1.webmagic框架
webmagic框架是一个Java实现的爬虫框架,底层依然是HttpClient和jsoup
组件:
- downloader:下载器组件
- PageProcessor:页面解析组件(必须自定义)
- scheculer:访问队列组件
- pipeline:数据持久化组件(默认是输出到控制台)

2.入门程序
2.1创建工程
- 创建一个Maven工程
- 添加坐标
<dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>3.8.1</version><scope>test</scope> </dependency> <dependency><groupId>us.codecraft</groupId><artifactId>webmagic-core</artifactId><version>0.9.0</version> </dependency> <dependency><groupId>us.codecraft</groupId><artifactId>webmagic-extension</artifactId><version>0.9.0</version> </dependency>
2.2入门程序
1.创建PageProcess接口实现类
package org.example;import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;/*** 实现分析的业务逻辑*/
public class MypageProcessor implements PageProcessor {/*** 页面分析** @param page 下载结果封装成Page对象* 可以从page对象中获得下载的结果*/@Overridepublic void process(Page page) {Html html = page.getHtml();String htmlStr = html.toString();//把结果输出到控制台
// ResultItems resultItems = page.getResultItems();
// resultItems.put("html", htmlStr);page.putField("html", htmlStr);}/*** 返回一个Site对象* Site就是站点的配置* 返回默认配置使用Site.me创建一个Site对象** @return*/@Overridepublic Site getSite() {return Site.me();}public static void main(String[] args) {Spider.create(new MypageProcessor())//设置起始的url.addUrl("http://www.itcast.cn")//启动爬虫//run 是同步方法在当前线程中执行//start 在新线程中执行爬虫.run();}
}
2.在实现类中实现页面分析的业务逻辑
3.初始化爬虫
4.启动爬虫
5.结果

3.组件介绍
3.1Downloader
下载器组件,使用HttpClient实现
如果没有特殊需求不需要自定义,默认的组件就可以满足全部需求
自定义时需要实现Downloader接口
向PageProcess传递数据时,把结果封装成Page对象
3.2PageProcess(必须自定义)
页面分析的业务组件,页面分析的逻辑在其中实现
需要实现PageProcessor接口
3.2.1.Site
Site代表一个站点信息
可以设置抓取的频率
重试的次数
超时时间

如果没有特殊需求 直接使用默认配置即可
3.2.2Page
getHtml(): 返回抓取的结果
getResultItems(): 返回ResultItems对象, 向pipeline传递数据时使用
getTargetReqyests()、getTargetReqyest(): 向scheduler对象中添加url
3.2.3html(Selectable)
html也是一个Selectable对象
一个Selectable就可以表示一个dom节点
使用html解析页面三种方式:
1.使用原生jsoup方法进行解析
Document document = html.getDocument();
2.使用框架提供的css选择器
html.css("选择器")
html.$("选择器")
3.使用Xpath解析
3.2.4ResultItems
作用就是把解析的结果传递给pipeline
可以使用page对象的getResultItems()方法获取该对象
也可以直接使用putField方法将数据添加到ResultItems对象中
3.2.5Request
并不是Http请求的Request对象,就是把url封装成Request对象
可以添加一个 也可以添加多个
3.3pipeline(自定义频率高)
数据持久化组件
框架提供了三个实现,ConsolePipeline:向控制台输出 默认的
FilePipeline:向磁盘文件中输出
JsonFilePipeline: 保存Json格式的文件


