-
Unsupervised Domain Adaptation for Medical Image Segmentation by Disentanglement Learning and Self-Training
摘要:无监督域适应(Unsupervised domain adaptive, UDA)旨在提高深度模型在无标记数据上的分割性能,近年来受到广泛关注。在本文中,我们提出了一种新的基于解纠缠学习和自训练的UDA分割方法(即DLaST)。解纠缠学习将图像分解为域不变的解剖和域特定的模态组件。为了充分利用解纠缠学习,我们提出了一种新的形状约束来提高自适应性能。自训练策略通过对抗学习和伪标签进一步自适应地提高了模型对目标域的分割性能,隐式地促进了解剖空间中的特征对齐。实验结果表明,本文提出的方法在三个公共数据集(心脏数据集、腹部数据集和大脑数据集)上的医学图像分割性能优于目前最先进的UDA方法。代码将很快发布。
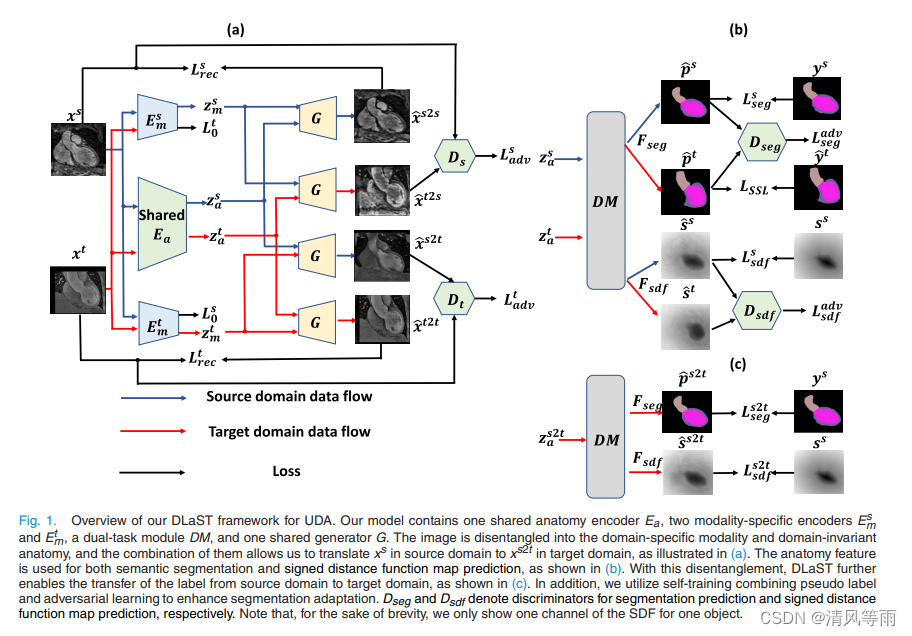
-
TransMatch: A Transformer-Based Multilevel Dual-Stream Feature Matching Network for Unsupervised Deformable Image Registration
摘要:特征匹配是指建立两幅图像之间区域(通常是体素特征)的对应关系,是基于特征的配准的重要前提。对于形变图像的配准任务,传统的基于特征的配准方法通常使用迭代匹配策略进行感兴趣区域匹配,其中特征选择和匹配是明确的,但特定的特征选择方案通常在解决特定应用的问题中有用,每次配准需要几分钟。在过去的几年里,基于学习的方法,如VoxelMorph和TransMorph,已经被证明是可行的,并且它们的性能已经显示出与传统方法相比的竞争力。然而,这些方法通常是单流,将两个待配准的图像拼接成一个2通道的整体,然后直接输出变形场。图像特征转化为图像间匹配关系是隐式的。在本文中,我们提出了一种新颖的端到端双流无监督框架,命名为TransMatch,其中每个图像被输入到一个单独的流分支,每个分支独立进行特征提取。然后,利用Transformer模型中自我注意机制的查询键匹配思想,实现图像对之间的显式多级特征匹配。在三个脑磁共振数据集(LPBA40, IXI和OASIS)上进行了全面的实验,结果表明,与常用的配准方法(SyN, NiftyReg, VoxelMorph, CycleMorph, vitv - v - net和TransMorph)相比,本文提出的方法在几个评估指标上达到了最先进的性能,证明了我们的模型在可变形医学图像配准中的有效性。
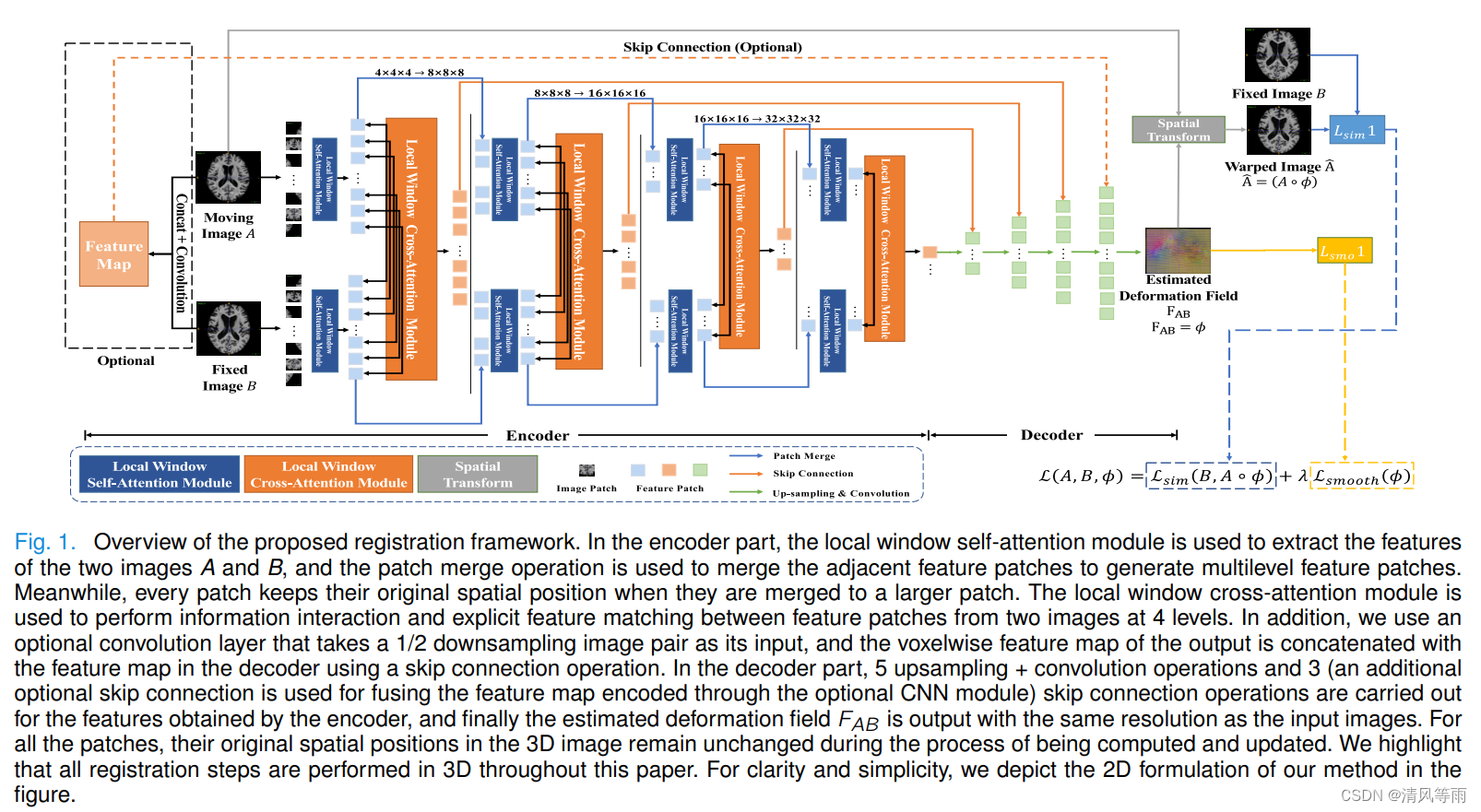
-
Correction for Mechanical Inaccuracies in a Scanning Talbot-Lau Interferometer
摘要:基于光栅的x射线相位衬度,特别是暗场x射线摄影是一种有前景的新的成像方式,用于医学应用。目前,人们正在研究暗视野成像在人类肺部疾病早期诊断中的潜在优势。这些研究使用了一个相对较大的扫描干涉仪,采集时间较短,与桌面实验室设置相比,这以显著降低机械稳定性为代价。振动会造成光栅排列的随机波动,造成图像中的伪影。在这里,我们描述了一种新的最大似然方法来估计这种运动,从而防止这些伪影。它是量身定制的扫描设置,不需要任何样品免费区域。不像以前描述的任何方法,它解释了在暴露之间和暴露期间的运动。 -
Robust Vascular Segmentation for Raw Complex Images of Laser Speckle Contrast Based on Weakly Supervised Learning
摘要:激光散斑衬比成像(Laser speckle contrast imaging, LSCI)因其无创能力和优异的时空分辨率,被广泛用于活体实时检测和分析局部血流微循环。然而,由于血液微循环结构的复杂性和病变区域不规则的血管畸变导致大量的特定噪声,LSCI图像的血管分割仍面临许多困难。此外,LSCI图像数据注释的困难也阻碍了基于监督学习的深度学习方法在LSCI图像血管分割领域的应用。为了解决这些问题,我们提出了一种鲁棒的弱监督学习方法,选择阈值组合和处理流程来代替人力密集型的标注工作来构建数据集的地面真实值,并设计了一个基于unet++和ResNeXt的深度神经网络FURNet。训练得到的模型实现了高质量的血管分割,在已构建和未知数据集上均能捕获多场景血管特征,具有良好的泛化性。此外,我们在肿瘤栓塞治疗前后对该方法进行了活体验证。本工作为实现LSCI血管分割提供了新的途径,也在人工智能辅助疾病诊断领域取得了新的应用层面的进展。
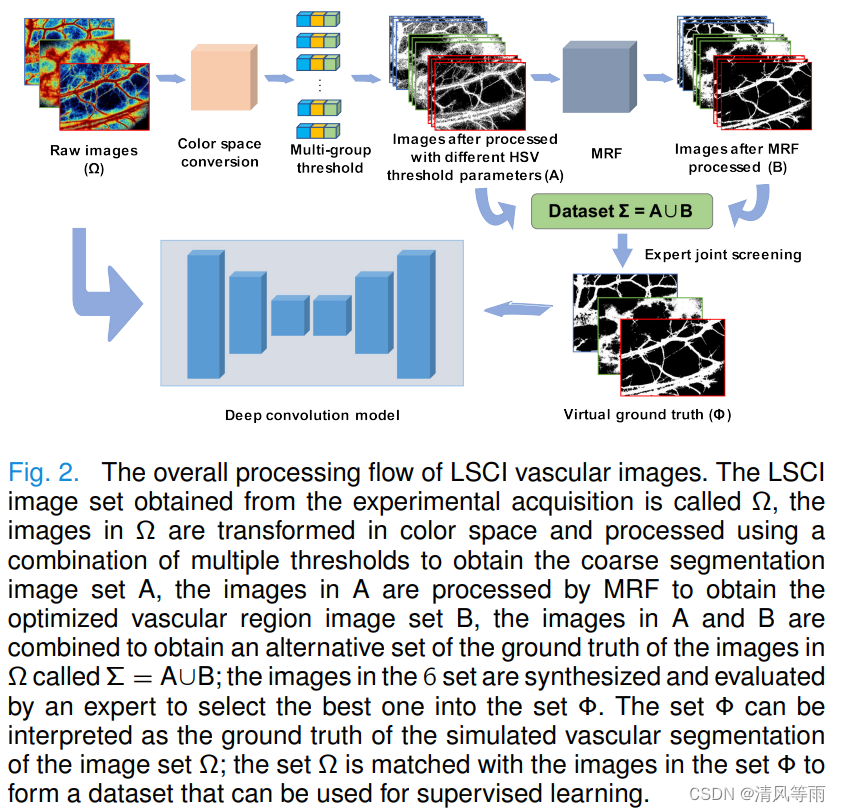
-
Locating X-Ray Coronary Angiogram Keyframes via Long Short-Term Spatiotemporal Attention With Image-to-Patch Contrastive Learning
摘要:x线冠状动脉造影(XCA)中,定位运动对比剂的起始、顶点和结束关键帧并进行关键帧计数,对心血管疾病的诊断和治疗具有重要意义。为了从重叠复杂背景的类别不平衡和边界不确定的前景血管动作中找到这些关键帧,我们提出了长短期时空注意,通过将卷积长短期记忆(CLSTM)网络集成到一个多尺度Transformer中来学习基于连续帧的深度特征中的分段和序列级依赖。图像到补丁的对比学习进一步嵌入在基于clstm的长期时空注意模块和基于transformer的短期注意模块之间。图像级对比模块利用了XCA序列对对比度图像级前景/背景的长期关注,而拼接式对比投影则选择背景中的随机小块作为卷积核,将前景/背景帧投射到不同的潜在空间中。采集一个新的XCA视频数据集来评估该方法。实验结果表明,本文提出的方法获得了72.45%的平均精度和0.8296的F-score,大大优于目前最先进的方法。源代码可在https://github.com/Binjie-Qin/STA-IPCon获取。
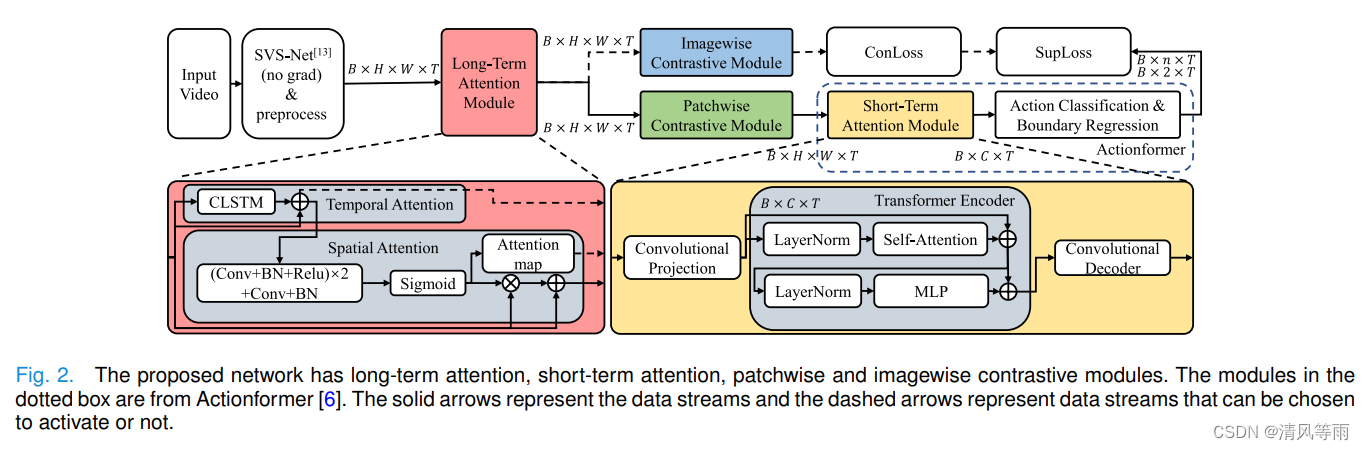
-
DSMT-Net: Dual Self-Supervised Multi-Operator Transformation for Multi-Source Endoscopic Ultrasound Diagnosis
