24.02 北京人工智能研究院(BAAI)提出以数据为中心的轻量级多模态模型
arxiv论文:2402.Efficient Multimodal Learning from Data-centric Perspective
代码:https://github.com/BAAI-DCAI/Bunny
在线运行:https://wisemodel.cn/space/baai/Bunny

项目进展 Bunny (兔子,音标 ˈbʌni )
2024.03.15 🔥 Bunny-v1.0-2B-zh,专注中文,发布!它建立在 SigLIP 和 Qwen1.5-1.8B 之上。
2024.03.06 🔥 Bunny训练数据发布!在 HuggingFace 或 ModelScope 中查看有关 Bunny-v1.0-data 的更多详细信息!
2024.02.20 🔥 Bunny技术报告出炉了!
2024.02.07 🔥 Bunny发布!基于 SigLIP 和 Phi-2 构建的 Bunny-v1.0-3B 不仅与类似尺寸的型号相比,而且与更大的 MLLM (7B) 相比,性能优于最先进的 MLLM,甚至实现了与 LLaVA-13B 相当的性能!
简介
| 翻译 | 原文 |
|---|---|
Bunny 是一个轻量级但功能强大的多模态模型系列。它提供多种即插即用的视觉编码器,如 EVA-CLIP、SigLIP 和语言主干网(LLM),包括 Phi-1.5、StableLM-2、Qwen1.5 和 Phi-2。为了弥补模型大小的减少,我们通过从更广泛的数据源中精选来构建信息量更大的训练数据。值得注意的是,我们基于 SigLIP 和 Phi-2 构建的 Bunny-v1.0-3B 型号不仅与类似尺寸的型号相比,而且与更大的 MLLM (7B) 相比,性能优于最先进的 MLLM,甚至实现了与 13B 型号相当的性能。 | > Bunny is a family of lightweight but powerful multimodal models. It offers multiple plug-and-play vision encoders, like EVA-CLIP, SigLIP and language backbones, including Phi-1.5, StableLM-2, Qwen1.5 and Phi-2. To compensate for the decrease in model size, we construct more informative training data by curated selection from a broader data source. Remarkably, our Bunny-v1.0-3B model built upon SigLIP and Phi-2 outperforms the state-of-the-art MLLMs, not only in comparison with models of similar size but also against larger MLLMs (7B), and even achieves performance on par with 13B models. |
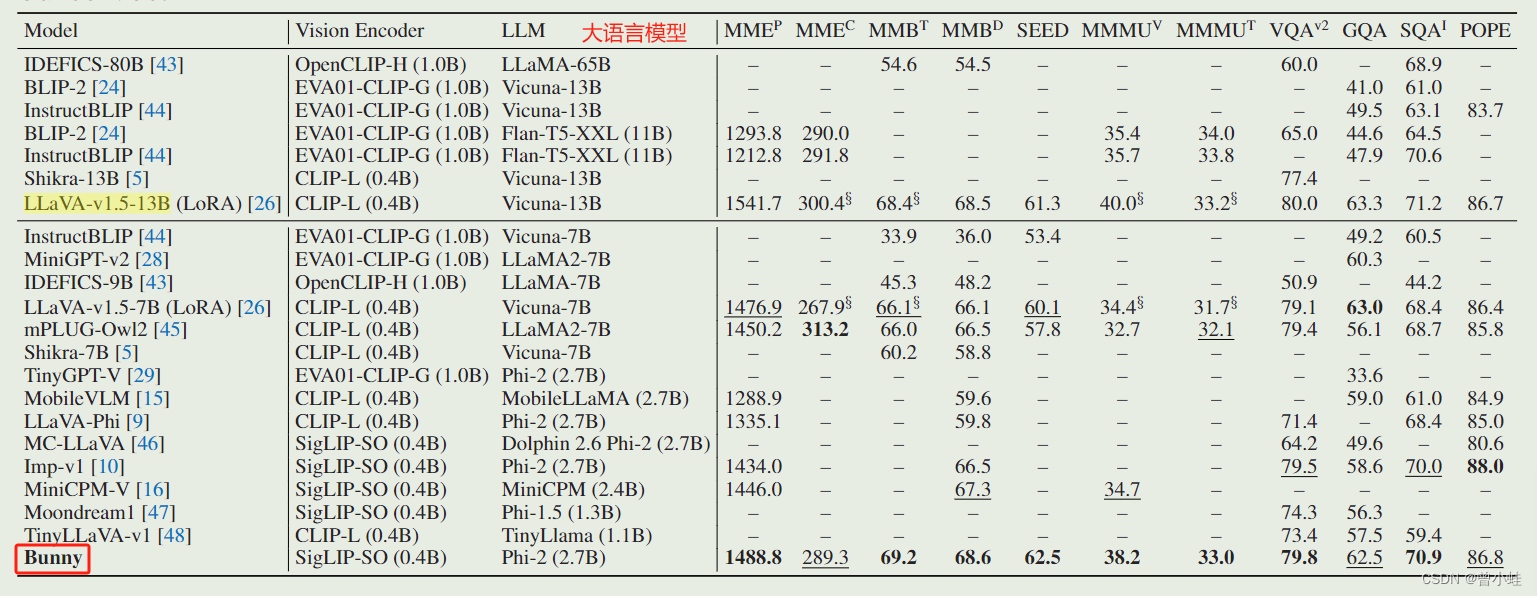
与主流模型性能对比
在 11 个基准测试中与最先进的 MLLM 的比较。我们的模型在大多数设置中都优于它们。例如LLaVA-v1.5-13B
算法架构(灵活选择不同的模型组件)
原图1:Bunny供了灵活的视觉编码器和LLM主干组合选择,这些组合通过跨模态的映射模型(projector)进行对齐
