声明:以下内容均属于本人本科论文内容,禁止盗用,否则将追究相关责任
基于深度学习的面部情绪识别算法仿真与分析
- 摘要
- 结果分析
- 1、本次设计通过网络爬虫技术获取了七种面部情绪图片:吃惊、恐惧、厌恶、高兴、伤心、愤怒、自然各若干张,图4.1是获取的部分原始网络图片示例(以厌恶情绪为例)。
- 2、数据的预处理
- 4.2 MTCNN算法仿真
- 1、数据集选择
- 2、仿真结果
- 4.3 面部情绪识别算法仿真
- 4.4 算法性能分析
- 4.4.1 FERA-C算法在自制数据集上的loss、acc分析
- 4.4.2 FERA-C算法在自制数据集上的混淆矩阵分析
- 4.4.3 CK+数据集上的算法对比分析
摘要
面部情绪是人们表达情感的直观画板,随着当代社会计算机视觉领域的不断发展,面部情绪识别已经成为图像识别领域的研究热点,在智能驾驶、智慧医疗、市场营销等公共领域有极大的应用价值。基于机器学习的传统面部情绪识别算法存在特征提取困难、泛化性能不好、训练样本过大、对噪声和变形敏感等劣势。相比之下,基于深度学习的面部情绪识别算法可以自动学习图像特征,并具有更好的泛化能力和鲁棒性。
本次设计结合深度学习中的人脸检测方法和图像识别方法,提出了一种将经典人脸检测算法MTCNN和加入混合注意力机制CBAM的残差神经网络组合起来的面部情绪识别算法,并且进行模型裁剪操作来减小模型参数计算量。主要从人脸检测、面部情绪识别分类、算法对比三个阶段来完成面部情绪识别算法总体设计。
第一个阶段采用经典人脸检测模型MTCNN训练出人脸检测模型权重,并进行人脸检测和人脸关键点的提取验证。第二个阶段在制作完成的七种面部情绪数据集上进行面部情绪识别模型的训练,调用训练权重及人脸检测权重进行图片、视频检测。通过损失率、准确率以及混淆矩阵统计识别结果,进行算法性能分析。最后与残差神经网络模型ResNet和通道注意力模型SENet进行模型性能对比。
仿真结果表明,设计的组合算法在算法整体评价中取得了不错的效果,验证了本次设计提出的组合算法的合理性和可行性。
关键词:卷积神经网络;混合注意力机制;残差结构;人脸检测;面部情绪
结果分析
1、本次设计通过网络爬虫技术获取了七种面部情绪图片:吃惊、恐惧、厌恶、高兴、伤心、愤怒、自然各若干张,图4.1是获取的部分原始网络图片示例(以厌恶情绪为例)。
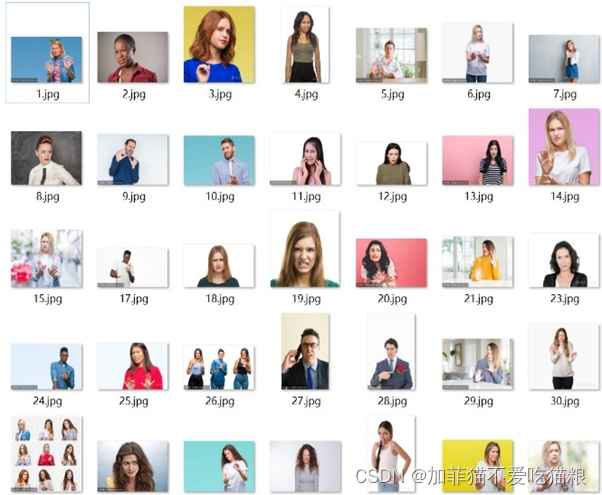
图 4.1 “厌恶”原始图片
通过网络获取的原始图片存在大小不一、肢体遮挡、表情图片混入等问题,需要进行数据的第一次清洗去除以上提到的不符合要求的图片。