摘要:胰腺癌是所有癌症中预后最差的。超声内镜(EUS)评估胰腺癌风险和深度学习对EUS图像分类的临床应用受到分级间变异性和标记能力的阻碍。造成这些困难的关键原因之一是,EUS图像来自多个来源,分辨率、有效区域和干扰信号不同,使得数据的分布高度可变,对深度学习模型的性能产生负面影响。此外,人工标记图像是耗时的,需要大量的努力,导致希望有效地利用大量的未标记数据进行网络训练。为了解决这些挑战,本研究提出了用于多源EUS诊断的双重自我监督多操作者转换网络(Dual Self-supervised Multi-Operator Transformation Network, DSMT-Net)。DSMT-Net包括一种多算子变换方法,以标准化提取EUS图像中的感兴趣区域,并消除不相关的像素。此外,本文还设计了一种基于变压器的双重自我监督网络,用于整合未标记的EUS图像,对表示模型进行预训练,并将其转移到分类、检测和分割等监督任务中。我们收集了一个大规模的基于EUS的胰腺图像数据集(LEPset),包括3500张病理证实的标记EUS图像(来自胰腺癌和非胰腺癌)和8000张用于模型开发的未标记EUS图像。自我监督方法也被应用于乳腺癌诊断,并在两个数据集中与最先进的深度学习模型进行了比较。结果表明,DSMT-Net显著提高了胰腺癌和乳腺癌诊断的准确性。
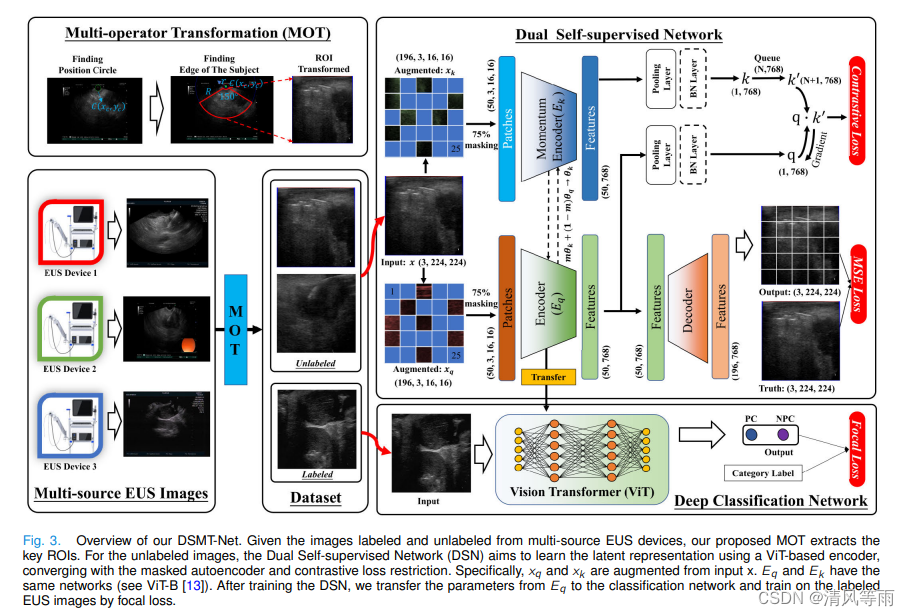
-
Multi-ConDoS: Multimodal Contrastive Domain Sharing Generative Adversarial Networks for Self-Supervised Medical Image Segmentation
摘要: 现有的自监督医学图像分割通常会遇到域移位问题(即预训练的输入分布与微调的输入分布不同)和/或多模态问题(即仅基于单模态数据,无法利用医学图像丰富的多模态信息)。针对这些问题,本文提出了多模态对比域共享(Multi-ConDoS)生成对抗网络,以实现有效的多模态对比自监督医学图像分割。与现有的自监督方法相比,Multi-ConDoS具有以下3个优势:(1)利用多模态医学图像,通过多模态对比学习学习更全面的对象特征;(ii)通过整合CycleGAN的循环学习策略和Pix2Pix的跨域翻译损失来实现域翻译;(3)引入了新的领域共享层,从多模态医学图像中既学习领域特定的信息,又学习领域共享的信息。在两个公开的多模态医学图像分割数据集上的广泛实验表明,只有5%(分别为10%)Multi-ConDoS不仅大大超过了最先进的自我监督和半监督医学图像分割基线与相同比例的标记数据,而且也达到了类似(有时甚至更好)的性能与完全监督分割方法的50%(分别为100%)的标记数据,从而证明我们的工作可以在极低的标记工作量下实现卓越的分割性能。此外,消融研究证明,以上三种改进对于Multi-ConDoS实现这种非常优越的性能都是有效和必不可少的。
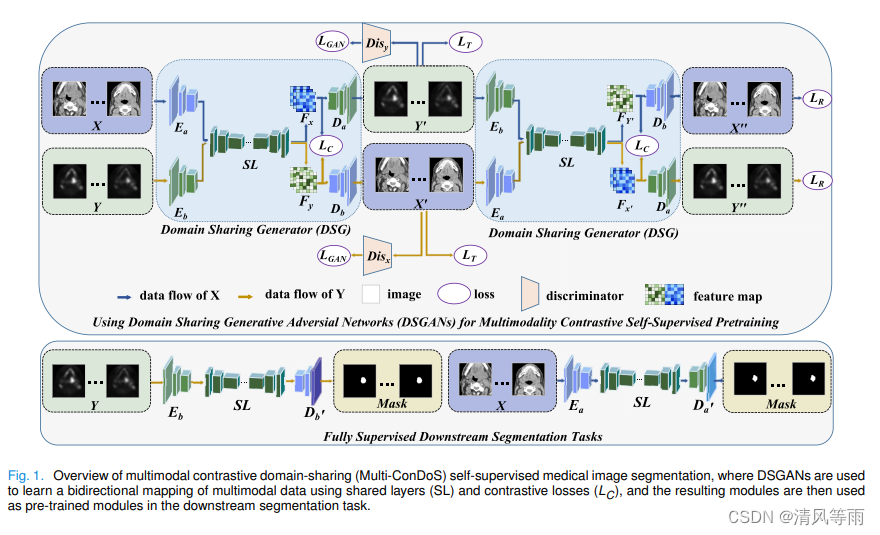
-
LViT: Language Meets Vision Transformer in Medical Image Segmentation
摘要: 深度学习已广泛应用于医学图像分割等方面。然而,由于数据注释成本过高,现有的医学图像分割模型难以获得足够的高质量标记数据,从而限制了其性能。为了缓解这一限制,我们提出了一种新的文本增强的医学图像分割模型LViT (Language meets Vision Transformer)。在我们的LViT模型中,加入了医学文本注释,以弥补图像数据的质量不足。此外,文本信息可以在半监督学习中引导生成质量更高的伪标签。我们还提出了一种指数伪标签迭代机制(EPI),以帮助像素级注意模块(PLAM)在半监督LViT设置中保持局部图像特征。在我们的模型中,LV(语言-视觉)损失的目的是直接使用文本信息监督未标记图像的训练。为了进行评估,我们构建了三个包含x射线和CT图像的多模态医学分割数据集(图像+文本)。实验结果表明,本文提出的LViT在完全监督和半监督条件下均具有较好的分割性能。代码和数据集可在https://github.com/HUANGLIZI/LViT获取。
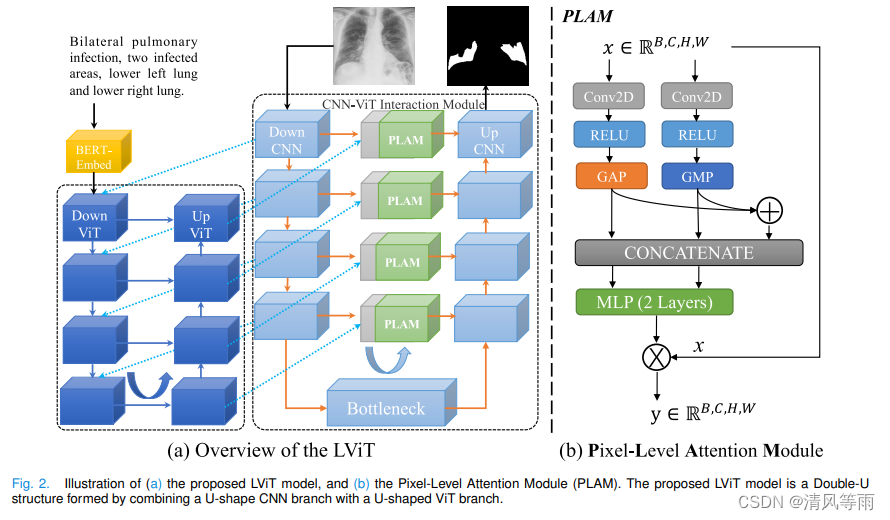
-
Mapping Multi-Modal Brain Connectome for Brain Disorder Diagnosis via Cross-Modal Mutual Learning
摘要: 近年来,多模态脑连接组的研究有了长足的发展,为脑疾病的诊断提供了新的思路。在这一范式中,功能网络和结构网络,例如来自fMRI和DTI的功能和结构连接,在某种程度上是相互作用的,但不一定是线性相关的。因此,利用互补信息进行脑连接组分析仍然是一个巨大的挑战。近年来,图卷积网络(Graph Convolutional Networks, GNN)被广泛应用于多模态脑连接体融合。然而,现有的GNN方法大多无法耦合多模态关系。在这方面,我们提出了一个跨模态图神经网络(Cross-GNN),通过动态图学习和相互学习来捕获跨模态依赖。具体来说,多模态表示法被巧妙地耦合到一个组合空间中,用于推理多模态依赖关系。此外,我们研究了显式和隐式的互学习:(1)基于多模态对应矩阵,通过显式交叉嵌入得到跨模态表示。(2)我们提出了一种跨模态蒸馏方法,以隐式正则化具有跨模态语义上下文的潜在表示。我们对用心学习的对应矩阵进行统计分析,以评估关联疾病生物标志物的多模态关系。我们在三个数据集上的大量实验表明,我们提出的方法在疾病诊断方面具有良好的预测性能和多模态连接组生物标志物定位方面的优越性。
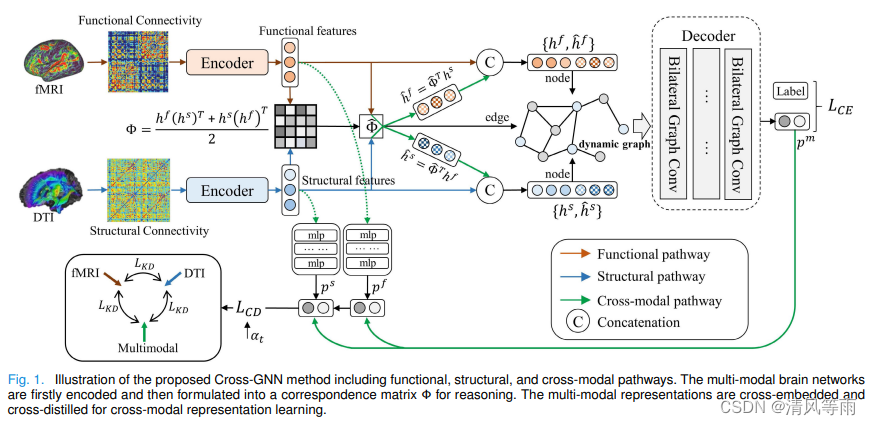
-
Deep Generalized Learning Model for PET Image Reconstruction
**摘要:**由于这个逆问题的病态性,低计数正电子发射断层成像(PET)成像具有挑战性。先前的研究表明,深度学习(DL)有望改善低计数PET图像的质量。然而,几乎所有数据驱动的深度学习方法在去噪后都存在精细结构退化和模糊效应。在传统的迭代优化模型中引入深度学习可以有效地改善其图像质量和恢复精细结构,但很少有研究考虑模型的完全松弛,导致这种混合模型的性能没有得到充分利用。本文提出了一种深度学习和基于交替方向乘子法(ADMM)的迭代优化模型的学习框架。该方法的创新之处在于我们打破了保真算子的固有形式,并使用神经网络对其进行处理。正则化项被进一步推广。在仿真数据和实际数据上对所提出的方法进行了评价。定性和定量结果均表明,本文提出的神经网络方法优于基于部分算子扩展的神经网络方法、神经网络去噪方法和传统方法。

