Measuring and Improving Compositional Generalization in Text-to-SQL via Component Alignment
NAACL 2022| CCF B
Abstract
在 text-to-SQL 任务中,正如在许多 NLP 中一样,组合泛化是一个重大挑战:神经网络在训练和测试分布不同的情况下难以实现组合泛化。然而,最近改进这一点的尝试都是基于单词级合成数据或特定数据集分割来生成组合偏差。在这项工作中,我们提出了一种子句级组合示例生成方法。我们首先将Spider文本转SQL数据集中的句子拆分为子句子,用相应的SQL子句注释每个子句子,从而得到一个新的数据集Spider-SS。然后,我们通过以不同的构成方式组合 Spider-SS 子句,进一步构建一个新的数据集 Spider-CG,以测试模型组合泛化的能力。实验表明,在 Spider-CG 上评估时,现有模型的性能会显着下降,即使每个子句在训练过程中都会出现。为了解决这个问题,我们修改了一些最先进的模型来训练 Spider-SS 的分段数据,并且我们表明这种方法提高了泛化性能。
1 Introduction
监督学习环境中的神经模型在从训练分布中提取的数据上表现出良好的性能。然而,分布外 (OOD,out-of-distribution ) 样本的泛化性能可能较差。即使新样本由已知成分组成,情况也可能如此;例如,在 SCAN 数据集上,许多模型对输入 “jump twice and walk” 给出了错误的预测,即使在训练过程中已经出现了 “jump twice”, “walk”, and “walk twice”。这种(通常缺乏)在训练期间能够观察到各种元素的新组合的泛化能力被称为组合泛化。
之前关于 text-to-SQL 的组合泛化的工作主要集中在查询拆分上。例如,Shaw 等人 (2021)提出基于SQL原子和化合物分析的TMCD分割和基于长度的问题分割。 Finegan-Dollak 等人(2018)提出了一种基于查询模板的带有单词替换的分割,这比问题分割更具挑战性。然而,这些分割受到数据集内容的限制,使得很难构建具有挑战性的基准,同时确保每个问题短语(子句)出现在训练集中。
之前的工作通过增强模型的组件意识来提高泛化能力。同样,尹等人(2021) 以及 Herzig 和 Berant (2021) 提出了基于跨度的语义解析器,可以预测话语跨度上的子程序。然而,这些工作都是基于数据集,其中组件对齐相对容易实现;但对于更复杂的文本转SQL,不能直接使用它们的方法。例如,如图所示,为了将子句与子SQL对齐,算法需要知道 ‘youngest’ 对应 ‘age’,‘weigh’ 对应 ‘weight’。对于小型或单域设置,可以通过建立规则来构建这样的对齐算法;然而,目前还没有简单可行的大型复杂跨域文本到 SQL 的对齐方法,例如Spider 基准。
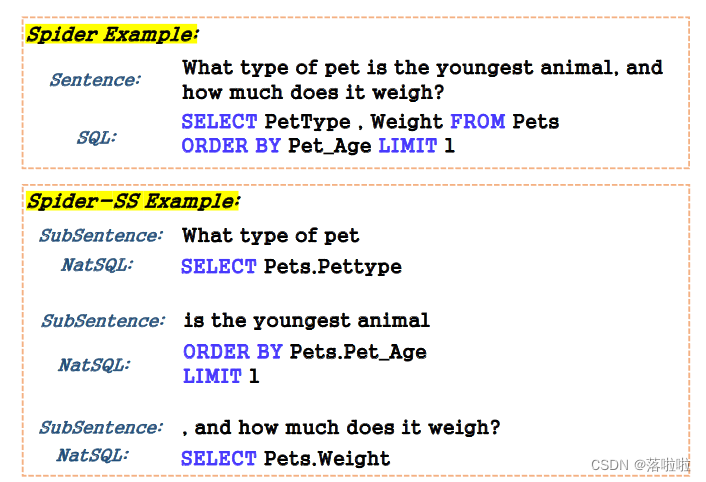
在本文的工作中,我们首先引入了一个新的数据集 Spider-SS(SS 代表sub-sentences子句),源自 Spider;图 1 对两者进行了比较。为了构建Spider-SS:
- 我们首先设计一个句子分割算法,将每个Spider句子分割成几个子句子(sub-sentences),直到不可分割。
- 接下来,我们用每个子句相对应的 SQL 子句对其进行注释。通过使用中间表示语言 NatSQL来降低此任务的难度,该语言更简单,并且在语法上与自然语言 (NL) 更一致。
因此,Spider-SS 为设计具有更好泛化能力的模型提供了新的资源,而无需设计复杂的对齐算法。此外,它还可以作为评估未来对齐算法的基准。据我们所知,这是第一个基于子句的 text-to-SQL 数据集。
带注释的 Spider-SS 为我们提供了与 NatSQL 子句配对的 sub-sentences ( 自然语言子句 ),这些sub-sentences作为我们的元素。基于Spider-SS,我们然后构建进一步的数据集Spider-CG(CG代表组合泛化),通过用其他样本中的sub-sentences替换该样本的 sub-sentences,或者组合两个sub-sentences以形成更复杂的样本。 Spider-CG 包含两个子集;图 2 显示了每种情况的一个示例:
- 第一个子集包含通过替换子句生成的 23,569 个示例;我们认为该子集中的大多数数据都是分布的 (in-distribution)。
- 第二个子集包含 22,030 个通过附加子句子生成的示例,与原始样本相比,增加了句子和 SQL 查询的长度和复杂性;我们将此子集视为 OOD (out-of-distribution )。我们证明,当仅在原始 Spider 数据集上训练模型时,即使一些子句已经出现在训练集中,它们在 Spider-CG 的第二个 OOD 子集上的性能也会显着下降。

为了提高 text-to-SQL 模型的泛化性能,我们修改了几个以前的最先进的模型,以便它们可以被应用在 Spider-SS 数据集上,并逐个使用 sub-sentence 训练模型。这一修改在 Spider-CG 的 OOD 子集上获得了超过 7.8% 的精度提升。
简而言之,我们做出以下贡献:
- 除了句子拆分算法之外,我们还引入了 Spider-SS,这是一个基于 Spider 基准的人工策划的基于子句的 text-to-SQL 数据集,通过将其 NL 问题拆分为子句。
- 我们引入了Spider-CG 基准测试来测量文本到SQL 模型的组合泛化性能。
- 我们证明 text-to-SQL 模型可以适应基于子句子的训练,从而提高其泛化性能。
2 Spider-SS
2.1 Overview
图 1 展示了 Spider 和 Spider-SS 之间的比较。与 Spider 将整个 SQL 查询为整个句子注释不同,Spider-SS 将 SQL 子句注释为子句子 sub-sentence。 Spider-SS 使用 NatSQL 代替 SQL 进行注释,由于 SQL语言的设计规则,有时候直接使用 sub-sentence 对应的 SQL 子句对其进行注释是比较困难的。Spider-SS提供了一种组合算法,收集所有NatSQL子句,然后生成NatSQL查询,其中NatSQL查询可以转换为SQL查询。
构建Spider-SS的目的是获得子句级别的 text-to-SQL 数据,避免需要 基于复杂的大型跨域 text-to-SQL数据集(例如Spider)难以构建的对齐算法。此外,我们可以通过Spider-SS的不同子句组合生成更复杂的例子。与 Spider 一致,Spider-SS 包含 7000 个训练示例和 1034 个开发示例,但 Spider-SS 不包含测试集,因为 Spider 测试集不公开。构建Spider-SS有两个步骤。首先设计句子分割算法,将句子切分成子句,然后手动标注每个子句对应的NatSQL子句。
2.2 Sentence Split Algorithm
我们在 NL 依存解析器 spaCy 上构建句子分割算法,它提供句子的语法结构。基本上,我们将句子分成以下依赖项:prep、relcl、advcl、acl、nsubj、npadvmod、csubj、nsubjpass 和 conj。根据(de Marnee and Manning,2016),这些依赖关系帮助我们区分主句、从句和修饰语。图 3 显示了一个句子的依存结构以及如何将该句子拆分为三个子句子。然而,并不是每个句子都会被分割,因为有一些不可分割的句子,如图 4 中的第三个示例,其注释与 Spider 数据集相同。虽然这种方法在大多数情况下可以很好地分割句子,但由于自然语言的可变性,有些例子无法完美分割。


为了解决句子拆分中的剩余问题,我们设计了一些针对 text-to-SQL 应用程序的细化步骤。例如,当模式列或表的阶段意外地分成两个子句时,这两个子句会自动连接起来。此外,当子句中只有一个单词时,也应该撤消相应的拆分。
