概述
一个查询具体如何被执行的过程,称为查询计划。MongoDB采用自底向上的方式来构造查询计划,每一个查询计划(query plan)都会被分解为若干个有层次的阶段(stage)。整个查询计划最终会呈现出一颗多叉树。
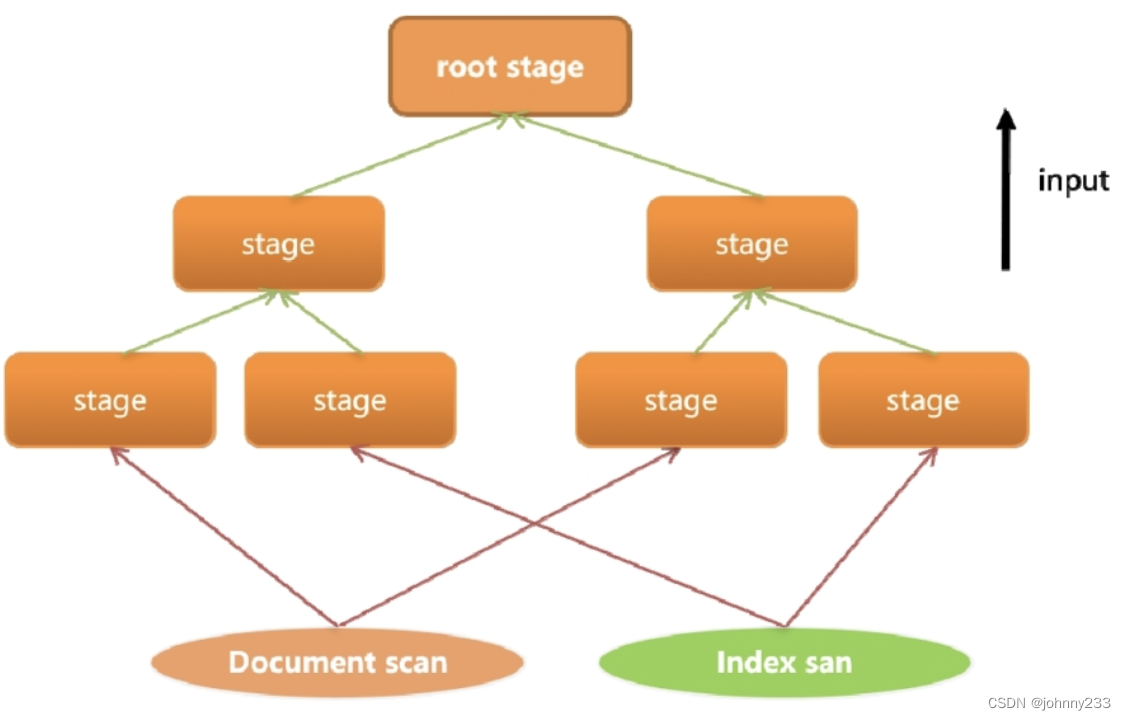
整个计算过程是从下向上投递的,每一个阶段的计算结果都是其上层阶段的输入,每一个阶段都有自己的逻辑语义。
执行模式
explain有3种执行模式:
- queryPlanner:默认,仅进行查询计划分析,输出计划中的阶段信息。
- executionStats:执行模式,在查询计划分析后,将按照winningPlan执行查询并统计过程信息。
- allPlansExecution:全计划执行模式,将执行所有计划(包括winningPlan和rejectPlans),并返回全部的过程统计信息。
根据MongoDB版本不同,explain命令的输出结果包含不同的丰富的信息(字段)。以MongoDB 6.0.5版本为例,执行命令db.game.find().explain();或db.game.find().explain('queryPlanner');,输出完全一样:
[{"command": {"find": "game","filter": {},"$db": "test"},"explainVersion": "1","ok": 1,"queryPlanner": {"namespace": "test.game","indexFilterSet": false,"parsedQuery": {},"queryHash": "17830885","planCacheKey": "17830885","maxIndexedOrSolutionsReached": false,"maxIndexedAndSolutionsReached": false,"maxScansToExplodeReached": false,"winningPlan": {"stage": "COLLSCAN","direction": "forward"},"rejectedPlans": []},"serverInfo": {"host": "johnnydeMBP.ada.local","port": 27017,"version": "6.0.5","gitVersion": "c9a99c120371d4d4c52cbb15dac34a36ce8d3b1d"},"serverParameters": {"internalQueryFacetBufferSizeBytes": 104857600,"internalQueryFacetMaxOutputDocSizeBytes": 104857600,"internalLookupStageIntermediateDocumentMaxSizeBytes": 104857600,"internalDocumentSourceGroupMaxMemoryBytes": 104857600,"internalQueryMaxBlockingSortMemoryUsageBytes": 104857600,"internalQueryProhibitBlockingMergeOnMongoS": 0,"internalQueryMaxAddToSetBytes": 104857600,"internalDocumentSourceSetWindowFieldsMaxMemoryBytes": 104857600}}
]
部分字段解读:
- queryPlanner:描述查询计划
queryPlanner.indexFilterSet:是否设置indexFilter,indexFilter可决定查询优化器对于某个查询将如何使用索引- serverInfo:MongoDB服务器概要信息
- serverParameters:参数设置
