Tensorflow2.0+部署(tensorflow/serving)过程备忘记录
部署思路:采用Tensorflow自带的serving进模型部署,采用容器docker
1.首先安装docker
下载地址(下载windows版本):https://desktop.docker.com/
- docker安装
安装就按正常流程一步一步安装即可 - window环境检查
win10,win11版本及以上
虚拟化是否开启(用处不知道,反正大家都开启了,网上有教程,可以搜搜)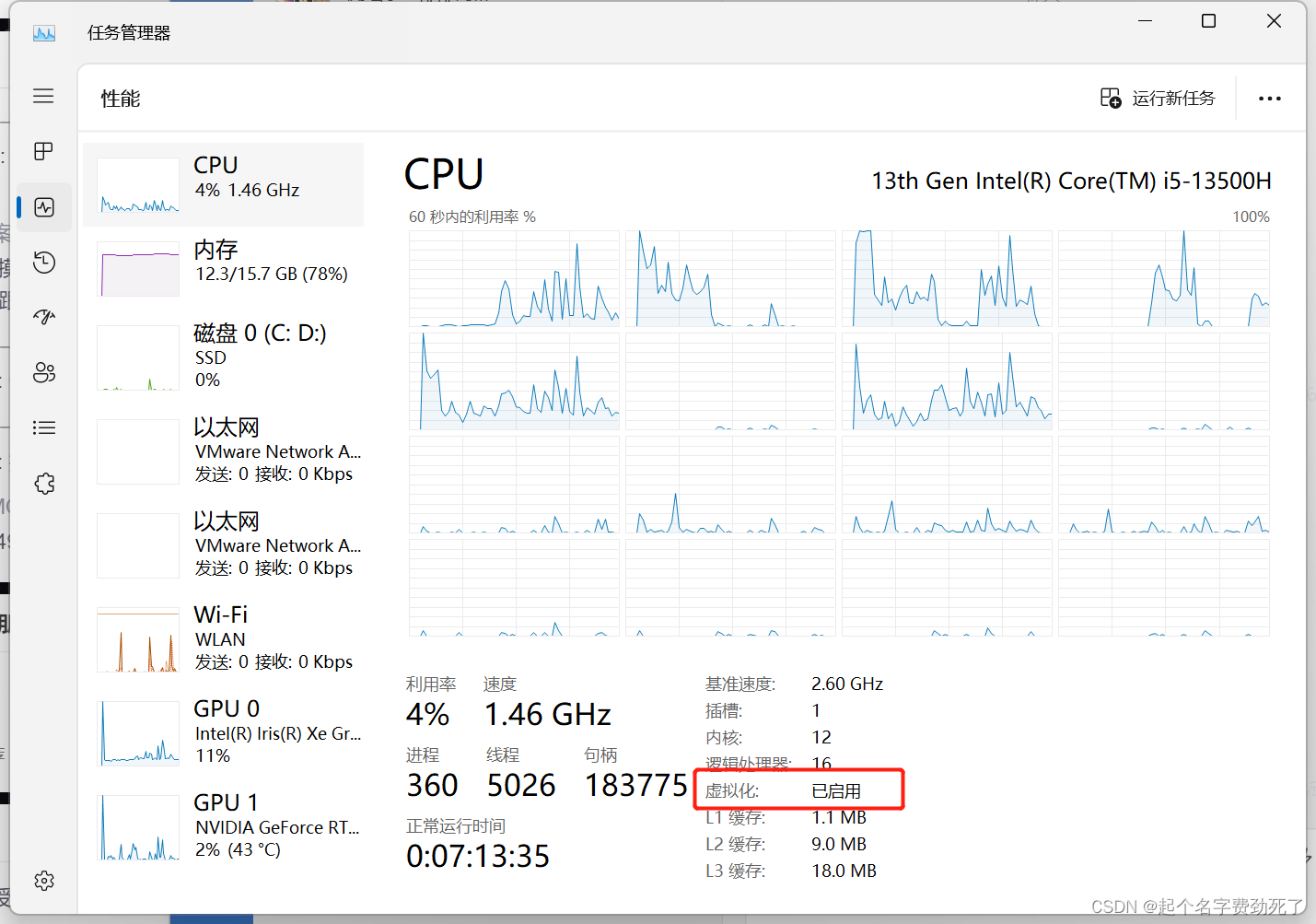
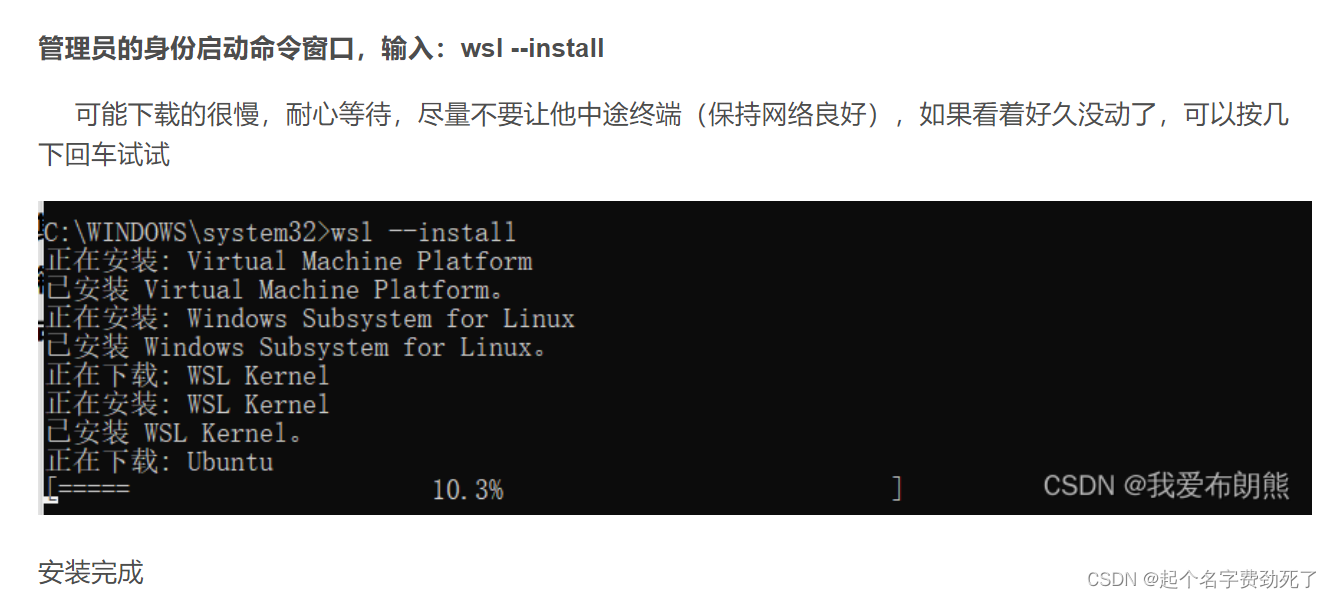
- 安装wsl
下图是截别人的图
- 安装docker成功
(1)桌面会出现Docker Desktop图标,点击进入后界面如下
(2)给docker添加阿里云镜像源,为了后续下载东西更方便
注册、登录阿里云(支付宝、淘宝扫码都可)

