目录
一、实验目的
二、实验准备
三、实验内容
1. 数据操作
2. 数据预处理
3. 线性代数
4. 微积分
5. 自动微分
四、实验心得
一、实验目的
(1)正确理解深度学习所需的数学知识;
(2)学习一些关于数据的实用技能,包括存储、操作和预处理数据;
(3)能够完成各种数据操作,存储和操作数据;
(4)PyTorch基础,完成《动⼿学深度学习》预备知识2.1-2.5节的课后练习。
二、实验准备
(1)根据GPU安装pytorch版本实现GPU运行实验代码;
(2)配置环境用来运行 Python、Jupyter Notebook和相关库等相关库。
三、实验内容
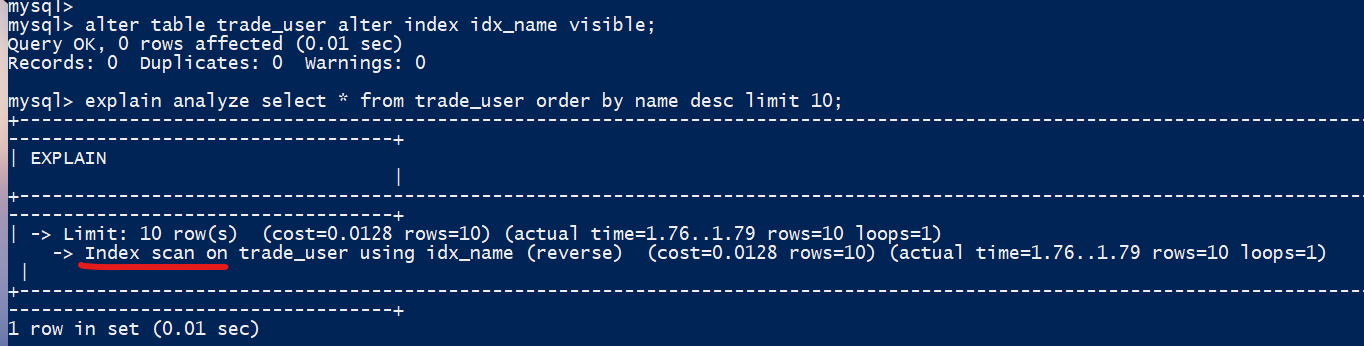
