目录
一、资源配置
二、主从同步基本原理:
1、具体步骤:
2、数据库是靠什么同步的?
3、pos与GTID的区别?
三、配置一主两从
(1)为主库和从库创建复制账户, 分别在主从库上执行如下命令:
(2)配置主库:
2.1 设置mysql Binlog日志保留时长配置&删除方法
(3)重启主库mysql服务并登录
(4)配置从库
4.1、设置mysql 从库 中继日志relay log 日志保留时长
四、MySQL主从测试
五、基于GTID的MySQL主从数据库复制
1、GTID的概念
2、为什么要有GTID
3、GTID优缺点
4、GTID的组成
5、GTID的工作原理
6、配置基于GTID的MySQL主从数据复制
1、配置主库
2、配置从库
3、测试
一、资源配置
主库:192.168.134.132
从库:192.168.134.133
从库:192.168.134.134
二、主从同步基本原理:
master用户写入数据,会生成event记录到binary log中,slave会从master读取binlog来进行数据同步;
1、具体步骤:
- master将数据改变记录到二进制binlog中;
- slave上执行start slave 命令后,slave会创建一个IO线程,用来连接master,请求master中的binlog;
- 当slave连接master时,master会创建一个log dump线程,用于发送binlog内容。在读取binlog的内容的操作中,会对主节点上的binlog加锁,当读取完成并且发送给从服务器后解锁;
- IO线程接受主节点发送过来的更新后,保存到中继日志relay log 中;
- slave的sql线程,读取relay log日志,并解析成具体的操作,从而实现主从操作一致,最终数据一致。
2、数据库是靠什么同步的?
主从复制,默认是通过pos复制(postion),就是说在日志文档里,将用户的每一项操作都进行了编号(pos),每一个event都有一个起始号,一个终止编号,配置主从复制时候,从节点要输入master的log_pos值,就是这个原因,要求它从哪个pos开始同步数据库里的数据,这也是传统的复制技术。
MySQL5.6以后,增加了GTID复制 GTID就类似pos的一个作用,不过它是整个mysql复制结构全局通用的,就是说在整个mysql冗余架构中,它们的日志文件里时间的GTID值是一致的。
3、pos与GTID的区别?
两者都是日志文件里事件的一个标志,如果将整个mysql集群看作一个整体,pos就是局部的,GTID就是全局的。
三、配置一主两从
(1)为主库和从库创建复制账户, 分别在主从库上执行如下命令:
mysql -uroot -p
mysql> create user 'repl'@'%' identified by '123456';
mysql> GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'repl'@'%';
mysql> ALTER USER 'repl'@'%' IDENTIFIED WITH mysql_native_password BY '123456';(2)配置主库:
开启主库的二进制日志功能、 定义主库的 server-id,并设置mysql Binlog日志保留时长配置&删除方法
vim /etc/my.cnf
在[mysqld]标签下添加如下内容:
log-bin=mysql-bin
server_id =1# 主从同步时,需要同步的数据库,多个数据库写多行binlog_do_db配置
# binlog_do_db=test_db
# binlog_do_db=test_db2
#主从同步时,不需要同步的数据库,多个数据库写多行binlog_ignore_db配置
# binlog_ignore_db=mysql
# binlog_ignore_db=information_schema
# binlog_ignore_db=sys
# binlog_ignore_db=performance_schema
#做双主时,每台数据库都可能在同一个表中插入数据,如果表有一个自动增长的主键,那么就会在多服务器上出现主键冲突;解决方案是让每个数据库的自增主键不连续;
#参数auto_increment_increment表示自增值,一般有n台主库,自增值就采用n;#auto_increment_offset表示起始序号,一般offset不超过自增值,且各主库的自增值不一样.
# auto_increment_increment = 2
# auto_increment_offset = 12.1 设置mysql Binlog日志保留时长配置&删除方法
当开启mysql数据库主从时,会产生大量如mysql-bin.00000*log 的文件,这会大大耗费磁盘空间
binlog日志文件只对 增删改有记录,查询操作是没有记录的
二进制日志文件,MySql8.0默认已经开启,低版本的MySql需要通过配置文件开启,并配置MySql日志格式,Linux系统:my.cnf1、查看是否开启binlog
mysql> show variables like '%log_bin%';
+---------------------------------+--------------------------------+
| Variable_name | Value |
+---------------------------------+--------------------------------+
| log_bin | ON on=启用,off=未启用 |
| log_bin_basename | /var/lib/mysql/mysql-bin |
| log_bin_index | /var/lib/mysql/mysql-bin.index |
| log_bin_trust_function_creators | OFF |
| log_bin_use_v1_row_events | OFF |
| sql_log_bin | ON |
-------------------------------------<永久有效>方式 - 配置文件 -mysql 8.0 以下版本适用,因为在8.0开始expire_logs_days 废弃 启用binlog_expire_logs_seconds设置binlog自动清除日志时间 ;方式 1:
先关闭mysql主从,
在/etc/my.cnf文件中的[mysqld]模块下, 新增如下参数:
expire_logs_days=7
这样设置将永久有效,但需重启mysqld服务才会生效.
