排序算法
- 排序的概述
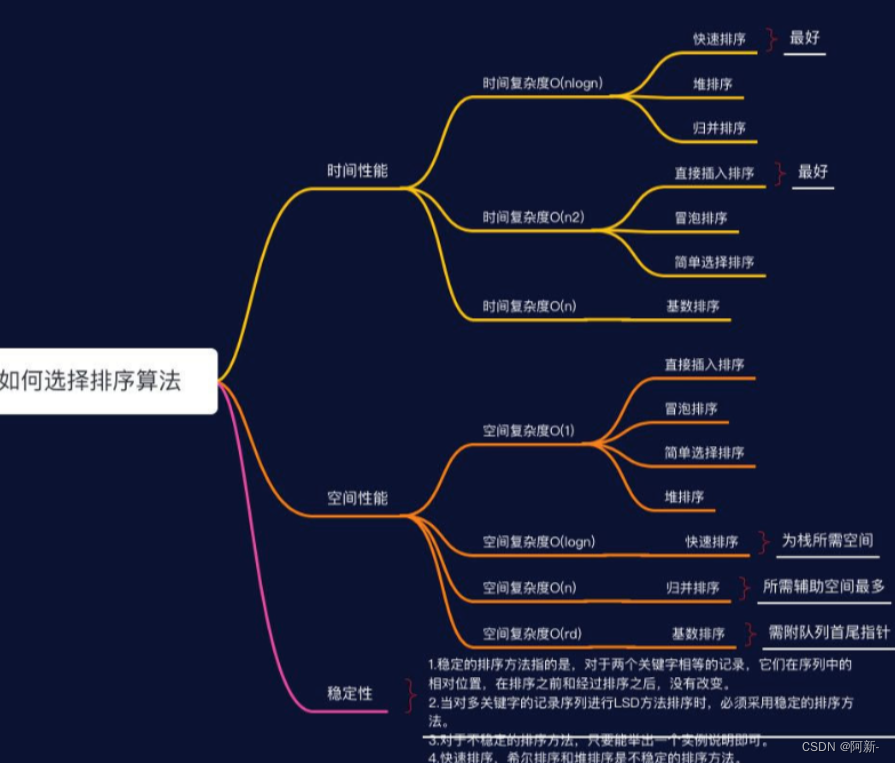
- 排序的分类
- 分为5大类:
- 优点及缺点
- 如何选择排序算法
- 八种排序之间的关系:
- 一、插入排序
- 直接插入排序
- 动图详解
- 代码实现
- 希尔排序
- 动图详解
- 代码实现
- 二、交换排序
- 冒泡排序:
- 动图详解
- 代码实现
- 快速排序:
- 动图详解
- 代码实现
- 三、选择排序
- 直接选择排序
- 动图详解
- 代码实现
- 堆排序
- 动图详解
- 代码实现
- 四、归并排序
- 归并排序
- 动图详解
- 代码实现
- 五、桶排序
- 基数排序
- 动图详解
- 代码实现
- 计数排序
- 动图详解
- 代码实现
- end
排序的概述

排序的分类
分为5大类:
1.插入排序(直接插入排序、希尔排序)。
2.交换排序(冒泡排序、快速排序)。
3.选择排序(直接选择排序、堆排序)。
4.归并排序。
5.分配排序(箱排序、基数排序)。
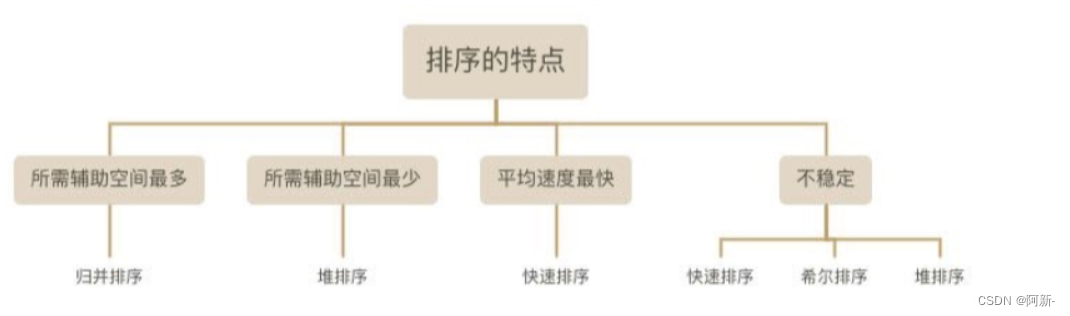
优点及缺点
所需辅助空间最多:归并排序
所需辅助空间最少:堆排序
平均速度最快:快速排序
不稳定:快速排序,希尔排序,堆排序。
如何选择排序算法
1.数据的规模;
2.数据的类型;
3.数据已有的顺序。
- 一般来说,当数据规模较小时,应选择直接插入排序或冒泡排序。
- 任何排序算法在数据量小时基本体现不出来差距。考虑数据的类型。
- 比如如果全部是正整数,那么考虑使用桶排序为最优。
- 考虑数据已有顺序,快排是一种不稳定的排序(当然可以改进),对于大部分排好的数据,快排会浪费大量不必要的步骤。
- 数据量极小,而且已经基本排好序,冒泡是最佳选择。我们说快排好,是指大量随机数据下,快排效果最理想。而不是所有情况。
八种排序之间的关系:

一、插入排序
1.直接插入排序。
2.希尔插入排序。
直接插入排序
说明:将一个记录插入到已经排序好的有序表中。1.sorted数组的第0个位置没有放数据。2.从sorted第二个数据开始处理。如果该数据比它前面的数据要小,说明该数据要往前面移动。
动图详解

用法:a.首先将该数据备份放到sorted的第0位置当哨兵。b.然后将该数据前面那个数据后移。c.然后往前搜索,找插入位置。d.找到插入位置之后讲第0位置的那个数据插入对应位置。
O(n*n),当待排记录序列为正序时,时间复杂度提高至O(n)。
代码实现
/*** 从小到大排序* @param l 排序起始下标位置* @param r 排序结束下标位置* @param array 要排序的数组*/
public static void insert_sort(int l, int r, int[] array) {for(int i=l+1;i<=r;++i) {for(int j=l;j<i;++j) {//要插入的数int temp=array[i];//找到比要插入的数大的位置if(array[j]>temp) {//将它们全部后移一位for(int k=i;k>j;--k)array[k]=array[k-1];//插入到该位置array[j]=temp;break;}}}
}
//也可以使用以下写法,后续的希尔排序将采用如下写法
public static void insert_sort(int l, int r, int[] array) {for(int i=l+1;i<=r;++i) {int j=i-1, temp=array[i];while(temp) {j>=0 && array[j]>array[j+1]=array[j];j--;}array[j+1]=temp;}
}
希尔排序
1.先将整个待排记录序列分割成若干个子序列分别进行直接插入排序。
2.待整个序列中的记录基本有序时,再对全体记录进行一次直接插入排序。
动图详解

代码实现
/*** 从小到大排序* @param l 排序起始位置* @param r 排序结束位置* @param array 要排序的数组*/
public static void shell_sort(int l, int r, int[] array) {int length=r-l+1;//确定每次的增量for(int gap=length>>1;gap>=1;gap>>=1) {//对每个增量分组使用插排for(int i=gap;i<=r;++i) {//i插入到它所在的增量分组int temp=array[i], j=i-gap;while(j>=0 && array[j]>temp) {array[j+gap]=array[j];j-=gap;}array[j+gap]=temp;}}
}
二、交换排序
1.冒泡排序。
2.快速排序。
冒泡排序:
该算法是专门针对已部分排序的数据进行排序的一种排序算法。
如果在你的数据清单中只有一两个数据是乱序的话,用这种算法就是最快的排序算法。
如果你的数据清单中的数据是随机排列的,那么这种方法就成了最慢的算法了。
因此在使用这种算法之前一定要慎重。
这种算法的核心思想是扫描数据清单,寻找出现乱序的两个相邻的项目。
当找到这两个项目后,交换项目的位置然后继续扫描。
重复上面的操作直到所有的项目都按顺序排好。
动图详解
代码实现
/*** 从小到大排序* @param l 排序起始下标位置* @param r 排序结束下标位置* @param array 要排序的数组*/
public static void bubble_sort(int l, int r, int[] array) {boolean flag = true;for(int i=r;i>l;--i) {for(int j=l;j<i;++j) {//若逆序就交换相邻的两个数if(array[j]>array[j+1]) {int temp=array[j];array[j]=array[j+1];array[j+1]=temp;flag=false;}}//如果一趟排序下来一次交换都没有,说明序列已经有序,无需继续排序了if(flag) break;}
}快速排序:
通过一趟排序,将待排序记录分割成独立的两个部分,
其中一部分记录的关键字均比另一部分记录的关键字小,
则可分别对这两部分记录继续进行排序,以达到整个序列有序。
具体做法是:使用两个指针lowhigh,初值分别设置为序列的头,和序列的尾,设置pivotkey为第一个记录,首先从high开始向前搜索第一个小于pivotkey的记录和pivotkey所在位置进行交换,然后从low开始向后搜索第一个大于pivotkey的记录和此时pivotkey所在位置进行交换,重复直到low=high了为止。
动图详解