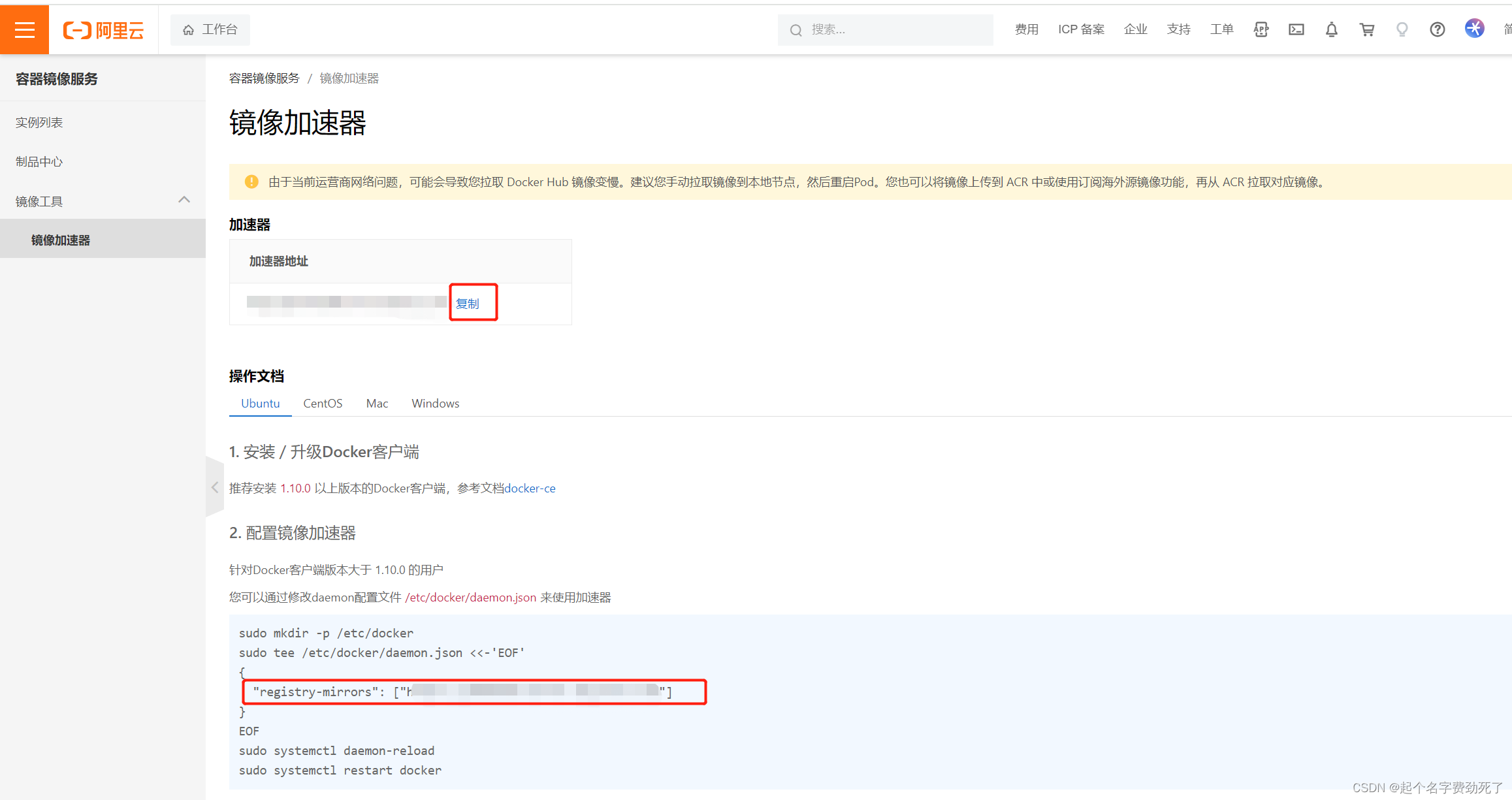
(3)进入后,可以看到自己独立的镜像加速器,是一个网址,最下方一行是给docker配置镜像源的方法,或者直接在Docker Desktop里面,添加那一行命令即可
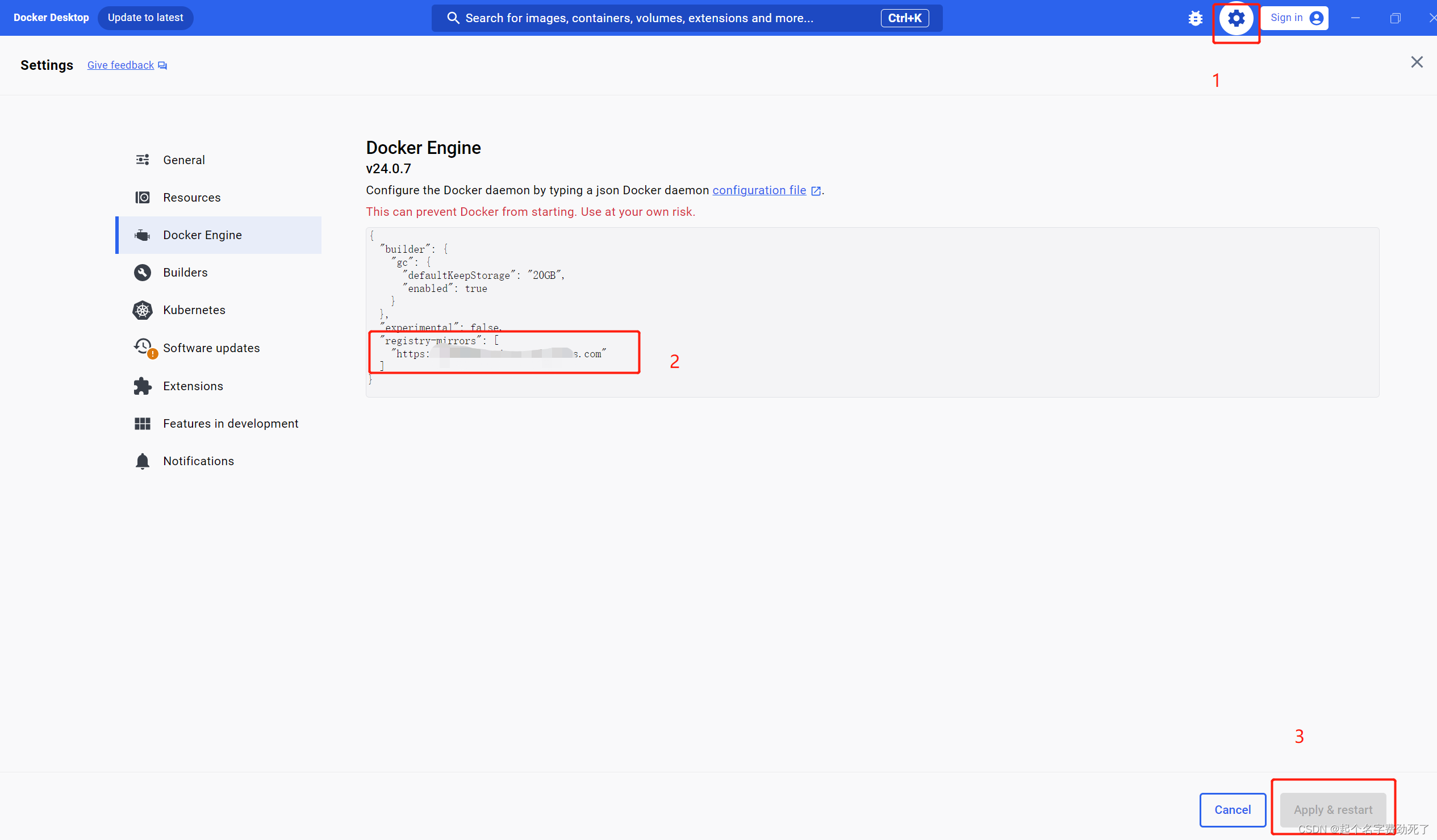
(4)打开Docker Desktop ,点击设置,Docker Engine,添加上图中的代码到窗口中,点击应用和重启按钮即可
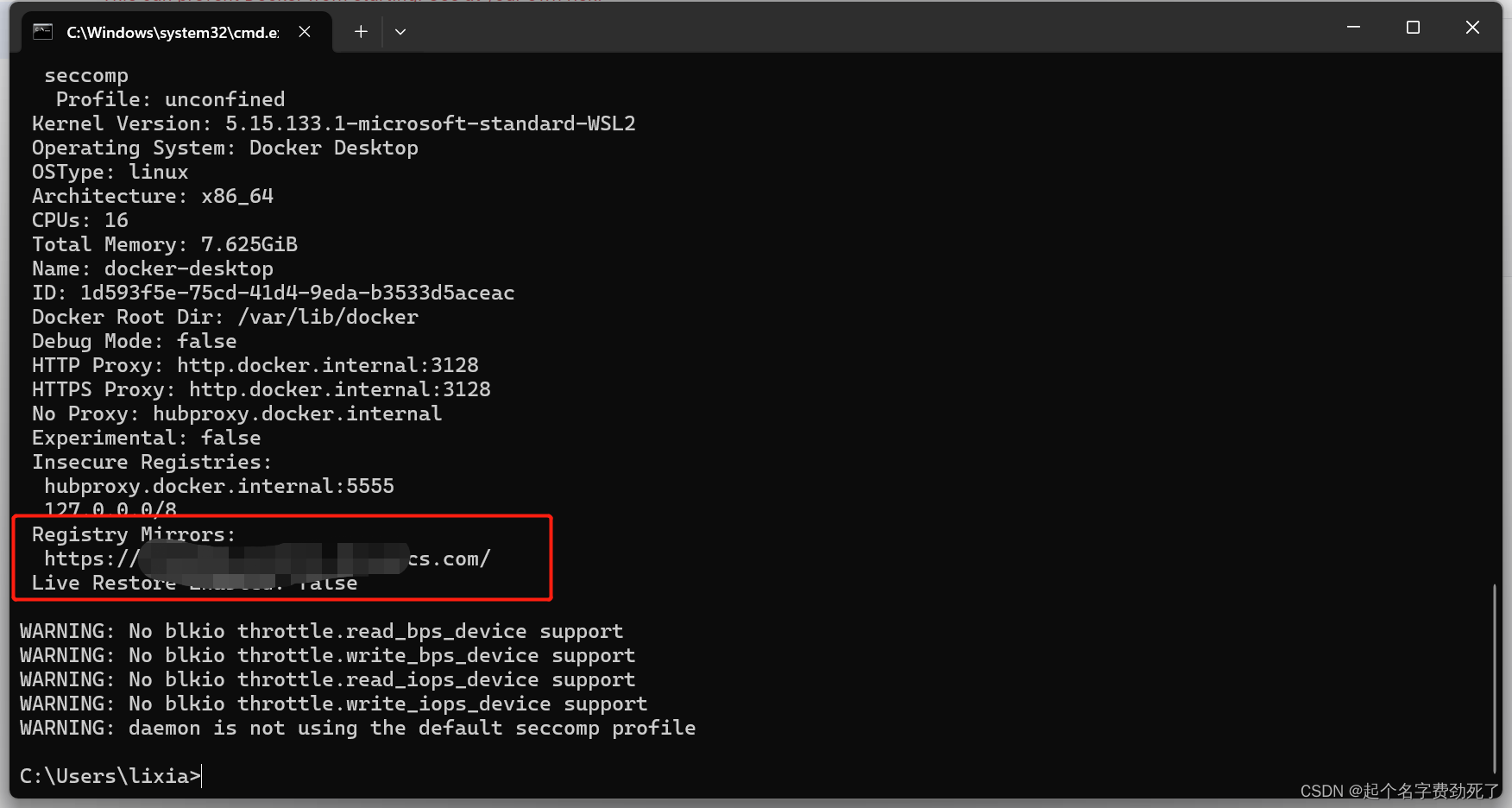
(5)win+R,打开命令行,输入docker info,查看是否应用成功
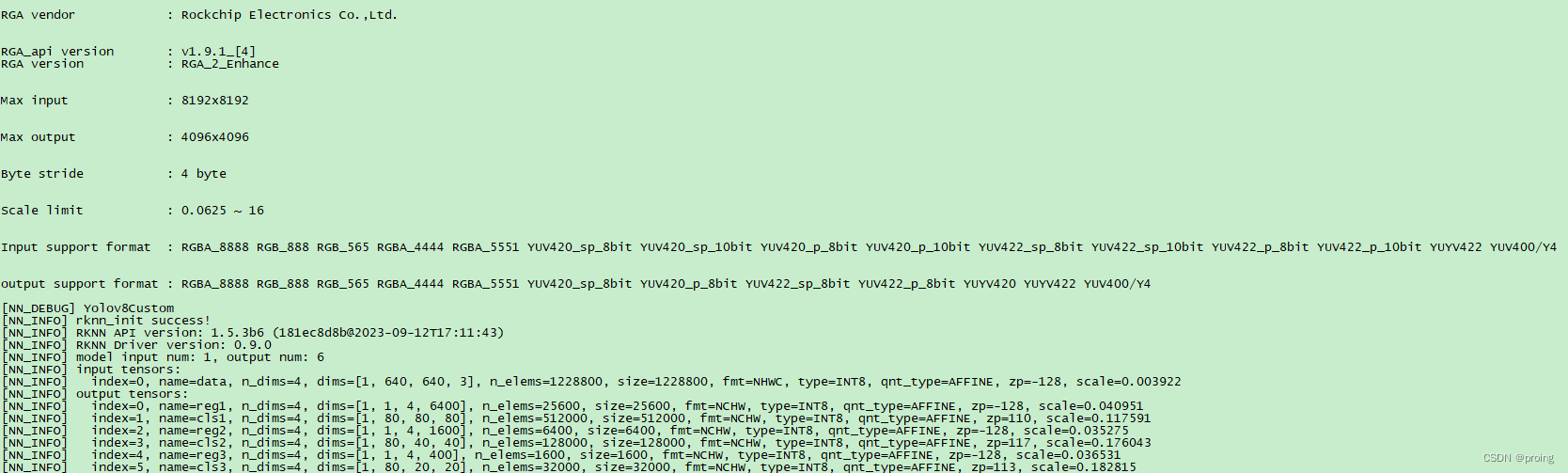
2.安装tensorflow/serving服务
1.docker 拉取tensorflow/serving服务
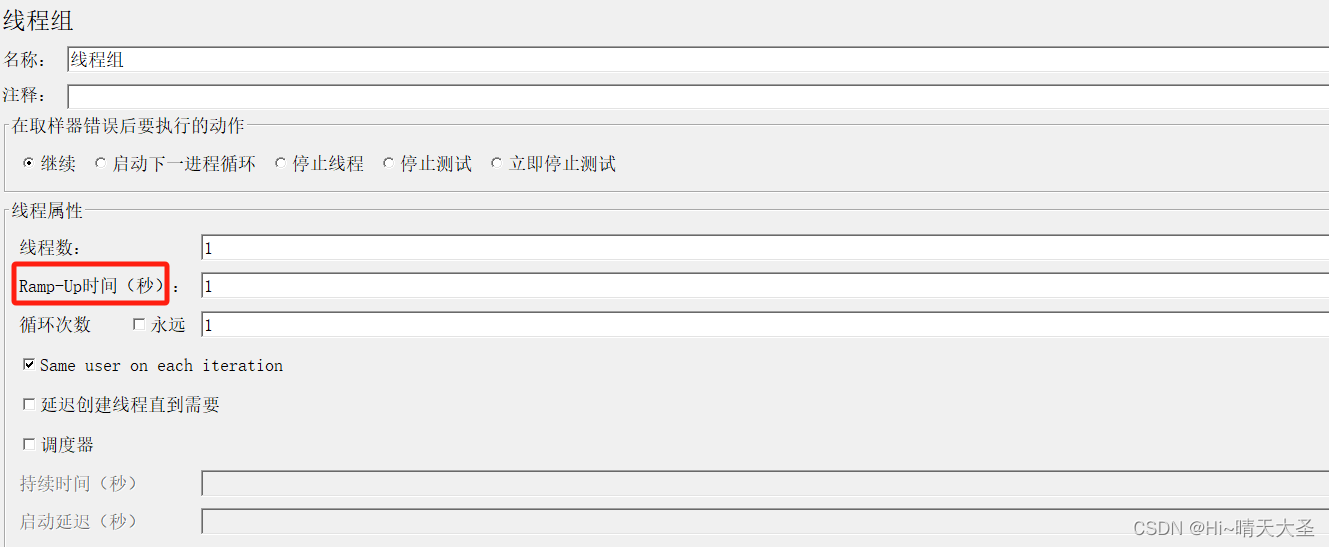
安装tensorflow 2.6.0的GPU服务
docker pull tensorflow/serving:2.6.0-gpu
安装tensorflow 2.6.0的CPU服务
docker pull tensorflow/serving:2.6.0
2.查看是否拉取成功,其中,GPU版本比较大
docker images