说明:0-表示永不过期, 单位为天。
重启后, 再手工将(/var/lib/mysql/)目录下的N天前的"mysql-bin.000数字" 文件删除.方式 2:不用重启数据库
登录到mysql数据库中,执行:
set global expire_logs_days=7;
这样设置后, 后续的文件将按该策略进行滚动删除;
但如果删除之前的文件(如删除7天前的mysql-bin binlog 文件), 还需执行如下操作:
mysql> PURGE MASTER LOGS BEFORE DATE_SUB(CURRENT_DATE, INTERVAL 7 DAY);- - - - - - -MySQL 8.0 以上版本,
查看当前数据库日志binlog保存时效 以秒为单位 默认为2592000 30天,
-- 14400 4小时;86400 1天;259200 3天;
mysql> show variables like "%binlog_expire_logs_seconds%";
+----------------------------+---------+
| Variable_name | Value |
+----------------------------+---------+
| binlog_expire_logs_seconds | 2592000 |
+----------------------------+---------+
1 row in set (0.00 sec)
先关闭主从,修改配置文件my.cnf
添加
binlog_expire_logs_seconds=259200
重启数据库生效,或者通过命令修改,再此不做演示。
(3)重启主库mysql服务并登录
service mysqld restartmysql -uroot -p
mysql> show master status; 
(4)配置从库
vim /etc/my.cnf
在[mysqld]标签下添加如下内容:
server_id=2
relay_log=/var/lib/mysql/mysql-relay-bin
read_only=1
重启从库mysql服务
service mysqld restart因为从库为了保证数据的一致性,从库是不允许写数据的,建议在从库执行
set global read_only= 1; //设置为只读,但是root 超级用户是可以的
set global read_only=0; --命令来将服务器设置为可写模式。
set global super_read_omly =1; //超级用户也无法进行 写的操作4.1、设置mysql 从库 中继日志relay log 日志保留时长
1、查看日志相关参数
mysql> show variables like '%relay%';
+---------------------------+--------------------------------------+
| Variable_name | Value |
+---------------------------+--------------------------------------+
| max_relay_log_size | 0 |
| relay_log | /var/lib/mysql/mysql-relay-bin |
| relay_log_basename | /var/lib/mysql/mysql-relay-bin |
| relay_log_index | /var/lib/mysql/mysql-relay-bin.index |
| relay_log_info_file | relay-log.info |
| relay_log_info_repository | TABLE |
| relay_log_purge | OFF |
| relay_log_recovery | OFF |
| relay_log_space_limit | 0 |
| sync_relay_log | 10000 |
| sync_relay_log_info | 10000 |
+---------------------------+--------------------------------------+2、参数详解max_relay_log_size #标记relay log允许的最大值,如果该值为0,则默认值为max_binlog_size(1G);如果不为0,则max_relay_log_size则为最大的relay_log文件大小。relay_log #定义relay_log的位置和名称,如果值为空,则默认位置在数据文件的目录(datadir),文件名默认为host_name-relay-bin.nnnnnn。relay_log_basename #
