第一部分:PyTorch 核心
欢迎来到本书的第一部分。在这里,我们将与 PyTorch 迈出第一步,获得理解其结构和解决 PyTorch 项目机制所需的基本技能。
在第一章中,我们将首次接触 PyTorch,了解它是什么,解决了什么问题,以及它与其他深度学习框架的关系。第二章将带领我们进行一次旅行,让我们有机会玩玩已经在有趣任务上预训练的模型。第三章会更加严肃,教授 PyTorch 程序中使用的基本数据结构:张量。第四章将带领我们再次进行一次旅行,这次是跨越不同领域的数据如何表示为 PyTorch 张量。第五章揭示了程序如何从示例中学习以及 PyTorch 如何支持这一过程。第六章介绍了神经网络的基础知识以及如何使用 PyTorch 构建神经网络。第七章通过一个神经网络架构解决了一个简单的图像分类问题。最后,第八章展示了如何使用卷积神经网络以更智能的方式解决同样的问题。
到第 1 部分结束时,我们将具备在第 2 部分中使用 PyTorch 解决真实世界问题所需的基本技能。
一、介绍深度学习和 PyTorch 库
本章涵盖
-
深度学习如何改变我们对机器学习的方法
-
了解为什么 PyTorch 非常适合深度学习
-
检查典型的深度学习项目
-
您需要的硬件来跟随示例
术语人工智能的定义模糊,涵盖了一系列经历了大量研究、审查、混乱、夸张和科幻恐慌的学科。现实当然要乐观得多。断言今天的机器在任何人类意义上都在“思考”是不诚实的。相反,我们发现了一类能够非常有效地逼近复杂非线性过程的算法,我们可以利用这些算法来自动化以前仅限于人类的任务。
例如,在inferkit.com/,一个名为 GPT-2 的语言模型可以逐字生成连贯的段落文本。当我们将这段文字输入时,它生成了以下内容:
接下来,我们将输入一组来自电子邮件地址语料库的短语列表,并查看程序是否能将列表解析为句子。再次强调,这比本文开头的搜索要复杂得多,也更加复杂,但希望能帮助您了解在各种编程语言中构建句子结构的基础知识。
对于一台机器来说,这是非常连贯的,即使在这些胡言乱语背后没有一个明确定义的论点。
更令人印象深刻的是,执行这些以前仅限于人类的任务的能力是通过示例获得的,而不是由人类编码为一组手工制作的规则。在某种程度上,我们正在学习智能是一个我们经常与自我意识混淆的概念,而自我意识绝对不是成功执行这类任务所必需的。最终,计算机智能的问题甚至可能并不重要。Edsger W. Dijkstra 发现,机器是否能够思考的问题“与潜艇是否能游泳的问题一样相关”。¹
我们谈论的那类算法属于深度学习的人工智能子类,它通过提供示例来训练名为深度神经网络的数学实体。深度学习使用大量数据来逼近输入和输出相距甚远的复杂函数,比如输入图像和输出的一行描述输入的文本;或者以书面脚本为输入,以自然语音朗读脚本为输出;甚至更简单的是将金毛寻回犬的图像与告诉我们“是的,金毛寻回犬在场”的标志相关联。这种能力使我们能够创建具有直到最近为止仅属于人类领域的功能的程序。
1.1 深度学习革命
要欣赏这种深度学习方法带来的范式转变,让我们退后一步,换个角度看一下。直到最近的十年,广义上属于机器学习范畴的系统在很大程度上依赖特征工程。特征是对输入数据的转换,有助于下游算法(如分类器)在新数据上产生正确的结果。特征工程包括想出正确的转换,以便下游算法能够解决任务。例如,为了在手写数字图像中区分 1 和 0,我们会想出一组滤波器来估计图像上边缘的方向,然后训练一个分类器来预测给定边缘方向分布的正确数字。另一个有用的特征可能是封闭孔的数量,如 0、8 和尤其是环绕的 2。
另一方面,深度学习处理的是自动从原始数据中找到这样的表示,以便成功执行任务。在二进制示例中,通过在训练过程中迭代地查看示例和目标标签对来逐步改进滤波器。这并不是说特征工程在深度学习中没有地位;我们经常需要在学习系统中注入某种形式的先验知识。然而,神经网络摄取数据并根据示例提取有用表示的能力是使深度学习如此强大的原因。深度学习从业者的重点不是手工制作这些表示,而是操作数学实体,使其自主地从训练数据中发现表示。通常,这些自动生成的特征比手工制作的特征更好!与许多颠覆性技术一样,这一事实导致了观念的变化。
在图 1.1 的左侧,我们看到一个从业者忙于定义工程特征并将其馈送给学习算法;在任务上的结果将取决于从业者工程的特征的好坏。在右侧,通过深度学习,原始数据被馈送给一个自动提取分层特征的算法,该算法受其在任务上性能优化的指导;结果将取决于从业者驱动算法朝着目标的能力。
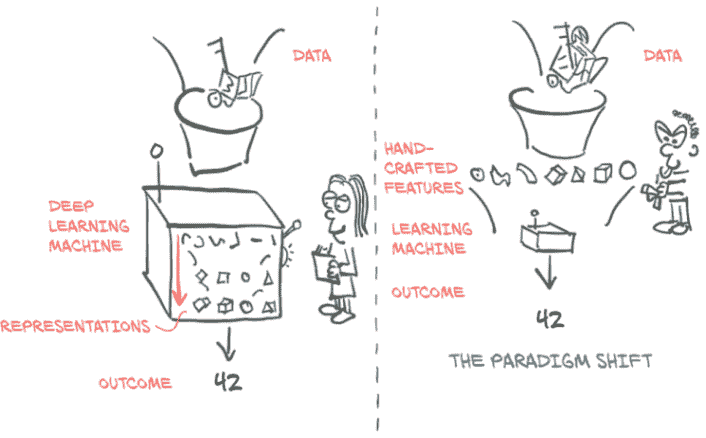
图 1.1 深度学习交换了手工制作特征的需求,增加了数据和计算需求。
从图 1.1 的右侧开始,我们已经可以看到我们需要执行成功的深度学习所需的一瞥:
-
我们需要一种方法来摄取手头的任何数据。
-
我们以某种方式需要定义深度学习机器。
-
我们必须有一种自动化的方式,训练,来获得有用的表示并使机器产生期望的输出。
这使我们不得不更仔细地看看我们一直在谈论的这个训练问题。在训练过程中,我们使用一个标准,这是模型输出和参考数据的实值函数,为我们的模型期望输出与实际输出之间的差异提供一个数值分数(按照惯例,较低的分数通常更好)。训练包括通过逐步修改我们的深度学习机器来将标准驱向更低的分数,直到它在训练过程中未见的数据上也能获得低分数。
1.2 PyTorch 用于深度学习
PyTorch 是一个用于 Python 程序的库,有助于构建深度学习项目。它强调灵活性,并允许用惯用 Python 表达深度学习模型。这种易接近性和易用性在研究界早期的采用者中得到了认可,在其首次发布后的几年里,它已经发展成为广泛应用于各种应用领域的最重要的深度学习工具之一。
就像 Python 用于编程一样,PyTorch 为深度学习提供了一个出色的入门。同时,PyTorch 已被证明完全适用于在实际工作中的专业环境中使用。我们相信 PyTorch 清晰的语法、简化的 API 和易于调试使其成为深入深度学习的绝佳选择。我们强烈推荐学习 PyTorch 作为你的第一个深度学习库。至于它是否应该是你学习的最后一个深度学习库,这是一个由你决定的问题。
在图 1.1 中的深度学习机器的核心是一个将输入映射到输出的相当复杂的数学函数。为了方便表达这个函数,PyTorch 提供了一个核心数据结构,张量,它是一个与 NumPy 数组有许多相似之处的多维数组。在这个基础上,PyTorch 提供了在专用硬件上执行加速数学运算的功能,这使得设计神经网络架构并在单台机器或并行计算资源上训练它们变得方便。
本书旨在成为软件工程师、数据科学家和精通 Python 的有动力的学生开始使用 PyTorch 构建深度学习项目的起点。我们希望这本书尽可能易于访问和有用,并且我们期望您能够将本书中的概念应用到其他领域。为此,我们采用了实践方法,并鼓励您随时准备好计算机,这样您就可以尝试示例并进一步深入研究。到本书结束时,我们期望您能够利用数据源构建出一个深度学习项目,并得到优秀的官方文档支持。
尽管我们强调使用 PyTorch 构建深度学习系统的实际方面,但我们认为提供一个易于理解的基础深度学习工具的介绍不仅仅是为了促进新技术技能的习得。这是向来自各种学科领域的新一代科学家、工程师和从业者提供工作知识的一步,这些知识将成为未来几十年许多软件项目的支柱。
为了充分利用本书,您需要两样东西:
一些在 Python 中编程经验。我们不会在这一点上有任何保留;您需要了解 Python 数据类型、类、浮点数等。
有愿意深入并动手实践的态度。我们将从基础开始建立工作知识,如果您跟着我们一起学习,学习将会更容易。
使用 PyTorch 进行深度学习 分为三个不同的部分。第一部分涵盖了基础知识,详细介绍了 PyTorch 提供的设施,以便用代码将图 1.1 中深度学习的草图付诸实践。第二部分将带您完成一个涉及医学成像的端到端项目:在 CT 扫描中查找和分类肿瘤,建立在第一部分介绍的基本概念基础上,并添加更多高级主题。简短的第三部分以 PyTorch 为主题,介绍了将深度学习模型部署到生产环境中的内容。
深度学习是一个庞大的领域。在本书中,我们将涵盖其中的一小部分:具体来说,使用 PyTorch 进行较小范围的分类和分割项目,其中大部分激励示例使用 2D 和 3D 数据集的图像处理。本书侧重于实用的 PyTorch,旨在涵盖足够的内容,使您能够解决真实世界的机器学习问题,例如在视觉领域使用深度学习,或者随着研究文献中出现新模型而探索新模型。大多数,如果不是全部,与深度学习研究相关的最新出版物都可以在 arXiV 公共预印本存储库中找到,托管在arxiv.org。
1.3 为什么选择 PyTorch?
正如我们所说,深度学习使我们能够通过向我们的模型展示说明性示例来执行非常广泛的复杂任务,如机器翻译、玩策略游戏或在混乱场景中识别物体。为了在实践中做到这一点,我们需要灵活的工具,以便能够适应如此广泛的问题,并且高效,以便允许在合理时间内对大量数据进行训练;我们需要训练好的模型在输入变化时能够正确执行。让我们看看我们决定使用 PyTorch 的一些原因。
PyTorch 之所以易于推荐,是因为它的简单性。许多研究人员和实践者发现它易于学习、使用、扩展和调试。它符合 Python 的风格,虽然像任何复杂的领域一样,它有注意事项和最佳实践,但使用该库通常对之前使用过 Python 的开发人员来说感觉很熟悉。
更具体地说,在 PyTorch 中编程深度学习机器非常自然。PyTorch 给我们提供了一种数据类型,即Tensor,用于保存数字、向量、矩阵或一般数组。此外,它提供了用于操作它们的函数。我们可以像在 Python 中一样逐步编程,并且如果需要,可以交互式地进行,就像我们从 Python 中习惯的那样。如果你了解 NumPy,这将非常熟悉。
但是 PyTorch 提供了两个使其特别适用于深度学习的特点:首先,它利用图形处理单元(GPU)进行加速计算,通常比在 CPU 上进行相同计算速度提高了 50 倍。其次,PyTorch 提供了支持数值优化的功能,用于训练深度学习所使用的通用数学表达式。请注意,这两个特点不仅适用于深度学习,而且适用于科学计算。事实上,我们可以将 PyTorch 安全地描述为一个在 Python 中为科学计算提供优化支持的高性能库。
PyTorch 的设计驱动因素是表达能力,允许开发人员实现复杂模型而不受库施加的复杂性(它不是一个框架!)。可以说 PyTorch 在深度学习领域中最顺畅地将思想转化为 Python 代码之一。因此,PyTorch 在研究中得到了广泛的采用,这可以从国际会议上的高引用计数看出。
PyTorch 在从研究和开发转向生产方面也有引人注目的故事。虽然最初它专注于研究工作流程,但 PyTorch 已经配备了一个高性能的 C++ 运行时,可以用于在不依赖 Python 的情况下部署推断模型,并且可以用于在 C++ 中设计和训练模型。它还增加了对其他语言的绑定和用于部署到移动设备的接口。这些功能使我们能够利用 PyTorch 的灵活性,同时将我们的应用程序带到完全无法获得或会带来昂贵开销的完整 Python 运行时的地方。
当然,声称易用性和高性能是微不足道的。我们希望当你深入阅读本书时,你会同意我们在这里的声明是有充分根据的。
1.3.1 深度学习竞争格局
尽管所有类比都有缺陷,但似乎 PyTorch 0.1 在 2017 年 1 月的发布标志着从深度学习库、包装器和数据交换格式的富集到整合和统一的时代的转变。
注意 深度学习领域最近发展迅速,到您阅读这篇文章时,它可能已经过时。如果您对这里提到的一些库不熟悉,那没关系。
在 PyTorch 首个 beta 版本发布时:
-
Theano 和 TensorFlow 是首屈一指的低级库,使用用户定义计算图然后执行它。
-
Lasagne 和 Keras 是围绕 Theano 的高级封装,Keras 也封装了 TensorFlow 和 CNTK。
-
Caffe、Chainer、DyNet、Torch(PyTorch 的 Lua 前身)、MXNet、CNTK、DL4J 等填补了生态系统中的各种领域。
在接下来的大约两年时间里,情况发生了巨大变化。社区在 PyTorch 或 TensorFlow 之间大多数集中,其他库的采用量减少,除了填补特定领域的库。简而言之:
-
Theano,第一个深度学习框架之一,已经停止了活跃开发。
-
TensorFlow:
-
完全消化了 Keras,将其提升为一流的 API
-
提供了一个立即执行的“急切模式”,与 PyTorch 处理计算方式有些相似
-
发布了默认启用急切模式的 TF 2.0
-
-
JAX 是 Google 开发的一个独立于 TensorFlow 的库,已经开始获得与 GPU、自动微分和 JIT 功能相当的 NumPy 等价物。
-
PyTorch:
-
-
消化了 Caffe2 作为其后端
-
替换了大部分从基于 Lua 的 Torch 项目中重复使用的低级代码
-
添加了对 ONNX 的支持,这是一个供应商中立的模型描述和交换格式
-
添加了一个延迟执行的“图模式”运行时称为TorchScript
-
发布了 1.0 版本
-
分别由各自公司的赞助商替换了 CNTK 和 Chainer 作为首选框架
-
TensorFlow 拥有强大的生产流水线、广泛的行业社区和巨大的知名度。PyTorch 在研究和教学社区中取得了巨大进展,得益于其易用性,并自那时起一直在增长,因为研究人员和毕业生培训学生并转向工业。它在生产解决方案方面也积累了动力。有趣的是,随着 TorchScript 和急切模式的出现,PyTorch 和 TensorFlow 的功能集开始收敛,尽管这些功能的展示和整体体验在两者之间仍然有很大的不同。
1.4 PyTorch 如何支持深度学习项目的概述
我们已经暗示了 PyTorch 中的一些构建模块。现在让我们花点时间来形式化一个构成 PyTorch 的主要组件的高级地图。我们最好通过查看深度学习项目从 PyTorch 中需要什么来做到这一点。
首先,PyTorch 中有“Py”代表 Python,但其中有很多非 Python 代码。实际上,出于性能原因,大部分 PyTorch 是用 C++和 CUDA(www.geforce.com/hardware/technology/cuda)编写的,CUDA 是 NVIDIA 的一种类似 C++的语言,可以编译成在 GPU 上进行大规模并行运行。有方法可以直接从 C++运行 PyTorch,我们将在第十五章中探讨这些方法。这种能力的一个动机是提供一个可靠的部署模型的策略。然而,大部分时间我们会从 Python 中与 PyTorch 交互,构建模型,训练它们,并使用训练好的模型解决实际问题。
实际上,Python API 是 PyTorch 在可用性和与更广泛的 Python 生态系统集成方面的亮点。让我们来看看 PyTorch 是什么样的思维模型。
正如我们已经提到的,PyTorch 的核心是一个提供多维数组或在 PyTorch 术语中称为张量的库(我们将在第三章详细介绍),以及由torch模块提供的广泛的操作库。张量和对它们的操作都可以在 CPU 或 GPU 上使用。在 PyTorch 中将计算从 CPU 移动到 GPU 不需要更多的函数调用。PyTorch 提供的第二个核心功能是张量能够跟踪对它们执行的操作,并分析地计算与计算输出相对于任何输入的导数。这用于数值优化,并且通过 PyTorch 的autograd引擎在底层提供。
通过具有张量和 autograd 启用的张量标准库,PyTorch 可以用于物理、渲染、优化、模拟、建模等领域–我们很可能会在整个科学应用的范围内看到 PyTorch 以创造性的方式使用。但 PyTorch 首先是一个深度学习库,因此它提供了构建神经网络和训练它们所需的所有构建模块。图 1.2 显示了一个标准设置,加载数据,训练模型,然后将该模型部署到生产环境。
用于构建神经网络的 PyTorch 核心模块位于torch.nn中,它提供常见的神经网络层和其他架构组件。全连接层、卷积层、激活函数和损失函数都可以在这里找到(随着我们在本书的后续部分的深入,我们将更详细地介绍这些内容)。这些组件可以用于构建和初始化我们在图 1.2 中看到的未经训练的模型。为了训练我们的模型,我们需要一些额外的东西:训练数据的来源,一个优化器来使模型适应训练数据,以及一种将模型和数据传输到实际执行训练模型所需计算的硬件的方法。