代码实现
/*** 从小到大排序* @param l 排序起始位置* @param r 排序结束位置* @param array 要排序的数组*/
public static void quick_sort(int l, int r, int[] array) {int i=l,j=r,mid=array[(l+r+1)>>1];//等号必须有为了让终止条件不为i==j,否则递归的区间会在i==j时出现重合while(i<=j) {//没有等号、不能将mid定义成(l+r+1)/2然后这里改成array[mid],因为位于mid位置的数字是可能被交换走的!while(array[i]<mid) i++;while(array[j]>mid) j--;if(i<=j) {int temp=array[i];array[i]=array[j];array[j]=temp;i++;j--;}}if(l<j) quick_sort(l,j,array);if(i<r) quick_sort(i,r,array);
}三、选择排序
1.直接选择排序。
2.堆排序
直接选择排序
第i次选取到arrayLength-1中间最小的值放在i位置。
动图详解

代码实现
/*** 从小到大排序* @param l 排序起始下标位置* @param r 排序结束下标位置* @param array 要排序的数组*/
public static void select_sort(int l, int r, int[] array) {int temp;for(int i=l;i<=r-1;++i) {//假设最值位于最前面,也就是i位置int min=i;//选出最值for(int j=i+1;j<=r;++j){if(array[j]<array[min]) min=j;}//如果真正的最值不在i处,就交换这两个位置的数if(min!=i) {temp=array[i];array[i]=array[min];array[min]=temp;}}
}
堆排序
首先,数组里面用层次遍历的顺序放一棵完全二叉树。
从最后一个非终端结点往前面调整,直到到达根结点,
这个时候除根节点以外的所有非终端节点都已经满足堆得条件了,
于是需要调整根节点使得整个树满足堆得条件,
于是从根节点开始,沿着它的儿子们往下面走
(最大堆沿着最大的儿子走,最小堆沿着最小的儿子走)。
主程序里面,首先从最后一个非终端节点开始调整到根也调整完,形成一个heap,
然后将heap的根放到后面去
(即:每次的树大小会变化,但是root都是在1的位置,以方便计算儿子们的index,
所以如果需要升序排序,则要逐步大顶堆。
因为根节点被一个个放在后面去了,降序排序则要建立小顶堆。
动图详解