3.准备模型测试
1.先拿官方例子测试一下,先下载一下tensorflow/serving2.6.0,然后在该目录结构下,找到 saved_model_half_plus_two_gpu例子,整体拷贝到想要放置的位置
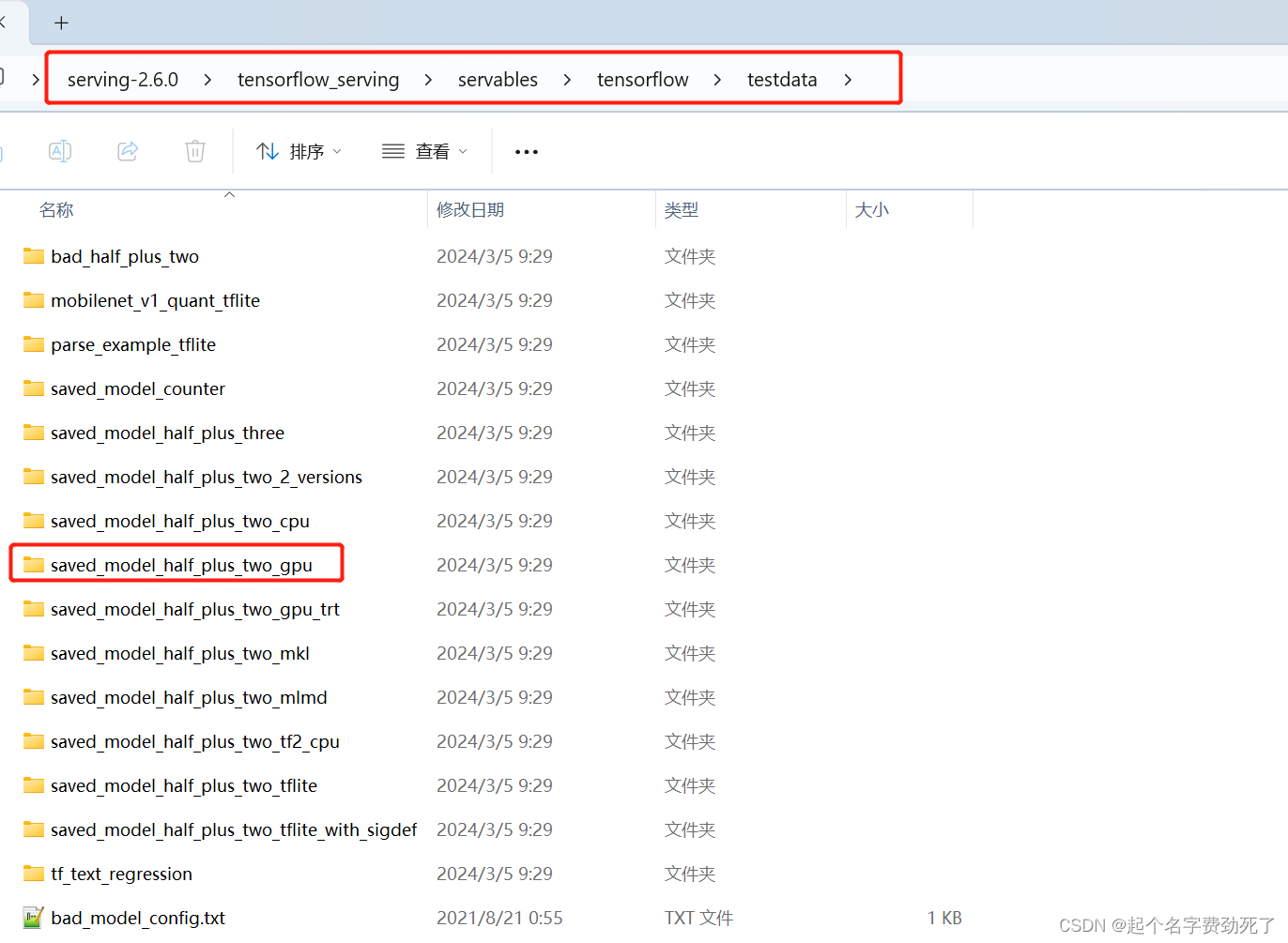
2.开始发布一下该服务
(1)GPU版本,–gpus all 标注了下使用机器的所有GPU,我这边不加提示找不到GPU
注意:
下面的绝对路径表示模型存放的实际路径,最后一个参数项需要指定运行的容器和版本,里面的其他参数照猫画虎吧,很好理解,具体参数项也比较复杂
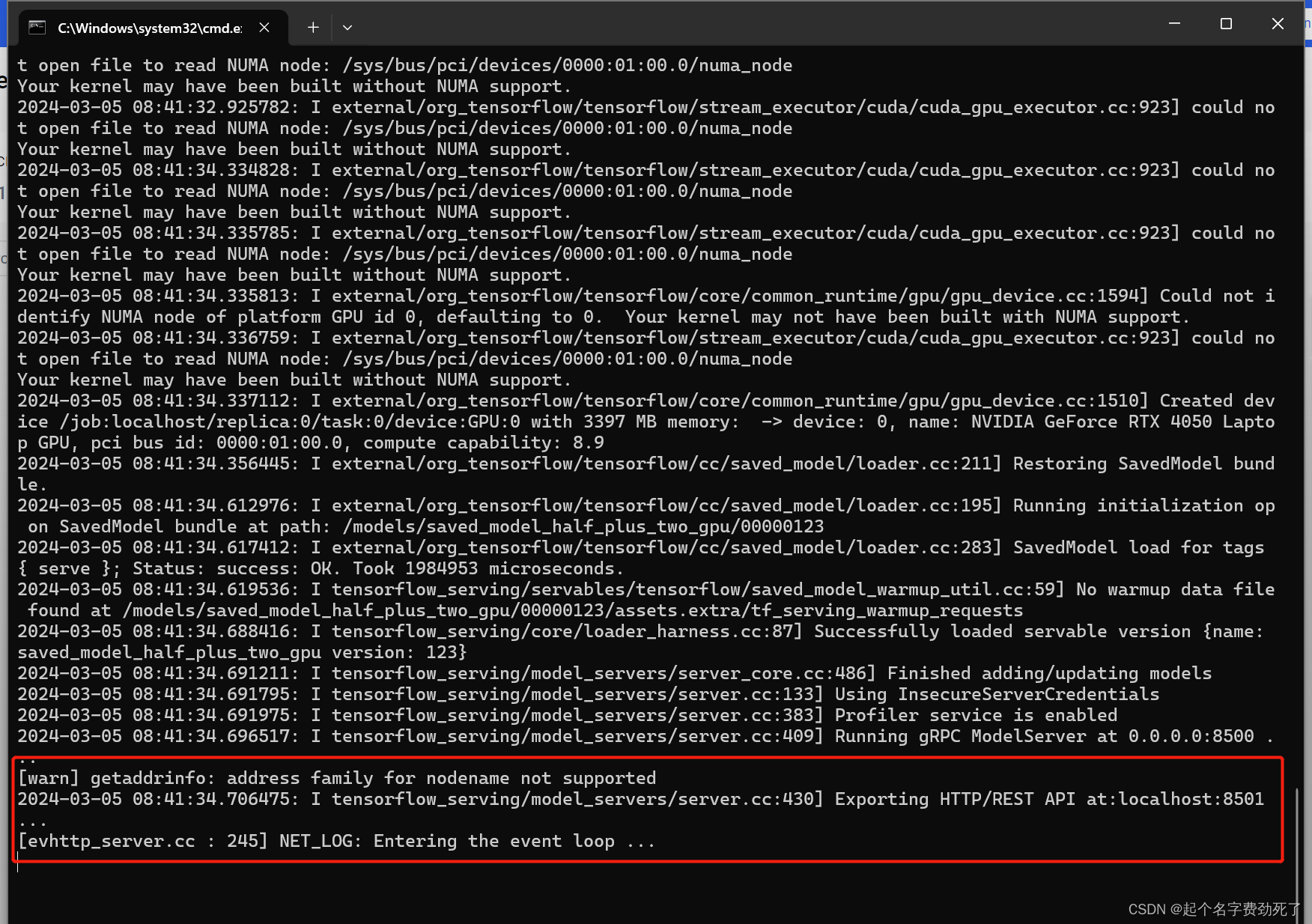
docker run --gpus all -t --rm -p 8501:8501 -v "C:/Users/lixia/.docker/tf_serving/saved_model_half_plus_two_gpu:/models/saved_model_half_plus_two_gpu" -e MODEL_NAME=saved_model_half_plus_two_gpu tensorflow/serving:2.6.0-gpu
出现了如下图,则表示发布成功
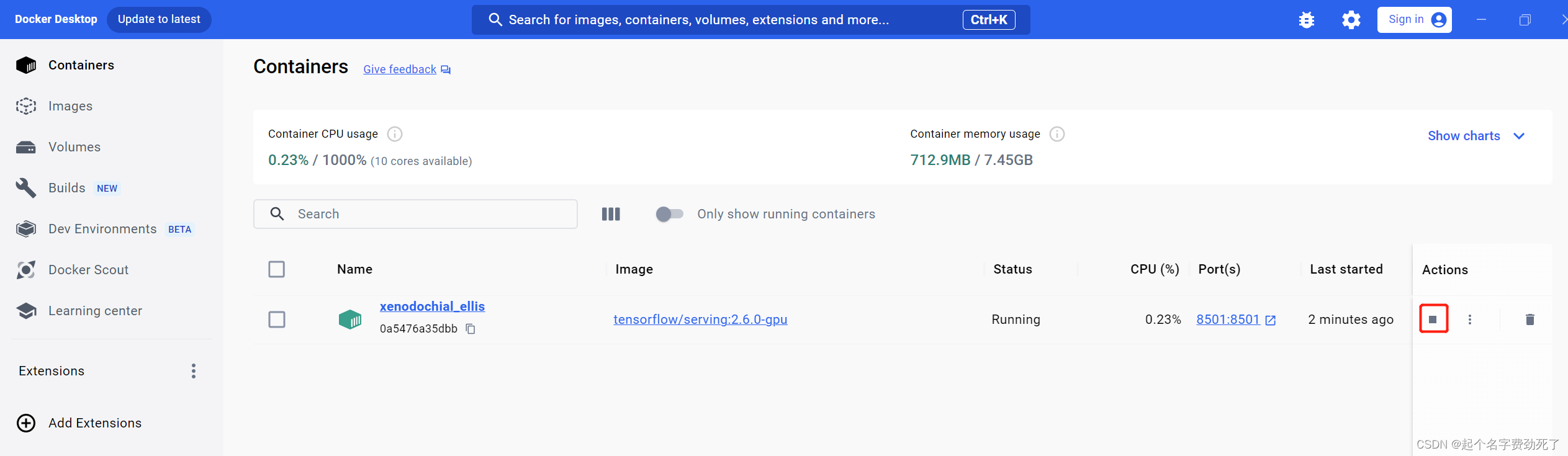
此时,在Docker Desktop中可以看到该服务信息
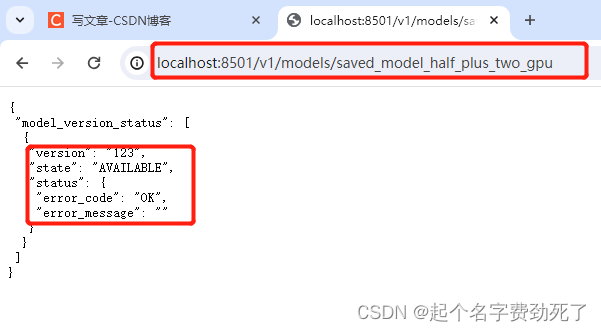
此时,浏览器访问localhost:8501,看是否能连通
http://localhost:8501/v1/models/saved_model_half_plus_two_gpu
出现该信息,则表示可以正常连通和访问了
3.测试调用一下该服务,是否能正常返回结果
#调用官方例子 线性回归小例子 y=0.5*x+2.0
import requests
import jsonurl='http://localhost:8501/v1/models/saved_model_half_plus_two_gpu:predict'
pdata = {"instances":[1.0, 2.0, 3.0]}
param = json.dumps(pdata)
res = requests.post(url, data= param)
print(res.text)
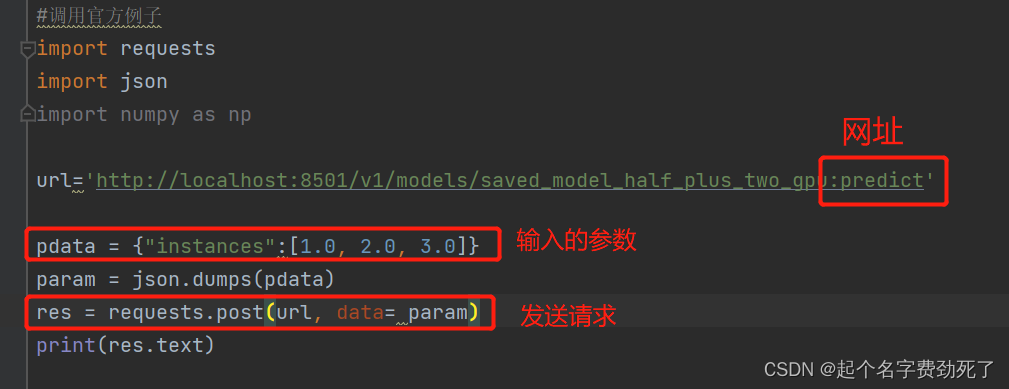
出现该结果表示部署成功