图 1.2 PyTorch 项目的基本高级结构,包括数据加载、训练和部署到生产环境
在图 1.2 的左侧,我们看到在训练数据到达我们的模型之前需要进行相当多的数据处理。首先,我们需要从某种存储中获取数据,最常见的是数据源。然后,我们需要将我们的数据中的每个样本转换为 PyTorch 实际可以处理的东西:张量。我们自定义数据(无论其格式是什么)与标准化的 PyTorch 张量之间的桥梁是 PyTorch 在torch.utils.data中提供的Dataset类。由于这个过程在不同问题之间差异很大,我们将不得不自己实现这个数据获取过程。我们将详细讨论如何将我们想要处理的各种类型的数据表示为张量在第四章。
由于数据存储通常较慢,特别是由于访问延迟,我们希望并行化数据加载。但由于 Python 受欢迎的许多功能并不包括简单、高效的并行处理,我们需要多个进程来加载数据,以便将它们组装成批次:包含多个样本的张量。这相当复杂;但由于它也相对通用,PyTorch 在DataLoader类中轻松提供了所有这些魔法。它的实例可以生成子进程,后台加载数据集中的数据,以便在训练循环可以使用时,数据已准备就绪。我们将在第七章中遇到并使用Dataset和DataLoader。
有了获取样本批次的机制,我们可以转向图 1.2 中心的训练循环本身。通常,训练循环被实现为标准的 Python for 循环。在最简单的情况下,模型在本地 CPU 或单个 GPU 上运行所需的计算,一旦训练循环有了数据,计算就可以立即开始。很可能这也是您的基本设置,这也是我们在本书中假设的设置。
在训练循环的每一步中,我们使用从数据加载器中获取的样本评估我们的模型。然后,我们使用一些标准或损失函数将我们模型的输出与期望输出(目标)进行比较。正如它提供了构建模型的组件一样,PyTorch 还提供了各种损失函数供我们使用。它们也是在torch.nn中提供的。在我们用损失函数比较了实际输出和理想输出之后,我们需要稍微推动模型,使其输出更好地类似于目标。正如前面提到的,这就是 PyTorch 自动求导引擎的作用所在;但我们还需要一个优化器来进行更新,这就是 PyTorch 在torch.optim中为我们提供的。我们将在第五章开始研究带有损失函数和优化器的训练循环,然后在第 6 至 8 章中磨练我们的技能,然后开始我们的大型项目。
越来越普遍的是使用更复杂的硬件,如多个 GPU 或多台机器共同为训练大型模型提供资源,如图 1.2 底部中心所示。在这些情况下,可以使用torch.nn.parallel.Distributed-DataParallel和torch.distributed子模块来利用额外的硬件。
训练循环可能是深度学习项目中最不令人兴奋但最耗时的部分。在此之后,我们将获得一个在我们的任务上经过优化的模型参数:图中训练循环右侧所示的训练模型。拥有一个能解决问题的模型很棒,但为了让它有用,我们必须将其放在需要工作的地方。这个过程的部署部分在图 1.2 右侧描述,可能涉及将模型放在服务器上或将其导出以加载到云引擎中,如图所示。或者我们可以将其集成到更大的应用程序中,或在手机上运行。
部署练习的一个特定步骤可以是导出模型。如前所述,PyTorch 默认为即时执行模式(急切模式)。每当涉及 PyTorch 的指令被 Python 解释器执行时,相应的操作立即由底层 C++或 CUDA 实现执行。随着更多指令操作张量,更多操作由后端实现执行。
PyTorch 还提供了一种通过TorchScript提前编译模型的方法。使用 TorchScript,PyTorch 可以将模型序列化为一组指令,可以独立于 Python 调用:比如,从 C++程序或移动设备上。我们可以将其视为具有有限指令集的虚拟机,特定于张量操作。这使我们能够导出我们的模型,无论是作为可与 PyTorch 运行时一起使用的 TorchScript,还是作为一种称为ONNX的标准化格式。这些功能是 PyTorch 生产部署能力的基础。我们将在第十五章中介绍这一点。
1.5 硬件和软件要求
本书将需要编写和运行涉及大量数值计算的任务,例如大量矩阵相乘。事实证明,在新数据上运行预训练网络在任何最近的笔记本电脑或个人电脑上都是可以的。甚至拿一个预训练网络并重新训练其中的一小部分以使其在新数据集上专门化并不一定需要专门的硬件。您可以使用标准个人电脑或笔记本电脑跟随本书第 1 部分的所有操作。
然而,我们预计完成第 2 部分中更高级示例的完整训练运行将需要一个支持 CUDA 的 GPU。第 2 部分中使用的默认参数假定具有 8 GB RAM 的 GPU(我们建议使用 NVIDIA GTX 1070 或更高版本),但如果您的硬件可用 RAM 较少,则可以进行调整。明确一点:如果您愿意等待,这样的硬件并非强制要求,但在 GPU 上运行可以将训练时间缩短至少一个数量级(通常快 40-50 倍)。单独看,计算参数更新所需的操作速度很快(从几分之一秒到几秒)在现代硬件上,如典型笔记本电脑 CPU。问题在于训练涉及一遍又一遍地运行这些操作,逐渐更新网络参数以最小化训练误差。
中等规模的网络在配备良好 GPU 的工作站上从头开始训练大型真实世界数据集可能需要几小时到几天的时间。通过在同一台机器上使用多个 GPU,甚至在配备多个 GPU 的机器集群上进一步减少时间。由于云计算提供商的提供,这些设置比听起来的要容易访问。DAWNBench(dawn.cs.stanford.edu/benchmark/index.html)是斯坦福大学的一个有趣的倡议,旨在提供关于在公开可用数据集上进行常见深度学习任务的训练时间和云计算成本的基准。
因此,如果在您到达第 2 部分时有 GPU 可用,那太好了。否则,我们建议查看各种云平台的提供,其中许多提供预装 PyTorch 的支持 GPU 的 Jupyter 笔记本,通常还有免费配额。Google Colaboratory(colab.research.google.com)是一个很好的起点。
最后考虑的是操作系统(OS)。PyTorch 从首次发布开始就支持 Linux 和 macOS,并于 2018 年获得了 Windows 支持。由于当前的苹果笔记本不包含支持 CUDA 的 GPU,PyTorch 的预编译 macOS 包仅支持 CPU。在本书中,我们会尽量避免假设您正在运行特定的操作系统,尽管第 2 部分中的一些脚本显示为在 Linux 下的 Bash 提示符下运行。这些脚本的命令行应该很容易转换为兼容 Windows 的形式。为了方便起见,尽可能地,代码将被列为从 Jupyter Notebook 运行时的形式。
有关安装信息,请参阅官方 PyTorch 网站上的入门指南(pytorch.org/get-started/locally)。我们建议 Windows 用户使用 Anaconda 或 Miniconda 进行安装(www.anaconda.com/distribution或docs.conda.io/en/latest/miniconda.html)。像 Linux 这样的其他操作系统通常有更多可行的选项,Pip 是 Python 最常见的包管理器。我们提供一个 requirements.txt 文件,pip 可以使用它来安装依赖项。当然,有经验的用户可以自由选择最符合您首选开发环境的方式来安装软件包。
第 2 部分还有一些不容忽视的下载带宽和磁盘空间要求。第 2 部分癌症检测项目所需的原始数据约为 60 GB,解压后需要约 120 GB 的空间。解压缩后的数据可以在解压缩后删除。此外,由于为了性能原因缓存了一些数据,训练时还需要另外 80 GB。您需要在用于训练的系统上至少有 200 GB 的空闲磁盘空间。虽然可以使用网络存储进行此操作,但如果网络访问速度慢于本地磁盘,则可能会导致训练速度下降。最好在本地 SSD 上有空间存储数据以便快速检索。
1.5.1 使用 Jupyter 笔记本
我们假设您已经安装了 PyTorch 和其他依赖项,并已验证一切正常。之前我们提到了在书中跟随代码的可能性。我们将大量使用 Jupyter 笔记本来展示我们的示例代码。Jupyter 笔记本显示为浏览器中的页面,通过它我们可以交互式地运行代码。代码由一个内核评估,这是在服务器上运行的进程,准备接收要执行的代码并发送结果,然后在页面上内联呈现。笔记本保持内核的状态,例如在评估代码期间定义的变量,直到终止或重新启动。我们与笔记本交互的基本单元是单元格:页面上的一个框,我们可以在其中输入代码并让内核评估它(通过菜单项或按 Shift-Enter)。我们可以在笔记本中添加多个单元格,新单元格将看到我们在早期单元格中创建的变量。单元格的最后一行返回的值将在执行后直接在单元格下方打印出来,绘图也是如此。通过混合源代码、评估结果和 Markdown 格式的文本单元格,我们可以生成漂亮的交互式文档。您可以在项目网站上阅读有关 Jupyter 笔记本的所有内容(jupyter.org)。
此时,您需要从 GitHub 代码检出的根目录启动笔记本服务器。启动服务器的确切方式取决于您的操作系统的细节以及您安装 Jupyter 的方式和位置。如果您有问题,请随时在书的论坛上提问。⁵ 一旦启动,您的默认浏览器将弹出,显示本地笔记本文件列表。
注意 Jupyter Notebooks 是通过代码表达和探索想法的强大工具。虽然我们认为它们非常适合本书的用例,但并非人人都适用。我们认为专注于消除摩擦和最小化认知负担很重要,对每个人来说都会有所不同。在使用 PyTorch 进行实验时,请使用您喜欢的工具。
书中所有示例的完整工作代码可以在书的网站(www.manning.com/books/deep-learning-with-pytorch)和我们在 GitHub 上的存储库中找到(github.com/deep-learning-with-pytorch/dlwpt-code)。
1.6 练习
-
启动 Python 以获得交互式提示符。
-
您正在使用哪个 Python 版本?我们希望至少是 3.6!
-
您能够
import torch吗?您得到了哪个 PyTorch 版本? -
torch.cuda.is_available()的结果是什么?它是否符合您基于所使用硬件的期望?
-
-
启动 Jupyter 笔记本服务器。
-
Jupyter 使用的 Python 版本是多少?
-
Jupyter 使用的
torch库的位置与您从交互式提示符导入的位置相同吗?
-
1.7 总结
-
深度学习模型会自动从示例中学习将输入和期望输出关联起来。
-
像 PyTorch 这样的库允许您高效地构建和训练神经网络模型。
-
PyTorch 专注于灵活性和速度,同时最大限度地减少认知负担。它还默认立即执行操作。
-
TorchScript 允许我们预编译模型,并不仅可以从 Python 中调用它们,还可以从 C++程序和移动设备中调用。
-
自 2017 年初发布 PyTorch 以来,深度学习工具生态系统已经显著巩固。
-
PyTorch 提供了许多实用库,以便促进深度学习项目。
¹Edsger W. Dijkstra,“计算科学的威胁”,mng.bz/nPJ5。
² 我们还推荐www.arxiv-sanity.com来帮助组织感兴趣的研究论文。
³ 在 2019 年的国际学习表示会议(ICLR)上,PyTorch 在 252 篇论文中被引用,比前一年的 87 篇增加了很多,并且与 TensorFlow 的水平相同,后者在 266 篇论文中被引用。
⁴ 这只是在运行时进行的数据准备,而不是预处理,后者在实际项目中可能占据相当大的部分。
⁵forums.manning.com/forums/deep-learning-with-pytorch
二、预训练网络
本章内容包括
-
运行预训练图像识别模型
-
GANs 和 CycleGAN 简介
-
能够生成图像文本描述的字幕模型
-
通过 Torch Hub 分享模型
我们在第一章结束时承诺在这一章中揭示令人惊奇的事物,现在是时候兑现了。计算机视觉无疑是深度学习的出现最受影响的领域之一,原因有很多。存在对自然图像进行分类或解释内容的需求,非常庞大的数据集变得可用,以及发明了新的构造,如卷积层,并且可以在 GPU 上以前所未有的准确性快速运行。所有这些因素与互联网巨头希望理解数百万用户使用移动设备拍摄的图片,并在这些巨头平台上管理的愿望相结合。简直是一场完美的风暴。
我们将学习如何使用该领域最优秀研究人员的工作,通过下载和运行已经在开放的大规模数据集上训练过的非常有趣的模型。我们可以将预训练的神经网络看作类似于一个接受输入并生成输出的程序。这样一个程序的行为由神经网络的架构和训练过程中看到的示例所决定,以期望的输入-输出对或输出应满足的期望属性。使用现成的模型可以快速启动深度学习项目,因为它利用了设计模型的研究人员的专业知识,以及用于训练权重的计算时间。
在本章中,我们将探索三种流行的预训练模型:一种可以根据内容标记图像的模型,另一种可以从真实图像中制作新图像,以及一种可以使用正确的英语句子描述图像内容的模型。我们将学习如何在 PyTorch 中加载和运行这些预训练模型,并介绍 PyTorch Hub,这是一组工具,通过这些工具,像我们将讨论的预训练模型这样的 PyTorch 模型可以通过统一接口轻松提供。在这个过程中,我们将讨论数据来源,定义术语如标签,并参加斑马竞技表演。
如果您是从其他深度学习框架转到 PyTorch,并且宁愿直接学习 PyTorch 的基础知识,您可以跳到下一章。本章涵盖的内容比基础知识更有趣,而且与任何给定的深度学习工具有一定的独立性。这并不是说它们不重要!但是,如果您在其他深度学习框架中使用过预训练模型,那么您已经知道它们可以是多么强大的工具。如果你已经熟悉生成对抗网络(GAN)游戏,那么我们不需要向您解释。
我们希望您继续阅读,因为本章隐藏了一些重要的技能。学习如何使用 PyTorch 运行预训练模型是一项有用的技能–毫无疑问。如果模型经过大型数据集的训练,这将尤其有用。我们需要习惯在真实世界数据上获取和运行神经网络的机制,然后可视化和评估其输出,无论我们是否对其进行了训练。
2.1 识别图像主题的预训练网络
作为我们对深度学习的首次尝试,我们将运行一个在对象识别任务上预训练的最先进的深度神经网络。可以通过源代码存储库访问许多预训练网络。研究人员通常会在其论文中发布源代码,而且通常该代码附带通过在参考数据集上训练模型获得的权重。使用其中一个模型可以使我们例如,可以轻松地为我们的下一个网络服务配备图像识别功能。
我们将在这里探索的预训练网络是在 ImageNet 数据集的一个子集上训练的(imagenet.stanford.edu)。ImageNet 是由斯坦福大学维护的一个非常庞大的数据集,包含超过 1400 万张图像。所有图像都标有来自 WordNet 数据集(wordnet.princeton.edu)的名词层次结构,WordNet 是一个大型的英语词汇数据库。
ImageNet 数据集,像其他几个公共数据集一样,起源于学术竞赛。竞赛一直是研究机构和公司研究人员经常挑战彼此的主要领域之一。自 2010 年创立以来,ImageNet 大规模视觉识别挑战赛(ILSVRC)已经变得越来越受欢迎。这个特定的竞赛基于一些任务,每年可能会有所不同,例如图像分类(告诉图像包含哪些对象类别)、对象定位(识别图像中对象的位置)、对象检测(识别和标记图像中的对象)、场景分类(对图像中的情况进行分类)和场景解析(将图像分割成与语义类别相关的区域,如牛、房子、奶酪、帽子)。特别是,图像分类任务包括获取输入图像并生成 5 个标签列表,来自 1000 个总类别,按置信度排序,描述图像的内容。
ILSVRC 的训练集包含了 120 万张图像,每张图像都标有 1000 个名词中的一个(例如,“狗”),被称为图像的类别。在这个意义上,我们将使用标签和类别这两个术语来互换使用。我们可以在图 2.1 中看到来自 ImageNet 的图像。

