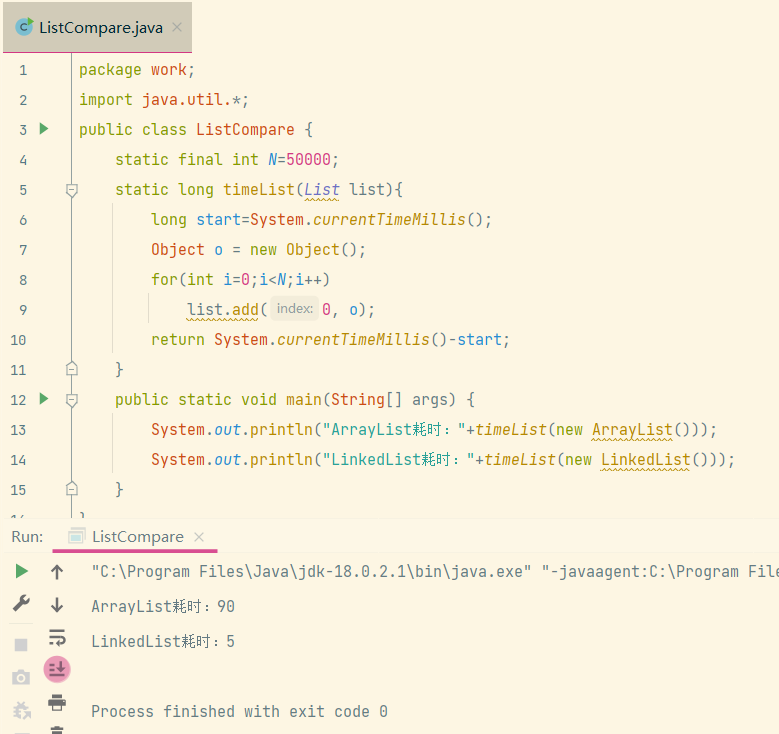
总结
本系列是机器学习课程的系列课程,主要介绍机器学习中神经网络算法。
本门课程的目标
完成一个特定行业的算法应用全过程:
懂业务+会选择合适的算法+数据处理+算法训练+算法调优+算法融合
+算法评估+持续调优+工程化接口实现
参考
机器学习定义
关于机器学习的定义,Tom Michael Mitchell的这段话被广泛引用:
对于某类任务T和性能度量P,如果一个计算机程序在T上其性能P随着经验E而自我完善,那么我们称这个计算机程序从经验E中学习。

机器学习的5大流派:
①符号主义:使用符号、规则和逻辑来表征知识和进行逻辑推理,最喜欢的算法是:规则和决策树
②贝叶斯派:获取发生的可能性来进行概率推理,最喜欢的算法是:朴素贝叶斯或马尔可夫
③联结主义:使用概率矩阵和加权神经元来动态地识别和归纳模式,最喜欢的算法是:神经网络
④进化主义:生成变化,然后为特定目标获取其中最优的,最喜欢的算法是:遗传算法
⑤类推学派Analogizer:根据约束条件来优化函数(尽可能走到更高,但同时不要离开道路),最喜欢的算法是:支持向量机
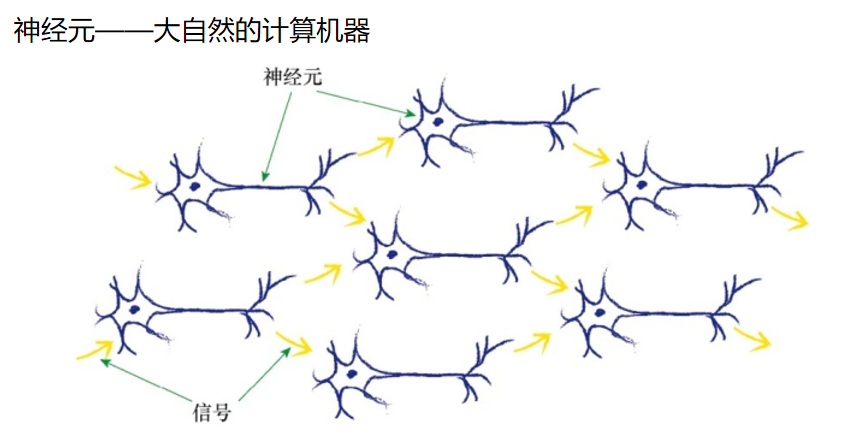
神经网络
人脑是怎样工作的
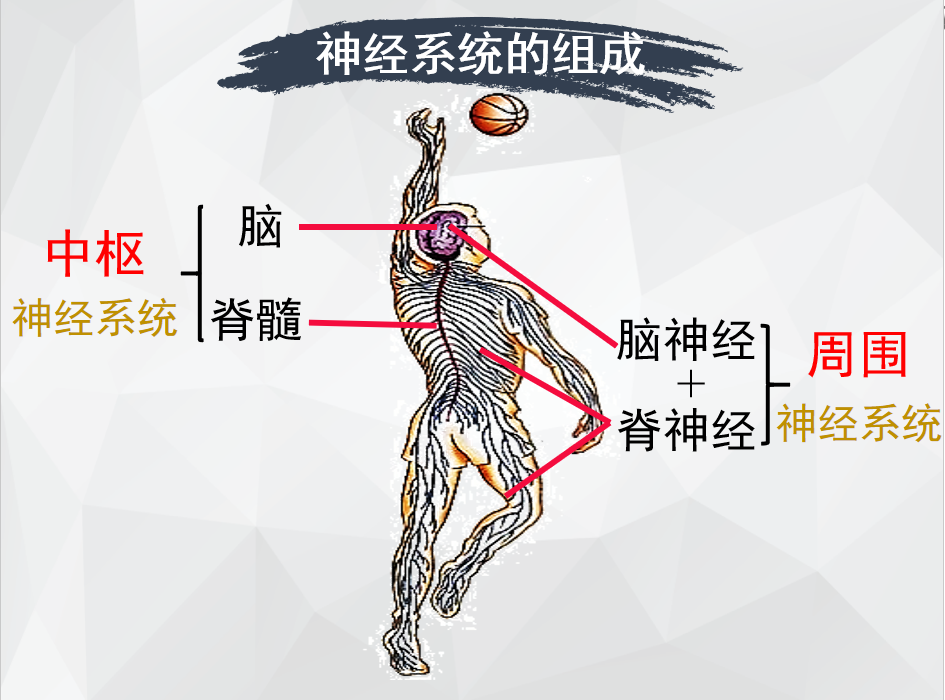


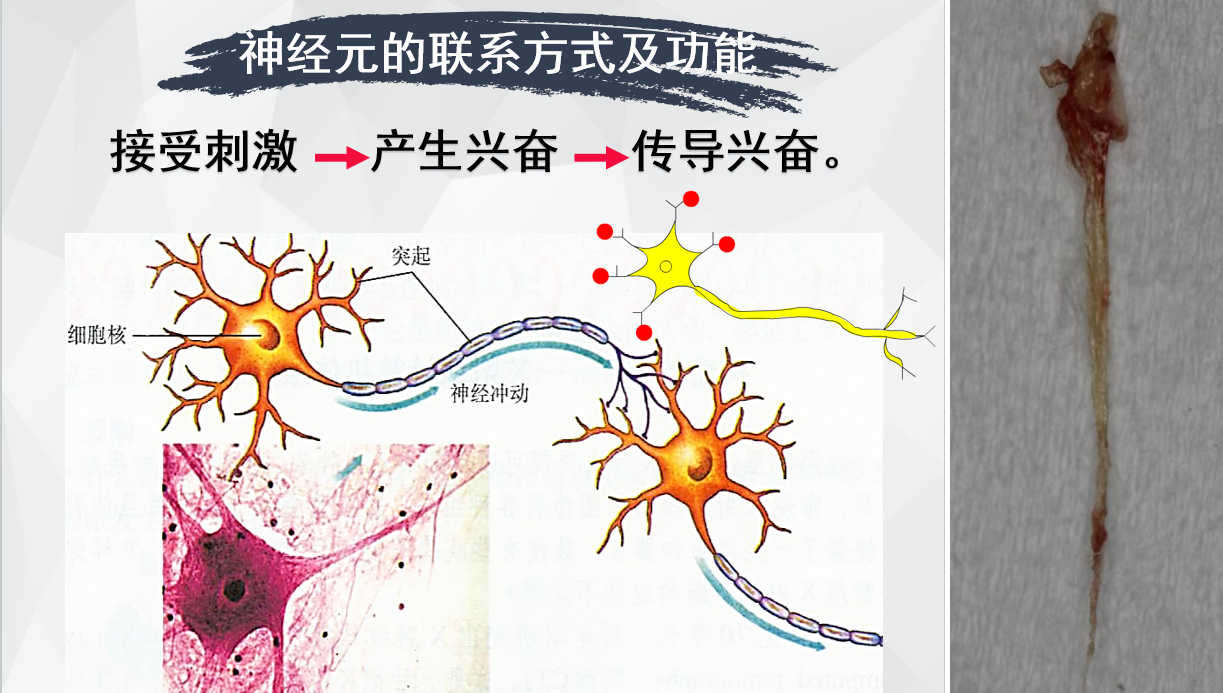
1)输入(感受)区就一个运动神经元来讲,胞体或树突膜上的受体是接受传入信息的输入区,该区可以产生突触后电位(局部电位)。
2)整合(触发冲动)区始段属于整合区或触发冲动区,众多的突触后电位在此发生总和,并且当达到阈电位时在此首先产生动作电位。
3)冲动传导区轴突属于传导冲动区,动作电位以不衰减的方式传向所支配的靶器官。
4)输出(分泌)区轴突末梢的突触小体则是信息输出区,神经递质在此通过胞吐方式加以释放。

人类大脑中神经元的总数可能在750亿到1250亿之间,一般人脑有神经元120到140亿个,而且大脑神经元是不可再生的,一般情况下,在成人以后会随着年龄的增加而逐渐减少。
大脑神经元一般估计数值是860亿,粗略1000亿也OK,140亿是大脑皮层的神经元数量,。
神经元的基本功能是通过接受、整合、传导和输出信息进行信息的传递与处理,通俗来说,神经元具有支配运动,感受信息的作用,人体通过神经元构成一个完整的个体,构成完整的神经功能。大脑的四周包着一层含有静脉和动脉的薄膜,这层薄膜里充满了感觉神经,但是大脑本身却没有感觉,人的大脑平均为人体总体重的2%,但它需要使用全身所用氧气的25%,相比之下肾脏只需12%,心脏只需7%,神经信号在神经或肌肉纤维中的传递速度可以高达每小时200英里。
随着人的年龄增大,血管(特别是毛细血管)越来越堵塞,大脑得到的血液越来越少,要保持血管畅通,就要少吃油、少吃肉、少吃糖,多吃蔬菜、水果,保持良好心态,适当运动,充足睡眠,经常适度用脑,这样便可以使脑细胞中的神经元更慢的流走。
模拟人脑神经元进行思考的神经网络
看到一幅画
输出 齐白石的虾
输出 栩栩如生、妙手丹青、神来之笔
听到一句话 Thank you all for your applause
输出 谢谢大家的掌声
看到一个数据集
输出数据集之间的关系

行星轨道方程简单推导
感知机 perceptron


看到一个数据集
输出数据集之间的关系
线性关系:累加和倍乘
现在想象一下,我们不知道千米和英里之间的转换公式。我们所知道 的就是,两者之间的关系是线性的。这意味着,如果英里数加倍,那么表 示相同距离的千米数也是加倍的。这是非常直观的。如果这都不是真理, 那么这个宇宙就太让人匪夷所思了。 千米和英里之间的这种线性关系,为我们提供了这种神秘计算的线 索,即它的形式应该是“英里=千米×C”,其中C为常数。现在,我们还不知 道这个常数C是多少。 我们拥有的唯一其他的线索是,一些正确的千米/英里匹配的数值对示 例。这些示例就像用来验证科学理论的现实世界观察实验一样,显示了世 界的真实情况。
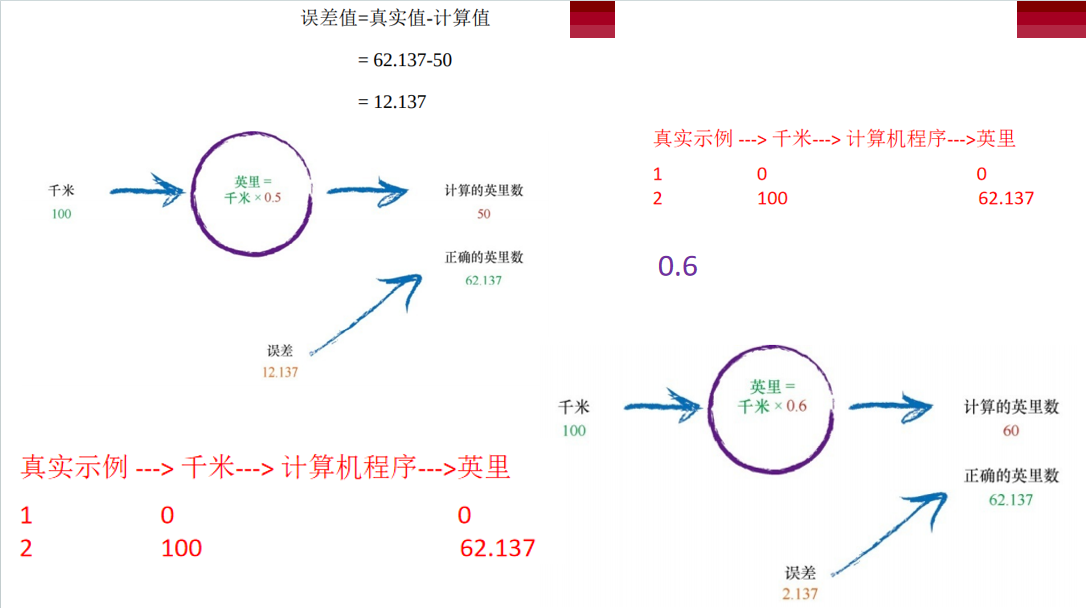
这里,我们令:英里=千米×C,其中千米为100,当前,我们猜测C为 0.5。 这台机器得到50英里的答案。 嗯,鉴于我们随机选择了C = 0.5,这种表现还算不错。但是,编号为2 的真实示例告诉我们,答案应该是62.137,因此我们知道这是不准确的。 我们少了12.137。这是计算结果与我们列出的示例真实值之间的差 值,是误差。即:
下一步,我们将做些什么呢?我们知道错了,并且知道差了多少。我 们无需对这种误差感到失望,我们可以使用这个误差,指导我们得到第二 个、更好的C的猜测值。再看看这个误差值。我们少了12.137。由于千米转换为英里的公式是 线性的,即英里= 千米×C,因此我们知道,增加C就可以增加输出。 让我们将C从0.5稍微增加到0.6,观察会发生什么情况。 现在,由于将C设置为0.6,我们得到了英里=千米×C = 100×0.6 = 60, 这个答案比先前50的答案更好。我们取得了明显的进步。
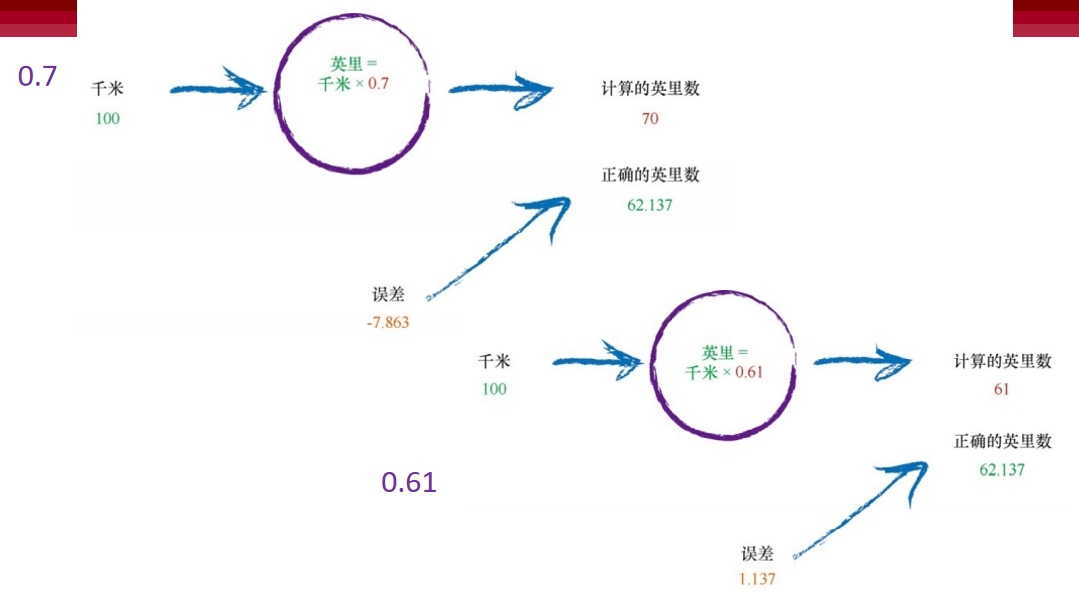
糟糕!过犹不及,结果超过了已知的正确答案。先前的误差值为 2.137,现在的误差值为-7.863。这个负号告诉我们,我们不是不足,而是 超调了。请记住上面的公式,误差值等于真实值减去计算值。 如此说来,C = 0.6比C = 0.7好得多。我们可以就此结束这个练习,欣 然接受C = 0.6带来的小小误差。但是,让我继续向前走一小段距离。我们 为什么不使用一个较小的量,微调C,将C从0.6调到0.61呢?
这比先前得到的答案要好得多。我们得到输出值61,比起正确答案 62.137,这只差了1.137。
因此,最后的这次尝试告诉我们,应该适度调整C值。如果输出值越 来越接近正确答案,即误差值越来越小,那么我们就不要做那么大的调 整。使用这种方式,我们就可以避免像先前那样得到超调的结果。同样,读者无需为如何使用确切的方式算出C值而分心,请继续关注 这种持续细化误差值的想法,我们建议将修正值取为误差值的百分比。直 觉上,这是正确的:大误差意味着需要大的修正值,小误差意味着我们只 需要小小地微调C的值。 无论你是否相信,我们刚刚所做的,就是走马观花地浏览了一遍神经 网络中学习的核心过程。我们训练机器,使其输出值越来越接近正确的答 案。 这值得读者停下来,思考一下这种方法,我们并未像在学校里求解数 学和科学问题时所做的一样一步到位,精确求解问题。相反,我们尝试得 到一个答案,并多次改进答案,这是一种非常不同的方法。一些人将这种 方法称为迭代,意思是持续地、一点一点地改进答案。