我们从Spider-SS开发集中抽取了500个样本来人工评估分割结果的可接受性,只有 < 3% 的分割结果不令人满意。例如,在图4中第一个示例的拆分结果中,最后两个子句应组合起来对应于“ORDER BY Customer.Email_Address, Customer.Phone_Number ASC ”。在这个例子中,我们并没有简单地给最后一个子句添加“ORDER BY Customer.Phone_Number ASC”,因为 sub-sentence 中没有提到任何与“ORDER BY”相关的内容。在这里,我们引入了“extra”,这是一个为Spider-SS数据集设计的新NatSQL关键字,表明该 sub-sentence 提到了暂时不适合任何其他NatSQL子句的列。当将 NatSQL 子句组合到最终的 NatSQL 查询中时,组合算法根据前后子句确定 “extra” 列的最终位置。请注意,即使有一小部分分割结果不满意,只要在 Spider-SS 上训练的模型能够根据输入的 sub-sentence 给出正确的输出,sub-sentences 本身的质量不会强烈影响模型效用。
2.3 Data Annotation
当我们得到上一步的分割结果后,我们就可以开始数据标注了。我们根据sub-sentence内容给出精确的注释,例如上一小节讨论的“extra”列注释。此外,如果子句中缺少 schema 列的描述,我们将为 schema 列添加一个“NO MENTIONED”标记。例如,在图 4 的第二个示例中,“按升序”子句没有提及“Farm.Total_Horses”列。因此,我们为其添加“NO MENTIONED”标记。对于那些没有提及任何与查询相关的子句,我们给出“NONE”标记,表示没有 NatSQL 子句。
由于标注是根据 sub-sentence 内容进行的,因此与 sub-sentence 更加一致的等价SQL会优先于原始SQL。同样,如果原来的SQL注释有错误,我们根据内容进行更正。
我们使用 NatSQL 而不是 SQL 来注释 sub-sentence ,其中 NatSQL 是 SQL 的中间表示,仅保留 SQL 中的 SELECT、WHERE 和 ORDER BY 子句。由于某些子句需要使用 GROUP BY 子句进行注释,因此我们选择使用GROUP BY 增强的NatSQL版本。我们没有直接使用 SQL,因为在某些情况下很难注释,例如图 5 中的 SQL 示例。困难在于这个 SQL 查询中有两个 SELECT 子句,但没有一个子句对应于两个 SELECT 子句。另外,考虑到两个WHERE条件对应不同的SELECT子句,基于SQL的标注工作完成起来要困难得多。如图5所示,我们可以使用NatSQL快速完成标注,同时NatSQL可以转换回目标SQL。

3 Spider-CG
3.1 Overview
Spider-CG是一个合成数据集,是通过重新组合Spider-SS的子句生成的。重组方法有两种。第一种是不同示例之间的子句替换,另一种是将子句附加到另一个句子中。为了方便后续讨论,我们将子句替换方法生成的Spider-CG子集命名为CG-SUB,将另一个命名为CG-APP。
在CG-SUB中,Spider-SS训练集生成了20,686个示例,而开发集生成了2,883个示例。在 CG-APP 中,训练集和开发集生成的示例分别为 18,793 个和 3,237 个。因此,Spider-CG 包含 45,599 个示例,大约是 Spider 数据集的六倍。如果需要更多数据,我们可以进一步在 CG-SUB 示例中附加子句子。
3.2 Generation Algorithm
根据算法1,我们可以根据组成元素生成CG-SUB和CG-APP。每个元素包含一个或多个带有来自 Spider-SS 的相应 NatSQL 子句的 sub-sentence,其中这些 NatSQL 只能是 WHERE 或 ORDER BY 子句。因此,算法1仅替换并附加WHERE和ORDER BY子句,并且不修改SELECT子句。我们通过从头到尾或从尾到头扫描所有 sub-sentences 来收集构成元素的子句,遇到除 WHERE 和 ORDER BY 之外的子句时停止。例如,我们生成一个组合元素,其中包含图 5 中 Spider-SS 示例的最后两个子句子。相反,图 1 中的示例没有提取任何元素。应该注意的是,一个域中的元素不能在另一个域中使用,因为模式项不同。因此,有多少个域,就需要运行算法 1 多少次。

