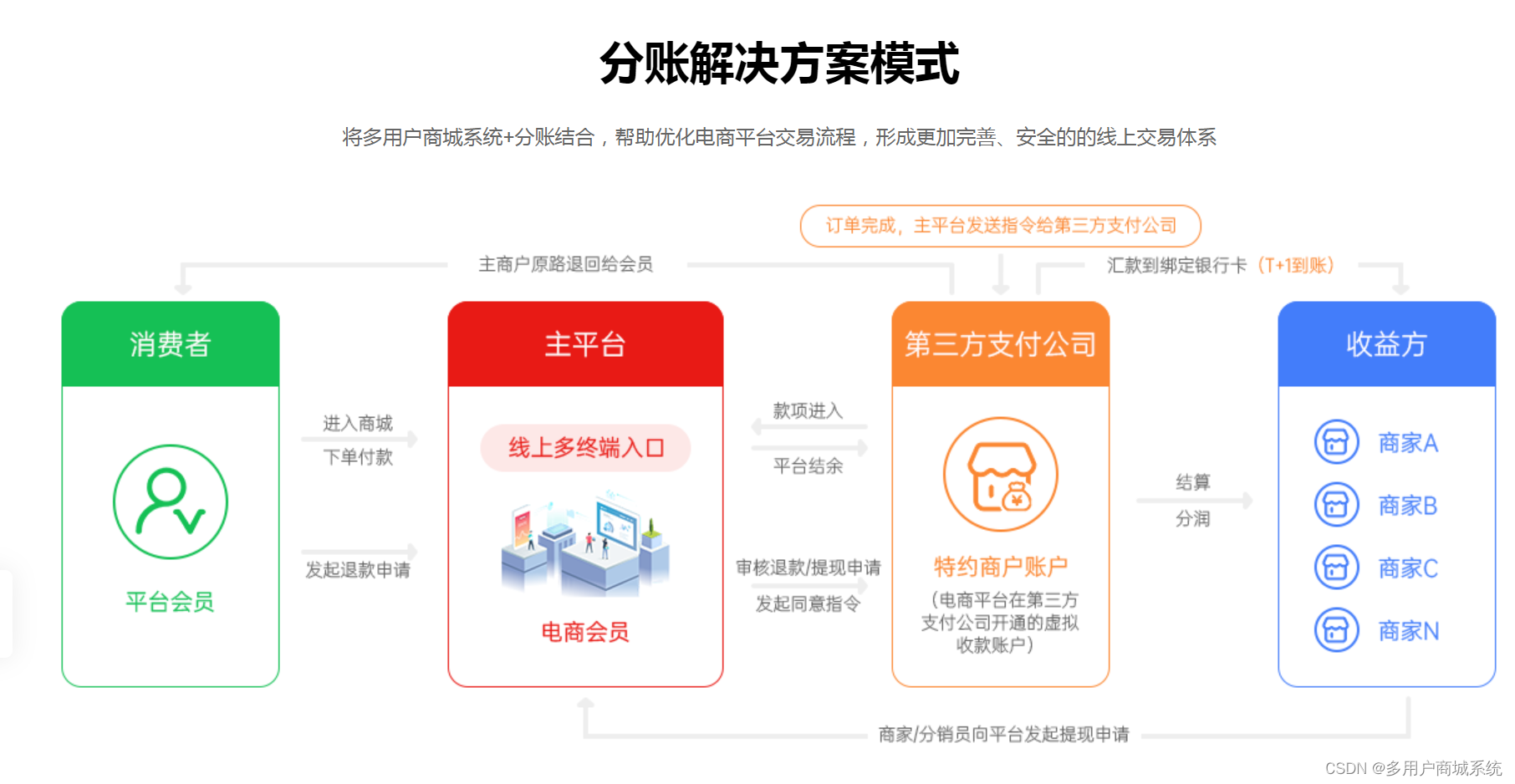
AI视野·今日CS.NLP 自然语言处理论文速览
Thu, 7 Mar 2024
Totally 52 papers
👉上期速览✈更多精彩请移步主页

Daily Computation and Language Papers
| The Heuristic Core: Understanding Subnetwork Generalization in Pretrained Language Models Authors Adithya Bhaskar, Dan Friedman, Danqi Chen 先前的工作发现,使用不同随机种子进行微调的预训练语言模型 LM 可以实现相似的领域性能,但在句法泛化测试中的泛化能力不同。在这项工作中,我们表明,即使在单个模型中,我们也可以找到在域中表现相似但概括却截然不同的多个子网络。为了更好地理解这些现象,我们研究是否可以从竞争子网络的角度来理解它们,该模型最初代表各种不同的算法,对应于不同的子网络,当它最终收敛到一个子网络时,就会发生泛化。这种解释已用于解释简单算法任务中的泛化。我们没有找到竞争的子网络,而是发现所有子网络无论是否泛化都共享一组注意力头,我们将其称为启发式核心。进一步的分析表明,这些注意力头在训练的早期就出现并计算浅层的、非泛化的特征。该模型通过合并额外的注意力头来学习泛化,这取决于启发式头的输出来计算更高级别的特征。 |
| Did Translation Models Get More Robust Without Anyone Even Noticing? Authors Ben Peters, Andr F.T. Martins 神经机器翻译 MT 模型在各种设置中都取得了很好的结果,但人们普遍认为它们对噪声输入高度敏感,例如拼写错误、缩写和其他格式问题。在本文中,我们根据最近应用于机器翻译的多语言机器翻译模型和大型语言模型法学硕士重新审视了这一见解。令人有些惊讶的是,我们通过对照实验表明,这些模型对多种噪声的鲁棒性比以前的模型要强得多,即使它们在干净数据上的表现相似。这是值得注意的,因为尽管法学硕士比过去的模型有更多的参数和更复杂的训练过程,但我们考虑的开放模型都没有使用任何专门设计来鼓励鲁棒性的技术。接下来,我们表明社交媒体翻译实验也存在类似的趋势,法学硕士对社交媒体文本更加稳健。我们分析了可以使用源校正技术来减轻噪声影响的情况。 |
| A Measure for Transparent Comparison of Linguistic Diversity in Multilingual NLP Data Sets Authors Tanja Samardzic, Ximena Gutierrez, Christian Bentz, Steven Moran, Olga Pelloni 越来越多地创建类型多样化的基准来跟踪多语言 NLP 所取得的进展。这些数据集的语言多样性通常以样本中包含的语言或语系的数量来衡量,但这种衡量方法不考虑所包含语言的结构属性。在本文中,我们建议根据参考语言样本评估数据集的语言多样性,作为从长远来看最大化语言多样性的手段。我们将语言表示为特征集,并应用适合比较度量集的 Jaccard 索引版本。除了从类型数据库中提取的特征之外,我们还提出了一种基于自动文本的度量,它可以用作克服手动收集的特征中众所周知的数据稀疏问题的方法。我们的多样性得分可以根据语言特征进行解释,并且可以识别数据集中未表示的语言类型。使用我们的方法,我们分析了一系列流行的多语言数据集 UD、Bible100、mBERT、XTREME、XGLUE、XNLI、XCOPA、TyDiQA、XQuAD。 |
| From One to Many: Expanding the Scope of Toxicity Mitigation in Language Models Authors Luiza Pozzobon, Patrick Lewis, Sara Hooker, Beyza Ermis 迄今为止,语言模型中的毒性缓解几乎完全集中在单一语言设置上。随着语言模型具备多语言功能,我们的安全措施保持同步至关重要。认识到这一研究差距,我们的方法扩大了传统毒性缓解的范围,以解决多种语言带来的复杂性。在缺乏足够的跨语言注释数据集的情况下,我们使用翻译后的数据来评估和增强我们的缓解技术。我们还在静态和连续毒性缓解场景下将微调缓解方法与检索增强技术进行比较。这使我们能够检查翻译质量和跨语言迁移对毒性缓解的影响。我们还探讨了模型大小和数据量如何影响这些缓解措施的成功。我们的研究涵盖九种语言,代表了广泛的语言家族和资源可用性水平,范围从高级到中级资源语言。通过全面的实验,我们深入了解了多语言毒性缓解的复杂性,提供了宝贵的见解,并为这个日益重要的领域的未来研究铺平了道路。 |
| FaaF: Facts as a Function for the evaluation of RAG systems Authors Vasileios Katranidis, Gabor Barany 来自参考源的事实回忆对于评估检索增强生成 RAG 系统的性能至关重要,因为它直接探究检索和生成的质量。然而,可靠、高效地进行这种评估仍然是一个挑战。最近的工作重点是通过提示语言模型 LM 评估器进行事实验证,但是我们证明这些方法在存在不完整或不准确信息的情况下是不可靠的。我们引入了 Facts as a Function FaaF ,这是一种新的事实验证方法,利用 LM 的函数调用能力和 RAG 事实召回评估框架。 |
| SaulLM-7B: A pioneering Large Language Model for Law Authors Pierre Colombo, Telmo Pessoa Pires, Malik Boudiaf, Dominic Culver, Rui Melo, Caio Corro, Andre F. T. Martins, Fabrizio Esposito, Vera L cia Raposo, Sofia Morgado, Michael Desa 在本文中,我们介绍了 SaulLM 7B,一个为法律领域量身定制的大型语言模型 LLM。 SaulLM 7B 拥有 70 亿个参数,是第一个专门为法律文本理解和生成而设计的法学硕士。 SaulLM 7B 以 Mistral 7B 架构为基础,在包含超过 300 亿个代币的英语法律语料库上进行训练。 SaulLM 7B 在理解和处理法律文件方面表现出最先进的能力。此外,我们提出了一种新颖的教学微调方法,该方法利用法律数据集进一步增强 SaulLM 7B 在法律任务中的性能。 |