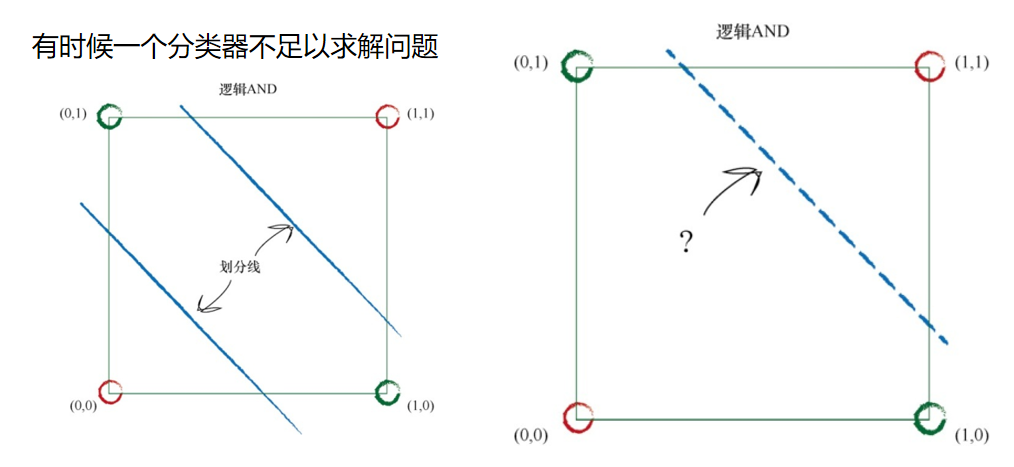
分类器和预测器
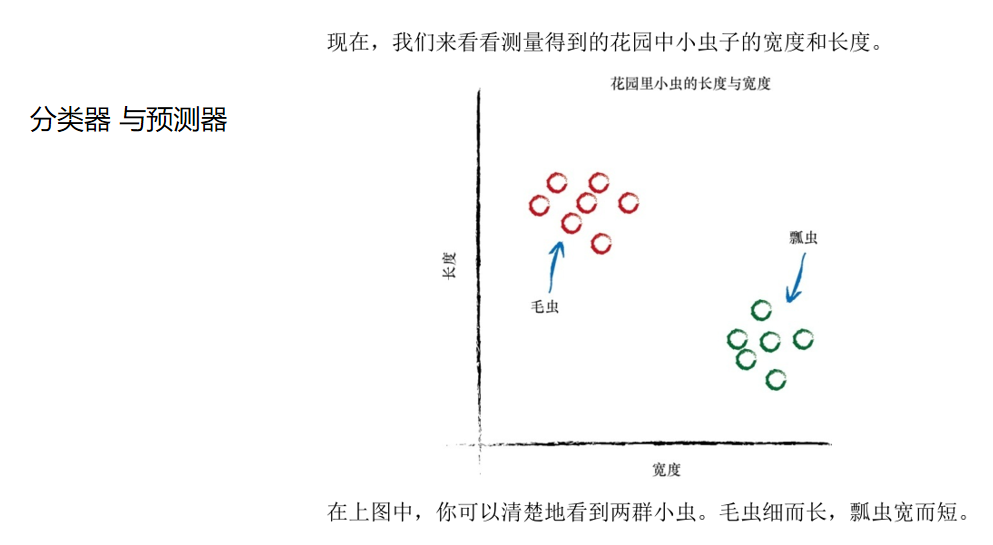
因为上述的简单机器接受了一个输入,并做出应有的预测,输出结 果,所以我们将其称为预测器。我们根据结果与已知真实示例进行比较所 得到的误差,调整内部参数,使预测更加精确。
在上图中,你可以清楚地看到两群小虫。毛虫细而长,瓢虫宽而短。 你还记得给定千米数,预测器试图找出正确的英里数这个示例吗?
这台预测器的核心有一个可调节的线性函数。当你绘制输入输出的关系图 时,线性函数输出的是直线。可调参数C改变了直线的斜率。
如果我们在这幅图上画上一条直线,会发生什么情况呢? 虽然我们不能使用先前将千米数转换成英里数时的同样方式,但是我 们也许可以使用直线将不同性质的事物分开。
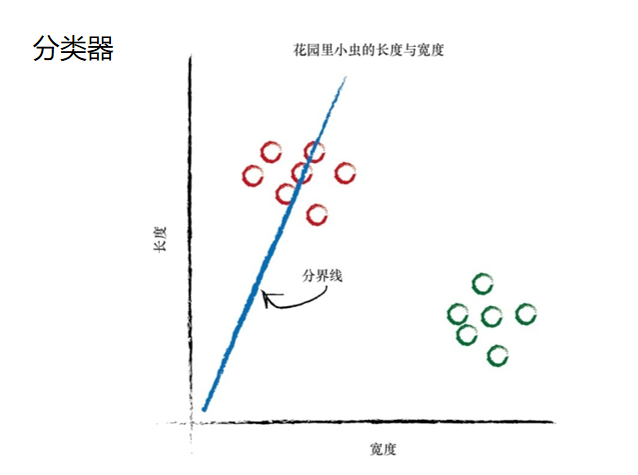
在上图中,如果直线可以将毛虫与瓢虫划分开来,那么这条直线就可 以根据测量值对未知小虫进行分类。由于有一半的毛虫与瓢虫在分界线的 同一侧,因此上述的直线并没有做到这一点。 让我们再次调整斜率,尝试不同的直线,看看会发生什么情况。 这一次,这条直线真是一无是处!它根本没有将两种小虫区分开来。 让我们再试一次:
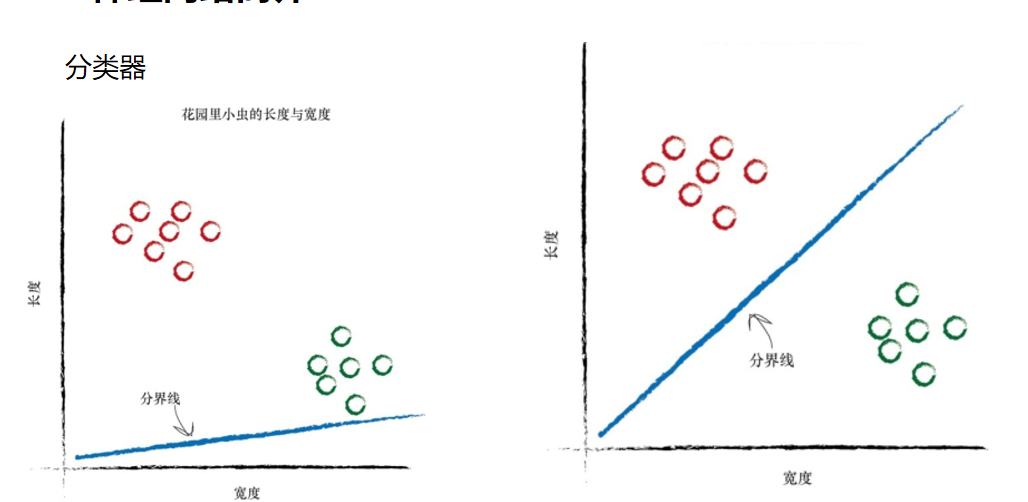
这条直线好多了!这条直线整齐地将瓢虫与毛虫区分开来了。现在, 我们可以用这条直线作为小虫的分类器。我们假设没有未经发现的其他类型的小虫,现在来说,这样假设是没 有问题的,因为我们只是希望说明构建一台简单的分类器的思路。 设想一下,下一次,计算机使用机器手臂抓起一只新的小虫,测量其 宽度和长度,然后它可以使用上面的分界线,将小虫正确归类为毛虫或瓢 虫。
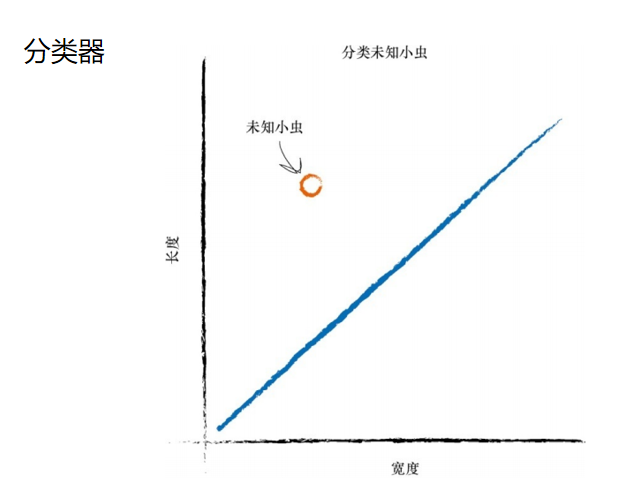
我们已经看到了,在简单的预测器中,如何使用线性函数对先前未知 的数据进行分类。 但是,我们忽略了一个至关重要的因素。我们如何得到正确的斜率 呢?我们如何改进不能很好划分这两种小虫的分界线呢? 这个问题的答案处于神经网络学习的核心地带。让我们继续。
训练分类器
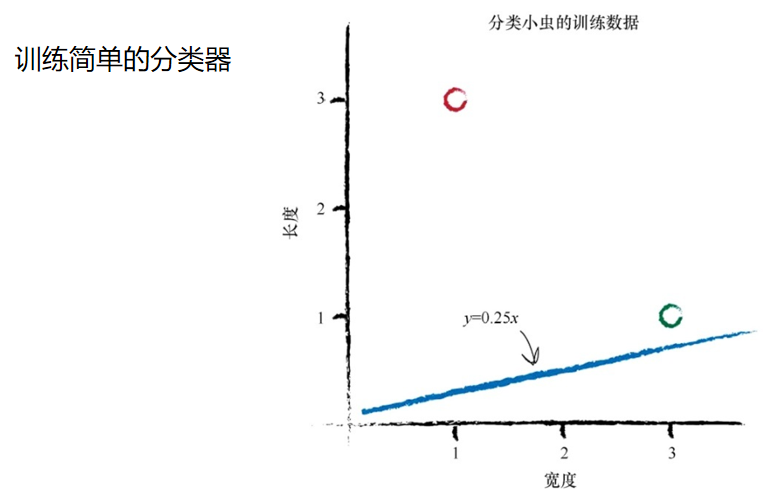
1.让我们尝试从A = 0.25开始,分界线为y = 0.25x 。我们可以观察到直线y = 0.25x 不是一台很好的分类 器。这条直线未将两种类型的小虫区分开来。
由于瓢虫也处在直线之上, 因此我们不能说“如果小虫在直线之上,则这是一条毛虫”。
直观上,我们观察到需要将直线向上移动一点,但是我们要抵制诱 惑,不能通过观察图就画出一条合适的直线。
我们希望能够找到一种可重 复的方法,也就是用一系列的计算机指令来达到这个目标。计算机科学家 称这一系列指令为算法(algorithm)。
让我们观察第一个训练样本数据:宽度为3.0和长度为1.0瓢虫。如果我 们使用这个实例测试函数y =Ax ,其中x 为3.0,我们得到:
y =0.25*3.0= 0.75
在这个函数中,我们将参数A设置为初始随机选择的值0.25,表明对于 宽度为3.0的小虫,其长度应为0.75。但是,由于训练数据告诉我们这个长 度必须为1.0,因此我们知道这个数字太小了。
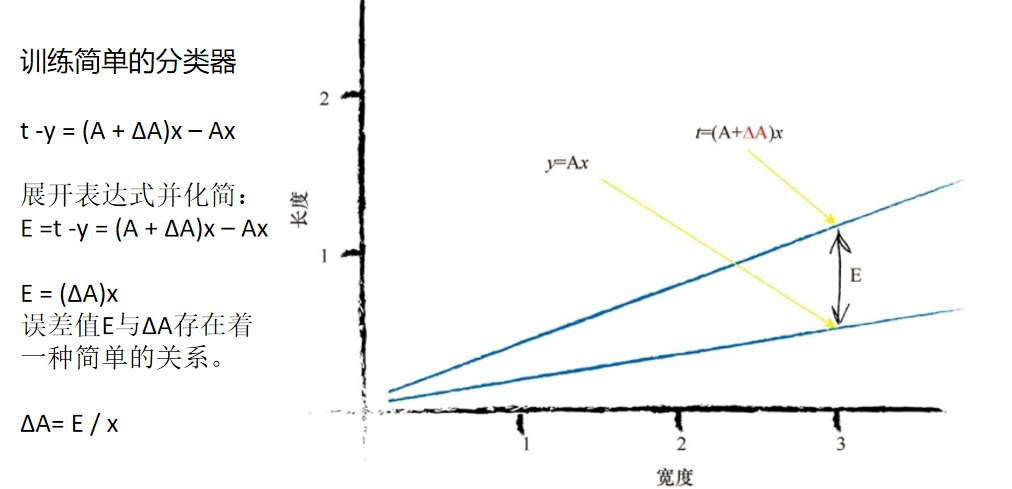
1.现在,我们需要对这个E做些什么,才能更好地指导我们调整参数A 呢?这是一个重要的问题。 在这个任务中,让我们退一步再想一想。我们希望用y 中称为E的误差值,来搞清楚参数A所需改变的值。要做到这一点,我们需要知道两者的 关系。A与E是如何关联的呢?如果我们知道了这一点,那么我们就可以理 解更改一个值如何影响另一个值。 我们先从分类器的线性函数开始:
y =Ax
我们知道,A的初始猜测值给出了错误的y 值,y 值应该等于训练数据 给定的值。我们将正确的期望值t 称为目标值。为了得到t 值,我们需要稍 微调整A的值。
数学家使用增量符号Δ表示“微小的变化量”。
下面我们将这 个变化量写出来:
t = (A + ΔA)x
让我们在图中将其画出来,以使其更容易理解。在图中,你可以看到 新的斜率
(A+ΔA)。
2.请记住,误差值E是期望的正确值与基于A的猜测值计算出来的值之间 的差值。
也就是说,E等于t -y 。
我们将这个过程写出来,这样就清楚了:
t -y = (A + ΔA)x - Ax
展开表达式并化简:
E =t -y = (A + ΔA)x - Ax
E = (ΔA)x
这是多么美妙啊!误差值E与ΔA存在着一种简单的关系。这种关系如 此简单,以至于我认为这是错的,但实际上这是正确的。无论如何,这种 简单的关系让我们的工作变得相对容易。
根据误差值E,我们希望知道需要将A调整多少,才能改进直线的斜 率,得到一台更好的分类器。要做到这一点,我们只要重新调整上一个方 程,
将 ΔA算出: ΔA= E / x
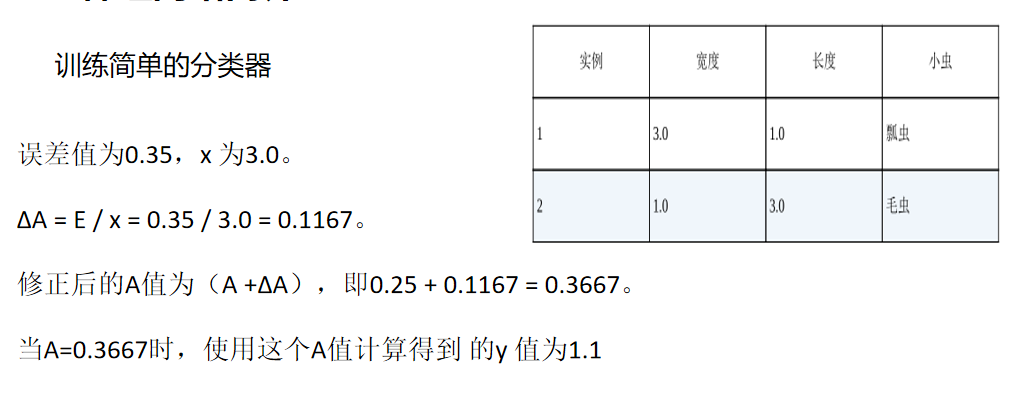
误差计算
x为3.0 设初始斜率参数A=0.25,则预测的y为0.25*3=0.75,
期望的t为1.1,因为要比1.0大一些,按照误差公式
E =t -y = (A + ΔA)x - Ax
E = (ΔA)x
E = 1.1-0.75 = (ΔA)x = 0.35
误差值为0.35,x 为3.0。可修正的斜率参数为
ΔA = E / x = 0.35 / 3.0 = 0.1167。
这意 味着当前的A = 0.25需要加上0.1167。
这也意味着,修正后的A值为(A +ΔA),即0.25 + 0.1167 = 0.3667。当A=0.3667时,使用这个A值计算得到 的y 值为1.1,正如你所期望的,这就是我们想要的目标值。 唷!我们做到了!我们找到了基于当前的误差值调整参数的方法。
目前我们已经完成了一个实例训练,让我们从下一个实例中学习。
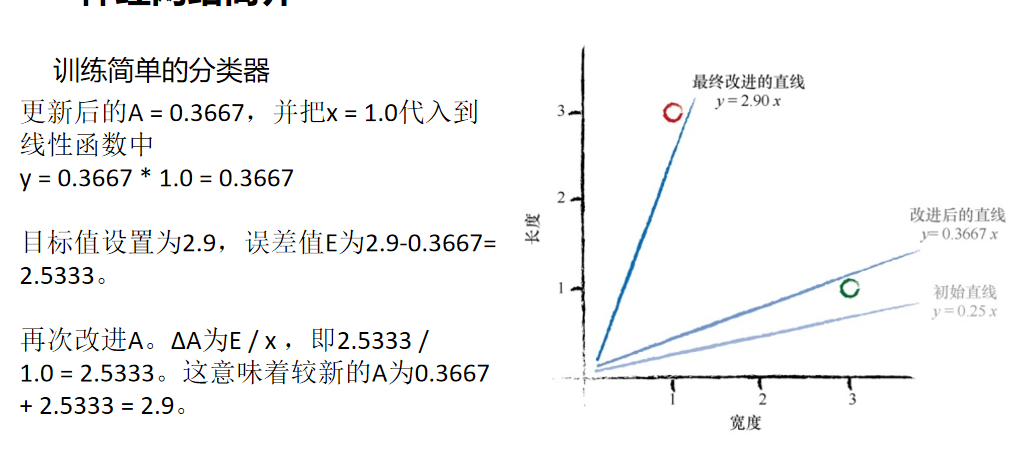
我们已经完成了一个实例训练,让我们从下一个实例中学习。
此时,我们已知正确值对为x = 1.0和y = 3.0。
当线性函数使用更新后的A = 0.3667,并把x = 1.0代入到线性函数中 时,让我们观察会发生什么情况。我们得到
y = 0.3667 * 1.0 = 0.3667。
这与 训练样本中y = 3.0相去甚远。
基于与先前同样的推理,我们希望直线不要经过训练数据,而是稍微高于或低于训练数据,我们将所需的目标值设置为2.9。这样,毛虫的训练样本就在直线上方,而不是在直线之上。
误差值E为2.9-0.3667= 2.5333。
比起先前,这个误差值更大,但是如果仔细想想,迄今为止,我们只使用一个单一的训练样本对线性函数进行训练,很明显,这使得直线偏向于这个单一的样本。
与我们先前所做的一样,让我们再次改进A。
ΔA为E / x ,即2.5333 /1.0 = 2.5333。
这意味着较新的A为0.3667 + 2.5333 = 2.9。这也意味着,对于x = 1.0,函数得出了2.9的答案,这正是所期望的值。
这个训练量有点大了,因此,让我们再次暂停,观察我们已经完成的内容。下图显示出了初始直线、向第一个训练样本学习后的改进直线和向第二个训练样本学习后的最终直线。
这是什么情况啊!看着这幅图,我们似乎并没有做到让直线以 我们所希望的方式倾斜。这条直线没有整齐地划分出瓢虫和毛虫。 好了,我们理解了先前的诉求。改进直线,以得出各个所需的y 值。 这种想法有什么错误呢?如果我们继续这样操作,使用各个训练数据 样本进行改进,那么我们所得到的是,最终改进的直线与最后一次训练样 本非常匹配。实际上,最终改进的直线不会顾及所有先前的训练样本,而 是抛弃了所有先前训练样本的学习结果,只是对最近的一个实例进行了学习。 如何解决这个问题呢?