图 2.1 ImageNet 图像的一个小样本

图 2.2 推理过程
我们最终将能够将我们自己的图像输入到我们的预训练模型中,如图 2.2 所示。这将导致该图像的预测标签列表,然后我们可以检查模型认为我们的图像是什么。有些图像的预测是准确的,而其他的则不是!
输入图像将首先被预处理为torch.Tensor类的实例。它是一个具有高度和宽度的 RGB 图像,因此这个张量将具有三个维度:三个颜色通道和特定大小的两个空间图像维度。(我们将在第三章详细介绍张量是什么,但现在,可以将其视为浮点数的向量或矩阵。)我们的模型将获取处理过的输入图像,并将其传递到预训练网络中,以获取每个类别的分数。最高分对应于权重下最可能的类别。然后,每个类别都被一对一地映射到一个类别标签。该输出包含一个具有 1000 个元素的torch.Tensor,每个元素代表与该类别相关的分数。
在我们进行所有这些之前,我们需要获取网络本身,看看它的结构,了解如何准备数据以便模型使用。
2.1.1 获取用于图像识别的预训练网络
正如讨论的那样,我们现在将配备一个在 ImageNet 上训练过的网络。为此,我们将查看 TorchVision 项目(github.com/pytorch/vision),其中包含一些最佳性能的计算机视觉神经网络架构,如 AlexNet(mng.bz/lo6z)、ResNet(arxiv.org/pdf/ 1512.03385.pdf)和 Inception v3(arxiv.org/pdf/1512.00567.pdf)。它还可以轻松访问 ImageNet 等数据集,以及其他用于快速掌握 PyTorch 中计算机视觉应用的实用工具。我们将在本书后面深入研究其中一些。现在,让我们加载并运行两个网络:首先是 AlexNet,这是早期用于图像识别的突破性网络;然后是残差网络,简称 ResNet,它在 2015 年赢得了 ImageNet 分类、检测和定位比赛等多个比赛。如果你在第一章中没有安装 PyTorch,现在是一个很好的时机。
预定义的模型可以在torchvision.models(code/p1ch2/2 _pre_trained_networks.ipynb)中找到:
# In[1]:
from torchvision import models
我们可以看一下实际的模型:
# In[2]:
dir(models)# Out[2]:
['AlexNet','DenseNet','Inception3','ResNet','SqueezeNet','VGG',
...'alexnet','densenet','densenet121',
...'resnet','resnet101','resnet152',
...]
大写的名称指的是实现一些流行模型的 Python 类。它们在架构上有所不同–即,在输入和输出之间发生的操作排列方式不同。小写的名称是方便函数,返回从这些类实例化的模型,有时使用不同的参数集。例如,resnet101返回一个具有 101 层的ResNet实例,resnet18有 18 层,依此类推。现在我们将注意力转向 AlexNet。
2.1.2 AlexNet
AlexNet 架构以绝对优势赢得了 2012 年 ILSVRC,其前 5 个测试错误率(即,正确标签必须在前 5 个预测中)为 15.4%。相比之下,第二名提交的模型,不是基于深度网络的,错误率为 26.2%。这是计算机视觉历史上的一个决定性时刻:社区开始意识到深度学习在视觉任务中的潜力。这一飞跃随后不断改进,更现代的架构和训练方法使得前 5 个错误率降至 3%。
从今天的标准来看,与最先进的模型相比,AlexNet 是一个相对较小的网络。但在我们的情况下,它非常适合初次了解一个做某事的神经网络,并学习如何在新图像上运行预训练版本。
我们可以在图 2.3 中看到 AlexNet 的结构。虽然我们现在已经具备了理解它的所有要素,但我们可以预见一些方面。首先,每个块由一堆乘法和加法组成,加上我们将在第五章中发现的输出中的其他函数。我们可以将其视为一个滤波器–一个接受一个或多个图像作为输入并产生其他图像作为输出的函数。它的工作方式是在训练过程中确定的,基于它所看到的示例和所需的输出。

图 2.3 AlexNet 架构
在图 2.3 中,输入图像从左侧进入,并经过五组滤波器,每组产生多个输出图像。在每个滤波器之后,图像会按照注释的方式减小尺寸。最后一组滤波器产生的图像被布置成一个 4,096 元素的一维向量,并进行分类以产生 1,000 个输出概率,每个输出类别一个。
为了在输入图像上运行 AlexNet 架构,我们可以创建一个AlexNet类的实例。操作如下:
# In[3]:
alexnet = models.AlexNet()
此时,alexnet是一个可以运行 AlexNet 架构的对象。目前,我们不需要了解这种架构的细节。暂时来说,AlexNet只是一个不透明的对象,可以像函数一样调用。通过为alexnet提供一些精确大小的输入数据(我们很快将看到这些输入数据应该是什么),我们将通过网络进行前向传递。也就是说,输入将通过第一组神经元,其输出将被馈送到下一组神经元,一直到最终输出。从实际角度来看,假设我们有一个正确类型的input对象,我们可以使用output = alexnet(input)来运行前向传递。
但如果我们这样做,我们将通过整个网络传递数据来产生…垃圾!这是因为网络未初始化:它的权重,即输入相加和相乘的数字,尚未经过任何训练–网络本身是一个空白(或者说是随机)状态。我们需要从头开始训练它,或者加载之前训练的权重,现在我们将这样做。
为此,让我们回到models模块。我们了解到大写名称对应于实现用于计算机视觉的流行架构的类。另一方面,小写名称是函数,用于实例化具有预定义层数和单元数的模型,并可选择下载和加载预训练权重。请注意,使用这些函数并非必要:它们只是方便地实例化具有与预训练网络构建方式相匹配的层数和单元数的模型。
2.1.3 ResNet
使用resnet101函数,我们现在将实例化一个 101 层的卷积神经网络。为了让事情有个对比,2015 年之前,在残差网络出现之前,实现这样深度的稳定训练被认为是极其困难的。残差网络使用了一个技巧,使这成为可能,并通过这样做,在当年一举超过了几个基准。
现在让我们创建网络的一个实例。我们将传递一个参数,指示函数下载在 ImageNet 数据集上训练的resnet101的权重,该数据集包含 1,200,000 张图像和 1,000 个类别:
# In[4]:
resnet = models.resnet101(pretrained=True)
当我们盯着下载进度时,我们可以花一分钟来欣赏resnet101拥有 4450 万个参数–这是一个需要自动优化的大量参数!
2.1.4 准备好了,几乎可以运行了
好的,我们刚刚得到了什么?由于我们很好奇,我们将看一眼resnet101是什么样子。我们可以通过打印返回模型的值来做到这一点。这给了我们一个文本表示形式,提供了与我们在 2.3 中看到的相同类型的关于网络结构的详细信息。目前,这将是信息过载,但随着我们在书中的进展,我们将增加理解这段代码告诉我们的能力:
# In[5]:
resnet# Out[5]:
ResNet((conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3),bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True,track_running_stats=True)(relu): ReLU(inplace)(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1,ceil_mode=False)(layer1): Sequential((0): Bottleneck(
...))(avgpool): AvgPool2d(kernel_size=7, stride=1, padding=0)(fc): Linear(in_features=2048, out_features=1000, bias=True)
)
我们在这里看到的是modules,每行一个。请注意,它们与 Python 模块没有任何共同之处:它们是单独的操作,神经网络的构建模块。在其他深度学习框架中,它们也被称为层。
如果我们向下滚动,我们会看到很多Bottleneck模块一个接一个地重复(共 101 个!),包含卷积和其他模块。这就是典型的用于计算机视觉的深度神经网络的解剖学:一个或多或少顺序级联的滤波器和非线性函数,最终以一个层(fc)产生每个 1,000 个输出类别(out_features)的分数。
resnet变量可以像函数一样调用,输入一个或多个图像,并为每个 1,000 个 ImageNet 类别产生相同数量的分数。然而,在这之前,我们必须对输入图像进行预处理,使其具有正确的大小,并使其值(颜色)大致处于相同的数值范围内。为了做到这一点,torchvision模块提供了transforms,允许我们快速定义基本预处理函数的流水线:
# In[6]:
from torchvision import transforms
preprocess = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])])
在这种情况下,我们定义了一个preprocess函数,将输入图像缩放到 256×256,将图像裁剪到围绕中心的 224×224,将其转换为张量(一个 PyTorch 多维数组:在这种情况下,一个带有颜色、高度和宽度的 3D 数组),并对其 RGB(红色、绿色、蓝色)组件进行归一化,使其具有定义的均值和标准差。如果我们希望网络产生有意义的答案,这些值需要与训练期间呈现给网络的值匹配。当我们深入研究如何制作自己的图像识别模型时,我们将更深入地了解 transforms,见第 7.1.3 节。
现在我们可以获取我们最喜欢的狗的图片(比如,GitHub 仓库中的 bobby.jpg),对其进行预处理,然后看看 ResNet 对其的看法。我们可以从本地文件系统中使用 Pillow(pillow.readthedocs.io/en/stable)加载图像,这是 Python 的图像处理模块:
# In[7]:
from PIL import Image
img = Image.open("../data/p1ch2/bobby.jpg")
如果我们是从 Jupyter Notebook 中跟随进行的,我们将执行以下操作以内联查看图片(它将显示在以下内容中的<PIL.JpegImagePlugin...处):
# In[8]:
img
# Out[8]:
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=1280x720 at0x1B1601360B8>
否则,我们可以调用show方法,这将弹出一个带有查看器的窗口,以查看图 2.4 中显示的图像:

