Spark系列文章:
大数据 - Spark系列《一》- 从Hadoop到Spark:大数据计算引擎的演进-CSDN博客
大数据 - Spark系列《二》- 关于Spark在Idea中的一些常用配置-CSDN博客
大数据 - Spark系列《三》- 加载各种数据源创建RDD-CSDN博客
大数据 - Spark系列《四》- Spark分布式运行原理-CSDN博客
大数据 - Spark系列《五》- Spark常用算子-CSDN博客
大数据 - Spark系列《六》- RDD详解-CSDN博客
大数据 - Spark系列《七》- 分区器详解-CSDN博客
大数据 - Spark系列《八》- 闭包引用-CSDN博客
大数据 - Spark系列《九》- 广播变量-CSDN博客
大数据 - Spark系列《十》- rdd缓存详解-CSDN博客
大数据 - Spark系列《十一》- Spark累加器详解-CSDN博客
大数据 - Spark系列《十二》- 名词术语理解-CSDN博客
大数据 - Spark系列《十三》- spark调度流程(运行过程)-CSDN博客
目录
Spark 程序分布式运行模式
14.1.1 🥙本地测试模式
14.1.2 StandAlone模式
集群安装步骤
spark-submit脚本方式提交
14.1.3 Yarn 模式:client vs cluster模式
1. 简介
2. 🥙 client模式
🍠Cluster和client模式的区别
14.1.4 Mesos/k8s
Mesos模式:
Kubernetes模式:
Spark 程序分布式运行模式
当运行 Spark 程序时,可以选择不同的部署模式,具体取决于集群管理系统和资源调度器。以下是常见的 Spark 程序分布式运行模式:
-
本地测试模式
-
Standalone模式(Client/cluster): spark内置的运行集群
-
Yarn 模式(Client/cluster):在yarn上运行
-
Mesos/k8s : 在mesos集群或者k8s集群上运行
14.1.1 🥙本地测试模式
Idea中
val conf = new SparkConf().setAppName("doe").setMaster("local[*]")虚拟机环境中 (安装包解压即可)
[root@doe01 bin]# ./spark-shell
Welcome to____ __/ __/__ ___ _____/ /___\ \/ _ \/ _ `/ __/ '_//___/ .__/\_,_/_/ /_/\_\ version 3.3.2/_/scala> val rdd = sc.makeRDD(List(1,2,3,4,5,6) , 2)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:2314.1.2 StandAlone模式
Spark standalone是一个类似于yarn的资源调度集群,属于spark自己的集群管理 , 规模小, 不通用 ;它构建一个基于 Master+Slaves 的资源调度集群,Spark 任务提交给 Master运行。生产中一般不使用.
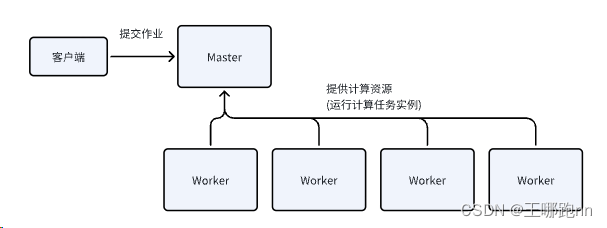
集群安装步骤
1. 上传安装包解压
2. 修改conf下的spark-env.sh
export JAVA_HOME=/opt/apps/jdk1.8
export HADOOP_CONF_DIR=/opt/apps/hadoop-3.1.1/
export YARN_CONF_DIR=/opt/apps/hadoop-3.1.1/ 
3. 修改conf下的workers文件,添加worker节点
hadoop01
hadoop02
hadoop03 
4. 将安装包分发到其他节点
Scp -r 5. 修改系统环境变量
vi /etc/profileexport SPARK_HOME=/opt/apps/spark-3.3.2-bin-hadoop3
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$FLUME_HOME/bi
n:$SQOOP_HOME/bin:$HBASE_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin
source /etc/profile6. 修改sbin下的指令名
sbin目录下的start-all.sh和stop-all.sh和Hadoop的指令冲突
修改成start-spark.sh stop-spark.sh

7. 启动standalone集群
sbin/start-spark.sh
Jps 可观察到Master worker 进程在浏览器上访问 : http://hadoop02:8080

此界面是standalone集群的监控界面
而每一个application都有一个自己的监控页面
spark-submit脚本方式提交
将自己的程序打包

注意代码中不用指定运行模式和appName
// conf.setAppName("").setMaster()
上传到虚拟机 , 然后将程序提交到 spark自己的集群上
./spark-submit --master spark://hadoop02:7077 \--name test_cf \--executor-cores 2 \--executor-memory 2G \--class com.doit.day0201.CommonFriend_HDFS \/opt/testDemo/Spark_module-1.0-SNAPSHOT.jar 
14.1.3 Yarn 模式:client vs cluster模式
1. 简介
YARN(Yet Another Resource Negotiator)是Apache Hadoop的资源管理器,Spark可以作为YARN应用程序在Hadoop集群上运行。在YARN模式下,Spark应用程序可以以两种方式运行:
-
Client模式:Driver程序运行在提交作业的客户端机器上。
-
Cluster模式:Driver程序运行在YARN集群中的一个容器内,由YARN资源管理器负责资源调度和任务执行。
2. 🥙 client模式
如果部署模式为 client,程序jar包可以放在本地磁盘, 程序初始化是在本地的SparkSubmit中的Driver中进行的
# cluster模式完整示例
# Usage: spark-submit [options] <app jar | python file | R file> [app arguments]
# 注意,cluster模式时,spark-submit先请求standalone获取资源启动driver,然后driver要请求standalone获取资源启动executor(需要jar包)
# 要提前将jar包放到hdfs
bin/spark-submit --master spark://doit01:7077 \
--deploy-mode cluster \
--class cn.doitedu.spark.WordCount \
--name "帅无边男人的帅无边程序" \
--driver-memory 1G \
--executor-memory 2G \
--executor-cores 2 \
--total-executor-cores 6 \
hdfs://doit01:8020/sparkjars/sparktest.jar hdfs://doit01:8020/sparktest/wordcount/input hdfs://doit01:8020/sparktest/wordcount/output3运行起来后,集群中会出现如下独立的进程:

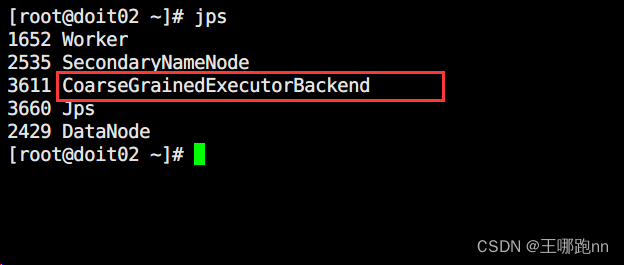
如果部署模式是cluster,DriverWrapper是在某个Worker节点上运行的!所以不使用提交作业机器的内存来做程序的初始化!
🍠Cluster和client模式的区别
区别在于Driver端创建的位置不同。工作过程中用cluster模式
14.1.4 Mesos/k8s
-
Mesos模式:
在Mesos模式下,Mesos作为资源管理器分配资源给Spark应用程序。Mesos负责在集群中启动和管理Executor容器,并分配资源给这些Executor容器以执行Spark任务。
-
Kubernetes模式:
在Kubernetes模式下,Kubernetes作为容器编排平台管理Spark应用程序的资源。Kubernetes启动和管理Executor容器,并根据Spark应用程序的需求动态调整资源。与Mesos模式类似,Kubernetes模式也提供了一种灵活且可扩展的方式来运行Spark作业。