4.服务停止
(1)去Docker Desktop界面端中,手动终止,上面有图
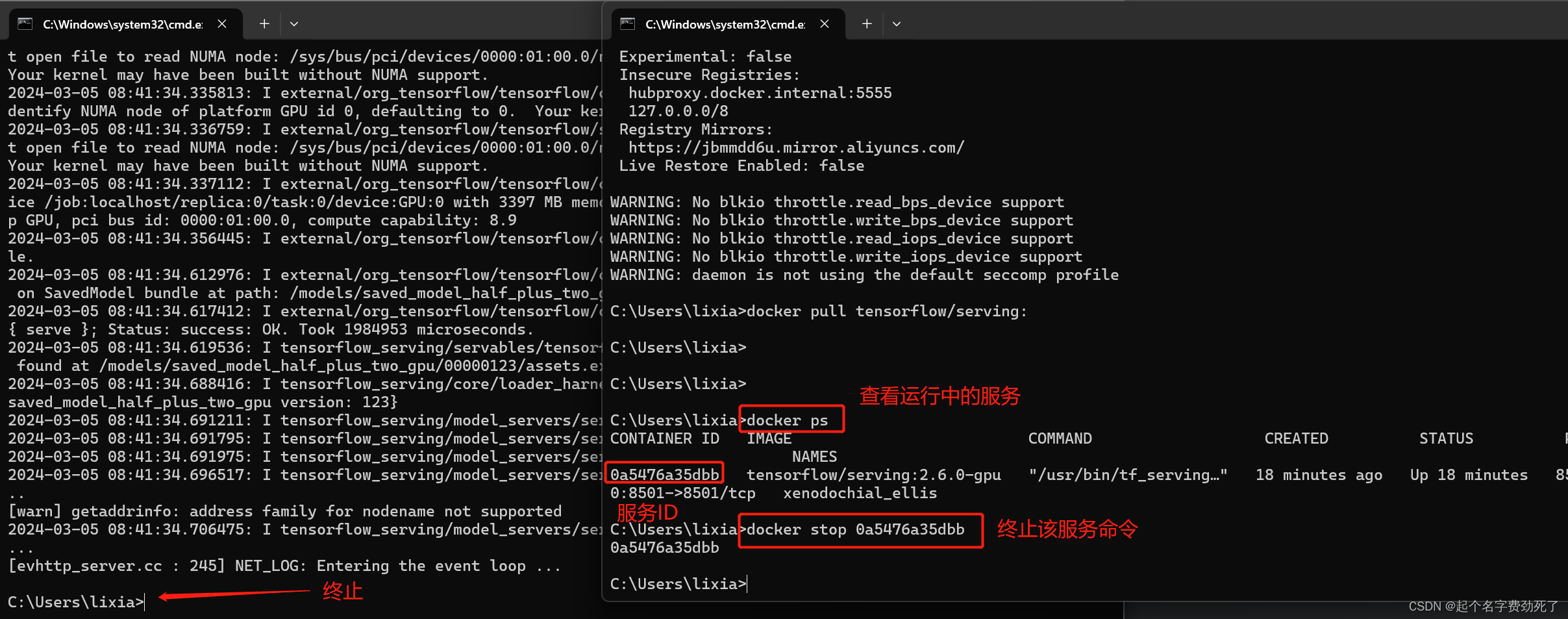
(2)命令行的形式停止
查看运行中的服务
docker ps
终止服务 ****表示ID
docker stop ******
4.准备自己的模型部署测试
准备一个部署练习代码:是否佩戴口罩检测(YOLOv5)
1.首先需要有一个训练好的模型文件,如下图,是我训练好的一个模型