启动jupyter notebook,使用新增的pytorch环境新建ipynb文件,为了检查环境配置是否合理,输入import torch以及torch.cuda.is_available() ,若返回TRUE则说明实验环境配置正确,若返回False但可以正确导入torch则说明pytorch配置成功,但实验运行是在CPU进行的,结果如下:
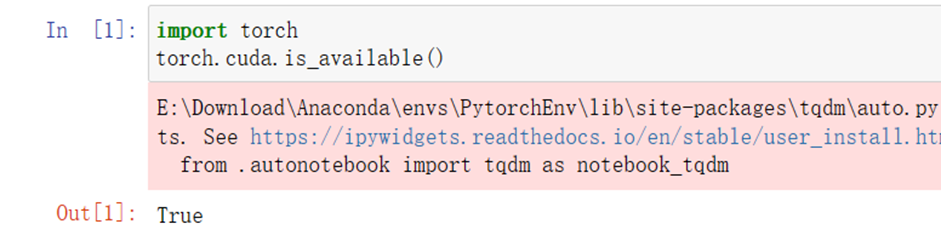
图1-1
1. 数据操作
(1)使用jupyter notebook新增的pytorch环境新建ipynb文件,完成基本数据操作的实验代码与练习结果如下:
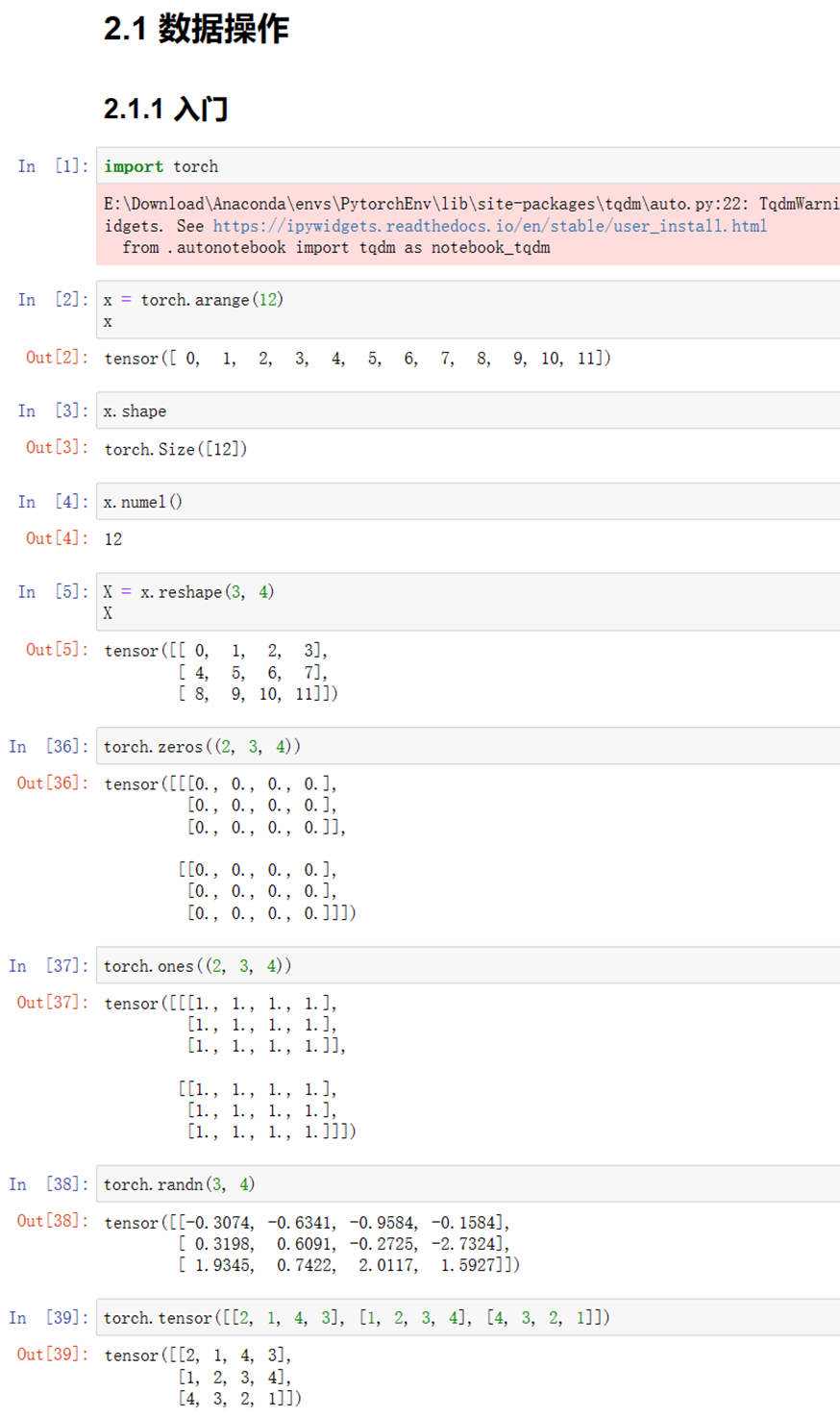
图1-2