2、数据的预处理
获取到原始数据集后,考虑到后期面部情绪识别模型主要是针对面部情绪进行训练,为了尽可能减小面部之外的其他人体部位对模型训练的影响,需要对原始数据图片进行人脸裁剪操作,完成数据集归一化处理,并再次进行数据集清洗,去除裁剪不到位和面部遮挡严重的图片,图4.2是数据预处理后得到的部分数据集展示(以厌恶情绪为例)。

图 4.2 数据预处理后的“厌恶”图片
以上图片都设置成100*100的图像大小,七种面部情绪以此为基准依次操作,经过数据增强最终制作出每类1500张的数据集。
4.2 MTCNN算法仿真
由于本次设计重心在于面部情绪识别分类算法的设计,MTCNN人脸检测算法不作为算法设计详细介绍的重点,在算法仿真阶段进行调用即可。在第二章的第二小节已经对MTCNN算法原理进行了阐述,并且在第三章算法设计中明确了MTCNN算法流程,本章节不再过多叙述。
1、数据集选择
为了生成的人脸检测权重更加精确,选择WIDER FACE数据集作为MTCNN模型训练的数据集,WIDER FACE数据集包含32,203个图片,其中有128,80张用作训练,6,971张用作验证,6,946张用作测试。数据集中的图片来自于各种实际场景,包括社交场合、视频剪辑、电视截图、名人图片等,具有大量的姿态、遮挡和背景变化,是一个比较具有挑战性的数据集。
2、仿真结果
由MTCNN算法流程可知要依次进行P-Net、R-Net、O-Net的训练,最终完成人脸和面部关键点的检测,保存生成的P-Net、R-Net、O-Net模型训练的权重以便后期面部情绪识别仿真阶段进行权重调用。图4.3是MTCNN在图片上的仿真验证。

图4.3 人脸及关键点图片仿真
在仿真时会首先生成图片中人脸框的左上角和右下角的位置信息以及人脸框置信度,同时生成人脸五个关键点的位置信息,如果图片是非人脸则会返回image not have face的提示。用实时摄像头进行仿真,输出结果与图片仿真一致。
4.3 面部情绪识别算法仿真
通过训练权重在面部情绪识别仿真阶段的调用可以得到仿真结果。图4.4是仿真阶段总体设计流程图。
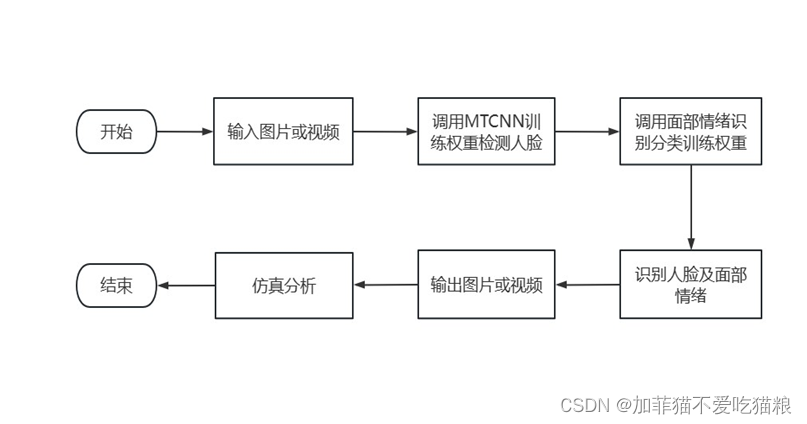
图4.4 仿真整体流程
图4.5是面部情绪识别模型在图片上的仿真结果展示,可以看出其能够识别人脸情绪,并标注人脸五个关键点,同时也存在个别情绪识别不准确的情况。
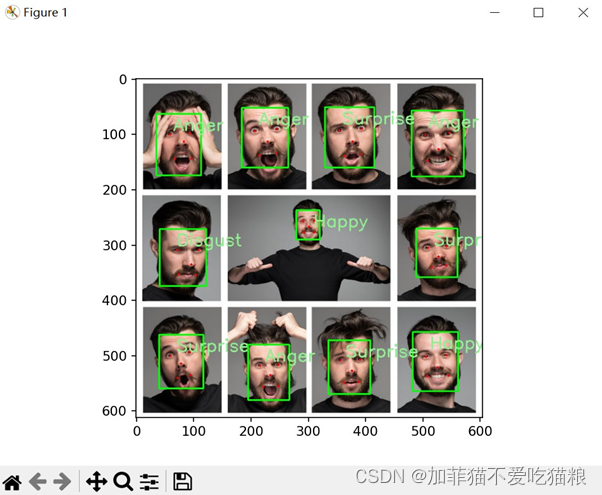