2.将.h5模型转换为.pb模型
直接使用TF自带的函数转(tf.keras.models.save_model),我的模型初始化+参数加载都在yolo.YOLO()中完成了
import tensorflow as tf
import yolodef export_serving_model(path,version=1):"""导出标准的模型格式:param path::return:"""#路径+模型名字+版本export_path = './yolov5_mask_detection/1'#调用模型,指定训练好的.h5文件model = yolo.YOLO()#导出模型tf.keras.models.save_model(model.yolo_model,export_path,overwrite=True,include_optimizer=True,save_format=None,signatures=None,options=None)
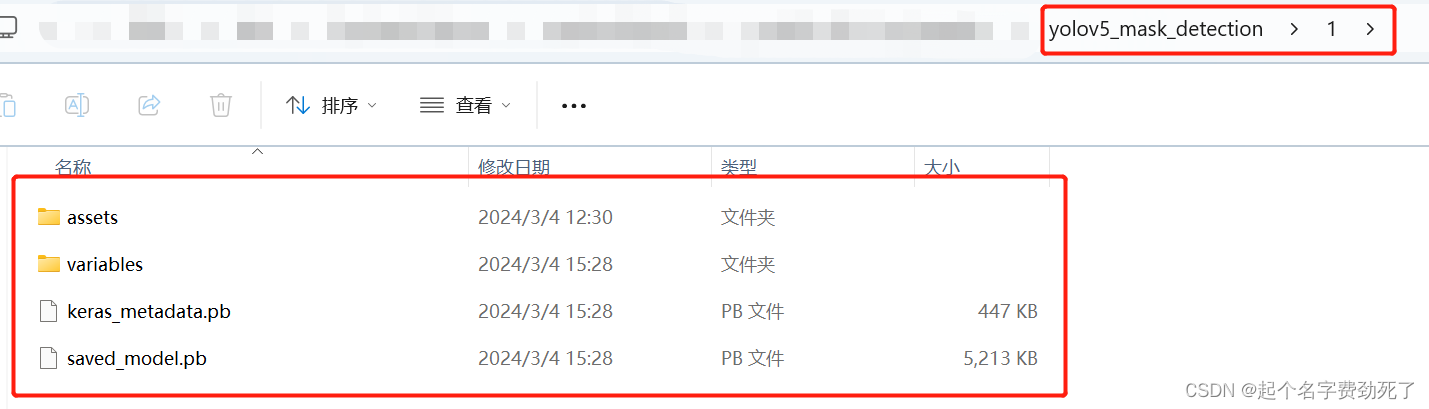
运行完后,会生产出下面文件结构的模型.pb文件,直接拷贝上上级整体目录结构即可yolov5_mask_detection
3.将pb模型发布服务
(1)我直接拷贝到D盘根目录