图 2.4 Bobby,我们非常特殊的输入图像
>>> img.show()
接下来,我们可以通过我们的预处理流程传递图像:
# In[9]:
img_t = preprocess(img)
然后我们可以以网络期望的方式重塑、裁剪和归一化输入张量。我们将在接下来的两章中更多地了解这一点;现在请耐心等待:
# In[10]:
import torch
batch_t = torch.unsqueeze(img_t, 0)
现在我们准备运行我们的模型。
2.1.5 运行!
在深度学习领域,对新数据运行经过训练的模型的过程称为推断。为了进行推断,我们需要将网络设置为eval模式:
# In[11]:
resnet.eval()# Out[11]:
ResNet((conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3),bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True,track_running_stats=True)(relu): ReLU(inplace)(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1,ceil_mode=False)(layer1): Sequential((0): Bottleneck(
...))(avgpool): AvgPool2d(kernel_size=7, stride=1, padding=0)(fc): Linear(in_features=2048, out_features=1000, bias=True)
)
如果我们忘记这样做,一些预训练模型,如批量归一化和丢弃,将不会产生有意义的答案,这仅仅是因为它们内部的工作方式。现在eval已经设置好,我们准备进行推断:
# In[12]:
out = resnet(batch_t)
out# Out[12]:
tensor([[ -3.4803, -1.6618, -2.4515, -3.2662, -3.2466, -1.3611,-2.0465, -2.5112, -1.3043, -2.8900, -1.6862, -1.3055,
...2.8674, -3.7442, 1.5085, -3.2500, -2.4894, -0.3354,0.1286, -1.1355, 3.3969, 4.4584]])
一个涉及 4450 万参数的惊人操作集刚刚发生,产生了一个包含 1,000 个分数的向量,每个分数对应一个 ImageNet 类别。这没花多少时间,是吧?
现在我们需要找出获得最高分数的类别的标签。这将告诉我们模型在图像中看到了什么。如果标签与人类描述图像的方式相匹配,那太棒了!这意味着一切正常。如果不匹配,那么要么在训练过程中出了问题,要么图像与模型期望的差异太大,模型无法正确处理,或者存在其他类似问题。
要查看预测标签列表,我们将加载一个文本文件,列出标签的顺序与网络在训练期间呈现给网络的顺序相同,然后我们将挑选出网络产生的最高分数的索引处的标签。几乎所有用于图像识别的模型的输出形式与我们即将处理的形式类似。
让我们加载包含 ImageNet 数据集类别的 1,000 个标签的文件:
# In[13]:
with open('../data/p1ch2/imagenet_classes.txt') as f:labels = [line.strip() for line in f.readlines()]
在这一点上,我们需要确定out张量中对应最高分数的索引。我们可以使用 PyTorch 中的max函数来做到这一点,该函数输出张量中的最大值以及发生最大值的索引:
# In[14]:
_, index = torch.max(out, 1)
现在我们可以使用索引来访问标签。这里,index不是一个普通的 Python 数字,而是一个单元素、一维张量(具体来说,tensor([207])),所以我们需要获取实际的数值以用作索引进入我们的labels列表,使用index[0]。我们还使用torch.nn.functional.softmax (mng.bz/BYnq) 来将我们的输出归一化到范围[0, 1],并除以总和。这给了我们大致类似于模型对其预测的信心。在这种情况下,模型有 96%的把握知道它正在看的是一只金毛寻回犬:
# In[15]:
percentage = torch.nn.functional.softmax(out, dim=1)[0] * 100
labels[index[0]], percentage[index[0]].item()# Out[15]:
('golden retriever', 96.29334259033203)
哦哦,谁是个好孩子?
由于模型生成了分数,我们还可以找出第二、第三等等最好的是什么。为此,我们可以使用sort函数,它可以将值按升序或降序排序,并在原始数组中提供排序后值的索引:
# In[16]:
_, indices = torch.sort(out, descending=True)
[(labels[idx], percentage[idx].item()) for idx in indices[0][:5]]# Out[16]:
[('golden retriever', 96.29334259033203),('Labrador retriever', 2.80812406539917),('cocker spaniel, English cocker spaniel, cocker', 0.28267428278923035),('redbone', 0.2086310237646103),('tennis ball', 0.11621569097042084)]
我们看到前四个是狗(红骨是一种品种;谁知道?),之后事情开始变得有趣起来。第五个答案“网球”可能是因为有足够多的狗旁边有网球的图片,以至于模型基本上在说:“我有 0.1%的机会完全误解了什么是网球。”这是人类和神经网络在看待世界的根本差异的一个很好的例子,以及奇怪、微妙的偏见如何很容易潜入我们的数据中。
玩耍的时候到了!我们可以继续用随机图像询问我们的网络,看看它会得出什么结果。网络的成功程度很大程度上取决于主题在训练集中是否得到很好的代表。如果我们呈现一个包含训练集之外主题的图像,网络很可能会以相当高的信心给出错误答案。实验和了解模型对未见数据的反应是很有用的。
我们刚刚运行了一个在 2015 年赢得图像分类比赛的网络。它学会了从狗的例子中识别我们的狗,以及许多其他真实世界的主题。现在我们将看看不同的架构如何实现其他类型的任务,从图像生成开始。
2.2 一个假装到成功的预训练模型
让我们假设一下,我们是职业罪犯,想要开始销售著名艺术家的“失落”画作的赝品。我们是罪犯,不是画家,所以当我们绘制我们的假雷姆布兰特和毕加索时,很快就会显而易见它们是业余的模仿品而不是真品。即使我们花了很多时间练习,直到我们也无法分辨出画作是假的,试图在当地艺术拍卖行兜售也会立即被赶出去。更糟糕的是,被告知“这显然是假的;滚出去”,并不能帮助我们改进!我们将不得不随机尝试很多事情,评估哪些需要稍微长一点时间才能识别为赝品,并在未来的尝试中强调这些特征,这将花费太长时间。
相反,我们需要找到一个道德标准有问题的艺术史学家来检查我们的作品,并告诉我们究竟是什么让他们发现这幅画不真实。有了这个反馈,我们可以以明确、有针对性的方式改进我们的作品,直到我们的可疑学者再也无法将我们的画作与真品区分开来。
很快,我们的“波提切利”将在卢浮宫展出,他们的百元钞票将进入我们的口袋。我们会变得富有!
尽管这种情景有点荒谬,但其基础技术是可靠的,并且很可能会对未来几年数字数据的真实性产生深远影响。整个“照片证据”的概念很可能会变得完全可疑,因为制作令人信服但虚假的图像和视频将变得非常容易。唯一的关键因素是数据。让我们看看这个过程是如何运作的。
2.2.1 GAN 游戏
在深度学习的背景下,我们刚刚描述的被称为GAN 游戏,其中两个网络,一个充当画家,另一个充当艺术史学家,竞争着互相愚弄,创造和检测伪造品。GAN 代表生成对抗网络,其中生成表示正在创建某物(在本例中是假的杰作),对抗表示两个网络正在竞争愚弄对方,而网络显而易见。这些网络是最近深度学习研究的最原创的成果之一。
请记住,我们的总体目标是生成一类图像的合成示例,这些示例无法被识别为伪造品。当与合法示例混合在一起时,一个熟练的检查员会很难确定哪些是真实的,哪些是我们的伪造品。
生成器网络在我们的场景中扮演画家的角色,负责从任意输入开始生成逼真的图像。鉴别器网络是无情的艺术检查员,需要判断给定的图像是由生成器制作还是属于真实图像集。这种双网络设计对于大多数深度学习架构来说是非典型的,但是,当用于实现 GAN 游戏时,可以产生令人难以置信的结果。

图 2.5 GAN 游戏的概念
图 2.5 展示了大致的情况。生成器的最终目标是欺骗鉴别器,混淆真实和虚假图像。鉴别器的最终目标是发现自己被欺骗,但它也帮助生成器找出生成图像中的可识别错误。在开始阶段,生成器产生混乱的三眼怪物,看起来一点也不像伦勃朗的肖像画。鉴别器很容易区分混乱的混乱图像和真实的绘画作品。随着训练的进行,信息从鉴别器返回,生成器利用这些信息进行改进。训练结束时,生成器能够产生令人信服的伪造品,鉴别器不再能分辨哪个是真实的。
请注意,“鉴别器获胜”或“生成器获胜”不应被字面意义上解释–两者之间没有明确的比赛。然而,两个网络都是基于另一个网络的结果进行训练的,这推动了每个网络参数的优化。
这种技术已经被证明能够导致生成器从仅有噪音和一个条件信号(比如,对于人脸:年轻、女性、戴眼镜)生成逼真图像,换句话说,一个训练良好的生成器学会了一个可信的模型,即使被人类检查也看起来很真实。
2.2.2 CycleGAN
这个概念的一个有趣演变是 CycleGAN。CycleGAN 可以将一个域的图像转换为另一个域的图像(反之亦然),而无需我们在训练集中明确提供匹配对。
在图 2.6 中,我们有一个 CycleGAN 工作流程,用于将一匹马的照片转换为斑马,反之亦然。请注意,有两个独立的生成器网络,以及两个不同的鉴别器。

图 2.6 一个 CycleGAN 训练到可以愚弄两个鉴别器网络的程度
如图所示,第一个生成器学会生成符合目标分布(在这种情况下是斑马)的图像,从属于不同分布(马)的图像开始,以便鉴别器无法判断从马照片生成的图像是否真的是斑马的真实图片。同时–这就是缩写中Cycle前缀的含义–生成的假斑马被发送到另一个生成器,沿着另一条路(在我们的情况下是从斑马到马),由另一个鉴别器进行判断。创建这样一个循环显著稳定了训练过程,解决了 GAN 的一个最初问题。
有趣的是,在这一点上,我们不需要匹配的马/斑马对作为地面真相(祝你好运,让它们匹配姿势!)。从一组不相关的马图片和斑马照片开始对生成器进行训练就足够了,超越了纯粹监督的设置。这个模型的影响甚至超出了这个范围:生成器学会了如何有选择性地改变场景中物体的外观,而不需要关于什么是什么的监督。没有信号表明鬃毛是鬃毛,腿是腿,但它们被转换成与另一种动物的解剖学相一致的东西。
2.2.3 将马变成斑马的网络
我们现在可以玩这个模型。CycleGAN 网络已经在从 ImageNet 数据集中提取的(不相关的)马图片和斑马图片数据集上进行了训练。网络学会了将一张或多张马的图片转换成斑马,尽可能保持其余部分的图像不变。虽然人类在过去几千年里并没有为将马变成斑马的工具而屏住呼吸,但这个任务展示了这些架构模拟复杂现实世界过程的能力,远程监督。虽然它们有局限性,但有迹象表明,在不久的将来,我们将无法在实时视频中区分真实和虚假,这打开了一个我们将立即关闭的潘多拉魔盒。
玩一个预训练的 CycleGAN 将给我们一个机会,更近距离地看一看网络–在这种情况下是一个生成器–是如何实现的。我们将使用我们的老朋友 ResNet。我们将在屏幕外定义一个ResNetGenerator类。代码在 3_cyclegan.ipynb 文件的第一个单元格中,但实现目前并不相关,而且在我们获得更多 PyTorch 经验之前,它太复杂了。现在,我们专注于它能做什么,而不是它是如何做到的。让我们用默认参数实例化这个类(code/p1ch2/3_cyclegan.ipynb):
# In[2]:
netG = ResNetGenerator()
netG模型已经创建,但它包含随机权重。我们之前提到过,我们将运行一个在 horse2zebra 数据集上预训练的生成器模型,该数据集的训练集包含 1068 张马和 1335 张斑马的图片。数据集可以在mng.bz/8pKP找到。模型的权重已保存在.pth 文件中,这只是模型张量参数的pickle文件。我们可以使用模型的load_state_dict方法将它们加载到ResNetGenerator中:
# In[3]:
model_path = '../data/p1ch2/horse2zebra_0.4.0.pth'
model_data = torch.load(model_path)
netG.load_state_dict(model_data)
此时,netG已经获得了在训练过程中获得的所有知识。请注意,这与我们在第 2.1.3 节中从torchvision中加载resnet101时发生的情况完全相同;但torchvision.resnet101函数将加载过程隐藏了起来。
让我们将网络设置为eval模式,就像我们为resnet101所做的那样:
# In[4]:
netG.eval()# Out[4]:
ResNetGenerator((model): Sequential(
...)
)
像之前打印模型一样,我们可以欣赏到它实际上相当简洁,考虑到它的功能。它接收一幅图像,通过查看像素识别出一匹或多匹马,并单独修改这些像素的值,使得输出看起来像一匹可信的斑马。我们在打印输出中(或者源代码中)不会认出任何类似斑马的东西:那是因为里面没有任何类似斑马的东西。这个网络是一个脚手架–关键在于权重。
我们准备加载一张随机的马的图像,看看我们的生成器会产生什么。首先,我们需要导入PIL和torchvision:
# In[5]:
from PIL import Image
from torchvision import transforms
然后我们定义一些输入转换,以确保数据以正确的形状和大小进入网络:
# In[6]:
preprocess = transforms.Compose([transforms.Resize(256),transforms.ToTensor()])
让我们打开一个马文件(见图 2.7):

图 2.7 一个骑马的人。马似乎不太乐意。
# In[7]:
img = Image.open("../data/p1ch2/horse.jpg")
img
好吧,有个家伙骑在马上。(看图片的话,可能不会持续太久。)不管怎样,让我们通过预处理并将其转换为正确形状的变量:
# In[8]:
img_t = preprocess(img)
batch_t = torch.unsqueeze(img_t, 0)
我们现在不必担心细节。重要的是我们要保持距离跟随。此时,batch_t可以被发送到我们的模型:
# In[9]:
batch_out = netG(batch_t)
batch_out现在是生成器的输出,我们可以将其转换回图像:
# In[10]:
out_t = (batch_out.data.squeeze() + 1.0) / 2.0
out_img = transforms.ToPILImage()(out_t)
# out_img.save('../data/p1ch2/zebra.jpg')
out_img# Out[10]:
<PIL.Image.Image image mode=RGB size=316x256 at 0x23B24634F98>
哦,天啊。谁像那样骑斑马呢?结果图像(图 2.8)并不完美,但请考虑到网络发现有人(某种程度上)骑在马上有点不寻常。需要重申的是,学习过程并没有经过直接监督,人类没有勾勒出成千上万匹马或手动 Photoshop 成千上万条斑马条纹。生成器已经学会生成一幅图像,可以愚弄鉴别器,让它认为那是一匹斑马,而图像并没有什么奇怪之处(显然鉴别器从未去过竞技场)。

