目录
- Hadoop 的运行模式
- 1.本地模式
- 1.1官方 Grep 案例
- 1.2官方 WordCount 案例
- 2.伪分布式运行模式
- 2.1启动 HDFS 并运行 MapReduce 程序
- 2.1.1 配置集群,修改 Hadoop 的配置文件(/hadoop/hadoop-2.7.7/etc/hadoop 目录下)
- 2.1.2 启动集群
- 2.1.3 查看集群
- 2.1.4 操作集群
- 2.2启动 YARN 并运行 MapReduce 程序
- 2.21. 配置集群,修改 Hadoop 的配置文件(/hadoop/hadoop-2.7.7/etc/hadoop 目录下)
- 2.2.2 启动集群
- 2.2.3 查看集群
- 2.2.4 操作集群
- 2.3配置历史服务器
- 2.3.1 配置 mapred-site.xml
- 2.3.2 启动历史服务器
- 2.3.3 查看历史服务器是否启动
- 2.3.4 查看 JobHistory `http://192.168.29.200:19888/`
- 2.4配置日志的聚集
- 2.4.1 关闭 NodeManager 、ResourceManager 和 HistoryManager
- 2.4.2 配置 yarn-site.xml
- 2.4.3 启动 NodeManager 、ResourceManager 和 HistoryManager
- 2.4.4 删除HDFS上已经存在的输出文件
- 2.4.5 在 hadoop-2.7.7 目录下,执行 WordCount 程序
- 2.4.6 查看日志
- 3.完全分布式运行模式
- 3.1虚拟机准备
- 3.1.1 准备(克隆) 3 台客户机
- 3.1.2 每台机器分别修改 /etc/hosts 文件,将每个机器的 hostname 和 ip 对应
- 3.1.3 修改slave设备配置
- 3.2 编写集群分发脚本 xsync
- 3.2.1 scp(secure copy)安全拷贝
- 3.2.2 rsync(remote synchronize)远程同步工具
- 3.2.3 xsync 集群分发脚本
- 3.3 集群配置
- 3.3.1 集群部署规划
- 3.3.2 配置集群
- 3.3.3 在集群上分发配置好的 Hadoop 目录
- 3.4 在集群上分发配置好的 Hadoop 目录
- 3.4.1 如果集群是第一次启动,需要格式化 NameNode
- 3.4.2 在 master上启动 NameNode
- 3.4.3 在 master、slave1 和 slave2 上分别启动 DataNode
- 3.5 配置 SSH 无密登录
- 3.5.1 免密登录原理
- 3.5.2 生成公钥和私钥
- 3.5.3 将公钥拷贝到要免密登录的目标机器上
- 3.5.4 在另两台机器上也做 2、3 操作
- 3.6 群起集群
- 3.6.1 配置 slaves(/hadoop/hadoop-2.7.7/etc/hadoop/slaves)
- 3.6.2 启动集群
- 3.6.3 编写查看集群所有节点 jps 脚本 alljps
- 3.7 集群时间同步
- 3.7.1 时间服务器配置(必须 root 用户)
