背景
之前我们在一片文章里简单介绍过Flink的多流合并算子
java Flink(三十六)Flink多流合并算子UNION、CONNECT、CoGroup、Join
今天我们通过Flink 1.14的源码对Flink的Interval Join进行深入的理解。
Interval Join不是两个窗口做关联,更适用于处理乱序数据流之间的关联。它的作用更类似于从左流中a元素本身出发,对右流中一段时间内的数据进行关联(Inner Join:只关联相同Key的数据)。
如图所示:
下边这条流中的2关联到上范围内的0/1

源码解析
Flink版本1.14.4
按住Ctrl+鼠标左键,点击process进入源码

这里process方法是在KeydStream.java下IntervalJoined类下的方法

包装返回类型的TypeInfomation(TypeInfo的介绍可以看上一篇)
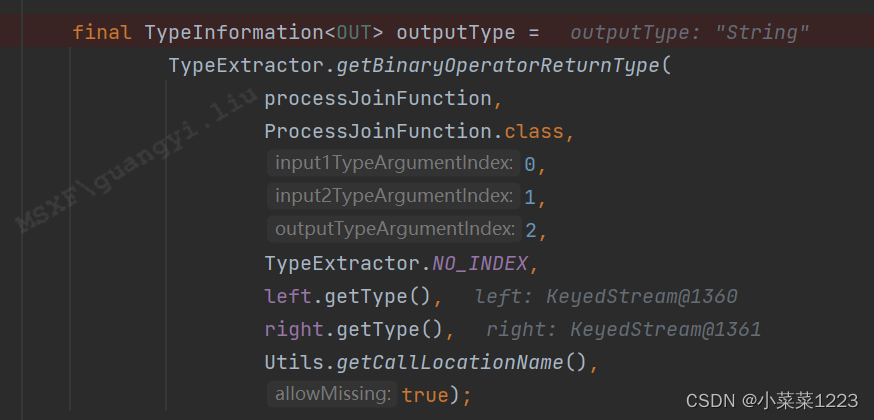
返回的outputType
 SingleOutputStreamOperator使用给定的用户函数完成联接操作,该函数针对每个联接的元素对执行。这种方法允许传递输出类型的显式类型信息。
SingleOutputStreamOperator使用给定的用户函数完成联接操作,该函数针对每个联接的元素对执行。这种方法允许传递输出类型的显式类型信息。

