干前端好几年了,只会前端总感觉少了条腿,处处不自在,决定今年学习下后端的东西.以前总想着学node会更快,但是实际工作上却用不上.
出来混,总是要还的,该学的javaWeb这一套体系的东西,总是需要学习的.
那就开始啦.
一,在本地电脑mac上安装mysql
这个参考的这篇文章,照着做一次就成功了.
https://zhuanlan.zhihu.com/p/168753680
二,数据库的理解
我们写代码的时候,变量一般存储在设备的内存中,浏览器的缓存中.但是这个是临时状态,一旦初始化或者刷新就会被重置.
于是我们还可以把数据存储在文件中,但是文件读写比较麻烦.并且不能多个客户端共用.
于是就想着有个远程的数据仓库,专门用来存储数据文件,这就是数据库.
三,mysql的登录
安装完成后,mysql的登录有三种方式.
mysql -u 用户名 -p 密码
mysql -hip地址 -u 用户名 -p 密码
mysql --host=ip地址 --user=用户名 --password=密码
四,数据库的基本理解
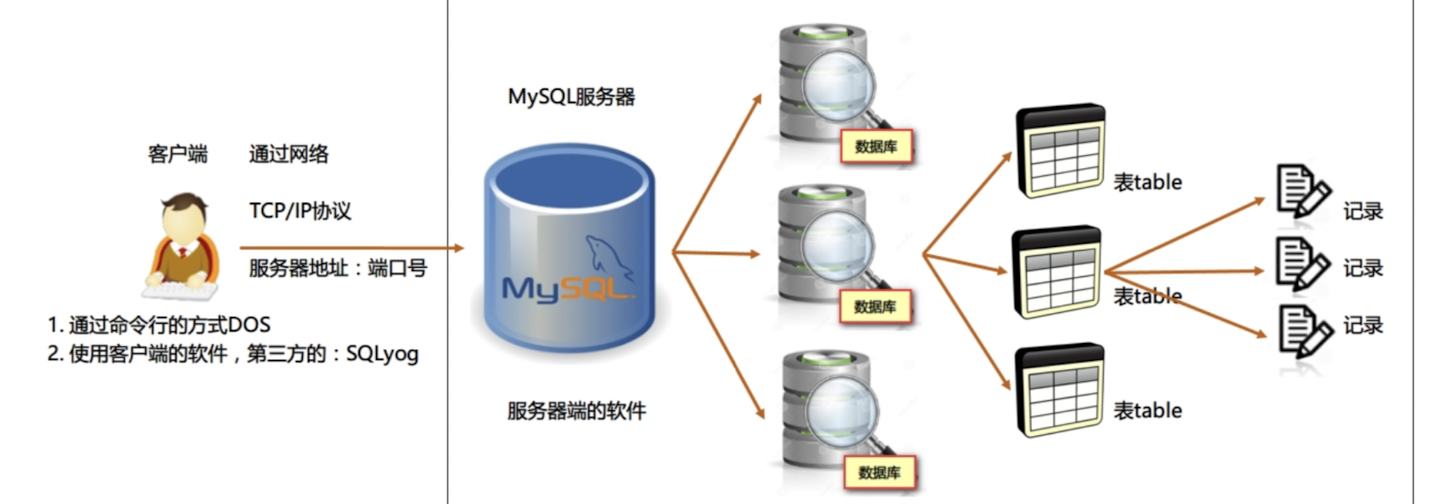
首先要理解数据库服务器-数据库-数据表-数据记录之间的关系.大概可以用下图来理解:
五,操作数据库
在sql的语法中,注释是--,一个语句的结束是分号.
5.1,创建数据库
--创建数据库
create database 数据库名;
--判断如果不存在则创建数据库
create database if not exists 数据库名;
5.2,查看数据库
show databases;
5.3,删除数据库
drop database 数据库名;
5.4,使用数据库
--查看正在使用的数据库
select database();
--选择使用某一个数据库
use 数据库名;
六,操作数据表
前提是已经确定使用哪个数据库.