relay_log_index #同relay_log,定义relay_log的位置和名称;一般和relay-log在同一目录。relay_log_info_file #设置relay-log.info的位置和名称(relay-log.info记录MASTER的binary_log的恢复位置和relay_log的位置)relay_log_purge #是否自动清空不再需要中继日志时。默认值为1(启用)。relay_log_recovery #当slave从库宕机后,假如relay-log损坏了,导致一部分中继日志没有处理,则自动放弃所有未执行的relay-log,并且重新从master上获取日志,这样就保证了relay-log的完整性。默认情况下该功能是关闭的,将relay_log_recovery的值设置为1时,可在slave从库上开启该功能,建议开启。relay_log_space_limit #防止中继日志写满磁盘,这里设置中继日志最大限额。注意,但此设置存在主库崩溃,从库中继日志不全的情况,不到万不得已,不推荐使用!sync_relay_log #这个参数和sync_binlog是一样的,当设置为1时,slave的I/O线程每次接收到master发送过来的binlog日志都要写入系统缓冲区,然后刷入relay log中继日志里,这样是最安全的,因为在崩溃的时候,你最多会丢失一个事务,但会造成磁盘的大量I/O。当设置为0时,并不是马上就刷入中继日志里,而是由操作系统决定何时来写入,虽然安全性降低了,但减少了大量的磁盘I/O操作。这个值默认是0,可动态修改,建议采用默认值。sync_relay_log_info:#这个参数和sync_relay_log参数一样,3、设置,可以通过命令或者配置文件的方式设置自动清空不在需要的中继日志3.1 通过命令设置 1:表示开启,0:表示关闭set global relay_log_purge=1;
flush logs;3.2 通过修改my.cnf配置文件,永久生效
# 设置保留最近5个历史日志文件
relay_log_purge=ON
relay_log_purge_reuse=5
修改完,重启数据库生效(5)启动复制:
登陆从库 mysql 服务,使用 change master to 语句来启动复制,即告诉从库如何连接到主库。
mysql -uroot -p
先关闭从库的slave服务
mysql> stop slave;
执行 change master to 语句:
change master to master_host='192.168.134.132',master_user='repl',master_password='123456',master_log_file='mysql-bin.000087',
master_log_pos=155;(取决于master的 Position)
检查复制是否正确执行:
mysql> show slave status\G;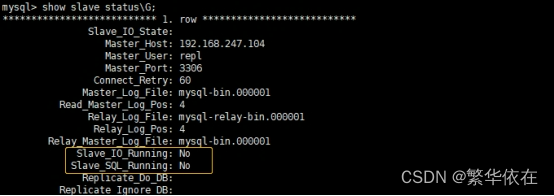
Slave_IO_State、 Slave_IO_Running、 Slave_SQL_Running 这三列显示
当前备库复制尚未运行。
运行如下命令开始复制
mysql> start slave;
mysql> show slave status\G; 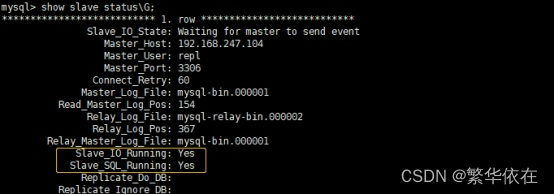
注意:两个yes则表示成功配置主从复制,Connection和No都是配置有问题
四、MySQL主从测试
主从数据同步验证
登录主库
mysql -uroot -pmysql> show databases;mysql> create database db_test;

登录从库查看
mysql -uroot -p
mysql> show databases;
五、基于GTID的MySQL主从数据库复制
1、GTID的概念
mysql 的GTID是mysql复制中引入的全局事务标识机制,用于唯一标识每个事物。不仅在主库上时唯一的,在集群中也是唯一的。
2、为什么要有GTID
在主从复制中,尤其是半同步复制中, 由于Master 的dump进程一边要发送binlog给Slave,一边要等待Slave的ACK消息,这个过程是串行的,即前一个事物的ACK没有收到消息,那么后一个事物只能排队候着; 这样将会极大地影响性能;有了GTID后,SLAVE就直接可以通过数据流获得GTID信息,而且可以同步;
另外,主从故障切换中,如果一台MASTER down,需要提取拥有最新日志的SLAVE做MASTER,这个是很好判断,而有了GTID,就只要以GTID为准即可方便判断;而有了GTID后,SLAVE就不需要一直保存这bin-log 的文件名和Position了;只要启用MASTER_AUTO_POSITION即可。
3、GTID优缺点
优点:
GTID相对于行复制数据安全性更高,故障切换更简单。
1) 根据 GTID 可以快速的确定事务最初是在哪个实例上提交的。
2) 简单的实现 failover,不用以前那样在需要找 log_file 和 log_pos。
3) 更简单的搭建主从复制,确保每个事务只会被执行一次。
4) 比传统的复制更加安全,一个 GTID 在一个服务器上只执行一次,避免重复执行导致数据混乱或者主从不一致。
5)GTID是连续的没有空洞的,保证数据的一致性,零丢失
6)GTID 用来代替classic的复制方法,不再使用 binlog+pos 开启复制。而是使用 master_auto_postion=1 的方式自动匹配 GTID 断点进行复制。
7) GTID 的引入,让每一个事务在集群事务的海洋中有了秩序,使得 DBA 在运维中做集群变迁时更加方便
缺点:
- 主从库的表存储引擎必须是一致的
- 在一个复制组中,必须要求统一开启GTID或是关闭GTID;
- 不支持create table….select 语句复制(主库直接报错);
- 不支持sal_slave_skip_counter.