图 2.8 一个骑斑马的人。斑马似乎不太乐意。
许多其他有趣的生成器是使用对抗训练或其他方法开发的。其中一些能够创建出可信的不存在个体的人脸;其他一些可以将草图转换为看起来真实的虚构景观图片。生成模型也被用于产生听起来真实的音频、可信的文本和令人愉悦的音乐。这些模型很可能将成为未来支持创造过程的工具的基础。
说真的,这种工作的影响难以言表。像我们刚刚下载的这种工具只会变得更加高质量和更加普遍。特别是换脸技术已经引起了相当多的媒体关注。搜索“deep fakes”会出现大量示例内容¹(尽管我们必须指出有相当数量的不适宜工作场所的内容被标记为这样;就像互联网上的一切一样,要小心点击)。
到目前为止,我们有机会玩弄一个能看到图像的模型和一个能生成新图像的模型。我们将以一个涉及另一个基本要素的模型结束我们的旅程:自然语言。
2.3 描述场景的预训练网络
为了亲身体验涉及自然语言的模型,我们将使用一个由 Ruotian Luo 慷慨提供的预训练图像字幕模型。这是 Andrej Karpathy 的 NeuralTalk2 模型的一个实现。当呈现一幅自然图像时,这种模型会生成一个用英语描述场景的字幕,如图 2.9 所示。该模型是在大量图像数据集上训练的,配有一对句子描述:例如,“一只虎斑猫斜靠在木桌上,一只爪子放在激光鼠标上,另一只放在黑色笔记本电脑上。”³
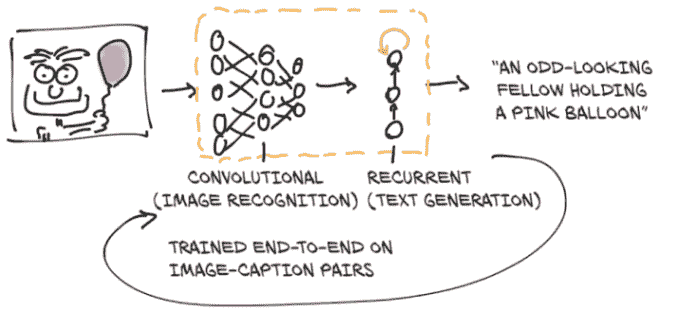
图 2.9 字幕模型的概念
这个字幕模型有两个连接的部分。模型的第一部分是一个网络,学习生成场景的“描述性”数值表示(Tabby 猫,激光鼠标,爪子),然后将这些数值描述作为第二部分的输入。第二部分是一个循环神经网络,通过将这些数值描述组合在一起生成连贯的句子。模型的两个部分一起在图像-字幕对上进行训练。
模型的后半部分被称为循环,因为它在后续的前向传递中生成其输出(单词),其中每个前向传递的输入包括前一个前向传递的输出。这使得下一个单词依赖于先前生成的单词,这是我们在处理句子或一般序列时所期望的。
2.3.1 神经对话 2
神经对话 2 模型可以在github.com/deep-learning-with-pytorch/ImageCaptioning.pytorch找到。我们可以将一组图像放在data目录中,并运行以下脚本:
python eval.py --model ./data/FC/fc-model.pth--infos_path ./data/FC/fc-infos.pkl --image_folder ./data
让我们尝试使用我们的 horse.jpg 图像。它说:“一个人骑着马在海滩上。”非常合适。
现在,就只是为了好玩,让我们看看我们的 CycleGAN 是否也能愚弄这个神经对话 2 模型。让我们在数据文件夹中添加 zebra.jpg 图像并重新运行模型:“一群斑马站在田野上。”嗯,它正确地识别了动物,但它在图像中看到了不止一只斑马。显然,这不是网络曾经见过斑马的姿势,也没有见过斑马上有骑手(带有一些虚假的斑马图案)。此外,斑马很可能是以群体形式出现在训练数据集中,因此我们可能需要调查一些偏见。字幕网络也没有描述骑手。同样,这可能是同样的原因:网络在训练数据集中没有看到骑手骑在斑马上。无论如何,这是一个令人印象深刻的壮举:我们生成了一张带有不可能情景的假图像,而字幕网络足够灵活,能够正确地捕捉主题。
我们想强调的是,像这样的东西,在深度学习出现之前是极其难以实现的,现在可以用不到一千行代码,使用一个不知道关于马或斑马的通用架构,以及一组图像和它们的描述(在这种情况下是 MS COCO 数据集)来获得。没有硬编码的标准或语法–一切,包括句子,都是从数据中的模式中产生的。
在这种情况下,网络架构在某种程度上比我们之前看到的更复杂,因为它包括两个网络。其中一个是循环的,但是它是由 PyTorch 提供的相同构建块构建的。
在撰写本文时,这样的模型更多地存在于应用研究或新颖项目中,而不是具有明确定义的具体用途。尽管结果令人鼓舞,但还不足以使用…至少现在还不足够。随着时间的推移(和额外的训练数据),我们应该期望这类模型能够向视觉受损的人描述世界,从视频中转录场景,以及执行其他类似的任务。
2.4 Torch Hub
从深度学习的早期就开始发布预训练模型,但直到 PyTorch 1.0,没有办法确保用户可以获得统一的接口来获取它们。TorchVision 是一个良好的接口示例,正如我们在本章前面看到的那样;但其他作者,正如我们在 CycleGAN 和神经对话 2 中看到的那样,选择了不同的设计。
PyTorch 1.0 引入了 Torch Hub,这是一个机制,通过该机制,作者可以在 GitHub 上发布一个模型,带有或不带有预训练权重,并通过 PyTorch 理解的接口公开它。这使得从第三方加载预训练模型就像加载 TorchVision 模型一样简单。
作者通过 Torch Hub 机制发布模型所需的全部工作就是在 GitHub 存储库的根目录中放置一个名为 hubconf.py 的文件。该文件具有非常简单的结构:
dependencies = ['torch', 'math'] # ❶def some_entry_fn(*args, **kwargs): # ❷model = build_some_model(*args, **kwargs)return modeldef another_entry_fn(*args, **kwargs):model = build_another_model(*args, **kwargs)return model
❶ 代码依赖的可选模块列表
❷ 一个或多个要向用户公开作为存储库入口点的函数。这些函数应根据参数初始化模型并返回它们
在我们寻找有趣的预训练模型的过程中,现在我们可以搜索包含 hubconf.py 的 GitHub 存储库,我们会立即知道可以使用 torch.hub 模块加载它们。让我们看看实际操作是如何进行的。为此,我们将回到 TorchVision,因为它提供了一个清晰的示例,展示了如何与 Torch Hub 交互。
让我们访问github.com/pytorch/vision,注意其中包含一个 hubconf.py 文件。很好,检查通过。首先要做的事情是查看该文件,看看存储库的入口点–我们稍后需要指定它们。在 TorchVision 的情况下,有两个:resnet18和resnet50。我们已经知道这些是做什么的:它们分别返回一个 18 层和一个 50 层的 ResNet 模型。我们还看到入口点函数包括一个pretrained关键字参数。如果为True,返回的模型将使用从 ImageNet 学习到的权重进行初始化,就像我们在本章前面看到的那样。
现在我们知道存储库、入口点和一个有趣的关键字参数。这就是我们加载模型所需的全部内容,使用 torch.hub,甚至无需克隆存储库。没错,PyTorch 会为我们处理:
import torch
from torch import hubresnet18_model = hub.load('pytorch/vision:master', # ❶'resnet18', # ❷pretrained=True) # ❸
❶ GitHub 存储库的名称和分支
❷ 入口点函数的名称
❸ 关键字参数
这将下载 pytorch/vision 存储库的主分支的快照,以及权重,到本地目录(默认为我们主目录中的.torch/hub),并运行resnet18入口点函数,返回实例化的模型。根据环境的不同,Python 可能会抱怨缺少模块,比如PIL。Torch Hub 不会安装缺少的依赖项,但会向我们报告,以便我们采取行动。
此时,我们可以使用适当的参数调用返回的模型,在其上运行前向传递,就像我们之前做的那样。好处在于,现在通过这种机制发布的每个模型都将以相同的方式对我们可用,远远超出视觉领域。
请注意,入口点应该返回模型;但严格来说,它们并不一定要这样做。例如,我们可以有一个用于转换输入的入口点,另一个用于将输出概率转换为文本标签。或者我们可以有一个仅包含模型的入口点,另一个包含模型以及预处理和后处理步骤。通过保持这些选项开放,PyTorch 开发人员为社区提供了足够的标准化和很大的灵活性。我们将看到从这个机会中会出现什么样的模式。
在撰写本文时,Torch Hub 还很新,只有少数模型是以这种方式发布的。我们可以通过谷歌搜索“github.com hubconf.py”来找到它们。希望在未来列表会增长,因为更多作者通过这个渠道分享他们的模型。
2.5 结论
希望这是一个有趣的章节。我们花了一些时间玩弄用 PyTorch 创建的模型,这些模型经过优化,可以执行特定任务。事实上,我们中更有进取心的人已经可以将其中一个模型放在 Web 服务器后面,并开始一项业务,与原始作者分享利润!一旦我们了解了这些模型是如何构建的,我们还将能够利用在这里获得的知识下载一个预训练模型,并快速对稍有不同的任务进行微调。
我们还将看到如何使用相同的构建块构建处理不同问题和不同类型数据的模型。PyTorch 做得特别好的一件事是以基本工具集的形式提供这些构建块–从 API 的角度来看,PyTorch 并不是一个非常庞大的库,特别是与其他深度学习框架相比。
本书不专注于完整地介绍 PyTorch API 或审查深度学习架构;相反,我们将建立对这些构建块的实践知识。这样,您将能够在坚实的基础上消化优秀的在线文档和存储库。
从下一章开始,我们将踏上一段旅程,使我们能够从头开始教授计算机技能,使用 PyTorch。我们还将了解,从预训练网络开始,并在新数据上进行微调,而不是从头开始,是解决问题的有效方法,特别是当我们拥有的数据点并不是特别多时。这是预训练网络是深度学习从业者必备的重要工具的另一个原因。是时候了解第一个基本构建块了:张量。
2.6 练习
-
将金毛猎犬的图像输入到马到斑马模型中。
-
你需要对图像进行哪些处理?
-
输出是什么样的?
-
-
在 GitHub 上搜索提供 hubconf.py 文件的项目。
-
返回了多少个存储库?
-
找一个带有 hubconf.py 的看起来有趣的项目。你能从文档中理解项目的目的吗?
-
收藏这个项目,在完成本书后回来。你能理解实现吗?
-
2.7 总结
-
预训练网络是已经在数据集上训练过的模型。这样的网络通常在加载网络参数后可以立即产生有用的结果。
-
通过了解如何使用预训练模型,我们可以将神经网络集成到项目中,而无需设计或训练它。
-
AlexNet 和 ResNet 是两个深度卷积网络,在它们发布的年份为图像识别设立了新的基准。
-
生成对抗网络(GANs)有两部分–生成器和判别器–它们共同工作以产生与真实物品无法区分的输出。
-
CycleGAN 使用一种支持在两种不同类别的图像之间进行转换的架构。
-
NeuralTalk2 使用混合模型架构来消耗图像并生成图像的文本描述。
-
Torch Hub 是一种标准化的方式,可以从具有适当的 hubconf.py 文件的任何项目中加载模型和权重。
¹Vox 文章“乔丹·皮尔模拟奥巴马公益广告是对假新闻的双刃警告”中描述了一个相关例子,作者是阿贾·罗曼诺;mng.bz/dxBz (警告:粗俗语言.
² 我们在github.com/deep-learning-with-pytorch/ImageCaptioning .pytorch上维护代码的克隆。
³Andrej Karpathy 和 Li Fei-Fei,“用于生成图像描述的深度视觉语义对齐”,cs.stanford.edu/people/karpathy/cvpr2015.pdf.
⁴ 联系出版商了解特许经营机会!
三、始于张量
本章涵盖
-
理解张量,PyTorch 中的基本数据结构
-
张量的索引和操作
-
与 NumPy 多维数组的互操作
-
将计算迁移到 GPU 以提高速度
在上一章中,我们参观了深度学习所能实现的许多应用。它们无一例外地包括将某种形式的数据(如图像或文本)转换为另一种形式的数据(如标签、数字或更多图像或文本)。从这个角度来看,深度学习实际上是构建一个能够将数据从一种表示转换为另一种表示的系统。这种转换是通过从一系列示例中提取所需映射的共同点来驱动的。例如,系统可能注意到狗的一般形状和金毛寻回犬的典型颜色。通过结合这两个图像属性,系统可以正确地将具有特定形状和颜色的图像映射到金毛寻回犬标签,而不是黑色实验室(或者一只黄褐色的公猫)。最终的系统可以处理数量相似的输入并为这些输入产生有意义的输出。
这个过程始于将我们的输入转换为浮点数。我们将在第四章中涵盖将图像像素转换为数字的过程,正如我们在图 3.1 的第一步中所看到的那样(以及许多其他类型的数据)。但在我们开始之前,在本章中,我们将学习如何通过张量在 PyTorch 中处理所有浮点数。
3.1 世界是由浮点数构成的
由于浮点数是网络处理信息的方式,我们需要一种方法将我们想要处理的现有世界数据编码为网络可以理解的内容,然后将输出解码回我们可以理解并用于我们目的的内容。