(2)发布GPU服务
docker run --gpus all -t --rm -p 8501:8501 -v "D:/yolov5_mask_detection:/models/yolov5_mask_detection" -e MODEL_NAME=yolov5_mask_detection tensorflow/serving:2.6.0-gpu
(3)发布CPU服务
直接发布即可,发现GPU模型直接可以在CPU使用
docker run -t --rm -p 8501:8501 -v "D:/yolov5_mask_detection:/models/yolov5_mask_detection" -e MODEL_NAME=yolov5_mask_detection tensorflow/serving:2.6.0
出现如下,表示发布成功

4.调用模型
(1)新建一个裸的python环境,最好和tf用的版本一致,保不齐会出现问题啥的,如果缺少requests 、numpy、PIL库,pip install安装即可;
(2)调用代码前,如果不知道输入输出是啥,需要看下
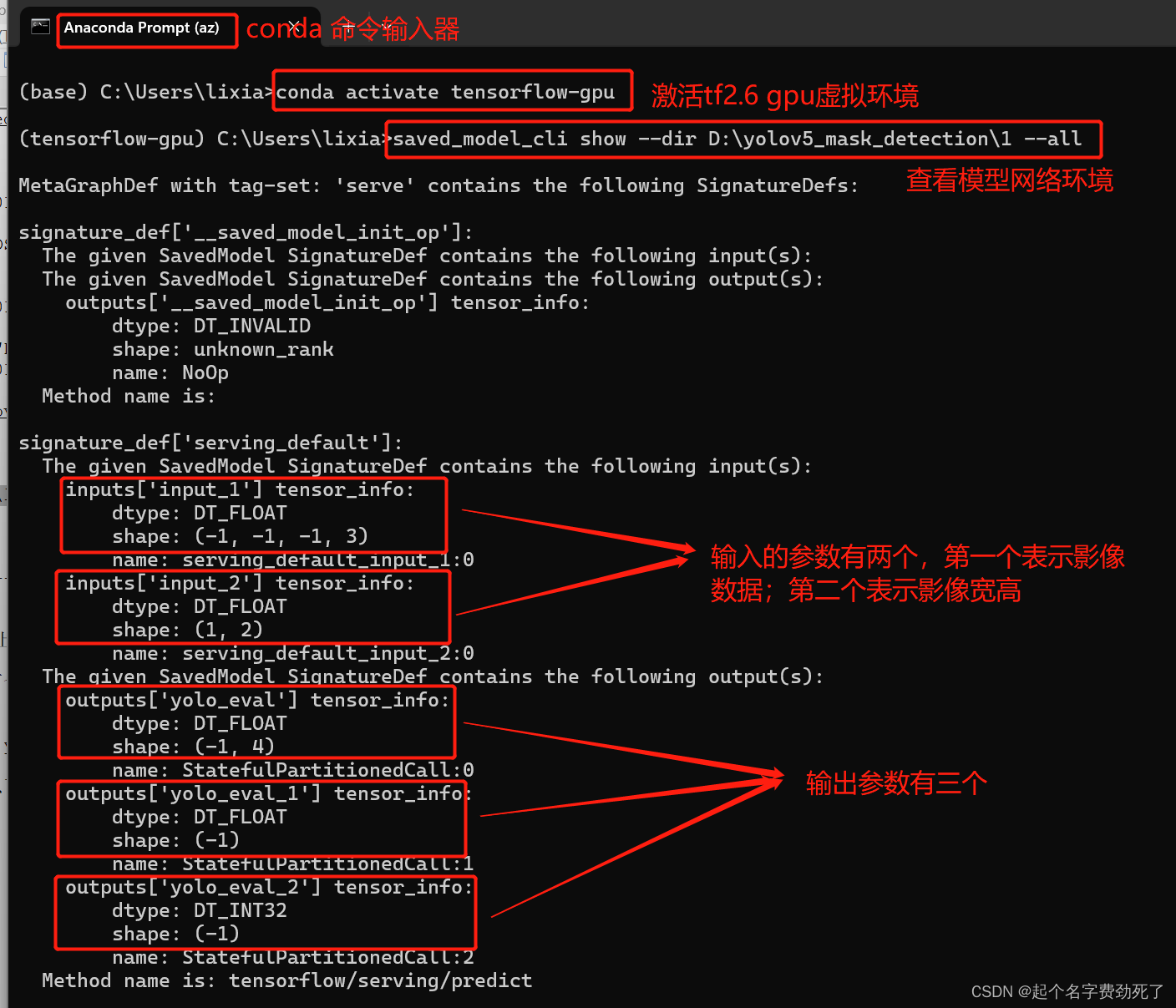
进行conda环境,激活tf虚拟环境,输入命令查看
#打开anaconda命令行输入
conda activate tensorflow-gpu
#产看模型的输入输出和网络结构,绝对路径表示模型存放路径
saved_model_cli show --dir D:\yolov5_mask_detection\1 --all
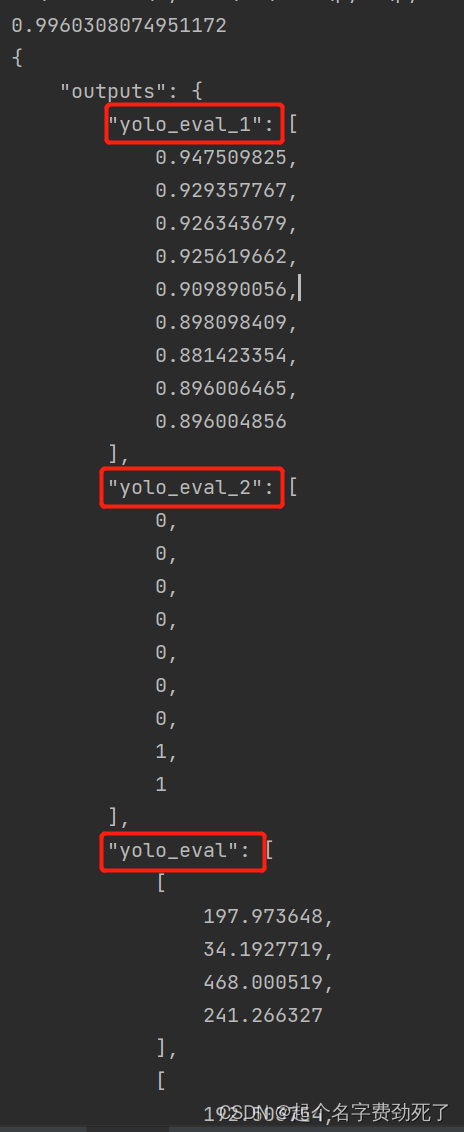
输出参数包含三个,yolo_eval_1表示概率值;yolo_eval_2表示标签值;yolo_eval表示目标检测框
(3)调用代码,核心代码和上述官方例子一致,只不过加了些影像读取+预处理代码
代码如下:
import json
import time
import requests
import numpy as np
from PIL import Image
import ujson#---------------------------------------------------#
# 对输入图像进行resize,模型训练过程也采用了同样的方法
#---------------------------------------------------#
def resize_image(image, size, letterbox_image):iw, ih = image.sizew, h = sizeif letterbox_image:scale = min(w/iw, h/ih)nw = int(iw*scale)nh = int(ih*scale)image = image.resize((nw,nh), Image.BICUBIC)new_image = Image.new('RGB', size, (128,128,128))new_image.paste(image, ((w-nw)//2, (h-nh)//2))else:new_image = image.resize((w, h), Image.BICUBIC)return new_image
#---------------------------------------------------#
# 对输入图像进行归一化,模型训练过程也采用了同样的方法
#---------------------------------------------------#
def preprocess_input(image):image /= 255.0return image
#服务网址
url = 'http://localhost:8501/v1/models/yolov5_mask_detection:predict'
#计时器
tt1 = time.time()
#输入的影像路径
image = Image.open("1.jpg")
#影像需要重采样成640*640
image_data = resize_image(image, (640, 640), True)
#维度扩展,和模型训练保持一致
image_data = np.expand_dims(preprocess_input(np.array(image_data, dtype='float32')), 0)
#原始影像大小,主要是为了将描框放缩到初始影像大小时用到的参数
input_image_shape = np.expand_dims(np.array([image.size[1], image.size[0]], dtype='float32'), 0)
#构造输入的参数类型,有两个参数,第一个表示影像数据1*640*640*3,第二个表示初始影像宽高
# data = json.dumps({
# "signature_name": "serving_default",
# "inputs":
# {"input_1": image_data.tolist(), "input_2": input_image_shape.tolist()}
# })
#换一种json解析方法,速度更快
data = ujson.dumps({"signature_name": "serving_default","inputs":{"input_1": image_data.tolist(), "input_2": input_image_shape.tolist()}})
#构造headers
headers = {"content-type":"application/json"}
#发送请求
r = requests.post(url, data=data, headers=headers)
#计时器终止
tt2 = time.time()
print(tt2-tt1)
#打印返回的结果,这里表示所有框的位置
print(r.text)
注意:
实际测试中发现,大影像转json时,效率偏低,可以直接使用ujson进行替换,其他更优的办法暂时也不过多探讨
**1.安装ujson
pip install ujson