--创建表(常用字段类型有int\double\varchar\date)
create table 表名(字段名1 字段类型1,字段名2 字段类型2
)
--查看数据库中的所有表
show tables;
--查看表结构
desc 表名;
--查看某个表创建该表的SQL语句
show create table 表名;
--快速创建一个表结构相同的表
create table 新表名 like 旧表名;
--直接删除表
drop table 表名;
--判断表是否存在,如果存在则删除表
drop table if exists 表名;
--修改表名
rename table 表名 to 新表名;
--添加表列
alter table 表名 add 列名 类型;
例子:
ALTER TABLE mytable
ADD COLUMN id INT,
ADD COLUMN age INT,
ADD COLUMN name VARCHAR(255);
--修改列的类型
alter table 表名 modify 列名 新的数据类型;
--修改列名
alter table 表名 change 旧列名 新列名 类型;
--删除列
alter table 表名 drop 列名;
--查看数据的表结构
SHOW COLUMNS FROM table_name;
七,数据表的操作
用于对数据表记录进行增删改查
--插入记录(没有添加数据的字段会填充null)
insert into 表名 (字段1,字段2,字段3) values (值1,值2,值3);
--更新表记录(如果不带筛选,就是修改全部)
update 表名 set 列名1=值1,列名2=值2 [where 条件表达式]
例如:update student set age=26,address='北京' where id=3;
--删除表记录(没添加表名则全部删除)
delete from 表名 [where 条件表达式]
--查询表中的数据
select 列名 from 表名 [where 条件表达式]
--查询所有列的数据(使用select *)
select * from 表名 [where 条件表达式];
--查询指定列的数据,多个列用逗号隔开
select 字段名1,字段名2,字段名3 from 表名 [where 条件表达式];
--查询制定列并且结果不出现重复数据
select distinct 字段名 from 表名;
有的时候会增加where条件查询,常见的运算符有:
比较运算符:>,<,<=,>=,=,<>
范围运算符:between…and,包含头尾
in(集合):集合表示多个值,使用逗号分隔
like '张%':模糊查询,_表示一个字符,%表示任意多个字符
is null:查询某一列的值是null,注:不能写=null
and:与
or:或
not:非
例子:
select * from student where id in (1,2,3);
八,mysql的约束与设计
--使用order by来进行排序显示
select 字段名 from 表名 where 筛选条件 order by 字段名 [ASC|DESC];
--asc升序,desc降序
--示例
select * from student order by age desc;
8.1,单列排序
只对其中一个字段进行排序.
select * from student order by age desc;
8.2,组合排序
组合排序主要适用于前面的排序有相等的情况,比如先按年龄排序,年龄相同了在以数学成绩升序排列.
select * from student order by age desc, math asc;
8.3,聚合函数
之前做的查询都是一行一行的查询,聚合函数主要的作用就是一列列合并计算,比如计算所有记录的人数这个字段的总和.聚合函数会忽略空值null,常用的聚合函数有以下几个
max(列名)
min(列名)
avg(列名)
count(列名)
sum(列名)
--示例:年龄总和
select sum(age) as 总年龄 from mytable;
因为null会被忽略,所以需要利用ifnull函数,把null值给个默认值.
select sum(ifnull(age)) from student;
8.4,分组
group by 分组字段是将分组字段中的相同内容作为一组,并且返回每一组的第一条数据,常常和聚合函数一起使用.
例如按照男女性别进行分组,最后分别统计成绩平均数:
select sex,avg(math) from student3 group by sex;
值得注意的是,group by后面不能用where,而是可以使用having,也就是先分组,后过滤数据.
8.5,limit的作用
数据准备,新建表:
create table students(id int,NAME varchar(10),age int,sex varchar(10),address varchar(10),math int,english int)
初始化数据
INSERT INTO students(id,NAME,age,sex,address,math,english) VALUES (9,'唐僧',25,'男','长安',87,78), (10,'孙悟空',18,'男','花果山',100,66), (11,'猪八戒',22,'男','高老庄',58,78), (12,'沙僧',50,'男','流沙河',77,88),(13,'白骨精',22,'女','白虎岭',66,66), (14,'蜘蛛精',23,'女','盘丝洞',88,88);
limit的作用就是限制查询记录的条数.