- 3.7.22 其他机器配置(必须root用户)
Hadoop 的运行模式
Hadoop 的运行模式包括:本地模式、伪分布式模式、完全分布式模式。
1.本地模式
1.1官方 Grep 案例
- 在/hadoop 文件下面创建一个 input 文件夹
mkdir -p /hadoop/input
cd /hadoop
- 将 Hadoop 的 xml 配置文件复制到 input
cp /hadoop/hadoop-2.7.7/etc/hadoop/*.xml input
- 在 /hadoop 目录下,执行 /hadoop/hadoop-2.7.7/share 目录下的 MapReduce 程序
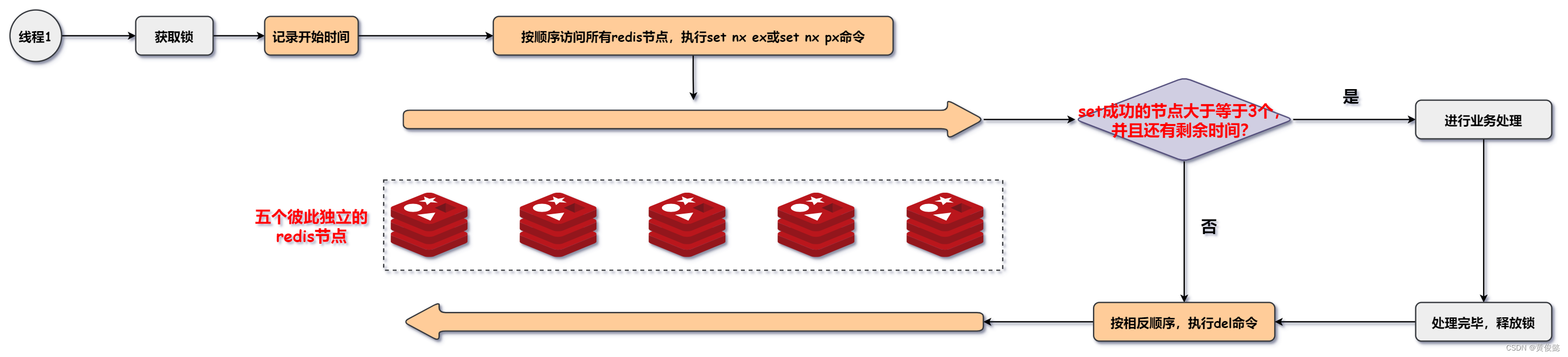
hadoop jar /hadoop/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar grep input/ output 'dfs[a-z.]+'
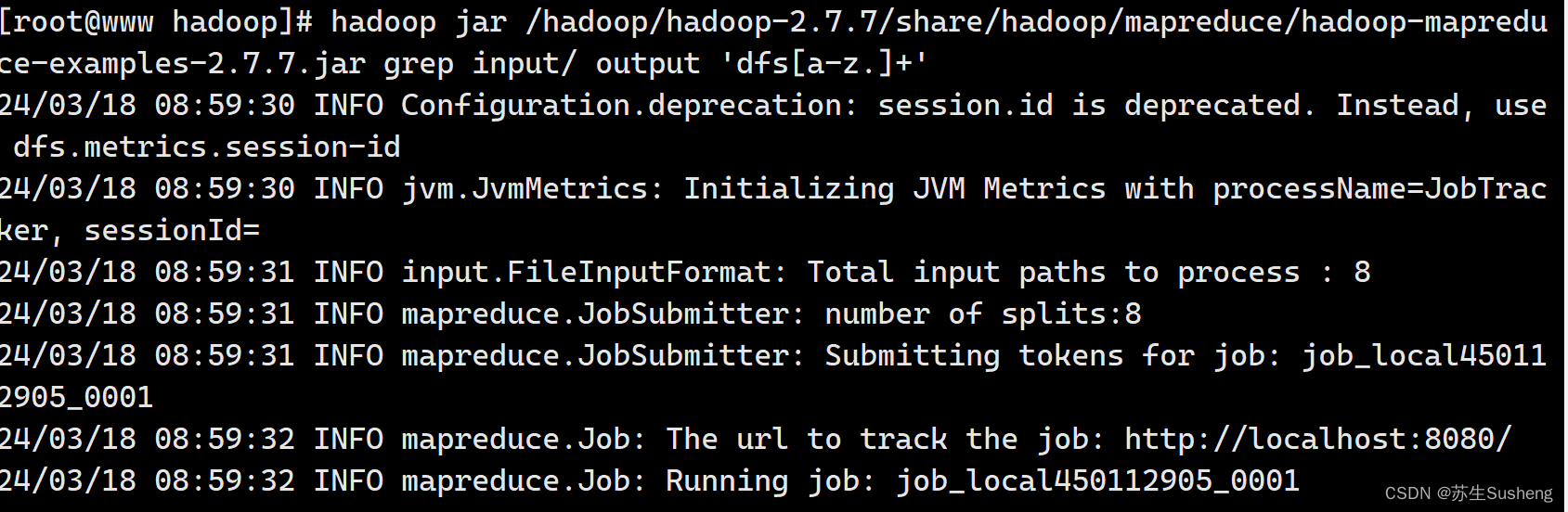
- 查看结果
1.2官方 WordCount 案例
- 在 /hadoop文件下面创建一个 wcinput 文件夹
mkdir -p /hadoop/wcinput
- 在 wcinput 文件下创建一个 wc.input 文件,在文件中输入以下内容:
vim wc.inputhadoop yarn
hadoop mapreduce
spark
spark
susheng
susheng hadoop
susheng csdn
- 在 /hadoop 目录下,执行 /hadoop/hadoop-2.7.7/share 目录下的 MapReduce 程序
hadoop jar /hadoop/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount wcinput/ wcoutput
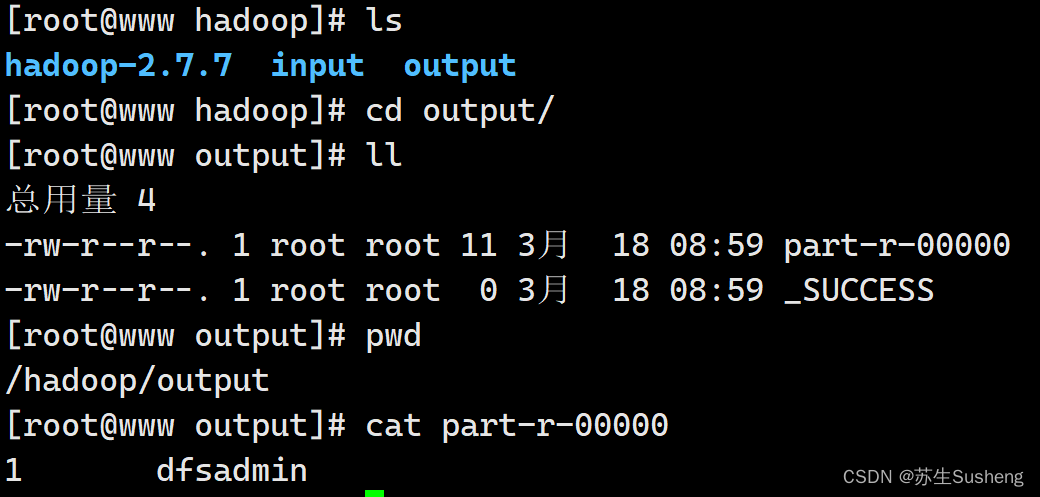
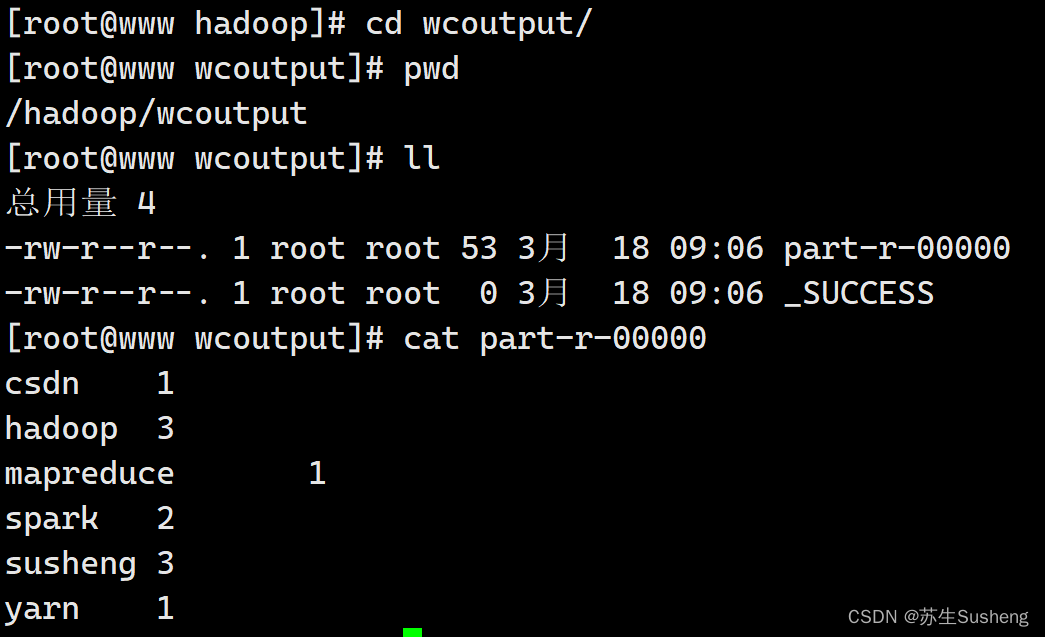
- 查看结果
2.伪分布式运行模式
2.1启动 HDFS 并运行 MapReduce 程序
2.1.1 配置集群,修改 Hadoop 的配置文件(/hadoop/hadoop-2.7.7/etc/hadoop 目录下)
- core-site.xml
<configuration><!-- 指定HDFS中NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://susheng:9000</value></property><!-- 指定Hadoop运行时产生文件的存储目录 --><property><name>hadoop.tmp.dir</name><value>/hadoop/hadoop-2.7.7/data/tmp</value></property>
</configuration>
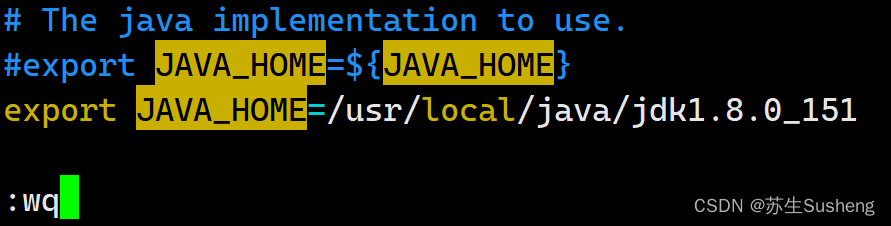
- hadoop-env.sh。修改 JAVA_HOME 路径:
# The java implementation to use.
export JAVA_HOME=/usr/local/java/jdk1.8.0_151
- hdfs-site.xml
<configuration><!-- 指定HDFS副本的数量 --><property><name>dfs.replication</name><value>1</value></property>
</configuration>
2.1.2 启动集群
- 格式化 NameNode(第一次启动时格式化,以后就不要总格式化)
hdfs namenode -format
- 启动 NameNode
hadoop-daemon.sh start namenode
- 启动 DataNode
hadoop-daemon.sh start datanode
2.1.3 查看集群
-
查看是否启动成功:
jps
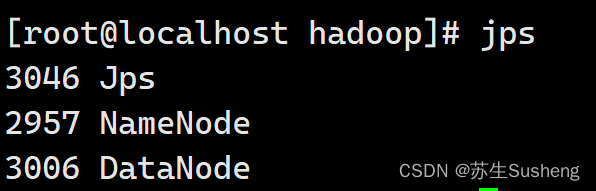
-
web 端查看 HDFS 文件系统:
http://192.168.29.200:50070
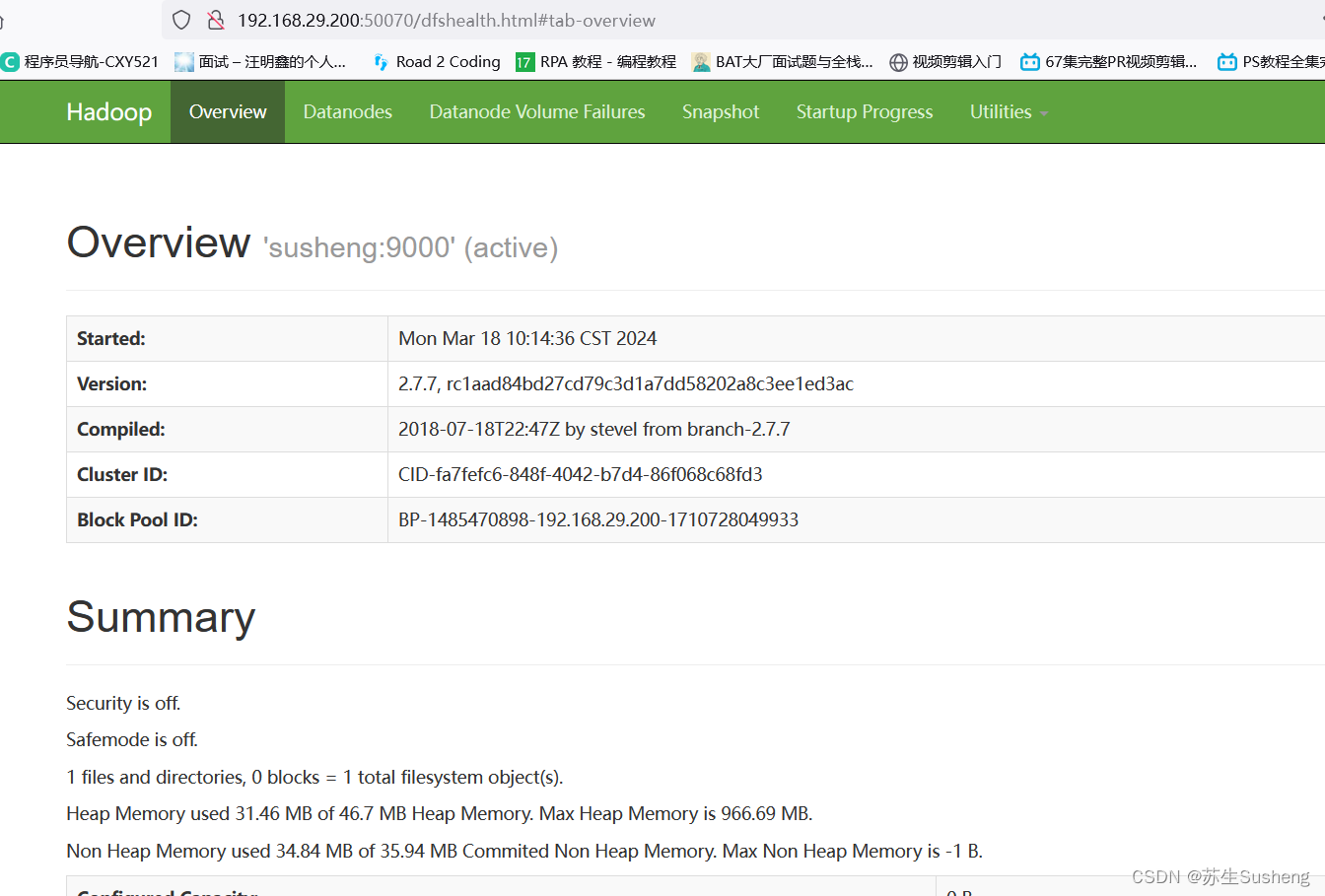
2.1.4 操作集群
- 在 HDFS 文件系统上创建一个 input 文件夹
cd /hadoop/wcinput
hdfs dfs -mkdir -p /user/susheng/input
- 将测试文件内容上传到文件系统上
hdfs dfs -put wc.input /user/susheng/input/
- 在 hadoop-2.7.7 目录下,运行 MapReduce 程序
hadoop jar /hadoop/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /user/susheng/input/ /user/susheng/output

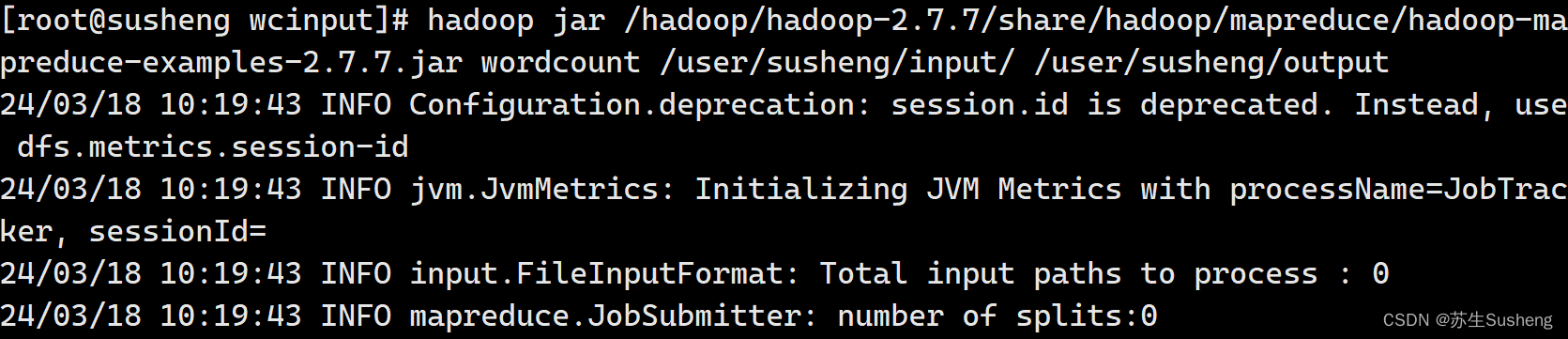
- 查看输出结果
命令行:
hdfs dfs -cat /user/susheng/output/*
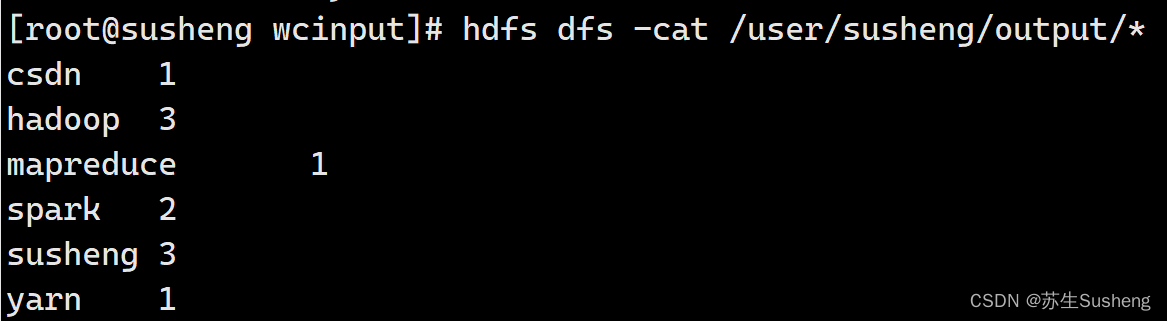 浏览器页面:
浏览器页面:
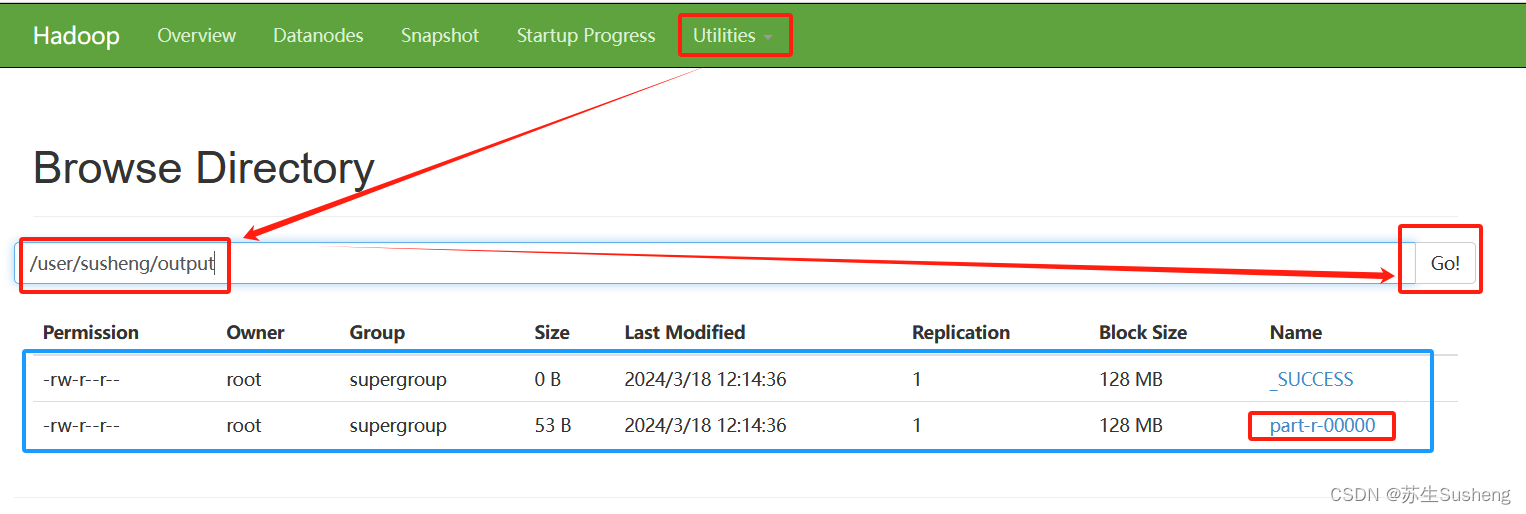
2.2启动 YARN 并运行 MapReduce 程序
2.21. 配置集群,修改 Hadoop 的配置文件(/hadoop/hadoop-2.7.7/etc/hadoop 目录下)
- yarn-site.xml
<configuration><!-- Reducer获取数据的方式 --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定YARN的ResourceManager的地址 --><property><name>yarn.resourcemanager.hostname</name><value>susheng</value></property>
</configuration>
- yarn-env.sh。修改 JAVA_HOME 路径:
export JAVA_HOME=/usr/local/java/jdk1.8.0_151
- mapred-env.sh。修改 JAVA_HOME 路径:
export JAVA_HOME=/usr/local/java/jdk1.8.0_151