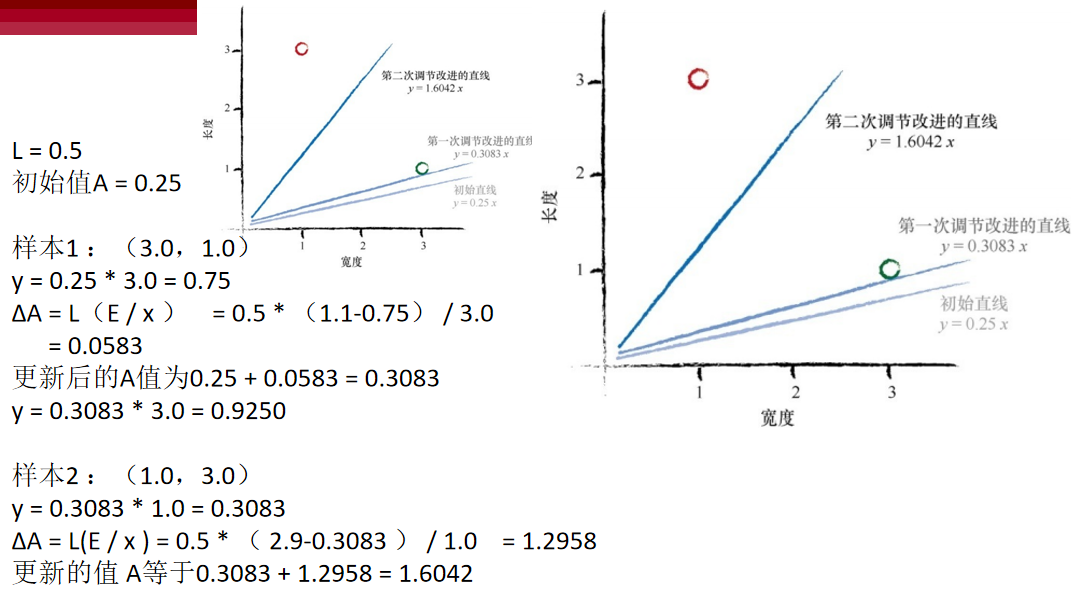
调节系数通常被称为学习率(learning rate),在此,我们称之为L。 我们就挑L = 0.5作为一个合理的系数开始学习过程。简单说来,这就意味 着我们只更新原更新值的一半。
再一次重复上述过程,我们有一个初始值A = 0.25。
使用第一个训练样 本,我们得到
y = 0.25 * 3.0 = 0.75,
期望值为1.1,得到了误差值0.35。
ΔA = L(E / x )= 0.5 * 0.35 / 3.0 = 0.0583。
更新后的A值为0.25 + 0.0583 = 0.3083。
尝试使用新的A值计算训练样本,
在x = 3.0时,得到y = 0.3083 * 3.0 = 0.9250。
现在,由于这个值小于1.1,因此这条直线落在了训练样本错误的 一边,但是,如果你将这视为后续的众多调整步骤的第一步,则这个结果 不算太差。与初始直线相比,这条直线确实向正确方向移动了。
我们继续使用第二个训练数据实例,x = 1.0。使用A = 0.3083,我们得 到
y = 0.3083 * 1.0 = 0.3083。
所需值为2.9,因此误差值是2.9-0.3083= 2.5917。
ΔA = L(E / x ) = 0.5 * 2.5917 / 1.0 = 1.2958。
当前,第二个更新的值 A等于0.3083 + 1.2958 = 1.6042。
让我们再次观察初始直线、改进后的直线和最终直线,观察这种有节 制的改进是否在瓢虫和毛虫区域之间是否得到了更好的分界线。


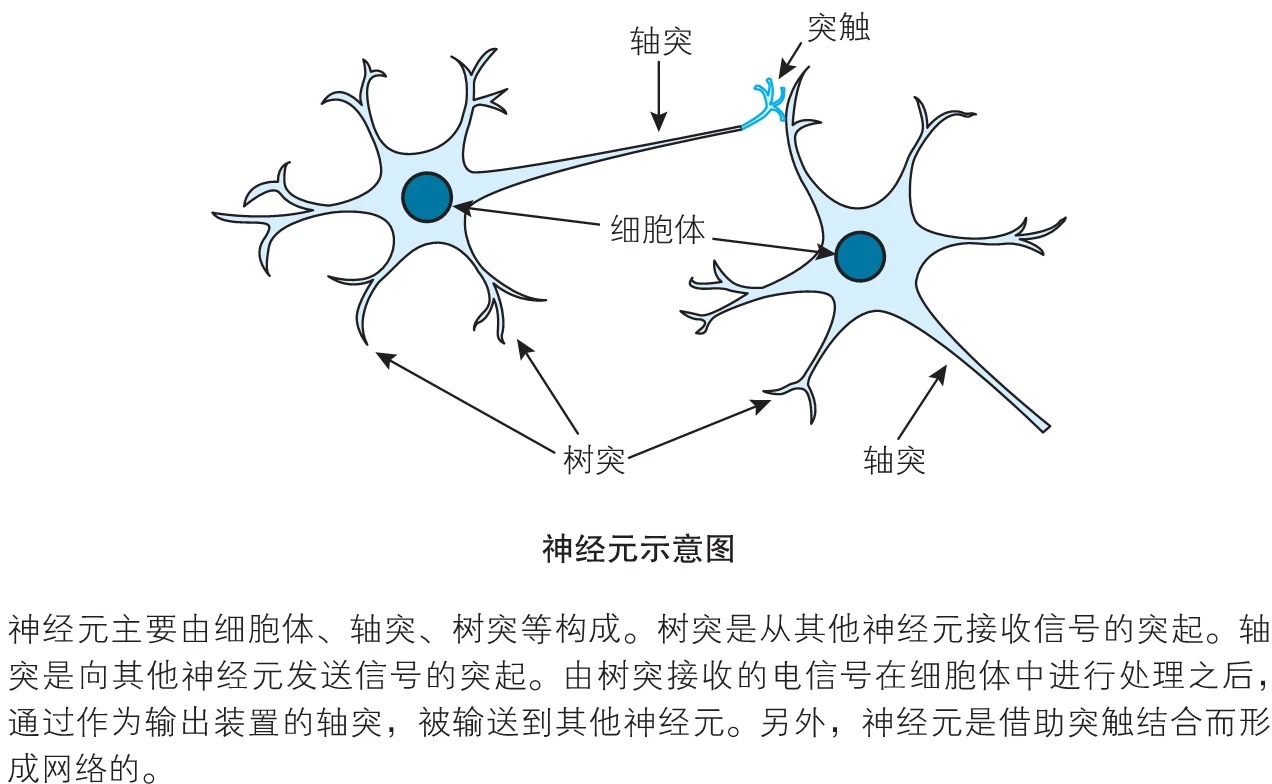
神经元
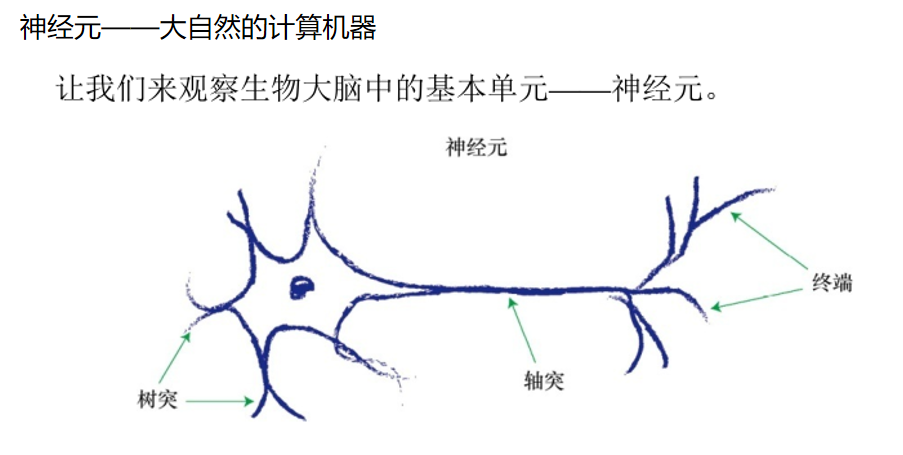
虽然神经元有各种形式,但是所有的神经元都是将电信号从一端传输 到另一端,沿着轴突,将电信号从树突传到树突。然后,这些信号从一个 神经元传递到另一个神经元。这就是身体感知光、声、触压、热等信号的 机制。来自专门的感觉神经元的信号沿着神经系统,传输到大脑,而大脑 本身主要也是由神经元构成的。
我们需要多少个神经元才能执行相对复杂的有趣任务呢? 一般说来,能力非常强的人类大脑有大约1000亿个神经元!一只果蝇 拥有约10万个神经元,能够飞翔、觅食、躲避危险、寻找食物以及执行许 多相当复杂的任务。10万个神经元,这个数字恰好落在了现代计算机试图复制的范围内。一只线虫仅仅具有302个神经元,与今天的数字计算机资源 相比,简直就是微乎其微!但是一只线虫能够完成一些相当有用的任务, 而这任务对于尺寸大得多的传统计算机程序而言却难以完成。

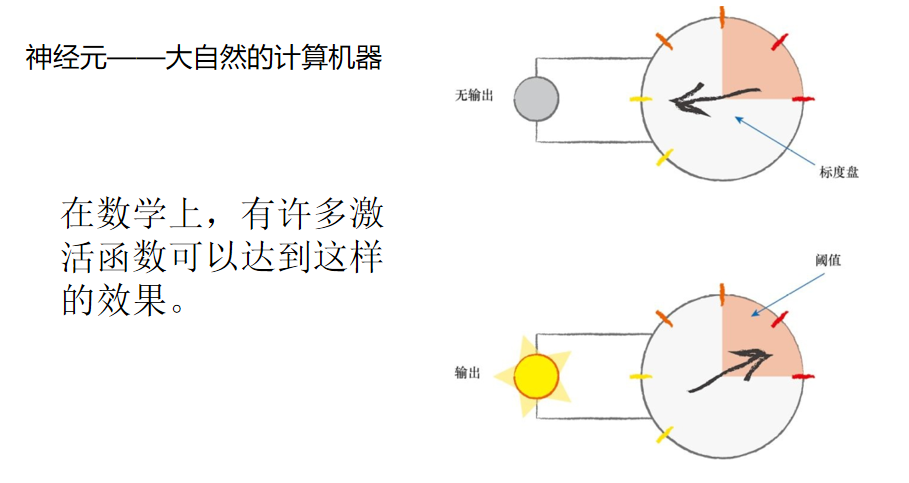
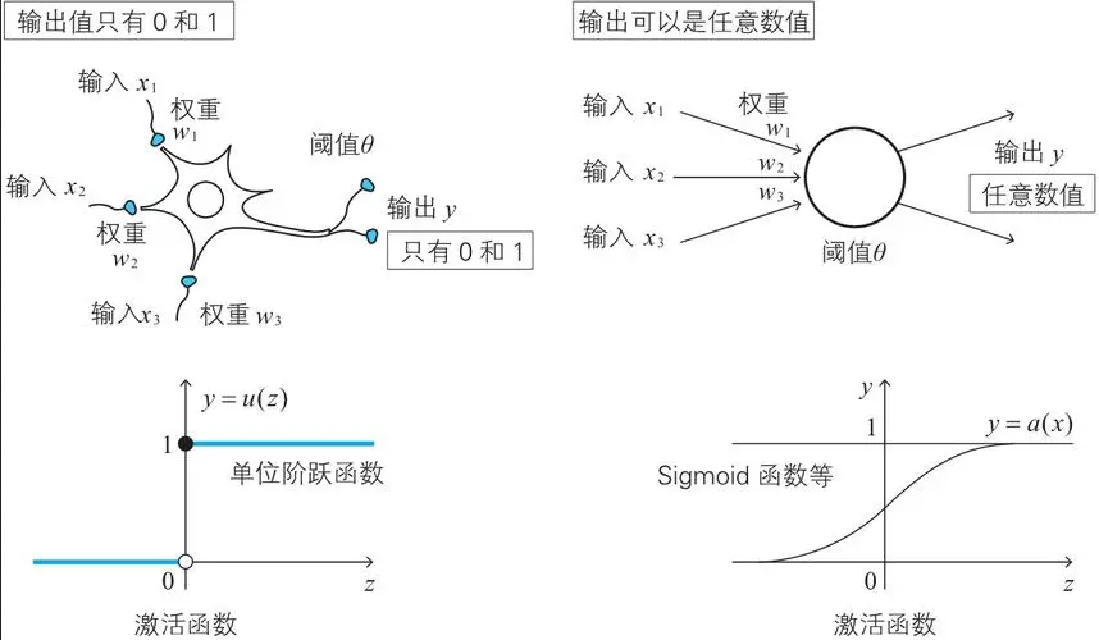
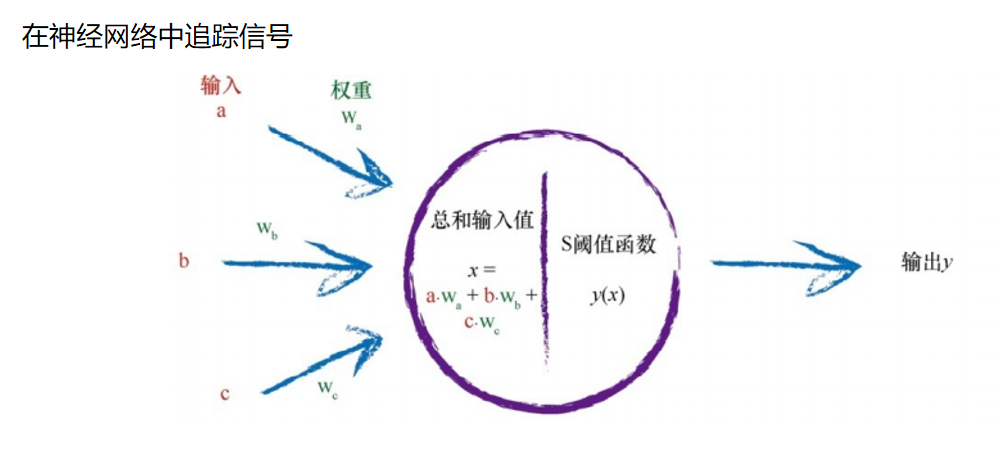
1.神经元表示为线性函数吗?虽然这是个好主意,但是不可以这样做。生物神经元与简单的线性函数不一样,不能简单地对输入做出的响应,生成输出。也就是说,它的输出不能采用这种形式:输出=(常数*输入)+(也许另一常数)。
观察表明,神经元不会立即反应,而是会抑制输入,直到输入增强,强大到可以触发输出。你可以这样认为,在产生输出之前,输入必须到达一个阈值。就像水在杯中——直到水装满了杯子,才可能溢出。直观上,这是有道理的——神经元不希望传递微小的噪声信号,而只是传递有意识的明显信号。下图说明了这种思想,只有输入超过了阈值(threshold),足够接通电路,才会产生输出信号。

