表板和报表,将数据可视化展示。
5、安全管理:可以配置和管理Hadoop集群的安全和权限设置。
12 API生成
12.1 Springcloud
Spring Cloud是一个基于Spring Framework的开源微服务框架,它提供了一系列工具和组件,使开发和部署分布式系统变得更加简单、高效和可靠。
Spring Cloud提供了多个功能和特点,包括:
1、配置管理:Spring Cloud Config可以集中管理微服务的配置文件,支持动态刷新配置。
2、服务注册与发现:通过Spring Cloud Netflix Eureka或Consul,可以轻松实现服务注册和发现,使微服务之间能够动态地发现和调用。
3、负载均衡:Spring Cloud Netflix Ribbon可以根据不同的负载均衡策略自动分发请求到后端的微服务实例。
4、熔断器:Spring Cloud Netflix Hystrix可以提供熔断器功能,防止服务雪崩效应,提高系统的容错性和稳定性。
5、API网关:通过Spring Cloud Netflix Zuul和Spring Cloud Gateway,可以实现统一的API网关,对外提供API路由、鉴权、限流等功能。
6、分布式追踪:Spring Cloud Sleuth和Zipkin可以实现分布式系统的请求追踪和链路跟踪,方便进行性能优化和故障排查。
7、消息总线:通过Spring Cloud Bus,可以实现微服务之间的消息总线通信,方便进行配置的动态刷新。
8、分布式事务:Spring Cloud Alibaba的Seata可以实现分布式事务的控制和管理。
Spring Cloud提供了丰富的组件和解决方案,便于构建和管理分布式系统。它与Spring Boot紧密集成,使得开发者可以更加简洁、高效地构建、测试和部署微服务应用。总体来说,Spring Cloud是开发分布式系统的首选框架之一,可以极大地提高开发效率和系统的弹性和可靠性。
12.2 RocketApi
RocketAPI 是一个开源的 API 网关和管理平台。它提供了一个统一的入口点来管理和保护您的 API,让您能够更轻松地构建、管理和扩展您的微服务架构。RocketAPI 具有以下核心功能和特点:
1、统一入口:RocketAPI 提供了一个统一的入口点,将所有的 API 集中管理和保护,使得您可以更方便地监控和管理您的 API。
2、安全保护:RocketAPI 具有强大的安全功能,包括身份验证、访问控制、流量控制、API 密钥管理等,保护您的 API 免受未经授权的访问和恶意攻击。
3、智能路由:RocketAPI 支持智能路由和负载均衡,能够根据不同的请求条件将请求转发到适合的后端服务,提高系统的可用性和性能。
4、数据转换:RocketAPI 能够根据您的需求将请求和响应的数据进行格式转换,使得不同系统之间可以更方便地进行数据交互。
5、分析和监控:RocketAPI 提供了强大的分析和监控功能,能够实时监控 API 的使用情况、性能指标和错误信息,帮助您更好地了解和优化您的 API。
RocketAPI 是一个强大而灵活的 API 网关和管理平台,可以帮助您更方便地管理和保护您的 API,并提供强大的分析和监控功能。
12.3 ApIJson
APIJSON 是一种用于构建和规范 RESTful API 的开源框架。它通过 JSON 配置文件描述和定义 API 接口,实现了强大的数据查询和过滤功能,同时提供了一系列的安全和性能优化,简化了 API 的开发和维护过程。以下是 APIJSON 的核心特点:
1、强大的数据查询和过滤:APIJSON 提供了灵活而强大的数据查询和过滤机制,可以精确定义和获取所需的数据,减少了网络传输和数据库查询的开销。
2、自动化接口生成:APIJSON 根据接口定义的 JSON 配置文件,自动生成对应的 CRUD 接口,简化了接口开发和维护的工作量。
3、数据权限控制:APIJSON 支持对接口进行细粒度的数据权限控制,通过 JSON 配置文件可以定义每个用户对数据的可见和可操作范围。
4、接口文档自动生成:APIJSON 根据接口定义的 JSON 配置文件,自动生成相应的接口文档,提供给客户端开发人员参考和使用。
5、性能优化:APIJSON 通过多项性能优化措施,如请求合并、数据缓存等,提高了 API 的响应速度和并发处理能力。
APIJSON 是一个简单而强大的框架,可以帮助开发人员快速构建和规范 RESTful API。它提供了丰富的功能和灵活的配置,使得 API 的开发和维护变得更加简单和高效。
13 服务网关