**2.测试记录
import ujson
****tt2 = time.time()# 构造输入的参数类型,有两个参数,第一个表示影像数据1*640*640*3,第二个表示初始影像宽高# -------------------------------------------------------------------------------------data = json.dumps({"signature_name": "serving_default","inputs":{"input_1": image_data.tolist(), "input_2": input_image_shape.tolist()}})tt21 = time.time()print("json方式:",tt21 - tt2)# ------------------------------------------------------------------------------------data = ujson.dumps({"signature_name": "serving_default","inputs":{"input_1": image_data.tolist(), "input_2": input_image_shape.tolist()}})tt22 = time.time()print("ujson方式:",tt22 - tt21)
效率大概提升一倍多,可以一定程度提升推理速度,大数据情况可以考虑,小数据无所谓

直接右键运行,得到结果,表示该程序检测出了9个目标,概率值+标签+目标框像素位置如下,通过解析json,可以得到目标检测结果
(4)我们看下,将检测结果标记到图上后,效果如下:

换个图片试一下

5.将docker环境整体打包到其他电脑测试(2024/03/06补充)
在本机电脑测试通过后,在其他电脑测试一下是否行的通
1.在测试机安装docker
(1)正常安装docker
需要注意的是:
我安装完成后,没有很顺利的打开软件,提示“docker machine stop”,经过查询说是没有关闭Hyper-V(控制面板->程序->启动和关闭windos功能),但是我的测试机压根没有这个选项,运行以下脚本安装即可,但是可能要下载东西,也不知道离线安装可咋弄,脚本如下(新建任意.bat文件,以管理员权限安装即可,安装后重启):
pushd "%~dp0"
dir /b %SystemRoot%\servicing\Packages\*Hyper-V*.mum >hyper-v.txt
for /f %%i in ('findstr /i . hyper-v.txt 2^>nul') do dism /online /norestart /add-package:"%SystemRoot%\servicing\Packages\%%i"
del hyper-v.txt
Dism /online /enable-feature /featurename:Microsoft-Hyper-V-All /LimitAccess /ALL
测试机docker启动正常
(2)将源机器中的tensorflow/serving:2.6.0镜像打包出来,docker命令如下:
#将镜像源打包出来 save后面的两个参数分别表示镜像源名称+版本和保存出的.tar包名称,或者指定输出目录
docker save tensorflow/serving:2.6.0 > tensorflow_serving.tar
docker save tensorflow/serving:2.6.0 > D:/tensorflow_serving.tar
打包后的结果

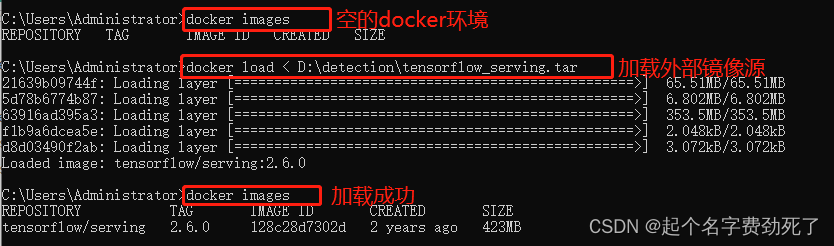
(3)在测试机的docker环境中加载该文件,命令如下:
#把指定位置的镜像源加载进来
docker load < D:\detection\tensorflow_serving.tar
2.将程序打包,或者在新机器安装python环境,我选择简单的方法,直接打包源程序到exe,看是否能正常调用
(1)将测试代码使用pyinstaller插件进行打包,打包命令很简单,打包后的结果在统计目录dist文件夹下
#安装
pip install pyinstaller -i 清华源地址
#打包
pyinstaller main.py