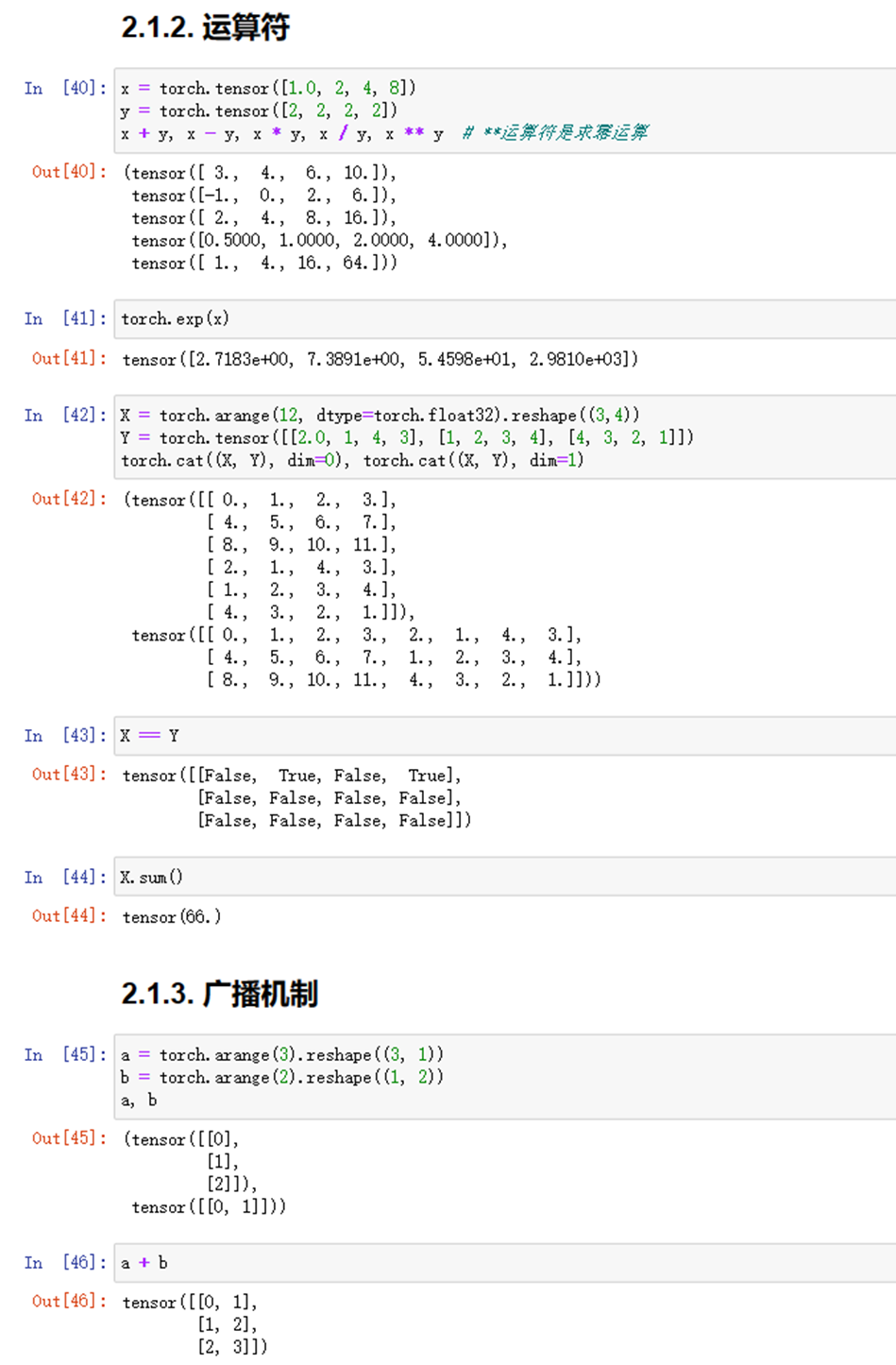
图1-3
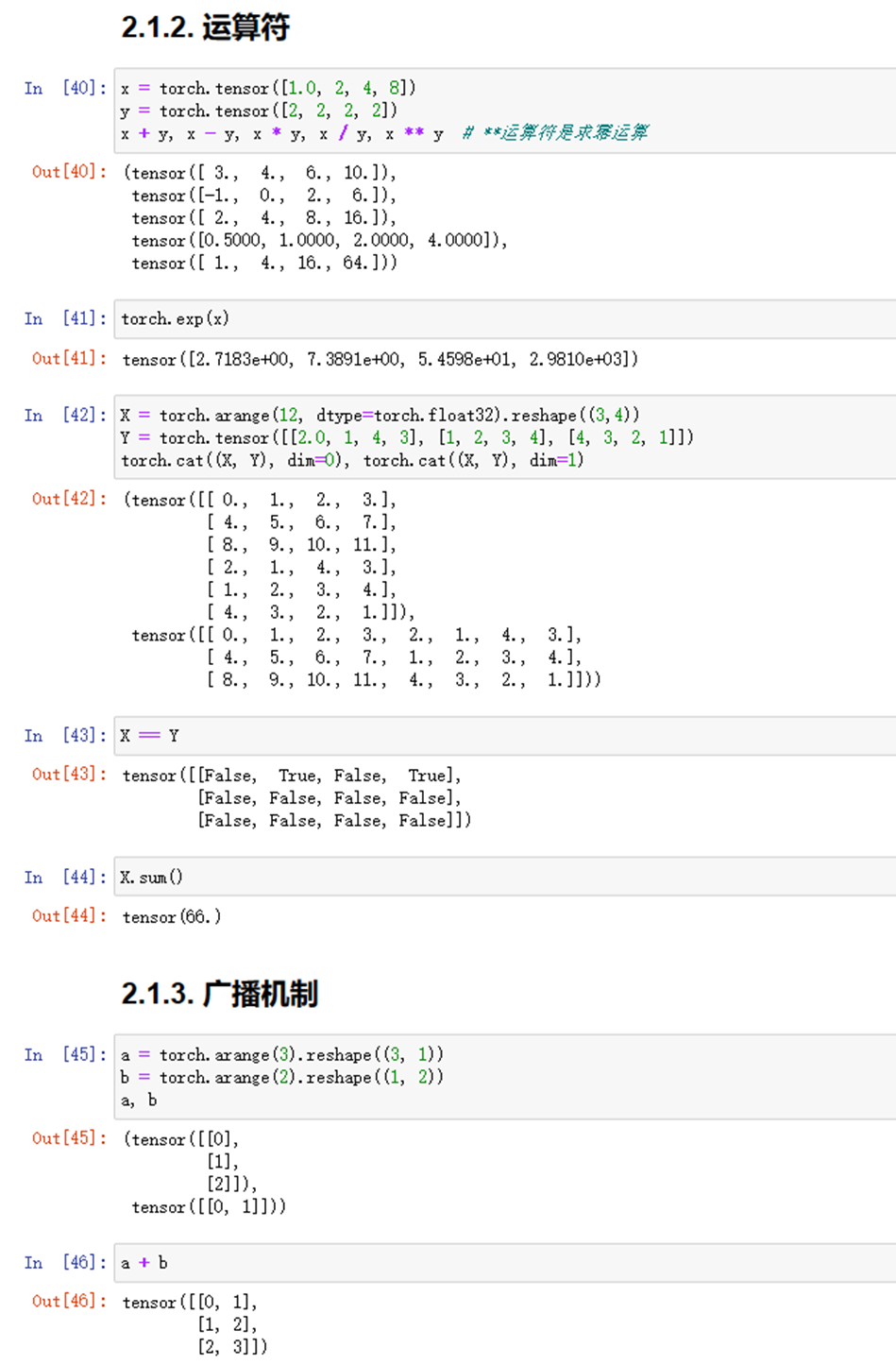
图1-4
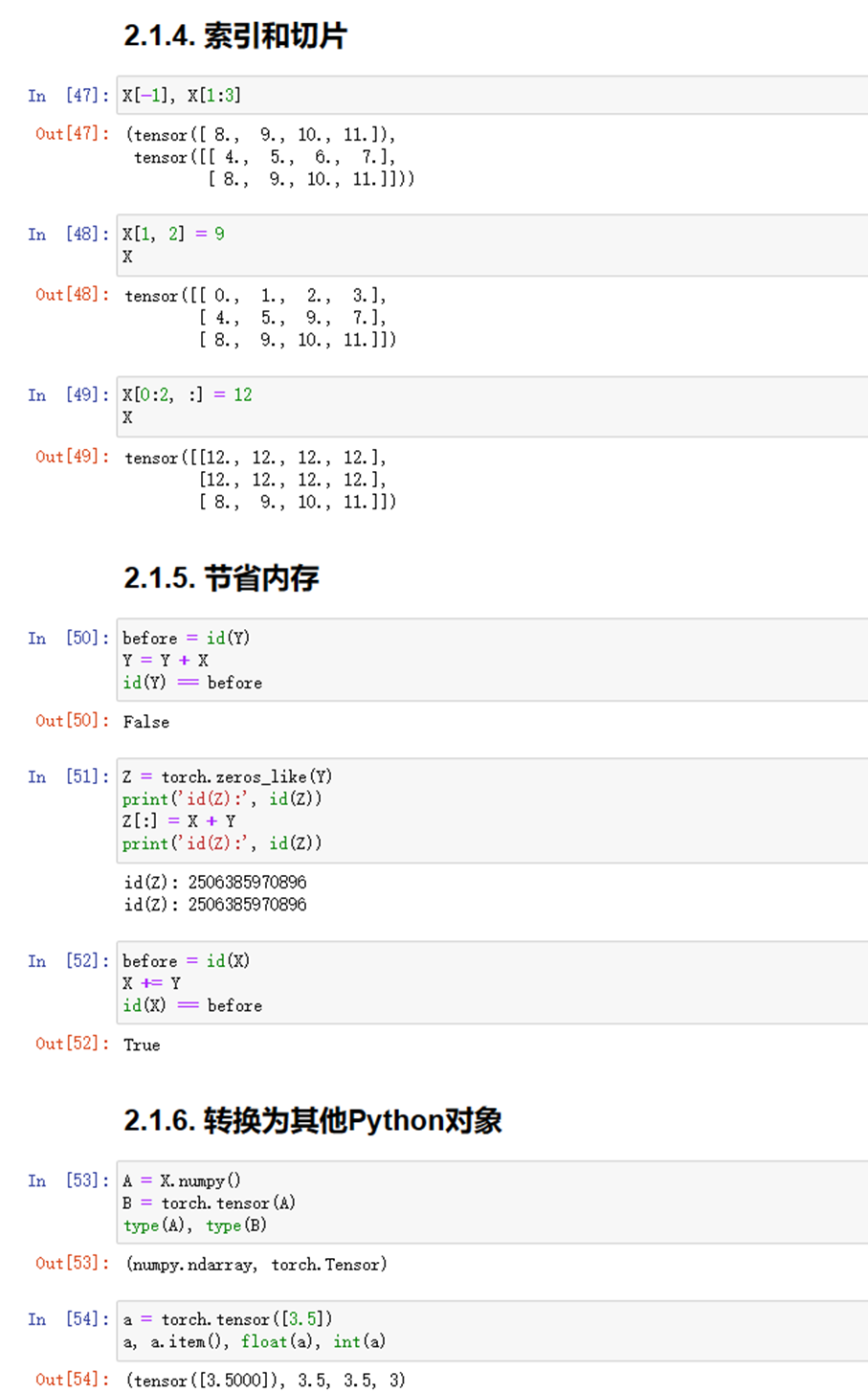
图1-5
练习1:
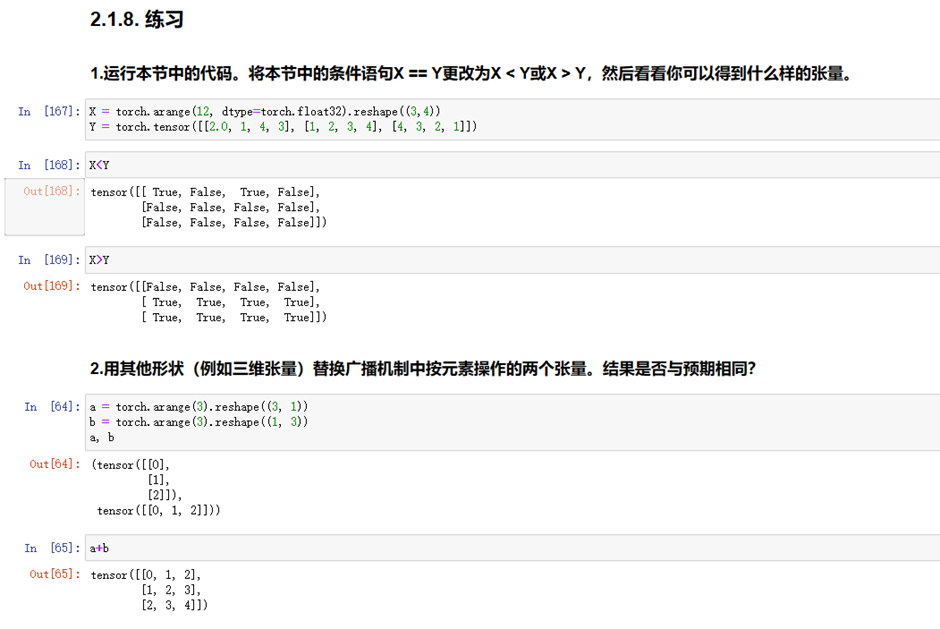
