文章目录
- 简介
- 数据格式介绍
- 准确率、召回率和F1评估
- 评估代码
- 评估结果
- 进一步阅读
- 参考
简介
使用大模型训练完命名实体识别的模型后,发现不知道怎么评估实体识别的准确率、召回率和F1。于是便自己实现了代码,同时提供了完整可运行的项目代码。
完整代码: https://github.com/JieShenAI/csdn/tree/main/KnowledgeGraph/ner_compute
数据格式介绍
instruction: 大模型做实体抽取的指令;label: 真实的label;output: 训练完成的大模型的预测结果;
{"id": "ce0...21","task": "NER","source": ".","instruction": "{\"instruction\": \"你是专门进行实体抽取的专家。请从input中抽取出符合schema定义的实体,不存在的实体类型返回空列表。请按照JSON字符串的格式回答。\", \"schema\": [\"PER\", \"ORG\", \"LOC\"], \"input\": \"我们变而以书会友,以书结缘,把欧美、港台流行的食品类图谱、画册、工具书汇集一堂。\"}","label": "[{\"entity\": \"美\", \"entity_type\": \"LOC\"}, {\"entity\": \"台\", \"entity_type\": \"LOC\"}]","output": "{\"PER\": [], \"ORG\": [], \"LOC\": [\"美\", \"台\"]}"
}
原始的label不便于使用,首先转换label为extra_label如下:
{"id": "ce0...21","task": "NER","source": ".","instruction": "{\"instruction\": \"你是专门进行实体抽取的专家。请从input中抽取出符合schema定义的实体,不存在的实体类型返回空列表。请按照JSON字符串的格式回答。\", \"schema\": [\"PER\", \"ORG\", \"LOC\"], \"input\": \"我们变而以书会友,以书结缘,把欧美、港台流行的食品类图谱、画册、工具书汇集一堂。\"}","label": "[{\"entity\": \"美\", \"entity_type\": \"LOC\"}, {\"entity\": \"台\", \"entity_type\": \"LOC\"}]","output": "{\"PER\": [], \"ORG\": [], \"LOC\": [\"美\", \"台\"]}","extra_label": {"PER": [],"ORG": [], "LOC": ["美","台"]}
}
下述代码完成label到extra_label的转换,然后再使用output和extra_label计算准确率、召回率和F1;
label到extra_label的转换的代码如下:
import json
ent_class = ["PER", "ORG", "LOC"]
# 添加额外标签
def add_extra_labels(file_path, output_path):def _add_extra_labels(file_path):with open(file_path, 'r', encoding='utf-8') as f:for line in f:data = json.loads(line)label_data = eval(data['label'])extra_labels = {ent: []for ent in ent_class}for ent in label_data:entity = ent['entity']entity_type = ent['entity_type']if entity_type in ent_class:extra_labels[entity_type].append(entity)data['extra_label'] = extra_labelsyield datawith open(output_path, 'w', encoding='utf-8') as f:for data in _add_extra_labels(file_path):f.write(json.dumps(data, ensure_ascii=False) + '\n')input_file = 'data/predict_data.json'
output_file = 'data/data.json'
add_extra_labels(input_file, output_file)
准确率、召回率和F1评估
-
精确率:识别出正确的实体数 / 识别出的实体数
-
召回率:识别出正确的实体数 / 样本的实体数
-
F1值 = (精确率 * 召回率 * 2) / ( 精确率 + 召回率)
评估代码
代码核心思路:
将预测结果与label转为集合,再利用集合的与操作,即可判断出模型预测成功的实体;
Node:
- predict_right_num:当前文本,模型预测正确的实体数;
- predict_num:模型预测实体总数;
- label_num:label中真实的实体数;
from dataclasses import dataclass@dataclass
class Node:# 默认值predict_right_num: int = 0predict_num: int = 0label_num: int = 0
def compute(input_file):with open(input_file, 'r', encoding='utf-8') as f:total_ent = {ent: Node()for ent in ent_class}error = 0for line in f:data = json.loads(line)extra_labels = data['extra_label']# 大模型采取的是序列到序列到文本生成,不能转换为字典的数据跳过即可try:predict = eval(data['output'])except:error += 1continue# 每个不同的实体类别单独计数for ent_name in ent_class:extra_s = set(extra_labels[ent_name])predict_s = set(predict[ent_name])total_ent[ent_name].predict_right_num += len(extra_s & predict_s)total_ent[ent_name].predict_num += len(predict_s)total_ent[ent_name].label_num += len(extra_s)for ent in ent_class:acc = total_ent[ent].predict_right_num / (total_ent[ent].predict_num + 1e-6)recall = total_ent[ent].predict_right_num / (total_ent[ent].label_num + 1e-6)f1 = 2 * acc * recall / (acc + recall)print(f'{ent} acc: {acc:.4f} recall: {recall:.4f} f1: {f1:.4f}')if __name__ == '__main__':compute('infer_1_epoch_extra.json')
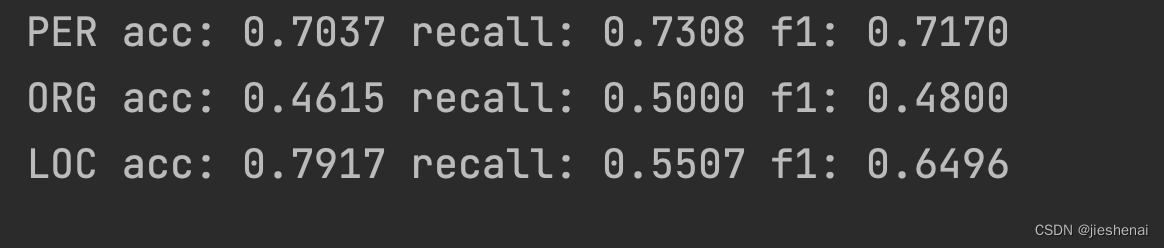
评估结果
进一步阅读
- https://huggingface.co/docs/evaluate/base_evaluator
参考
- 命名实体识别的评价指标





![[Spring] IoC 控制反转和DI依赖注入和Spring中的实现以及常见面试题](https://img-blog.csdnimg.cn/direct/593357fb2524418faa30e4f07364f3a7.png)