图4.5 面部情绪识别图片仿真
图4.6是面部情绪识别模型在视频中的仿真结果

图4.6 面部情绪识别视频仿真
4.4 算法性能分析
4.4.1 FERA-C算法在自制数据集上的loss、acc分析
图4.7是FERA-C模型在自制数据集上的训练结果展示。
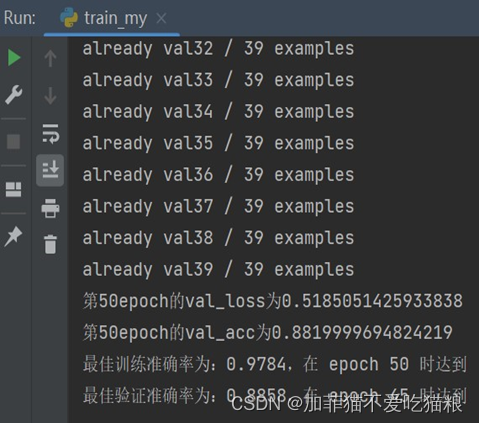
图4.7 FERA-C模型在自制数据集上的训练结果
图4.8是FERA-C模型在自制数据集上训练得到的loss变化过程。
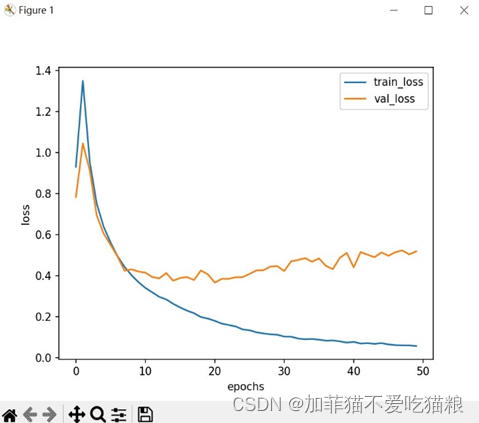
图4.8 FERA-C在自制数据集上的loss变化
由于模型学到了一些数据集的简单特征,导致train_loss和val_loss前期出现转折,后期模型学到更复杂的特征后,两者变化趋于稳定,但切合度较低。
图4.9是FERA-C模型在自制数据集上训练得到的acc变化过程。
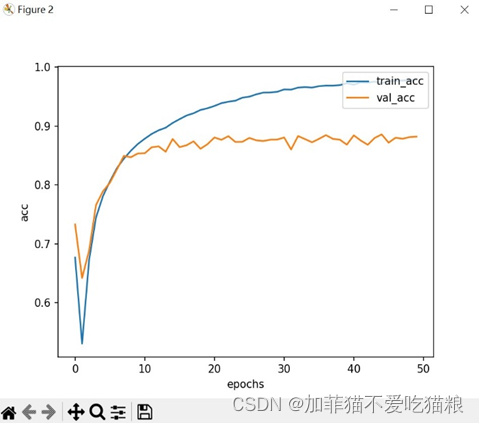
图4.9 FERA-C在自制数据集上的acc变化
从上图可以看出自制数据集在训练集上的准确率较高且acc变化平滑,但数据集在验证集上的准确率较低,变化波动较为平滑,前期acc转折与自制数据集上loss转折一致。
根据对面部情绪识别算法和训练模型模块的分析,以下问题是导致训练集和验证集在模型训练时loss、acc变化曲线不紧密的一般原因,每一个原因在经过分析后都给出了合理推测。
(1)数据集过小
当数据集较小时,模型会对训练集过拟合,不能很好地泛化到未知数据上,从而导致验证集上的损失波动较大。
自制数据集是每类1500张,总量为10500。其中训练集8400张,验证集2100张,由于在模型训练过程中进行了一定的数据增强,所以数据集过小导致训练集和验证集的loss和acc变化曲线不紧密的可能性较小,后续在算法对比阶段会使用CK+公开数据集进行验证。
(2)模型复杂度较高
过于复杂的模型会更容易对训练集过拟合。当模型过于复杂时,它很可能会在训练集上表现得很好,但在验证集上表现不佳。
本次设计使用的面部情绪识别算法FERA-C主要由残差块、混合注意力机制、基本卷积结构构成,为了避免出现模型复杂度高、参数计算量大的问题,对模型进行了裁剪处理,通过训练得到的权重大小可知此类原因导致训练集和验证集的loss、acc变化曲线不紧密依旧不成立。
(3)学习率过高
学习率过高可能导致模型参数更新过于快速,容易跳过最优解,从而使验证集准确率和损失值跟不上训练集的变化。