图1-6
2. 数据预处理
(1)完成数据预处理的实验代码及练习内容如下:

图1-7
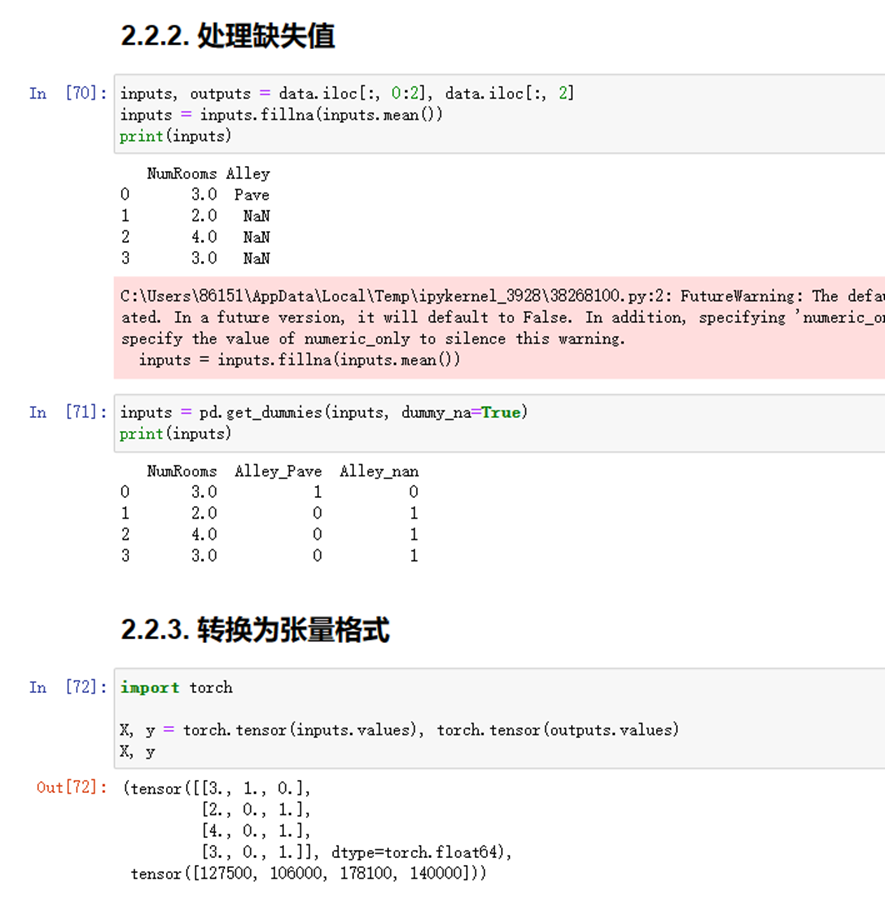
图1-8
练习2:

图1-9

图1-10
3. 线性代数
(1)完成线性代数的实验代码及练习结果如下:
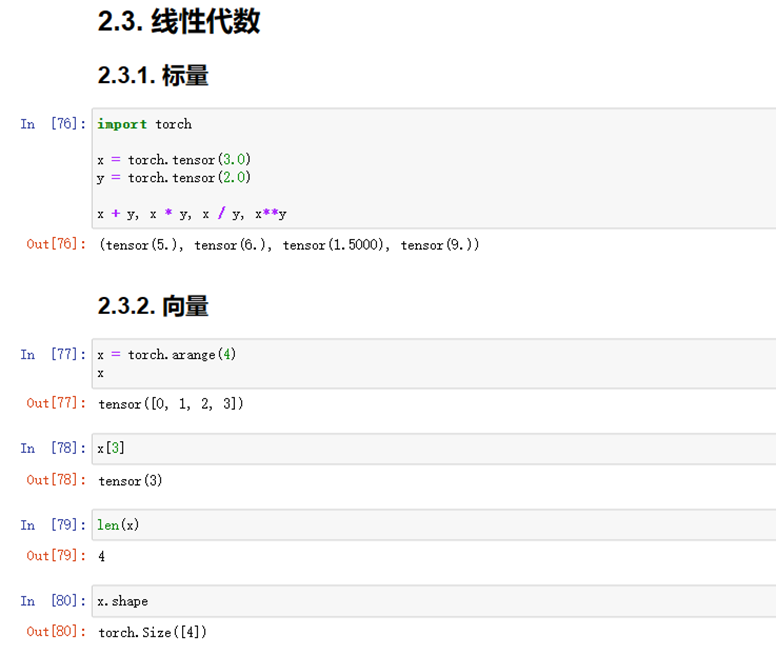
