Linux 系统是如何收发⽹络包的?
⽹络模型
为了使得多种设备能通过⽹络相互通信,和为了解决各种不同设备在⽹络互联中的兼容性问题,国际标准化组织制定了开放式系统互联通信参考模型(Open System Interconnection Reference Model),也就是 OSI ⽹络模型,该模型主要有 7 层,分别是应⽤层、表示层、
会话层、传输层、⽹络层、数据链路层以及物理层。
- OSI模型分析
OSI(Open Systems Interconnection)模型是一个理论上的网络通信模型,由国际标准化组织(ISO)提出,目的是促进不同系统之间的通信标准化。它将网络通信分成了七个层次:
- 物理层(Physical Layer):负责通过物理媒体传输原始比特流。这涉及到数据接口、传输媒介(如电缆、光纤)和信号。
- 数据链路层(Data Link Layer):在物理层提供的服务上增加了数据帧的封装、物理地址寻址、流量控制等功能。
- 网络层(Network Layer):负责数据包的路由选择、传输和分片,以确保数据可以跨越不同的网络。
- 传输层(Transport Layer):提供端到端的通信服务,包括数据的分段、传输控制(如TCP的可靠传输)和错误检测。
- 会话层(Session Layer):管理应用程序之间的会话,包括会话的建立、维持和终止。
- 表示层(Presentation Layer):确保信息的语义以及它的格式在不同系统间能正确交换,例如加密、压缩和数据格式转换。
- 应用层(Application Layer):为最终用户提供网络服务接口,如HTTP、FTP和电子邮件服务。
OSI模型的优点在于它提供了一个清晰的网络通信分层框架,有助于不同网络技术和协议的开发和标准化。但在实践中,由于其复杂性和理论性,它并没有被广泛直接实现。
- TCP/IP模型分析
TCP/IP模型是一种更实际、基于实际网络协议栈的网络通信模型,它简化了OSI模型的七层为四层:
- 应用层(Application Layer):相当于OSI模型的应用层、表示层和会话层,提供各种网络服务给终端用户,如HTTP、FTP、DNS等。
- 传输层(Transport Layer):与OSI模型的传输层类似,主要用于提供端到端的通信控制,主要协议有TCP(提供可靠的字节流服务)和UDP(提供无连接的数据报服务)。
- 网络层(Network Layer):负责数据包的路由选择和传输,主要协议是IP(Internet Protocol)。
- 网络接口层(Network Interface Layer):相当于OSI模型的物理层和数据链路层,负责数据的物理传输。
TCP/IP模型由于其简化的层次结构和实用性,成为了互联网的基础协议栈,得到了广泛的应用和发展。

不过,我们常说的七层和四层负载均衡,是⽤ OSI ⽹络模型来描述的,七层对应的是应⽤
层,四层对应的是传输层。
- 四层负载均衡适合对速度和低延迟有高要求的场景,但它无法进行复杂的决策。
- 七层负载均衡适用于需要根据具体应用逻辑进行智能路由的场景,尽管它可能比四层负载均衡处理速度慢一些。
Linux ⽹络协议栈
我们可以把⾃⼰的身体⽐作应⽤层中的数据,打底⾐服⽐作传输层中的 TCP 头,外套⽐作⽹络层中 IP 头,帽⼦和鞋⼦分别⽐作⽹络接⼝层的帧头和帧尾。
在冬天这个季节,当我们要从家⾥出去玩的时候,⾃然要先穿个打底⾐服,再套上保暖外套,最后穿上帽⼦和鞋⼦才出⻔,这个过程就好像我们把 TCP 协议通信的⽹络包发出去的时候,会把应⽤层的数据按照⽹络协议栈层层封装和处理。
你从下⾯这张图可以看到,应⽤层数据在每⼀层的封装格式。

- 数据包的封装过程
- 应用层到传输层:当数据从应用层发送时,传输层(如TCP或UDP)会给数据包添加一个头部,这个头部包括端口号(用于标识发送和接收应用程序)、序列号(仅TCP,用于确保数据的有序和完整性)、确认号(仅TCP,用于确认接收)、以及其他控制信息(如窗口大小、校验和等)。
- 传输层到网络层:网络层(通常是IP层)再给这个已经有了传输层头部的数据包添加它自己的头部,这个IP头部包括源IP地址和目的IP地址(用于在网络中路由数据包),以及其他控制信息如生存时间(TTL)、协议类型等。
- 网络层到网络接口层:最后,在网络接口层(数据链路层和物理层的组合),数据包被进一步封装,加上了帧头和帧尾,这包括物理地址信息(MAC地址)、错误检测和校正码等。这个过程准备数据包在物理媒介上的传输,如以太网或Wi-Fi。
- 最大传输单元(MTU)和分片
MTU是网络层面上可以传输的最大数据包大小。对于以太网,标准MTU大小通常是1500字节。如果一个IP数据包的大小超过了网络路径上的MTU,那么这个数据包就需要在网络层进行分片,以确保每个片段都不会超过MTU大小。分片的过程增加了额外的头部信息(因为每个片段都需要被独立地封装为有效的IP数据包),并且可能导致接收端需要重组这些片段,这一切都会引入额外的处理延迟。
- 对网络性能的影响
- 增加开销:每层添加的头部信息增加了总的传输数据量。尽管这些协议头是必要的,它们占用了传输中的带宽,特别是当传输的有效负载较小时,这种开销比例会变得更大。
- 分片的处理:当数据包需要分片时,这不仅增加了传输的总字节数(因为每个片段都有自己的IP头部),还可能在接收端造成额外的重组开销。此外,如果任何一个片段在传输过程中丢失,整个数据包可能都需要重新发送,从而降低了网络的效率。
- 网络吞吐能力:理论上,较大的MTU可以提高网络的吞吐能力,因为它减少了因为分片所必需的开销和处理时间。然而,在实际环境中,最优的MTU大小还要考虑网络的特定条件,如链路类型、存在的干扰、以及网络拥塞情况。
知道了 TCP/IP ⽹络模型,以及⽹络包的封装原理后,Linux网络协议栈是一个实现了TCP/IP四层模型的复杂系统,负责处理从应用程序到物理网络媒介的所有数据传输。在Linux中,这个过程涉及多个组件和层次,每一层都有其特定的功能和责任。下面是对Linux网络协议栈的一般分析:
应用层与Socket层的交互
- 应用程序与Socket层:应用程序通过系统调用与Socket层进行交互。Socket API提供了一组函数,允许应用程序创建套接字(socket),这些套接字用于发送和接收数据。在应用层,开发人员不需要关心数据是如何在网络中传输的;他们只需要使用标准的Socket接口,比如
send()和recv()函数,以及更高级的API,如HTTP库或数据库连接库,这些库在内部使用Socket进行通信。
Linux网络协议栈的核心层
- 传输层:位于Socket层之下,主要处理端到端的数据传输,包括TCP和UDP协议的实现。TCP负责提供可靠的、有序的和基于字节流的连接,而UDP提供了一个简单的、不可靠的消息传递服务。
- 网络层:负责数据包的路由和寻址。在这一层,IP协议是核心,它负责将数据包从源主机传输到目的主机,无论它们在网络中的位置如何。IP层也处理数据包分片和重组,以及错误报告(通过ICMP)。
- 网络接口层:这一层包括数据链路层和物理层的功能,负责数据包的实际传输。在Linux中,这通常意味着与网络设备驱动程序的交互,网络设备驱动程序负责将数据包发送到物理媒体(例如,以太网)上,以及从物理媒体接收数据包。
网卡驱动程序和硬件网卡设备
- 网卡驱动程序和硬件网卡:这是Linux网络协议栈的最底层。网卡驱动程序负责与硬件网卡设备通信,执行如初始化设备、处理中断、发送和接收数据包等操作。硬件网卡是物理设备,负责电信号的发送和接收。

Linux 接收⽹络包的流程
Linux系统接收网络包的流程是一个精心设计的机制,旨在有效管理网络流量和CPU资源。这个流程利用了硬件(网卡)和软件(操作系统内核)之间的协作,确保在高性能网络环境下,系统能够高效地处理大量网络数据包,而不会过度占用CPU资源。以下是对该流程的详细分析:
- 网络包的接收
- 网卡接收网络包:当网卡接收到一个网络包时,它使用直接内存访问(DMA)技术,将网络包直接写入到预先分配的内存区域,通常是一个环形缓冲区(Ring Buffer)。这个过程不需要CPU的直接干预,提高了数据传输的效率。
- 中断触发:接收到网络包后,网卡会触发一个硬件中断,通知CPU有新的数据到达。在传统的处理机制中,每接收一个网络包就会触发一次中断,这在网络流量较低时是可行的,但在高流量环境下会导致大量的中断,严重影响系统性能。
- NAPI(New API)机制
为了解决上述问题,Linux内核引入了NAPI机制,它是一种混合使用中断和轮询的方法来处理网络数据包的接收。NAPI的工作流程如下:
- 初次中断:当第一个网络包到达并通过DMA写入内存后,网卡会触发一个硬件中断。
- 中断处理函数:CPU响应硬件中断,并执行注册的中断处理函数。这个函数的首要任务是暂时禁用进一步的中断。这意味着,在这个阶段,即使有新的网络包到达,也不会触发新的硬件中断。
- 启用软中断:中断处理函数随后会触发一个软中断(或者称为“下半部”处理),并重新启用硬件中断。软中断负责实际的数据包处理工作,如从环形缓冲区中读取数据包并进行进一步处理。
- 轮询模式:在软中断处理期间,系统进入轮询模式,这时系统会主动检查环形缓冲区中是否有新的数据包到达,而不是依赖硬件中断。这种方式显著减少了中断的次数,降低了CPU的负载。
- 恢复中断模式:当环形缓冲区中没有更多的数据包需要处理时,系统会退出轮询模式,并恢复到正常的中断驱动模式。这样,下一个到达的网络包会再次触发硬件中断,重启整个流程。
- 效率提升
通过NAPI机制,Linux能够在保持高吞吐量的同时,显著减少CPU的中断负载。在高性能网络环境中,这种机制可以有效地平衡网络包处理速度和系统资源使用,提高了系统的整体性能和稳定性。NAPI通过减少在高流量情况下不必要的中断,使CPU可以更好地执行其他任务,从而优化了多任务处理环境下的资源分配。
ksoftirqd线程处理软中断
- ksoftirqd线程:Linux内核中的
ksoftirqd线程负责处理软中断。每个CPU都有一个对应的ksoftirqd线程。当网络流量较高时,软中断处理会从硬件中断上下文转移到这些线程中,以减少硬件中断处理对系统性能的影响。 - 数据处理:
ksoftirqd线程会轮询处理环形缓冲区(Ring Buffer)中的数据。这些数据以数据帧的形式存储,通常使用sk_buff(socket buffer)结构来表示,它是一个关键的数据结构,用于在Linux网络栈中传递网络包。
网络协议栈处理
- 网络接口层:处理开始于网络接口层,这里会进行报文的基本检查(如合法性检查)。对于合法的报文,根据帧头信息确定上层协议类型(例如IPv4或IPv6),然后移除帧头和帧尾,将剩余内容传递到网络层。
- 网络层:在网络层,IP包被进一步处理。这一层负责判断网络包的目的地,是直接上交给上层处理(如TCP或UDP处理)还是需要路由转发。
- 传输层:到达传输层时,会根据IP头中指定的协议(TCP或UDP)去掉IP头,再根据包头信息(如TCP头或UDP头)处理数据。此层利用源IP、源端口、目标IP和目标端口这四元组唯一标识找到对应的Socket,并将数据放入Socket的接收缓冲区。
- 应用层:应用层程序通过调用Socket API,如
recv(),将数据从内核的Socket接收缓冲区拷贝到应用层的缓冲区,并处理数据。完成这一步骤后,数据包的接收过程就结束了。
⾄此,⼀个⽹络包的接收过程就已经结束了,你也可以从下图左边部分看到⽹络包接收的流
程,右边部分刚好反过来,它是⽹络包发送的流程。

Linux 发送⽹络包的流程
Linux发送网络包的过程是一个从应用层数据到物理传输的完整路径,涉及数据在协议栈各层的处理和转换。这个过程确保了数据按照TCP/IP模型的要求被正确封装、路由、发送,最后通过物理网络到达目标。下面是对这个过程的分析:
1. 应用层到内核态的数据传输
-
Socket发送数据包接口:应用程序通过调用Socket API(如
send或write函数)发起数据传输请求。这个操作会使得进程从用户态陷入到内核态。 -
sk_buff结构体:内核为了处理这些待发送的数据,会申请一个
sk_buff(socket buffer)结构体的内存空间,这个结构是Linux网络子系统中一个关键的数据结构,用于在内核中表示网络数据包。应用层的数据会被拷贝到这个sk_buff中,并加入到发送缓冲区。
2. 网络协议栈处理
-
TCP/IP协议栈处理:从Socket发送缓冲区中取出
sk_buff后,数据包会按照TCP/IP协议栈从上到下逐层进行处理。 -
TCP传输与sk_buff副本:如果是TCP传输,因为TCP支持数据的丢失重传,所以会创建一个
sk_buff的副本。原始sk_buff用于实际发送,而副本在收到对方的ACK确认前,用于可能的重传。
3. 数据包的封装
-
填充协议头:在向下传递的过程中,每一层都会向
sk_buff中添加相应的协议头(如TCP头、IP头和以太网帧头)。这⾥提⼀下,sk_buff 可以表示各个层的数据包,在应⽤层数据包叫 data,在 TCP 层我们称为 segment,在 IP 层我们叫 packet,在数据链路层称为frame。 -
sk_buff指针调整:通过调整
sk_buff中的data指针的方法,避免了在层与层之间传递数据时发生的多次拷贝,提高了CPU效率。当接收报⽂时,从⽹卡驱动开始,通过协议栈层层往上传送数据报,通过增加 skb->data
的值,来逐步剥离协议⾸部。
当要发送报⽂时,创建 sk_buff 结构体,数据缓存区的头部预留⾜够的空间,⽤来填充各
层⾸部,在经过各下层协议时,通过减少 skb->data 的值来增加协议⾸部。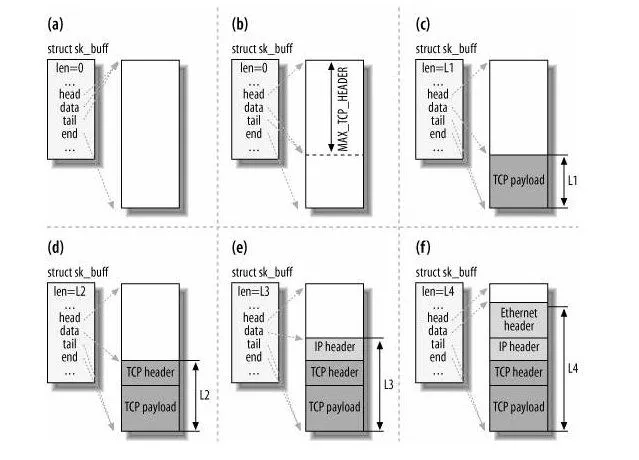
4. 数据发送准备
-
网络层处理:在网络层,会进行路由选择(确认下⼀跳的 IP)、IP头填充、netfilter过滤、对大于MTU的数据包进行分片等处理。
-
网络接口层处理:在这一层,会通过ARP协议确定下一跳的MAC地址,并填充帧头帧尾,将
sk_buff放入网卡的发送队列。
5. 数据包的物理发送
-
触发软中断:软中断被触发来通知网卡驱动程序有新的网络包待发送。
-
网卡驱动处理:网卡驱动从发送队列中读取
sk_buff,将数据映射到网卡的DMA区域,并触发物理发送。
6. 发送完成与内存清理
-
发送完成中断:数据发送完成后,网卡设备会触发一个硬件中断来通知CPU,主要任务是释放
sk_buff内存和清理环形缓冲区。 -
确认ACK与释放资源:对于TCP传输,一旦收到对方的ACK确认,传输层就会释放掉原始的
sk_buff副本。
这个过程展现了Linux内核如何高效、有序地处理网络数据包的发送,从应用层数据的准备到最终的物理传输,每一步都经过精心设计,确保数据的正确传输和系统资源的有效利用。
发送⽹络数据的时候,涉及⼏次内存拷⻉操作?
-
- 从用户空间到内核空间的拷贝
当应用程序调用发送数据的系统调用(如send或write)时,数据需要从用户空间传输到内核空间。此时,内核会为这些待发送的数据申请一个sk_buff结构体的内存,并将用户空间的数据拷贝到这个sk_buff内存中。这个sk_buff随后被加入到发送缓冲区。这是第一次内存拷贝操作。
-
- TCP协议的sk_buff克隆
对于使用TCP传输协议的情况,为了实现TCP的可靠传输(即支持数据的重传机制),在从传输层向网络层转发数据时,会克隆一个新的sk_buff副本。这个副本是实际被发送到网络层的,而原始的sk_buff保留在传输层,用于在需要时重新发送数据(如未收到对方的ACK确认)。这个副本在发送完成后会被释放,而原始的sk_buff在收到对方的ACK确认后才会被释放。这是第二次内存拷贝操作。
-
- 处理大于MTU的sk_buff
当网络层发现一个sk_buff的大小超过了MTU(最大传输单元)时,会进行分片处理。这意味着原始的sk_buff会被分割成多个小的sk_buff,每个都小于或等于MTU的大小。为了分片,内核会为每个片段申请新的sk_buff内存,并将原始sk_buff的相应部分数据拷贝到这些新的sk_buff中。这是第三次内存拷贝操作。
因此,在发送网络数据的过程中,涉及到的内存拷贝操作主要有三次:一次是从用户空间到内核空间的拷贝,第二次是TCP协议的sk_buff克隆操作,第三次是处理超过MTU大小需要分片的情况。需要注意的是,第三次拷贝操作只在原始sk_buff大于MTU时才会发生。这些内存拷贝操作确保了数据的正确处理和传输,同时支持了TCP的可靠传输机制。

![[HackMyVM]靶场 XMAS](https://img-blog.csdnimg.cn/direct/ab385716590a4dea88cf09a6212f5831.png)