3.3 Quality Evaluation
我们认为 text-to-SQL 语句的质量由两个标准决定:包含所需信息和合理。 “信息”标准要求一个句子包含导出目标 NatSQL 所需的所有信息。 “合理”的标准要求句子逻辑正确、表达流畅、易于理解。我们从 Spider-CG 数据集中随机抽取了 2000 个样本,其中大约 99% 是可以接受的,即它们满足这两个标准。评估由具有 text-to-SQL 丰富知识的计算机科学毕业生手动进行。然而,这些可接受的例子并不意味着没有语法错误,而且它们可能毫无意义。我们在表1中给出了一个可以接受但不完美的例子,其中这个句子是没有意义的,因为它要查询的内容就是它给出的条件。此外,在这些可接受的示例中,大约有 5% 的 NatSQL 查询无法转换为正确的 SQL。这个问题可以在未来通过设计良好的数据库模式或者更新NatSQL转换函数来解决。

4 Model
现有的 text-to-SQL 模型输入一个句子并输出相应的SQL查询。因此,考虑使用 Spider-SS 数据集的最简单方法是训练输入子句并输出相应 NatSQL 子句的模型。然而,这种方法并不可行,因为它会丢失一些重要的模式信息。例如,如果只看图1中的第三个子句,你不知道它是查询宠物的体重还是人的体重。
为了考虑Spider-SS的上下文和子句数据,我们提出seq2seq模型可以对整个句子进行编码,但仅对子句进行解码。图 6 展示了对整个句子进行编码但仅解码“who is old than ten”的子句并输出相应的 NatSQL 子句的工作流程。

基于这样的改进,seq2seq 的 text-to-SQL 模型可以在 Spider-SS 上适用。尽管之前基于跨度的语义解析器可以使用基于 Spider-SS 数据集的对齐注释,但它们都不是为复杂的文本到 SQL 问题而设计的。我们的修改思路与基于span的语义解析器原理上类似,但是我们没有按照基于span的方式改变现有的模型,因为我们的修改思路工作量更小。
一般来说,我们可以通过三个步骤使基于seq2seq的 text-to-SQL模型适应Spider-SS。
- 数据预处理。按子句子拆分 Spider-SS 示例。例如,将图6中的示例拆分为图7中所示的两个示例。
- 模型修改。经过数据预处理后,模型有两个输入数据。第一个输入是直接进入编码器的整个问题。第二个输入是子句索引,用于选择编码器输出,如图6所示。
- 输出组合。由于模型输出可能只是一个子句,而不是完整的 NatSQL 查询,因此我们在模型输出所有 NatSQL 子句后生成最终的 NatSQL 查询。
5 Experiment
5.1 Experimental Setup
**数据集。**我们在 Spider-CG 和 Spider (Yu et al., 2018b) 数据集上评估了之前最先进的模型。因为 Spider 的测试集没有公开,Spider-CG 不包含测试集。正如 3.1 节中所讨论的,我们将 Spider-CG 分为两个子集:CG-SUB 和 CGAPP。因此,有五个评估集:
- S p i d e r D Spider_D SpiderD:原始 Spider 开发集,包含 1,034 个示例,用于 cross-domain in-distribution text-to-SQL 评估。
- C G − S U B T CG-SUB_T CG−SUBT:CG-SUB 训练集,包含从Spider-SS 训练集中通过替换子句生成的20,686 个示例。 C G − S U B T CG-SUB_T CG−SUBT可用于域内 in-domain in-distribution text-to-SQL 评估。
- C G − S U B D CG-SUB_D CG−SUBD:CG-SUB 开发集,包含 2,883 个用于 cross-domain in-distribution text-to-SQL 评估的示例。
- C G − A P P T CG-APP_T CG−APPT:CG-APP 训练集,包含通过附加子句子从Spider-SS 训练集中生成的18,793 个示例。 C G − A P P T CG-APP_T CG−APPT 可用于 in-domain out-of-distribution text-to-SQL 评估。
