背景
vLLM是伯克利大学LMSYS组织开源的大语言模型高速推理框架,旨在极大地提升实时场景下的语言模型服务的吞吐与内存使用效率。vLLM是一个快速且易于使用的库,用于 LLM 推理和服务,可以和HuggingFace 无缝集成。vLLM利用了全新的注意力算法「PagedAttention」,有效地管理注意力键和值。在吞吐量方面,vLLM的性能比HuggingFace Transformers(HF)高出 24 倍,文本生成推理(TGI)高出3.5倍。

特点
1、PagedAttention
- LLM 的推理,最大的瓶颈在于显存。
- 自回归模型的 keys 和 values 通常被称为 KV cache,这些 tensors 会存在 GPU 的显存中,用于生成下一个 token。
- 这些 KV cache 都很大,并且大小是动态变化的,难以预测。已有的系统中,由于显存碎片和过度预留,浪费了60%-80%的显存。
实现:
- 受到操作系统中,虚拟内存和分页经典思想的启发
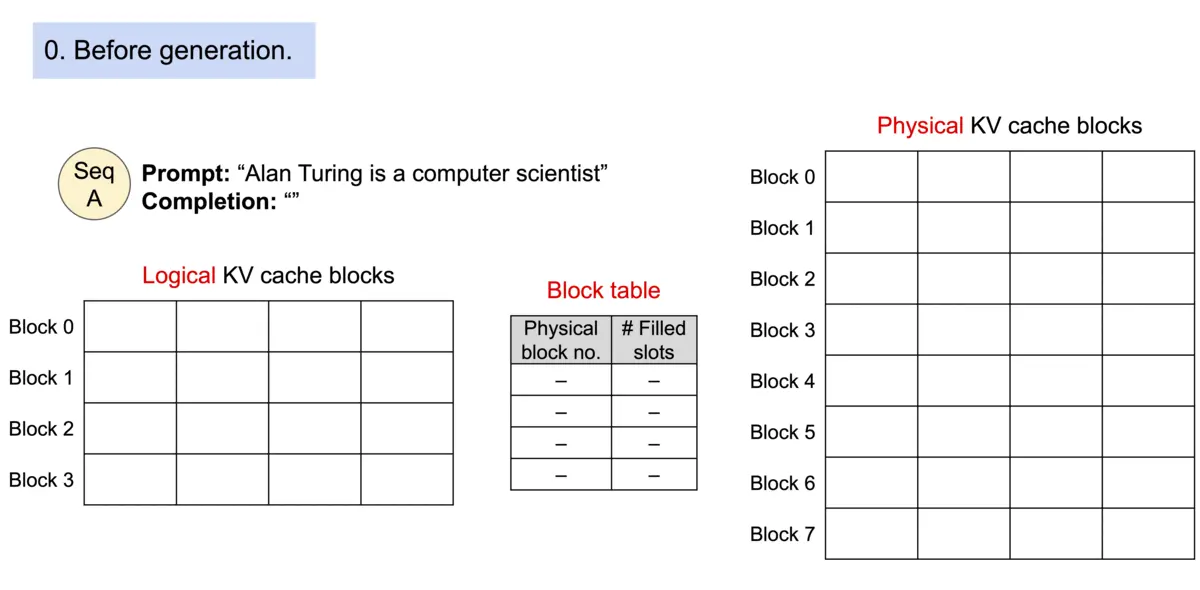
- PagedAttention 允许在不连续的内存空间中存储连续的 keys 和 values。 具体来说,PagedAttention 会将每个序列的 KV cache 划分为块,每个块包含固定数量 tokens 的 keys 和 values。 在注意力计算过程中,PagedAttention 内核有效地识别并获取这些块。
- 分块之后,这些 KV cache 不再需要连续的内存,从而可以像在操作系统的虚拟内存中一样,更灵活地对这些 KV cache 进行管理。
- PagedAttention 对于显存的利用接近理论上的最优值(浪费比例低于4%)。通过对显存进行更好的管理,可以使得单次可以使用更大的 batch size,从而进一步利用 GPU 的并行计算能力。
示意图:
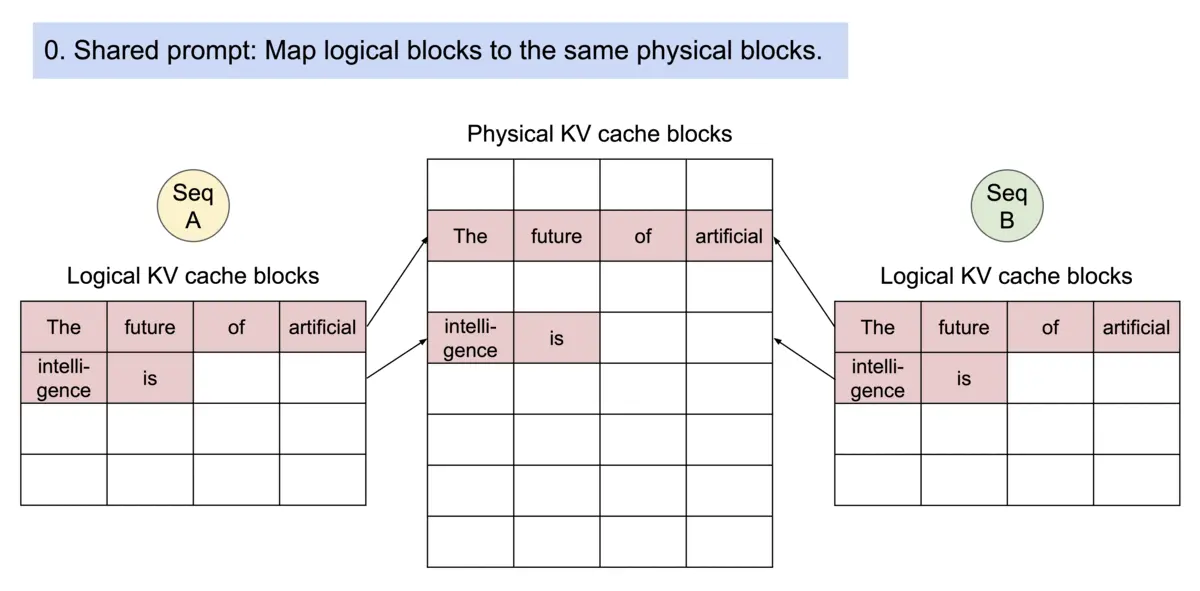
2、memory sharing
- memory sharing 是 PagedAttention 的另一个关键特性。
- 当用单个 prompt 产出多个不同的序列时,可以共享计算量和显存。
- 通过将不同序列的 logical blocks 映射到同一个 physical blocks,可以实现显存共享。
- 为了保证共享的安全性,对于 physical blocks 的引用次数进行统计,并实现了 Copy-on-Write 机制。
- 这种内存共享机制,可以大幅降低复杂采样算法对于显存的需求(最高可下降55%),从而可以提升2.2倍的吞吐量。
示意图:
应用场景
vLLM(Very Large Language Model)作为一种高速推理框架,在自然语言处理领域有着广泛的应用场景。下面是关于vLLM应用场景的详细描述:
-
文本生成: vLLM在文本生成领域具有突出的应用价值。通过大规模的语言模型,vLLM能够生成高质量、流畅的文本,包括文章、故事、诗歌等。这种能力在自动写作、创意生成、内容生成等应用场景中得到了广泛的应用。例如,可以利用vLLM来自动生成新闻报道、创作小说、生成广告文案等。
-
语言建模: vLLM可以用于语言建模任务,即根据给定的文本序列预测下一个单词或字符。通过大规模的预训练模型和高效的推理引擎,vLLM能够实现对语言的深层理解和建模,从而在语言模型评估、词语预测、句子生成等任务中取得良好的性能。语言建模在自然语言处理中是一个基础性的任务,对于机器翻译、语音识别、文本摘要等任务具有重要意义。