本次设计中,在训练模型时,为了获得合适的精确度,设置了不同学习率进行训练,从0.001到0.01不等,实验分析表明0.001较为适合,学习率过高不是导致出现上述训练问题的原因。
(4)训练次数不足
当训练次数不足时,模型可能没有充分收敛,使得验证集上的损失表现波动较大。
在模型训练阶段,将模型训练轮次设置成50轮,batch_size设置为16,通过loss和acc变化可知训练轮次已经达到训练稳定阶段,因此此类原因同样不成立。
(5)数据集缺少代表性
如果数据集缺少代表性,比如数据分布与实际情况有较大出入,则会导致模型对数据集过拟合,进而导致验证集上的损失波动较大,验证集准确率与训练集准确率相差较大。
通过对数据集的仔细分析,发现数据集中存在背景色彩差异度较大、面部化妆严重、不同类数据辨识度较低等问题,此类原因导致出现上述问题较为符合实际情况。
4.4.2 FERA-C算法在自制数据集上的混淆矩阵分析
通过混淆矩阵可以分析单一类别在验证集上的准确率,因为本次设计是七分类问题,故混淆矩阵是7*7的方阵,图4.10是通过自制数据集中的验证集调用面部情绪识别模型训练权重画出的混淆矩阵。
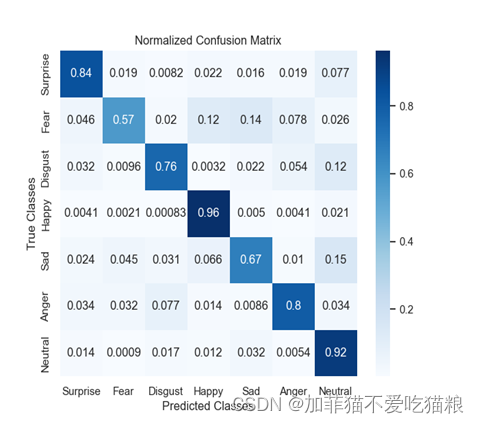
图4.10 FERA-C算法在自制数据集上的混淆矩阵
通过上图混淆矩阵可以看出七类面部情绪中,只有fear类与sad类的验证准确率较低,主要原因是两类数据集与其他类数据集区分程度较低。
4.4.3 CK+数据集上的算法对比分析
在算法对比阶段,为了验证模型效果,统一采用公开数据集CK+来进行模型训练。由于在设计FERA-C模型结构时参考了ResNet残差结构并使用了CBAM模块,故选择经典卷积神经网络中的ResNet模型和SENet模型来进行算法对比分析。
(1)ResNet模型
ResNet是一种深度卷积神经网络,通过残差块(Residual Block)连接来实现网络的深度。在传统卷积神经网络中,随着网络的加深,出现了梯度爆炸和梯度消失问题。为了解决这些问题,ResNet提出了残差学习的概念,即通过将恒等映射添加到残差块的输出路径上,这使得ResNet可以比传统卷积神经网络更深,并具有更高的准确率。
(2)SENet模型
SENet是一种用于神经网络的注意力机制模型,其核心思想是通过增强网络的注意力机制来提高网络的表现和泛化能力。