- 将 mapred-site.xml.template 重新命名为 mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
<configuration><!-- 指定MR运行在YARN上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
2.2.2 启动集群
-
启动前必须保证 NameNode 和 DataNode 已经启动
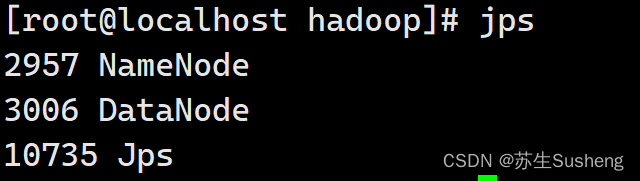
-
启动 ResourceManager
yarn-daemon.sh start resourcemanager

- 启动NodeManager
yarn-daemon.sh start nodemanager

2.2.3 查看集群
- 命令行:
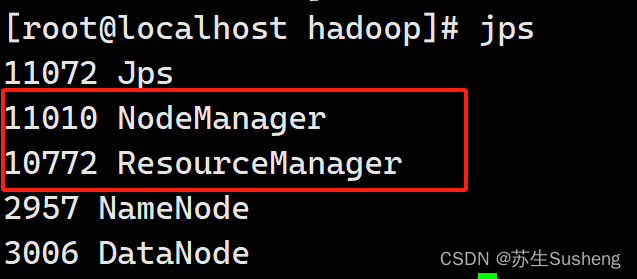
- web 端查看 YARN 页面:
http://192.168.29.200:8088
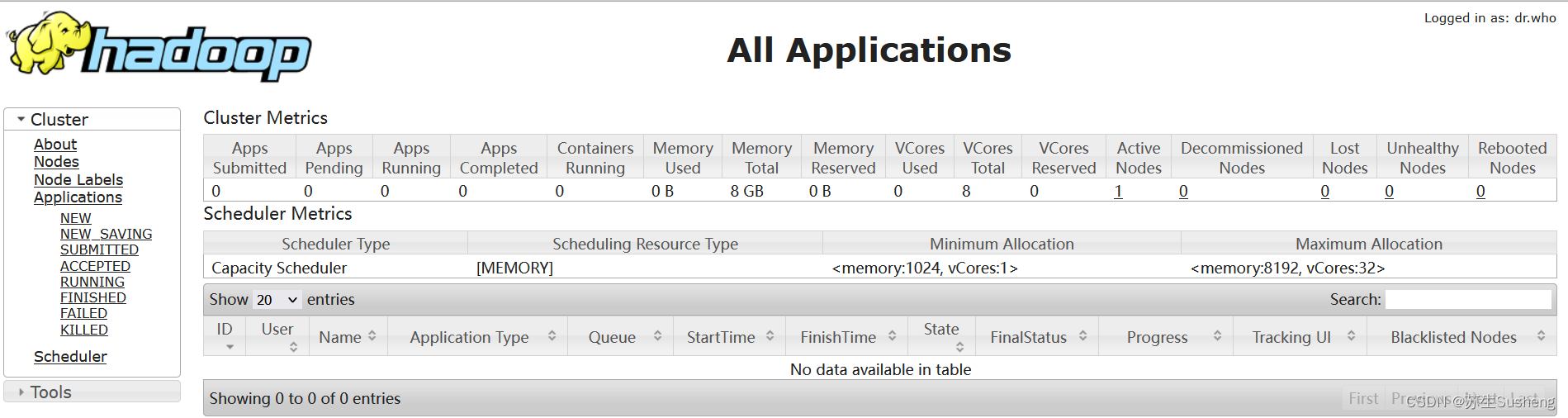
2.2.4 操作集群
- 删除 HDFS 文件系统上的 output 文件
hdfs dfs -rm -R /user/susheng/output
- 在 hadoop-2.7.7 目录下,运行 MapReduce 程序
hadoop jar /hadoop/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /user/susheng/input /user/susheng/output
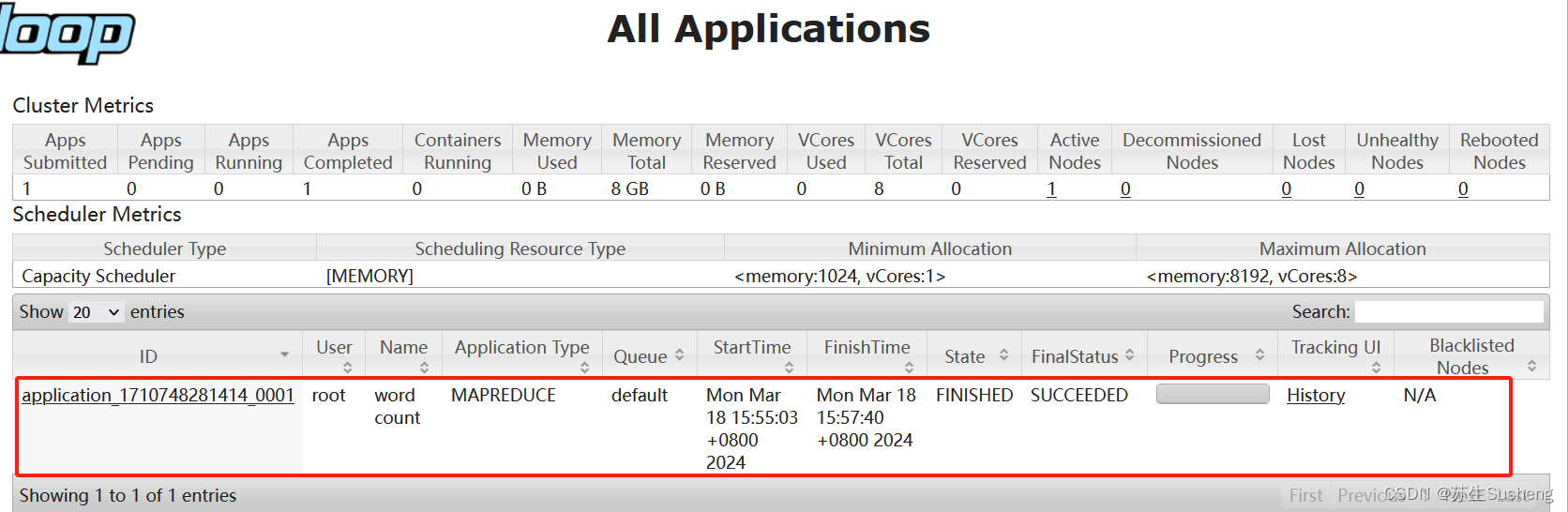
- 查看运行结果
-
命令行查看:
hdfs dfs -cat /user/susheng/output/*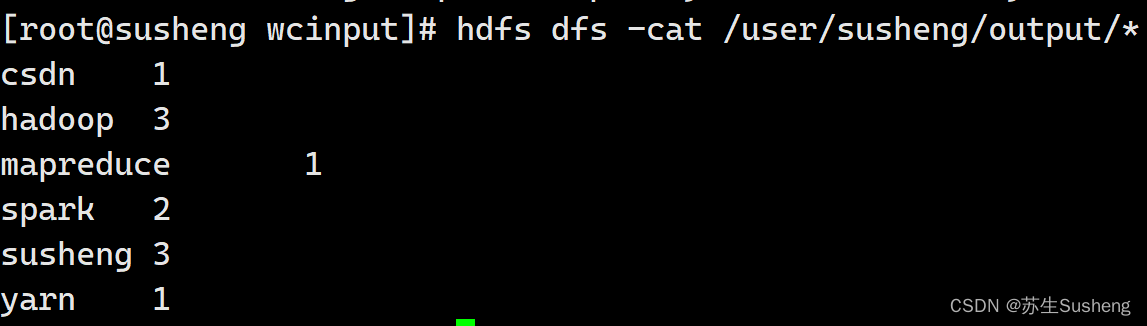
-
浏览器页面查看:
2.3配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。
2.3.1 配置 mapred-site.xml
在该文件里面增加以下配置:
<!-- 历史服务器端地址 --><property><name>mapreduce.jobhistory.address</name><value>susheng:10020</value></property><!-- 历史服务器web端地址 --><property><name>mapreduce.jobhistory.webapp.address</name><value>susheng:19888</value></property>
2.3.2 启动历史服务器
mr-jobhistory-daemon.sh start historyserver

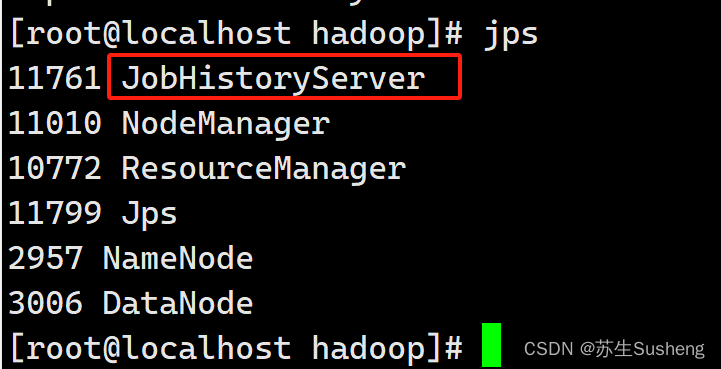
2.3.3 查看历史服务器是否启动
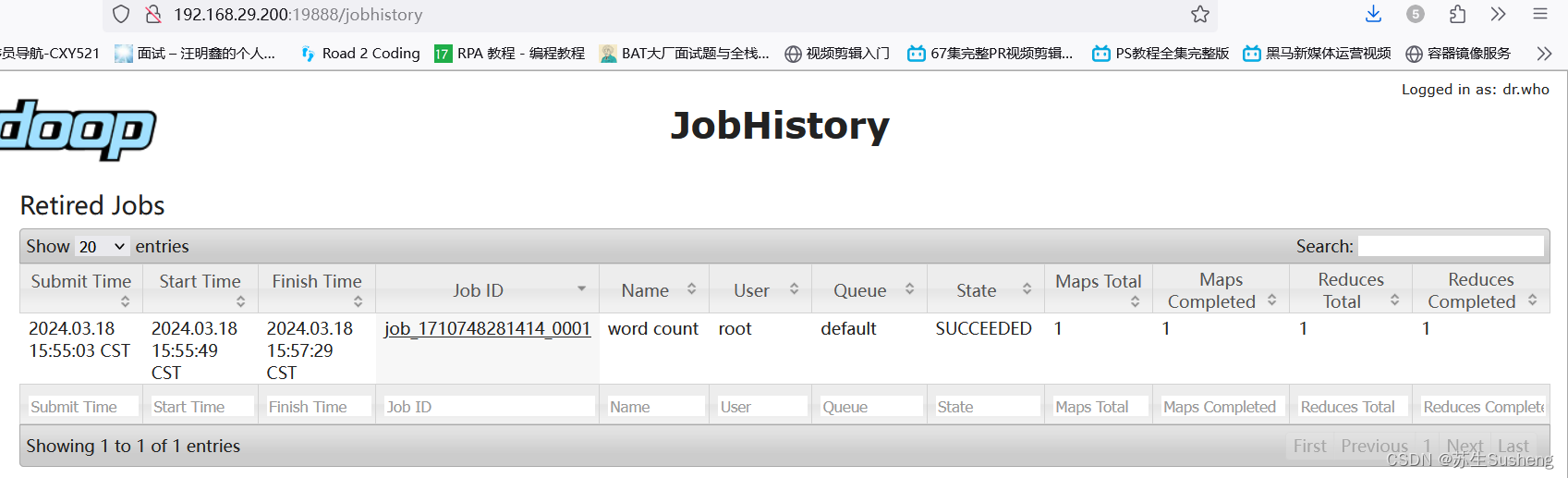
2.3.4 查看 JobHistory http://192.168.29.200:19888/
2.4配置日志的聚集
日志聚集:应用运行完成以后,将程序运行日志信息上传到 HDFS 系统上。
作用:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动 NodeManager 、ResourceManager 和 HistoryManager。