图 3.1 一个深度神经网络学习如何将输入表示转换为输出表示。(注意:神经元和输出的数量不是按比例缩放的。)
深度神经网络通常通过阶段性地学习从一种数据形式到另一种数据形式的转换来进行学习,这意味着每个阶段之间部分转换的数据可以被视为一系列中间表示。对于图像识别,早期的表示可以是边缘检测或某些纹理,如毛皮。更深层次的表示可以捕捉更复杂的结构,如耳朵、鼻子或眼睛。
一般来说,这种中间表示是描述输入并以对描述输入如何映射到神经网络输出至关重要的方式捕捉数据结构的一组浮点数。这种描述是针对手头的任务具体的,并且是从相关示例中学习的。这些浮点数集合及其操作是现代人工智能的核心–我们将在本书中看到几个这样的例子。
需要记住这些中间表示(如图 3.1 的第二步所示)是将输入与前一层神经元的权重相结合的结果。每个中间表示对应于其前面的输入是独一无二的。
在我们开始将数据转换为浮点输入的过程之前,我们必须首先对 PyTorch 如何处理和存储数据–作为输入、中间表示和输出有一个扎实的理解。本章将专门讨论这一点。
为此,PyTorch 引入了一种基本数据结构:张量。我们在第二章中已经遇到了张量,当我们对预训练网络进行推断时。对于那些来自数学、物理或工程领域的人来说,张量这个术语通常与空间、参考系统和它们之间的变换捆绑在一起。在深度学习的背景下,张量是将向量和矩阵推广到任意维数的概念,正如我们在图 3.2 中所看到的。同一概念的另一个名称是多维数组。张量的维数与用于引用张量内标量值的索引数量相一致。
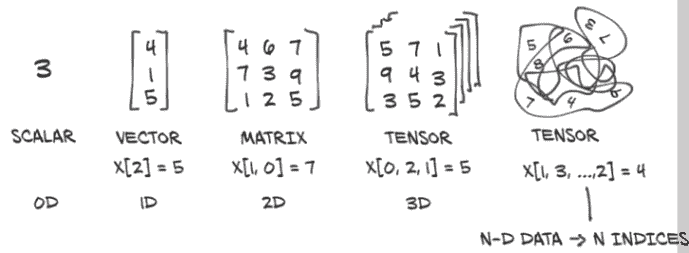
图 3.2 张量是 PyTorch 中表示数据的基本构件。
PyTorch 并不是唯一处理多维数组的库。NumPy 是迄今为止最流行的多维数组库,以至于现在可以说它已经成为数据科学的通用语言。PyTorch 与 NumPy 具有无缝互操作性,这带来了与 Python 中其他科学库的一流集成,如 SciPy (www.scipy.org)、Scikit-learn (scikit-learn.org)和 Pandas (pandas.pydata.org)。
与 NumPy 数组相比,PyTorch 张量具有一些超能力,比如能够在图形处理单元(GPU)上执行非常快速的操作,将操作分布在多个设备或机器上,并跟踪创建它们的计算图。这些都是在实现现代深度学习库时的重要特性。
我们将通过介绍 PyTorch 张量来开始本章,涵盖基础知识,以便为本书其余部分的工作做好准备。首先,我们将学习如何使用 PyTorch 张量库来操作张量。这包括数据在内存中的存储方式,如何在常数时间内对任意大的张量执行某些操作,以及前面提到的 NumPy 互操作性和 GPU 加速。如果我们希望张量成为编程工具箱中的首选工具,那么理解张量的能力和 API 是很重要的。在下一章中,我们将把这些知识应用到实践中,并学习如何以一种能够利用神经网络进行学习的方式表示多种不同类型的数据。
3.2 张量:多维数组
我们已经学到了张量是 PyTorch 中的基本数据结构。张量是一个数组:即,一种数据结构,用于存储一组可以通过索引单独访问的数字,并且可以用多个索引进行索引。
3.2.1 从 Python 列表到 PyTorch 张量
让我们看看list索引是如何工作的,这样我们就可以将其与张量索引进行比较。在 Python 中,取一个包含三个数字的列表(.code/p1ch3/1_tensors.ipynb):
# In[1]:
a = [1.0, 2.0, 1.0]
我们可以使用相应的从零开始的索引来访问列表的第一个元素:
# In[2]:
a[0]# Out[2]:
1.0# In[3]:
a[2] = 3.0
a# Out[3]:
[1.0, 2.0, 3.0]
对于处理数字向量的简单 Python 程序,比如 2D 线的坐标,使用 Python 列表来存储向量并不罕见。正如我们将在接下来的章节中看到的,使用更高效的张量数据结构,可以表示许多类型的数据–从图像到时间序列,甚至句子。通过定义张量上的操作,其中一些我们将在本章中探讨,我们可以高效地切片和操作数据,即使是从一个高级(并不特别快速)语言如 Python。
3.2.2 构建我们的第一个张量
让我们构建我们的第一个 PyTorch 张量并看看它是什么样子。暂时它不会是一个特别有意义的张量,只是一个列中的三个 1:
# In[4]:
import torch # ❶
a = torch.ones(3) # ❷
a# Out[4]:
tensor([1., 1., 1.])# In[5]:
a[1]# Out[5]:
tensor(1.)# In[6]:
float(a[1])# Out[6]:
1.0# In[7]:
a[2] = 2.0
a# Out[7]:
tensor([1., 1., 2.])
❶ 导入 torch 模块
❷ 创建一个大小为 3、填充为 1 的一维张量
导入 torch 模块后,我们调用一个函数,创建一个大小为 3、填充值为 1.0 的(一维)张量。我们可以使用基于零的索引访问元素或为其分配新值。尽管表面上这个例子与数字对象列表没有太大区别,但在底层情况完全不同。
3.2.3 张量的本质
Python 列表或数字元组是单独分配在内存中的 Python 对象的集合,如图 3.3 左侧所示。另一方面,PyTorch 张量或 NumPy 数组是对(通常)包含未装箱的 C 数值类型而不是 Python 对象的连续内存块的视图。在这种情况下,每个元素是一个 32 位(4 字节)的 float,正如我们在图 3.3 右侧所看到的。这意味着存储 1,000,000 个浮点数的 1D 张量将需要确切的 4,000,000 个连续字节,再加上一些小的开销用于元数据(如维度和数值类型)。

图 3.3 Python 对象(带框)数值值与张量(未带框数组)数值值
假设我们有一个坐标列表,我们想用它来表示一个几何对象:也许是一个顶点坐标为 (4, 1), (5, 3) 和 (2, 1) 的 2D 三角形。这个例子与深度学习无关,但很容易理解。与之前将坐标作为 Python 列表中的数字不同,我们可以使用一维张量,将X存储在偶数索引中,Y存储在奇数索引中,如下所示:
# In[8]:
points = torch.zeros(6) # ❶
points[0] = 4.0 # ❷
points[1] = 1.0
points[2] = 5.0
points[3] = 3.0
points[4] = 2.0
points[5] = 1.0
❶ 使用 .zeros 只是获取一个适当大小的数组的一种方式。
❷ 我们用我们实际想要的值覆盖了那些零值。
我们也可以将 Python 列表传递给构造函数,效果相同:
# In[9]:
points = torch.tensor([4.0, 1.0, 5.0, 3.0, 2.0, 1.0])
points# Out[9]:
tensor([4., 1., 5., 3., 2., 1.])
要获取第一个点的坐标,我们执行以下操作:
# In[10]:
float(points[0]), float(points[1])# Out[10]:
(4.0, 1.0)
这是可以的,尽管将第一个索引指向单独的 2D 点而不是点坐标会更实用。为此,我们可以使用一个 2D 张量:
# In[11]:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
points# Out[11]:
tensor([[4., 1.],[5., 3.],[2., 1.]])
在这里,我们将一个列表的列表传递给构造函数。我们可以询问张量的形状:
# In[12]:
points.shape# Out[12]:
torch.Size([3, 2])
这告诉我们张量沿每个维度的大小。我们也可以使用 zeros 或 ones 来初始化张量,提供大小作为一个元组:
# In[13]:
points = torch.zeros(3, 2)
points# Out[13]:
tensor([[0., 0.],[0., 0.],[0., 0.]])
现在我们可以使用两个索引访问张量中的单个元素:
# In[14]:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
points# Out[14]:
tensor([[4., 1.],[5., 3.],[2., 1.]])# In[15]:
points[0, 1]# Out[15]:
tensor(1.)
这返回我们数据集中第零个点的Y坐标。我们也可以像之前那样访问张量中的第一个元素,以获取第一个点的 2D 坐标:
# In[16]:
points[0]# Out[16]:
tensor([4., 1.])
输出是另一个张量,它呈现了相同基础数据的不同视图。新张量是一个大小为 2 的 1D 张量,引用了 points 张量中第一行的值。这是否意味着分配了一个新的内存块,将值复制到其中,并返回了包装在新张量对象中的新内存?不,因为那样会非常低效,特别是如果我们有数百万个点。当我们在本章后面讨论张量视图时,我们将重新讨论张量是如何存储的。
3.3 张量索引
如果我们需要获取一个不包含第一个点的张量,那很容易使用范围索引表示法,这也适用于标准 Python 列表。这里是一个提醒:
# In[53]:
some_list = list(range(6))
some_list[:] # ❶
some_list[1:4] # ❷
some_list[1:] # ❸
some_list[:4] # ❹
some_list[:-1] # ❺
some_list[1:4:2] # ❻
❶ 列表中的所有元素
❷ 从第 1 个元素(包括)到第 4 个元素(不包括)
❸ 从第 1 个元素(包括)到列表末尾
❹ 从列表开头到第 4 个元素(不包括)
❺ 从列表开头到倒数第二个元素之前
❻ 从第 1 个元素(包括)到第 4 个元素(不包括),步长为 2
为了实现我们的目标,我们可以使用与 PyTorch 张量相同的符号表示法,其中的额外好处是,就像在 NumPy 和其他 Python 科学库中一样,我们可以为张量的每个维度使用范围索引:
# In[54]:
points[1:] # ❶
points[1:, :] # ❷
points[1:, 0] # ❸
points[None] # ❹
❶ 第一个之后的所有行;隐式地所有列
❷ 第一个之后的所有行;所有列
❸ 第一个之后的所有行;第一列
❹ 添加一个大小为 1 的维度,就像 unsqueeze 一样
除了使用范围,PyTorch 还具有一种强大的索引形式,称为高级索引,我们将在下一章中看到。
3.4 命名张量
我们的张量的维度(或轴)通常索引像素位置或颜色通道之类的内容。这意味着当我们想要索引张量时,我们需要记住维度的顺序,并相应地编写我们的索引。随着数据通过多个张量进行转换,跟踪哪个维度包含什么数据可能会出错。
为了使事情具体化,想象我们有一个三维张量 img_t,来自第 2.1.4 节(这里为简单起见使用虚拟数据),我们想将其转换为灰度。我们查找了颜色的典型权重,以得出单个亮度值:¹
# In[2]:
img_t = torch.randn(3, 5, 5) # shape [channels, rows, columns]
weights = torch.tensor([0.2126, 0.7152, 0.0722])
我们经常希望我们的代码能够泛化–例如,从表示为具有高度和宽度维度的 2D 张量的灰度图像到添加第三个通道维度的彩色图像(如 RGB),或者从单个图像到一批图像。在第 2.1.4 节中,我们引入了一个额外的批处理维度 batch_t;这里我们假装有一个批处理为 2 的批次:
# In[3]:
batch_t = torch.randn(2, 3, 5, 5) # shape [batch, channels, rows, columns]
有时 RGB 通道在维度 0 中,有时它们在维度 1 中。但我们可以通过从末尾计数来概括:它们总是在维度-3 中,距离末尾的第三个。因此,懒惰的、无权重的平均值可以写成如下形式:
# In[4]:
img_gray_naive = img_t.mean(-3)
batch_gray_naive = batch_t.mean(-3)
img_gray_naive.shape, batch_gray_naive.shape# Out[4]:
(torch.Size([5, 5]), torch.Size([2, 5, 5]))
但现在我们也有了权重。PyTorch 将允许我们将形状相同的东西相乘,以及其中一个操作数在给定维度上的大小为 1。它还会自动附加大小为 1 的前导维度。这是一个称为广播的特性。形状为 (2, 3, 5, 5) 的 batch_t 乘以形状为 (3, 1, 1) 的 unsqueezed_weights,得到形状为 (2, 3, 5, 5) 的张量,然后我们可以对末尾的第三个维度求和(三个通道):
# In[5]:
unsqueezed_weights = weights.unsqueeze(-1).unsqueeze_(-1)
img_weights = (img_t * unsqueezed_weights)
batch_weights = (batch_t * unsqueezed_weights)
img_gray_weighted = img_weights.sum(-3)
batch_gray_weighted = batch_weights.sum(-3)
batch_weights.shape, batch_t.shape, unsqueezed_weights.shape# Out[5]:
(torch.Size([2, 3, 5, 5]), torch.Size([2, 3, 5, 5]), torch.Size([3, 1, 1]))
因为这很快变得混乱–出于效率考虑–PyTorch 函数 einsum(改编自 NumPy)指定了一个索引迷你语言²,为这些乘积的和给出维度的索引名称。就像在 Python 中经常一样,广播–一种总结未命名事物的形式–使用三个点 '...' 完成;但不要太担心 einsum,因为我们接下来不会使用它:
# In[6]:
img_gray_weighted_fancy = torch.einsum('...chw,c->...hw', img_t, weights)
batch_gray_weighted_fancy = torch.einsum('...chw,c->...hw', batch_t, weights)
batch_gray_weighted_fancy.shape# Out[6]:
torch.Size([2, 5, 5])
正如我们所看到的,涉及到相当多的簿记工作。这是容易出错的,特别是当张量的创建和使用位置在我们的代码中相距很远时。这引起了从业者的注意,因此有人建议³给维度赋予一个名称。
PyTorch 1.3 添加了命名张量作为一个实验性功能(参见pytorch.org/tutorials/intermediate/named_tensor_tutorial.html 和 pytorch.org/docs/stable/named_tensor.html)。张量工厂函数如 tensor 和 rand 接受一个 names 参数。这些名称应该是一个字符串序列:
# In[7]:
weights_named = torch.tensor([0.2126, 0.7152, 0.0722], names=['channels'])
weights_named# Out[7]:
tensor([0.2126, 0.7152, 0.0722], names=('channels',))
当我们已经有一个张量并想要添加名称(但不更改现有名称)时,我们可以在其上调用方法 refine_names。类似于索引,省略号 (...) 允许您省略任意数量的维度。使用 rename 兄弟方法,您还可以覆盖或删除(通过传入 None)现有名称:
# In[8]:
img_named = img_t.refine_names(..., 'channels', 'rows', 'columns')
batch_named = batch_t.refine_names(..., 'channels', 'rows', 'columns')
print("img named:", img_named.shape, img_named.names)
print("batch named:", batch_named.shape, batch_named.names)# Out[8]:
img named: torch.Size([3, 5, 5]) ('channels', 'rows', 'columns')
batch named: torch.Size([2, 3, 5, 5]) (None, 'channels', 'rows', 'columns')
对于具有两个输入的操作,除了通常的维度检查–大小是否相同,或者一个是否为 1 且可以广播到另一个–PyTorch 现在将为我们检查名称。到目前为止,它不会自动对齐维度,因此我们需要明确地执行此操作。方法 align_as 返回一个具有缺失维度的张量,并将现有维度排列到正确的顺序:
# In[9]:
weights_aligned = weights_named.align_as(img_named)
weights_aligned.shape, weights_aligned.names# Out[9]:
(torch.Size([3, 1, 1]), ('channels', 'rows', 'columns'))
接受维度参数的函数,如 sum,也接受命名维度:
# In[10]:
gray_named = (img_named * weights_aligned).sum('channels')
gray_named.shape, gray_named.names# Out[10]:
(torch.Size([5, 5]), ('rows', 'columns'))
如果我们尝试结合具有不同名称的维度,我们会收到一个错误:
gray_named = (img_named[..., :3] * weights_named).sum('channels')attempting to broadcast dims ['channels', 'rows','columns'] and dims ['channels']: dim 'columns' and dim 'channels'are at the same position from the right but do not match.
如果我们想在不操作命名张量的函数之外使用张量,我们需要通过将它们重命名为 None 来删除名称。以下操作使我们回到无名称维度的世界:
# In[12]:
gray_plain = gray_named.rename(None)
gray_plain.shape, gray_plain.names# Out[12]:
(torch.Size([5, 5]), (None, None))
鉴于在撰写时此功能的实验性质,并为避免处理索引和对齐,我们将在本书的其余部分坚持使用无名称。命名张量有潜力消除许多对齐错误的来源,这些错误——如果以 PyTorch 论坛为例——可能是头痛的根源。看到它们将被广泛采用将是很有趣的。
3.5 张量元素类型
到目前为止,我们已经介绍了张量如何工作的基础知识,但我们还没有涉及可以存储在 Tensor 中的数值类型。正如我们在第 3.2 节中暗示的,使用标准的 Python 数值类型可能不是最佳选择,原因有几个:
-
Python 中的数字是对象。 虽然浮点数可能只需要,例如,32 位来在计算机上表示,但 Python 会将其转换为一个完整的 Python 对象,带有引用计数等等。这个操作,称为装箱,如果我们需要存储少量数字,那么这并不是问题,但分配数百万个数字会变得非常低效。
-
Python 中的列表用于对象的顺序集合。 没有为例如高效地计算两个向量的点积或将向量相加等操作定义。此外,Python 列表无法优化其内容在内存中的布局,因为它们是指向 Python 对象(任何类型,不仅仅是数字)的可索引指针集合。最后,Python 列表是一维的,虽然我们可以创建列表的列表,但这同样非常低效。
-
与优化的编译代码相比,Python 解释器速度较慢。 在大量数值数据上执行数学运算时,使用在编译、低级语言如 C 中编写的优化代码可以更快地完成。
出于这些原因,数据科学库依赖于 NumPy 或引入专用数据结构如 PyTorch 张量,它们提供了高效的低级数值数据结构实现以及相关操作,并包装在方便的高级 API 中。为了实现这一点,张量中的对象必须都是相同类型的数字,并且 PyTorch 必须跟踪这种数值类型。
3.5.1 使用 dtype 指定数值类型
张量构造函数(如 tensor、zeros 和 ones)的 dtype 参数指定了张量中将包含的数值数据类型。数据类型指定了张量可以保存的可能值(整数与浮点数)以及每个值的字节数。dtype 参数故意与同名的标准 NumPy 参数相似。以下是 dtype 参数可能的值列表:
-
torch.float32或torch.float:32 位浮点数 -
torch.float64或torch.double:64 位,双精度浮点数 -
torch.float16或torch.half:16 位,半精度浮点数 -
torch.int8:有符号 8 位整数 -
torch.uint8:无符号 8 位整数 -
torch.int16或torch.short:有符号 16 位整数 -
torch.int32或torch.int:有符号 32 位整数 -
torch.int64或torch.long:有符号 64 位整数 -
torch.bool:布尔值
张量的默认数据类型是 32 位浮点数。
3.5.2 每个场合的 dtype
正如我们将在未来的章节中看到的,神经网络中发生的计算通常以 32 位浮点精度执行。更高的精度,如 64 位,不会提高模型的准确性,并且会消耗更多的内存和计算时间。16 位浮点、半精度数据类型在标准 CPU 上并不存在,但在现代 GPU 上提供。如果需要,可以切换到半精度以减少神经网络模型的占用空间,对准确性的影响很小。
张量可以用作其他张量的索引。在这种情况下,PyTorch 期望索引张量具有 64 位整数数据类型。使用整数作为参数创建张量,例如使用 torch.tensor([2, 2]),将默认创建一个 64 位整数张量。因此,我们将大部分时间处理 float32 和 int64。
最后,关于张量的谓词,如 points > 1.0,会产生 bool 张量,指示每个单独元素是否满足条件。这就是数值类型的要点。
3.5.3 管理张量的 dtype 属性
为了分配正确数值类型的张量,我们可以将适当的 dtype 作为构造函数的参数指定。例如:
# In[47]:
double_points = torch.ones(10, 2, dtype=torch.double)
short_points = torch.tensor([[1, 2], [3, 4]], dtype=torch.short)
通过访问相应的属性,我们可以了解张量的 dtype:
# In[48]:
short_points.dtype# Out[48]:
torch.int16
我们还可以使用相应的转换方法将张量创建函数的输出转换为正确的类型,例如
# In[49]:
double_points = torch.zeros(10, 2).double()
short_points = torch.ones(10, 2).short()
或更方便的 to 方法:
# In[50]:
double_points = torch.zeros(10, 2).to(torch.double)
short_points = torch.ones(10, 2).to(dtype=torch.short)
在幕后,to 检查转换是否必要,并在必要时执行。像 float 这样以 dtype 命名的转换方法是 to 的简写,但 to 方法可以接受我们将在第 3.9 节讨论的其他参数。
在操作中混合输入类型时,输入会自动转换为较大的类型。因此,如果我们想要 32 位计算,我们需要确保所有输入都是(最多)32 位:
# In[51]:
points_64 = torch.rand(5, dtype=torch.double) # ❶
points_short = points_64.to(torch.short)
points_64 * points_short # works from PyTorch 1.3 onwards# Out[51]:
tensor([0., 0., 0., 0., 0.], dtype=torch.float64)
❶ rand 将张量元素初始化为介于 0 和 1 之间的随机数。
3.6 张量 API
到目前为止,我们知道 PyTorch 张量是什么,以及它们在幕后是如何工作的。在我们结束之前,值得看一看 PyTorch 提供的张量操作。在这里列出它们都没有太大用处。相反,我们将对 API 有一个大致了解,并在在线文档 pytorch.org/docs 中确定一些查找内容的方向。
首先,大多数张量上的操作都可以在 torch 模块中找到,并且也可以作为张量对象的方法调用。例如,我们之前遇到的 transpose 函数可以从 torch 模块中使用
# In[71]:
a = torch.ones(3, 2)
a_t = torch.transpose(a, 0, 1)a.shape, a_t.shape# Out[71]:
(torch.Size([3, 2]), torch.Size([2, 3]))
或作为 a 张量的方法:
# In[72]:
a = torch.ones(3, 2)
a_t = a.transpose(0, 1)a.shape, a_t.shape# Out[72]:
(torch.Size([3, 2]), torch.Size([2, 3]))
这两种形式之间没有区别;它们可以互换使用。
我们 之前提到过在线文档 (pytorch.org/docs)。它们非常详尽且组织良好,将张量操作分成了不同的组:
创建操作 --用于构建张量的函数,如 ones 和 from_numpy
索引、切片、连接、变异操作 --用于改变张量形状、步幅或内容的函数,如 transpose
数学操作 --通过计算来操作张量内容的函数
-
逐点操作 --通过独立地对每个元素应用函数来获取新张量的函数,如
abs和cos -
缩减操作 --通过迭代张量计算聚合值的函数,如
mean、std和norm -
比较操作 --用于在张量上评估数值谓词的函数,如
equal和max -
频谱操作 --用于在频域中进行转换和操作的函数,如
stft和hamming_window -
其他操作 --在向量上操作的特殊函数,如
cross,或在矩阵上操作的函数,如trace -
BLAS 和 LAPACK 操作 --遵循基本线性代数子程序(BLAS)规范的函数,用于标量、向量-向量、矩阵-向量和矩阵-矩阵操作
随机抽样 --通过从概率分布中随机抽取值生成值的函数,如randn和normal
序列化 --用于保存和加载张量的函数,如load和save
并行性 --用于控制并行 CPU 执行线程数的函数,如set_num_threads
花些时间玩玩通用张量 API。本章提供了进行这种交互式探索所需的所有先决条件。随着我们继续阅读本书,我们还将遇到几个张量操作,从下一章开始。
3.7 张量:存储的景观
是时候更仔细地查看底层实现了。张量中的值是由torch.Storage实例管理的连续内存块分配的。存储是一个一维数值数据数组:即,包含给定类型数字的连续内存块,例如float(表示浮点数的 32 位)或int64(表示整数的 64 位)。PyTorch 的Tensor实例是这样一个Storage实例的视图,能够使用偏移量和每维步长索引到该存储中。⁵