SELECT *|字段列表 [as 别名] FROM 表名 [WHERE 子句] [GROUP BY 子句][HAVING 子句][ORDER BY 子 句][LIMIT 子句];
limit的语法:limit offset,length;
--查询学生表中的数据,从第三条开始,显示4条.
select * from students limit 2,4;
九,数据库的备份与还原
9.1,备份格式
DOS下,未登录的时候,这是一个可执行文件exe,在bin文件夹:
mysqldump -u root -p 数据库名 >/Users/mac名字/Desktop/test.sql
如果报错可以看这篇博客:https://blog.csdn.net/lxf3887125/article/details/125335957
这样桌面就会生成一个sql文件.
9.2,还原格式
执行上文生成的mysql文件,这个需要登录mysql.
show databases;
use 数据库;
source 导入文件的路径;
--source /Users/huangchuanbiao/Desktop/test.sql
十,数据库表的约束
对表中数据进行约束,用来保证数据的正确性有效性和完整性.约束在创建表的时候添加比较合适.
约束的种类主要有以下几种:
主键:primary key
唯一:unique
非空:not null
外键:foreign key
检查约束:check (mysql不支持)
10.1,主键约束
主键的作用:用来唯一标识数据库中的每一条记录,主键只能有一个
主键的选择:不用业务字段,因为主键是给程序和数据库使用的
主键的创建(将该字段作为主键):
----在创建表的时候给字段添加主键:字段名 字段类型 primary key
----在已有表中添加主键:alter table 表名 add primary key(字段名)
删除主键:alter table 表名 drop primary key;
主键自增:auto_increment-默认的开始值是1
----设置起始值
----create table 表名(字段名 类型 primary key auto_increment
)auto_increment=起始值
创建完毕后修改起始值:alter table 表名 auto_increment=新的起始值
delete和truncate的区别:前者自增长无影响,后者自增长重置
10.2,唯一约束
唯一约束是针对字段名而言的,也就是不允许该表在该字段有多条相同的记录.
字段名 类型 unique
----不许出现同名的学生
create table student(id int,name varchar(5) unique
)
10.3,非空约束
非空约束就是限定该表中的某一字段不能是null值.或者给定一个默认值.
字段名 类型 not null
--创建表,并且设置name不能为null
create table student(id int,name varchar(5) not null
)
字段名 类型 default 默认值
--创建表,并且设置name默认值为:孙悟空
create table student(id int,name varchar(5) default '孙悟空'
)
10.4,外键约束
数据准备,创建一个员工表并添加数据:
CREATE TABLE emp (id INT PRIMARY KEY AUTO_INCREMENT,NAME VARCHAR(30),age INT,dep_name VARCHAR(30),dep_location VARCHAR(30)
);
-- 添加数据
INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('张三', 20, '研发部', '广州'); INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('李四', 21, '研发部', '广州'); INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('王五', 20, '研发部', '广州');
INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('老王', 20, '销售部', '深圳'); INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('大王', 22, '销售部', '深圳'); INSERT INTO emp (NAME, age, dep_name, dep_location) VALUES ('小王', 18, '销售部', '深圳');
可以看到有很多数据是重复的,比如部门都是研发部,地点都是广州.
于是可以考虑创建两张表,一个员工表,一个部门表.员工表用一个dep_id来连接部门表.