图1-11
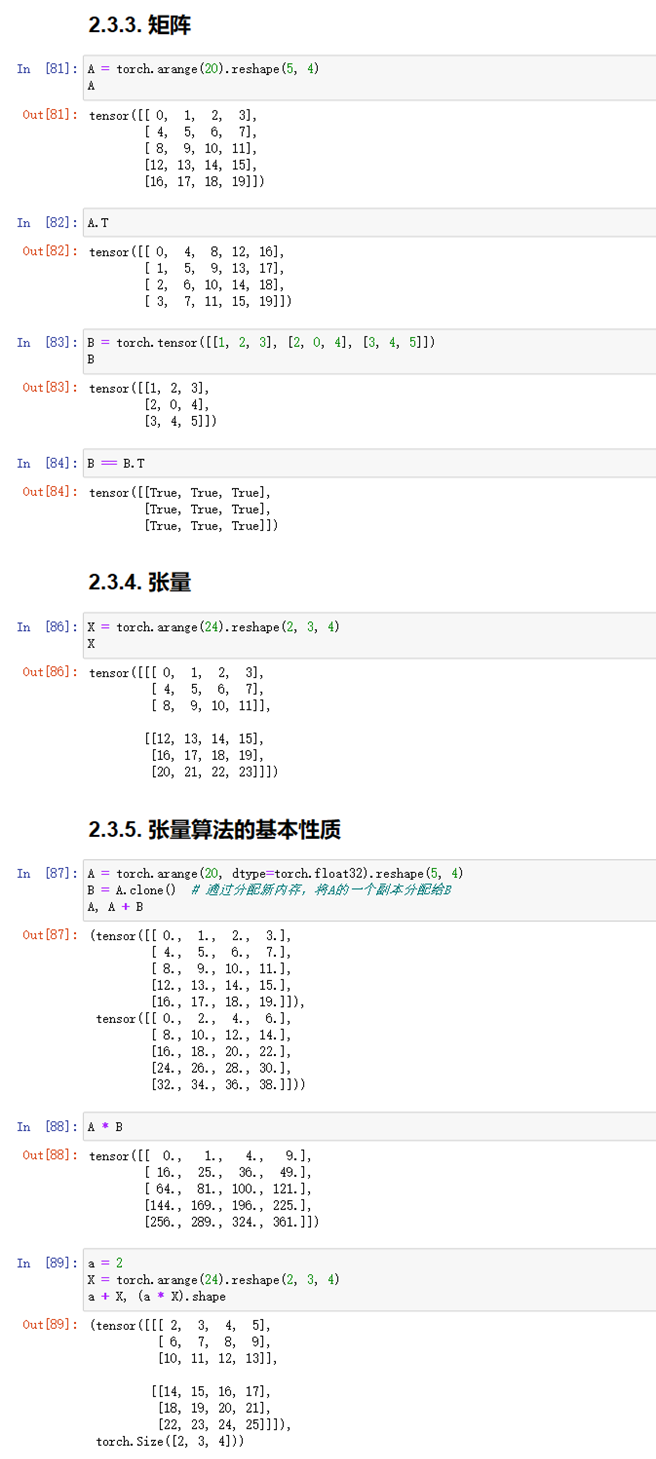
图1-12
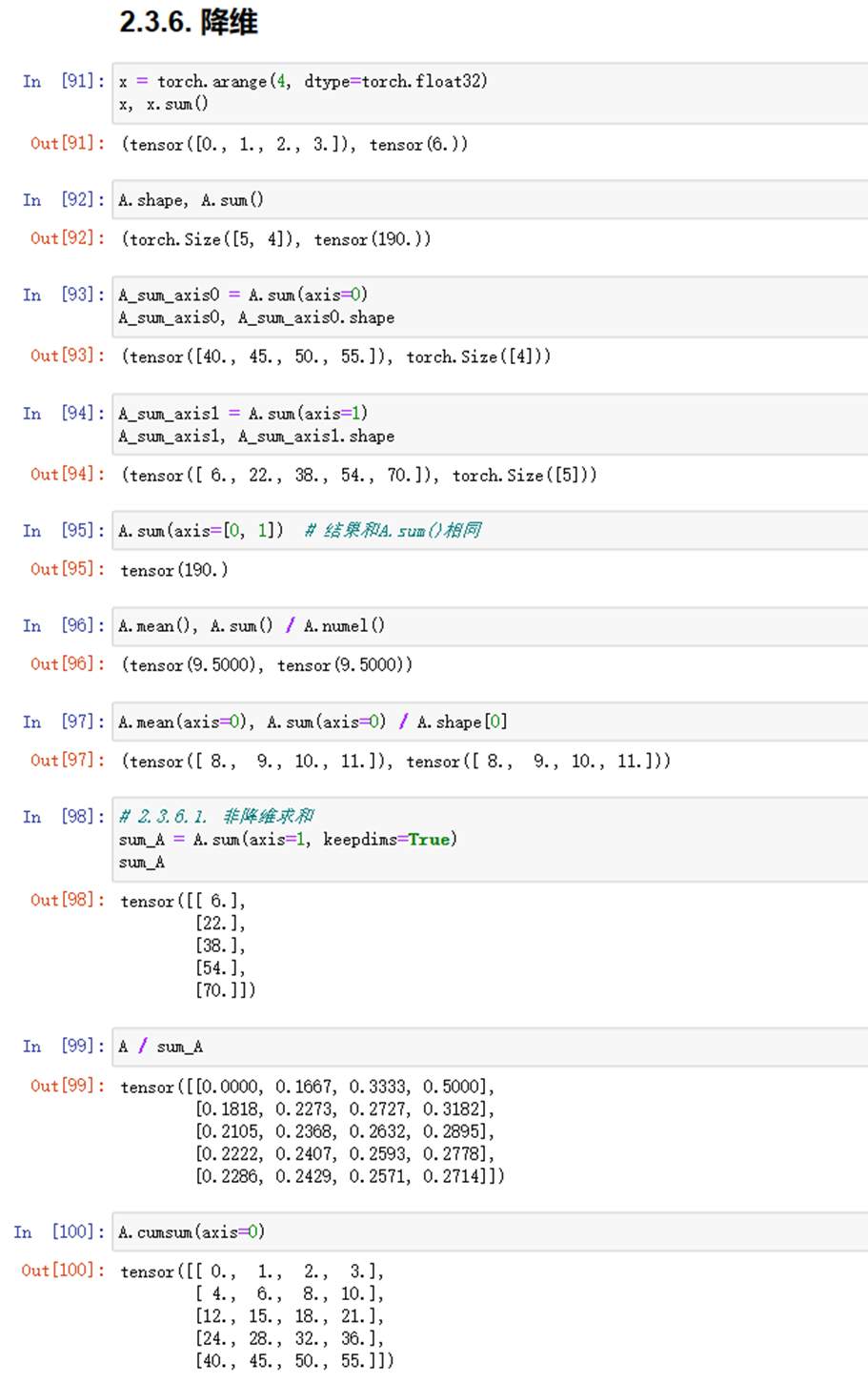
图1-13
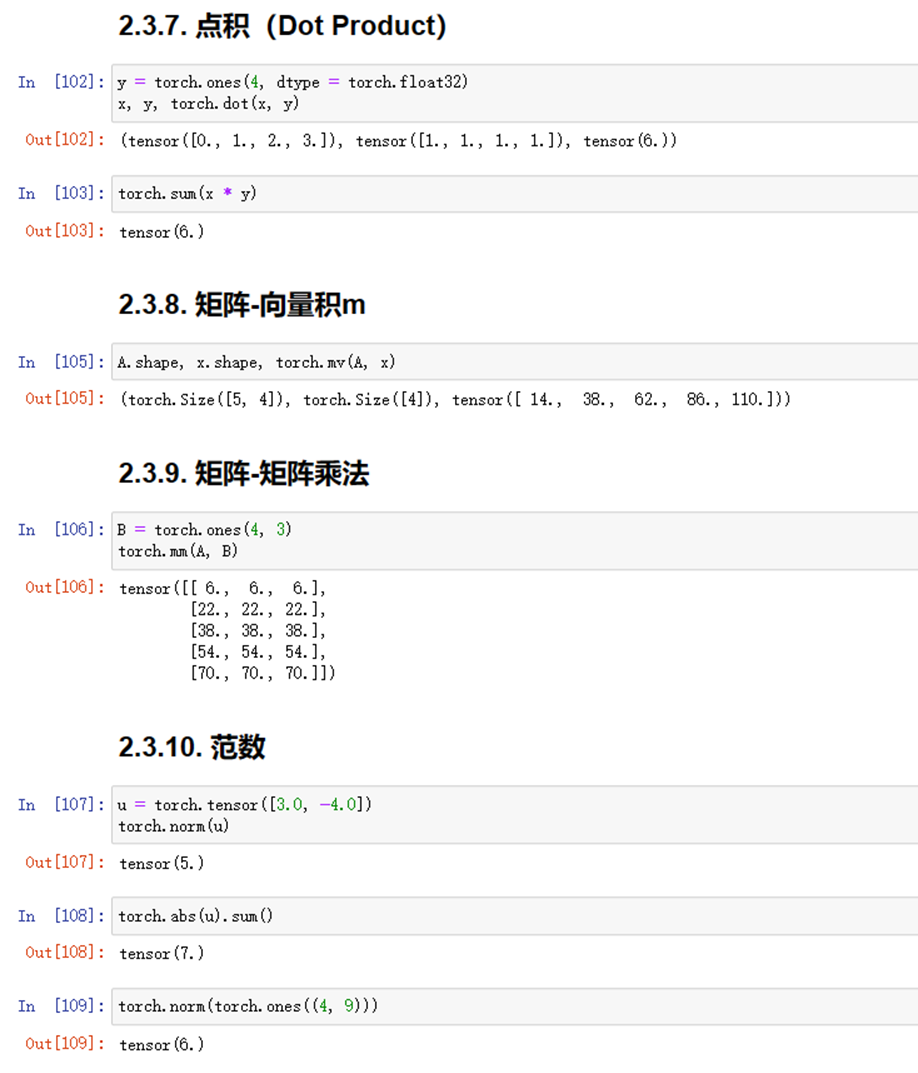
图1-14
练习3:

图1-15