| Impoverished Language Technology: The Lack of (Social) Class in NLP Authors Amanda Cercas Curry, Zeerak Talat, Dirk Hovy 自 Labov 1964 年关于语言社会分层的基础性工作以来,语言学一直致力于理解社会人口因素与语言产生和感知之间的关系。尽管有大量证据表明社会人口因素与语言产生之间存在显着关系,但在 NLP 技术背景下研究的这些因素相对较少。虽然年龄和性别都得到了很好的涵盖,但拉博夫最初的目标——社会经济阶层——基本上没有被提及。我们调查了现有的自然语言处理 NLP 文献,发现只有 20 篇论文甚至提到了社会经济地位。然而,这些论文中的大多数除了收集注释者人口统计信息之外,并不涉及课堂。 |
| Learning to Decode Collaboratively with Multiple Language Models Authors Shannon Zejiang Shen, Hunter Lang, Bailin Wang, Yoon Kim, David Sontag 我们提出了一种方法来教导多个大型语言模型 LLM 通过在令牌级别交错它们的代来进行协作。我们将哪个 LLM 生成下一个标记的决策建模为潜在变量。通过优化潜变量模型下训练集的边际似然,基础 LLM 自动学习何时生成自身以及何时调用辅助语言模型之一来生成,所有这些都无需直接监督。解码过程中的令牌级协作允许以针对当前特定任务的方式融合每个模型的专业知识。我们的协作解码在跨领域设置中特别有用,其中通才基础法学硕士学习调用领域专家模型。在指令遵循、特定领域的 QA 和推理任务方面,我们表明联合系统的性能超过了单个模型的性能。通过对学习到的潜在决策进行定性分析,我们展示了用我们的方法训练的模型表现出几种有趣的协作模式,例如模板填充。 |
| On the Origins of Linear Representations in Large Language Models Authors Yibo Jiang, Goutham Rajendran, Pradeep Ravikumar, Bryon Aragam, Victor Veitch 最近的研究表明,高级语义概念是在大型语言模型的表示空间中线性编码的。在这项工作中,我们研究了这种线性表示的起源。为此,我们引入了一个简单的潜变量模型来抽象和形式化下一个令牌预测的概念动态。我们使用这种形式主义来表明,具有交叉熵的下一个令牌预测目标softmax和梯度下降的隐式偏差共同促进了概念的线性表示。实验表明,当从匹配潜变量模型的数据中学习时,会出现线性表示,证实这种简单的结构已经足以产生线性表示。 |
| KIWI: A Dataset of Knowledge-Intensive Writing Instructions for Answering Research Questions Authors Fangyuan Xu, Kyle Lo, Luca Soldaini, Bailey Kuehl, Eunsol Choi, David Wadden 适合遵循用户指令的大型语言模型法学硕士现在被广泛部署为对话代理。在这项工作中,我们研究了一项日益常见的指令,该指令遵循提供写作帮助以撰写长格式答案的任务。为了评估当前法学硕士在这项任务上的能力,我们构建了 KIWI,这是科学领域知识密集型写作指令的数据集。给定一个研究问题、一个初始模型生成的答案和一组相关论文,专家注释者会迭代地向模型发出指令,以修改和改进其答案。我们从与三位最先进的法学硕士进行的 234 次互动会话中收集了 1,260 次互动回合。每轮包括用户指令、模型响应以及模型响应的人工评估。通过对收集到的答案进行详细分析,我们发现所有模型都难以将新信息纳入现有答案,并执行精确且明确的编辑。此外,我们发现模型很难判断其输出是否成功遵循用户指令,其准确度至少比人类的一致性低 10 个百分点。 |
| X-Shot: A Unified System to Handle Frequent, Few-shot and Zero-shot Learning Simultaneously in Classification Authors Hanzi Xu, Muhao Chen, Lifu Huang, Slobodan Vucetic, Wenpeng Yin 近年来,很少镜头学习和零镜头学习(即学习用有限的注释实例来预测标签)引起了人们的广泛关注。传统方法通常将具有丰富实例、少量镜头和零镜头学习的频繁镜头标签视为不同的挑战,仅针对其中一种场景优化系统。然而,在现实世界中,标签的出现情况差异很大。其中一些可能会出现数千次,而另一些可能只会偶尔出现或根本不出现。对于实际部署来说,系统能够适应任何标签的出现至关重要。我们引入了一种新颖的分类挑战 X shot,反映了现实世界的背景,其中频率镜头、少量镜头和零镜头标签在没有预定义限制的情况下同时出现。这里,X 的范围可以从 0 到正无穷大。 X shot 的关键在于开放域泛化和设计一个足够通用的系统来管理各种标签场景。为了解决 X shot,我们提出了基于指令跟随的 BinBin 二进制推理,通过指令跟随利用来自大量 NLP 任务的间接监督,并得到大型语言模型提供的弱监督的支持。 BinBin 在跨多个领域的三个基准数据集上超越了之前最先进的技术。 |
| Designing Informative Metrics for Few-Shot Example Selection Authors Rishabh Adiga, Lakshminarayanan Subramanian, Varun Chandrasekaran 当提供正确格式的示例时,预训练的语言模型 PLM 表现出了出色的少数镜头学习能力。然而,选择最好的例子仍然是一个开放的挑战。我们提出了一种用于序列标记任务的基于复杂性的提示选择方法。这种方法避免了训练用于选择示例的专用模型,而是使用某些度量来调整测试句子和示例的句法语义复杂性。我们使用句子和单词级别的指标来将示例的复杂性与正在考虑的测试句子相匹配。我们的结果表明,我们的方法从 PLM 中提取了更高的性能,它在少量 NER 上实现了最先进的性能,在 GPT 4 的 CoNLL2003 数据集上的 F1 分数绝对提高了 5 个。我们还看到 F1 Acc 的大幅提升,高达 28.85 分。 |
| Emojinize : Enriching Any Text with Emoji Translations Authors Lars Henning Klein, Roland Aydin, Robert West 表情符号在书面交流、网络及其他领域已经变得无处不在。它们可以强调或澄清情绪,为对话添加细节,或者只是起到装饰作用。然而,这种随意的使用仅仅触及了表情符号表达能力的表面。为了进一步释放这种力量,我们提出了 Emojinize,一种无需人工输入即可将任意文本短语翻译为一个或多个表情符号序列的方法。通过利用大型语言模型的力量,Emojinize 可以通过基于上下文消除歧义来选择合适的表情符号,例如板球棒 vs 蝙蝠,并且可以通过组合多个表情符号 eq 组合表达复杂的概念,Emojinize 被翻译为输入拉丁字母 right arrow 笑脸 。在基于完形填空测试的用户研究中,我们发现 Emojinize 的表情符号翻译将人类对屏蔽词的猜测性提高了 55 ,而人类选择的表情符号翻译仅提高了 29 。这些结果表明,表情符号提供了足够丰富的词汇量,可以准确翻译各种单词。 |