13.1 SpringCloud Gateway
Spring Cloud Gateway 是一个基于 Spring Boot 的服务网关,用于构建和管理微服务架构中的路由和过滤器。它提供了统一的入口点,用于将外部请求转发到相应的微服务,同时支持自定义的过滤器链来完成请求的处理和转换。
Spring Cloud Gateway 的主要特点包括:
1、动态路由:可以根据需要动态配置路由规则,从而实现灵活的请求转发和负载均衡。
2、过滤器链:提供了丰富的过滤器来处理请求和响应,包括身份验证、鉴权、日志记录等功能,可以自定义过滤器链来满足特定的需求。
3、集成实现:与 Spring Cloud 体系中的其他组件(如 Eureka、Consul 和 Ribbon)紧密集成,可以方便地实现服务注册和发现、负载均衡等功能。
4、高性能:采用异步非阻塞的编程模型,基于 Netty 实现,具有较高的性能和吞吐量。
5、可扩展性:提供了常用的扩展点和接口,可以轻松进行功能扩展和定制化开发。
Spring Cloud Gateway 提供了一个强大而灵活的服务网关解决方案,可以帮助开发者简化微服务架构中的路由和过滤处理,提高系统的可靠性和性能。
13.2 Kong
Kong 是一个开源的云原生 API 网关和服务网格解决方案。它旨在为分布式微服务架构提供统一的入口和管理,具有高性能、可扩展和灵活的特点。
Kong 的主要特点包括:
1、API 管理:提供了灵活的路由和转发功能,可以将外部请求转发到相应的后端服务,并支持请求转换和协议适配。
2、认证和授权:支持多种身份验证和鉴权机制,可以对 API 进行访问控制和权限管理,保护后端服务的安全性。
3、监控和分析:提供实时的流量监控和错误报警,可用于服务的性能优化和故障排查。
4、限流和熔断:支持对请求进行限流和熔断处理,防止后端服务受到过多请求的影响,保证系统的稳定性。
5、插件扩展:提供了丰富的插件机制,可以方便地扩展功能和定制化开发,满足特定需求。
6、多协议支持:支持常用的协议,如 HTTP、HTTPS、TCP 和 WebSocket,可以适用于不同类型的服务。
Kong 可以与现有的微服务架构和云原生技术栈无缝集成,如 Kubernetes、Docker 和 Consul 等,提供统一的服务管理和治理。它的高可用性架构和水平扩展能力使得 Kong 成为构建可靠和高性能的 API 网关的首选解决方案。
14 服务熔断
14.1 sentinel
Sentinel 是阿里巴巴开源的一款轻量级流量控制和熔断降级工具。它具有实时的监控、控制、熔断、降级等功能,可以帮助开发者保护微服务架构中的稳定性。Sentinel 支持多种流量控制规则,包括基于 QPS(每秒查询率)、线程数、并发性等。通过这些规则,开发者可以灵活地对系统进行流量控制,防止系统负载过高。
除了流量控制,Sentinel 还提供了熔断降级的功能。通过设置阈值和异常比例,当系统出现异常情况时,Sentinel 可以自动触发熔断并进行降级处理,以保护系统的稳定性。同时,Sentinel 还提供了实时的监控和统计信息,可以帮助开发者及时发现和解决系统中的问题。
Sentinel 可以帮助开发者在微服务架构中实现流量控制和熔断降级,提高系统的可靠性和性能。它是一个非常实用的工具,特别适用于大规模的分布式系统。
14.2 Resilience4J
Resilience4J 是一个轻量级的容错库,用于构建弹性和可靠的分布式系统。它提供了一系列的容错模式和工具,包括熔断、限流、重试和超时控制等。Resilience4J 的设计目标是提供简单而灵活的方式来处理常见的分布式系统问题。
其中,熔断功能可以在服务不可用或故障的情况下快速失败,减少对资源的消耗和等待时间。限流功能可以限制并发请求的数量,保护系统免受过载。重试功能可以在请求失败时自动进行重试,提高系统的可靠性。超时控制功能可以设置请求的最大执行时间,以避免长时间的阻塞。
Resilience4J 还提供了丰富的配置选项和监控指标,可以帮助开发者灵活地管理和监控容错策略的行为。它与常见的框架和库(如 Spring Boot、Micronaut 和 Vert.x)集成良好,非常易于集成到现有的项目中。
Resilience4J 是一个弹性和可靠性的容错库,提供了熔断、限流、重试和超时控制等功能,能够帮助开发者构建具有弹性的分布式系统。它是一个非常实用的工具,特别适用于微服务架构和云原生应用开发。
以上是所有开源的技术栈的介绍,希望对大家有用~
摘自:https://mp.weixin.qq.com/s/T6rCKgRXbWQ-U72ESU6LcQ