SENet模型的通道注意力机制由两个操作组成:Squeeze操作和Excitation操作。Squeeze操作通过使用全局平均池化操作将每个通道的特征压缩成一个数值,然后使用一个非线性激活函数对该数值进行激活,以获得该通道的重要性权重。Excitation操作通过使用一个全连接层对这些权重进行线性变换,并使用Sigmoid函数对变换结果进行激活,从而得到该通道的注意力权重。通过将这些注意力权重乘以原始的特征图,SENet模型可以加强网络对重要的特征信息的关注,提高网络的表现和泛化能力。
(3)CK+数据集
CK+数据集是在 CK数据集的基础上扩展来的,其数据集单张图片大小皆为48*48尺寸的黑白图像,图4.11是CK+数据集部分展示,这个数据集是人脸表情识别中比较流行的一个数据集。
图4.11 CK+数据集
三种模型训练时的超参数保持一致,训练轮次设置为100轮、batch_size设置为16、优化器选择Adam、学习率设置为0.001。三种模型在CK+数据集上分别进行模型训练,并对比模型效果参数,验证设计的FERA-C模型的可行性和合理性。
图4.12是FERA-C模型在CK+数据集上的loss变化。
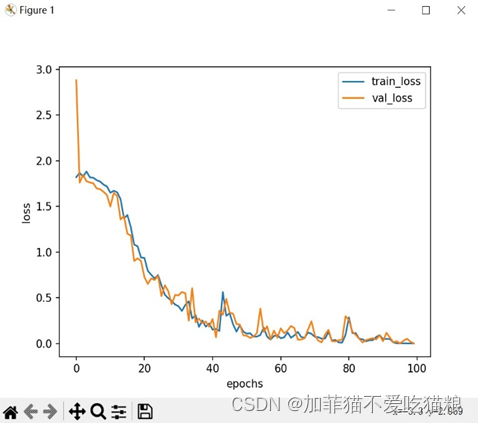
图4.12 FERA-C在CK+数据集上的loss变化
通过上图可知FERA-C模型在CK+数据集上训练得到的train_loss和val_loss变化曲线较为紧密,上一小节中的推测成立。
图4.13是FERA-C模型在CK+数据集上训练得到的acc变化结果。
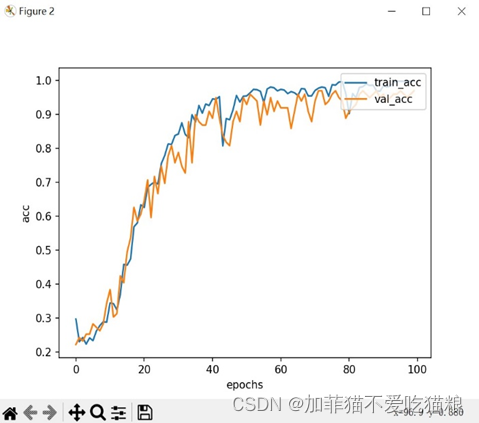
图4.13 FERA-C在CK+数据集上的acc变化
通过上图可以看出FERA-C模型在CK+数据集上的训练集准确度与验证集准确度十分接近,证明模型没有出现过拟合或欠拟合风险。图4.14是FERA-C模型训练100轮所用的训练总时间以及最高train_acc和val_acc结果显示。
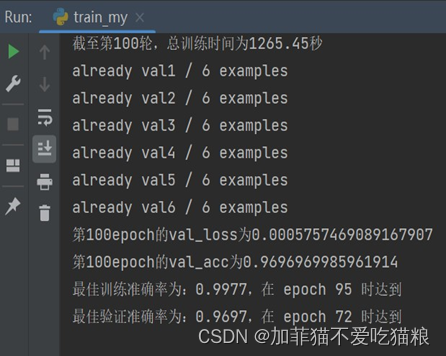
图4.14 FERA-C在CK+数据集上的训练结果
通过上图可以看出,FERA-C模型训练在第95轮获得最佳训练准确率:0.9977,在第72轮获得最佳验证准确率:0.9697,总训练时间1265.45s。
图4.15是ResNet模型在CK+数据集上训练得到的loss变化。
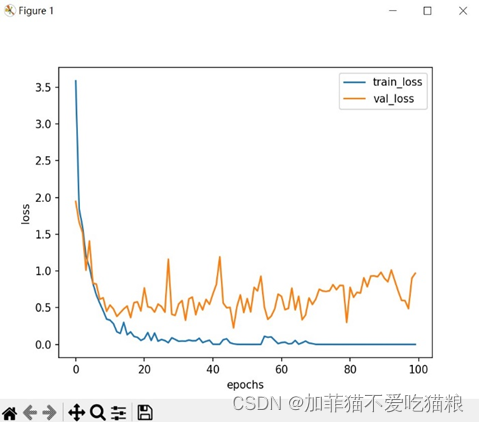
图4.15 ResNet在CK+数据集上的loss变化
通过上图可以看出ResNet在CK+数据集上训练得到的train_loss和val_loss变化曲线同样较为紧密,图4.16是ResNet模型在CK+数据集上训练得到的acc变化。