| ShortGPT: Layers in Large Language Models are More Redundant Than You Expect Authors Xin Men, Mingyu Xu, Qingyu Zhang, Bingning Wang, Hongyu Lin, Yaojie Lu, Xianpei Han, Weipeng Chen 随着大型语言模型法学硕士的性能不断提高,其规模也显着扩大,当前的法学硕士包含数十亿甚至数万亿个参数。然而,在这项研究中,我们发现LLM的许多层表现出高度相似性,并且某些层在网络功能中发挥的作用可以忽略不计。基于这一观察,我们定义了一个名为“区块影响力 BI”的指标来衡量法学硕士中每一层的重要性。然后,我们提出了一种直接的剪枝方法层删除,其中我们根据 LLM 的 BI 分数直接删除其中的冗余层。实验表明,我们的方法(我们称之为 ShortGPT)在模型修剪方面显着优于先前最先进的 SOTA 方法。此外,ShortGPT 与类似量化的方法正交,可以进一步减少参数和计算量。 |
| A Modular Approach for Multimodal Summarization of TV Shows Authors Louis Mahon, Mirella Lapata 在本文中,我们解决了总结电视节目的任务,该任务涉及人工智能研究复杂推理、多种模式和长叙述的关键领域。我们提出了一种模块化方法,其中单独的组件执行专门的子任务,我们认为与端到端方法相比,这种方法提供了更大的灵活性。我们的模块包括检测场景边界、重新排序场景以尽量减少不同事件之间的剪辑次数、将视觉信息转换为文本、总结每个场景中的对话,以及将场景摘要融合为整个剧集的最终摘要。我们还提出了一个新的指标,即 PREFS textbf Precision 和 textbf Recall textbf E 对 Summary textbf F act textbf s 的评估,以衡量生成的摘要的精度和召回率,我们将其分解为原子事实。 |
| Evaluating the Elementary Multilingual Capabilities of Large Language Models with MultiQ Authors Carolin Holtermann, Paul R ttger, Timm Dill, Anne Lauscher 法学硕士需要为所有人服务,包括全球大多数非英语国家的大型语言模型。然而,当今大多数法学硕士,尤其是开放式法学硕士,通常仅用于英语,例如Llama2、Mistral 或少数高资源语言,例如混合,Qwen。最近的研究表明,尽管法学硕士的预期用途受到限制,人们还是会用许多不同的语言来提示法学硕士。因此,在本文中,我们研究了最先进的开放式法学硕士的基本多语言能力,超出了其预期用途。为此,我们引入了 MultiQ,这是一种新的基本开放式问答银标准基准,包含 137 种不同类型语言的 27,400 个测试问题。通过 MultiQ,我们评估语言保真度,即模型是否以提示语言进行响应,以及问题回答的准确性。我们测试的所有法学硕士都对至少某些超出其预期用途的语言做出了忠实和/或准确的反应。大多数模型在忠实响应时会更加准确。然而,不同模型之间的差异很大,而且在很长的语言中,模型既不准确也不忠实。 |
| PPTC-R benchmark: Towards Evaluating the Robustness of Large Language Models for PowerPoint Task Completion Authors Zekai Zhang, Yiduo Guo, Yaobo Liang, Dongyan Zhao, Nan Duan 人们越来越依赖大型语言模型法学硕士来完成用户指令,因此需要全面了解它们在现实世界中完成复杂任务的稳健性。为了满足这一关键需求,我们提出了 PowerPoint 任务完成稳健性基准 PPTC R 来衡量法学硕士对用户 PPT 任务指令和软件版本的稳健性。具体来说,我们通过在句子、语义和多语言级别攻击用户指令来构建对抗性用户指令。为了评估语言模型对软件版本的稳健性,我们改变提供的 API 数量来模拟最新版本和早期版本设置。随后,我们使用包含这些鲁棒性设置的基准测试了 3 个闭源和 4 个开源 LLM,旨在评估偏差如何影响 LLM API 调用以完成任务。我们发现GPT 4在我们的基准测试中表现出了最高的性能和很强的鲁棒性,特别是在版本更新和多语言设置方面。然而,我们发现所有法学硕士在面临多重挑战时都会失去稳健性,例如同时进行多轮转,导致性能显着下降。我们在基准中进一步分析了 LLM 的稳健性行为和错误原因,这为研究人员了解 LLM 在任务完成方面的稳健性并开发更稳健的 LLM 和代理提供了宝贵的见解。 |
| German also Hallucinates! Inconsistency Detection in News Summaries with the Absinth Dataset Authors Laura Mascarell, Ribin Chalumattu, Annette Rios 大型语言模型法学硕士的出现导致了广泛的自然语言处理任务的显着进展。尽管取得了进步,这些大型模型在输出中仍然受到幻觉信息的影响,这在自动文本摘要中提出了一个主要问题,因为我们必须保证生成的摘要与源文档的内容一致。先前的研究解决了检测输出中的幻觉(即不一致检测)的挑战性任务,以评估生成的摘要的真实性。然而,这些作品主要关注英语,而最近的多语言方法缺乏德语数据。这项工作提出了苦艾酒,这是一个用于德国新闻摘要中幻觉检测的手动注释数据集,并探索了新颖的开源法学硕士在微调和上下文学习设置中在此任务上的能力。 |
| Rapidly Developing High-quality Instruction Data and Evaluation Benchmark for Large Language Models with Minimal Human Effort: A Case Study on Japanese Authors Yikun Sun, Zhen Wan, Nobuhiro Ueda, Sakiko Yahata, Fei Cheng, Chenhui Chu, Sadao Kurohashi 用于服务大型语言模型的指令数据和评估基准的创建通常涉及大量的人工注释。当为日语等非英语语言快速开发此类资源时,这个问题变得尤为明显。我们没有遵循将现有英语资源直接翻译成日语(例如 Japanese Alpaca)的流行做法,而是提出了一种基于 GPT 4 的高效自指导方法。我们首先将少量英语指令翻译成日语,然后对其进行后期编辑以获得母语水平质量。 GPT 4 然后利用它们作为演示来自动生成日语指令数据。我们还构建了一个评估基准,包含 8 个类别的 80 个问题,使用 GPT 4 自动评估法学硕士的回答质量,无需人工参考。实证结果表明,在我们的 GPT 4 自指导数据上进行微调的模型在所有三个基础预训练模型中均显着优于日本羊驼。我们的 GPT 4 自指导数据使 LLaMA 13B 模型以 54.37 的胜率击败了 GPT 3.5 Davinci 003。人类评估表现出 GPT 4 的评估与人类偏好之间的一致性。 |