3.在测试机启动服务
(1)将模型文件整体拷贝到测试机的某个位置,如还是D盘
(2)启动命令和上面一致,我拷贝下来
docker run -t --rm -p 8501:8501 -v "D:/detection/yolov5_mask_detection:/models/yolov5_mask_detection" -e MODEL_NAME=yolov5_mask_detection tensorflow/serving:2.6.0
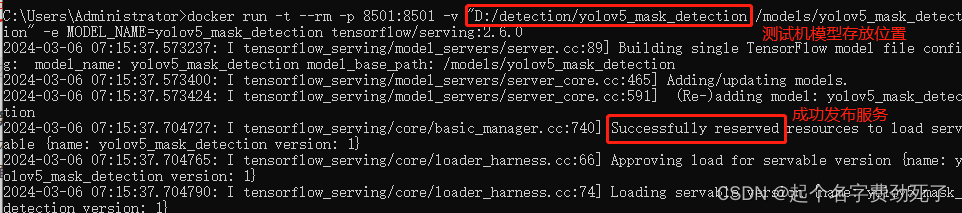
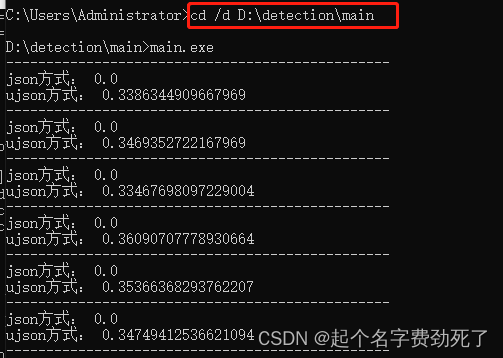
(3)运行测试exe,看是否正常打印结果,代码还是口罩检测,只不过我输出的信息只显示了ujson方式将影像数据整理为json格式的耗时;
**注意:**实际使用过程中,可以给exe传入一个json参数文件,做输入参数和输出参数的交互文件,外部再包一层解析json和可视化的程序
6.linux部署测试(实际使用中,大部分应该都是linux环境)
发现很方便,部署步骤和windows一模一样,linux环境下,安装docker,加载镜像,发布服务,调用,直接用window那一套东西就行
(1)准备一个linux环境,我使用的是centos7.5,虚拟机,保证本地和虚拟机环境可以互通(可以ping通网址)
#查看ip地址
ip addr
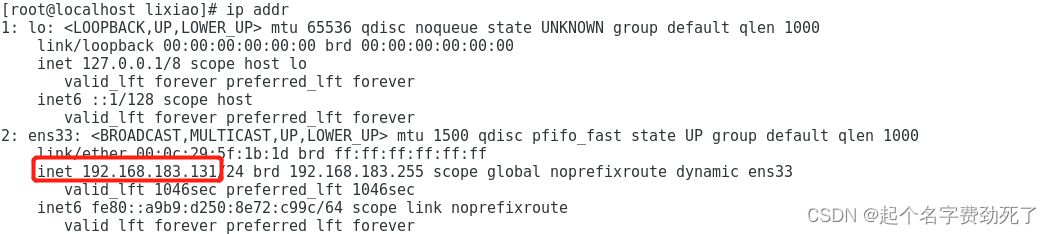
本地和虚拟机可以互通

(2)安装docker环境,如果有网络的话,直接yum命令安装即可,离线安装也可,需要查对应教程,我使用前者
#更新源,看情况吧
yum update
# 不指定版本安装,默认安装最新版
yum install -y docker-ce
# 指定版本安装
yum -y install docker-ce-20.10.6-3.el7
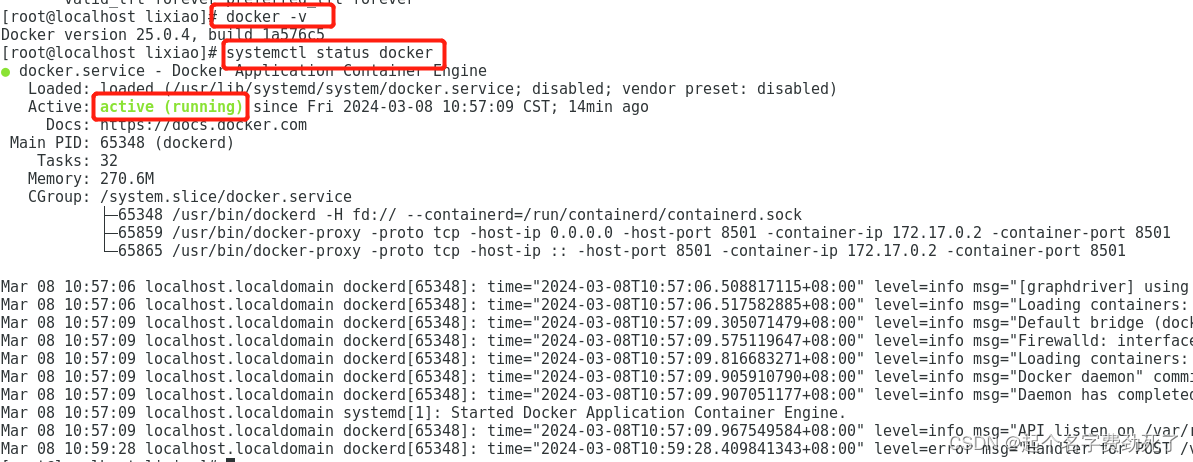
#启动docker
systemctl start docker
#查看docker状态systemctl status docker
(3)加载镜像+把模型文件拷贝到linux,直接用window那一套东西,然后启动服务
#加载镜像
docker load < /home/lixiao/software/AImodel/tensorflow_serving.tar
#查看当前docker环境下的镜像
docker images
#启动服务:模型存放路径要改改
docker run -t --rm -p 8501:8501 -v "D:/detection/yolov5_mask_detection:/models/yolov5_mask_detection" -e MODEL_NAME=yolov5_mask_detection tensorflow/serving:2.6.0

当前正在运行的服务docker ps

查看是否能正常访问http://localhost:8501/v1/models/yolov5_mask_detection
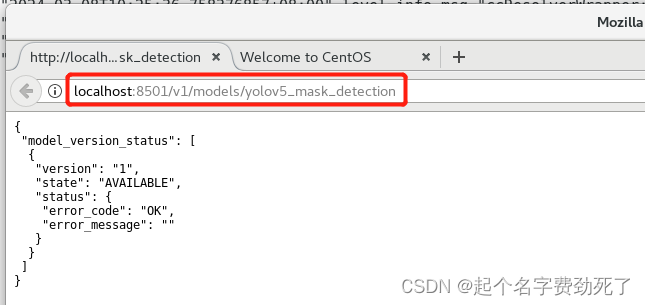
(4)本地调用,需要注意的是localhost需要改成实际的虚拟机地址

用上面的代码测试,可以测试通过,至此,完成linux+docker下的tensorflow模型部署
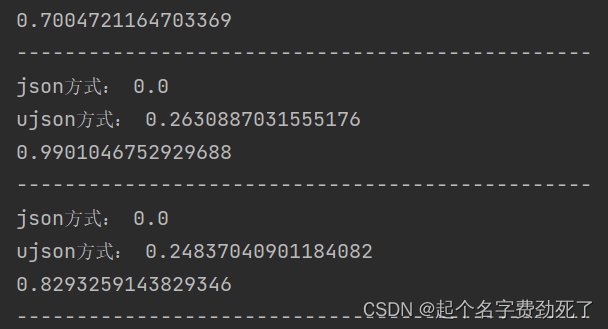
问题1:linux下部署的模型,post请求时,耗时比window下部署的情况要慢的多,差不多三四倍吧
原因1:可能是虚拟机和本机的网络问题,有裸机实体机+高速网络可能就会好点了
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++分割线++++++++++++++++++++++++++++++++++++++++++++
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
至此,深度学习tensorflow的部署先告一段落,目前没有项目需求,只是练手阶段,如果遇到新问题还会继续补充在后续…
7.一些备忘记录
1.conda 环境整体打包移植
//----------------------------------------------------------------------------------------------------------
conda 环境打包到其他电脑要将 Conda 环境打包并迁移到其他电脑上使用,可以按照以下步骤进行操作:导出 Conda 环境: 在源电脑上使用以下命令导出 Conda 环境的配置信息到一个 YAML 文件中:conda env export > environment.yml
复制环境文件: 将生成的 environment.yml 文件复制到目标电脑上。创建 Conda 环境: 在目标电脑上使用以下命令根据导出的环境文件创建相同的 Conda 环境:conda env create -f environment.yml
激活环境: 激活新创建的 Conda 环境:conda activate <environment_name>