其中
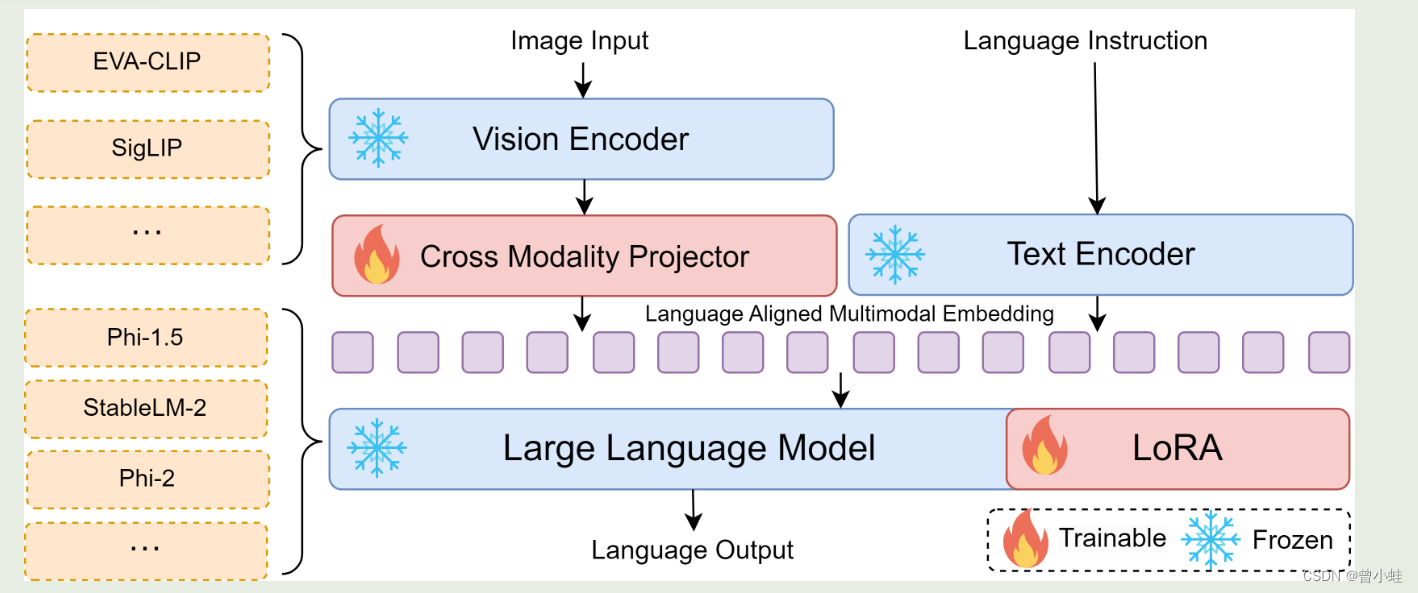
Large Language Model Backbone:提供了三种最先进的轻量级LLM选项:
Phi-1.5 (1.3B)、
StableLM-2 (1.6B)
Phi-2 (2.7B)
视觉编码器(Vision Encoder):
轻量级视觉编码器提供了两个选项:
SigLIP [14] 和 EVACLIP [30],
它们都是具有 428M 参数的高效与语言对齐图像编码器(language-aligned image encoders)。
图像到语言特征的映射模块(Cross-modality Projector)
基于LLaVA模型,我们利用一个带有GELU激活函数的两层MLP作为跨模态投影仪来对齐视觉编码器和LLM。
原文效果图
| 提问为英文 | 翻译 |
|---|---|
 |  |
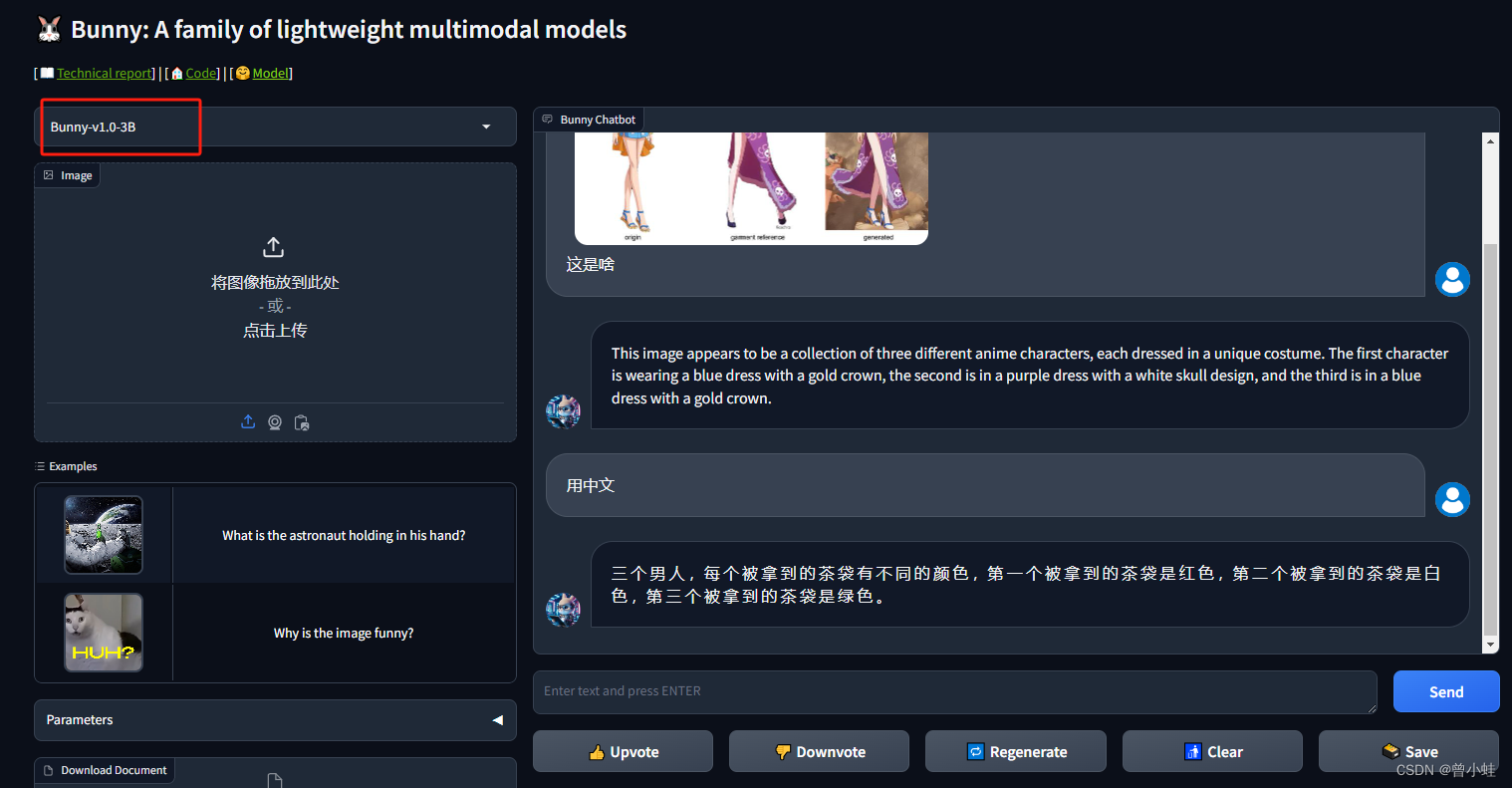
实测 (v1.0-3B-中文翻车)
无法用中文直接提问
如何训练?
Bunny 在 8 个 A100 GPU 上进行训练. (也可用更小的gpu训练)
作者分别构建了 Bunny-pretrain-LAION-2M 和 Bunny-695K 进行预训练和指令调整。
两阶段训练策略。
最初,我们将预训练的视觉编码器中的视觉嵌入与来自 LLM 的文本嵌入对齐。
随后,我们应用视觉指令微调来充分利用 MLLM 在各种多模态任务中的能力。
我们在两个阶段采用相同的交叉熵损失进行下一个令牌预测。
在预训练阶段,只对一个 epoch 优化跨模态投影仪。
在微调阶段,我们利用 LoRA [34] 为一个 epoch 训练跨模态投影仪和 LLM 主干。