| General2Specialized LLMs Translation for E-commerce Authors Kaidi Chen, Ben Chen, Dehong Gao, Huangyu Dai, Wen Jiang, Wei Ning, Shanqing Yu, Libin Yang, Xiaoyan Cai 现有的神经机器翻译NMT模型主要处理一般领域的翻译,而忽略了具有特殊书写公式的领域,例如电子商务和法律文档。以电子商务为例,文本通常包含大量领域相关单词并且存在更多语法问题,这导致当前 NMT 方法的性能较差。为了解决这些问题,我们收集了两个领域相关资源,包括一组与中英双语术语对齐的术语对和一个针对电子商务领域注释的平行语料库。此外,我们提出了一种名为 G2ST 的两步微调范例,具有自对比语义增强功能,将一个通用 NMT 模型转换为专门用于电子商务的 NMT 模型。该范式可用于基于大型语言模型 LLM 的 NMT 模型。 |
| Apollo: Lightweight Multilingual Medical LLMs towards Democratizing Medical AI to 6B People Authors Xidong Wang, Nuo Chen, Junyin Chen, Yan Hu, Yidong Wang, Xiangbo Wu, Anningzhe Gao, Xiang Wan, Haizhou Li, Benyou Wang 尽管全球医学知识库主要以英语为主,但当地语言对于提供定制医疗服务至关重要,特别是在医疗资源有限的地区。为了将医疗人工智能进步的影响范围扩大到更广泛的人群,我们的目标是开发六种最广泛使用的语言的医学法学硕士,涵盖全球 61 亿人口。这项工作最终创建了 ApolloCorpora 多语言医学数据集和 XMedBench 基准。在多语言医学基准测试中,已发布的 Apollo 模型在 0.5B、1.8B、2B、6B 和 7B 等各种相对较小的尺寸下,在同等尺寸的模型中取得了最佳性能。特别是,Apollo 7B 是最先进的多语言医学法学硕士,最高可达 70B。此外,这些精简模型可用于提高大型模型的多语言医疗功能,而无需以代理调整方式进行微调。 |
| GPTopic: Dynamic and Interactive Topic Representations Authors Arik Reuter, Anton Thielmann, Christoph Weisser, Sebastian Fischer, Benjamin S fken 主题建模似乎几乎与生成热门词列表来表示大型文本语料库中的主题同义。然而,从这样的单个术语列表中推导出主题可能需要大量的专业知识和经验,使得不熟悉热门词解释的特殊性和陷阱的人难以进行主题建模。仅限于热门词的主题表示可能进一步无法提供主题可能具有的各个方面、方面和细微差别的全面且易于访问的特征。为了应对这些挑战,我们推出了 GPTopic,这是一个利用大型语言模型 LLM 来创建动态、交互式主题表示的软件包。 GPTopic 提供了直观的聊天界面,供用户交互式地探索、分析和提炼主题,使主题建模更加易于理解和全面。相应的代码可以在这里 https github 找到。 |
| Multimodal Large Language Models to Support Real-World Fact-Checking Authors Jiahui Geng, Yova Kementchedjhieva, Preslav Nakov, Iryna Gurevych 多模态大语言模型 MLLM 具有支持人类处理大量信息的潜力。虽然 MLLM 已被用作事实检查工具,但它们在这方面的能力和局限性尚未得到充分研究。我们的目标是弥合这一差距。特别是,我们提出了一个框架,用于系统评估当前多模式模型的能力,以促进现实世界的事实检查。我们的方法是无证据的,仅利用这些模型的内在知识和推理能力。通过设计提取模型预测、解释和置信水平的提示,我们深入研究有关模型准确性、鲁棒性和失败原因的研究问题。我们凭经验发现,1 个 GPT 4V 在识别恶意和误导性多模态声明方面表现出优越的性能,能够解释不合理的方面和潜在动机,而 2 个现有的开源模型表现出强烈的偏见,并且对提示高度敏感。我们的研究为打击虚假多模式信息和构建安全、值得信赖的多模式模型提供了见解。 |
| Design of an Open-Source Architecture for Neural Machine Translation Authors S amus Lankford, Haithem Afli, Andy Way AdaptNMT 是一个开源应用程序,它提供了一种简化的方法来开发和部署循环神经网络和 Transformer 模型。该应用程序建立在广泛采用的 OpenNMT 生态系统之上,对于该领域的新进入者特别有用,因为它简化了开发环境的设置以及训练、验证和测试拆分的创建。该应用程序提供了图形功能,可以说明模型训练的进度,并使用 SentencePiece 创建子词分割模型。此外,该应用程序提供了直观的用户界面,有利于超参数定制。值得注意的是,已经实现了单击模型开发方法,并且可以使用一系列指标来评估由 AdaptNMT 开发的模型。为了鼓励生态友好型研究,adaptNMT 纳入了一份绿色报告,其中标记了模型开发过程中产生的功耗和 kgCO 2 排放量。 |
| Enhancing ASD detection accuracy: a combined approach of machine learning and deep learning models with natural language processing Authors Sergio Rubio Mart n, Mar a Teresa Garc a Ord s, Mart n Bay n Guti rrez, Natalia Prieto Fern ndez, Jos Alberto Ben tez Andrades 目的我们的研究探索使用人工智能AI来诊断自闭症谱系障碍ASD。 |