-- 解决方案:分成 2 张表
-- 创建部门表(id,dep_name,dep_location)
-- 一方,主表
create table department(id int primary key auto_increment,dep_name varchar(20),dep_location varchar(20)
);
-- 创建员工表(id,name,age,dep_id)
-- 多方,从表
create table employee(
id int primary key auto_increment, name varchar(20),
age int,
dep_id int -- 外键对应主表的主键
)
-- 添加2个部门
insert into department values(null, '研发部','广州'),(null, '销售部', '深圳'); select * from department;
-- 添加员工,dep_id 表示员工所在的部门
INSERT INTO employee (NAME, age, dep_id) VALUES ('张三', 20, 1);
INSERT INTO employee (NAME, age, dep_id) VALUES ('李四', 21, 1); INSERT INTO employee (NAME, age, dep_id) VALUES ('王五', 20, 1);
INSERT INTO employee (NAME, age, dep_id) VALUES ('老王', 20, 2); INSERT INTO employee (NAME, age, dep_id) VALUES ('大王', 22, 2); INSERT INTO employee (NAME, age, dep_id) VALUES ('小王', 18, 2);
select * from employee;
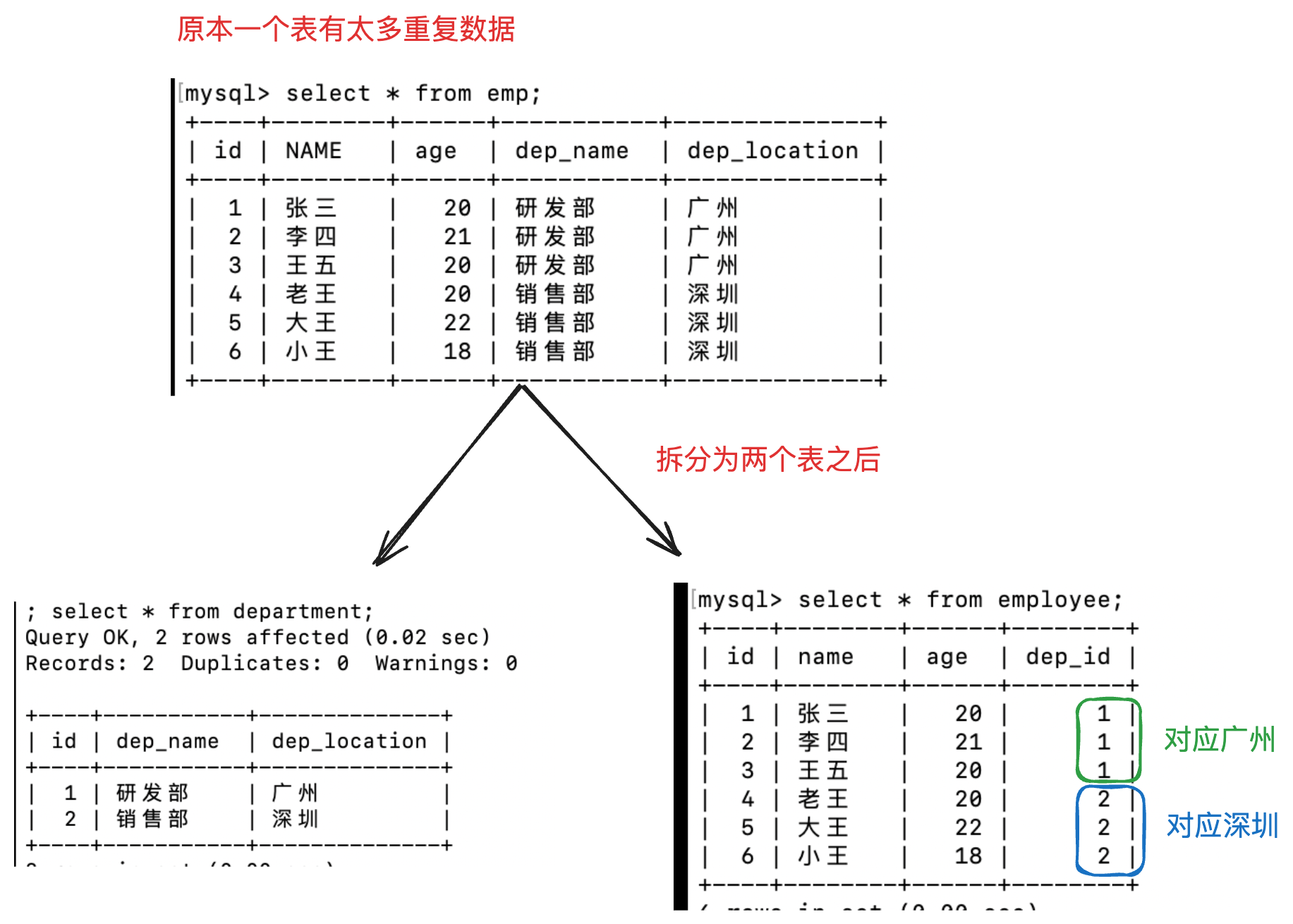
现在新的问题又出现了,employee中的dep_id不应该加入除了12的值,因为否则department中没有对应的部门了.