IntervalJoinOperator初始化
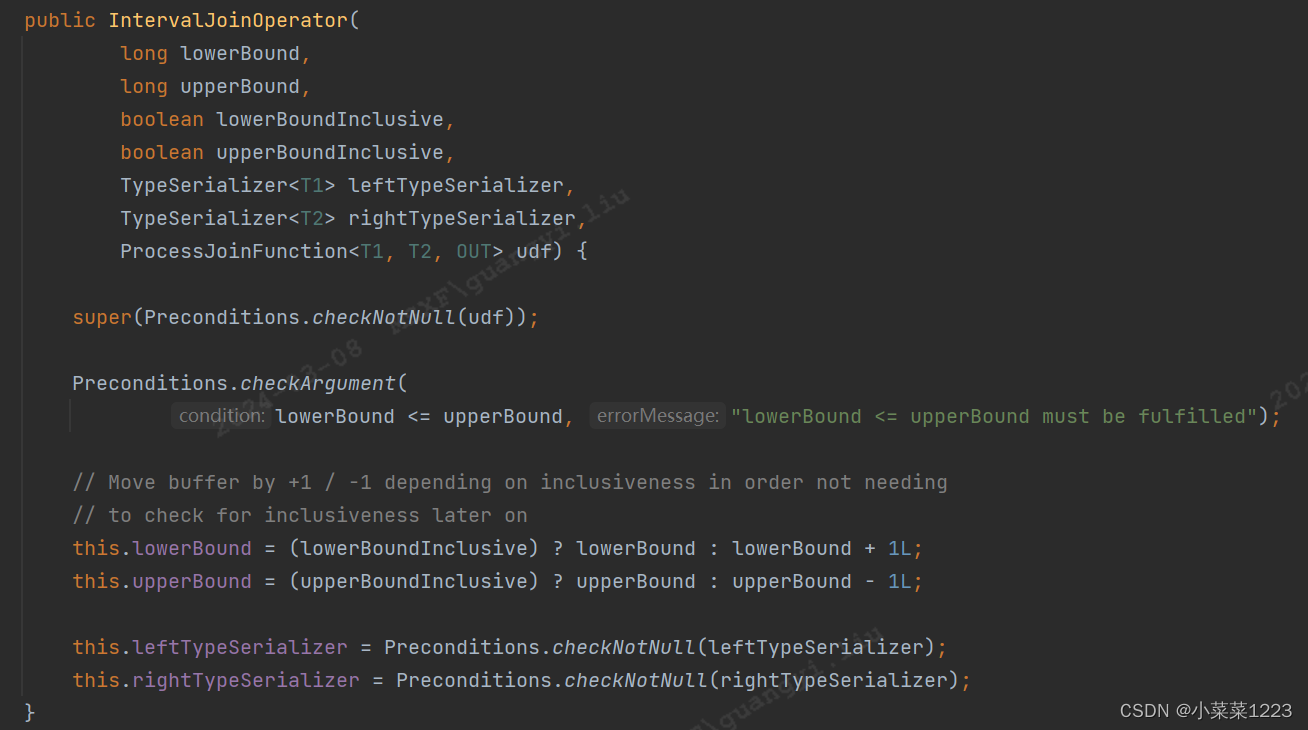
左边界<=右边界检查

获取左流还有右流数据对应的序列化(从TypeInfo获取的)

继续看IntervalJoinOperator中的其余关键实现
open方法用来注册定时器
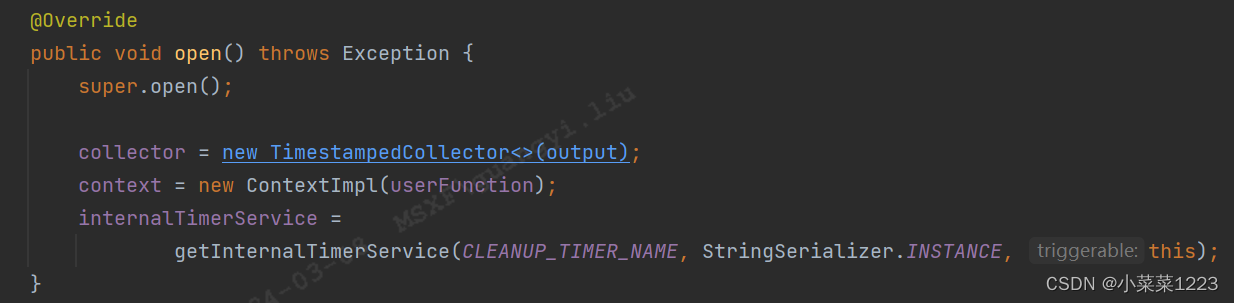
初始化两个流的map状态

处理左侧流中的数据。每当数据到达左流时,它就会被添加到左缓冲区。将从右侧缓冲区中查找该元素可能的候选联接,如果该对位于用户定义的边界内,则将其传递给 ProcessJoinFunction
 同理处理右流
同理处理右流
进入数据处理函数
获取数据,取出事件时间