- C G − A P P D CG-APP_D CG−APPD:CG-APP 开发集,包含 3,237 个 cross-domain out-of-distribution text-to-SQL 评估的示例。
我们的评估基于原始 Spider 基准中定义的精确匹配指标。精确匹配度量衡量不带条件值的预测查询的语法树是否与黄金查询的语法树相同。所有模型仅在 7000 个 Spider 或 Spider-SS 训练样本上进行训练。
模型。我们评估了以下在 Spider 上达到竞争性能的开源模型:
- GNN:使用 GLOVE嵌入的 GNN 模型。
- RATSQL:使用 GLOVE 嵌入的 RATSQL 模型。
- R A T S Q L B RATSQL_B RATSQLB:使用 BERT嵌入的 RATSQL 模型。
- R A T S Q L G RATSQL_G RATSQLG:使用 GAP 嵌入的 RATSQL 模型。
- ( N ) (_N) (N):该下标表示模型使用 NatSQL 而不是 SQL。
- ( S ) (_S) (S):该下标表示模型根据第4节进行修改并在Spider-SS上进行训练。此外,因为 Spider-SS 是由 NatSQL 进行标注的,这个下标也意味着模型使用 NatSQL 而不是 SQL。
5.2 Dataset Analysis
Spider-SS。表 2 显示了 Spider 中的 SQL 与 Spider-SS 中 NatSQL 生成的 SQL 之间的差异。我们的评估结果低于原始 NatSQL 数据集,因为 Spider-SS 使用等效的 SQL 并纠正了一些错误,如第 2.3 节所述。某些等效且更正的 SQL 无法在精确匹配指标和执行匹配方面获得积极结果。因此,在 Spider-SS 上训练的模型可能不适合追逐 Spider 基准,尤其是基于精确匹配指标。同样,扩展 NatSQL 的 RATSQLG 在 Spider 测试集的执行匹配中取得了之前的 SOTA 结果,但在精确匹配中得到了比原始结果更差的结果(Gan et al., 2021b)。因此,我们建议使用基于 NatSQL 的数据集来评估在 NatSQL 上训练的模型。

Spider-CG。表3列出了五个不同评估集的难度分布。难度标准由Spider benchmark定义,包括简单、中等、困难和超困难。实验表明,SQL越难,正确预测就越困难。从表3可以发现, C G − S U B T CG-SUB_T CG−SUBT和 C G − S U B D CG-SUB_D CG−SUBD的难度分布与 S p i d e r D Spider_D SpiderD类似。 C G − S U B T CG-SUB_T CG−SUBT、 C G − S U B D CG-SUB_D CG−SUBD 和 S p i d e r D Spider_D SpiderD 之间的相似分布支持第 1 节中讨论的观点,即替换方法生成的示例是分布的。
另一方面, C G − A P P T CG-APP_T CG−APPT和 C G − A P P D CG-APP_D CG−APPD的难度分布与 S p i d e r D Spider_D SpiderD明显不同。由于添加了子句, C G − A P P CG-APP CG−APP 中的NL和SQL变得更加复杂,其中Extra Hard中的SQL比例明显增加,而easy则相反。

5.3 Sentence Split Algorithm Evaluation
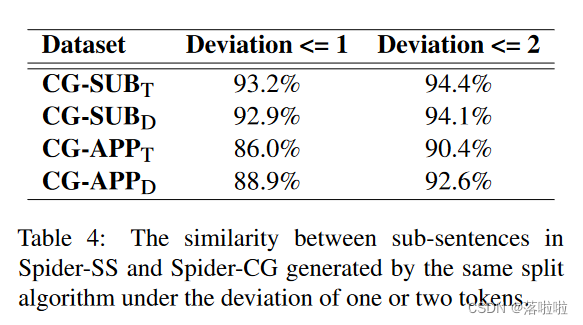
我们根据2.2节中介绍的算法分割的Spider-SS子句的组合生成Spider-CG。我们可以利用该算法对Spider-CG中的句子进行分割,然后将分割结果与SpiderSS子句子进行比较,以评估分割算法的稳定性。我们认为去除结果中一两个token的偏差是可以接受的。例如,在图1中,我们认为将第三个子句的逗号放入第二个子句中不会改变子句的含义,对于移动逗号和“and”一词也是如此。
