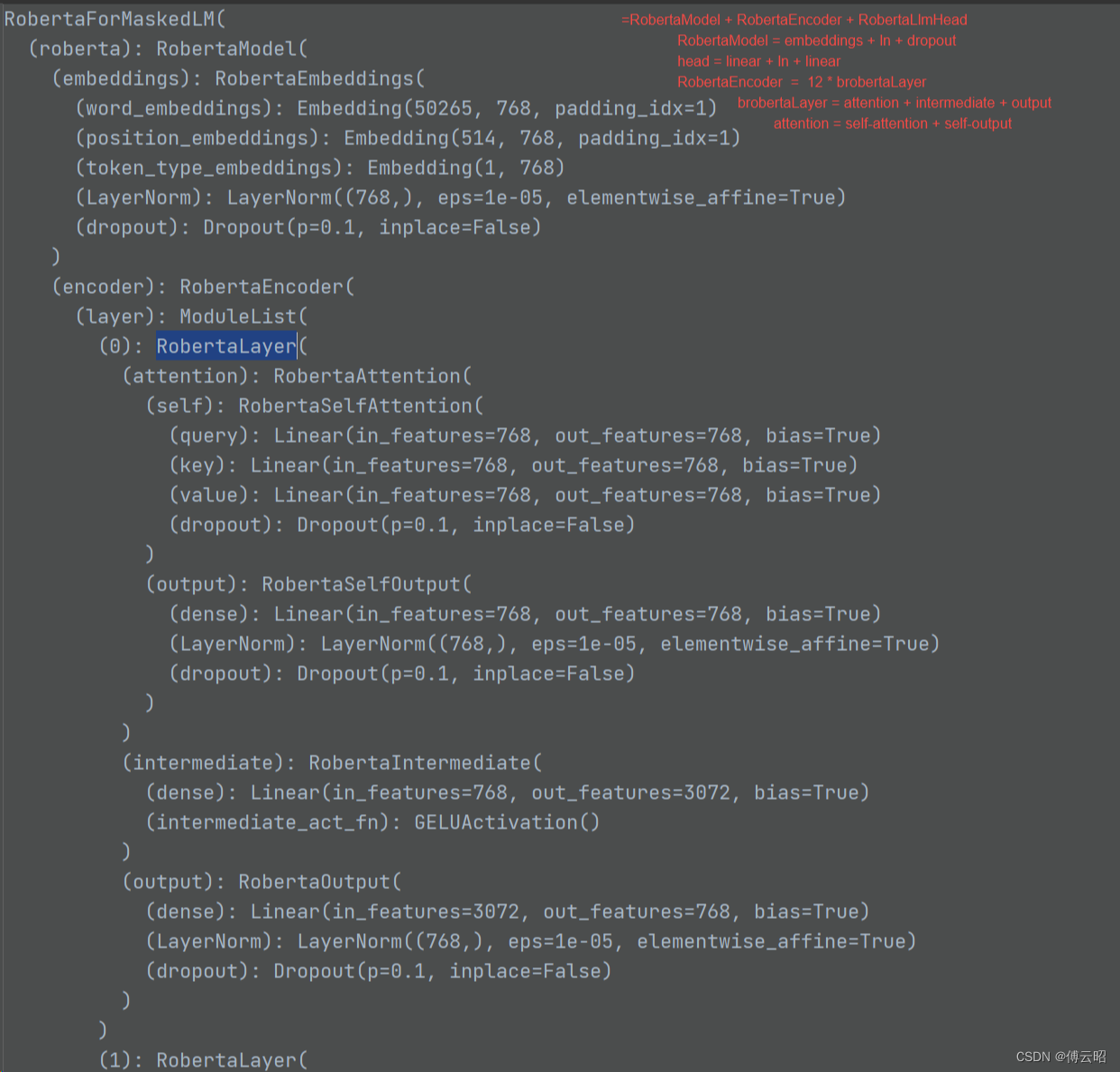
一、数据仓库架构
1、数据仓库的概念
数据仓库(Data Warehouse)是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。
数据仓库通常包含多个来源的数据,这些数据按照主题进行组织和存储,以便于分析和报告。数据仓库中的数据一般不再进行更新或删除操作,而是存储历史数据,以便进行历史趋势分析或进行数据挖掘。数据仓库的设计和实施需要考虑数据的安全性、完整性和准确性,以及如何有效地检索和呈现数据。数据仓库是BI(商业智能)系统的核心,它不仅存储数据,还提供数据管理、分析和报告的功能。
2、关系性数据库和数据仓库
OLTP:OLTP系统通常面向的主要数据操作是随机读写,主要采用满足3NF的实体关系模型存储数据,从而在事务处理中解决数据冗余和一致性问题;主要适用于传统关系型数据库;
OLAP:OLAP系统面向的主要的操作是数据的批量读写,事务处理过程中的一致性不是OLAP关注的,其主要关注数据的整合,以及在一次性的复杂大数据查询中和处理中的性能,因此会采用一些不同的建模方法。
注:3NF 三范式
第一范式:原子性,确保数据库表的每一列都是不可分割的原子数据项,即列中的数据要么是一个整体,要么是单独的元素
第二范式:唯一性,在满足第一范式的基础上,消除非主键列对主键的部分依赖。即非主键列必须直接依赖于主键,不能间接依赖于主键。
第三范式:传递性,在满足第二范式的基础上,消除非主键列之间的传递依赖。即如果非主键列依赖于其他非主键列,则必须将这些非主键列移至新的表中。
3、数据仓库架构
3.1数仓基本架构

3.2数据仓库分层的好处
1. 清晰数据结构:每一个数据分层都有它的作用域,在使用表的时候能更方便地定位和理解。
2. 统一数据口径:通过数据分层,提供统一的数据出口,统一对外输出的数据口径。
3. 减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。