图 3.4 张量是Storage实例的视图。
即使多个张量以不同方式索引数据,它们可以索引相同的存储。我们可以在图 3.4 中看到这种情况。实际上,在我们在第 3.2 节请求points[0]时,我们得到的是另一个索引与points张量相同存储的张量–只是不是全部,并且具有不同的维度(1D 与 2D)。然而,底层内存只分配一次,因此可以快速创建数据的备用张量视图,而不管Storage实例管理的数据大小如何。
3.7.1 存储索引
让我们看看如何在实践中使用我们的二维点进行存储索引。给定张量的存储可以通过.storage属性访问:
# In[17]:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
points.storage()# Out[17]:4.01.05.03.02.01.0
[torch.FloatStorage of size 6]
尽管张量报告自身具有三行和两列,但底层存储是一个大小为 6 的连续数组。在这种意义上,张量只知道如何将一对索引转换为存储中的位置。
我们也可以手动索引到存储中。例如:
# In[18]:
points_storage = points.storage()
points_storage[0]# Out[18]:
4.0# In[19]:
points.storage()[1]# Out[19]:
1.0
我们不能使用两个索引索引二维张量的存储。存储的布局始终是一维的,而不管可能引用它的任何和所有张量的维度如何。
在这一点上,改变存储的值导致改变其引用张量的内容应该不会让人感到意外:
# In[20]:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
points_storage = points.storage()
points_storage[0] = 2.0
points# Out[20]:
tensor([[2., 1.],[5., 3.],[2., 1.]])
3.7.2 修改存储的值:原地操作
除了前一节介绍的张量操作外,还存在一小部分操作仅作为Tensor对象的方法存在。它们可以通过名称末尾的下划线识别,比如zero_,表示该方法通过修改输入来原地操作,而不是创建新的输出张量并返回它。例如,zero_方法将所有输入元素都置零。任何没有末尾下划线的方法都不会改变源张量,并且会返回一个新的张量:
# In[73]:
a = torch.ones(3, 2)# In[74]:
a.zero_()
a# Out[74]:
tensor([[0., 0.],[0., 0.],[0., 0.]])
3.8 张量元数据:大小、偏移和步长
为了索引到存储中,张量依赖于一些信息,这些信息与它们的存储一起,明确定义它们:尺寸、偏移和步幅。它们的相互作用如图 3.5 所示。尺寸(或形状,在 NumPy 术语中)是一个元组,指示张量在每个维度上代表多少个元素。存储偏移是存储中对应于张量第一个元素的索引。步幅是在存储中需要跳过的元素数量,以获取沿每个维度的下一个元素。

图 3.5 张量的偏移、尺寸和步幅之间的关系。这里的张量是一个更大存储的视图,就像在创建更大的张量时可能分配的存储一样。
3.8.1 另一个张量存储的视图
通过提供相应的索引,我们可以获取张量中的第二个点:
# In[21]:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
second_point = points[1]
second_point.storage_offset()# Out[21]:
2# In[22]:
second_point.size()# Out[22]:
torch.Size([2])
结果张量在存储中的偏移为 2(因为我们需要跳过第一个点,它有两个项目),尺寸是Size类的一个实例,包含一个元素,因为张量是一维的。重要的是要注意,这与张量对象的shape属性中包含的信息相同:
# In[23]:
second_point.shape# Out[23]:
torch.Size([2])
步幅是一个元组,指示当索引在每个维度上增加 1 时,必须跳过存储中的元素数量。例如,我们的points张量的步幅是(2, 1):
# In[24]:
points.stride()# Out[24]:
(2, 1)
在 2D 张量中访问元素i, j会导致访问存储中的storage_offset + stride[0] * i + stride[1] * j元素。偏移通常为零;如果这个张量是一个查看存储的视图,该存储是为容纳更大的张量而创建的,则偏移可能是一个正值。
Tensor和Storage之间的这种间接关系使得一些操作变得廉价,比如转置张量或提取子张量,因为它们不会导致内存重新分配。相反,它们包括为尺寸、存储偏移或步幅分配一个具有不同值的新Tensor对象。
当我们索引特定点并看到存储偏移增加时,我们已经提取了一个子张量。让我们看看尺寸和步幅会发生什么变化:
# In[25]:
second_point = points[1]
second_point.size()# Out[25]:
torch.Size([2])# In[26]:
second_point.storage_offset()# Out[26]:
2# In[27]:
second_point.stride()# Out[27]:
(1,)
底线是,子张量的维度少了一个,正如我们所期望的那样,同时仍然索引与原始points张量相同的存储。这也意味着改变子张量将对原始张量产生副作用:
# In[28]:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
second_point = points[1]
second_point[0] = 10.0
points# Out[28]:
tensor([[ 4., 1.],[10., 3.],[ 2., 1.]])
这可能并不总是理想的,所以我们最终可以将子张量克隆到一个新的张量中:
# In[29]:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
second_point = points[1].clone()
second_point[0] = 10.0
points# Out[29]:
tensor([[4., 1.],[5., 3.],[2., 1.]])
3.8.2 在不复制的情况下转置
现在让我们尝试转置。让我们拿出我们的points张量,其中行中有单独的点,列中有X和Y坐标,并将其转向,使单独的点在列中。我们借此机会介绍t函数,这是二维张量的transpose的简写替代品:
# In[30]:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
points# Out[30]:
tensor([[4., 1.],[5., 3.],[2., 1.]])# In[31]:
points_t = points.t()
points_t# Out[31]:
tensor([[4., 5., 2.],[1., 3., 1.]])
提示 为了帮助建立对张量机制的扎实理解,可能是一个好主意拿起一支铅笔和一张纸,像图 3.5 中的图一样在我们逐步执行本节代码时涂鸦图表。
我们可以轻松验证这两个张量共享相同的存储
# In[32]:
id(points.storage()) == id(points_t.storage())# Out[32]:
True
它们只在形状和步幅上有所不同:
# In[33]:
points.stride()# Out[33]:
(2, 1)
# In[34]:
points_t.stride()# Out[34]:
(1, 2)
这告诉我们,在points中将第一个索引增加 1(例如,从points[0,0]到points[1,0])将会跳过存储中的两个元素,而增加第二个索引(从points[0,0]到points[0,1])将会跳过存储中的一个元素。换句话说,存储按行顺序顺序保存张量中的元素。
我们可以将points转置为points_t,如图 3.6 所示。我们改变了步幅中元素的顺序。之后,增加行(张量的第一个索引)将沿着存储跳过一个元素,就像我们在points中沿着列移动一样。这就是转置的定义。不会分配新的内存:转置只是通过创建一个具有不同步幅顺序的新Tensor实例来实现的。