超过当前watermark的数据进行过滤

数据没问题的话,将数据添加到状态

遍历另一条流的状态,遍历其中的数据,把满足时间要求的数据进行collect

注册一个当前事件时间戳+右边界的定时器

定时器触发后,清空map状态中时间戳-左边界的那条数据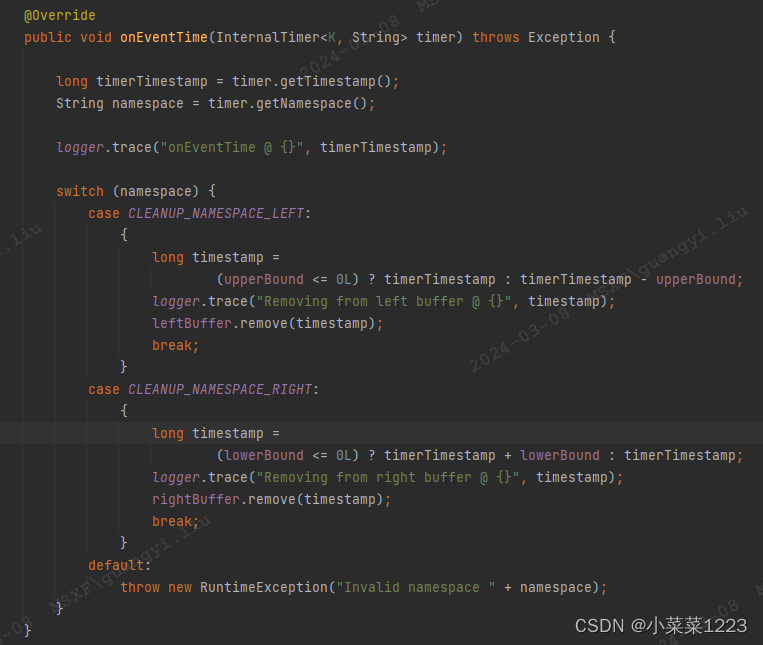
简单实例
pom
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>FlinkCode</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><jdk.version>1.8</jdk.version><jar.name>ubs-data-converter</jar.name><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><!--Flink 版本--><flink.version>1.14.4</flink.version></properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.11</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.11</artifactId><version>${flink.version}</version><exclusions><exclusion><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-runtime-web_2.11</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId><version>4.5.10</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.8</version></dependency><dependency><groupId>org.apache.avro</groupId><artifactId>avro</artifactId><version>1.9.2</version></dependency><dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpcore</artifactId><version>4.4.1</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.16</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.16</version><scope>compile</scope></dependency></dependencies><build><plugins><plugin><groupId>org.apache.avro</groupId><artifactId>avro-maven-plugin</artifactId><version>1.9.2</version><executions><execution><phase>generate-sources</phase><goals><goal>schema</goal></goals><configuration><sourceDirectory>${project.basedir}/src/main/resources/</sourceDirectory></configuration></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.1</version><configuration><source>${jdk.version}</source><target>${jdk.version}</target><encoding>${project.build.sourceEncoding}</encoding></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.1.1</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><finalName>${jar.name}</finalName><artifactSet><excludes><exclude>com.google.code.findbugs:jsr305</exclude><exclude>org.slf4j:*</exclude><exclude>log4j:*</exclude><exclude>org.glassfish.jersey.core:jersey-common</exclude></excludes></artifactSet><relocations><relocation><pattern>com.google.common</pattern><shadedPattern>com.shade.google.common</shadedPattern></relocation><relocation><pattern>org.apache.kafka</pattern><shadedPattern>org.shade.apache.kafka</shadedPattern></relocation></relocations><filters><filter><artifact>*</artifact><includes><include>org/apache/htrace/**</include><include>org/apache/avro/**</include><include>org/apache/flink/streaming/**</include><include>org/apache/flink/connector/**</include><include>org/apache/kafka/**</include><include>org/apache/hive/**</include><include>org/apache/hadoop/hive/**</include><include>org/apache/curator/**</include><include>org/apache/zookeeper/**</include><include>org/apache/jute/**</include><include>org/apache/thrift/**</include><include>org/apache/http/**</include><include>org/I0Itec/**</include><include>jline/**</include><include>com/yammer/**</include><include>kafka/**</include><include>org/apache/hadoop/hbase/**</include><include>com/alibaba/fastjson/**</include><include>org/elasticsearch/action/**</include><include>io/confluent/**</include><include>com/fasterxml/**</include><include>org/elasticsearch/**</include><include>hbase-default.xml</include><include>hbase-site.xml</include></includes></filter><filter><artifact>org.apache.hadoop.hive.*:*</artifact><excludes><exclude></exclude><exclude></exclude><exclude></exclude></excludes></filter></filters></configuration></execution></executions></plugin></plugins></build>
</project>user bean
package ubs.app.intervaljoin.bean;import lombok.*;@Data
@AllArgsConstructor
@Setter
@Getter
@NoArgsConstructor
public class User{Integer id;Long t;}
order bean
package ubs.app.intervaljoin.bean;import lombok.*;@Data
@AllArgsConstructor
@Setter
@Getter
@NoArgsConstructor
public class Order {Integer id;Long price;Long time;}main
package ubs.app.intervaljoin;import org.apache.flink.api.common.eventtime.*;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
import ubs.app.intervaljoin.bean.Order;
import ubs.app.intervaljoin.bean.User;
import ubs.app.intervaljoin.source.OrderSource;
import ubs.app.intervaljoin.source.UserSource;import java.time.Duration;public class IntervalJoinApp {public static void main(String[] args) throws Exception{StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//设置watermarkWatermarkStrategy<User> userWatermarkStrategy = WatermarkStrategy.<User>forBoundedOutOfOrderness(Duration.ofSeconds(1)).withTimestampAssigner(new SerializableTimestampAssigner<User>() {@Overridepublic long extractTimestamp(User element, long recordTimestamp) {return element.getT();}});DataStream<User> userDataStreamSource = env.addSource(new UserSource()).assignTimestampsAndWatermarks(userWatermarkStrategy);//设置watermarkWatermarkStrategy<Order> orderWatermarkStrategy = WatermarkStrategy.<Order>forBoundedOutOfOrderness(Duration.ofSeconds(1)).withTimestampAssigner(new SerializableTimestampAssigner<Order>() {@Overridepublic long extractTimestamp(Order element, long recordTimestamp) {return element.getTime();}});DataStream<Order> orderDataStreamSource = env.addSource(new OrderSource()).assignTimestampsAndWatermarks(orderWatermarkStrategy);env.setParallelism(1);SingleOutputStreamOperator<String> process = userDataStreamSource.keyBy(o -> o.getId()).intervalJoin(orderDataStreamSource.keyBy(o -> o.getId())).between(Time.seconds(-5), Time.seconds(0)).process(new ProcessJoinFunction<User, Order, String>() {@Overridepublic void processElement(User left, Order right, ProcessJoinFunction<User, Order, String>.Context ctx, Collector<String> out) throws Exception {Integer lid = left.getId();Long lt = left.getT();Integer rid = right.getId();long rt = right.getTime();out.collect(String.format("左%s 左时间%s 右%s 右时间%s 关联到了 %s", lid, lt/1000, rid, rt/1000, rt/1000-lt/1000));}});process.print();env.execute();}
}