这时候,就需要引入外键约束,让dep_id和deparment表中的id联系起来.
外键约束的定义:
外键约束:从表中与主表主键对应的那一列
主表:一方,用来约束别人的表
从表/副表:多方,被别人约束的表

添加外键:
--创建新表时
constraint [外键约束名称(后续指代这个外键)] foreign key (外键字段名,从表中) references 主表名(主键字段名主表中)
--已有的表中新增
alter table 从表 add constraint [外键约束名称(后续指代这个外键)] foreign key (外键字段名) referenecs 主表名(主键字段名);
我们可以新建一个从表:
create table employee2(id int primary key auto_increment,name varchar(20),age int,dep_id int,constraint emp_depid_fk foreign key (dep_id) references department(id)
);
然后正常新增数据,显示正常:
INSERT INTO employee2 (NAME, age, dep_id) VALUES ('张三', 20, 1);
INSERT INTO employee2 (NAME, age, dep_id) VALUES ('李四', 21, 1);
INSERT INTO employee2 (NAME, age, dep_id) VALUES ('王五', 20, 1);
INSERT INTO employee2 (NAME, age, dep_id) VALUES ('老王', 20, 2);
INSERT INTO employee2 (NAME, age, dep_id) VALUES ('大王', 22, 2);
INSERT INTO employee2 (NAME, age, dep_id) VALUES ('小王', 18, 2);
但是如果新增不正常的数据,则会报错:
INSERT INTO employee2 (NAME, age, dep_id) VALUES ('小王', 18, 6);

删除外键
alter table 从表 drop foreign key 外键名称;
例如现在我需要把从表的外键dep_id删除,则如下:
alter table employee2 drop foreign key emp_depid_fk;
于是又出现了新的问题,当我们已经拥有了外键,而主表的主键的值要是发生了变更怎么办?因为这时候从表中的外键还是依赖的这个值,这样贸然变更必然有问题.
也就是说主表的主键不能随意变更或删除(从表的外键还依赖于它)
于是就有了级联操作:在更新或删除主表的主键时,会更新从表的外键值.
级联操作需要在创建表声明外键约束的时候就特别声明,主要有以下两种:
on update cascade:级联更新
on delete cascade:级联删除
于是创建新的从表声明外键就变成:
create table employee(id int primary key auto_increment, name varchar(20),age int,dep_id int, -- 外键对应主表的主键-- 创建外键约束constraint emp_depid_fk foreign key (dep_id) referencesdepartment(id) on update cascade on delete cascade
)
十一,表与表之间的关系
表与表之间常见的有以下三种关系:
一对多:部门和员工
多对多:学生选课表和学生表
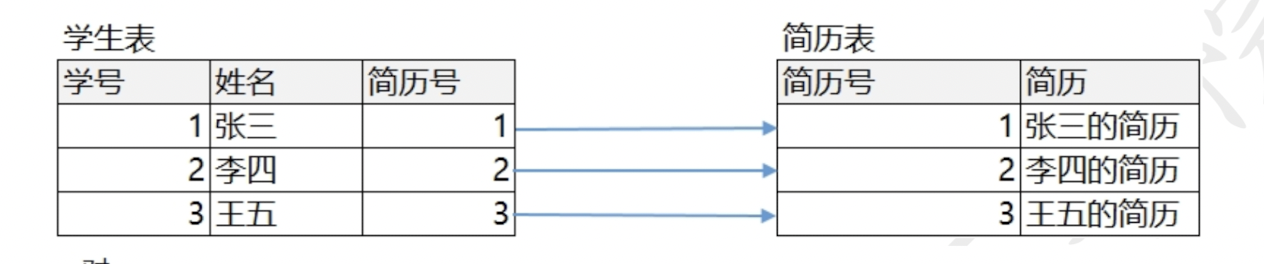
一对一:员工表和简历表
11.1,一对多
一对多的建表原则:从表(多方)创建一个字段,该字段作为外键指向主表(一方).