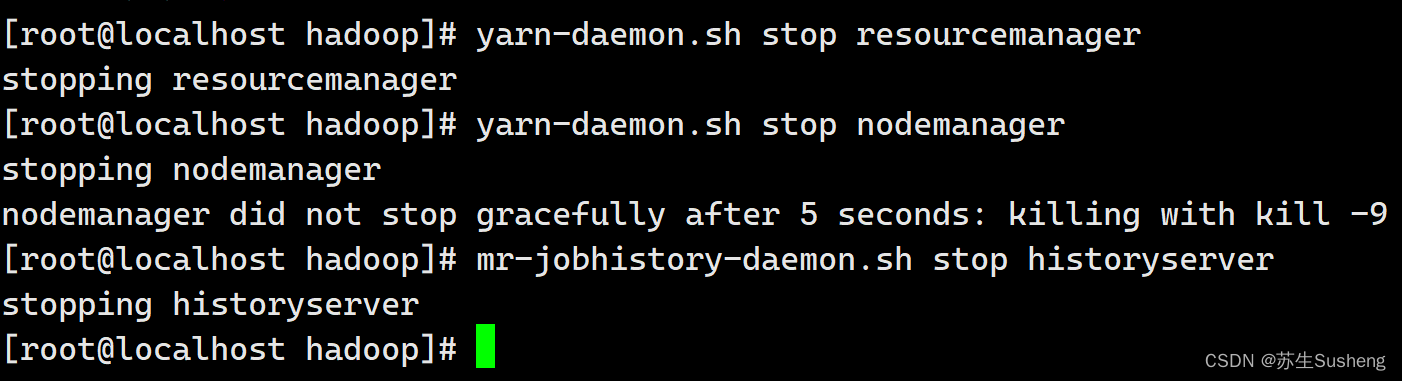
2.4.1 关闭 NodeManager 、ResourceManager 和 HistoryManager
yarn-daemon.sh stop resourcemanager
yarn-daemon.sh stop nodemanager
mr-jobhistory-daemon.sh stop historyserver
2.4.2 配置 yarn-site.xml
在该文件里面增加以下配置:
<!-- 日志聚集功能使能 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!-- 日志保留时间设置7天 --><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property>
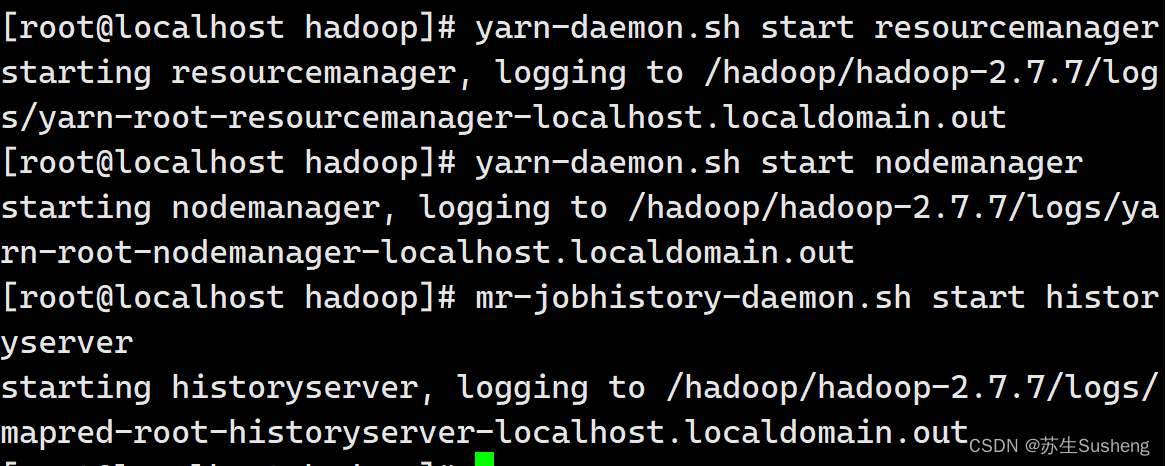
2.4.3 启动 NodeManager 、ResourceManager 和 HistoryManager
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start nodemanager
mr-jobhistory-daemon.sh start historyserver
2.4.4 删除HDFS上已经存在的输出文件
hdfs dfs -rm -R /user/susheng/output
2.4.5 在 hadoop-2.7.7 目录下,执行 WordCount 程序
hadoop jar /hadoop/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /user/susheng/input /user/susheng/output
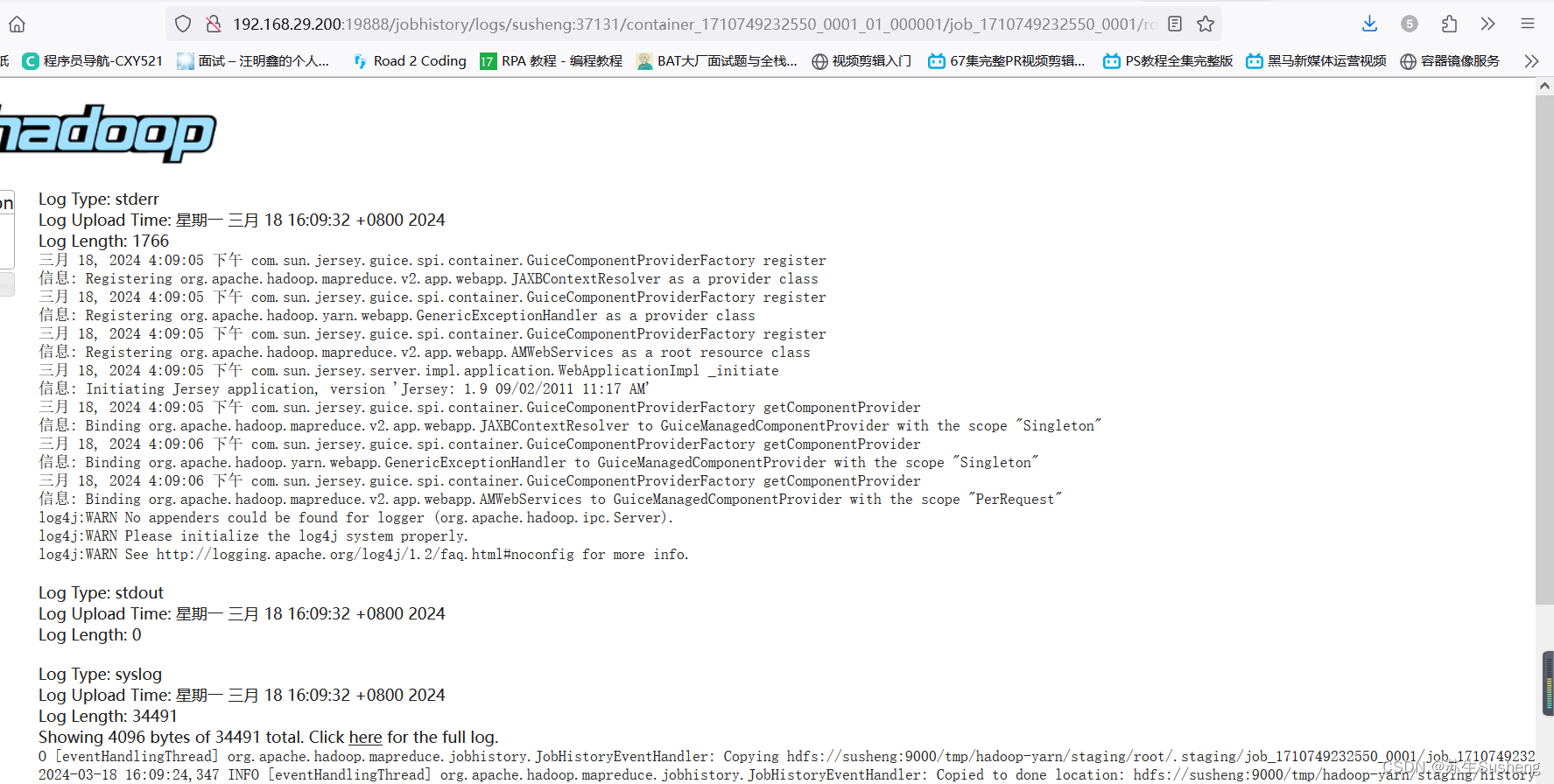
2.4.6 查看日志

3.完全分布式运行模式
3.1虚拟机准备
3.1.1 准备(克隆) 3 台客户机
| 主机名称 | IP地址 |
|---|---|
| master | 192.168.29.200 |
| slave1 | 192.168.29.31 |
| slave2 | 192.168.29.32 |
3.1.2 每台机器分别修改 /etc/hosts 文件,将每个机器的 hostname 和 ip 对应
vim /etc/hosts#master的host
192.168.217.200 master
#slave1的host
192.168.217.31 slave1
#slave2的host
192.168.217.32 slave2
3.1.3 修改slave设备配置
-
修改静态ip,重启网关服务
systemctl restart network -
修改主机名称
hostnamectl set-hostname susheng -
关闭防火墙
systemctl stop firewalld
3.2 编写集群分发脚本 xsync
3.2.1 scp(secure copy)安全拷贝
-
scp 定义:scp 可以实现服务器与服务器之间的数据拷贝。
-
基本语法:
scp -r 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
3.2.2 rsync(remote synchronize)远程同步工具
-