| gaHealth: An English-Irish Bilingual Corpus of Health Data Authors S amus Lankford, Haithem Afli, rla N Loinsigh, Andy Way 机器翻译对于许多高资源语言对来说是一项成熟的技术。然而,在资源匮乏的语言环境中,缺乏可用于开发翻译模型的并行数据集。此外,低资源语言数据集的开发通常侧重于简单地为通用翻译创建尽可能大的数据集。较小的领域数据集的好处和发展很容易被忽视。为了评估在领域数据中使用的优点,针对资源匮乏的英语到爱尔兰语对开发了特定健康领域的数据集。我们的研究概述了开发语料库的过程,并凭经验证明了在健康领域使用域内数据集的好处。在翻译健康相关数据的背景下,与 LoResMT2021 共享任务中表现最佳的模型相比,使用 gaHealth 语料库开发的模型的 BLEU 得分最大提高了 22.2 分 40。此外,我们还定义了开发 gaHealth 的语言指南,这是第一个爱尔兰语健康数据双语语料库,我们希望它对低资源数据集的其他创建者有用。 |
| Benchmarking Hallucination in Large Language Models based on Unanswerable Math Word Problem Authors Yuhong Sun, Zhangyue Yin, Qipeng Guo, Jiawen Wu, Xipeng Qiu, Hui Zhao 大型语言模型 LLM 在各种自然语言处理 NLP 任务中非常有效。然而,他们很容易在模棱两可的环境中产生不可靠的猜想,称为幻觉。本文提出了一种基于无解数学应用题 MWP 的问答 QA 中评估 LLM 幻觉的新方法。为了支持这种方法,我们创新性地开发了一个名为“Unanswerable Math Word Problem UMWP”的数据集,其中包含五个类别的 5200 个问题。我们开发了一种结合文本相似性和数学表达式检测的评估方法,以确定 LLM 是否认为该问题无法回答。对 31 个 LLM(包括 GPT 3、InstructGPT、LLaMA 和 Claude)进行的广泛实验结果表明,在具有人类反馈的情境学习和强化学习中,RLHF 训练显着增强了模型避免幻觉的能力。我们证明,利用 MWP 是评估幻觉的可靠且有效的方法。 |
| BiVert: Bidirectional Vocabulary Evaluation using Relations for Machine Translation Authors Carinne Cherf, Yuval Pinter 神经机器翻译 NMT 在过去几年中发展迅速,有望对不同语言进行改进并提高翻译质量。对该任务的评估对于确定翻译质量至关重要。总体而言,传统方法对翻译的实际意义重视不够。我们提出了一种基于双向语义的评估方法,旨在评估翻译与源文本的感知距离。该方法采用综合多语言百科全书词典 BabelNet。通过计算源与其输出的反向翻译之间的语义距离,我们的方法引入了一种可量化的方法,可以在相同的语言级别上进行句子比较。事实分析表明,我们的方法生成的平均评估分数与各种机器翻译系统对英语德语语言对的人工评估之间存在很强的相关性。 |
| Unsupervised Multilingual Dense Retrieval via Generative Pseudo Labeling Authors Chao Wei Huang, Chen An Li, Tsu Yuan Hsu, Chen Yu Hsu, Yun Nung Chen 密集检索方法在多语言信息检索中表现出了良好的性能,其中查询和文档可以使用不同的语言。然而,密集检索器通常需要大量的配对数据,这在多语言场景中提出了更大的挑战。本文介绍了 UMR,一种无需任何配对数据训练的无监督多语言密集检索器。我们的方法利用多语言语言模型的序列似然估计功能来获取用于训练密集检索器的伪标签。我们提出了一个两阶段框架,它迭代地提高了多语言密集检索器的性能。两个基准数据集的实验结果表明,UMR 优于监督基线,展示了在没有配对数据的情况下训练多语言检索器的潜力,从而增强了其实用性。 |
| CLongEval: A Chinese Benchmark for Evaluating Long-Context Large Language Models Authors Zexuan Qiu, Jingjing Li, Shijue Huang, Wanjun Zhong, Irwin King 开发具有强大的长上下文能力的大型语言模型法学硕士一直是最近的研究热点,导致精通中文的长上下文法学硕士的出现。然而,由于缺乏基准,这些模型的评估仍然不发达。为了弥补这一差距,我们推出了 CLongEval,这是一个用于评估长背景法学硕士的综合中国基准。 CLongEval 具有三个关键特征 1 足够的数据量,包括 7 个不同的任务和 7,267 个示例 2 广泛的适用性,适应上下文窗口大小从 1K 到 100K 的模型 3 高质量,除了自动构建的标签。通过 CLongEval,我们对 6 名开源长语境法学硕士和 2 名具有长语境能力和中文熟练程度的领先商业同行进行了全面评估。我们还根据实证结果提供深入分析,试图阐明在长上下文环境中提出挑战的关键能力。 |
| Towards Detecting AI-Generated Text within Human-AI Collaborative Hybrid Texts Authors Zijie Zeng, Shiqi Liu, Lele Sha, Zhuang Li, Kaixun Yang, Sannyuya Liu, Dragan Ga evi , Guanliang Chen 本研究探讨了人类人工智能协作混合文本中句子级人工智能生成文本检测的挑战。现有的人工智能生成的混合文本文本检测研究通常依赖于合成数据集。这些通常涉及边界数量有限的混合文本。我们认为,检测人工智能在混合文本中生成的内容的研究应该涵盖在现实环境中生成的不同类型的混合文本,以更好地为现实世界的应用程序提供信息。因此,我们的研究利用了 CoAuthor 数据集,其中包括通过人类作家和智能写作系统在多轮交互中协作生成的多样化、真实的混合文本。我们采用两步基于分段的管道,即检测给定混合文本中的片段,其中每个片段包含作者身份一致的句子,并对每个已识别片段的作者身份进行分类。我们的实证研究结果强调 1 检测混合文本中人工智能生成的句子总体而言是一项具有挑战性的任务,因为 1.1 人类作家根据个人喜好选择甚至编辑人工智能生成的句子增加了识别片段作者的难度 1.2 文本中相邻句子之间作者身份的频繁变化混合文本给片段检测器识别作者一致片段带来了困难 1.3 混合文本中文本片段的长度较短,为可靠的作者确定提供了有限的风格线索 2 在开始检测过程之前,评估文本片段中片段的平均长度是有益的混合文本。 |
| A Knowledge Plug-and-Play Test Bed for Open-domain Dialogue Generation Authors Xiangci Li, Linfeng Song, Lifeng Jin, Haitao Mi, Jessica Ouyang, Dong Yu 基于知识的开放域对话生成旨在构建使用挖掘的支持知识与人类对话的聊天系统。许多类型和来源的知识先前已被证明可用作支持知识。即使在大型语言模型时代,基于从其他最新来源检索的知识的响应生成仍然是一种实际重要的方法。虽然先前使用单一源知识的工作表明知识选择和响应生成的性能之间存在明显的正相关性,但目前还没有用于评估支持知识检索的多源数据集。此外,先前的工作假设测试时可用的知识源与训练期间相同。这种不切实际的假设不必要地阻碍了模型,因为在模型训练后可以使用新的知识源。在本文中,我们提出了一个名为多源维基百科 Ms.WoW 向导的高质量基准,用于评估多源对话知识选择和响应生成。与现有数据集不同,它包含干净的支持知识,基于话语级别并划分为多个知识源。 |