字母e是数学常数 2.71828
e是自然对数的底数
自然对数是以e为底的对数函数,e是一个无理数,约等于2.718281828
由于任何数的0次方都等于1,因此当x 为0时,e -x 为1。因 此y 变成了1/(1 + 1),为1/2。此时,基本S形函数在y = ½时,对y 轴进行 切分。 我们使用这种S函数,而不使用其他可以用于神经元输出的S形函数, 还有另一个非常重要的原因,那就是,这个S函数比起其他S形函数计算起 来容易得多,在后面的实践中,我们会看到为什么。 让我们回到神经元,并思考我们如何建模人工神经。
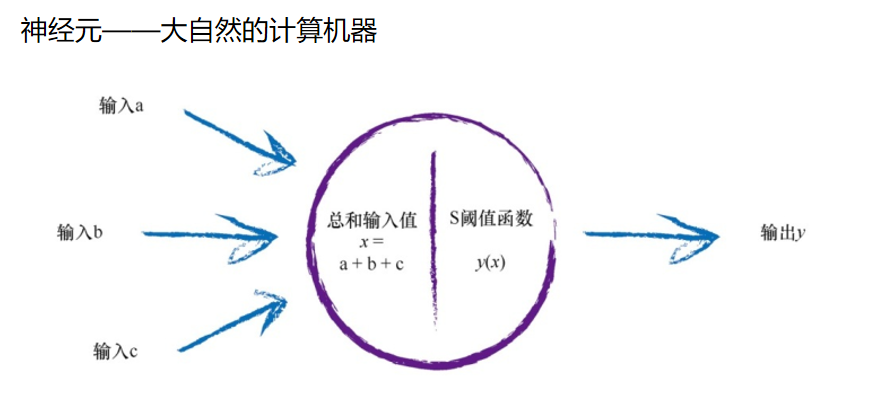
如果组合信号不够强大,那么S阈值函数的效果是抑制输出信号。如 果总和x 足够大,S函数的效果就是激发神经元。有趣的是,如果只有其中 一个输入足够大,其他输入都很小,那么这也足够激发神经元。更重要的 是,如果其中一些输入,单个而言一般大,但不是非常大,这样由于信号 的组合足够大,超过阈值,那么神经元也能激发。这给读者带来了一种直 观的感觉,即这些神经元也可以进行一些相对复杂、在某种意义上有点模 糊的计算。
树突收集了这些电信号,将其组合形成更强的电信号。如果信号足够 强,超过阈值,神经元就会发射信号,沿着轴突,到达终端,将信号传递 给下一个神经元的树突。下图显示了使用这种方式连接的若干神经元。
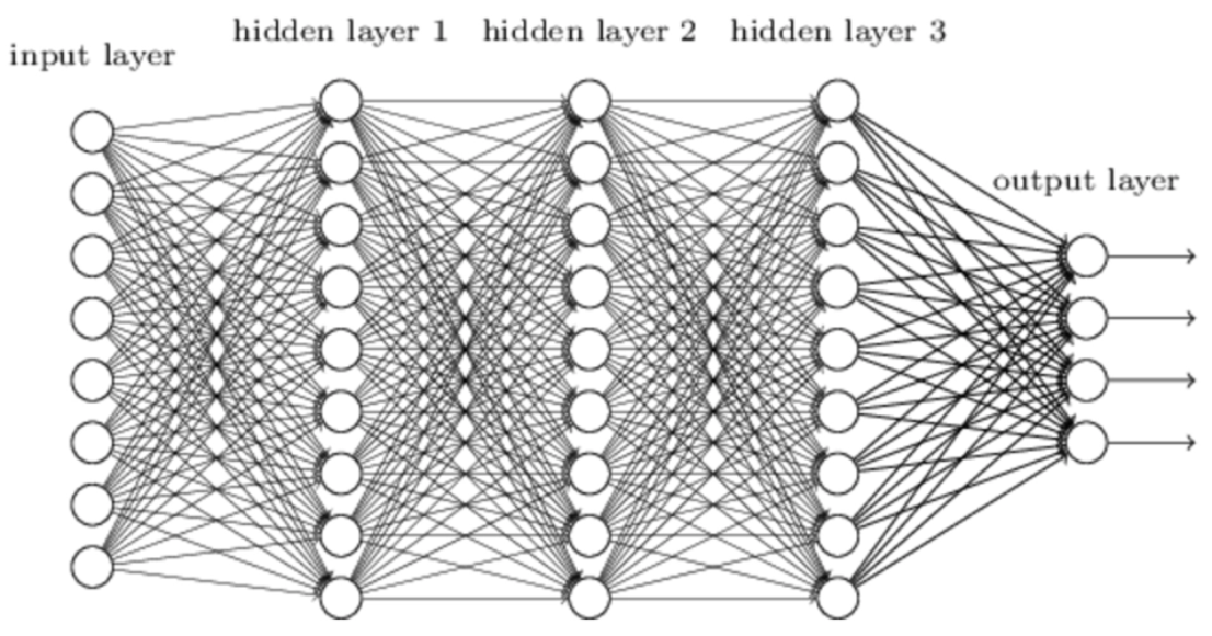
需要注意的一点是,每个神经元接受来自其之前多个神经元的输入, 并且如果神经元被激发了,它也同时提供信号给更多的神经元。 将这种自然形式复制到人造模型的一种方法是,构建多层神经元,每 一层中的神经元都与在其前后层的神经元互相连接。
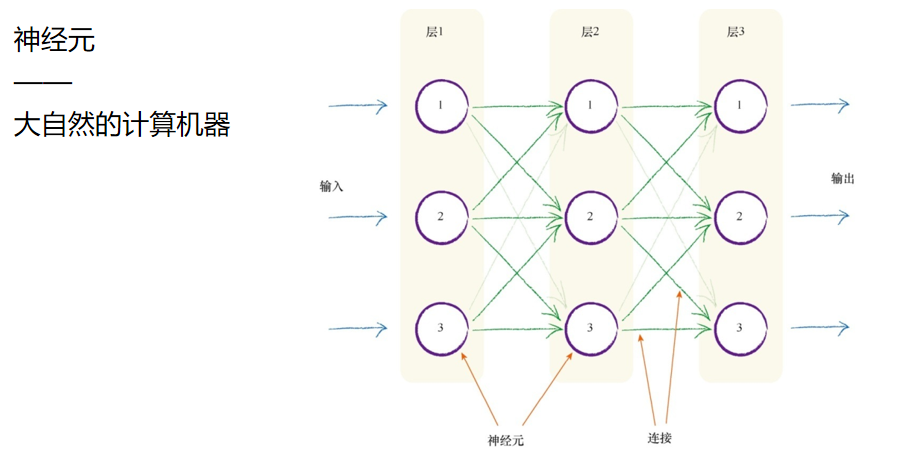
你可以看到三层神经元,每一层有三个人工神经元或节点。你还可以 看到每个节点都与前一层或后续层的其他每一个节点互相连接。 这真是太棒了!
但是,这看起来很酷的体系架构,哪一部分能够执行 学习功能呢?针对训练样本,我们应该如何调整做出反应呢?有没有和先 前线性分类器中的斜率类似的参数供我们调整呢? 最明显的一点就是调整节点之间的连接强度。
在一个节点内,我们可 以调整输入的总和或S阈值函数的形状,但是比起简单地调整节点之间的 连接强度,调整S阀值函数的形状要相对复杂。
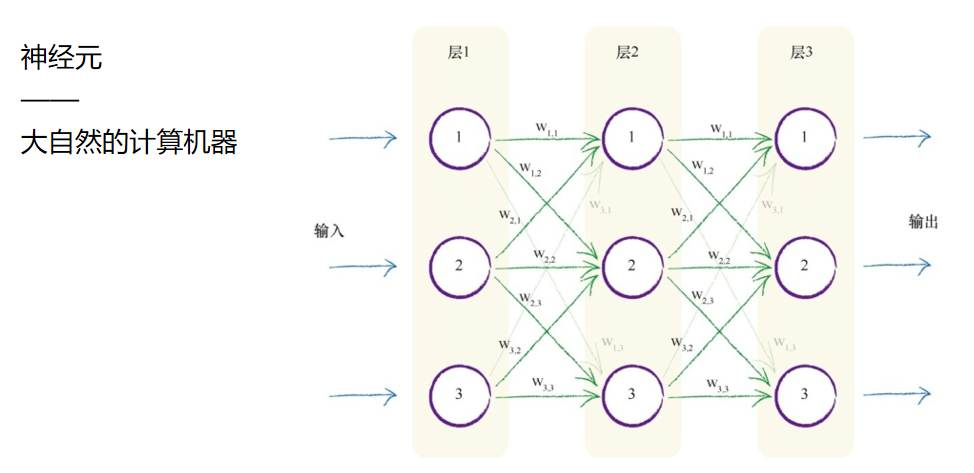
本图再一次显示了连接的节点,但是这次在每个连接上显示了相关的权重。较小的权重 将弱化信号,而较大的权重将放大信号。
此处,我需要解释一下权重符号旁边的有趣小数字(即下标)。简单 说来,权重w 2,3 与前一层节点2传递给下一层的节点3的信号相关联。
因此,权重w 1,2 减小或放大节点1传递给下一层节点2的信号。为了详细说明 这种思路,下图突出显示了第一层和第二层之间的两条连接。
你可能有充分的理由来挑战这种设计,质问为什么必须把前后层的每 一个神经元与所有其他层的神经元互相连接,并且你甚至可以提出各种创 造性的方式将这些神经元连接起来。我们不采用创造性的方式将神经元连 接起来,原因有两点,第一是这种一致的完全连接形式事实上可以相对容 易地编码成计算机指令,第二是神经网络的学习过程将会弱化这些实际上 不需要的连接(也就是这些连接的权重将趋近于0),因此对于解决特定任 务所需最小数量的连接冗余几个连接,也无伤大雅。
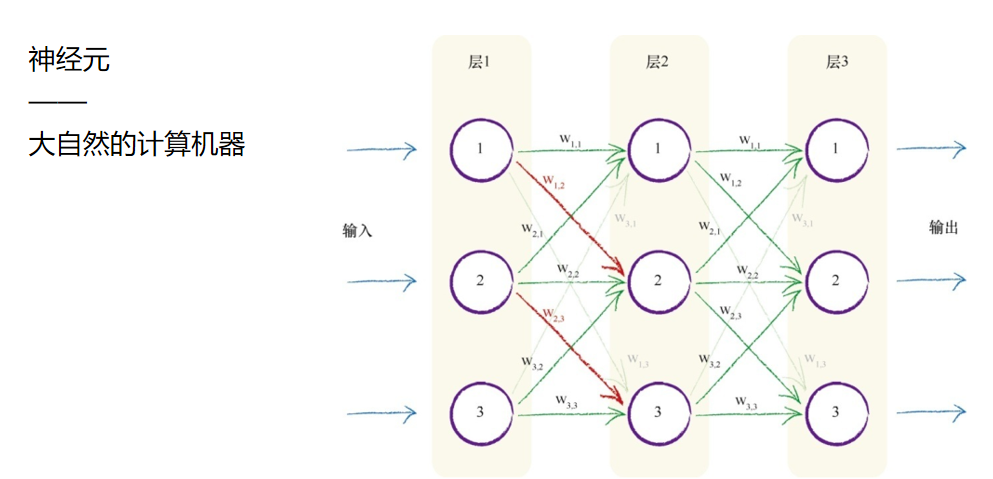
我们的意思是什么呢?这意味着,随着神经网络学习过程 的进行,神经网络通过调整优化网络内部的链接权重改进输出,一些权重 可能会变为零或接近于零。零或几乎为零的权重意味着这些链接对网络的 贡献为零,因为没有传递信号。零权重意味着信号乘以零,结果得到零, 因此这个链接实际上是被断开了。

在神经网络中追踪信号
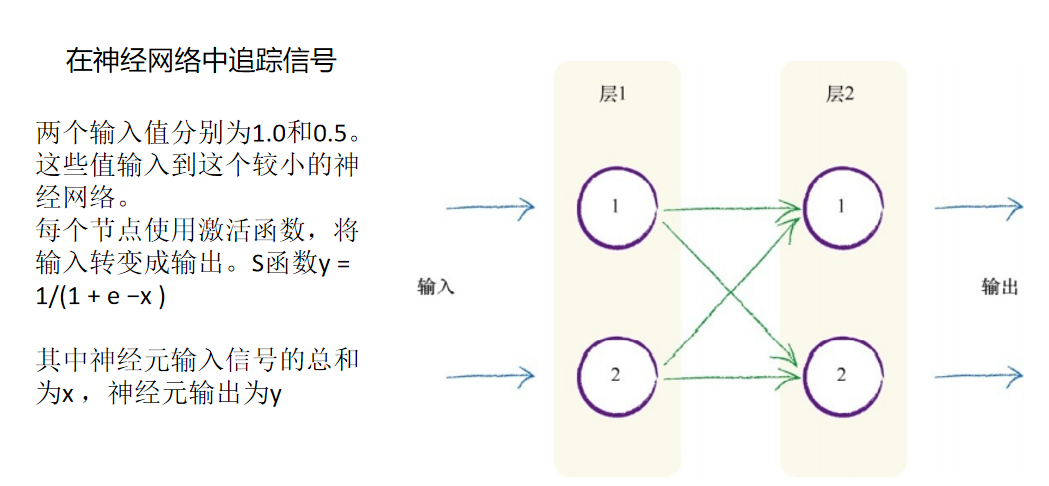

些随机权重
这也是我们在先前简单的线性分类器中 选择初始斜率值时所做的事情。随着分类器学习各个样本,随机值就可以 得到改进。对于神经网络链接的权重而言,这也是一样的。
让我们开始计算吧!
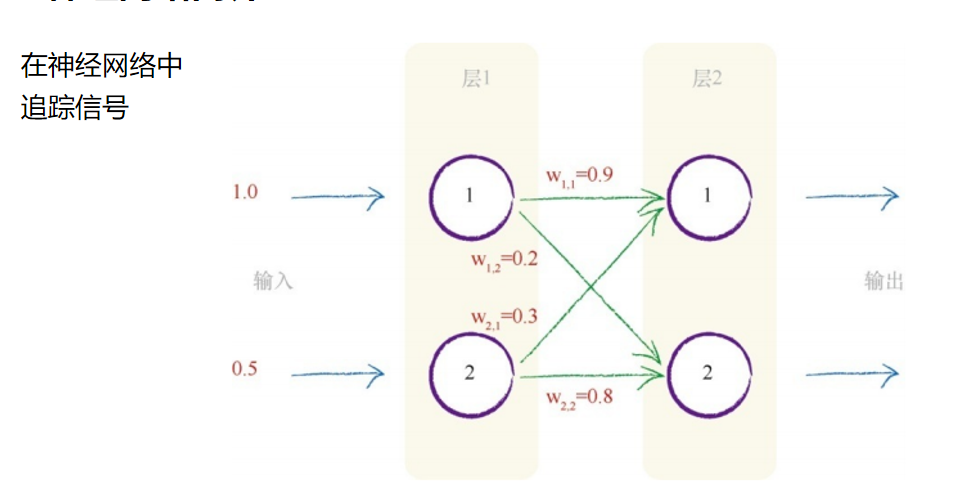
第一层节点是输入层,这一层不做其他事情,仅表示输入信号。也就 是说,输入节点不对输入值应用激活函数。这没有什么其他奇妙的原因, 自然而然地,历史就是这样规定的。神经网络的第一层是输入层,这层所 做的所有事情就是表示输入,仅此而已。 第一层输入层很容易,此处,无需进行计算。
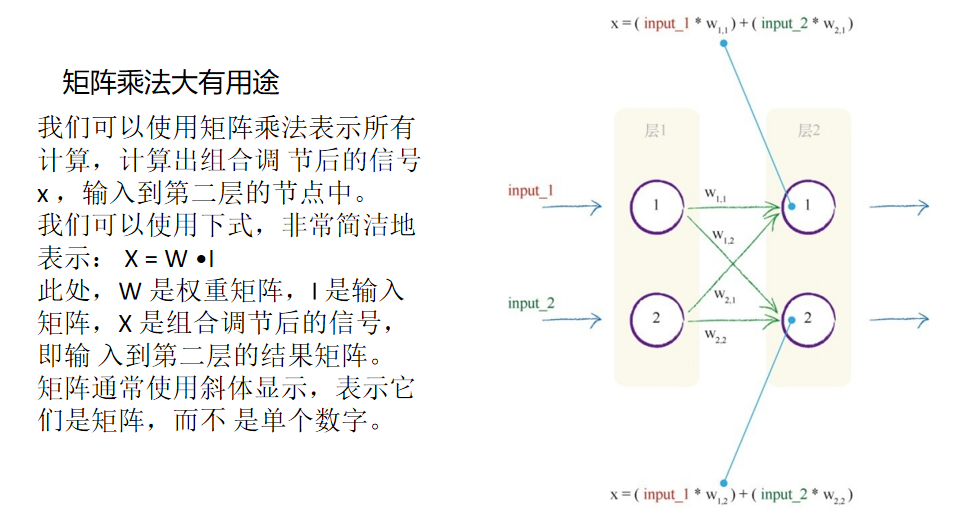
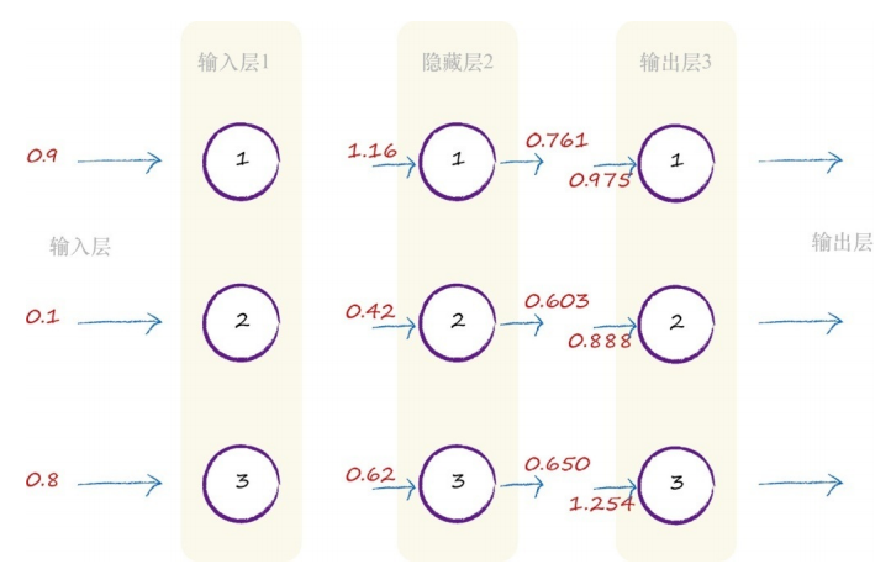
接下来的第二层,我们需要做一些计算。对于这一层的每个节点,我 们需要算出组合输入。还记得S函数y = 1 /(1 + e -x )吗?这个函数中的x 表示一个节点的组合输入。此处组合的是所连接的前一层中的原始输出, 但是这些输出得到了链接权重的调节。下图就是我们先前所看到的一幅 图,但是现在,这幅图包括使用链接权重调节输入信号的过程。

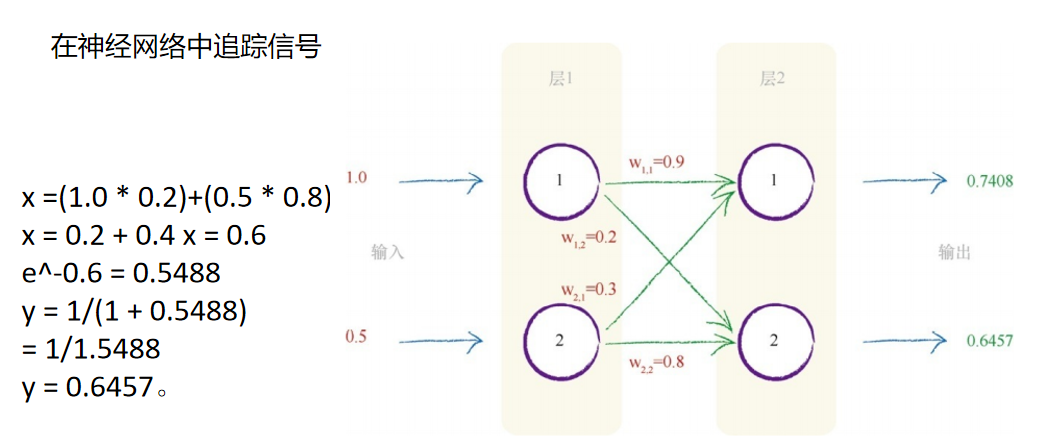
因此,首先让我们关注第二层的节点1。第一层输入层中的两个节点连 接到了这个节点。这些输入节点具有1.0和0.5的原始值。来自第一个节点的 链接具有0.9的相关权重,来自第二个节点的链接具有0.3的权重。因此,组 合经过了权重调节后的输入,如下所示: x = (第一个节点的输出链接权重)+(第二个节点的输出链接权重)
x =(1.0 * 0.9)+(0.5 * 0.3) = 0.9 + 0.15 = 1.05
我们不希望看到:不使用权重调节信号,只进行一个非常简单的信号 相加1.0 + 0.5。权重是神经网络进行学习的内容,这些权重持续进行优 化,得到越来越好的结果。
现在,我们已经得到了x =1.05,这是第二层第一个节点的组合 调节输入。最终,我们可以使用激活函数y = 1 /(1 + e -x )计算该节点的 输出。你可以使用计算器来进行这个计算。答案为y = 1 /(1 + 0.3499)= 1 / 1.3499。因此,y = 0.7408。
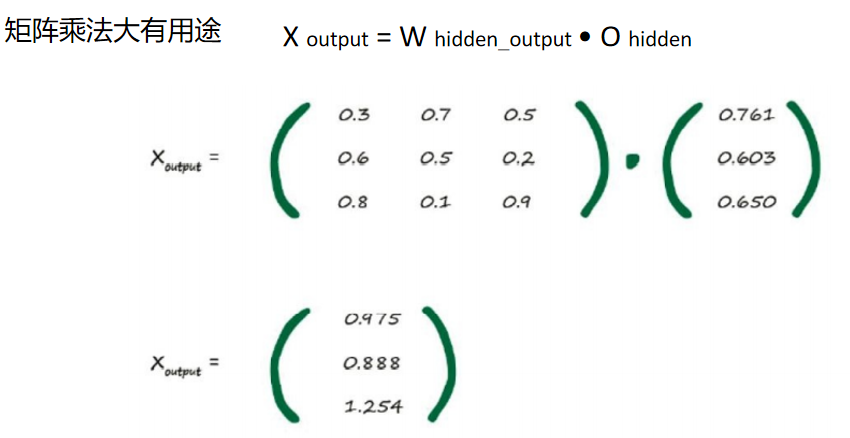
矩阵乘法