rsync 定义:rsync 主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。rsync 和 scp 区别:用 rsync 做文件的复制要比 scp 的速度快,rsync 只对差异文件做更新。scp 是把所有文件都复制过去。
-
基本语法:
rsync -rvl 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称说明:-v:显示复制过程 、-l:拷贝符号链接
3.2.3 xsync 集群分发脚本
需求:循环复制文件到所有节点的相同目录下
-
在 /usr/local/bin 目录下创建 xsync 文件
vim xsync -
在文件中输入以下内容:
#!/bin/bash #1 获取输入参数个数,如果没有参数,直接退出 pcount=$# if((pcount==0)); thenecho no args;exit; fi#2 获取文件名称 p1=$1 fname=`basename $p1` echo fname=$fname#3 获取上级目录到绝对路径 pdir=`cd -P $(dirname $p1); pwd` echo pdir=$pdir#4 获取当前用户名称 user=`whoami`#5 循环 for i in master slave1 slave2doecho "****************** $i *********************"rsync -rvl $pdir/$fname $user@$i:$pdirdone -
修改脚本 xsync 具有执行权限
chmod 777 xsync -
调用脚本形式:xsync 文件名称
3.3 集群配置
3.3.1 集群部署规划
| master | slave1 | slave2 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
3.3.2 配置集群
- 配置核心文件:配置 core-site.xml
<configuration><!-- 指定HDFS中NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://master:9000</value></property><!-- 指定Hadoop运行时产生文件的存储目录 --><property><name>hadoop.tmp.dir</name><value>/hadoop/hadoop-2.7.7/data/tmp</value></property>
</configuration>
- HDFS 配置文件
-
配置 hadoop-env.sh:修改 JAVA_HOME 路径:
# The java implementation to use. export JAVA_HOME=/usr/local/java/jdk1.8.0_151 -
配置 hdfs-site.xml
<configuration><!-- 指定HDFS副本的数量 --><property><name>dfs.replication</name><value>3</value></property><!-- 指定Hadoop辅助名称节点主机配置 --><property><name>dfs.namenode.secondary.http-address</name><value>slave2:50090</value></property> </configuration>
- YARN 配置文件
-
配置 yarn-env.sh:修改 JAVA_HOME 路径:
# The java implementation to use. export JAVA_HOME=/usr/local/java/jdk1.8.0_151 -
配置 yarn-site.xml
<configuration><!-- Reducer获取数据的方式 --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定YARN的ResourceManager的地址 --><property><name>yarn.resourcemanager.hostname</name><value>slave1</value></property><!-- 日志聚集功能使能 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!-- 日志保留时间设置7天 --><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property>
</configuration>
- MapReduce 配置文件
- 配置 mapred-env.sh:修改 JAVA_HOME 路径:
# The java implementation to use. export JAVA_HOME=/usr/local/java/jdk1.8.0_151 - 配置 mapred-site.xml
<configuration><!-- 指定MR运行在YARN上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property><!-- 历史服务器端地址 --><property><name>mapreduce.jobhistory.address</name><value>master:10020</value></property><!-- 历史服务器web端地址 --><property><name>mapreduce.jobhistory.webapp.address</name><value>master:19888</value></property>
</configuration>
3.3.3 在集群上分发配置好的 Hadoop 目录
xsync /hadoop/
3.4 在集群上分发配置好的 Hadoop 目录
3.4.1 如果集群是第一次启动,需要格式化 NameNode
hadoop namenode -format
3.4.2 在 master上启动 NameNode
hadoop-daemon.sh start namenode
3.4.3 在 master、slave1 和 slave2 上分别启动 DataNode
hadoop-daemon.sh start datanode
3.5 配置 SSH 无密登录
3.5.1 免密登录原理
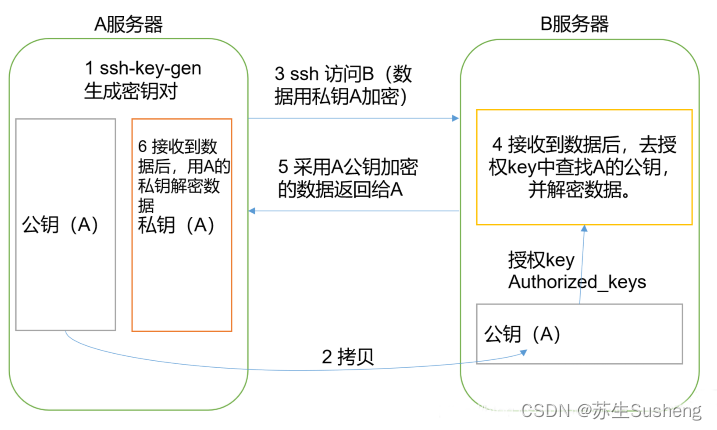
3.5.2 生成公钥和私钥
在 /root 目录下输入以下命令,然后敲(三个回车),就会在 .ssh 目录下生成两个文件 id_rsa(私钥)、id_rsa.pub(公钥):
ssh-keygen -t rsa
3.5.3 将公钥拷贝到要免密登录的目标机器上
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2
3.5.4 在另两台机器上也做 2、3 操作
3.6 群起集群
3.6.1 配置 slaves(/hadoop/hadoop-2.7.7/etc/hadoop/slaves)
-
在该文件中增加如下内容:
master slave1 slave2注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
-
同步所有节点配置文件
xsync slaves
3.6.2 启动集群
-
如果集群是第一次启动,需要格式化 NameNode (注意格式化之前,一定要先停止上次启动的所有 namenode 和 datanode 进程,然后再删除 data 和 log 数据)
hdfs namenode -format -
启动 HDFS
start-dfs.sh -
启动 YARN(slave1 上)
注意:NameNode 和 ResourceManger 如果不是同一台机器,不能在 NameNode 上启动 YARN,应该在 ResouceManager 所在的机器上启动 YARN。start-yarn.sh
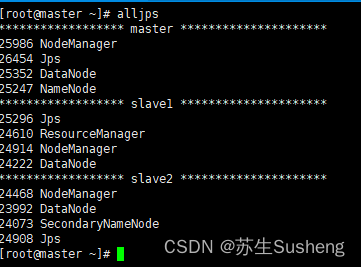
3.6.3 编写查看集群所有节点 jps 脚本 alljps
-
在 /usr/local/bin 目录下创建文件 alljps
vim alljps#!/bin/bashfor i in master slave1 slave2doecho "****************** $i *********************"ssh $i "source /etc/profile && jps"done -
修改脚本 alljps 具有执行权限
chmod 777 alljps -
调用脚本形式:alljps
3.7 集群时间同步
时间同步的方式:找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,比如,每隔十分钟,同步一次时间。
3.7.1 时间服务器配置(必须 root 用户)
-
安装 ntp
yum install ntp -
修改 ntp 配置文件
vim /etc/ntp.conf
修改内容如下:
⑴ 授权 192.168.1.0-192.168.1.255 网段上的所有机器可以从这台机器上查询和同步时间
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
⑵ 集群在局域网中,不使用其他互联网上的时间
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
⑶ 当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步
server 127.127.1.0
fudge 127.127.1.0 stratum 10
-
修改/etc/sysconfig/ntpd 文件
vim /etc/sysconfig/ntpd #添加内容如下(让硬件时间与系统时间一起同步) SYNC_HWCLOCK=yes -
重新启动 ntpd 服务
systemctl restart ntpd.service -
设置 ntpd 服务开机启动
systemctl enable ntpd.service
3.7.22 其他机器配置(必须root用户)
在其他机器配置10分钟与时间服务器同步一次
crontab -e
编写定时任务如下:
*/10 * * * * /usr/sbin/ntpdate master








![[善用佳软]推荐掌握小工具:Json解析的命令行工具jq](https://img-blog.csdnimg.cn/img_convert/8c6fa468367da2885f965762226e00cd.png)