4、GTID的组成
GTID = source_id:transaction_id
source_id:用于鉴别原服务器,即mysql服务器唯一的的server_uuid,由于GTID会传递到slave,所以也可以理解为源ID。
transaction_id:为当前服务器上已提交事务的一个序列号,通常从1开始自增长的序列,一个数值对应一个事务。
示例:
3E11FA47-71CA-11E1-9E33-C80AA9429562:235、GTID的工作原理
- 当一个事务在主库端执行并提交时,产生GTID,一同记录到binlog日志中,
- binlog传输到slave,并存储到slave的relaylog后,读取这个GTID的这个值设置gtid_next变量,即告诉slave,下一个要执行GTID 的值
- sql线程从relaylog中读取这个GTID值,然后对比slave端的binlog中有没有该GTID 的值
- 如果有,说明该事务已经执行,slave会忽略
- 如果没有,slave会执行该事务,并把该事务的GTID记录到自身的binlog中,在读取执行事务前会先检查其他session持有该GTID,确保不被重复执行。在解析过程中会判断是否有主键,如果有就用二级索引,没有的话就用全局扫描
6、配置基于GTID的MySQL主从数据复制
1、配置主库
1、
[root@server1 mysql]# vim /etc/my.cnf
在最后写入:log-bin=mysql-bin #启动mysql二进制日志,即数据同步语句,从数据库会一条一条的执行这些语句
server-id=1 #服务器唯一标识
gtid_mode=ON #开启gtid模式
enforce-gtid-consistency=true #强制gtid一致性,开启后对于特定create table不被支持2、
修改完之后,重启mysql服务
[root@server1 mysql]# systemctl restart mysqld
3、查看主库状态
show master status;2、配置从库
1、
[root@server2 mysql]# vim /etc/my.cnf
在最后写入:gtid_mode=ON #开启gtid模块
enforce-gtid-consistency=true #强制gtid一致性,开启后对于特定create table不被支持
server-id=2 #服务器唯一标识2、
修改完之后,重启mysql服务
[root@server1 mysql]# systemctl restart mysqld3、设定从库,将主库与从库连接起来,并开启从库(从库执行)
change master to master_host='192.168.134.132',master_user='repl',master_password='123456',master_auto_postion=1;4、start slave;
5、检查复制是否正确执行:
mysql> show slave status\G;3、测试
当主从之间同步存在差异,而自己又知道什么情况时,主从状态肯定时异常的,可以选择跳过当前事务
查看从库执行 GTID 的进度
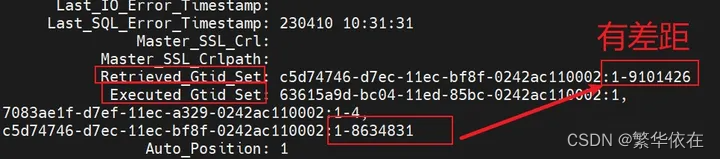
Retrieved_Gtid_Set 表示从库收到的所有日志的 GTID 集合。
Executed_Gtid_Set 表示从库已经执行完成的 GTID 集合。
如果 Executed_Gtid_Set 集合是包含 Retrieved_Gtid_Set,则表示从库接收到的日志已经同步完成。
这里 Executed_Gtid_Set 的集合为 1-8634831,而 Retrieved_Gtid_Set 为 1-9101426,说明从库有些 GTID 是没有执行的。从库已经执行到了 8634831,下一个要执行的 GTID 为 8634832。
因为我们采用的同步方式是 GTID 方式,所以只要让从库跳过这个 GTID ,从下一个 GTID 开始同步就行。
方法一:我们验证一种常用的方法,在从节点上跳过错误事务:
1. 停止slave进程mysql> STOP SLAVE;mysql> reset slave;
2. 设置事务号,事务号从 Retrieved_Gtid_Set 获取,在session里设置gtid_next,即跳过这个GTIDmysql> SET @@SESSION.GTID_NEXT= '1d9b633d-e1ae-11ec-8ece-0242ac110002:15'或者--都可以试下mysql> setgtid_next='c5d74746-d7ec-11ec-bf8f-0242ac110002:8634832';
3. 设置空事物mysql> BEGIN; COMMIT;
4. 恢复自增事物号mysql> SET SESSION GTID_NEXT = AUTOMATIC;
5. 启动slave进程mysql> START SLAVE;