表4展示了Spider-SS和Spider-CG中子句之间的相似度,这些子句是在一两个词的偏差下通过相同的分割算法生成的。当允许存在两个偏差词时,所有评价集中的相似度超过90%。考虑到在Spider-SS上训练的模型不需要一致的分割结果,如2.2节中讨论的,分割算法的相似度结果足够好。 CG-SUB的相似度高于CG-APP,这意味着句子越复杂,对算法的挑战就越大。虽然算法在训练集上进行了细化,但CG-SUB和CG-APP中的训练和开发相似度接近,表明该算法对于未知领域中的句子表现一致。综上所述,我们认为只要句子不比CG-APP复杂,该算法就可以在其他文本转SQL数据集中稳定使用。
5.4 Model Results
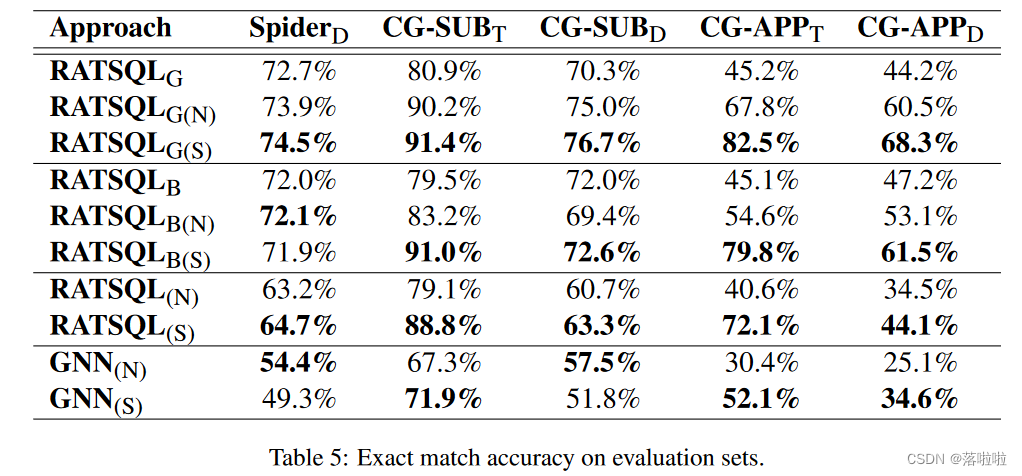
表 5 显示了五个不同评估集的精确匹配精度。在 C G − A P P T CG-APP_T CG−APPT 和 C G − A P P D CG-APP_D CG−APPD 这两个 OOD 数据集中,所有模型的性能均下降了约 10% 至 30%。然而,在 OOD 数据集上进行评估时,在 Spider-SS 上训练的模型明显优于在 Spider 上训练的模型。在输入带有下标(S)的模型之前,我们使用句子分割算法来分割每个句子。尽管分割的子句与训练时看到的不完全一致,但这并不妨碍带有下标(S)的模型获得良好的性能,即 R A T S Q L G ( S ) RATSQL_{G(S)} RATSQLG(S)在所有评估集上始终优于所有其他模型。这些结果表明基于子句的方法可以提高泛化性能。限制是该方法可能与原始模型不兼容,例如 R A T S Q L B ( S ) RATSQLB_{(S)} RATSQLB(S)中的原始超参数不可行,还有GNN在SpiderD和 C G − S U B D CG-SUB_D CG−SUBD上的性能下降。
每个模型在未见过的 S p i d e r D Spider_D SpiderD和 C G − S U B D CG-SUB_D CG−SUBD之间都有接近的结果,这表明从模型的角度来看,合成句子与NL非常相似。因此,我们相信 C G − S U B D CG-SUB_D CG−SUBD 的性能可以推广到现实世界。而且,考虑到生成 C G − S U B D CG-SUB_D CG−SUBD和 C G − A P P D CG-APP_D CG−APPD的算法很接近(参见附录A),我们可以进一步推测 C G − A P P D CG-APP_D CG−APPD的合成句子也接近自然语言。
在 Spider-CG 上评估时,使用 NatSQL 的模型明显优于不使用 NatSQL 的模型。原因之一是Spider和Spider-SS的训练数据大约有10%的差异,这导致在Spider上训练的模型在对Spider-SS的NatSQL生成的SQL进行评估时性能下降,反之亦然。另一方面,(Gan et al., 2021b)中的实验表明 NatSQL 提高了 extra hard SQL 中的模型性能。因此, R A T S Q L G ( N ) RATSQL_{G(N)} RATSQLG(N) 和 R A T S Q L B ( N ) RATSQL_{B(N)} RATSQLB(N) 在 C G − A P P T CG-APP_T CG−APPT 和$ CG-APP_D$ 中比 R A T S Q L G RATSQL_G RATSQLG 和$ RATSQL_B$ 遭受更少的性能下降。
6 Conclusion
我们引入 Spider-SS 和 Spider-CG 来测量文本到 SQL 模型的组合泛化。具体来说,Spider-SS 是一个基于 Spider 基准的人工策划的基于子句的 text-to-SQL 数据集。 Spider-CG是通过替换和附加不同样本的子句子构建的合成文本到SQL数据集,使得训练集和测试集由不同的子句组成。我们发现以前的 text-to-SQ 模型的性能在 Spider-CG OOD 子集上急剧下降,而修改模型以适应 Spider-SS 的分段数据可以提高组合泛化性能。