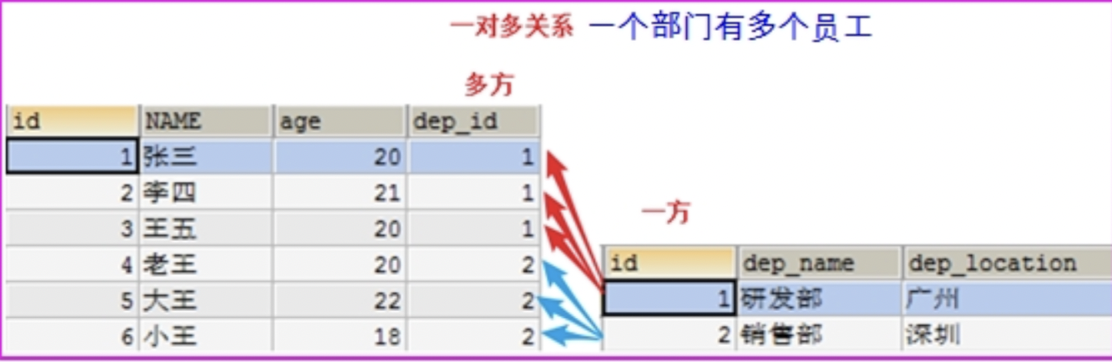
示例:一个旅游分类学下有多条线路:
-- 创建旅游线路分类表 tab_category -- cid 旅游线路分类主键,自动增长
-- cname 旅游线路分类名称非空,唯一,字符串 100 create table tab_category (cid int primary key auto_increment,cname varchar(100) not null unique
)
-- 添加旅游线路分类数据:
insert into tab_category (cname) values ('周边游'), ('出境游'), ('国内游'), ('港澳游');
select * from tab_category;
-- 创建旅游线路表 tab_route
/*
rid 旅游线路主键,自动增长
rname 旅游线路名称非空,唯一,字符串 100 price 价格
rdate 上架时间,日期类型 cid 外键,所属分类
*/
create table tab_route(rid int primary key auto_increment,rname varchar(100) not null unique,price double,rdate date,--创建外键cid int,--声明外键foreign key (cid) references tab_category(cid)
)
-- 添加旅游线路数据
INSERT INTO tab_route VALUES
(NULL, '【厦门+鼓浪屿+南普陀寺+曾厝垵 高铁 3 天 惠贵团】尝味友鸭面线 住 1 晚鼓浪屿', 1499, '2018-01-27', 1),
(NULL, '【浪漫桂林 阳朔西街高铁 3 天纯玩 高级团】城徽象鼻山 兴坪漓江 西山公园', 699, '2018-02- 22', 3),
(NULL, '【爆款¥1699 秒杀】泰国 曼谷 芭堤雅 金沙岛 杜拉拉水上市场 双飞六天【含送签费 泰风情 广州 往返 特价团】', 1699, '2018-01-27', 2),
(NULL, '【经典•狮航 ¥2399 秒杀】巴厘岛双飞五天 抵玩【广州往返 特价团】', 2399, '2017-12-23', 2),
(NULL, '香港迪士尼乐园自由行2天【永东跨境巴士广东至迪士尼去程交通+迪士尼一日门票+香港如心海景酒店 暨会议中心标准房1晚住宿】', 799, '2018-04-10', 4);
select * from tab_route;
11.2,多对多
例如学生和课程表的关系.一门课可以被多名学生选择,一个学生也可以选择多个课程.这时候,就需要一个中间表来记录这种关系.