| Magic Markup: Maintaining Document-External Markup with an LLM Authors Edward Misback, Zachary Tatlock, Steven L. Tanimoto 文本文档(包括程序)通常具有人类可读的语义结构。从历史上看,对这些语义的编程访问需要明确的文档标记。特别是在文本具有执行语义的系统中,这意味着它是一个难以正确支持的选择功能。如今,语言模型提供了一种新方法,可以使用模型对语义的类似人类理解,将元数据绑定到更改文本中的实体,而对文档结构没有要求。该方法扩展了文档注释的应用范围,文档注释是程序编写、调试、维护和演示中的基本操作。我们贡献了一个系统,该系统采用智能代理来重新标记修改后的程序,使丰富的注释能够随着代码的发展自动跟随代码。我们还提供了正式的问题定义、经验综合基准套件和基准生成器。我们的系统在基准测试中达到了 90 的准确度,并且可以以每个标签 5 秒的速度并行替换文档标签。 |
| VLSP 2023 -- LTER: A Summary of the Challenge on Legal Textual Entailment Recognition Authors Vu Tran, Ha Thanh Nguyen, Trung Vo, Son T. Luu, Hoang Anh Dang, Ngoc Cam Le, Thi Thuy Le, Minh Tien Nguyen, Truong Son Nguyen, Le Minh Nguyen 在人工智能快速发展的新时代,特别是在语言处理领域,法律领域对人工智能的需求日益迫切。在英语、日语和汉语等其他语言的研究已经成熟的背景下,我们通过越南语言和语音处理研讨会引入了法律领域法律文本蕴含识别中越南语的第一个基础研究。 |
| Mixture-of-LoRAs: An Efficient Multitask Tuning for Large Language Models Authors Wenfeng Feng, Chuzhan Hao, Yuewei Zhang, Yu Han, Hao Wang 指令调优有潜力激发或增强大型语言模型法学硕士的特定能力。然而,实现数据的正确平衡对于防止灾难性遗忘和任务之间的干扰至关重要。为了解决这些限制并增强训练灵活性,我们提出了 LoRA MoA 架构的混合,这是一种新颖且参数高效的调整方法,专为法学硕士的多任务学习而设计。在本文中,我们首先使用相应的监督语料库数据单独训练多个特定领域的 LoRA 模块。这些 LoRA 模块可以与 MoE 专家混合中遵守的专家设计原则保持一致。随后,我们使用显式路由策略组合多个 LoRA,并引入域标签来促进多任务学习,这有助于防止任务之间的干扰,并最终提高每个任务的性能。此外,每个 LoRA 模型都可以迭代地适应新领域,从而实现快速的特定领域适应。 |
| Negating Negatives: Alignment without Human Positive Samples via Distributional Dispreference Optimization Authors Shitong Duan, Xiaoyuan Yi, Peng Zhang, Tun Lu, Xing Xie, Ning Gu 大型语言模型法学硕士彻底改变了人工智能的作用,但也带来了传播不道德内容的潜在风险。对齐技术已被引入以引导法学硕士迎合人类的偏好,并受到越来越多的关注。尽管在这个方向上取得了显着的突破,但现有的方法严重依赖于高质量的正负训练对,受到噪声标签以及首选和不首选响应数据之间边缘差异的影响。鉴于最近法学硕士在产生有用反应方面的熟练程度,这项工作转向一个新的研究重点,仅使用人类注释的阴性样本来实现对齐,保留有用性,同时减少危害性。为此,我们提出分布式不偏好优化 D 2 O ,它最大化生成的响应与不偏好的响应之间的差异,以有效避开有害信息。我们从理论上证明,D 2 O 相当于学习一个分布而非实例级别的偏好模型,反映了人类对负面反应分布的不偏好。此外,D 2 O 集成了隐式杰弗里散度正则化来平衡参考策略的利用和探索,并在训练过程中收敛到非负策略。 |
| Japanese-English Sentence Translation Exercises Dataset for Automatic Grading Authors Naoki Miura, Hiroaki Funayama, Seiya Kikuchi, Yuichiroh Matsubayashi, Yuya Iwase, Kentaro Inui 本文提出了句子翻译练习 STE 的自动评估任务,该任务已在 L2 语言学习的早期阶段使用。我们将任务正式化为根据教育工作者预先指定的每个评分标准对学生的反应进行评分。然后,我们创建了日语和英语之间的 STE 数据集,其中包括 21 个问题,以及总共 3, 498 名学生的平均回答 167 。答案是从学生和人群工作人员那里收集的。使用这个数据集,我们展示了基线的性能,包括经过微调的 BERT 和 GPT 模型,在上下文学习中很少使用。实验结果表明,经过微调的 BERT 基线模型能够对 F1 中大约 90 的正确答案进行分类,但对错误答案的分类结果只有不到 80。 |
| Learning to Maximize Mutual Information for Chain-of-Thought Distillation Authors Xin Chen, Hanxian Huang, Yanjun Gao, Yi Wang, Jishen Zhao, Ke Ding 知识蒸馏是将知识从大型复杂模型转移到较小模型的技术,标志着高效人工智能部署的关键一步。 Distilling Step by Step DSS 是一种利用思想链 CoT 蒸馏的新颖方法,通过为较小的模型赋予较大模型的卓越推理能力,展现出了良好的前景。在 DSS 中,蒸馏模型获得了通过多任务学习框架同时生成原理和预测标签的能力。然而,DSS忽略了两个训练任务之间的内在关系,导致CoT知识与标签预测任务的无效整合。为此,我们从信息瓶颈的角度研究了两个任务的相互关系,并将其表示为最大化两个任务的表示特征的互信息。我们提出了一种使用基于学习的方法来解决此优化问题的变分方法。我们在四个数据集上的实验结果表明,我们的方法优于最先进的 DSS。我们的研究结果为未来语言模型蒸馏的研究以及涉及 CoT 的应用提供了富有洞察力的指导。 |
