背景
低功耗设备上资源有限,但又比较重要。对其的管理难度很大,有些时候又必须时刻了解其运行状况。我们自然想到的是能否有办法监控它呢?当时是有的!而且很成熟的解决方案。TICK技术栈,那TICK是什么呢?
TICK是由InfluxData开源的监控技术栈,由 Telegraf, InfluxDB, Chronograf, Kapacitor 四个工具的首字母组成。
- Telegraf:go语言开发的数据采集工具;
- InfluxDB:go语言开发的时序数据库;
- Chronograf:数据可视化报表展示;
- Kapacitor:时序数据的监控告警;

以上只是做个了解,不在本文重点。而且每个人遇到的工作场景不同,这样的架构也不一定适合自己。取其所需整合到自己的系统中,可以完美的满足业务需求最好。当然了解这个解决方案也是必须的。自己去花时间吧。
问题
在我的尝试中使用telegraf+influxdb+业务系统去跟踪并管理终端设备,通过交叉编译环境–现场设备–数据采集–数据入库–设备管理等正式环境运行后,欣喜的发现数据上来了。但是没过多久telegraf数据时断时续,最终挂掉而导致数据出现中断。个人模糊的感觉可能是入库时出现了什么我不知道的问题。通过抓包分析发现,其在对influxdb建立网络连接时网络不稳定,主程序进程占用的内存也多,多方面因数导致数据不能及时发出去最终撑爆了telegraf。也有一种通过限制telegraf连接失败时Telegraf将尝试重新连接InfluxDB的最大次数,influx_max_retry_interval参数指定了重试连接的最大时间间隔。但这样不能解决我数据丢失的问题呀。
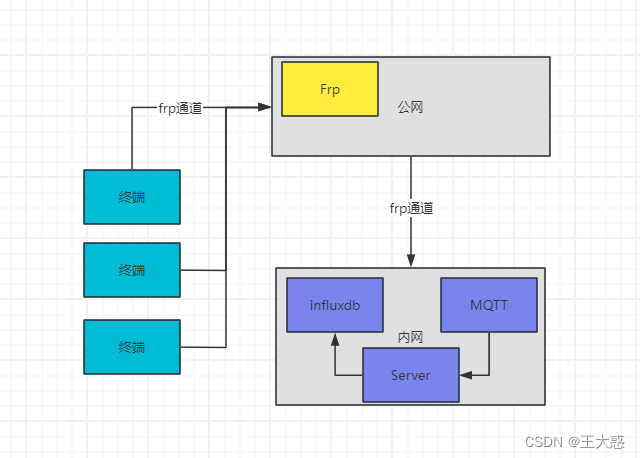
项目摘取部分架构
解决
针对上面的问题决定替换直接连接influxdb的想法,利用终端本身与mqtt交互的方式,将数据回传到系统中。于是有了上面的截图。再一番修改后,数据到了server时又出现了问题。telegraf采集时,上报到mqtt过程中设置了数据格式为“json”,想着通过server转手时再做点自动分析处理的工作。然后再将数据直接入库!想法是好的,也是可行的。就是数据格式中出现了integer与float的交替出现导致了influxdb入库失败。查阅资料时发现可以直接配置数据的类型为influx,Telegraf数据格式配置
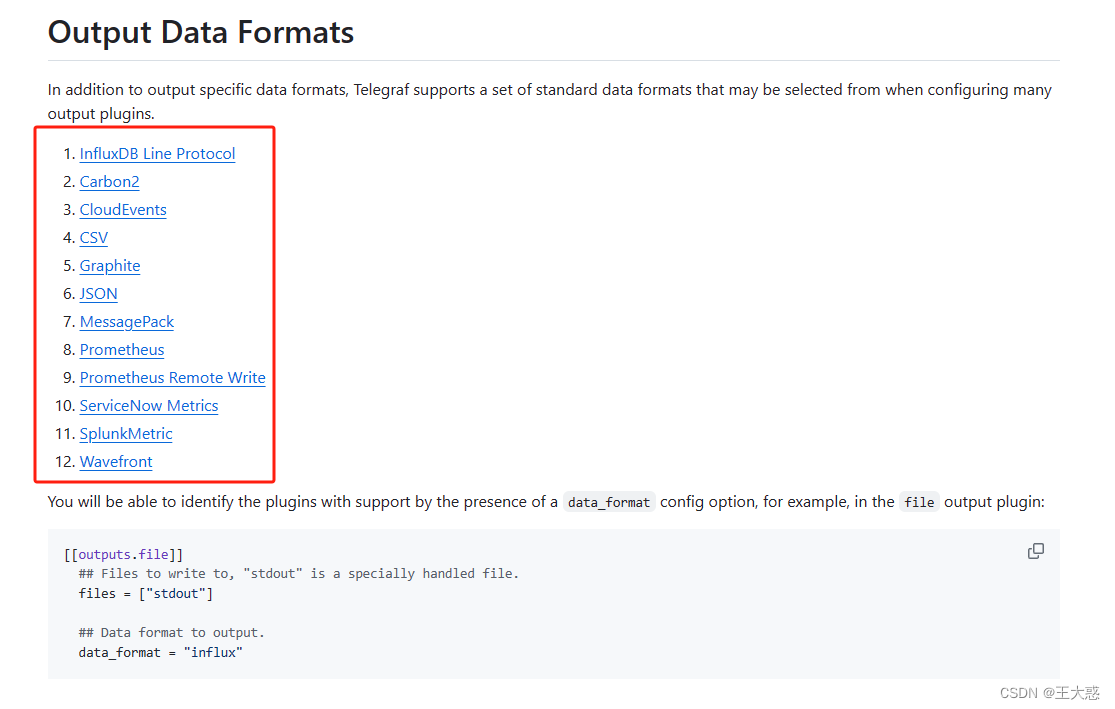
于是我修改配置如下:
root@lm70:/tffs0a# cat telegraf.conf
## 配置在采集终端的telegraf.conf,注意配置信息的正确性# Telegraf Configuration
# Global tags can be specified here in key="value" format.
[global_tags]device="3"
# Configuration for telegraf agent
[agent]interval = "10s"round_interval = truemetric_batch_size = 1000metric_buffer_limit = 10000collection_jitter = "0s"flush_interval = "10s"flush_jitter = "0s"precision = ""debug = falsequiet = falsehostname = ""omit_hostname = false# CPU input plugin
[[inputs.cpu]]percpu = truetotalcpu = truecollect_cpu_time = falsereport_active = false
# Memory input plugin
[[inputs.mem]]
# Disk input plugin
[[inputs.disk]]ignore_fs = ["tmpfs", "devtmpfs", "devfs"]
# System input plugin (for boot time)
[[inputs.system]]