-
Windowed Radon Transform and Tensor Rank-1 Decomposition for Adaptive Beamforming in Ultrafast Ultrasound
**摘要:**极速超声是近年来出现的一种可替代传统聚焦超声的超声技术。由于所需的超声次数少,极速超声能够以潜在的非常高的帧率对人体进行成像。然而,未考虑到的声速变化,往往导致重建图像的相位像差。因此,极速超声的诊断能力最终受到阻碍。因此,有强烈的需求自适应波束形成方法,以适应声速像差。最近提出了一些这样的技术,但它们通常缺乏平行性或直接纠正发射和接收相位畸变的能力。在本文中,我们介绍了一种自适应波束形成方法,旨在解决这些缺点。为此,我们计算了几幅利用延时和求和重建的复杂射频图像的加窗Radon变换。然后,对得到的局部正弦图进行加权张量秩-1分解,最终利用其结果重建出校正后的图像。我们使用模拟和体外数据证明了我们的方法能够成功地恢复无像差的图像,并且它优于相干复合和最近引入的SVD波束形成器。最后,我们在活体数据上验证了所提出的波束形成技术,与两种参考方法相比,图像质量得到了显著改善。

-
RECIST-Induced Reliable Learning: Geometry-Driven Label Propagation for Universal Lesion Segmentation
摘要: 基于计算机断层扫描(CT)图像的自动通用病灶分割(ULS)可以减轻放射科医师的负担,提供比现行实体肿瘤疗效评价标准(RECIST)更准确的评估。然而,由于缺乏大规模的像素级标记数据,这项任务尚不完善。本文提出了一种弱监督学习框架,利用医院图像存档和通信系统(PACS)中现有的大规模病变数据库进行ULS。与以往通过浅层交互式分割技术构建伪替代掩码进行全监督训练的方法不同,我们提出从RECIST注释中挖掘隐含信息,从而设计一个统一的RECIST诱导的可靠学习(RiRL)框架。特别地,我们引入了一种新的标签生成方法和一种动态软标签传播策略,以避免噪声训练和泛化不良的问题。前者命名为RECIST诱导几何标记,利用RECIST的临床特征对标签进行初步、可靠的传播。trimap将病变切片分为前景、背景和不清晰3个区域,从而在大范围内提供强而可靠的监测信号。建立拓扑知识驱动图,对最优分割边界进行动态标签传播,进一步优化分割边界。在一个公共基准数据集上的实验结果表明,本文提出的方法在很大程度上超过了基于SOTA recist的ULS方法。我们的方法超过了SOTA方法超过2.0%,1.5%,1.4%和1.6% Dice与ResNet101, ResNet50, HRNet和ResNest50骨干。

-
Coarse–Super-Resolution–Fine Network (CoSF-Net): A Unified End-to-End Neural Network for 4D-MRI With Simultaneous Motion Estimation and Super-Resolution
摘要: 四维磁共振成像(4D-MRI)是图像引导放射治疗(IGRT)中用于肿瘤运动管理的新兴技术。然而,目前的4D-MRI由于采集时间长和患者的呼吸变化,存在空间分辨率低和强运动伪影的问题。如果处理不当,这些局限性会对IGRT的治疗计划和实施产生不利影响。在本研究中,我们开发了一种新的深度学习框架,称为粗-超分辨率-细网络(CoSF-Net),以在一个统一的模型中同时实现运动估计和超分辨率。我们在充分挖掘4D-MRI固有特性的基础上,考虑到有限和不完全匹配的训练数据集,设计了CoSF-Net。我们在多个真实患者数据集上进行了大量实验,以评估开发的网络的可行性和鲁棒性。与现有网络和3种最先进的常规算法相比,CoSF-Net不仅准确估计了4D-MRI呼吸时相之间的形变向量场,而且同时提高了4D-MRI的空间分辨率,增强了解剖特征,生成了高时空分辨率的4D-MRI图像。

-
One-Shot Weakly-Supervised Segmentation in 3D Medical Images
摘要: 深度神经网络在医学图像分割中通常需要精确且大量的标注来实现出色的分割性能。单次监督学习和弱监督学习是很有前景的研究方向,它们通过分别从一个带注释的图像学习一个新类别和使用粗标签来减少标记工作。在这项工作中,我们提出了一种创新的框架,用于一次性和弱监督设置的3D医学图像分割。首先,基于不同人体解剖模式相似的假设,提出了一种传播-重建网络,将涂鸦从一个注释的体积传播到未标记的三维图像。然后设计一个多级相似性去噪模块,基于从解剖级到像素级的嵌入来细化涂鸦。将涂鸦扩展为伪掩模后,我们观察到漏分类的体素主要发生在边界区域,并提出提取自支撑原型进行具体细化。在这些弱监督分割结果的基础上,我们进一步使用噪声标签训练策略训练新的类的分割模型。在3个CT和1个MRI数据集上的实验表明,所提出的方法比目前最先进的方法得到了显著的改进,即使在严重的类别不平衡和低对比度下也能保持鲁棒性。代码可以在https://github.com/LWHYC/OneShot_WeaklySeg上公开获取。

-
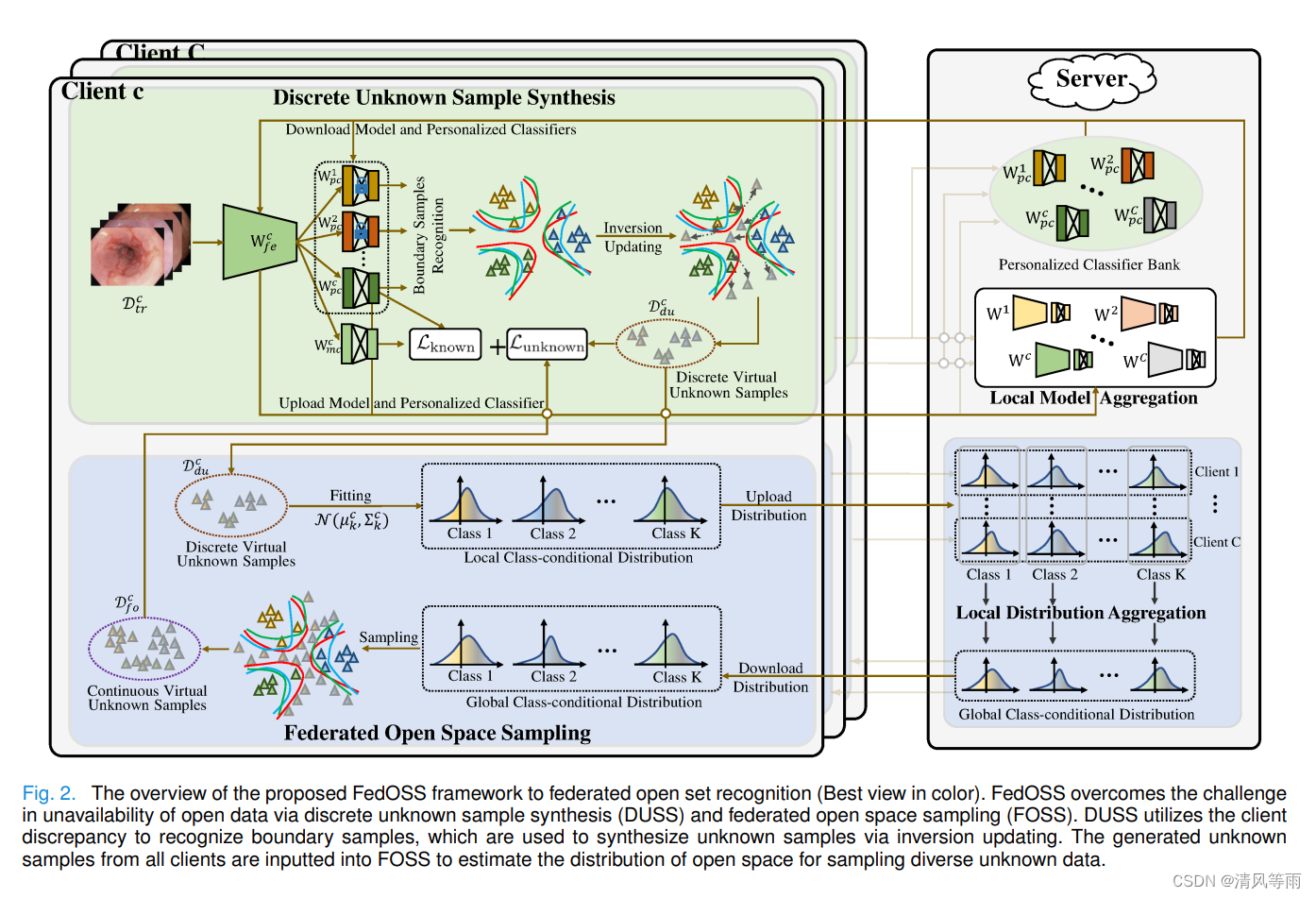
FedOSS: Federated Open Set Recognition via Inter-Client Discrepancy and Collaboration
摘要: 开放集识别(Open set recognition, OSR)旨在对已知疾病进行准确分类,并将未见疾病识别为医疗场景中的未知类别。然而,在现有的OSR方法中,从分布式站点收集数据来构建大规模的集中训练数据集通常会导致高度的隐私和安全风险,通过流行的跨站点训练范式联邦学习(FL)可以优雅地缓解这一风险。为此,我们首次提出了联邦开放集识别(FedOSR),同时提出了一种新的联邦开放集综合(FedOSS)框架,以解决FedOSR的核心挑战:在训练阶段,所有预期客户端无法获得未知样本。提出的FedOSS框架主要利用两个模块,即离散未知样本合成(DUSS)和联邦开放空间采样(FOSS),以生成虚拟未知样本,用于学习已知和未知类之间的决策边界。具体来说,DUSS利用客户间的知识不一致性识别决策边界附近的已知样本,然后将它们推到决策边界之外,合成离散的虚拟未知样本。FOSS将这些来自不同客户端的未知样本联合起来,估计决策边界附近开放数据空间的类条件分布,进一步对开放数据进行采样,从而提高虚拟未知样本的多样性。此外,我们还进行了全面的消融实验来验证DUSS和FOSS的有效性。与最先进的方法相比,FedOSS在公共医疗数据集上表现出卓越的性能。源代码可在https://github.com/CityU-AIM-Group/FedOSS获取。
-
Patient-Specific Heart Geometry Modeling for Solid Biomechanics Using Deep Learning
摘要: 基于患者特定心脏几何形状的自动体积网格划分有助于加速各种生物力学研究,如干预后应激估计。对于成功的下游分析,以前的网格划分技术往往会忽略重要的建模特征,特别是对于像瓣叶这样的薄结构。在本研究中,我们提出了一种新的基于变形的深度学习方法,该方法可以自动生成具有高空间精度和单元质量的个性化体积网格。我们的方法的主要新颖之处在于使用最小的足够的表面网格标签来实现精确的空间精度,并同时优化各向同性和各向异性的变形能量来实现体积网格质量。在推断过程中,网格生成只需0.13 s/次扫描,每个网格可以直接用于有限元分析,而无需任何人工后处理。钙化网格也可以随后加入,以提高模拟精度。大量的支架部署模拟验证了我们的方法用于大规模分析的可行性。我们的代码可以在https://github.com/danpak94/Deep-Cardiac-Volumetric-Mesh获取。

-
Masked Conditional Variational Autoencoders for Chromosome Straightening
**摘要:**染色体核型分析是检测人类疾病中染色体畸变的重要手段。然而,染色体在显微镜下很容易出现弯曲,这阻碍了细胞遗传学家对染色体类型的分析。为了解决这个问题,我们提出了一个染色体矫直的框架,包括一个初步的处理算法和一个被称为掩蔽条件变分自动编码器(MC-VAE)的生成模型。该处理方法利用补片重排解决了低曲率擦除困难的问题,为MC-VAE提供了合理的初步结果。MC-VAE进一步利用基于曲率的染色体斑来了解显带模式和条件之间的映射,从而使结果变得更直。在模型训练中,我们采用高掩蔽比的掩蔽策略来训练消除冗余的MC-VAE。这产生了一项艰巨的重建任务,使模型能够有效地保存重建结果中的染色体带型和结构细节。在三个具有两种染色风格的公共数据集上的广泛实验表明,我们的框架在保留条带模式和结构细节方面优于最先进的方法。与使用真实世界的弯曲染色体相比,使用由本文方法生成的高质量的拉直染色体可以大大提高各种深度学习模型的染色体分类性能。这种矫直方法有可能与其他核型分析系统结合,以辅助细胞遗传学家进行染色体分析。

-
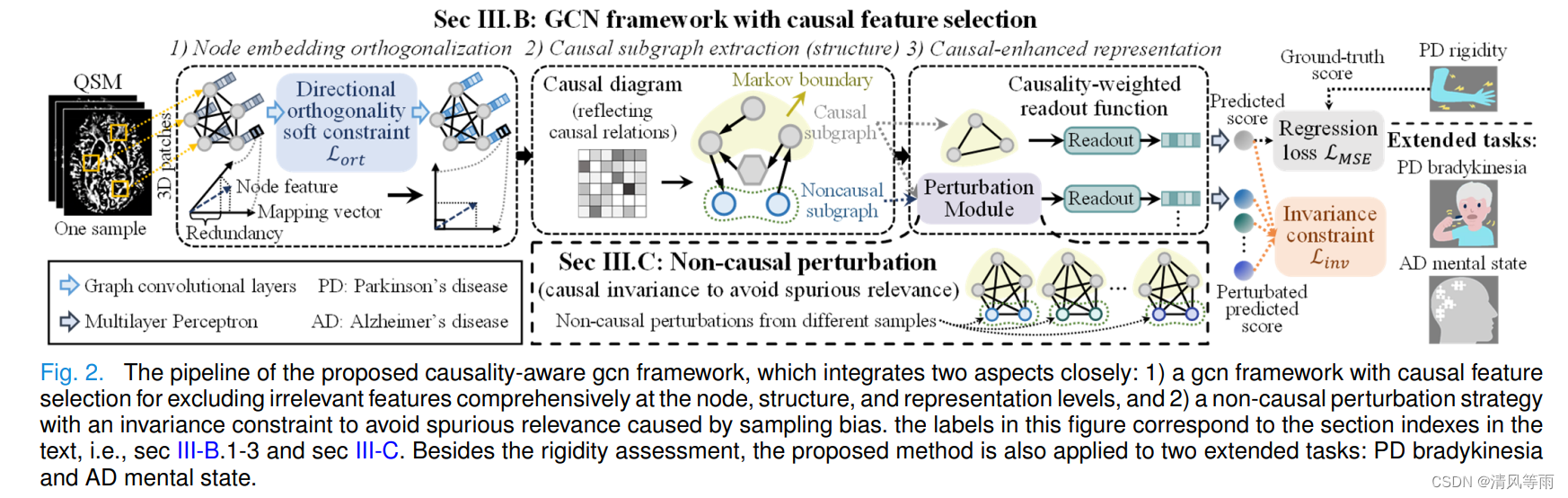
A Causality-Aware Graph Convolutional Network Framework for Rigidity Assessment in Parkinsonians
摘要: 僵硬是帕金森病(Parkinson 's disease, PD)常见的运动障碍之一,可导致生活质量下降。目前广泛使用的基于评分量表的僵硬度评估方法仍然依赖于有经验的神经内科医师,并受到评分主观性的限制。近年来,定量磁敏感图(quantitative susceptibility mapping, QSM)在辅助PD诊断中的成功应用,基本实现了对PD刚度的自动化评估。然而,一个主要的挑战是由于混杂因素(如噪声和分布转移)导致的性能不稳定,这些因素掩盖了真正的因果特征。因此,我们提出了一个因果感知的图卷积网络(GCN)框架,其中因果特征选择与因果不变性相结合,以确保达成基于因果的模型决策。首先,在节点、结构和表示三个图级上系统构建了一个集成因果特征选择的GCN模型。在这个模型中,我们学习了一个因果图来提取一个包含真正因果信息的子图。其次,提出了一种非因果扰动策略和不变性约束,以保证评估结果在不同分布下的稳定性,从而避免由于分布偏移引起的伪相关。大量实验表明了该方法的优越性,并通过PD中选定的脑区与僵直的直接相关性揭示了该方法的临床价值。此外,在帕金森病运动迟缓和阿尔茨海默病精神状态两项任务上验证了其可延展性。总之,我们提供了一个具有临床潜力的工具,用于自动化和稳定地评估PD强直。我们的源代码可以在https://github.com/SJTUBME-QianLab/Causality-Aware-Rigidity上找到。
-
Unsupervised Pathology Detection: A Deep Dive Into the State of the Art
摘要: 深度无监督方法在医学图像中的病理检测和分割等应用中受到越来越多的关注,因为它有望缓解对大标记数据集的需求,并且在检测任何类型的罕见病理方面比有监督的方法更具有普适性。随着无监督异常检测(UAD)文献的不断增长和新范式的出现,在一个共同的框架中持续评估和基准化新方法,以重新评估最先进的(SOTA)和识别有前景的研究方向是至关重要的。为此,我们在多个医疗数据集中评估了多种尖端UAD方法的选择,并将它们与用于脑MRI的UAD中已建立的SOTA进行了比较。我们的实验表明,与之前的工作相比,从工业和医学文献中新开发的特征建模方法实现了更高的性能,并在各种模式和数据集中设置了新的SOTA。此外,我们还表明,这些方法能够受益于最近开发的自我监督预训练算法,进一步提高其性能。最后,我们进行了一系列实验,以进一步了解所选模型和数据集的一些独特特征。我们的代码可以在https://github.com/iolag/UPD_study/下找到。 -
Evaluating the Predictive Value of Glioma Growth Models for Low-Grade Glioma After Tumor Resection
摘要: 肿瘤生长模型具有建模和预测个体胶质瘤时空演变的潜力。众所周知,胶质瘤细胞沿白质束的浸润速度更快,因此结构磁共振成像(MRI)和扩散张量成像(DTI)可用于告知模型。然而,在真实患者数据中应用和评估增长模型具有挑战性。在这项工作中,我们提出将肿瘤生长问题作为一个排序问题,而不是分割问题,并使用平均精度(AP)作为性能指标。这使得不需要体积截断值的空间模式的评估成为可能。在肿瘤切除术后,我们使用AP度量来评估结构MRI和DTI所建立的扩散-增殖模型。我们将该模型应用于14例手术切除后未接受任何治疗的低级别胶质瘤(LGG)患者的纵向数据集,以预测肿瘤切除术后复发的肿瘤形状。基于结构MRI和DTI的扩散模型对均质各向同性扩散的预测性能均有小幅但显著提高,其中DTI模型的预测性能最佳。我们的结论是,使用基于dti的各向异性扩散模型对复发肿瘤形状的预测有显著的改善,并且AP是一个合适的指标来评价这些模型。本出版物中使用的所有代码和数据都是公开的。 -
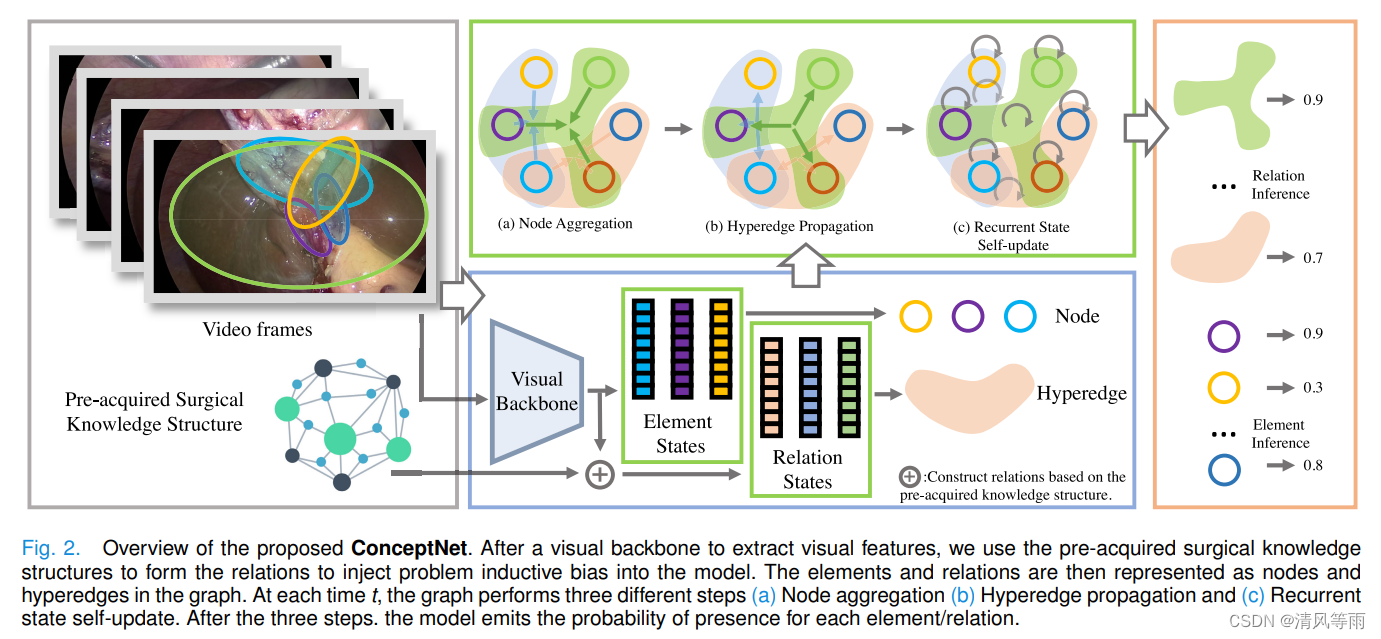
Concept Graph Neural Networks for Surgical Video Understanding
摘要: 分析手术视频中物体之间的关系和对抽象概念的理解在人工智能增强手术中具有重要意义。然而,构建整合我们对外科知识和理解的模型仍然是一项具有挑战性的努力。在本文中,我们提出了一种新的方法,利用时间概念图网络将概念知识整合到时间分析任务中。在提出的网络中,一个知识图被纳入到外科概念的时间视频分析中,学习概念的含义和关系,因为它们应用于数据。我们展示了在验证安全性的批判观点、估计Parkland分级量表以及识别器械-动作-组织三联体等任务中,手术视频数据的结果。结果表明,我们的方法提高了复杂基准的识别和检测,并使其他感兴趣的分析应用成为可能。
-
A Fully Differentiable Framework for 2D/3D Registration and the Projective Spatial Transformers
摘要: 基于图像的2D/3D配准是x线引导下外科手术的关键技术。传统的基于强度的2D/3D配准方法——由于手工制作的图像相似函数中存在局部最小值,因此捕获范围有限。在这项工作中,我们的目标是通过一个学习近似凸形状相似函数的完全可微的深度网络框架来扩展2D/3D配准捕捉范围。该网络使用了一种新颖的投影空间变压器(ProST)模块,该模块对三维姿态参数具有独特的可微性,并使用创新的双后向梯度驱动损失函数进行训练。我们比较了文献中最流行的基于学习的姿态回归方法,并使用公认的基于强度的CMAES配准作为基准。我们报告了配准姿态误差,目标配准误差(TRE)和成功率(SR),平均TRE的阈值为10mm。在骨盆解剖中,ProST序于CMAES的中位TRE为4.4mm, SR为65.6%;在真实数据中为2.2mm, SR为73.2%。未使用ProST配准的CMAES在模拟和真实数据中的SRs分别为28.5%和36.0%。我们的研究结果表明,所提出的ProST网络学习了一个实用的相似函数,极大地扩展了传统的基于强度的2D/3D配准的捕获范围。我们相信,ProST独特的可微分特性有可能有益于相关的3D医学成像研究应用。源代码可在https://github.com/gaocong13/Projective-Spatial-Transformers获取。

-
New Theory and Faster Computations for Subspace-Based Sensitivity Map Estimation in Multichannel MRI
摘要: 灵敏度图估计在多通道MRI应用中具有重要意义。像ESPIRiT这样的基于子空间的灵敏度图估计方法很受欢迎,并且性能很好,但可能会有很高的计算成本,而且它们的理论原理很难理解。在本研究的第一部分中,我们提出了一种基于线性可预测性/结构化低秩建模视角的基于子空间的灵敏度图估计的新理论推导。这就产生了一种与ESPIRiT相当的估计方法,但它具有不同的理论,对一些读者来说可能更直观。在本论文的第二部分中,我们提出并评估了一组计算加速方法(统称为PISCO),该方法可以显著提高计算时间(在我们展示的例子中高达约100倍)和基于子空间的灵敏度映射估计的内存。 -
FedDP: Dual Personalization in Federated Medical Image Segmentation
摘要: 个性化联邦学习(PFL)解决了通用联邦学习(GFL)面临的数据异构问题。PFL不是学习单一的全局模型,而是根据每个地点的独特特征分布采用一系列模型。然而,目前的PFL方法很少考虑可以通过长程依赖建模处理数据异质性的自我注意网络,也没有利用局部模型的预测不一致性作为站点唯一性的指标。在本文中,我们提出了一种新的具有双向个性化的馈电学习方案FedDP,该方案从特征和预测两个方面改进了模型的个性化,从而提高了图像分割的效果。我们通过设计一个本地查询(LQ)来利用远程依赖,它将查询嵌入层从每个本地模型中解耦出来,其参数被单独训练,以更好地适应站点的各自特征分布。然后,我们提出了不一致性指导校准(IGC),该方法利用研究中心之间的预测不一致性来适应模型学习集中。通过鼓励一个模型来惩罚具有较大不一致性的像素,我们可以更好地为每个局部站点定制预测级别的模式。在实验中,我们比较了FedDP和最先进的PFL方法在两个流行的医学图像分割任务与不同的模式,在这两个任务中,我们的结果始终优于其他人。我们的代码和模型可以在https://github.com/jcwang123/PFL-Seg-Trans上找到。

IEEE Transactions on Medical Imaging(TMI)论文推荐:2024年01月(1)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/280082.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
el-input设置max、min无效的解决方案
目录
一、方式1:type“number”
二、方式2:oninput(推荐)
三、计算属性 如下表所示,下面为官方关于max,min的介绍:
el-input:
max原生属性,设置最大值min原生属性&a…
如何在 Linux ubuntu 系统上搭建 Java web 程序的运行环境
如何在 Linux ubuntu 系统上搭建 Java web 程序的运行环境 基于包管理器进行安装
Linux 会把一些软件包放到对应的服务器上,通过包管理器这样的程序,来把这些软件包给下载安装 ubuntu系统上的包管理器是 apt centos系统上的包管理器 yum 注:…

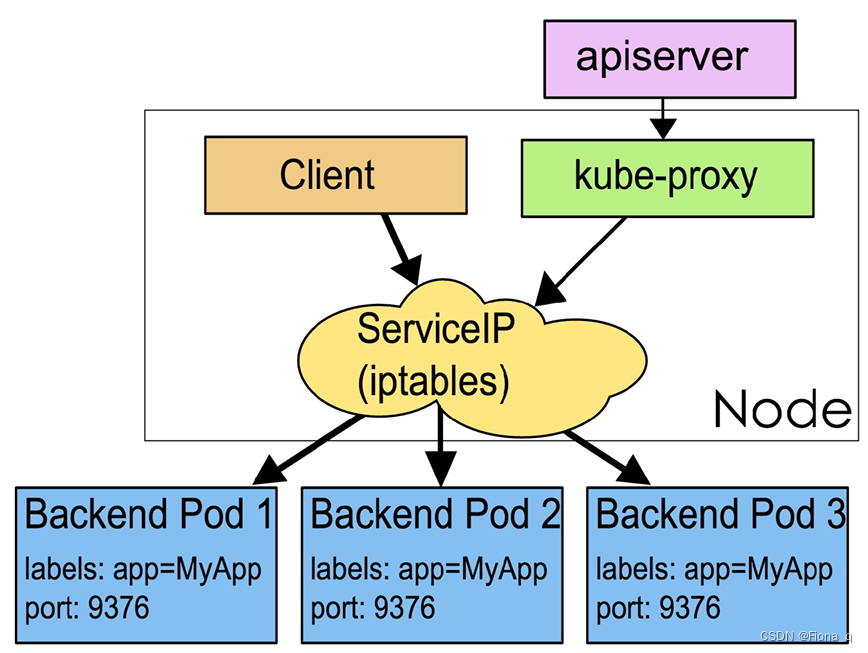
打卡学习kubernetes——了解k8s基本概念
目录 1 Container
2 Pod
3 Node
4 Namespace
5 Service
6 Label
7 Annotations
8 Volume 1 Container
Container(容器)是一种便携式、轻量级的操作系统级虚拟化技术。它使用namespace隔离不同的软件运行环境,并通过镜像自包含软件的运行环境,从而…
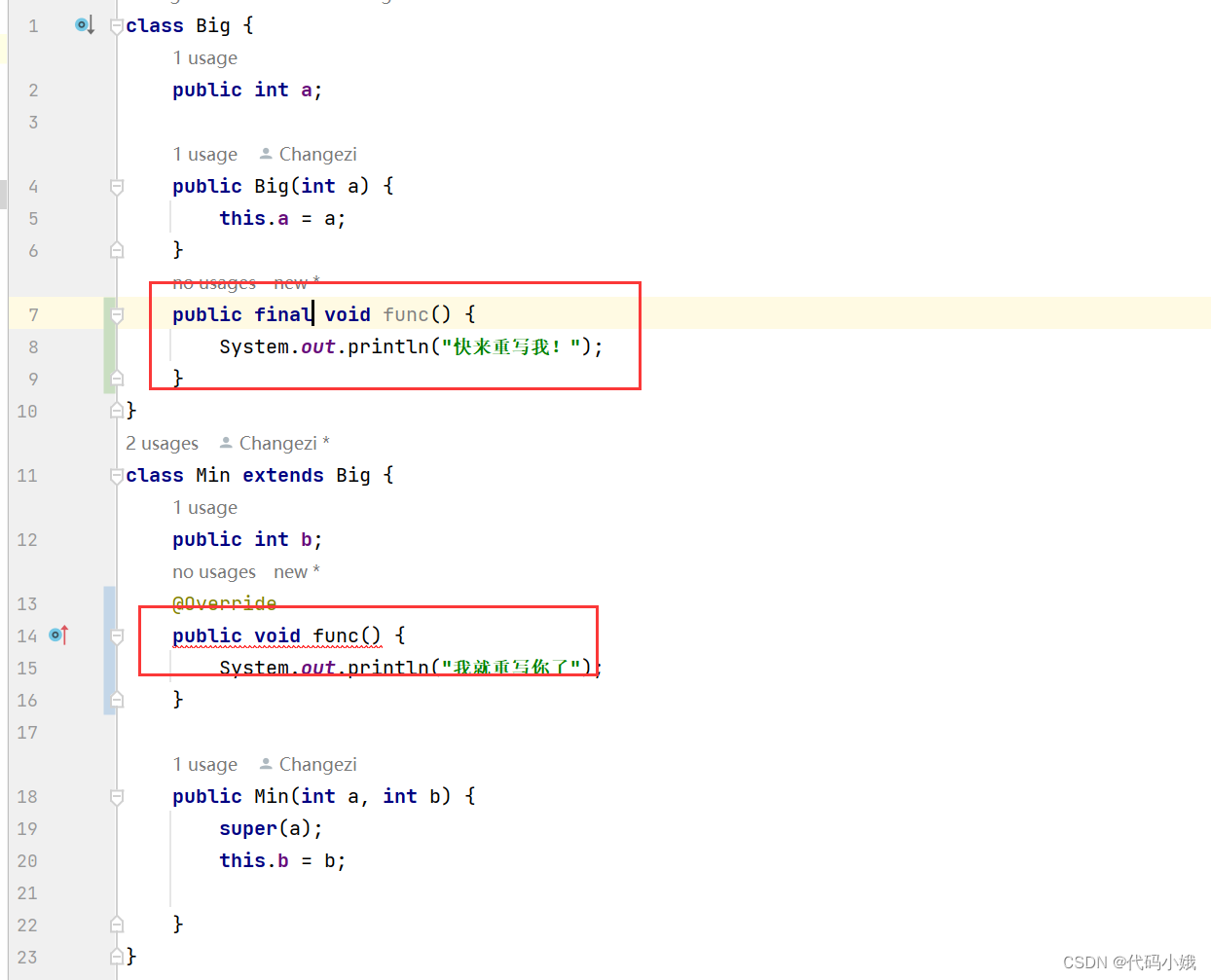
关于继承是怎么样的?那当然是很好理解之
本文描述了关于继承的大部分知识,但是并不全,每篇博客之间的知识都有互串,所以需要把几篇文章合起来看,学会融会贯通! 温馨提示:使用PC端观看,效果更佳!
目录
1.继承是什么
2.什…

JavaScript进阶:js的一些学习笔记-4
文章目录 1. 拷贝1. 浅拷贝2. 深拷贝 2. 异常处理 1. 拷贝
这里指的拷贝是指拷贝引用类型的数据(对象)
1. 浅拷贝
拷贝对象:Object.assign() 或者 {…obj} 展开运算符
const obj {name:liuze,age:23
}
const o {...obj};
o.age 22;
console.log(o);
console.…
Linux | Ubuntu安装pylsl
PYNQ开发中使用pylsl过程记录 操作系统为 Linux pynq 5.15.19-xilinx-v2022.1 #1 SMP PREEMPT Mon Apr 11 17:52:14 UTC 2022 armv7l armv7l armv7l GNU/Linux
使用 pip install pylsl 安装后在导入包的过程中会遇到如下错误:
RuntimeError: LSL binary library f…

深入浅出前端本地储存(1)
引言
2021 年,如果你的前端应用,需要在浏览器上保存数据,有三个主流方案:
CookieWeb Storage (LocalStorage)IndexedDB
这些方案就是如今应用最广、浏览器兼容性最高的三种前端储存方案
今天这篇文章就聊一聊这三种方案的历史…
前端基础篇-深入了解 Ajax 、Axios
🔥博客主页: 【小扳_-CSDN博客】 ❤感谢大家点赞👍收藏⭐评论✍ 文章目录 1.0 Ajax 概述 2.0 Axios 概述 3.0 综合案例 1.0 Ajax 概述 通过 Ajax 可以给服务器发送请求,并获取服务器响应的数据。异步交互是指,可以在不…
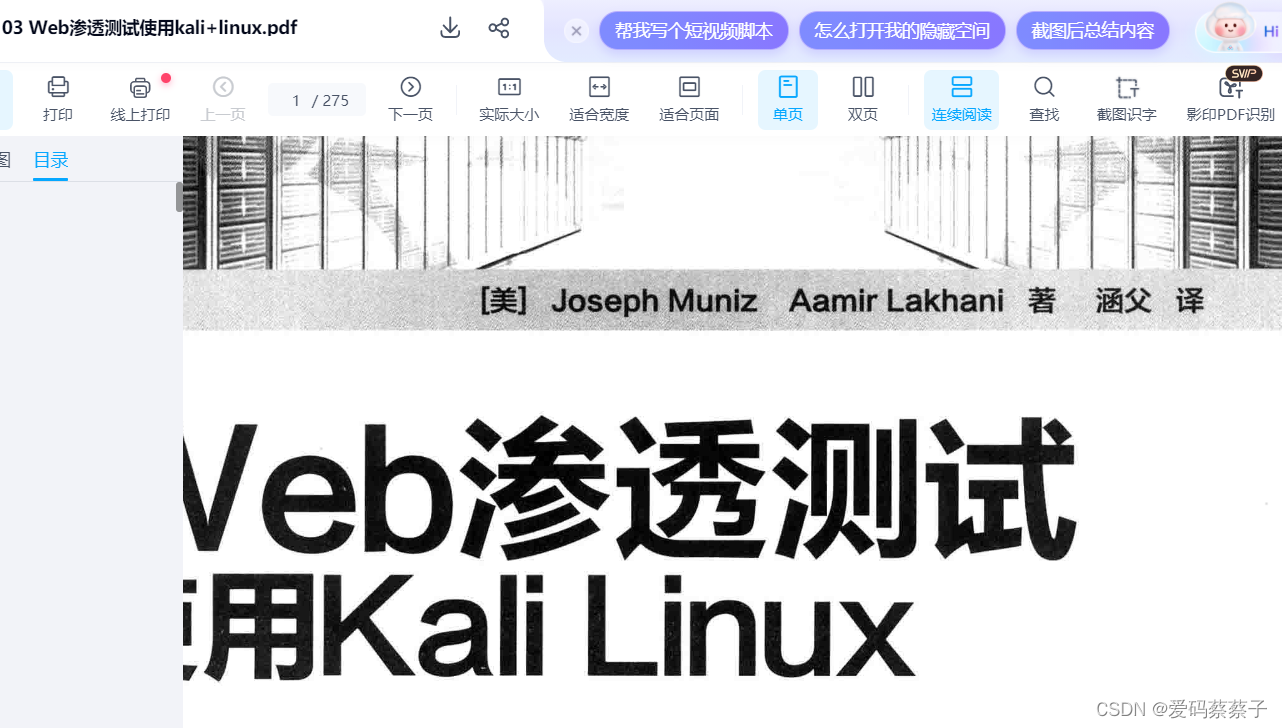
【安全类书籍-2】Web渗透测试:使用Kali Linux
目录 内容简介 作用
下载地址 内容简介
书籍的主要内容是指导读者如何运用Kali Linux这一专业的渗透测试平台对Web应用程序进行全面的安全测试。作者们从攻击者的视角出发,详细阐述了渗透测试的基本概念和技术,以及如何配置Kali Linux以适应渗透测试需求。书中不仅教授读者…
![[zdyz]FreeRTOS笔记](https://img-blog.csdnimg.cn/direct/7b64f040d3324d5a86db8fb697e04f9b.png)
[zdyz]FreeRTOS笔记
FreeRTOS基础知识 1,任务调度器简介
调度器就是使用相关的调度算法来决定当前需要执行的哪个任务
抢占式调度 时间片调度 协程式调度
略
2,任务状态
运行态
正在执行的任务,该任务就处于运行态,注意在STM32中,同…
【JAVA】Servlet开发
目录
HttpServlet
HttpServletRequest HttpServletResponse
错误页面
设置网页自动刷新时间
构造重定向相应
js发起http请求
服务器端对js发起的http请求进行处理
前端获取后端数据,添加到当前页面的末尾,代码示例: 前后端交互&…
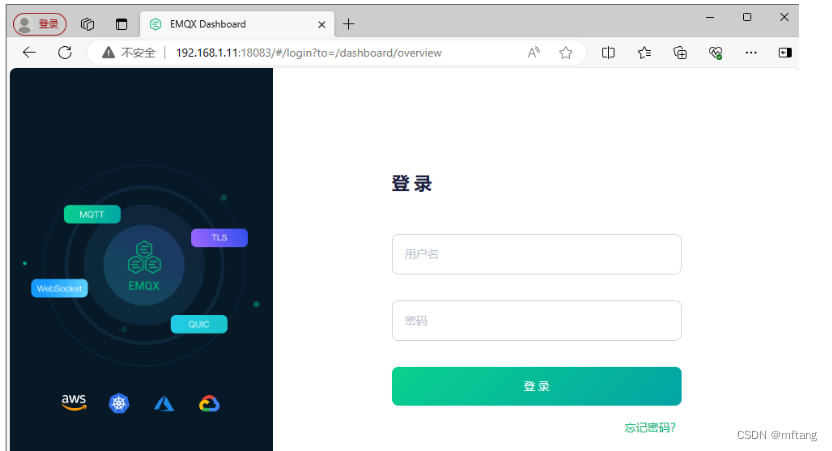
Linux环境(Ubuntu)上搭建MQTT服务器(EMQX )
目录 概述
1 认识EMQX
1.1 EMQX 简介
1.2 EMQX 版本类型
2 Ubuntu搭建EMQX 平台
2.1 下载和安装
2.1.1 下载
2.1.2 安装
2.2 查看运行端口
3 运行Dashboard 管理控制台
3.1 查看Ubuntu上的防火墙
3.2 运行Dashboard 管理控制台 概述
本文主要介绍EMQX 的一些内容&a…