-
机器翻译: vLLM在机器翻译领域也有着重要的应用。通过将源语言句子输入到vLLM中,再利用其生成的特征向量或上下文表示,可以实现高质量的机器翻译。vLLM能够学习源语言和目标语言之间的语义关系,并生成准确、流畅的翻译结果。这种能力对于跨语言沟通、跨文化交流等具有重要意义。
-
问答系统: 在问答系统中,vLLM可以用于自动回答用户提出的问题。通过理解问题的语义和上下文,vLLM能够生成准确、详细的回答。这种能力对于智能客服、虚拟助手、智能搜索等应用场景具有重要意义。vLLM可以帮助用户快速获取所需信息,并提高用户体验和工作效率。
-
情感分析: vLLM可以用于情感分析任务,即对文本的情感色彩进行判断和分类。通过学习大量的情感标注数据和情感相关的语义信息,vLLM能够识别文本中蕴含的情感倾向,并进行情感分类。这种能力在舆情监控、社交媒体分析、产品评论分析等领域具有重要意义,可以帮助企业和组织了解用户的情感态度和需求。
总的来说,vLLM作为一种高效的语言模型推理框架,具有广泛的应用场景,涵盖了文本生成、语言建模、机器翻译、问答系统、情感分析等多个领域。其强大的能力和灵活性使其成为自然语言处理领域的重要工具,为各种语言相关任务提供了高效、准确的解决方案。
安装使用
安装命令:
pip3 install vllm
本文使用的Python第三方模块的版本如下:
vllm==0.2.7
transformers==4.36.2
requests==2.31.0
gradio==4.14.0vLLM初步使用
线下批量推理
线下批量推理:为输入的prompts列表,使用vLLM生成答案
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "6,7"from vllm import LLM, SamplingParamsllm = LLM('/data-ai/model/llama2/llama2_hf/Llama-2-13b-chat-hf')INFO 01-18 08:13:26 llm_engine.py:70] Initializing an LLM engine with config: model='/data-ai/model/llama2/llama2_hf/Llama-2-13b-chat-hf', tokenizer='/data-ai/model/llama2/llama2_hf/Llama-2-13b-chat-hf', tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.float16, max_seq_len=4096, download_dir=None, load_format=auto, tensor_parallel_size=1, quantization=None, enforce_eager=False, seed=0)
INFO 01-18 08:13:37 llm_engine.py:275] # GPU blocks: 3418, # CPU blocks: 327
INFO 01-18 08:13:39 model_runner.py:501] Capturing the model for CUDA graphs. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce