来源:机器之心
当前,大型语言模型的性能已经达到了很高的水平,除了进一步挖掘其潜力,我们还应该关注到模型背后的人工标注成本。
ChatGPT 是今年年底 AI 圈的新晋顶流,人们惊叹于它强大的问答语言能力和掌握的编程知识。但越是强大的模型,其背后的技术要求也就越高。
ChatGPT 是在 GPT 3.5 系列模型的基础上,引入「人工标注数据 + 强化学习」(RLHF)来不断微调预训练语言模型,旨在让大型语言模型(LLM)学会理解人类的命令,并学会根据给定的 prompt 给出最优的答案。
这种技术思路是当前语言模型的发展趋势。这类模型虽然很有发展前景的,但模型训练和微调所需的成本非常高。
根据 OpenAI 目前公开的信息,ChatGPT 的训练过程共分为三个阶段:
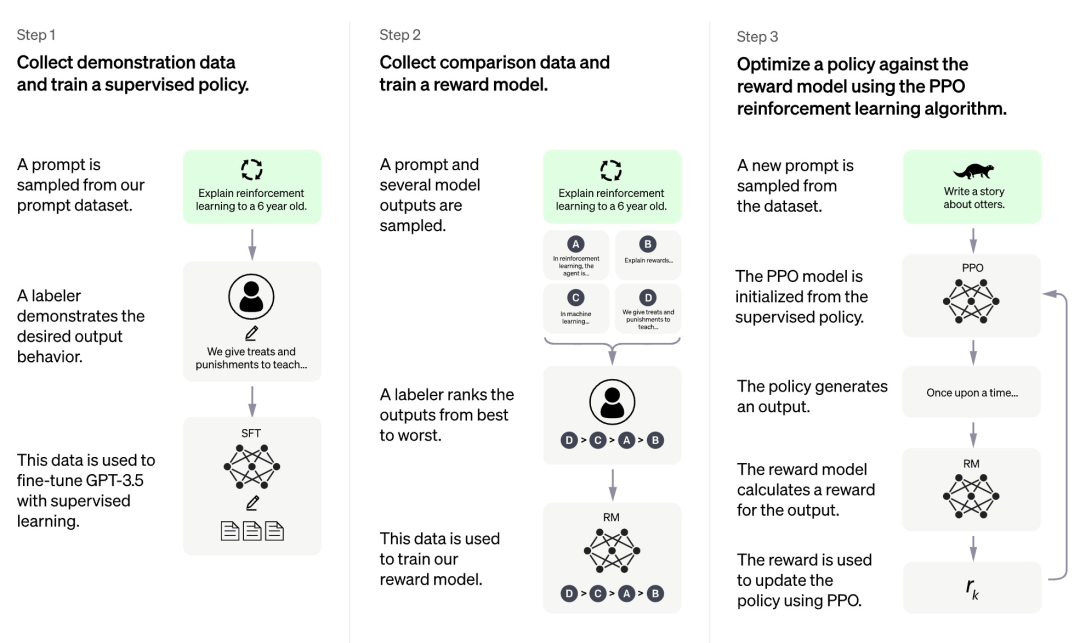
首先,第一个阶段是类似于 GPT 3.5 的有监督策略模型,这个基础模型很难理解人类不同类型指令中蕴含的意图,也很难判断生成内容的质量高低。研究人员从 prompt 数据集中随机抽取了一些样例,然后让专业的标注人员根据指定 prompt 给出高质量的答案。这个人工过程获得的 prompt 及其相应高质量答案被用于微调初始的有监督策略模型,使其具备基本的 prompt 理解能力,并初步提高生成答案的质量。
第二阶段研究团队抽取模型根据给定 prompt 生成的多个输出,然后让人类研究员对这些输出进行排序,再用排序数据训练奖励模型(reward model,RM)。ChatGPT 采取 pair-wise loss 来训练 RM。
第三阶段研究团队采用强化学习来增强预训练模型的能力,利用上一阶段学好的 RM 模型来更新预训练模型参数。
我们可以发现,在 ChatGPT 训练的三个阶段中,只有第三阶段不需要使用人工标注数据,而第一第二阶段都需要大量的人工标注。因此 ChatGPT 这类模型虽然性能很好,但是为了提高其遵循指令的能力,人工成本非常高。随着模型规模越来越大,能力范围越来越广,这个问题就会越发严重,最终成为阻碍模型发展的瓶颈。
一些研究尝试提出解决这一瓶颈的方法,比如华盛顿大学等机构近期联合发表了一篇论文《SELF-INSTRUCT: Aligning Language Model with Self Generated Instructions》,提出的新框架 SELF-INSTRUCT 通过引导模型自己的生成过程,提高了预训练语言模型的指令遵循能力。

论文地址:https://arxiv.org/pdf/2212.10560v1.pdf
SELF-INSTRUCT 是一种半自动化过程,使用来自模型本身的指令信号对预训练的 LM 进行指令调整。如下图所示,整个过程是一个迭代引导算法。
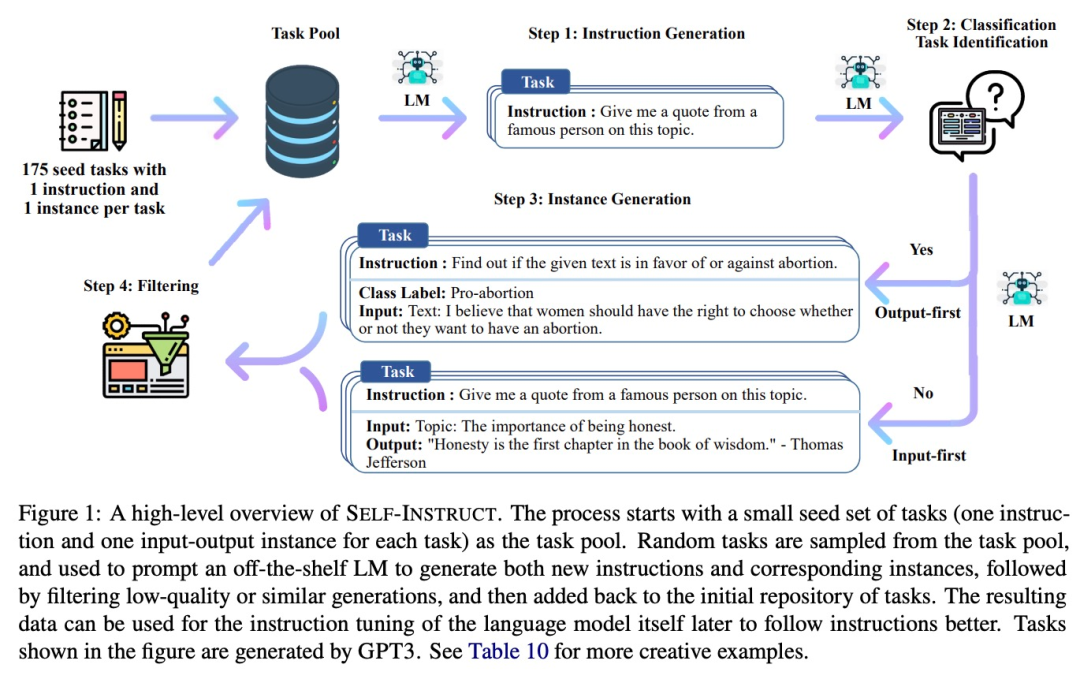
SELF-INSTRUCT 从有限的种子集开始,指导整个生成过程的手动编写指令。在第一阶段,模型被 prompt 成为新任务生成指令,该步骤是利用现有的指令集来创建更广泛的指令,以此来定义新任务。SELF-INSTRUCT 还为新生成的指令集创建输入输出实例,以用于监督指令调整。最后,SELF-INSTRUCT 还对低质量和重复指令进行修剪。整个过程是反复迭代执行的,最终模型能为大量任务生成指令。
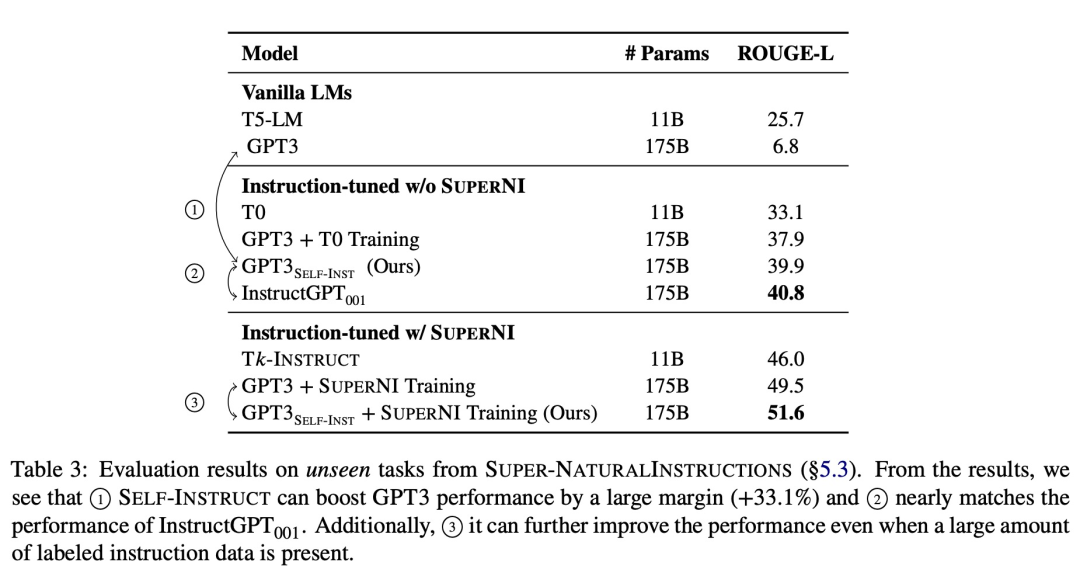
为了验证新方法的有效性,该研究在 GPT-3 上应用 SELF-INSTRUCT 框架,最终产生大约 52k 条指令,82k 实例输入和目标输出。研究者观察到 GPT-3 在 SUPER-NATURALINSTRUCTIONS 数据集中的新任务上比原始模型获得了 33.1% 的绝对改进,与使用私人用户数据和人工标注训练的 InstructGPT_001 性能相当。
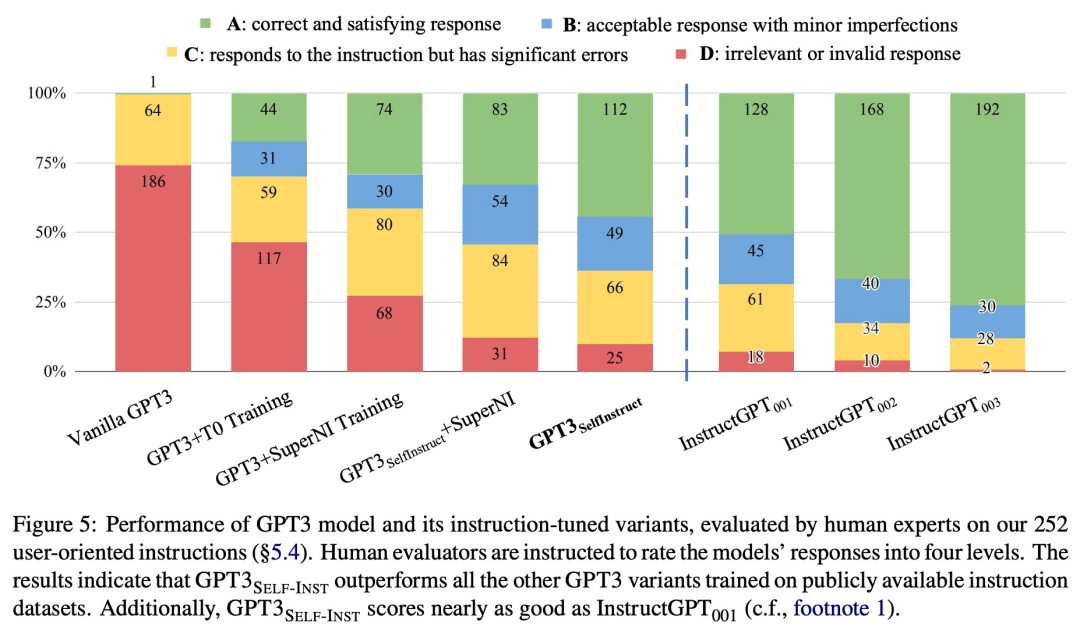
为了进一步评估,该研究为新任务整理了一组专家编写的指令,并通过人工评估表明,使用 SELF-INSTRUCT 的 GPT-3 性能会大大优于现有使用公共指令数据集的模型,并且仅比 InstructGPT_001 落后 5%。
SELF-INSTRUCT 提供了一种几乎不需要人工标注的方法,实现了预训练语言模型与指令对齐。已有多个工作在类似的方向上做出尝试,都收获了不错的结果,可以看出这类方法对于解决大型语言模型人工标注成本高的问题非常有效。这将让 ChatGPT 等 LLM 变得更强,走得更远。
参考链接:
https://zhuanlan.zhihu.com/p/589533490
https://openai.com/blog/chatgpt/
推荐阅读
西电IEEE Fellow团队出品!最新《Transformer视觉表征学习全面综述》
润了!大龄码农从北京到荷兰的躺平生活(文末有福利哟!)
如何做好科研?这份《科研阅读、写作与报告》PPT,手把手教你做科研
一位博士在华为的22年
奖金675万!3位科学家,斩获“中国诺贝尔奖”!
又一名视觉大牛从大厂离开!阿里达摩院 XR 实验室负责人谭平离职
最新 2022「深度学习视觉注意力 」研究概述,包括50种注意力机制和方法!
【重磅】斯坦福李飞飞《注意力与Transformer》总结,84页ppt开放下载!
2021李宏毅老师最新40节机器学习课程!附课件+视频资料
欢迎大家加入DLer-计算机视觉技术交流群!
大家好,群里会第一时间发布计算机视觉方向的前沿论文解读和交流分享,主要方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如图像分类+上交+小明)

👆 长按识别,邀请您进群!