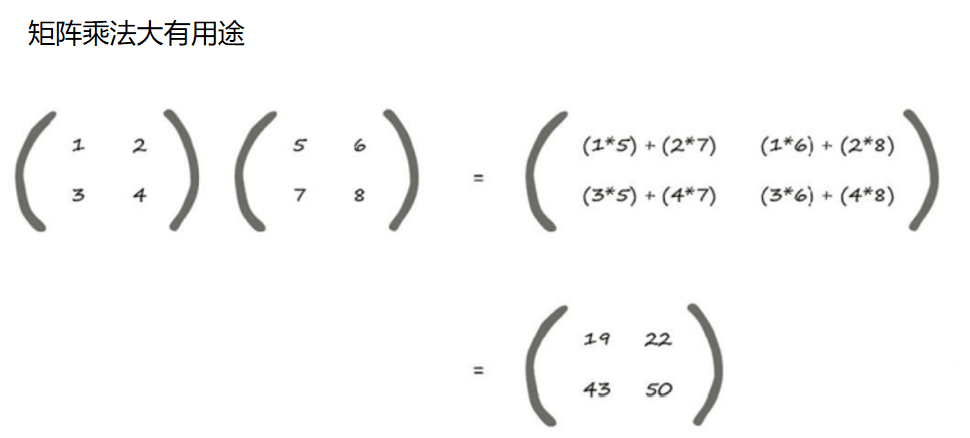
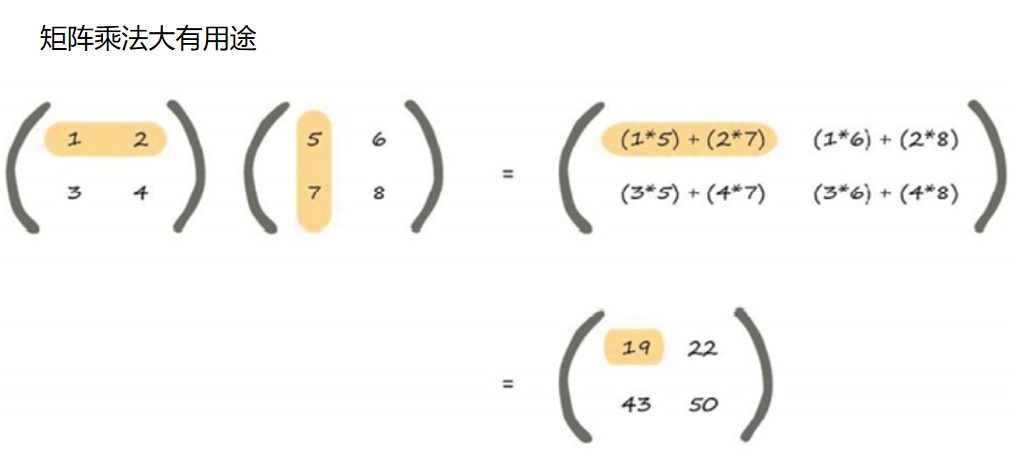
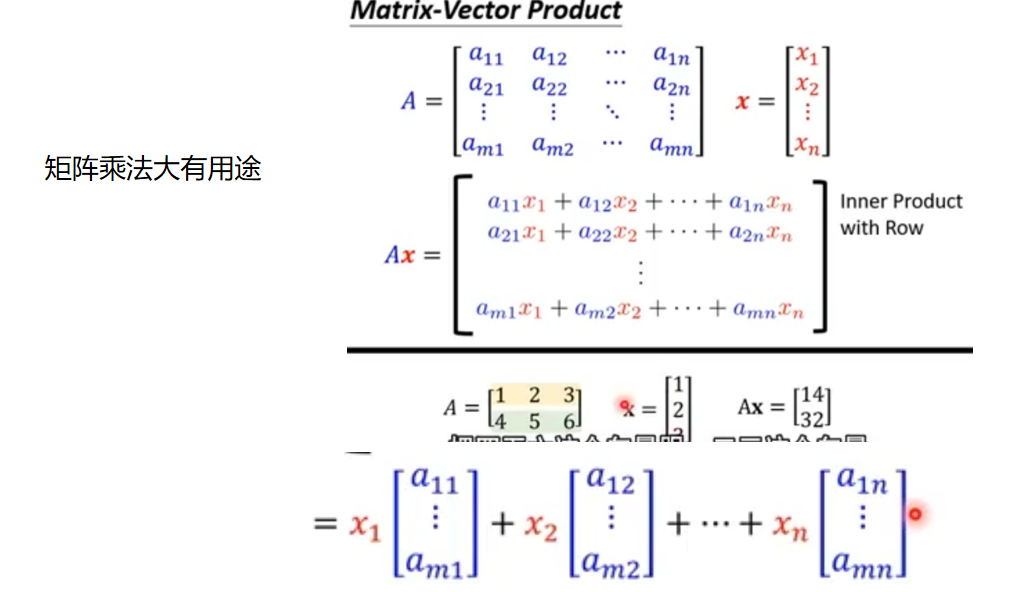

我们不需要在乎每一层有多少个节点。如果我们有较多的节 点,那么矩阵将会变得较大。但是,我们不需要写出长长的一串数字或大 量的文字。我们可以简单地写为W • I ,不管 I 有2个元素还是有200个元素。 现在,如果计算机编程语言可以理解矩阵符号,那么计算机就可以完 成所有这些艰辛的计算工作,算出X = W • I ,而无需我们对每一层的每个 节点给出单独的计算指令。

比如说,我们有3层,我们 简单地再次进行矩阵乘法,使用第二层的输出作为第三层的输入。当然, 这个输出应该使用权重系数进行调节并进行组合。 理论已经足够了,现在,让我们看看这如何在一个真实示例中工作。 这一次,我们将使用3层、每一层有3个节点的、稍大一点的神经网络。

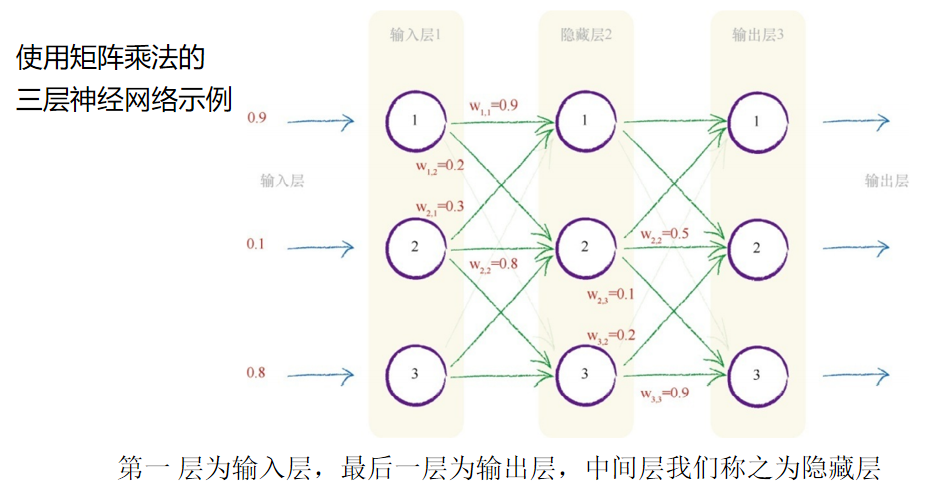
我们观察到了3个输入是 0.9、0.1和0.8。因此,输入矩阵I 为:
这很简单。这是输入层所做的所有事情,就是表示输入,因此我们已 经完成了第一层输入层。 接下来是中间的隐藏层。在这里,我们需要计算出输入到中间层每个 节点的组合(调节)信号。请记住,中间隐藏层的每个节点都与输入层的 每个节点相连,因此每个节点都得到输入信号的部分信息。我们不想再像 先前那样做大量的计算,我们希望尝试这种矩阵的方法。 正如我们刚才看到的,输入到中间层的组合调节信号为X = W •I ,其 中I 为输入信号矩阵,W 为权重矩阵。这个神经网络的I 、W 是什么样的 呢?图中显示了这个神经网络的一些权重,但是并没有显示所有的权重。 下图显示了所有的权重,同样,这些数字是随机列举的。在这个示例中, 权重没有什么特殊的含义。
你可以看到,第一个输入节点和中间隐藏层第一个节点之间的权重为 w 1,1 = 0.9,正如上图中的神经网络所示。同样,你可以看到输入的第二节 点和隐藏层的第二节点之间的链接的权重为w 2,2 = 0.8。图中并没有显示输 入层的第三个节点和隐藏层的第一个节点之间的链接,我们随机编了一个 权重w 3,1 = 0.4。 但是等等,为什么这个W 的下标我们写的是“input_hidden”呢?这是因 为W input_hidden 是输入层和隐藏层之间的权重。

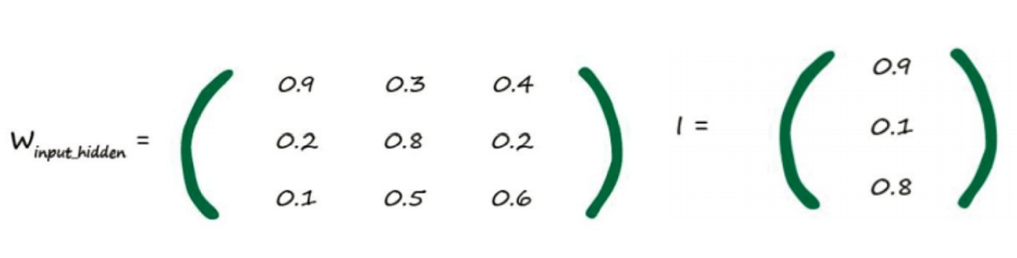
我们已经拥有了输入到中间隐藏层的组合调节输入值,它们为1.16、 0.42和0.62。

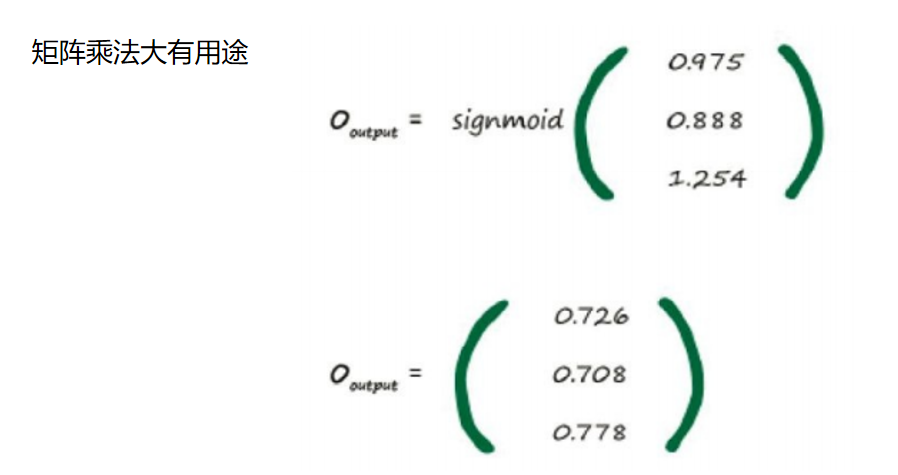
S函数为y = 1 /(1 + e -x ),
因 此,当x = 1.16时,e -1.16 是0.3135。
这意味着y = 1 /(1 + 0.3135)= 0.761。
你会看到,S函数的值域在0和1之间,所有的值都处在这个区间。
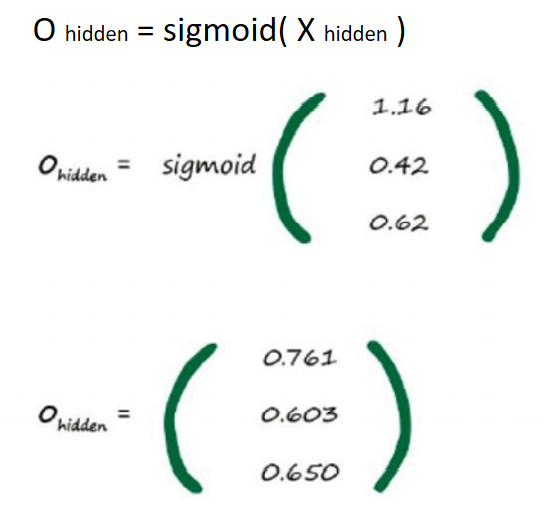
我们需要另一个权重矩阵来 表示隐藏层和输出层之间的链接,这个矩阵我们称之为W hidden_output 。
。这时第二个矩阵W hidden_output ,如先前一样,矩阵中填写了权 重。举个例子,同样你可以看到,隐藏层第三个节点和输出层第三个节点 之间链接的权重为w 3,3 = 0.9。

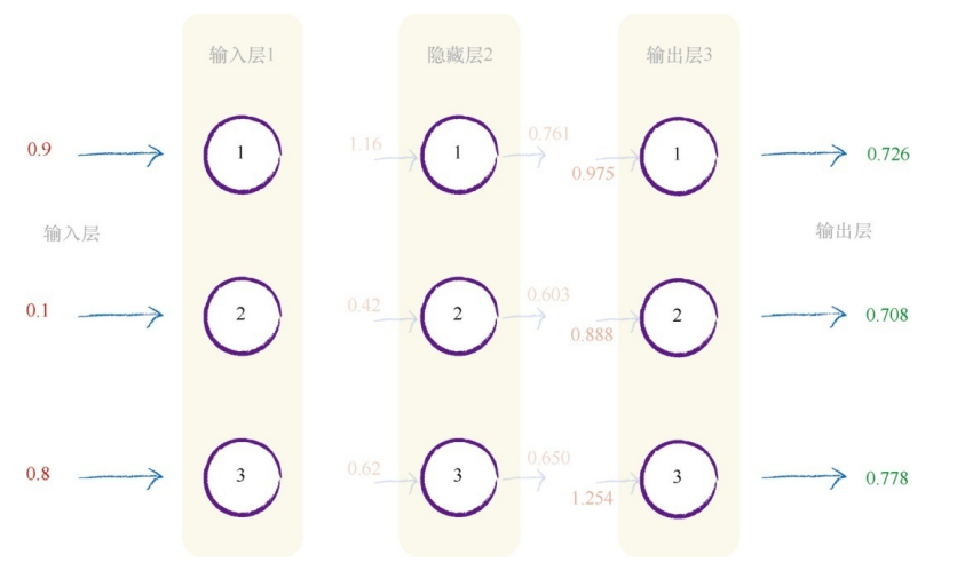
我们如何处理通过第三层的信号呢?我们可以采用与处理第二层信号 相同的方式进行处理,这没有任何实质的区别。我们仍然可以得到第三层 的输入信号,就像我们得到第二层的输入信号一样。我们依然使用激活函 数,使得节点的反应与我们在自然界中所见到的一样。因此,需要记住的 事情是,不管有多少层神经网络,我们都“一视同仁”,即组合输入信号, 应用链接权重调节这些输入信号,应用激活函数,生成这些层的输出信号。我们不在乎是在计算第3层、第53层或是第103层的信号,使用的方法 如出一辙。
X = W •I
学习来自多个节点的权重
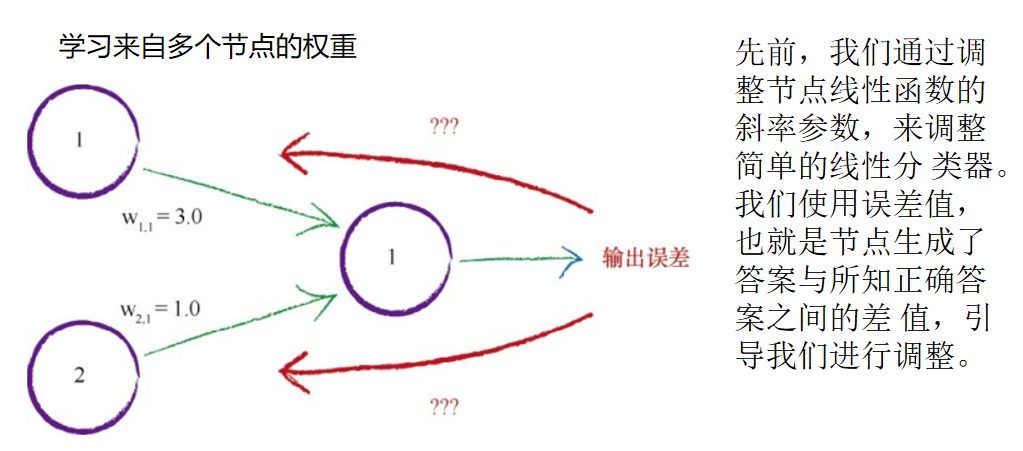
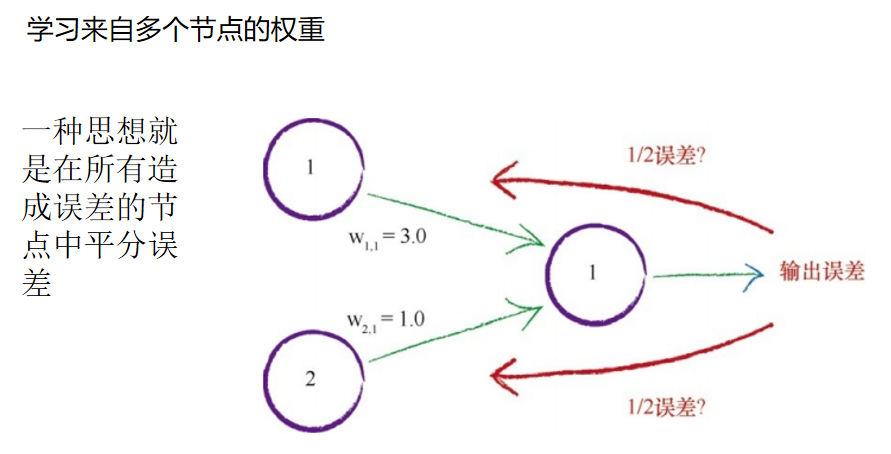
当只有一个节点前馈信号到输出节点,事情要简单得多。如果有两个 节点,我们如何使用输出误差值呢? 使用所有的误差值,只对一个权重进行更新,这种做法忽略了其他链 接及其权重,毫无意义。多条链接都对这个误差值有影响。 只有一条链接造成了误差,这种机会微乎其微。如果我们改变了已 经“正确”的权重而使情况变得更糟,那么在下一次迭代中,这个权重就会 得到改进,因此神经网络并没有失去什么。
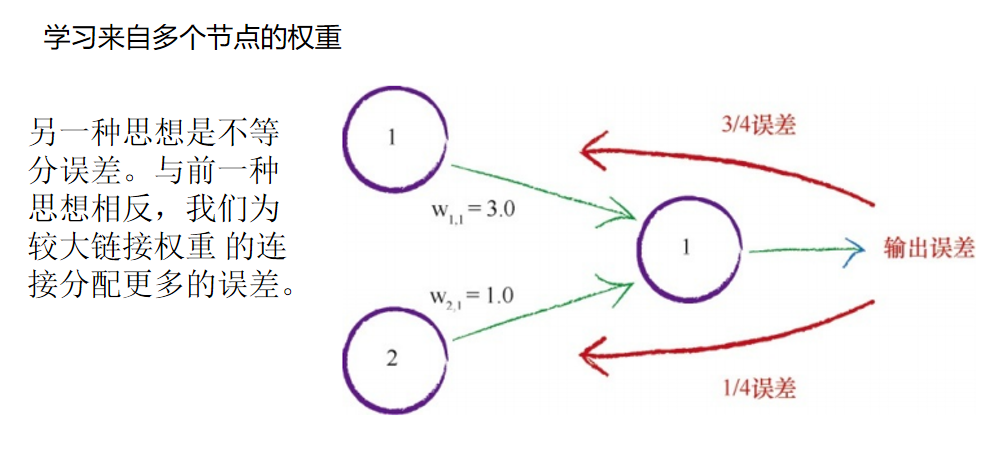
此处,有两个节点对输出节点的信号做出了贡献,它们的链接权重分 别是3.0和1.0。如果按权重比例分割误差,那么我们就可以观察到输出误差 的3/4应该可以用于更新第一个较大的权重,误差的1/4 可以用来更新较小 的权重。 我们可以将同样的思想扩展到多个节点。如果我们拥有100个节点链接 到输出节点,那么我们要在这100条链接之间,按照每条链接对误差所做贡 献的比例(由链接权重的大小表示),分割误差。