执行命令db.game.find().explain('executionStats');,输出内容除executionStats字段外,和db.game.find().explain('queryPlanner');完全一致,都出部分:
"executionStats": {"executionSuccess": true,"nReturned": 0,"executionTimeMillis": 0,"totalKeysExamined": 0,"totalDocsExamined": 0,"executionStages": {"stage": "COLLSCAN","nReturned": 0,"executionTimeMillisEstimate": 0,"works": 2,"advanced": 0,"needTime": 1,"needYield": 0,"saveState": 0,"restoreState": 0,"isEOF": 1,"direction": "forward","docsExamined": 0}
}
executionStats:执行过程统计,捕获计划在执行过程中的相关信息,只有在executionStats或allPlansExecution模式下才会输出。
执行命令db.game.find().explain('allPlansExecution');相比于db.game.find().explain('executionStats');,输出结果多一个allPlansExecution字段。
IndexFilter
queryPlanner.winningPlan.stage
queryPlanner.winningPlan.stage参数如下:
| 类型 | 描述 |
|---|---|
| COLLSCAN | 全表扫描 |
| IXSCAN | 索引扫描 |
| FETCH | 根据索引检索指定的文档 |
| SHARD_MERGE | 将各个分片的返回结果进行merge |
| SORT | 在内存中进行排序 |
| LIMIT | 使用limit限制返回结果数量 |
| SKIP | 使用skip进行跳过 |
| IDHACK | 针对_id字段进行查询 |
| SHANRDING_FILTER | 通过mongos对分片数据进行查询 |
| COUNT | 利用db.coll.explain().count()进行count运算 |
| COUNTSCAN | 不使用index进行count时 |
| COUNT_SCAN | 使用Index进行count时 |
| SUBPLA | 未使用到索引的$or查询的stage返回 |
| TEXT | 使用全文索引进行查询时候的stage返回 |
| PROJECTION | 限定返回字段时候stage的返回 |
缓存
一个查询操作可能对应多个不同的查询计划。无论是哪一种方式,都会先经过内部的评分机制进行评估,最终选出一个最优的执行方案。查询计划的评估必然会产生一定的计算开销。
MongoDB提供PlanCache用以实现查询计划缓存能力,可避免在一定条件内对同一个查询模型进行重复性的分析和评估工作。如果对于某个查询已经有了确定性的选择,查询优化器会直接做出选择,此时缓存并不会启用。
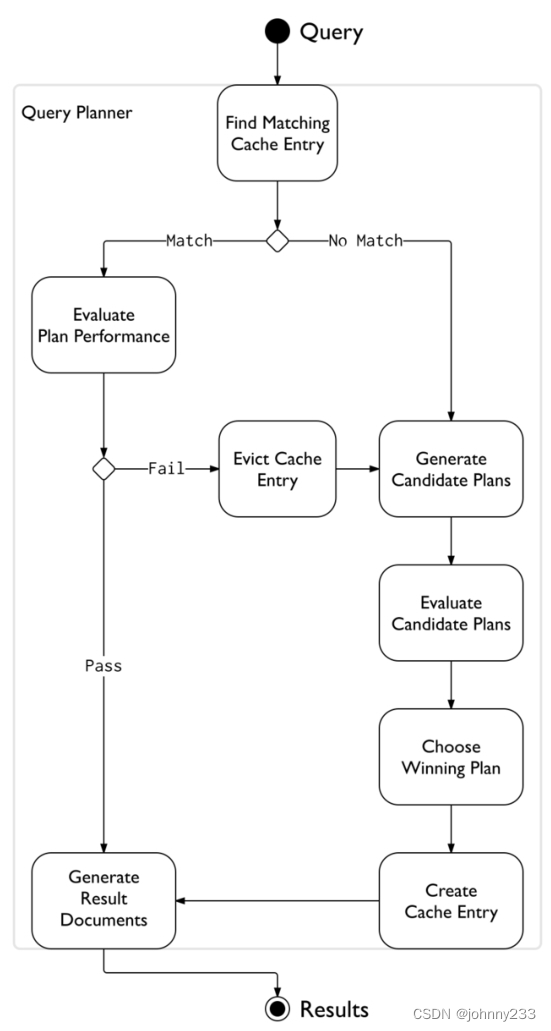
步骤解读:
- 查询开始执行,判断PlanCache中是否有对应的缓存。
- 如果没有缓存,则进入计划生成阶段,执行如下步骤:
- 分析查询语句与全部索引,产生候选计划。
- 评估查询计划,包括对计划的并发执行、采样。
- 选择最优的计划。
- 将计划存入缓存。
- 如果存在缓存,则触发replanning机制,评估查询性能,此时有两种结果:
- 查询性能不达标,淘汰缓存重新生成计划。
- 查询性能达标,采纳计划。
- 执行最终计划,返回结果。
查询模型(query shape)是对于当前查询场景的唯一性结构描述。查询优化器会首先将查询请求解析为某个查询模型,根据这个模型再进行计划缓存的查询。查询模型的组成包括以下3个部分:
- query:描述查询条件的结构,该结构由条件的字段、操作符(谓词)以及条件的嵌套关系组成,并不包含查询条件的具体值
- projection:描述即将返回哪些字段
- sort:描述排序的规则。
如果同时存在多个候选计划,那么需要根据一种评分机制从这些计划中选出一个最优计划,这就涉及计划的评优(evaluate)过程。
首先,让所有计划都同时执行一定量的扫描任务,扫描任务在满足以下条件时停止:
- 扫描次数达到numWorks次,
numWorks=Math.max(10000, 0.3×collection.count) - 返回结果达到numResults个,
numResults=Math.min(101, query.getN(), query.getLimit()),其中query.getN()来自getMore命令,query.getLimit()则只有限制limit条件才会出现。这两个参数只有存在时才会参与比较,否则numResults默认就是101。
为每个计划的执行情况打分,计算分数的因子来自下面几点:
- isEOF是否为true,如果出现isEOE则说明扫描的指针已经到达末尾。如果计划提前结束,则扫描会获得最大的机会。
- advance/workUnits(%),如果返回的结果数占扫描数的比例越大,则代表扫描效率越高。
是否存在以下低效率的阶段:
- PROJECTION+FETCH(非覆盖索引查询)
- SORT(内存排序)
- AND_HASH|STAGE_AND_SORTED(索引正交阶段)。
任意一种低效阶段的存在都会导致候选计划被扣分。
最后,根据所得分数进行排序,得分最高的计划被评选为最优计划并写入缓存。
对于已经缓存的计划,MongoDB仍会采用一种replaining的机制来保证其高效性。在返回缓存的计划之前,首先对该计划进行扫描采样,这次的采样数相比之前的numWorks会扩大10倍:
- 扫描过程中如果返回numResults个条目,或者到达EOF,则达到通过(pass)条件,此时仍然选用此计划。
- 如果超过采样数之后仍未达到通过条件,则转为失败(fail)状态,触发replain过程,此时将重新评选计划。
- 如果扫描过程中出错,则同样会变成失败状态,此时也会触发replain过程。
触发查询计划缓存清除的时机:
- 执行
PlanCache.clear方法。 - 创建、删除索引或者执行集合的drop操作。
- 重启MongoDB进程。
强制命中
在某些极少情况下,某些查询产生的最终计划可能并不是你想要的。事实上,想实现一个完美的查询计划是非常困难的,MongoDB在查询优化器上做了很多合理性方面的努力,如提供一些干预的手段。
hint方法实现对查询计划机制的干预,在查询计划中使用hint语句可以让MongoDB忽略查询优化器的结果,从而直接使用指定的索引。hint方法参数可以传入索引的定义对象,也可以是索引的名称。
IndexFilter方法也可以于预查询索引:
db.runCommand({planCacheSetFilter: "test",query: {a: 3, b: 4},index: [{b: 1}]}
)
执行planCacheSetFilter命令会在test集合中增加一个IndexFilter对象,该对象将会自动关联到同时包含a字段与b字段的等值查询,并引导查询优化器使用{b: 1}这个索引。
IndexFilter的优先级高于hint方法,如果查询优化器发现关联的IndexFilter,则一定会忽略hint语句。但是,IndexFilter并不能保证查询优化器最终一定会选择对应的索引,事实上优化器会将这些索引与全表扫描方式一并进行评估,再抉择出最终的结果。在最坏的情况下,如果指定不存在的索引,就会导致全表扫描。
IndexFilter是内存态的,重启MongoDB则会自动失效。另外,也可以使用planCacheClearFilters进行擦除。
参考
- MongoDB进阶与实战:微服务整合、性能优化、架构管理