| DIVERSE: Deciphering Internet Views on the U.S. Military Through Video Comment Stance Analysis, A Novel Benchmark Dataset for Stance Classification Authors Iain J. Cruickshank, Lynnette Hui Xian Ng 社交媒体文本的立场检测是下游任务的关键组成部分,涉及识别对疫苗接种和争论等有争议的话题持反对意见的用户群体。特别是,立场表明了对实体的看法。本文介绍了 DIVERSE,这是一个包含超过 173,000 条 YouTube 视频评论的数据集,注释了他们对美国军方视频的立场。该立场是通过人类引导、机器辅助的标记方法来注释的,该方法利用句子中的微弱语气信号作为支持指标,而不是使用人类手动注释。这些微弱信号包括仇恨言论和讽刺的存在、特定关键字的存在、文本的情绪以及来自两个大型语言模型的立场推断。然后,在用最终立场标签对每条评论进行注释之前,使用数据编程模型来整合弱信号。 |
| Guardrail Baselines for Unlearning in LLMs Authors Pratiksha Thaker, Yash Maurya, Virginia Smith 最近的工作表明,微调是从大型语言模型中忘却概念的一种有前途的方法。然而,微调可能会很昂贵,因为它需要生成一组示例并运行微调迭代来更新模型。在这项工作中,我们证明了基于简单护栏的方法(例如提示和过滤)可以实现与微调相当的遗忘结果。我们建议研究人员在评估计算密集型微调方法的性能时研究这些轻量级基线。虽然我们并不认为提示或过滤等方法是解决遗忘问题的通用解决方案,但我们的工作表明需要评估指标来更好地区分护栏与微调的力量,并强调护栏本身可能会影响的场景。 |
| Book2Dial: Generating Teacher-Student Interactions from Textbooks for Cost-Effective Development of Educational Chatbots Authors Junling Wang, Jakub Macina, Nico Daheim, Sankalan Pal Chowdhury, Mrinmaya Sachan 教育聊天机器人是一种很有前途的帮助学生学习的工具。然而,在教育领域开发有效的聊天机器人一直具有挑战性,因为该领域很少有高质量的数据。在本文中,我们提出了一个基于一组教科书生成综合师生互动的框架。我们的方法捕捉了学习互动的一个方面,即具有部分知识的好奇学生向老师互动地询问有关教科书材料的问题。我们强调了此类对话应满足的各种质量标准,并比较了依赖于提示或微调大型语言模型的几种方法。我们使用合成对话来训练教育聊天机器人,并展示在不同教育领域进一步微调的好处。然而,人类评估表明,我们最好的数据合成方法仍然存在幻觉,并且倾向于重申之前对话中的信息。我们的研究结果为未来合成对话数据的努力提供了见解,以在大小和质量之间取得平衡。 |
| Best of Both Worlds: A Pliable and Generalizable Neuro-Symbolic Approach for Relation Classification Authors Robert Vacareanu, Fahmida Alam, Md Asiful Islam, Haris Riaz, Mihai Surdeanu 本文介绍了一种用于关系分类 RC 的新型神经符号架构,它将基于规则的方法与当代深度学习技术相结合。这种方法利用了两种范式的优势:基于规则的系统的适应性和神经网络的泛化能力。我们的架构由两个组件组成,一个是用于透明分类的基于声明性规则的模型,另一个是通过语义文本匹配来增强规则泛化性的神经组件。值得注意的是,我们的语义匹配器以无监督的领域不可知方式进行训练,仅使用合成数据。此外,这些组件是松散耦合的,允许修改规则而无需重新训练语义匹配器。在我们的评估中,我们重点关注两个少数镜头关系分类数据集Few Shot TACRED和NYT29的Few Shot版本。我们表明,尽管没有看到任何人类注释的训练数据,但我们提出的方法在四分之三的设置中优于以前最先进的模型。此外,我们表明我们的方法仍然是模块化和柔韧的,即可以局部修改相应的规则以改进整体模型。 |
| Mad Libs Are All You Need: Augmenting Cross-Domain Document-Level Event Argument Data Authors Joseph Gatto, Parker Seegmiller, Omar Sharif, Sarah M. Preum 文档级事件参数提取 DocEAE 是一个极其困难的信息提取问题,在低资源跨域设置中具有很大的局限性。为了解决这个问题,我们引入了 Mad Lib Aug MLA,一种新颖的生成式 DocEAE 数据增强框架。我们的方法利用了 Mad Libs 的直觉,Mad Libs 是一种被明确屏蔽的文档,用作流行游戏的一部分,可以由法学硕士生成和解决,为 DocEAE 生成数据。使用 MLA,我们的总体 F1 分数平均提高了 2.6 分。 |
| Backtracing: Retrieving the Cause of the Query Authors Rose E. Wang, Pawan Wirawarn, Omar Khattab, Noah Goodman, Dorottya Demszky 许多在线内容门户允许用户提出问题来补充他们的理解,例如讲座。虽然信息检索 IR 系统可以为此类用户查询提供答案,但它们不会直接帮助内容创建者(例如想要改进其内容的讲师)识别导致用户提出这些问题的片段。我们引入回溯任务,其中系统检索最有可能引起用户查询的文本段。我们形式化了三个现实世界领域,对于这三个领域,回溯对于改善内容交付和沟通理解非常重要,其中理解 a 讲座领域中学生困惑的原因,b 新闻文章领域中读者的好奇心,以及 c 对话领域中用户情感的原因。我们评估了流行的信息检索方法和语言建模方法的零样本性能,包括双编码器、重新排序和基于似然的方法以及 ChatGPT。虽然传统的 IR 系统检索语义相关的信息,例如,查询的投影矩阵的详细信息,多次投影仍然会导致同一点,但它们经常会错过因果相关的上下文,例如,讲师指出投影两次会得到与一次投影相同的答案。我们的结果表明回溯还有改进的空间,并且需要新的检索方法。我们希望我们的基准测试能够改进未来的回溯检索系统,生成系统,从而改进内容生成并识别影响用户查询的语言触发器。 |