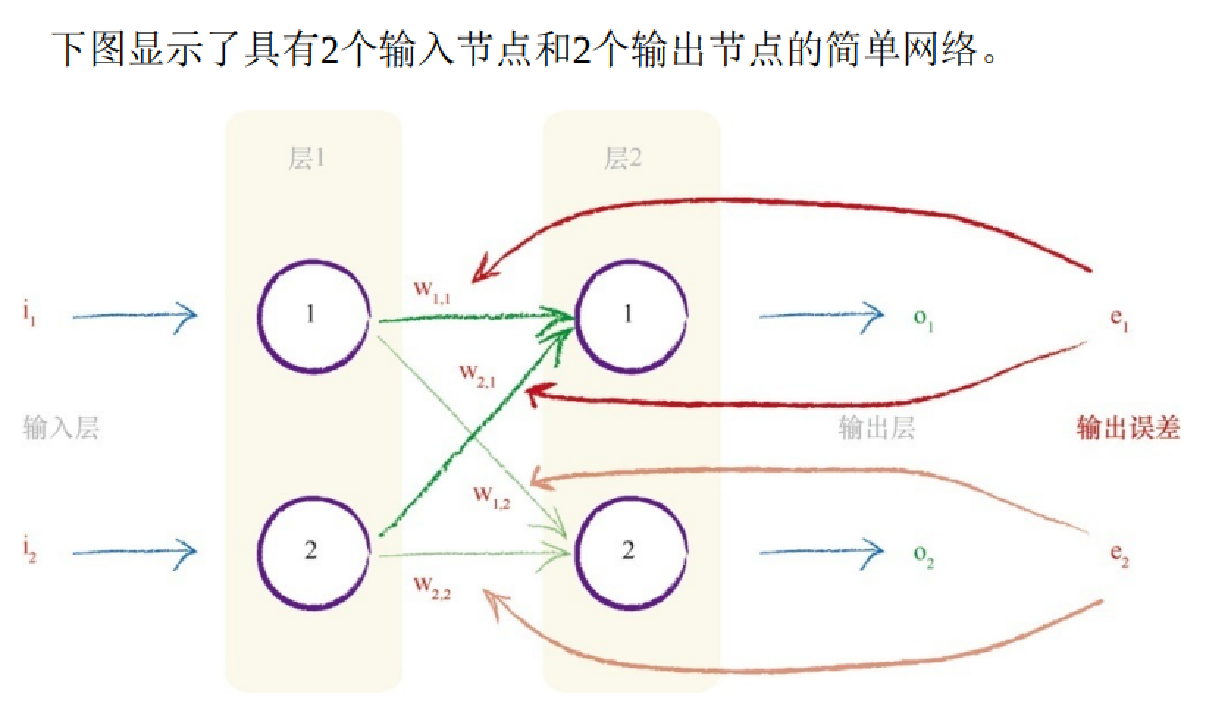
两个输出节点都有误差——事实上,在未受过训练的神经网络中,这 是极有可能发生的情况。你会发现,在网络中,我们需要使用这两个误差 值来告知如何调整内部链接权重。我们可以使用与先前一样的方法,也就 是跨越造成误差的多条链接,按照权重比例,分割输出节点的误差。 我们拥有多个节点这一事实并没有改变任何事情。
对于第二个输出节 点,我们只是简单地重复第一个节点所做的事情。为什么如此简单呢?这 是由于进入输出节点的链接不依赖于到另一个输出节点的链接,因此事情 就变得非常简单,在两组的链接之间也不存在依赖关系。
让我们再次观察此图,我们将第一个输出节点的误差标记为e1 。请记住,这个值等于由训练数据提供的所期望的输出值t1 与实际输出值o1 之间 的差。也就是,e 1 = ( t 1 -o 1 )。我们将第二个输出节点的误差标记为e2 。 从图中,你可以发现,按照所连接链接的比例,也就是权重w 1,1 和w 2,1 ,我们对误差e 1 进行了分割。类似地,我们按照权重w 1,2 和w 2,2 的比 例分割了e2 。

这些分数看起来可能令人有点费解,让我们详细阐释这些分数。
在所 有这些符号背后,思想非常简单,也就是误差e1 要分割更大的值给较大的 权重,分割较小的值给较小的权重。
如果w1,1 是w2,1 的2倍,比如说,w1,1 = 6,w2,1 = 3,那么用于更新w1,1 的e1 的部分就是6 /(6 + 3)= 6/9 = 2/3。
同时,这留下了1/3的e1 给较小的 权重w 2,1 ,我们可以通过表达式3 /(6 + 3)= 3/9确认这确实是1/3。
如果权重相等,正如你所期望的,各分一半。
让我们确定一下,假设 w1,1 = 4和w2,1 = 4,那么针对这种情况,e1 所分割的比例都等于4 /(4 + 4)= 4/8 = 1/2。
反向传播误差到更多层中
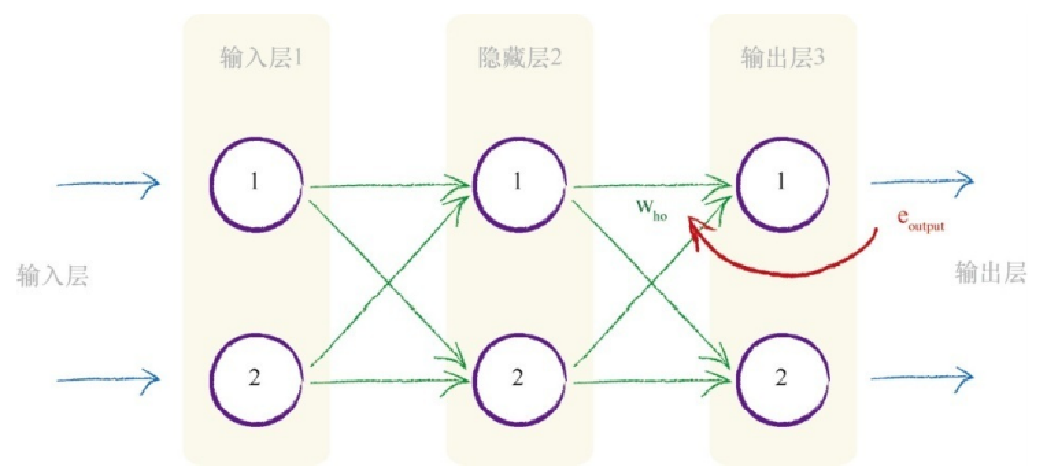
从右手边的最终输出层开始,往回工作,我们可以看到,我们使用在 输出层的误差值引导调整馈送到最终层的链接权重。更一般地,我们将输 出误差标记为eoutput ,将在输出层和隐藏层之间的链接权重标记为who 。通 过将误差值按权重的比例进行分割,我们计算出与每条链接相关的特定误 差值。
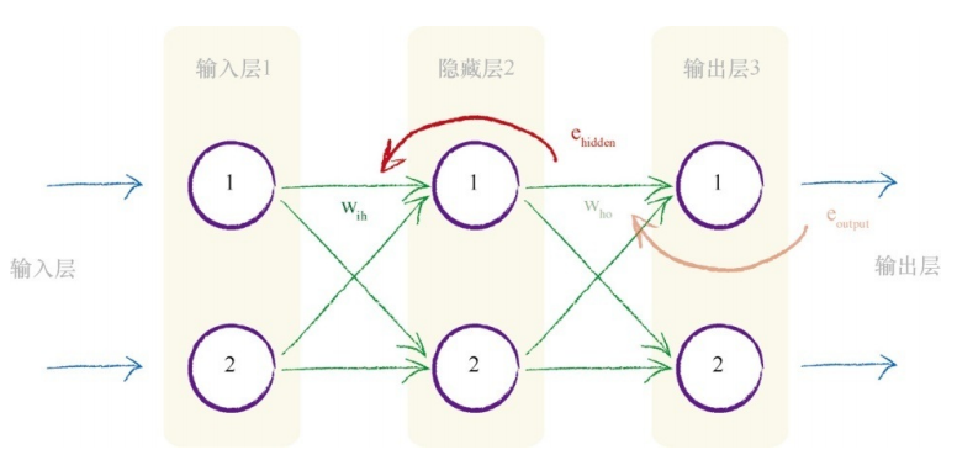
如果神经网络具有多个层,那么我们就从最终输出层往回工作,对每一层重复应用相同的思路。误差信息流具有直观意义。同样,你明白为什么我们称之为误差的反向传播了。
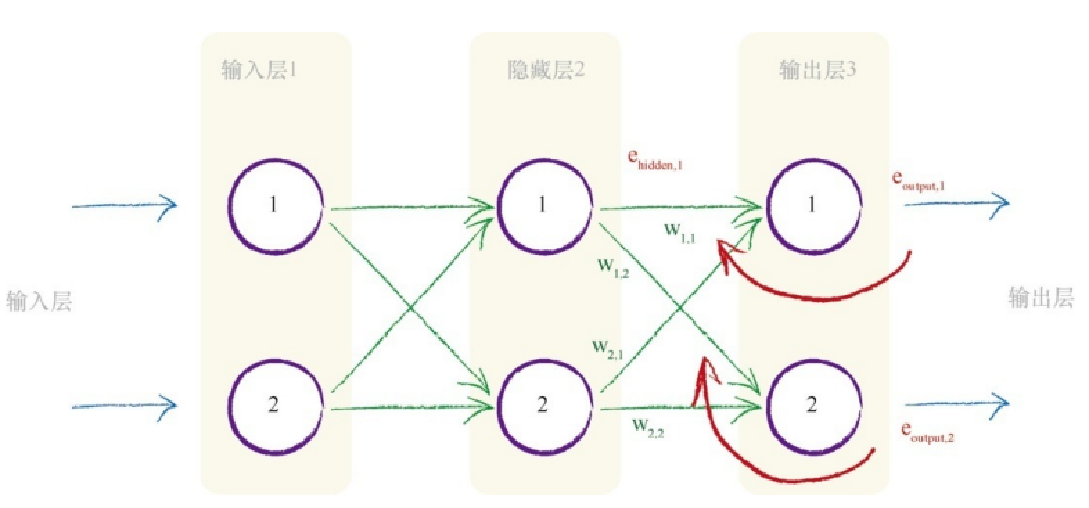
虽然你可以相对清楚地观察到发生的事情,但是我们还是要再次演示,确认一下。
我们需要隐藏层节点的误差,这样我们就可以使用这个误差更新前一层中的权重。我们称这个误差为ehidden 。但是,我们不需要明确地回答这些误差是什么。我们的训练样本数据只给出了最终输出节点的 目标值,因此不能说这个误差等于中间层节点所需目标输出值与实际输出 值之间的差。 训练样本数据只告诉我们最终输出节点的输出应该为多少,而没有告 诉我们任何其他层节点的输出应该是多少。
这是这道谜题的核心。 我们可以使用先前所看到的误差反向传播,为链接重组分割的误差。 因此,第一个隐藏层节点的误差是与这个节点前向连接所有链接中分割误 差的和。在上图中,我们得到了在权重为w1,1 的链接上的输出误差eoutput,1 的一部分,同时也得到了在权重为w1,2 的链接上第二个输出节点的输出误 差eoutput,2 的一部分。

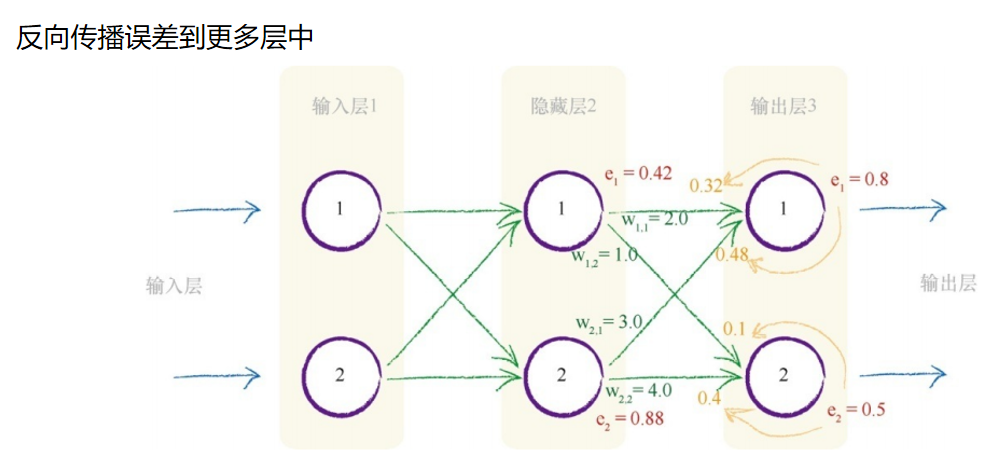
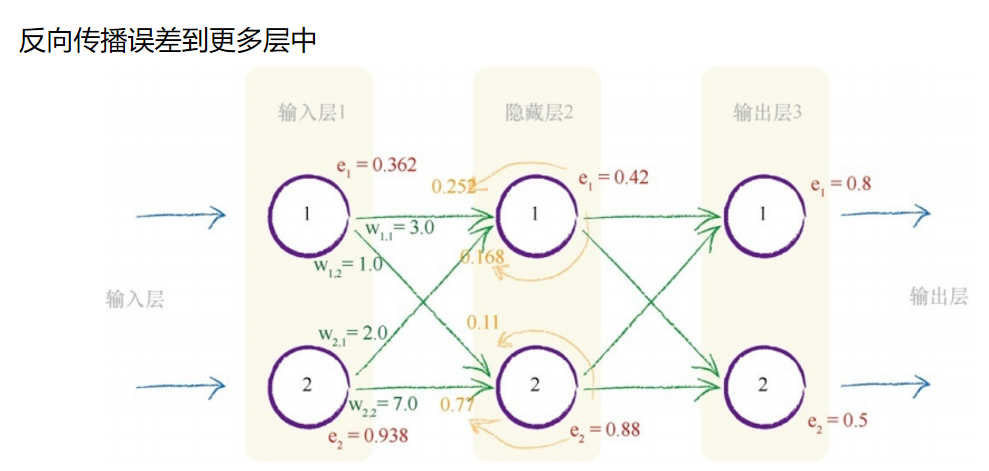
让我们演示一下反向传播的误差。你可以观察到,第二个输出层节点 的误差0.5,在具有权重1.0和4.0的两个链接之间,根据比例被分割成了0.1 和0.4。你也可以观察到,在隐藏层的第二个节点处的重组误差等于连接的 分割误差之和,也就是0.48与0.4的和,等于0.88。 如下图所示,我们进一步向后工作,在前一层中应用相同的思路。