# Net input plugin (for network traffic)
[[inputs.net]]# 配置influxdb信息,出现数据中断的,后改为下面的mqtt方式接收数据
# InfluxDB v2 output plugin
#[[outputs.influxdb_v2]]
# urls = ["http://remote_ip:port"]
# token = "token"
# organization = "org"
# bucket = "bucket"# 配置mqtt的数据接收方式,第一次选择了data_format="json"的格式入库,出现了数据类型不匹配的情况,
# 当然可以自行处理,如果不想处理也是可以直接设置data_format=“influx”这种方式去规避
[[outputs.mqtt]]servers = ["tcp://remote_ip:port"]topic = "topic"qos = 1username = "admin"password = "passwd"data_format = "influx"
通过这么配置后,就能在server中直接转存到infludb中即可
# 对着上图的Server中运行的python代码片段import paho.mqtt.client as mqtt
from influxdb_client import InfluxDBClient
from concurrent.futures import ThreadPoolExecutor
from influxdb_client.client.write_api import SYNCHRONOUS# 线程池
executor = ThreadPoolExecutor(max_workers=20)
# Influxdb连接信息,此处版本2.x
client = InfluxDBClient(url=ENV_INFLUX_URL, token=ENV_INFLUX_TOKEN, org=ENV_INFLUX_ORG, timezone='Asia/Shanghai')
write_api = client.write_api(write_options=SYNCHRONOUS)def save_data(bytes_array):try:print(bytes_array)write_api.write("bucket", 'org', bytes_array)# 你可以对数据在做点什么也不是不可以....# dosomething...except Exception as e:print(f"监控数据入库失败...{e}")def on_connect(client, userdata, flags, rc):"""订阅设备监控数据的topic"""print("MQTT连接成功")client.subscribe(ENV_MQTT_MT)def on_message(client, userdata, msg):if "mt_device" in msg.topic:executor.submit(save_data, msg.payload)else:passif __name__ == '__main__':# mqtt配置信息根据自己的配置client = mqtt.Client()client.on_connect = on_connectclient.on_message = on_messageclient.connect(ENV_MQTT_IP, int(ENV_MQTT_PORT), 60)client.loop_forever()
官方链接:
https://github.com/influxdata/telegraf/tree/master/plugins
到这里我遇到的问题就解决了,而且没有再出现断断续续的情况,一直很稳定。这就不禁让我感到疑惑。同样的网络环境下为什么这种方式可以安全平稳的运行,而直接配置influxdb数据库就会出现问题呢?
讨论
如果你有好的解决办法,请在评论区告诉我。