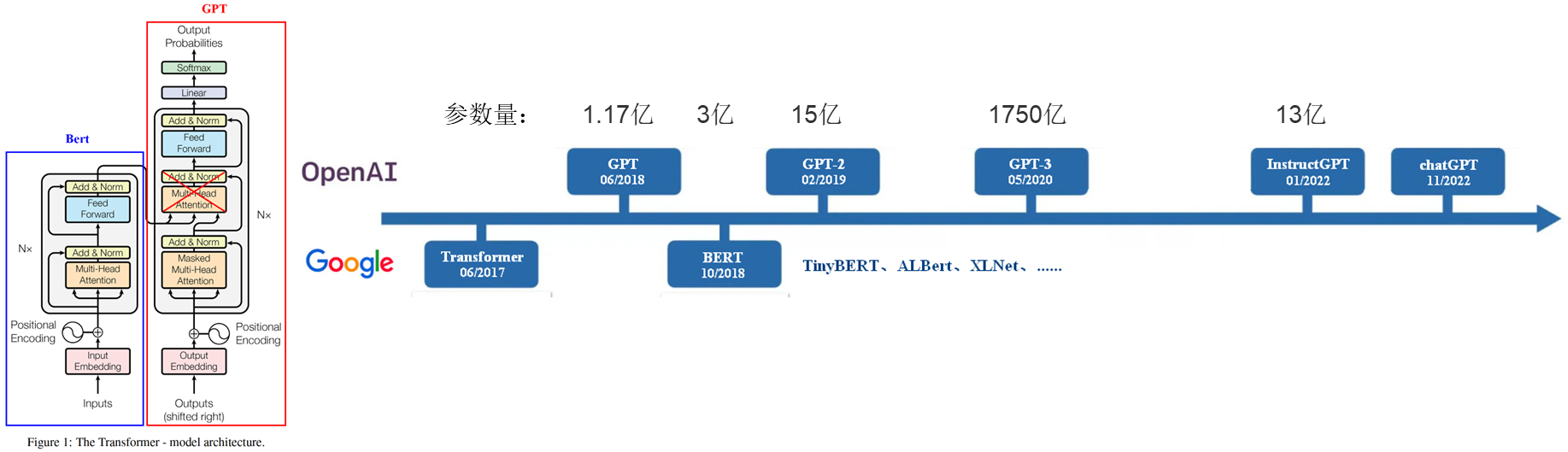
GPT1:Imporoving Language Understanding By Generative Pre-training
GPT2:Lanuage Models Are Unsupervised Multitask Learners
GPT3:Language Models Are Few-shot Learners
GitHub:https://github.com/openai/gpt-3
从GPT三个版本的论文名也能看出各版本模型的重点:
- GPT1:强调预训练
- GPT2:强调Unsupervised Multitask就是说下游任务fintune的时候不用重新调整模型结构了
- GPT3:强调Few-shot 就是连finetune都剩了,巨大的参数空间,可以直接few-shot甚至zero-shot
ChatGPT一夜走红,它会成为下一代搜索引擎吗?