| Enhancing Instructional Quality: Leveraging Computer-Assisted Textual Analysis to Generate In-Depth Insights from Educational Artifacts Authors Zewei Tian, Min Sun, Alex Liu, Shawon Sarkar, Jing Liu 本文通过对教育制品的深入了解,探讨了计算机辅助文本分析在提高教学质量方面的变革潜力。我们整合 Richard Elmore 的教学核心框架来研究人工智能 AI 和机器学习 ML 方法,特别是自然语言处理 NLP,如何分析教育内容、教师话语和学生反应,以促进教学改进。通过对教学核心框架内的全面审查和案例研究,我们确定了 AI ML 集成可提供显着优势的关键领域,包括教师辅导、学生支持和内容开发。我们揭示的模式表明 AI ML 不仅简化了管理任务,还引入了个性化学习的新颖途径,为教育工作者提供了可操作的反馈,并有助于更丰富地理解教学动态。 |
| IRCoder: Intermediate Representations Make Language Models Robust Multilingual Code Generators Authors Indraneil Paul, Jun Luo, Goran Glava , Iryna Gurevych 代码理解和生成已迅速成为语言模型 LM 最流行的应用之一。尽管如此,对代码 LM 的多语言方面的研究,即用于代码生成的 LM,例如不同编程语言之间的跨语言传输、特定于语言的数据增强和事后 LM 适应,以及对原始文本内容以外的数据源的利用,已经比自然语言的对应物要稀疏得多。特别是,大多数主流 Code LM 都仅针对源代码文件进行了预训练。 |
| Probabilistic Topic Modelling with Transformer Representations Authors Arik Reuter, Anton Thielmann, Christoph Weisser, Benjamin S fken, Thomas Kneib 在过去的十年中,主题建模主要由贝叶斯图模型主导。然而,随着自然语言处理中 Transformer 的兴起,一些依赖于基于 Transformer 的嵌入空间中的直接聚类方法的成功模型已经出现,并将主题的概念巩固为嵌入向量的集群。我们提出了 Transformer Representation Neural Topic Model TNTM ,它结合了基于 Transformer 的嵌入空间和概率建模中主题表示的优点。因此,这种方法将基于转换器嵌入的强大且通用的主题概念与完全概率建模相结合,如潜在狄利克雷分配 LDA 等模型。我们利用变分自动编码器 VAE 框架来提高推理速度和建模灵活性。实验结果表明,我们提出的模型在嵌入一致性方面取得了与各种最先进的方法相当的结果,同时保持了几乎完美的主题多样性。 |
| Prompt Mining for Language-based Human Mobility Forecasting Authors Hao Xue, Tianye Tang, Ali Payani, Flora D. Salim 随着大型语言模型的进步,基于语言的预测最近已成为预测人员流动模式的创新方法。核心思想是使用提示将以数值形式给出的原始移动数据转换为自然语言句子,以便可以利用语言模型来生成未来观察的描述。然而,之前的研究仅采用固定的、手动设计的模板来将数值转换为句子。由于语言模型的预测性能严重依赖于提示,因此使用固定模板进行提示可能会限制语言模型的预测能力。在本文中,我们提出了一种基于语言的移动预测中提示挖掘的新颖框架,旨在探索多样化的提示设计策略。具体来说,该框架包括基于提示信息熵的提示生成阶段和集成思想链等机制的提示细化阶段。现实世界大规模数据的实验结果证明了我们的提示挖掘管道生成的提示的优越性。此外,不同提示变体的比较表明,所提出的提示细化过程是有效的。 |
| RADIA -- Radio Advertisement Detection with Intelligent Analytics Authors Jorge lvarez, Juan Carlos Armenteros, Camilo Torr n, Miguel Ortega Mart n, Alfonso Ardoiz, scar Garc a, Ignacio Arranz, igo Galdeano, Ignacio Garrido, Adri n Alonso, Fernando Bay n, Oleg Vorontsov 广播广告仍然是现代营销策略不可或缺的一部分,其吸引力和目标受众潜力无可否认是有效的。然而,广播播放时间的动态性质和多个广播节目的增长趋势需要一个有效的系统来监控广告广播。本研究研究了一种新颖的自动广播广告检测技术,结合了先进的语音识别和文本分类算法。 RadIA 的方法超越了传统方法,无需事先了解广播内容。这一贡献允许检测即兴广告和新引入的广告,为无线电广播中的广告检测提供全面的解决方案。实验结果表明,所得到的模型经过仔细分段和标记的文本数据的训练,取得了 87.76 的 F1 宏观分数,而理论最大值为 89.33。本文深入探讨了超参数的选择及其对模型性能的影响。这项研究证明了它在确保遵守广告广播合同和提供竞争性监控方面的潜力。 |
| Non-verbal information in spontaneous speech - towards a new framework of analysis Authors Tirza Biron, Moshe Barboy, Eran Ben Artzy, Alona Golubchik, Yanir Marmor, Smadar Szekely, Yaron Winter, David Harel 语音中的非语言信号由韵律编码,并携带从对话动作到态度和情感的信息。尽管它很重要,但控制韵律结构的原则尚未得到充分理解。本文为韵律信号的分类及其与意义的关联提供了分析模式和技术概念证明。该模式解释了多层韵律事件的表面表征。作为实现的第一步,我们提出了一个分类过程,可以解开三个顺序的韵律现象。它依赖于微调预训练的语音识别模型,从而实现同时多类多标签检测。它概括了各种各样的自发数据,其性能与人类注释相当或优于人类注释。除了韵律的标准化形式化之外,解开韵律模式还可以指导沟通和言语组织的理论。 |
| Human vs. Machine: Language Models and Wargames Authors Max Lamparth, Anthony Corso, Jacob Ganz, Oriana Skylar Mastro, Jacquelyn Schneider, Harold Trinkunas 兵棋推演在军事战略的发展和国家对威胁或攻击的反应方面有着悠久的历史。人工智能的出现有望做出更好的决策并提高军事效率。然而,关于人工智能系统,尤其是大型语言模型法学硕士,与人类相比如何表现仍然存在争议。为此,我们对 107 名国家安全专家的人类玩家进行了兵棋实验,旨在观察虚构的中美情景中的危机升级,并将人类玩家与 LLM 模拟反应进行比较。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com