使用矩阵乘法进行反向传播误差

第一件事与隐藏层中的第一个节点相关。如果你再次观察上图可以看到,在输出 层中,有两条路径对隐藏层第一个节点的误差做出了“贡献”。
沿着这些路 径,我们发现了误差信号
e1 * w1,1 / ( w1,1 + w2,1 )
和
e 2 * w 1,2 / ( w1,2 + w2,2 )。
现在,让我们看看隐藏层的第二个节点,同样,我们看到了有两条路径 对这个误差做出了“贡献”,我们得到误差信号
e1 * w2,1 / ( w2,1 + w1,1 )
和
e2 * w2,2 / ( w2,2 + w1,2 )。
先前,我们就已经明白了这些表达式是如何计算得 到的。
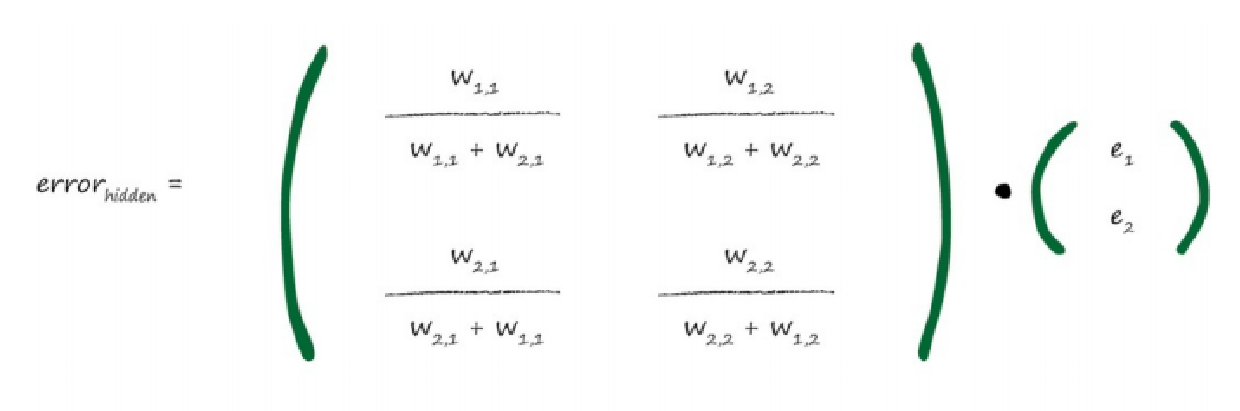
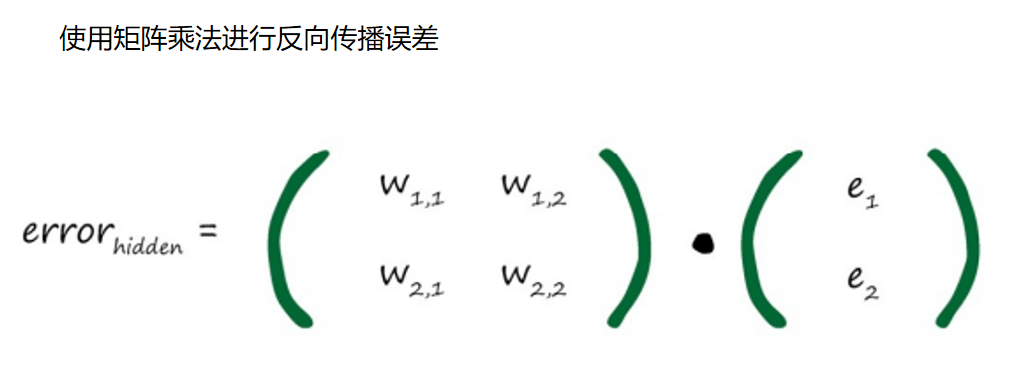
再次观察上面的表达式。你可以观察到,最重要的事情是输出误差与 链接权重wij 的乘法。较大的权重就意味着携带较多的输出误差给隐藏层。 这是非常重要的一点。这些分数的分母是一种归一化因子。如果我们忽略 了这个因子,那么我们仅仅失去后馈误差的大小。也就是说,我们使用简 单得多的
e1 * w1,1
来代替
e1 * w1,1 / ( w1,1 + w2,1 )。
如果我们采用这种方法,那么矩阵乘法就非常容易辨认。如下所示:

这个权重矩阵与我们先前构建的矩阵很像,但是这个矩阵沿对角线进 行了翻转,因此现在右上方的元素变成了左下方的元素,左下方的元素变 成了左上方的元素。我们称此为转置矩阵,记为wT 。 此处,有两个数字转置矩阵的示例,因此,我们可以清楚地观察到所 发生的事情。你可以看到,即使矩阵的行数和列数不同,也是可以进行转 置的。

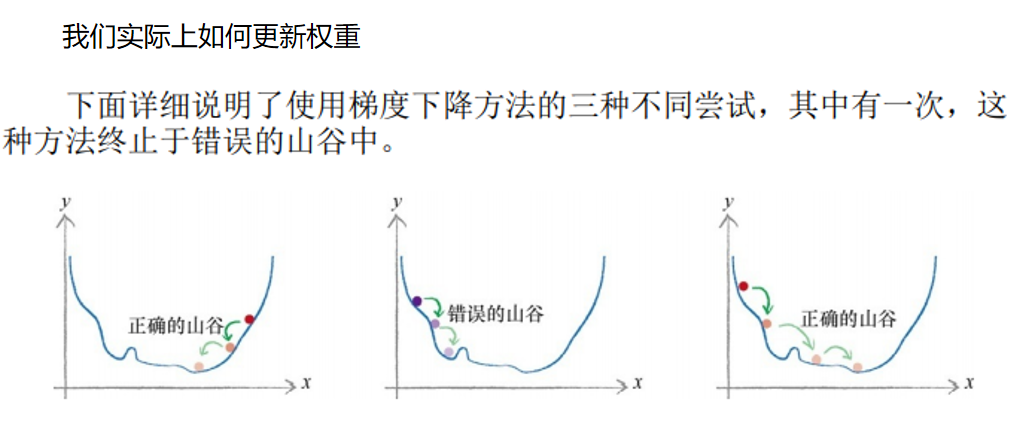
我们实际上如何更新权重

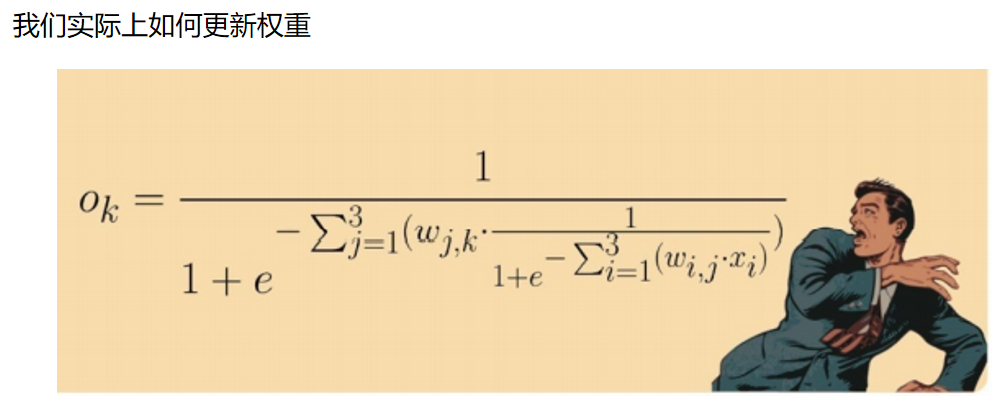
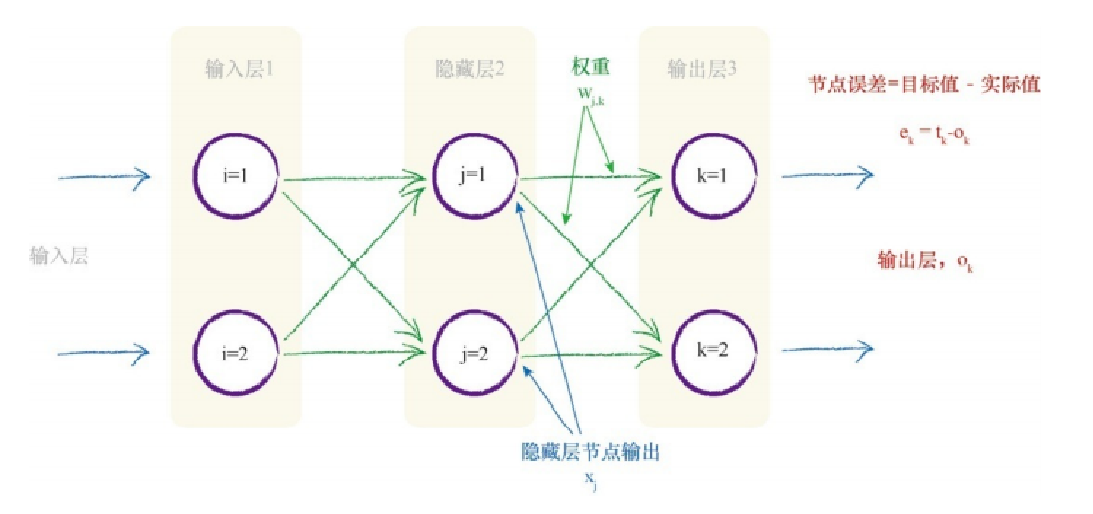
意识到这件事情的重要性,请观察下面这个“面目可憎”的表达式, 这是一个简单的3层、每层3个节点的神经网络,其中输入层节点的输出是 输入值和链接权重的函数。在节点i处的输入是xi ,连接输入层节点i到隐 藏层节点j的链接权重为wi,j ,类似地,隐藏层节点j的输出是xj ,连接隐 藏层节点j和输出层节点k的链接权重是wj ,k 。那个看似有趣的符号Σ b a 意味 着对在a和b值之间的所有后续表达式求和。

当我们陷入一个困难的问题而焦头烂额时,这不算是一个疯狂的想 法。我们称这种方法为暴力方法。有些人使用暴力方法试图破解密码,如 果密码是一个英文单词并且不算太长,那么由于没有太多的组合,一台快 速的家用计算机就可以搞定,因此这种方法是行之有效的。现在,假设每 个权重在-1和+1之间有1 000种可能的值,如0.501、-0.203和0.999。那么对 于3层、每层3个节点的神经网络,我们可以得到18个权重,因此有18 000 种可能性需要测试。如果有一个相对典型的神经网络,每层有500个节点, 那么我们需要测试5亿种权重的可能性。如果每组组合需要花费1秒钟计 算,那么对于一个训练样本,我们需要花费16年更新权重!对于1 000种训 练样本,我们要花费16 000年!

让我们详细解释一下这是什么意思。想象一下,一个非常复杂、有波 峰波谷的地形以及连绵的群山峻岭。在黑暗中,伸手不见五指。你知道你 是在一个山坡上,你需要到坡底。对于整个地形,你没有精确的地图,只 有一把手电筒。你能做什么呢?你可能会使用手电筒,做近距离的观察。 你不能使用手电筒看得更远,无论如何,你肯定看不到整个地形。你可以 看到某一块土地看起来是下坡,于是你就小步地往这个方向走。通过这种 方式,你不需要完整的地图,也不需要事先制定路线,你一步一个脚印, 缓慢地前进,慢慢地下山。
在数学上,这种方法称为梯度下降(gradient descent),你可以明白 这是为什么吧。在你迈出一步之后,再次观察周围的地形,看看你下一步 往哪个方向走,才能更接近目标,然后,你就往那个方向走出一步。你一 直保持这种方式,直到非常欣喜地到达了山底。梯度是指地面的坡度。你走的方向是最陡的坡度向下的方向。
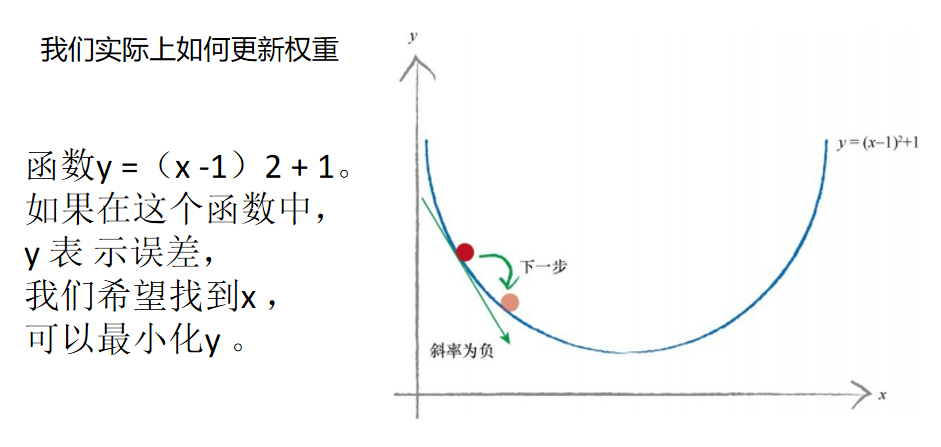
要应用梯度下降的方法,我们必须找一个起点。上图显示了随机选择 的起点。就像登山者,我们正站在这个地方,环顾四周,观察哪个方向是向下的。在图上标记了当前情况下的斜率,其斜率为负。我们希望沿着向 下的方向,因此我们沿着x 轴向右。也就是说,我们稍微地增加x 的值。这 是登山者的第一步。你可以观察到,我们改进了我们的位置,向实际最小 值靠近了一些。
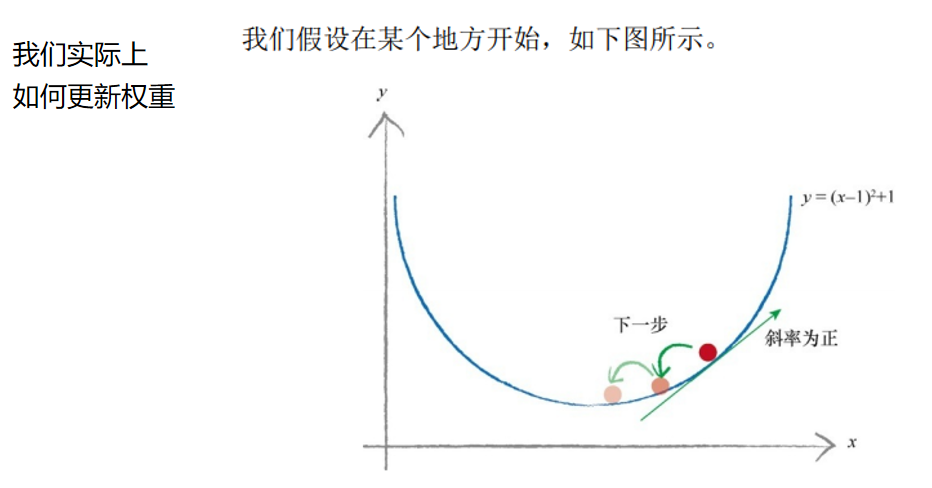
这一次,我们所在之处的斜率为正,因此我们向左移动。也就是说, 我们稍微减小x 值。同样,你可以观察到我们已经改善了位置,向真实的 最小值靠近了一些。我们可以继续这样操作,直到几乎不能改进为止,这 样我们就确信已经到达了最小值。
我们要改变步子大小,避免超调,这样就会避免在最小值的地方来回 反弹,这是一个必要的优化。你可以想象,如果我们距离真正的最小值只 有0.5米,但是采用2米的步长,那么由于向最小值的方向走的每一步都超 过了最小值,我们就会错过最小值。如果我们调节步长,与梯度的大小成 比例,那么在接近最小值时,我们就可以采用小步长。这一假设的基础 是,当我们接近最小值时,斜率也变得平缓了。对于大多数光滑的连续函 数,这个假设是合适的。但是对于有时突然一跃而起、有时突然急剧下降 的锯齿函数而言,也就是说存在数学家所说的间断点,这不是一个合适的 假设。
顺便说一句,你是否注意到,我们往相反的梯度方向增加x 值?正梯 度意味着减小x ,负梯度意味着增加x 。画图可以让这个现象变得很清晰, 但是我们很容易忘记这一点,并经常误入歧途。

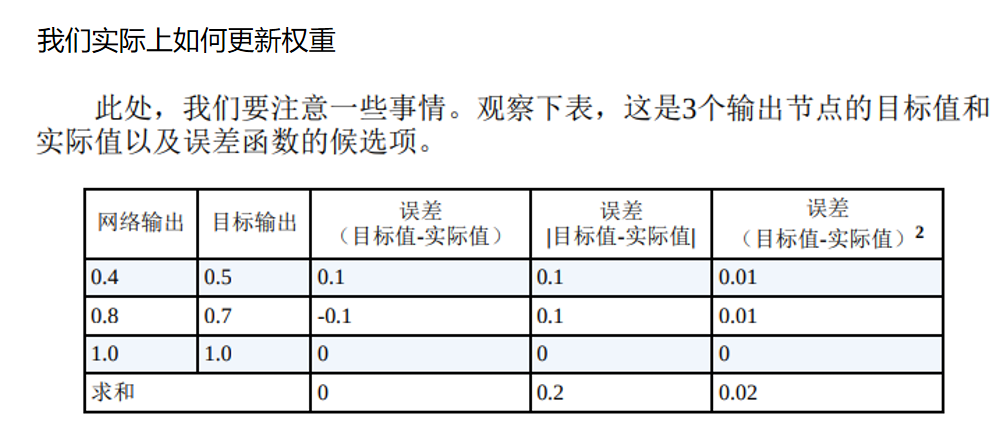
误差函数的第一个候选项是(目标值-实际值),非常简单。这似乎足 够合理了,对吧?如果你观察对所有节点的误差之和,以判断此时网络是 否得到了很好的训练,你会看到总和为0!
这是如何发生的呢?很显然,由于前两个节点的输出值与目标值不 同,这个网络没有得到很好的训练。但是,由于正负误差相互抵消,我们 得到误差总和为0。总和为零意味着没有误差。然而即使正负误差没有完全 互相抵消,这也很明显不符合实际情况,由此你也可以明白这不是一个很 好的测量方法。
为了纠正这一点,我们采用差的绝对值,即将其写成|目标值-实际 值|,这意味着我们可以无视符号。由于误差不能互相抵消,这可能行得 通。由于斜率在最小值附近不是连续的,这使得梯度下降方法无法很好地 发挥作用,由于这个误差函数,我们会在V形山谷附近来回跳动,因此这个误差函数没有得到广泛应用。在这种情况下,即使接近了最小值,斜率 也不会变得更小,因此我们的步长也不会变得更小,这意味着我们有超调 的风险。
第三种选择是差的平方,即(目标值-实际值)2 。我们更喜欢使用第 三种误差函数,而不喜欢使用第二种误差函数,原因有以下几点:
使用误差的平方,我们可以很容易使用代数计算出梯度下降的斜率。
误差函数平滑连续,这使得梯度下降法很好地发挥作用——没有间 断,也没有突然的跳跃。
越接近最小值,梯度越小,这意味着,如果我们使用这个函数调节步 长,超调的风险就会变得较小。
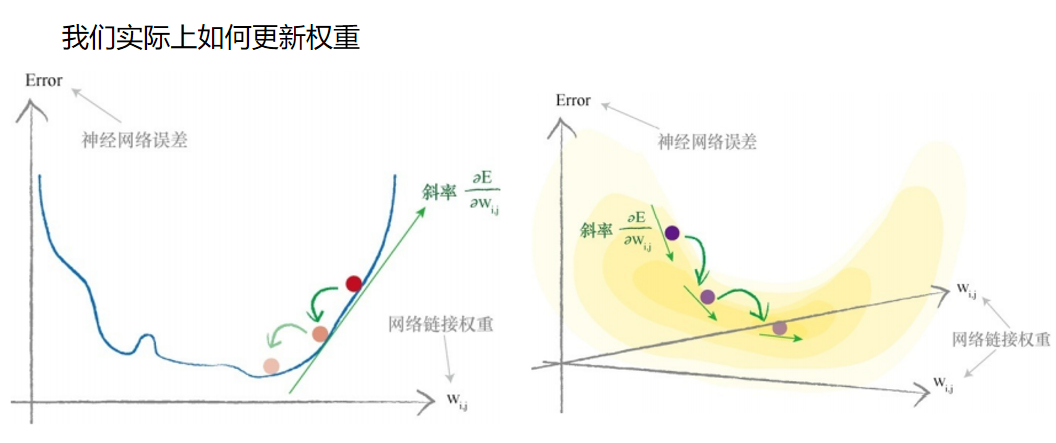
此图与我们先前看到的图一样,主要是强调我们所做的事情没有什么 不同。这一次,我们希望最小化的是神经网络的误差函数。我们试图优化 的参数是网络链接权重。在这个简单的例子中,我们只演示了一个权重, 但是我们知道神经网络有众多权重参数。 下图显示了两个链接权重,这次,误差函数是三维曲面,这个曲面随 着两个链接权重的变化而变化。你可以看到,我们努力最小化误差,现 在,这有点像在多山的地形中寻找一个山谷。

