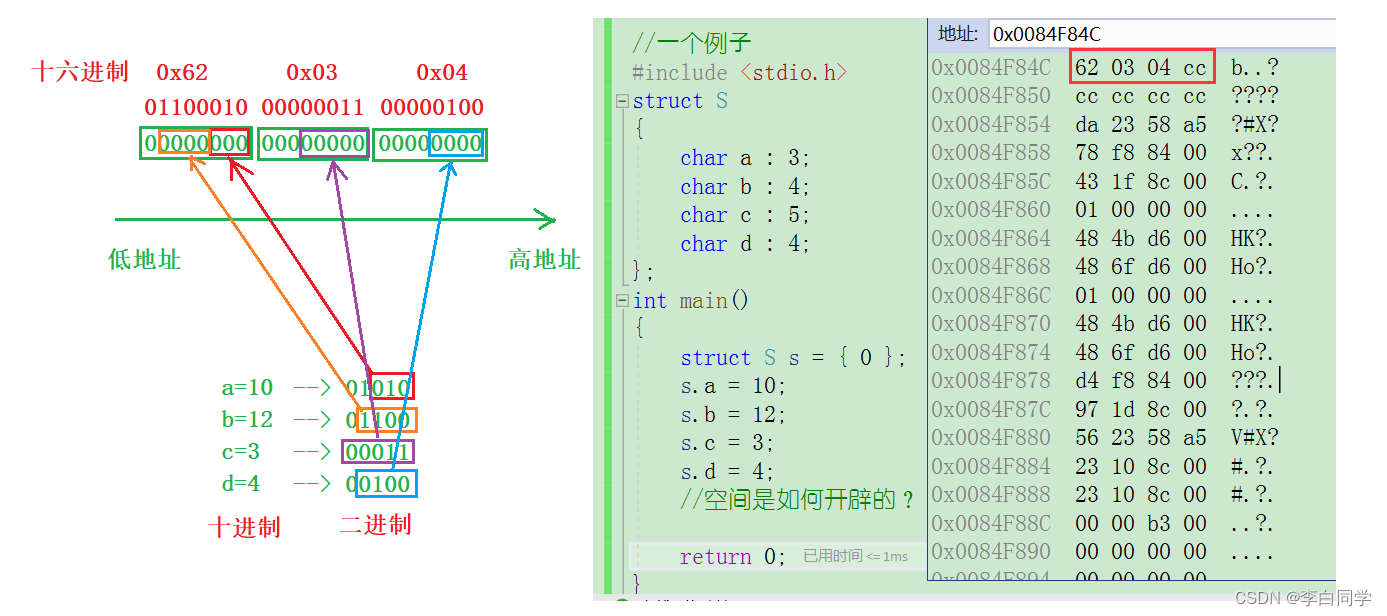
预备知识
RAG介绍一文搞懂大模型RAG应用(附实践案例) - 知乎 (zhihu.com)
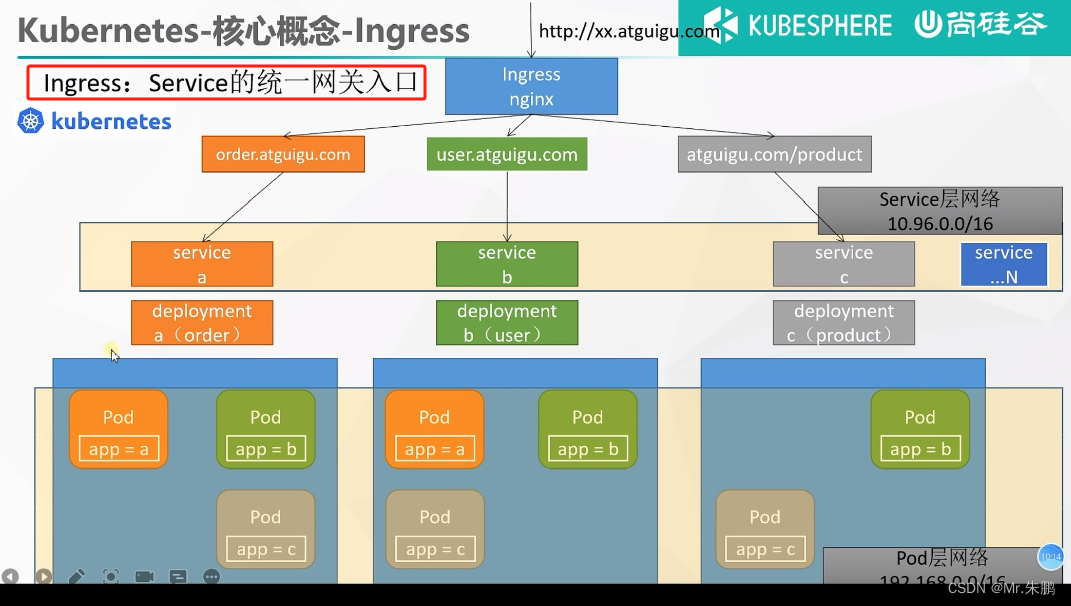
RAG的核心理解为“检索+生成”
检索:者主要是利用向量数据库的高效存储和检索能力,召回目标知识;
生成:利用大模型和Prompt工程,将召回的知识合理利用,生成目标答案
- 数据准备阶段:数据提取——>文本分割——>向量化(embedding)——>数据入库
- 应用阶段:用户提问——>数据检索(召回)——>注入Prompt——>LLM生成答案
- 总的来说,在数据准备时候加入doc入dataset,在提问阶段根据dataset检索出prompt进行答案生成
RATF与RAG区别(chatgpt)
-
目标:
- 检索增强微调旨在利用大规模检索到的文本数据来增强模型的微调过程。它的主要目标是通过利用外部知识源来提高模型在目标任务上的性能。
- 检索增强生成技术的目标是结合检索和生成两种技术,以生成与输入相关的连贯、准确的文本。它侧重于生成文本的质量和相关性。
-
方法:
- 检索增强微调通过将检索到的文本信息与目标任务的数据合并,然后在合并的数据集上进行模型微调。这种方法通常会使用一些特定的策略,例如数据蒸馏或伪标签生成,以更好地利用检索到的信息。(含有预训练过程)
- 检索增强生成技术将检索到的文本信息作为上下文,结合生成模型以生成文本。它通常不涉及对模型参数的微调,而是利用检索到的信息来指导生成过程。
零次学习(Zero-Shot Learning)
希望我们的模型能够对其从没见过的类别进行分类,让机器具有推理能力,实现真正的智能。其中零次(Zero-shot)是指对于要分类的类别对象,一次也不学习。
在训练阶段不存在与测试阶段完全相同的类别。
论文总结概括
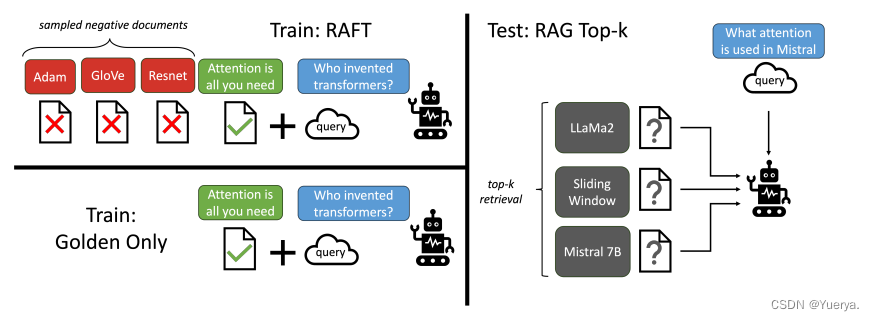
RAFT
在训练阶段加入该领域的doc进行ft,生成阶段LLM与一个检索器配对,该检索器可检索到‘k’文档(或文档的特定片段)并附加到提示符prompt中。
surpervised ft (SFT)
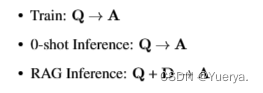
训练数据
每个数据点包含一个问题(Q),一组文档(Dk)和从其中一个文档(D∗)生成相应的思维链风格答案(A∗)---->Q、Dk、A*
文档分为两类:1. oracle(D*)可推断出问题答案的文档(可以为多个)
2.Di干扰文档
对于数据集:p%的数据 ---> 保存oracle文档和k-1个干扰文档
(1-p%)的数据--->仅包含干扰文档
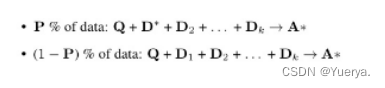
baseline:
1.zero-shot的Llama2-7b-chat,指令集微调模型,提供了书面的指令instruct,没有提供参考文档。
2.基于RAG的Llama2-7b-chat(LLM+RAG),多提供了参考文档。
3.zero-shot的(DSF)特定领域微调,没有上下文文档。
4.基于RAG特定领域微调(DSF+RAG),基于RAG微调模型储备外部知识。
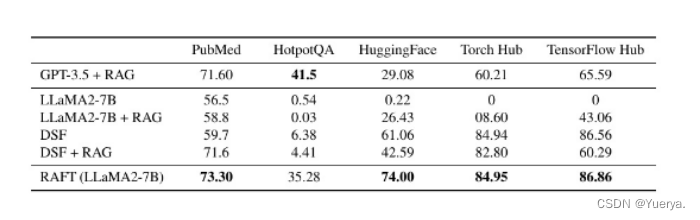
RAFT与基线对比:将RAG引入Domain Specific Fine-tuning(DSF)->模型缺乏上下文处理和从中提取有用信息的训练。(数据集干扰文档的处理上面)
CoT(Chain-of-Thought )
生成问题时,整合出一个推理链,丰富模型的理解,提高整体准确性,增强训练鲁班性 。

top-K RAG
注意与train时的p%dataset区分开,此时是测试时的场景!!
解决LLM的检索能力——>oracle文档与干扰文档混合——>完善相关和不相关文档的比例
微调方法:结合高度相关文档和干扰文档。该模型使用不同数量的干扰物文档进行训练,但始终使用从检索器中获得的top-k文档进行评估。
现象:仅使用oracle文档进行微调会导致性能更差