4. 把复杂问题简单化:将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,而且便于维护数据的准确性。且以空间换时间;
4、数据仓库规范
可参考MaxCompute数据仓库的公共规范_云原生大数据计算服务 MaxCompute(MaxCompute)-阿里云帮助中心
二、数据采集
1、同步方式
1.1 批量同步
1.2 实时同步
2、数据同步解决方案
2.1分库分表的处理
2.2 高效同步和批量同步
2.3 增量同步和全量同步的合并
2.4 同步性能的处理
2.5 数据漂移的处理
数据漂移通常是指ODS表在同一个业务日期数据中包含前一天或后一天凌晨附近的数据或者丢失当天变更的数据,也称作零点漂移。
2.5.1数据漂移的原因
由于ODS需要承接面向历史的细节数据查询需求,这就需要物理落地到数据仓库ods层的表按照时间段来切分分区进行存储,通常做法事按照某些时间戳字段进行切分,而实际上由于时间戳字段的准确性问题导致了数据发生漂移。一般来说数据库会有以下时间戳字段:
数据创建时间 create_time
数据更新时间 modified_time
数据日志时间 log_time
业务时间 process_time
数据抽取时间 extract_time
理论上这几个时间是同一天是一致的,但是实际生产中,这几个时间往往存在差异,主要原因可能是:
①由于数据抽取是需要时间的,extract_time往往会晚于其他时间;
②前台业务系统手工订正数据时未更新modified_time;
③由于网络或者系统压力问题,log_time或者modified_time晚于process_time
2.5.2数据漂移的场景
①
2.5.3数据漂移的处理方法
①
3、数据同步工具的使用
三、离线开发
thread.sleep(9)
四、实时开发
thread.sleep(8)
五、数据建模
thread.sleep(7)
六、维度建模
thread.sleep(6)
七、事实表设计
thread.sleep(5)
八、数据管理
thread.sleep(4)
九、数据治理
thread.sleep(3)
十、数据服务
thread.sleep(2)