代码实现
public class Heap {public int[] array;//注意下标是从1开始private boolean type= Lower;//默认为小根堆private static final int default_capacity = 11;//初始容量为11private int size=0;public static final boolean Lower = true;public static final boolean upper = false;//默认建堆public Heap() {array = new int[default_capacity];}/*** @param type 指定优先级*/public Heap(boolean type) {array = new int[default_capacity];this.type=type;}/*** @param array 指定堆中的内容* @param size 指定堆的大小*/public Heap(int[] array,int size) {this.array = new int[size+1];this.size=size;System.arraycopy(array,0,this.array,1,size);build(size);}/*** @param array 指定堆中的内容* @param size 指定堆的大小* @param type 指定优先级*/public Heap(int[] array,int size,boolean type) {this.array = new int[size+1];this.size=size;this.type=type;System.arraycopy(array,0,this.array,1,size);build(size);}//交换函数private void swap(int x,int y,int[] a){int tmp=a[x];a[x]=a[y]; a[y]=tmp;}/*** 优先级比较函数* @param x* @param y* @return 若为Lower模式,x<y返回1;若为upper模式,x>y返回1。返回1表示x的优先级更高,返回-1表示y的优先级更高,返回0表示优先级相同。*/private int compare(int x,int y) {if(x>y) return (type? -1:1);if(x<y) return (type? 1:-1);return 0;}//上浮操作private void rise(int k) {if(k==1) return;//到达根结点就停止上浮int father=k>>1;if(compare(array[father],array[k])!=-1) return;swap(father,k,array);//若父结点的优先级低于子结点,就交换它们的位置rise(father);//父结点继续上浮}//下沉操作private void sink(int k) {int l=k<<1,r=l+1;//左子结点,右子结点if(l>size) return;//到达叶子结点就停止下沉int t=l;//假设左子结点优先级更高if(r<=size) t=compare(array[l],array[r])==1? l:r;//如果右子结点存在,则比较左右子结点的优先级,取优先级更高的if(compare(array[k],array[t])!=-1) return;swap(k,t,array);//若父结点的优先级低于子结点,就交换它们的位置sink(t);//交换后的子结点继续下沉}//高效建堆private void build(int tail) {int k=tail/2;while(k!=0) {sink(k);k--;}}//添加元素public void push(int x) {int oldCapacity = array.length-1;//堆满,就执行扩容if(oldCapacity == size) grow(oldCapacity);array[++size]=x;rise(size);}//扩容private void grow(int oldCapacity) {int newCapacity = oldCapacity + ((oldCapacity < 64) ?(oldCapacity + 2) :(oldCapacity >> 1));int[] newArray = new int[newCapacity+1];System.arraycopy(array,1,newArray,1,size);array = newArray;}//删除优先级最高的元素public void pop() {array[1]=array[size--];sink(1);}//获取优先级最高的元素public int top() {return array[1];}//获取长度public int size() {return size;}
}
四、归并排序
归并排序
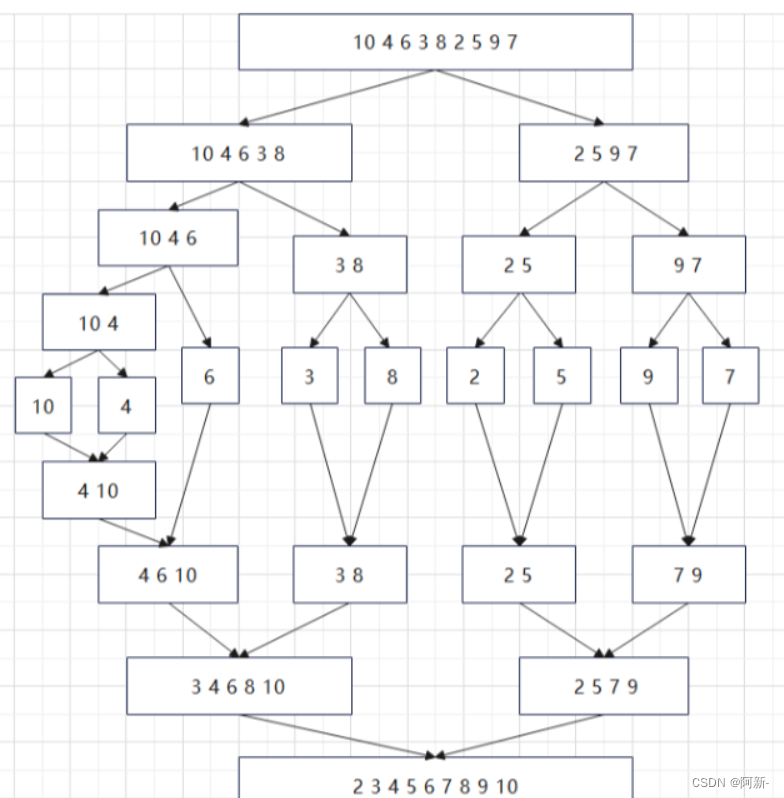
将两个或两个以上的有序表组合成一个新的有序表。
归并排序要使用一个辅助数组,大小跟原数组相同,递归做法。
每次将目标序列分解成两个序列,分别排序两个子序列之后,
再将两个排序好的子序列merge到一起。
动图详解

代码实现
/*** 从小到大排序* @param l 排序起始下标位置* @param r 排序结束下标位置* @param array 要排序的数组* @param assist 辅助数组*/
public static void binary_sort(int l, int r, int[] array, int[] assist) {if(l==r) return;int mid=(l+r)>>1;//分成两个子序列binary_sort(l,mid,array,assist);binary_sort(mid+1,r,array,assist);int i=l,j=mid+1,tag=l;//将两边的子序列合并成一个有序的序列while(i<=mid && j<=r) {if(array[i]<=array[j]) assist[tag++]=array[i++];else assist[tag++]=array[j++];}//若两边子序列长度不等,就要单独复制while(i<=mid) assist[tag++]=array[i++];while(j<=r) assist[tag++]=array[j++];for(int k=l;k<=r;++k) array[k]=assist[k];
}
五、桶排序
基数排序
使用10个辅助队列,假设最大数的数字位数为 x,则一共做x次,
从个位数开始往前,以第i位数字的大小为依据,将数据放进辅助队列,搞定之后回收。
下次再以高一位开始的数字位为依据。
动图详解