深入解析C++树形关联式容器:map、set及其衍生容器的使用与原理
文章目录 一、引言二、关联式容器的中的 paira.pair 的创建及使用b.pair 间的比较 三、 map 与 set 详解1. map 的基本操作2. set 的基本操作3.关联式容器的迭代器 四、 multimap 与 multiset 的特性五、关联式容器的使用技巧与注意事项1. 键值类型的选择与设计2. 自定义比较函…
SVN修改已提交版本的注释
目录
一、需求分析
二、问题分析
三、解决办法 一、需求分析
开发过程中,在SVN提交文件后,发现注释写的不完整或不够明确,想再修改之前的注释文字。 使用环境: SVN服务器操作系统:Ubuntu 20.04.6 LTS SVN版本&…

vr虚拟现实游戏世界介绍|数字文化展览|VR元宇宙文旅
虚拟现实(VR)游戏世界是一种通过虚拟现实技术创建的沉浸式游戏体验,玩家可以穿上VR头显,仿佛置身于游戏中的虚拟世界中。这种技术让玩家能够全方位、身临其境地体验游戏,与游戏中的环境、角色和物体互动。 在虚拟现实游…
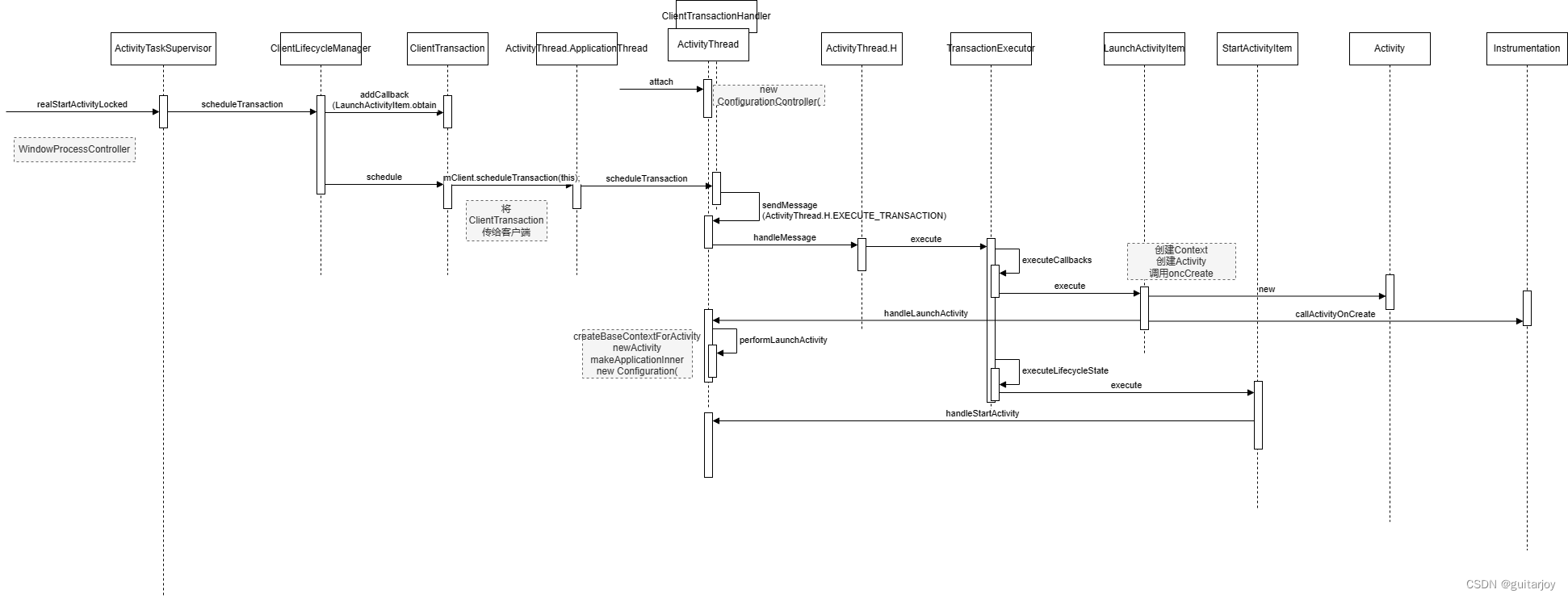
Android14 - AMS之Activity启动过程(3)
Android14 - AMS之Activity启动过程(1)-CSDN博客 Android14 - AMS之Activity启动过程(2)-CSDN博客 上篇中我们梳理完ActivityStarter的startActivityInner,本篇从这里开始: platform/frameworks/base/servi…
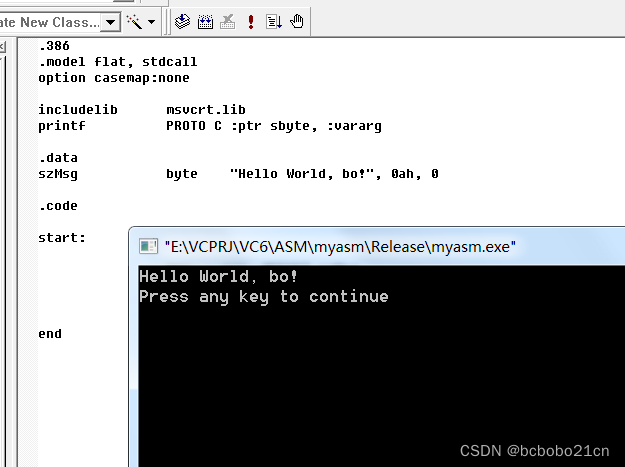
VC6环境开发汇编程序和汇编语言调用C库
新建一个Win32控制台类型的空项目;
新建一个源文件,输入文件名时输入后缀.asm;.asm后缀的文件如果不会出现在Source Files文件夹下,可将其拖放到Source Files文件夹下; 输入如下代码;调用C的printf函数输出…

UE5.1 iClone8 正确导入角色骨骼与动作
使用iClone8插件Auto Setup 附录下载链接
里面有两个文件夹,使用Auto Setup
C:\Program Files\Reallusion\Shared Plugins 在UE内新建Plugins,把插件复制进去 在工具栏出现这三个人物的图标就安装成功了 iClone选择角色,导入动作 选择导出FBX UE内直接导入 会出现是否启动插件…
推荐文章
- (41)MATLAB中fftshift函数与ifftshift函数的用法
- (done) Beam search
- (十八)mmdetection源码解读:forward_train
- (四)activit5.23.0修复跟踪高亮显示BUG
- (四)C++自制植物大战僵尸游戏启动流程
- (微信小程序)基于Spring Boot的校园失物招领平台的设计与实现(vue3+uniapp+mysql)
- (一)Jetpack Compose 从入门到会写
- .mkp勒索病毒数据怎么处理|数据解密恢复
- .NET Core异步编程与多线程解析:提升性能与响应能力的关键技术
- .NET Nuget包推荐安装
- .Net6 Web Core API 配置 Autofac 封装 --- 依赖注入
- : 依赖: qtbase5-dev (= 5.12.8+dfsg-0ubuntu2.1) 但是它将不会被安装 或