目录
收起
1 Sora的技术特点与原理
1.1 技术特点概述
1.2 时间长度与时序一致性
1.3 真实世界物理状态模拟
1.4 Sora原理
1.4.1扩散模型与单帧图像的生成
1.4.2 Transformer模型与连续视频语义的生成
1.4.3 从文本输入到视频生成
2 Sora的关键技术
2.1 传统文生图技术的回顾
2.2 数据的统一表示与时空潜图块(Spacetime Latent Patches)
2.3 多尺寸视频视频输入处理
2.4 视频压缩网络
2.5 时长扩展技术
2.6 安全
延伸阅读:
本文从Sora的特点和原理开始,从“专业+科普”的角度详解Sora的关键技术与模型架构,适用于T2V/V2V技术入门和相关投资领域的读者。
主编作者陈巍,高级职称,曾担任华为系相关自然语言处理( NLP )企业的首席科学家,大模型算法-芯片协同设计专家,国际计算机学会(ACM)会员、中国计算机学会(CCF)专业会员。主要研究领域包括大模型(Finetune、Agent、RAG)、存算一体、GPGPU。
本文为全文的上篇,重点介绍Sora技术特点、原理与关键技术。
2023下半年到2024第一季度,AI视频生成领域出现了明显的爆发趋势。在Open AI的Sora之前,Runway ML的Gen-2、谷歌的Lumiere、Stable Video Diffusion等技术或产品陆续登场,一起为Sora的横空出世铺平了道路。
对Open AI来说,通过人工智能理解和模拟运动中的物理世界,可以帮助人类解决需要现实世界交互的各种任务或问题,这也是Open AI训练Sora这类T2V(Text to Video,文生视频)模型的目的。国内网络上流传有Sora用于影视或者数字孪生等种种设计目的猜测,但相对于让AI理解真实的物理世界来说,影视和数字孪生的目的都显得太渺小。

AI视频生成技术时间线/2023-2024(作者团队修改自@venturetwins,转载请注明出处)
在Sora之前,AI视频生成的天花板是Runway的Gen-2,支持最长18秒的视频生成,镜头(机位)相对固定,图像质量一般达不到影视级要求。而到了Sora,才是真正迎来了视频生成的GPT时刻。
1 Sora的技术特点与原理
相对于Gen-2和Pika等一众文生视频的前辈,Sora出场就达到了60秒的最大视频时长,并且生成的视频质量达到了影视级的效果。下面归纳下Sora的突出技术特点与原理

AI视频生成技术产品一览(作者团队绘制,转载请注明出处)
1.1 技术特点概述
我们将Sora的技术特点划分为输入输出特征、功能特征、时空与角色一致性三类。
以往的文生视频算法多数是采用公开训练数据,生成的视频多数不够美观,分辨率低,而且在生成视频的过程中,无法精准体现文本提示的内容,用户的文本提示难以转化为高清高质量视频。当然更大的难点是视频中主角运动不连贯或不自然,在镜头移动的时候,主体边缘容易畸变,特别是人物表情细节的畸变严重影响视频的表达效果。

Sora技术特征图示(来源:Data Science Dojo)
相对来说,Sora这类扩散Transformer模型,通过输入的信息和噪声图块(Noisy Patches)来生成清晰的视频,除了支持不同长宽比和分辨率外,还具备高保真的渲染能力,可以相对精准的表达各种输入的提示,且具备较好的时空与角色一致性,甚至能模拟真实世界的物理状态。
视频输入输出的灵活性:Sora能够生成不同分辨率、长宽比的视频,并且支持多机位,支持不同分辨率的提示图/视频输入,提高了内容创作的灵活性。
多模态语言理解与文本提示:Sora提高了视频生成过程对文本的准确性和整体生成质量。能够根据用户的简短提示生成详细的文本提示,从而生成高质量的视频。同时Sora还具备扩展视频和拼接视频的能力,进一步提升视频创作功能。此功能使 Sora 能够执行各种图像和视频编辑任务,包括创建循环视频、动画静态图像、向前或向后扩展视频等。
时空与角色的一致性:这是Sora最关键的优势,生成的视频主体能保持较长时间的时序一致性,确保视频中的事件在时间上连续,同时视频中的物体和背景在视角切换过程中保持相对位置稳定,且主体不发生明显畸变,可以准确的表现复杂场景。

Sora的技术特点(作者团队绘制,转载请注明出处)
1.2 时间长度与时序一致性
在Sora之前的Runway Gen-2、Pika 以及 Stability 的SAD等,所生成的视频长度最长不过18秒。单从视频生成长度来说,Sora已经吊打之前的所有模型了。
从模型训练角度看,十几秒到一分钟,难度并不是简单的线性关系。限制 AI 视频长度的主要因素包括模型训练资源、内容连贯性和逻辑性。视频由连续的多帧图像组成的,生成视频所需要的计算资源随着时间增加呈几何级数的增加。训练能生成较长时间视频的模则需要更大规模的计算资源来支持。
但对于文生视频算法,比计算资源更关键的是生成视频的时间连续性和逻辑一致性的维护,也就是时序一致性问题。例如准确的理解和预测物体的运动和变化,既要时间上连贯,又要符合物理世界的客观时序规律,这才能保证生成的视频是逼真的。比如椅子,不能像气球一样轻飘飘。
相对来说,开发能够理解复杂叙述结构和逻辑关系的文生视频模型较为困难的,时间越长,维持时序连贯性和逻辑性难度就越高。
Sora在时间长度与时序一致性方面具备以下特点:
空间一致性:Sora能够确保生成视频中的物体在空间上保持相对位置的一致性,即使在复杂的场景变换中,多个物体或人物也能保持正确的相对位置和运动轨迹。
角色和物体的一致性:Sora能够在视频中保持角色和物体的长期一致性和存在,即使在视频中出现遮挡或角色离开画面的情况,Sora也能保持其存在和重新出现后的外观。
视频内容的连贯性:Sora能够生成具有连贯故事线的视频,确保视频中的事件和动作在时间上是连续的,符合叙事逻辑,没有剧情的跳跃。

Sora 与Lumiere比较(来源:Sepideh Yazdi)
1.3 真实世界物理状态模拟
Open AI团队发现,在大规模训练下,Sora展示出了一系列引人注目的涌现能力。这让 Sora 有能力在一定程度上模拟真实世界中的人、动物和环境。例如画家可以在画布上留下新的笔触,并随着时间的推移而持续,符合真实世界的物理规律。
Sora在真实世界物理状态模拟方面具备以下特点:
简单影响行为模拟:Sora能够模拟一些简单的与世界互动的行为,如画家在画布上留下笔触,或者人物在吃食物时留下痕迹。这些行为不是预设的规则,而是模型通过学习大量数据后自然涌现的能力。
动态相机运动:Sora能够生成包含动态相机运动的视频,这意味着视频中的人物和场景元素能够在三维空间中保持连贯的运动。例如,当相机移动或旋转时,视频中的物体会相应地改变位置,就像在现实世界中一样。
1.4 Sora原理
Sora通过扩散Transformer模型(Diffusion Transformer Model)来处理输入数据和生成视频。
在训练过程中,扩散Transformer通过学习输入的视频/图像等数据的分布,将这些分布映射到低维空间,从而实现对视频的压缩和重构的学习。
目前猜测Sora包括向量量化变分自编码器(VQ-VAE-2)、多模态Transformer(MMT)以及去噪扩散概率模型(DDPM)等组件。简而言之,Sora的本质就是Diffusion和Transformer模型的结合,下面通过这两类模型来介绍Sora的原理。
1.4.1扩散模型与单帧图像的生成
扩散模型实现了文本生成单帧图像的功能。
扩散模型(Diffusion Model)起源于非均衡热动力学,通过模拟自然界中常见的扩散过程来学习生成新数据。通过增加(高斯)噪声来逐步混淆数据(扩散过程),随后学习逆转噪声过程以重新构造样本(逆扩散过程)。

扩散过程与逆扩散过程(来源:作者团队修改自北京大学)
扩散过程(X0->XT):逐步对图像(训练数据集)加噪声,这一逐步过程可以认为是参数化的马尔可夫过程,相当于制作模型训练/学习的素材。
逆扩散过程(XT->X0):从噪声中反向推导,逐渐消除噪声以逆转生成图像。这一过程相当于从少量信息中生成图像。

扩散模型论文数量逐年增加(来源:Standford)
扩散模型在计算机视觉、自然语言处理等领域有着广泛的应用,大有超越GAN模型的趋势。例如OpenAI的DALL·E 2和Google的Imagen这两个先进的文本生成图像算法,都是基于扩散模型架构。
在Sora中,Transformer功能生成的潜空间数据通过扩散功能生成富于细节的单帧图像,单帧图像再组成连续的视频。
1.4.2 Transformer模型与连续视频语义的生成
扩散模型在生成高清晰度、近乎照片般图像方面擅长,但是并不具备建立连续语义关联的能力。仅用扩散模型和UNet难以实现连续而逻辑自洽的视频流。
相比之下,Transformer模型利用自注意力机制来把握序列数据(对于Sora就是单帧图像的潜空间表征)中各个元素之间的关联,在图像分类和自然语言处理(NLP)任务中表现突出。
输入的序列数据,在Transformer计算后,生成最大概率的对应输出数据。无论是文本还是视频(两者都是序列),都可以转换为一个高维向量组成的序列。对于自然语言处理,这个最小单位是Token,对于Sora等文生视频算法来说,这个最小单位就是图块(Patch)。

以Encoder为例的Transformer生成示例(来源:Towards Data Science)
Transformer在数学上类似大矩阵的计算,通过计算不同语义之间的关联度(概率)来生成具有最高概率的语义反馈。传统的RNN、LSTM或者GRU主要是进行模式识别,而Transformer不仅仅是一个矩阵计算,事实上还承载着语义关联的重要功能。
Transformer中的核心组件是多头自注意机制模块。Transformer将输入的编码表示视为一组键值对(K,V),两者的维度都等于输入序列长度。

多头自注意机制模块(来源:作者团队修改自Google)
在Sora中,扩散模型功能处理后的输入数据,变成有时序的向量(潜空间的表征),Transformer功能则负责解读输入的图块和指令的潜空间信息,根据输入的向量信息预测下一个向量,从而根据文本指令(文本也作为Transformer功能的输入)生成有时序和因果含义的潜空间表征,进而通过解码器输出。
1.4.3 从文本输入到视频生成
Sora通过结合扩散Transformer模型和视频压缩网络的工作原理,实现了高效的视频生成能力。Sora还设计了相应的解码器来处理生成的低维潜空间数据,增强视频帧的渲染效果,确保了模型的实用性和灵活性。
在训练(Training)过程中,Sora通过视频压缩网络来压缩输入的视频或图片(训练数据),使其成为一个低维的潜空间表征形式,然后将该表征形式传入扩散过程进行训练。对应的表征形式为空间时间图块(Spatial and Temporal Patches)。时间和空间信息被压缩入图块(Patchs),减少视频动态内容的数据量(有助于提高模型的训练效率和可扩展性)。Transformer功能被训练为理解时空数据图块,并进行逻辑自洽的推演,生成对应于视频的低维潜空间数据。

Sora通过低维信息序列生成图像序列(来源:Open AI)
与其他文生视频模型不同,Sora支持不同分辨率的输入输出,即训练时支持缩放(Scaling),支持长内容(Long Context,长达1分钟的视频。这其中的关键在于集群训练期间累积误差(Error Accumulatio)的控制,视频中实体的高质量渲染和物理一致性,以及视频、图像、文本的多模态支持。
在视频生成(Inference)过程,Sora中的解码器模型,将Transformer功能生成的低维潜空间数据转换回像素空间,并进行一定程度的渲染,以进行进一步的处理和应用。
2 Sora的关键技术
Sora 本身是一种扩散模型与Transformer模型的合体,其本质是根据输入,通过Transformer生成潜空间表征序列,再通过扩散模型对表征序列进行解释,逐渐消除噪声生成逻辑自洽的图像序列的过程。
Sora 的关键在于能一次生成整个较长的视频(60秒),而且保持视频中的主体和逻辑的一致性,确保主体暂时离开视野时也保持不变。
2.1 传统文生图技术的回顾
为了更好的了解Sora中的技术,我们首先回顾下文生图的一些传统技术。视频本质上就是图像的序列。
在文生图领域,比较成熟的模型模式包括生成对抗网络( GAN )和扩散模型( Diffusion Models ),本次OpenAI 推出的 Sora 则是一种扩散模型的变种。相较于 GAN,扩散模型的生成多样性和训练稳定性都要更好很多。

几种典型的文生图模型架构对比(来源:Lilian Weng)
在GAN(Generative Adversarial Networks,生成对抗网络)模型中,生成器(Generator)的目标是生成尽可能接近真实数据分布的样本,而判别器(Discriminator)的目标则是区分这些生成的样本和真实的样本。两者相互竞争,通过交替训练,提升对原作的模仿能力。
VAE(Variational Autoencoder,变分自编码器)模型是对输入数据和潜在变量的联合分布进行建模,通过编码器对输入的训练数据进行降维,提取原始关键信息,然后再通过译码器(Decoder)重建原始信息,学习图像生成能力。为了使模型不受限于数据的分布形式,VAE使用了变分推断(Variational Inference)方法来近似计算潜变量的后验分布。

文生图模型训练与推断的简单流程(来源:OpenAI)
GAN 模型的原理本质上是机器对人的模仿和对抗训练,到VAE模型时已经有了扩散模型思路的雏形;而扩散模型则更像是机器学会 “ 成为一个人 ”,具有多样性,学会还原世界的特征。特别是GAN 模型训练过程高度依赖于对原始数据的比对和仿真,多样性少,难以提升创造力。
而扩散模型,在训练学习大量原始数据的过程中,侧重图像内涵与图像之间的关系,侧重于关键特征的挖掘和提炼。
2.2 数据的统一表示与时空潜图块(Spacetime Latent Patches)
在Sora中,数据的统一表示对训练效率和生成质量都有很大影响。
Sora的思路是将输入的训练数据转换为具备时序特征的向量,然后由Sora中的Transformer预测下一个向量。无论是文本还是视频,都需要转化为高维向量组成的序列才能正常参与计算。对于GPT而言,这一向量中的这个最小单位是Token,对于Sora等文生视频模型来说,这个最小单位就是时空图块(Spacetime Latent Patches)。

Sora中的时空潜图块表征(来源:OpenAI)
文本的Token序列天然是一维线性排列。而视频具有时序、长、宽等维度,所以Patch是高维度向量组成的三维空间,然后通过压缩模型处理成单维向量序列。每帧图像是由多个Patch组成,具有很强的扩展和表征能力。

时空潜图块的应用与表征方式(来源:复旦/微软)
例如对于视频流,给定视频片段中T帧,通过采样计算提取特征,每个Patch包含96维特征。再通过线性嵌入层处理后输入到Transformer结构中。
这个数据的统一表征并不难,但找到一个适合视频生成的表征算法需要大量的数据进行训练和选优。
2.3 多尺寸视频视频输入处理
Sora模型支持在不同时长、分辨率和宽高比的视频和图像上进行训练。
目前推测Sora采用了类似NaViT的图块打包技术。

NaViT图块打包技术示意(来源:Google Deepmind)
NaViT(Native Resolution ViT)没有采用传统的将图像调整至固定大小的做法,而通过特定的架构来实现对任意分辨率和宽高比图像的灵活处理。打包支持保持宽高比的可变分辨率图像,减少了训练时间,提高了性能,并增加了灵活性。
打包技术的要点包括:
1) 序列打包(Sequence Packing)
在数据预处理(Data Preprocessing)过程中,序列打包的技术将来自不同图像的Patch组合成一个序列,从而使模型能够同时处理多个图像片段。
2) 屏蔽自注意力(Masked Self-Attention)
为了防止不同图像帧间的不当交互,NaViT引入额外的自注意力屏蔽,确保了模型在处理一个图像序列中的不同片段时,只关注于同一图像内的相关部分。
3) 分解和分数位置嵌入(Factorized & Fractional Positional Embeddings)
NaViT重新设计了位置嵌入以适应可变的图像尺寸和宽高比。NaViT采用了分解的方法来分别处理x和y坐标的位置嵌入,再将这些嵌入相加。该方法允许模型灵活处理各种尺寸和宽高比的图像,同时保留空间信息。
4) 屏蔽池化(Masked Pooling)
在编码器顶部使用屏蔽池化,目的是在序列中将每个Token/Patach表征汇聚成单个向量表示。这一步是为了在保留每个图像独立信息的同时,实现高效的特征提取。
在生成视频内容时,通过这种打包方法可以根据需求灵活调整视频的分辨率和宽高比,无需将视频统一调整到固定的大小,方便进行多样化的训练。另外可以处理并生成保持原始宽高比的视频,在应用于不同类型的屏幕和媒体格式时非常便利。
2.4 视频压缩网络
Sora 使用视频压缩网络(Video Compression Network)来“压缩”视频,将图块转换成统一且信息更小的形式,即低维或者压缩潜空间,并重构为时空潜图块。这一压缩非常重要,因为压缩后的图块可以大幅降低训练与推断的计算负荷,使 Sora 能够在训练过程中更加高效的学习海量数据。

低维/压缩隐空间扩散(来源:NVIDIA)
在Sora模型的技术报告中,对视频压缩的引用基于较早的VAE(变分自编码器)工作。传统的VAE主要用于文生图的训练,目前推测Sora采用了向量量化变分自编码器(VQ-VAE-2)技术,来同时实现压缩和编码。
VQ-VAE-2是VAE的量化改进版本,通过向量量化的方法来处理潜空间的表示。在VQ-VAE-2中,潜空间被量化为离散的向量表征,每个输入数据点都被映射到最接近的离散向量。

VQ-VAE的向量空间压缩(来源:Google)
在分析VQ-VAE-2前,先分析下VQ-VAE的思路:
1)嵌入式空间(Embedding Space)是一个量化后的单位向量空间(ei).
2)将一张(训练)图片经过编码器(Encoder), 得到特征图Ze(x).
3)将特征图中的各向量分别去嵌入式空间里找最近的ei,将向量表征为量化单位向量的组合q(z|x)。
4)替换后可以得到向量量化表征Zq(x),再通过解码器(Decoder)输出,重构得到图片。
有了VQ-VAE的原理分析,再看VQ-VAE-2的思路。

VQ-VAE-2架构(来源:Google)
如图所示,左边是训练过程,分上下两层。顶层(Top Level)潜空间尺寸为32x32, 底层潜空间尺寸 64 x 64。顶层先进行分层量化,得到量化后的单位向量etop。再以此单位向量为基础,与输入一起,计算底层(Bottom Level)的单位向量ebottom。顶层与底层的单位向量同时进入解码器,完成解码计算与训练。
在右边的生成过程中,解码分为两层,顶层保证全局自洽,底层保证全局高清。
在 VQ-VAE-2 中,对顶层使用了多头自注意力机制 (Multi-headed Self-Attention ),有比较好的长程关联。
VQ-VAE-2可以实现对视频数据的有效压缩,将原始视频数据转换为更加高效和紧凑的量化潜空间表示。这对于模型后续处理和生成高质量视频至关重要。
2.5 时长扩展技术
OpenAI在Sora技术报告中提到了扩展生成视频(Extending Generated Videos)技术,使 Sora 具备可以让视频在时间线上向前或向后扩展的能力。例如官方演示的中,有几段不同的视频,都是四个不同视频的视频开始,却走向相同的结尾(时间线向前扩展)。
另一方面,Sora也达到了超越其他文生视频工具的60秒生成视频时长,我们猜测这也是时长扩展技术的体现。
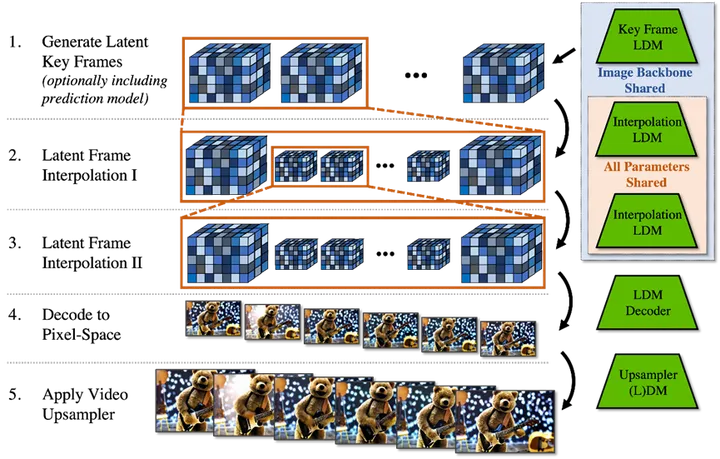
通过多次插值实现时长扩展(来源:NVIDIA)
预测Sora最初以低帧速率生成稀疏关键帧(时间线向前或向后),然后通过另一个插值潜扩散模型在时间上采样两次或两次以上。另外,通过调整起始帧来选择性的训练视频潜空间扩散模型进行视频预测,以自回归方式生成长视频。
2.6 安全
Sora 之中有几个重要的安全措施,包括对抗性测试、检测分类器。
Sora团队与红队成员(错误信息、仇恨内容和偏见等领域的专家)合作,并以对抗性方式测试Sora模型。
Sora前后端还包括检测误导性内容的检测分类器。前端的文本分类检测器将检查并拒绝违反使用许可的输入提示,例如要求仇恨图像、名人肖像或他人 IP 的文本输入提示。Sora后端的图像分类检测器,会检查生成的每个视频帧,以帮助在显示之前符合法律法规和OpenAI的规则。




![[linux]--关于进程概念(下)](https://img-blog.csdnimg.cn/direct/828df22432b94941b6573a8b1f5c9330.png)
![[游戏开发][UE5.3]GAS学习心得](https://img-blog.csdnimg.cn/direct/28b8a8018bc940eb807831998a6e15dc.png)