代码实现
/*** 从小到大排序* @param l 排序起始位置* @param r 排序结束位置* @param array 要排序的数组*/
public static void radix_sort(int l, int r, int[] array) {int max=array[l];for(int i=l;i<=r;++i) if(array[i]>max) max=array[i];int[][] assist = new int[10][r-l+1];//0~9int[] b = new int[10];for(int i=0;i<10;++i) b[i]=0;//最大的数有几位int length=(max+"").length();//最大的数有几位就排序几次for(int i=0,n=1;i<length;++i,n*=10) {//n=1时,按个位排序,n=10时按十位排序,以此类推for(int j=l;j<=r;++j) {//0~9,rest即为b[]的下标int rest=array[j]/n %10;//array[j]被放在rest处的第b[rest]个位置assist[rest][b[rest]]=array[j];b[rest]++;}int tag=0;//0~9for(int k=0;k<10;++k) {if(b[k]!=0) {for(int t=0;t<b[k];++t)//取出放在k处的第t个位置的数字,k对应放入时的rest,t对应放入时的b[rest]array[tag++]=assist[k][t];b[k]=0;}}}
}
计数排序
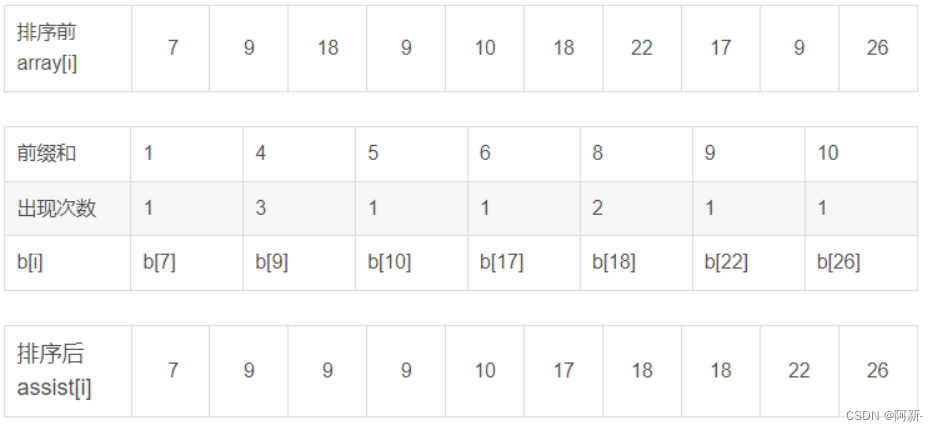
基本思想:
待排序的数不是存放在数组里,而是作为数组的下标存放,
数组中存放该数字在序列中出现的个数,所以叫计数排序。
由于每个数组都可以类比成一个桶,数组下标就是桶的标号,
当数字等于标号时就将其放入该桶中,所以也可以叫作桶排序,
不过真正的桶排序要比这复杂
该排序需要序列中的数字在一个明显的范围内。
最终只要按顺序输出数组值不为0的下标即可,
数组值等于多少就输出几次,时间复杂度为O(n)。
动图详解

代码实现
/*** 从小到大排序* @param l 排序起始位置* @param r 排序结束位置* @param array 要排序的数组*/
public static void bucket_sort(int l, int r, int[] array) {int max=array[l];for(int i=l;i<=r;++i) if(array[i]>max) max=array[i];int[] assist = new int[r-l+1];int[] b = new int[max+1];for(int i=0;i<=max;++i) b[i]=0;for(int i=l;i<=r;++i) b[array[i]]++;//统计前缀和for(int i=1;i<=max;++i) b[i]+=b[i-1];//逆序遍历arrayfor(int i=r;i>=l;--i) {assist[b[array[i]]-1]=array[i];b[array[i]]--;}//assist只是暂时存放数据,最后仍然要将数据放回arrayfor(int i=l;i<=r;++i) array[i]=assist[i];
}