作者发现 LoRA 在经验上比跨模型架构的所有组合进行完全调整带来更好的性能,这可能是因为较小的模型更容易受到灾难性遗忘的影响,而 LoRA 调整缓解了这个问题
预训练对齐数据构建
我们从LAION-2B 构建了一个高质量的预训练数据,即我们将LAION-2B浓缩为2M核心集,用于数据高效学习
设计了一种基于CLIP嵌入的三步核心集选择方案。
首先,受 SemDeDup 论文的启发,我们通过 k-means 对所有 2B 图像嵌入进行聚类,然后在每个集群中,构建一个无向图,如果它们的余弦相似度高于预定阈值,则任何两个嵌入都连接起来。在每个连通子图中只保留一个样本,其到簇质心的欧几里得距离在中位数处排名。通过将阈值设置为 0.86,我们获得了 952M 的子集。
其次,我们通过其文本嵌入和图像嵌入之间的余弦相似度对剩余的样本进行排序,并保持样本排名 40% - 60%,从而导致 190M 的子集。这样,去除了低质量的图像-文本对。
第三,我们通过其图像嵌入与其聚类质心之间的余弦相似度对剩余的样本进行排序,并保持样本排名 15%-35%,导致子集 38M,捕获 LAION-2B 的本质和多样性。我们最终从38M核心集中随机抽样200万个样本,从而得到Bunny-pretrain-LAION-2M,以获得适当的培训成本。
微调数据Bunny695K的构建
我们收集了一组视觉指令调优数据集——DataOptim,在此基础上我们探索了微调数据集的更好组合。
具体来说,我们利用
SVIT-mix-665K from: SVIT: Scaling up Visual Instruction Tuning
并结合 WizardLM-evol-intstruct-70K 、 ShareGPT-40K ,从而得到 Bunny695K。
我们发现,在多模态数据上调整 MLLM 可能会损害其继承认知能力
本地部署测试
待续