当函数具有多个参数时,要画出误差曲面相对较难,但是使用梯度下 降寻找最小值的思想是相同的。 让我们使用数学的方式,写下想要取得的目标。
这个表达式表示了当权重wj,k 改变时,误差E是如何改变的。这是误差 函数的斜率,也就是我们希望使用梯度下降的方法到达最小值的方向。
在我们求解表达式之前,让我们只关注隐藏层和最终输出层之间的链 接权重。下图突出显示了我们所感兴趣的这个区域。我们将重回输入层和 隐藏层之间的链接权重。
在进行微积分计算时,我们会时不时地返回来参照此图,以确保我们 没有忘记每个符号的真正含义。读者请不要被吓倒而裹足不前,这个过程 并不困难,我们还会进行解释,我们先前已经介绍了所有所需的概念。

首先,让我们展开误差函数,这是对目标值和实际值之差的平方进行 求和,这是针对所有n个输出节点的和。
此处,我们所做的一切,就是写下实际的误差函数E。 注意,在节点n的输出on 只取决于连接到这个节点的链接,因此我们可以直接简化这个表达式。这意味着,由于这些权重是链接到节点k的权 重,因此节点k的输出ok 只取决于权重wj,k 。
t k 的部分是一个常数,因此它不会随着wj,k 的变化而变化。也就是 说,tk 不是wj,k 的函数。仔细想想,如果真实示例所提供的目标值根据权 重变化,就太让人匪夷所思了!由于我们使用权重前馈信号,得到输出值 ok ,因此这个表达式留下了我们所知的依赖于wj,k 的ok 部分。

1.我们可以反过来对相对简单的部分各个击破。我们对平方函数 进行简单的微分,就很容易击破了第一个简单的项。这使我们得到了以下 的式子:
2.对于第二项,我们需要仔细考虑一下,但是无需考虑过久。ok 是节点 k的输出,如果你还记得,这是在连接输入信号上进行加权求和,在所得到 结果上应用S函数得到的结果。让我们将这写下来,清楚地表达出来。
3.oj 是前一个隐藏层节点的输出,而不是最终层的输出ok 。 我们如何微分S函数呢?使用附录A介绍的基本思想,对S函数求微 分,这对我们而言是一种非常艰辛的方法,但是,其他人已经完成了这项 工作。我们可以只使

1.这个额外的最后一项是什么呢?由于在sigmoid()函数内部的表达式也 需要对wj,k 进行微分,因此我们对S函数微分项再次应用链式法则。这也非 常容易,答案很简单,为oj 。
2.在写下最后的答案之前,让我们把在前面的2 去掉。我们只对误差函 数的斜率方向感兴趣,这样我们就可以使用梯度下降的方法,因此可以去 掉2。只要我们牢牢记住需要什么,在表达式前面的常数,无论是2、3还是 100,都无关紧要。因此,去掉这个常数,让事情变得简单。 这就是我们一直在努力要得到的最后答案,这个表达式描述了误差函 数的斜率,这样我们就可以调整权重w j,k 了。
这个表达式值得再次回味,颜色标记有助于显示出表达式的各个部 分。第一部分,非常简单,就是(目标值-实际值),我们对此已经很清楚 了。在sigmoid中的求和表达式也很简单,就是进入最后一层节点的信号, 我们可以称之为ik ,这样它看起来比较简单。这是应用激活函数之前,进 入节点的信号。最后一部分是前一隐藏层节点j的输出。

1.我们需要完成工作,为输入层和隐藏 层之间的权重找到类似的误差斜率。 同样,我们可以进行大量的代数运算,但是不必这样做。我们可以很 简单地使用刚才所做的解释,为感兴趣的新权重集重新构建一个表达式。第一部分的(目标值-实际值)误差,现在变成了隐藏层节点中重组的 向后传播误差,正如在前面所看到的那样。我们称之为ej 。 sigmoid部分可以保持不变,但是内部的求和表达式指的是前一层,因 此求和的范围是所有由权重调节的进入隐藏层节点j的输入。我们可以 称之为i j 。 现在,最后一部分是第一层节点的输出oi ,这碰巧是输入信号。 这种巧妙的方法,简单利用问题中的对称性构建了一个新的表达式, 避免了大量的工作。这种方法虽然很简单,但却是一种很强大的技术,一 些天赋异禀的数学家和科学家都使用这种技术。你肯定可以使用这个技 术,给你的队友留下深刻印象。 因此,我们一直在努力达成的最终答案的第二部分如下所示,这是我 们所得到误差函数斜率,用于输入层和隐藏层之间权重调整。
2.更新后的权重wj,k 是由刚刚得到误差斜率取反来调整旧的权重而得到 的。正如我们先前所看到的,如果斜率为正,我们希望减小权重,如果斜 率为负,我们希望增加权重,因此,我们要对斜率取反。符号α是一个因 子,这个因子可以调节这些变化的强度,确保不会超调。我们通常称这个因子为学习率。 这个表达式不仅适用于隐藏层和输出层之间的权重,而且适用于输入 层和隐藏层之间的权重。差值就是误差梯度,我们可以使用上述两个表达 式来计算这个误差梯度。

1.如果我们试图按照矩阵乘法的形式进行运算,那么我们需要看看计算 的过程。为了有助于理解,我们将按照以前那样写出权重变化矩阵的每个 元素。
由于学习率只是一个常数,并没有真正改变如何组织矩阵乘法,因此 我们省略了学习率α。 权重改变矩阵中包含的值,这些值可以调整链接权重wj,k ,这个权重 链接了当前层节点j与下一层节点k。你可以发现,表达式中的第一项使用 下一层(节点k)的值,最后一项使用前一层(节点j)的值。 仔细观察上图,你就会发现,表达式的最后一部分,也就是单行的水 平矩阵,是前一层oj 的输出的转置。颜色标记显示点乘是正确的方式。如 果你不能确定,请尝试使用另一种方式的点乘,你会发现这是行不通的。
2.因此,权重更新矩阵有如下的矩阵形式,这种形式可以让我们通过计 算机编程语言高效地实现矩阵运算。

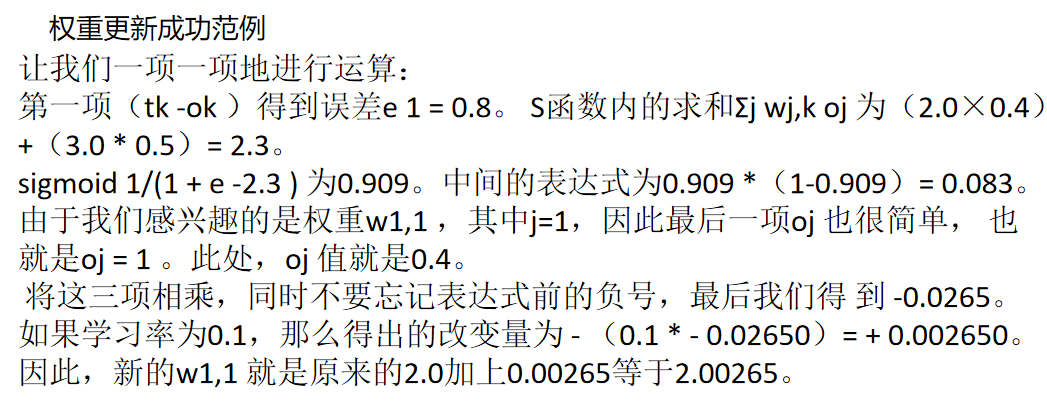
权重更新成功范例
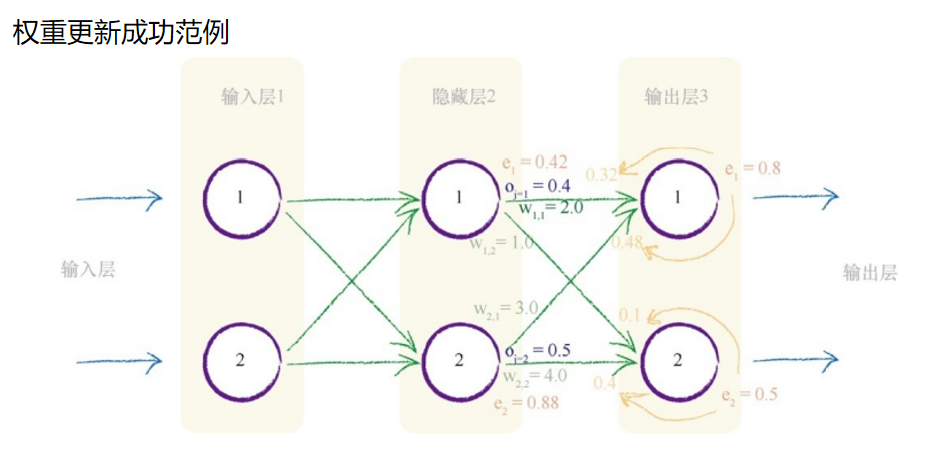
下面的网络是我们之前演示过的一个,但是这次,我们添加了隐藏层 第一个节点oj = 1 和隐藏层第二个节点oj = 2 的示例输出值。这些数字只是为 了详细说明这个方法而随意列举的,读者不能通过输入层前馈信号正确计 算得到它们。

准备数据

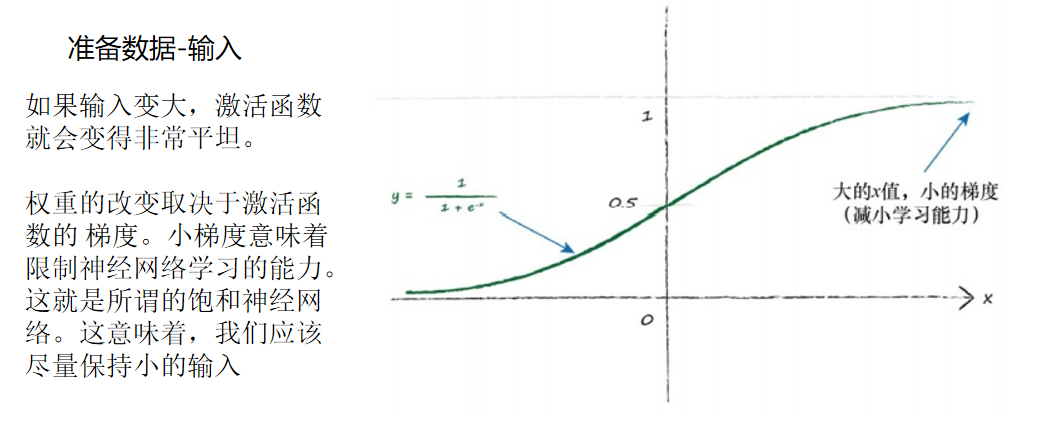

这个表达式也取决于输入信号(oj ),因此,我们也不应该让输入信号太小。
当计算机处理非常小或非常大的数字时,可能会丧失 精度,因此,使用非常小的值也会出现问题。 一个好的建议是重新调整输入值,将其范围控制在0.0到1.0。输入0会 将oj 设置为0,这样权重更新表达式就会等于0,从而造成学习能力的丧 失,因此在某些情况下,我们会将此输入加上一个小小的偏移,如0.01, 避免输入0带来麻烦。
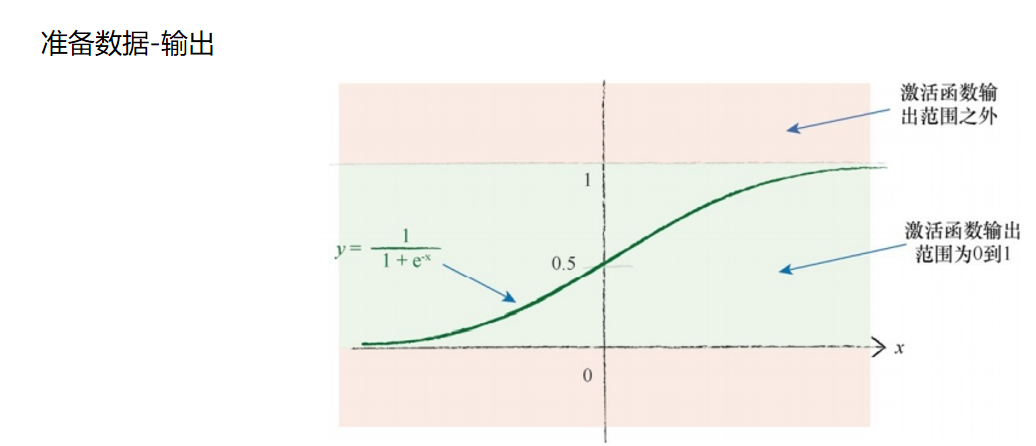
神经网络的输出是最后一层节点弹出的信号。如果我们使用的激活函 数不能生成大于1的值,那么尝试将训练目标值设置为比较大的值就有点愚 蠢了。请记住,逻辑函数甚至不能取到1.0,只能接近1.0。数学家称之为渐 近于1.0。
如果我们将目标值设置在这些不可能达到的范围,训练网络将会驱使 更大的权重,以获得越来越大的输出,而这些输出实际上是不可能由激活 函数生成的。这使得网络饱和,因此我们知道这种情况是很糟糕的。 因此,我们应该重新调整目标值,匹配激活函数的可能输出,注意避 开激活函数不可能达到的值。 虽然,常见的使用范围为0.0~1.0,但是由于0.0和1.0这两个数也不可能是目标值,并且有驱动产生过大的权重的风险,因此一些人也使用0.01 ~0.99的范围。

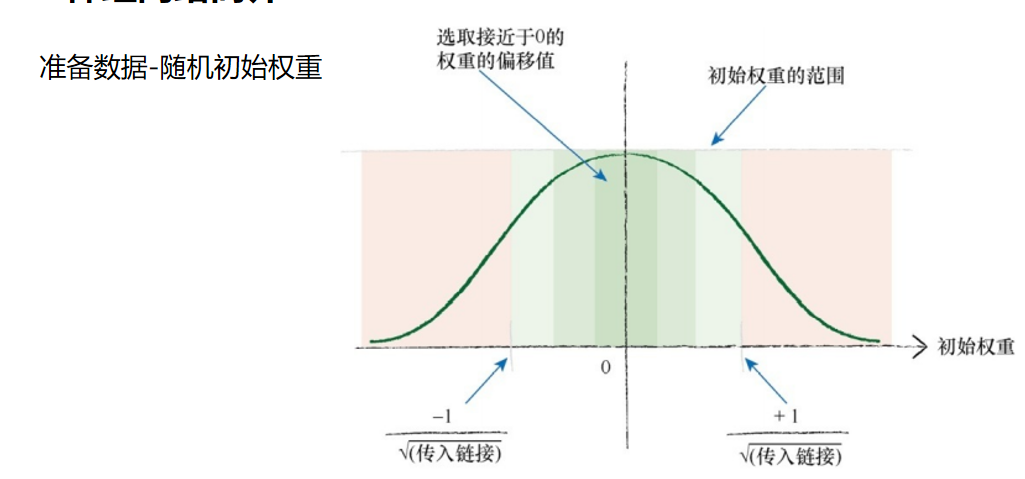
直觉上说,这是有意义的。一些过大的初始权重将会在偏置方向上偏 置激活函数,非常大的权重将会使激活函数饱和。一个节点的传入链接越 多,就有越多的信号被叠加在一起。因此,如果链接更多,那么减小权重 的范围,这个经验法则是有道理的。 如果你已经熟悉从概率分布中进行采样的思想,那么这一经验法则实 际上讲的是,从均值为0、标准方差等于节点传入链接数量平方根倒数的正 态分布中进行采样。但是,由于经验法则所假设的一些事情,如可替代的激活函数tanh()、输入信号的特定分布等,可能不是真的,因此,我们不必 太担心要精确正确地理解这个法则。
不管你做什么,禁止将初始权重设定为相同的恒定值,特别是禁止将 初始权重设定为0。要不然,事情会变得很糟糕。 如果这样做,那么在网络中的每个节点都将接收到相同的信号值,每 个输出节点的输出值也是相同的,在这种情况下,如果我们在网络中通过 反向传播误差更新权重,误差必定得到平分。你还记得误差按权重比例进 行分割吧!那么,这将导致同等量的权重更新,再次出现另一组值相等的 权重。由于正确训练的网络应该具有不等的权重(对于几乎所有的问题, 这是极有可能的情况),那么由于这种对称性,你将永远得不到这种网 络,因此这是一种很糟糕的情况。 由于0权重,输入信号归零,取决于输入信号的权重更新函数也因此归 零,这种情况更糟糕。网络完全丧失了更新权重的能力。
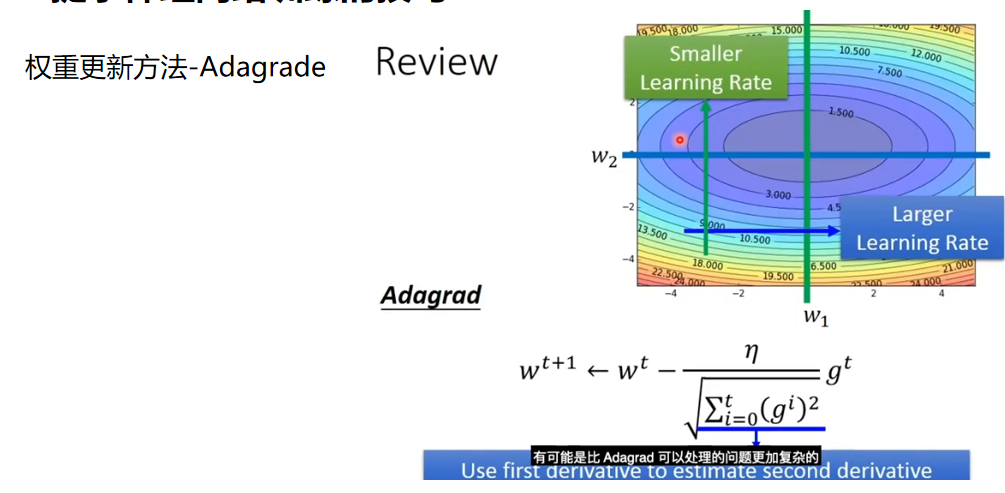
问题
深度学习与传统机器学习网络相比,不需设计特征,但需要设计结构,传统的机器学习需要找到好的特征,不需要设计结构
深度学习遇到的第一个问题,不是过拟合,而是训练集上的效果不佳,影响因素包括结构,初始值,
Test结果不好时,可以使用dropout
确定方向过程
针对完全没有基础的同学们
1.确定机器学习的应用领域有哪些
2.查找机器学习的算法应用有哪些
3.确定想要研究的领域极其对应的算法
4.通过招聘网站和论文等确定具体的技术
5.了解业务流程,查找数据
6.复现经典算法
7.持续优化,并尝试与对应企业人员沟通心得
8.企业给出反馈