RIPGeo中有:
训练目标为:
![]()
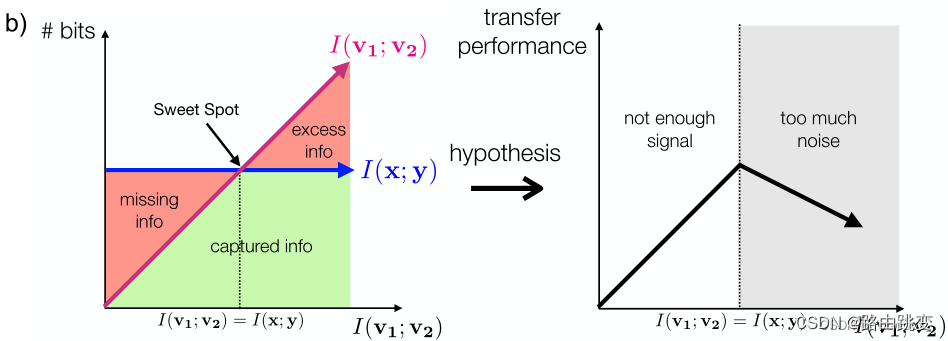
由于需要准确的地理定位预测,损失鼓励图表示学习来保持IP地理定位的基本信号。同时,
和
通过最大化原始图与摄动图[33]、[37]之间的一致性,保证了不相关信息的消除。考虑到模型在训练早期的不稳定性,我们不直接同时优化多个训练目标。相反,我们采用课程学习方法——首先用标准目标
训练模型,直到收敛,然后继续使用扰动目标
和
。
[33] Y. Tian, C. Sun, B. Poole, D. Krishnan, C. Schmid, and P. Isola, “What makes for good views for contrastive learning?” NeurIPS, vol. 33, 2020.
[37] A. M. Saxe, Y. Bansal, J. Dapello, M. Advani, A. Kolchinsky, B. D. Tracey, and D. D. Cox, “On the information bottleneck theory of deep learning,” Journal of Statistical Mechanics: Theory and Experiment, vol. 2019, no. 12, 2019.
[33] What makes for good views for contrastive learning?
具体实现见:
RIPGeo参文31—36(关于对比学习):鼓励对同一数据点进行各种增强(视图),以学习更健壮的表示-CSDN博客
[37] 信息瓶颈理论
这篇论文发表在2018年,ICLR。
论文地址:https://openreview.net/pdf?id=ry_WPG-A-
代码地址:https://github.com/artemyk/ibsgd/tree/iclr2018
信息瓶颈理论的实用化问题集中在训练过程的互信息估计。
这块将简要介绍:为什么我们关注表示学习,什么样的表示是一个好的表示,神经网络如何学习表示,信息瓶颈理论在表示学习上的应用,如何学习最优的表示。
一. 为什么关注表示学习
目前,表示学习已经在机器学习领域无处不在,例如:语音识别和信号处理、目标识别、自然语言处理、多任务学习、迁移学习、域自适应等。
那么,为什么我们要显式地学习这样一个表示呢?Bengio等人[1]2013年在TPAMI上发表的表示学习综述论文中认为,这样做能够方便地表达许多现实世界中的通用的先验,这些任务无关的先验对于一个学习机器解决AI任务来说是至关重要的。那么,有什么先验是我们表示学习所需要的呢?这也同时回答了这样一个问题:
1、什么样的表示是一个好的表示
Bengio等人提出了10个构成一个好的表示所需要的先验。
2、平滑性(Smoothness)
即期望当 x≈y 时,我们有 f(x)≈f(y) 。这个先验也是机器学习最基本的假设。但是仅有这个假设是不够的,因为无法解决唯独灾难问题。

Figure from: https://www.visiondummy.com/2014/04/curse-dimensionality-affect-classification/
3、多重解释因素(Multiple explanatory factors)
数据生成分布由不同的潜在因素生成。这一假设其实就是NLP中常用的分布式表示(distributed representations)背后的思想。
这也与一系列解耦表示学习论文有关,他们的目标是解开变化因素(factors of variation)。
4、解释因素的分层组织(A hierarchical organization of explanatory factors)
描述我们周围世界有用的概念通常可以用其他概念来定义,这也构成了一个层次结构。更高抽象概念是由根据不太抽象的概念定义而成的。
这个假设被我们常用的深度表示学习所利用,即网络的低层学习低抽象概念,高层学习高抽象概念。
5、半监督学习(Semi-supervised learning)
在给定 X 的






![[Linux][CentOs][Mysql]基于Linux-CentOs7.9系统安装并配置开机自启Mysql-8.0.28数据库](https://img-blog.csdnimg.cn/direct/7a7412d3c5e245fe8abd726b56726d4f.png)