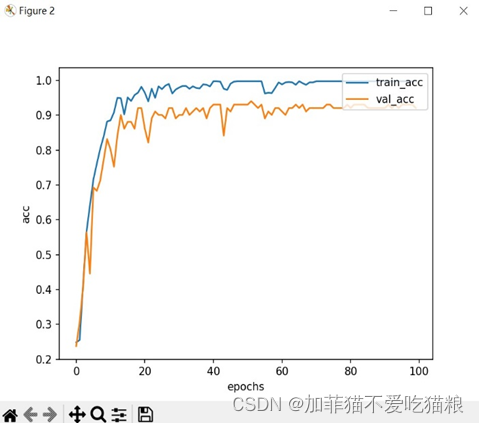
图4.16 ResNet在CK+数据集上的acc变化
通过上图可以看出ResNet在CK+数据集上的acc变化符合loss变化。图4.17是ResNet模型训练100轮所用的训练总时间以及最高train_acc和val_acc结果显示。
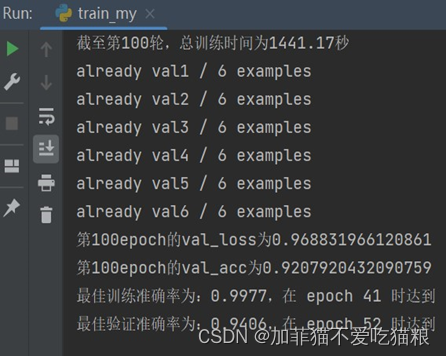
图4.17 ResNet在CK+数据集上的训练结果
通过上图可以看出,ResNet模型训练在第41轮获得最佳训练准确率:0.9977,在第52轮获得最佳验证准确率:0.9406,总训练时间1441.17s。
图4.18是SENet模型在CK+数据集上训练得到的loss变化。
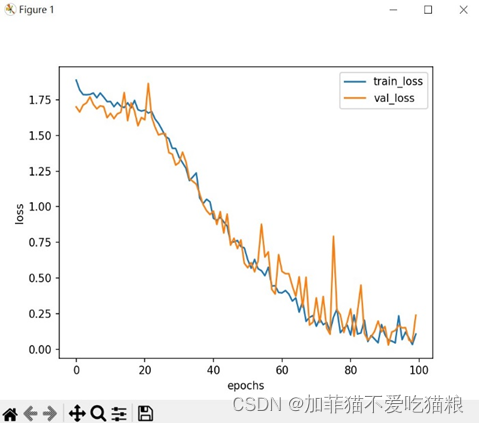
图4.18 SENet在CK+数据集上的loss变化
通过上图可以看出SENet模型在CK+数据集上得到的train_loss和val_loss并行变化。图4.19是SENet模型在CK+数据集上训练得到的acc变化。
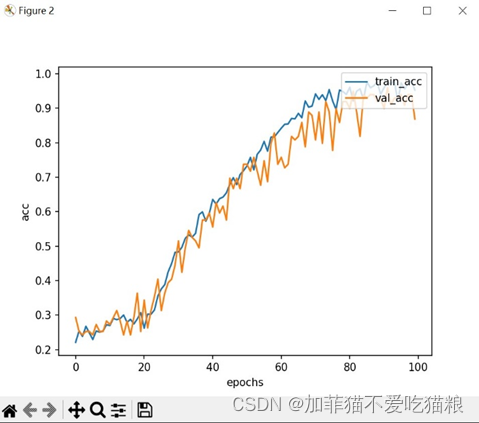
图4.19 SENet在CK+数据集上的acc变化
通过上图可以看出SENet模型在CK+数据集上训练得到的train_acc和val_acc并行变化,在80轮附近趋于稳定。图4.20是SENet模型在CK+数据集上的训练结果。
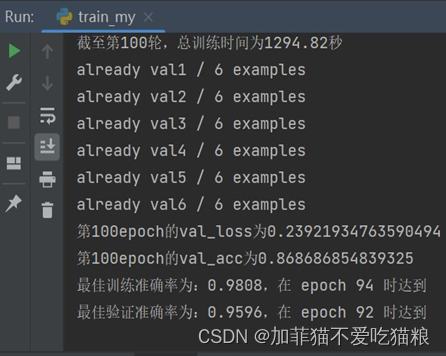
图4.20 SENet在CK+数据集上的训练结果
通过上图可以看出,SENet模型训练在第94轮获得最佳训练准确率:0.9808,在第92轮获得最佳验证准确率:0.9596,总训练时间1294.82s。
(4)整体对比总结
三种模型对比分析如表4.1表述

在对比分析阶段,由于ResNet模型网络深度较深,硬件处理设备无法符合实验要求,故选择三种模型在统一浅层卷积数量中训练。
通过上表可知三种模型在CK+数据集上的最好验证集准确率分别是0.9697、0.9406、0.9596,FERA-C模型在验证集上的最高准确率略高于另外两种模型,由于FERA-C设计时使用了模型裁剪技术减小了参数计算量,故FERA-C模型的总训练时间不算太长,SENet模型作为ResNet模型的升级版,其总训练时间比ResNet模型总训练时间短。