中间表至少包含两个字段,这两个字段分别作为外键指向各自的主键.
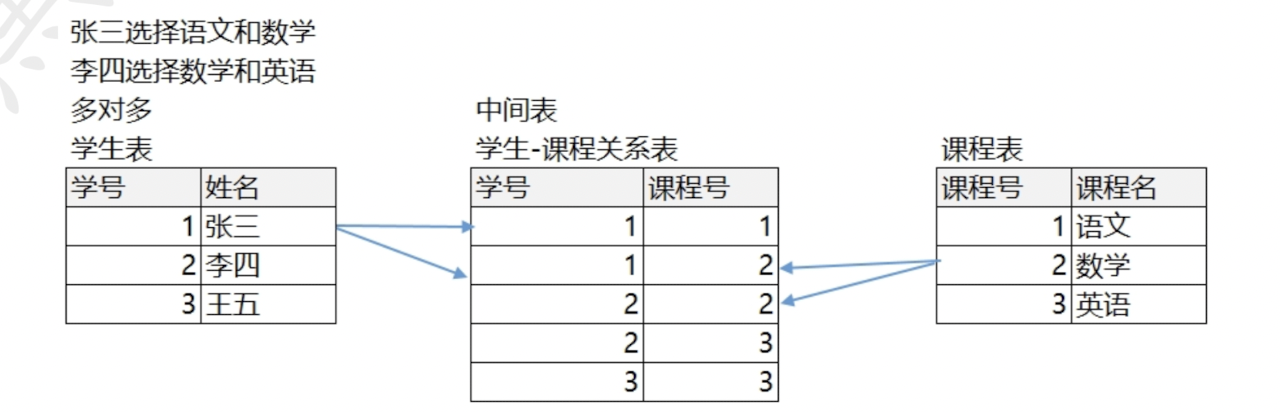
示例:一个用户收藏多个线路,一个线路被多个用户收藏
创建用户表 tab_user
uid 用户主键,自增长
username 用户名长度 100,唯一,非空 password 密码长度 30,非空
name 真实姓名长度 100
birthday 生日
sex 性别,定长字符串 1
telephone 手机号,字符串 11
email 邮箱,字符串长度 100
*/
create table tab_user (uid int primary key auto_increment,username varchar(100) unique not null,password varchar(30) not null,name varchar(100),
birthday date,
sex char(1) default '男',telephone varchar(11),email varchar(100)
)
-- 添加用户数据
INSERT INTO tab_user VALUES
(NULL, 'cz110', 123456, '老王', '1977-07-07', '男', '13888888888', '66666@qq.com'), (NULL, 'cz119', 654321, '小王', '1999-09-09', '男', '13999999999', '99999@qq.com');
select * from tab_user;
/*
创建收藏表 tab_favorite rid 旅游线路 id,外键
date 收藏时间 uid 用户 id,外键
rid 和 uid 不能重复,设置复合主键,同一个用户不能收藏同一个线路两次 */
create table tab_favorite (
rid int,
date datetime,
uid int,
-- 创建复合主键
primary key(rid,uid),
foreign key (rid) references tab_route(rid), foreign key(uid) references tab_user(uid)
)
-- 增加收藏表数据
INSERT INTO tab_favorite VALUES(1, '2018-01-01', 1), -- 老王选择厦门 (2, '2018-02-11', 1), -- 老王选择桂林 (3, '2018-03-21', 1), -- 老王选择泰国 (2, '2018-04-21', 2), -- 小王选择桂林 (3, '2018-05-08', 2), -- 小王选择泰国 (5, '2018-06-02', 2); -- 小王选择迪士尼
select * from tab_favorite
11.3,一对一
实际上一对一见的不多,因为可以合并成一个表.