也可以自定义pipeline:
需要实现pipeline接口。
package org.example;import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
import us.codecraft.webmagic.pipeline.FilePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
import us.codecraft.webmagic.selector.Selectable;import java.util.List;/*** 获取黑马网站全部网页*/
public class FilePipelinePageProcessor implements PageProcessor {@Overridepublic void process(Page page) {//访问黑马首页Html html = page.getHtml();//解析首页中所有的链接地址
// Selectable css = html.css("a", "href");Selectable links = html.links();List<String> all = links.all();//把链接地址添加到访问队列中page.addTargetRequests(all);//把页面传递给pipeline 保存到磁盘page.putField("html",html.get());}@Overridepublic Site getSite() {return PageProcessor.super.getSite();}public static void main(String[] args) {FilePipeline filePipeline = new FilePipeline();filePipeline.setPath("Z:\\html");//使用spider初始化爬虫Spider.create(new FilePipelinePageProcessor())//设置起始的url.addUrl("http://www.itheima.com")//设置使用的pipeline.addPipeline(new ConsolePipeline()).addPipeline(filePipeline)//启动.run();}
}
3.4Scheduler
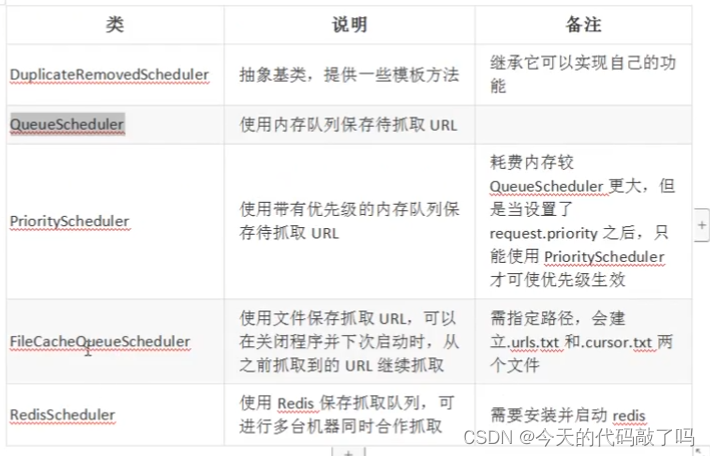
访问url队列
1.默认使用的内存队列
url数据量大时会占用大量的内存
2.文件形式的队列
需要制定保存队列文档的文件路径和文件名
3.redis分布式队列
实现分布式爬虫时 大规模爬虫时使用
3.4.1url去重
webmagic框架中可以对url进行去重处理
1.默认使用HashSet进行去重
需要占用大量的内存
2.规模大时 应该是用redis去重
使用redis成本高,需要搭建集群
3.布隆过滤器去重
内存小,速度快,成本低
缺点是有可能误判,不能删除
3.4.2布隆过滤器的使用
1.添加guava的jar包
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>16.0.1</version></dependency>
public static void main(String[] args) {FilePipeline filePipeline = new FilePipeline();filePipeline.setPath("Z:\\html");//创建一个SchedulerQueueScheduler scheduler = new QueueScheduler();//指定队列使用布隆过滤器去重//初始化一个布隆过滤器 参数就是容量scheduler.setDuplicateRemover(new BloomFilterDuplicateRemover(10000000));//使用spider初始化爬虫Spider.create(new FilePipelinePageProcessor())//设置起始的url.addUrl("http://www.itheima.com")//设置使用的pipeline.addPipeline(new ConsolePipeline()).addPipeline(filePipeline)//设置使用的Scheduler对象.setScheduler(scheduler)//启动.run();}3.5Spider
工具类,可以初始化爬虫
在spider中配置各个组件
启动爬虫
4.页面解析
4.1jsoup
package org.example;import org.jsoup.nodes.Document;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;public class MypageProcessor1 implements PageProcessor {@Overridepublic void process(Page page) {//使用原生Jsoup的api解析页面Html html = page.getHtml();//得到一个jsoup的Document对象Document document = html.getDocument();String title = document.getElementsByTag("title").text();//传递给pipelinepage.putField("title", title);}@Overridepublic Site getSite() {return PageProcessor.super.getSite();}public static void main(String[] args) {Spider.create(new MypageProcessor1()).addUrl("https://www.jd.com").start();}
}
4.2css选择器解析
//使用css解析器解析页面Selectable domTitle = html.$("title","text");
// String title1 = domTitle.toString();String title2 = domTitle.get();page.putField("title2",title2);Selectable元素 两个方法 get()、toString() 都可以把结果转换为字符串
如果返回的是一个dom列表,那么只返回第一个元素
all()就可以得到列表
4.3Xpath解析
这个是webmagic框架中实现的

XPath 教程 (w3school.com.cn)
package org.example;import org.jsoup.nodes.Document;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
import us.codecraft.webmagic.selector.Selectable;import java.util.List;public class MypageProcessor1 implements PageProcessor {@Overridepublic void process(Page page) {//使用原生Jsoup的api解析页面Html html = page.getHtml();//得到一个jsoup的Document对象Document document = html.getDocument();String title = document.getElementsByTag("title").text();//传递给pipelinepage.putField("title", title);//使用css解析器解析页面Selectable domTitle = html.$("title", "text");
// String title1 = domTitle.toString();String title2 = domTitle.get();page.putField("title2", title2);//选择一个节点列表// 只返回第一个String s = html.css("link", "href").get();// 返回列表List<String> all = html.css("link", "href").all();System.out.println(s);System.out.println(all);//使用Xpath进行解析Selectable xpath = html.xpath("//*[@id=\"navitems-group1\"]/li[1]/a/text()");String addr = xpath.get();page.putField("addr", addr);}@Overridepublic Site getSite() {return PageProcessor.super.getSite();}public static void main(String[] args) {Spider.create(new MypageProcessor1()).addUrl("https://www.jd.com").start();}
}