图 3.6 张量的转置操作
3.8.3 高维度中的转置
在 PyTorch 中,转置不仅限于矩阵。我们可以通过指定应该发生转置(翻转形状和步幅)的两个维度来转置多维数组:
# In[35]:
some_t = torch.ones(3, 4, 5)
transpose_t = some_t.transpose(0, 2)
some_t.shape# Out[35]:
torch.Size([3, 4, 5])# In[36]:
transpose_t.shape# Out[36]:
torch.Size([5, 4, 3])# In[37]:
some_t.stride()# Out[37]:
(20, 5, 1)# In[38]:
transpose_t.stride()# Out[38]:
(1, 5, 20)
从存储中右起维度开始排列数值(即,对于二维张量,沿着行移动)的张量被定义为contiguous。连续张量很方便,因为我们可以有效地按顺序访问它们,而不需要在存储中跳跃(改善数据局部性会提高性能,因为现代 CPU 的内存访问方式)。当然,这种优势取决于算法的访问方式。
3.8.4 连续张量
PyTorch 中的一些张量操作仅适用于连续张量,例如我们将在下一章中遇到的view。在这种情况下,PyTorch 将抛出一个信息性异常,并要求我们显式调用contiguous。值得注意的是,如果张量已经是连续的,则调用contiguous不会做任何事情(也不会影响性能)。
在我们的例子中,points是连续的,而其转置则不是:
# In[39]:
points.is_contiguous()# Out[39]:
True# In[40]:
points_t.is_contiguous()# Out[40]:
False
我们可以使用contiguous方法从非连续张量中获得一个新的连续张量。张量的内容将保持不变,但步幅和存储将发生变化:
# In[41]:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
points_t = points.t()
points_t# Out[41]:
tensor([[4., 5., 2.],[1., 3., 1.]])# In[42]:
points_t.storage()# Out[42]:4.01.05.03.02.01.0
[torch.FloatStorage of size 6]# In[43]:
points_t.stride()# Out[43]:
(1, 2)# In[44]:
points_t_cont = points_t.contiguous()
points_t_cont# Out[44]:
tensor([[4., 5., 2.],[1., 3., 1.]])# In[45]:
points_t_cont.stride()# Out[45]:
(3, 1)# In[46]:
points_t_cont.storage()# Out[46]:4.05.02.01.03.01.0
[torch.FloatStorage of size 6]
请注意,存储已经重新排列,以便元素按行排列在新存储中。步幅已更改以反映新布局。
作为复习,图 3.7 再次显示了我们的图表。希望现在我们已经仔细研究了张量是如何构建的,一切都会变得清晰。

图 3.7 张量的偏移、大小和步幅之间的关系。这里的张量是一个更大存储的视图,就像在创建更大的张量时可能分配的存储一样。
3.9 将张量移动到 GPU
到目前为止,在本章中,当我们谈论存储时,我们指的是 CPU 上的内存。PyTorch 张量也可以存储在不同类型的处理器上:图形处理单元(GPU)。每个 PyTorch 张量都可以传输到 GPU 中的一个(或多个)以执行高度并行、快速的计算。将在张量上执行的所有操作都将使用 PyTorch 提供的 GPU 特定例程执行。
PyTorch 对各种 GPU 的支持
截至 2019 年中期,主要的 PyTorch 发行版只在支持 CUDA 的 GPU 上有加速。PyTorch 可以在 AMD 的 ROCm 上运行(rocm.github.io),主存储库提供支持,但到目前为止,您需要自行编译它。(在常规构建过程之前,您需要运行tools/amd_build/build_amd.py来转换 GPU 代码。)对 Google 的张量处理单元(TPU)的支持正在进行中(github.com/pytorch/xla),当前的概念验证可在 Google Colab 上公开访问:https://colab.research.google.com。在撰写本文时,不计划在其他 GPU 技术(如 OpenCL)上实现数据结构和内核。](https://colab.research.google.com)
3.9.1 管理张量的设备属性
除了dtype,PyTorch 的Tensor还有device的概念,即张量数据所放置的计算机位置。以下是我们如何通过为构造函数指定相应参数来在 GPU 上创建张量的方法:
# In[64]:
points_gpu = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]], device='cuda')
我们可以使用to方法将在 CPU 上创建的张量复制到 GPU 上:
# In[65]:
points_gpu = points.to(device='cuda')
这样做会返回一个新的张量,其中包含相同的数值数据,但存储在 GPU 的 RAM 中,而不是常规系统 RAM 中。现在数据存储在 GPU 上,当对张量执行数学运算时,我们将开始看到之前提到的加速效果。在几乎所有情况下,基于 CPU 和 GPU 的张量都暴露相同的用户接口,这样编写代码就更容易,不用关心重要的数值计算到底在哪里运行。
如果我们的机器有多个 GPU,我们还可以通过传递一个从零开始的整数来决定将张量分配到哪个 GPU 上,例如
# In[66]:
points_gpu = points.to(device='cuda:0')
此时,对张量执行的任何操作,例如将所有元素乘以一个常数,都是在 GPU 上执行的:
# In[67]:
points = 2 * points # ❶
points_gpu = 2 * points.to(device='cuda') # ❷
❶ 在 CPU 上执行的乘法
❷ 在 GPU 上执行的乘法
请注意,points_gpu张量在计算结果后并没有返回到 CPU。这是这一行中发生的事情:
-
points张量被复制到 GPU 上。 -
在 GPU 上分配一个新的张量,并用于存储乘法的结果。
-
返回一个指向该 GPU 张量的句柄。
因此,如果我们还向结果添加一个常数
# In[68]:
points_gpu = points_gpu + 4
加法仍然在 GPU 上执行,没有信息流向 CPU(除非我们打印或访问生成的张量)。为了将张量移回 CPU,我们需要在to方法中提供一个cpu参数,例如
# In[69]:
points_cpu = points_gpu.to(device='cpu')
我们还可以使用cpu和cuda的简写方法,而不是to方法来实现相同的目标:
# In[70]:
points_gpu = points.cuda() # ❶
points_gpu = points.cuda(0)
points_cpu = points_gpu.cpu()
❶ 默认为 GPU 索引 0
还值得一提的是,通过使用to方法,我们可以通过同时提供device和dtype作为参数来同时更改位置和数据类型。
3.10 NumPy 互操作性
我们在这里和那里提到了 NumPy。虽然我们不认为 NumPy 是阅读本书的先决条件,但我们强烈建议您熟悉 NumPy,因为它在 Python 数据科学生态系统中无处不在。PyTorch 张量可以与 NumPy 数组之间进行非常高效的转换。通过这样做,我们可以利用围绕 NumPy 数组类型构建起来的 Python 生态系统中的大量功能。这种与 NumPy 数组的零拷贝互操作性归功于存储系统与 Python 缓冲区协议的工作(docs.python.org/3/c-api/buffer.html)。
要从我们的points张量中获取一个 NumPy 数组,我们只需调用
# In[55]:
points = torch.ones(3, 4)
points_np = points.numpy()
points_np# Out[55]:
array([[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.]], dtype=float32)
这将返回一个正确大小、形状和数值类型的 NumPy 多维数组。有趣的是,返回的数组与张量存储共享相同的底层缓冲区。这意味着numpy方法可以在基本上不花费任何成本地执行,只要数据位于 CPU RAM 中。这也意味着修改 NumPy 数组将导致源张量的更改。如果张量分配在 GPU 上,PyTorch 将把张量内容复制到在 CPU 上分配的 NumPy 数组中。
相反,我们可以通过以下方式从 NumPy 数组获得一个 PyTorch 张量
# In[56]:
points = torch.from_numpy(points_np)
这将使用我们刚刚描述的相同的缓冲区共享策略。
注意 PyTorch 中的默认数值类型是 32 位浮点数,而 NumPy 中是 64 位。正如在第 3.5.2 节中讨论的那样,我们通常希望使用 32 位浮点数,因此在转换后,我们需要确保具有dtype torch .float的张量。
3.11 广义张量也是张量
对于本书的目的,以及一般大多数应用程序,张量都是多维数组,就像我们在本章中看到的那样。如果我们冒险窥探 PyTorch 的内部,会有一个转折:底层数据存储方式与我们在第 3.6 节讨论的张量 API 是分开的。只要满足该 API 的约定,任何实现都可以被视为张量!
PyTorch 将调用正确的计算函数,无论我们的张量是在 CPU 还是 GPU 上。这是通过调度机制实现的,该机制可以通过将用户界面 API 连接到正确的后端函数来满足其他张量类型的需求。确实,还有其他种类的张量:有些特定于某些类别的硬件设备(如 Google TPU),而其他的数据表示策略与我们迄今所见的稠密数组风格不同。例如,稀疏张量仅存储非零条目,以及索引信息。图 3.8 左侧的 PyTorch 调度程序被设计为可扩展的;图 3.8 右侧所示的用于适应各种数字类型的后续切换是实现的固定方面,编码到每个后端中。

图 3.8 PyTorch 中的调度程序是其关键基础设施之一。
我们将在第十五章遇到量化张量,它们作为另一种具有专门计算后端的张量类型实现。有时,我们使用的通常张量被称为稠密或分步,以区别于使用其他内存布局的张量。
与许多事物一样,随着 PyTorch 支持更广泛的硬件和应用程序范围,张量种类的数量也在增加。我们可以期待随着人们探索用 PyTorch 表达和执行计算的新方法,新的种类将继续出现。
3.12 序列化张量
在需要的时候,即使现场创建张量也很好,但如果其中的数据很有价值,我们会希望将其保存到文件中,并在某个时候加载回来。毕竟,我们不想每次运行程序时都从头开始重新训练模型!PyTorch 在底层使用pickle来序列化张量对象,还有专门的存储序列化代码。这里是如何将我们的points张量保存到一个 ourpoints.t 文件中的方法:
# In[57]:
torch.save(points, '../data/p1ch3/ourpoints.t')
作为替代方案,我们可以传递文件描述符而不是文件名:
# In[58]:
with open('../data/p1ch3/ourpoints.t','wb') as f:torch.save(points, f)
类似地,加载我们的点也是一行代码
# In[59]:
points = torch.load('../data/p1ch3/ourpoints.t')
或者,等效地,
# In[60]:
with open('../data/p1ch3/ourpoints.t','rb') as f:points = torch.load(f)
虽然我们可以快速以这种方式保存张量,如果我们只想用 PyTorch 加载它们,但文件格式本身不具有互操作性:我们无法使用除 PyTorch 之外的软件读取张量。根据使用情况,这可能是一个限制,也可能不是,但我们应该学会如何在需要时以互操作的方式保存张量。接下来我们将看看如何做到这一点。
3.12.1 使用 h5py 序列化到 HDF5
每种用例都是独特的,但我们怀疑在将 PyTorch 引入已经依赖不同库的现有系统时,需要以互操作方式保存张量将更常见。新项目可能不需要这样做那么频繁。
然而,在需要时,您可以使用 HDF5 格式和库(www.hdfgroup.org/solutions/hdf5)。HDF5 是一种便携式、广泛支持的格式,用于表示序列化的多维数组,以嵌套的键值字典组织。Python 通过h5py库(www.h5py.org)支持 HDF5,该库接受并返回 NumPy 数组形式的数据。
我们可以使用以下命令安装h5py
$ conda install h5py
在这一点上,我们可以通过将其转换为 NumPy 数组(如前所述,没有成本)并将其传递给create_dataset函数来保存我们的points张量:
# In[61]:
import h5pyf = h5py.File('../data/p1ch3/ourpoints.hdf5', 'w')
dset = f.create_dataset('coords', data=points.numpy())
f.close()
这里的'coords'是 HDF5 文件中的一个键。我们可以有其他键–甚至是嵌套的键。在 HDF5 中的一个有趣之处是,我们可以在磁盘上索引数据集,并且只访问我们感兴趣的元素。假设我们只想加载数据集中的最后两个点:
# In[62]:
f = h5py.File('../data/p1ch3/ourpoints.hdf5', 'r')
dset = f['coords']
last_points = dset[-2:]
当打开文件或需要数据集时,数据不会被加载。相反,数据会保留在磁盘上,直到我们请求数据集中的第二行和最后一行。在那时,h5py访问这两列并返回一个类似 NumPy 数组的对象,封装了数据集中的那个区域,行为类似 NumPy 数组,并具有相同的 API。
由于这个事实,我们可以将返回的对象传递给torch.from_numpy函数,直接获得一个张量。请注意,在这种情况下,数据被复制到张量的存储中:
# In[63]:
last_points = torch.from_numpy(dset[-2:])
f.close()
加载数据完成后,我们关闭文件。关闭 HDFS 文件会使数据集无效,尝试在此之后访问dset将导致异常。只要我们按照这里显示的顺序进行操作,我们就可以正常工作并现在可以使用last_points张量。
3.13 结论
现在我们已经涵盖了我们需要开始用浮点数表示一切的一切。我们将根据需要涵盖张量的其他方面–例如创建张量的视图;使用其他张量对张量进行索引;以及广播,简化了在不同大小或形状的张量之间执行逐元素操作的操作–。
在第四章中,我们将学习如何在 PyTorch 中表示现实世界的数据。我们将从简单的表格数据开始,然后转向更复杂的内容。在这个过程中,我们将更多地了解张量。
3.14 练习
-
从
list(range(9))创建一个张量a。预测并检查大小、偏移和步长。-
使用
b = a.view(3, 3)创建一个新的张量。view函数的作用是什么?检查a和b是否共享相同的存储。 -
创建一个张量
c = b[1:,1:]。预测并检查大小、偏移和步长。
-
-
选择一个数学运算,如余弦或平方根。你能在
torch库中找到相应的函数吗?-
对
a逐元素应用函数。为什么会返回错误? -
使函数工作需要什么操作?
-
是否有一个在原地操作的函数版本?
-
3.15 总结
-
神经网络将浮点表示转换为其他浮点表示。起始和结束表示通常是人类可解释的,但中间表示则不太容易理解。
-
这些浮点表示存储在张量中。
-
张量是多维数组;它们是 PyTorch 中的基本数据结构。
-
PyTorch 拥有一个全面的标准库,用于张量的创建、操作和数学运算。
-
张量可以序列化到磁盘并重新加载。
-
PyTorch 中的所有张量操作都可以在 CPU 和 GPU 上执行,而不需要更改代码。
-
PyTorch 使用尾随下划线来表示一个函数在张量上的原地操作(例如,
Tensor.sqrt_)。
¹ 由于感知不是一个简单的规范,人们提出了许多权重。例如,参见en.wikipedia.org/wiki/Luma_(video)。
²Tim Rocktäschel 的博文“Einsum is All You Need–Einstein Summation in Deep Learning”( rockt.github.io/2018/04/30/einsum)提供了很好的概述。
³ 参见 Sasha Rush 的博文“Tensor Considered Harmful”,Harvardnlp,nlp.seas.harvard.edu/NamedTensor。
⁴ 以及在uint8的情况下的符号。
⁵ 在未来的 PyTorch 版本中,Storage可能无法直接访问,但我们在这里展示的内容仍然提供了张量在内部工作方式的良好思维图。