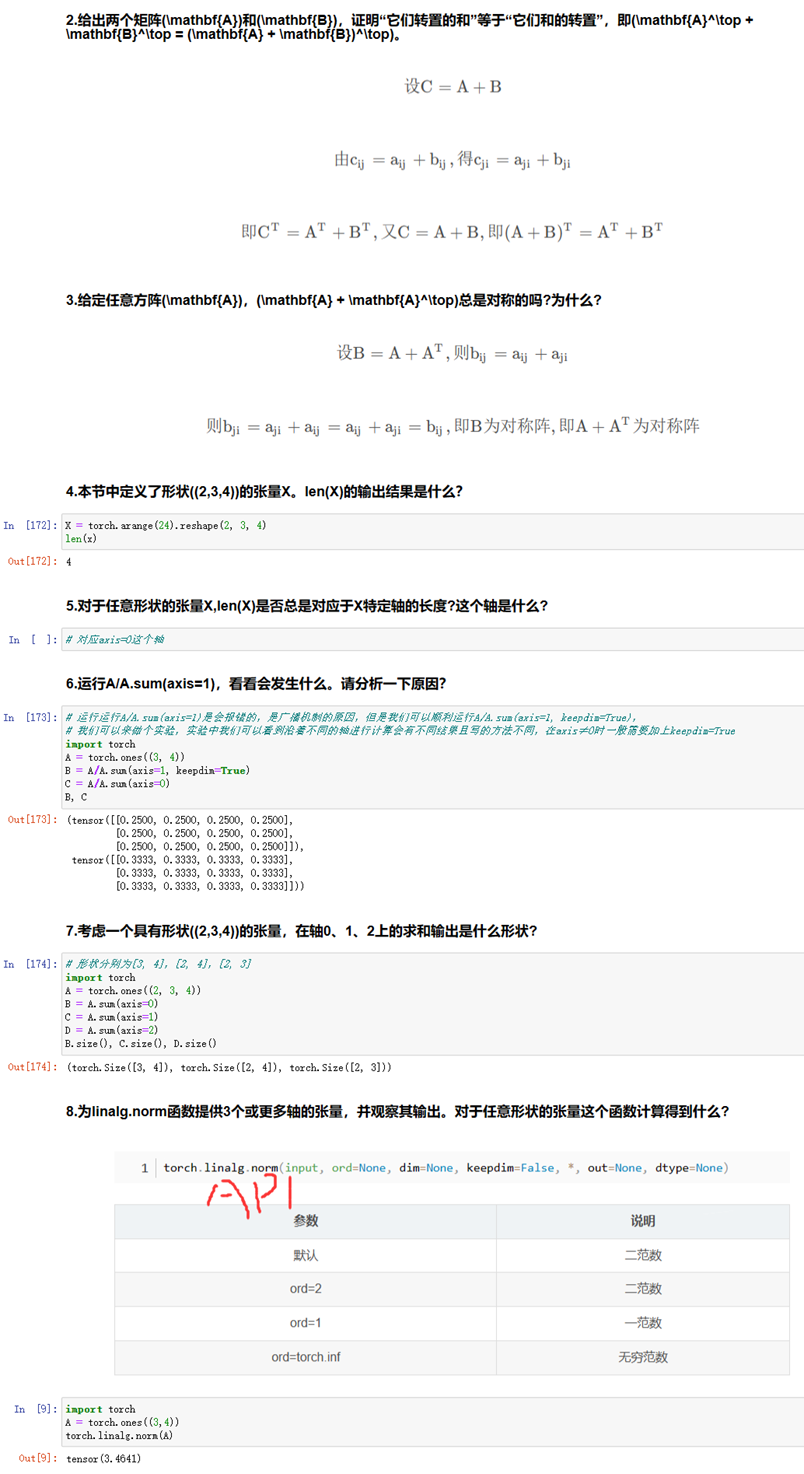
图1-16
4. 微积分
(1)完成微积分的实验代码及练习结果如下:

图1-17
练习4:
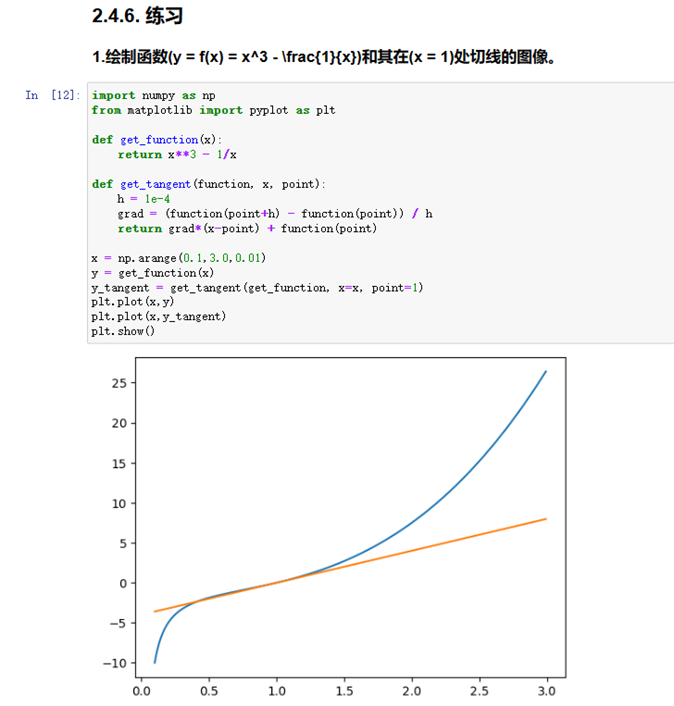
图1-18

图1-19
5. 自动微分
(1)完成自动微分的实验代码及练习结果如下:
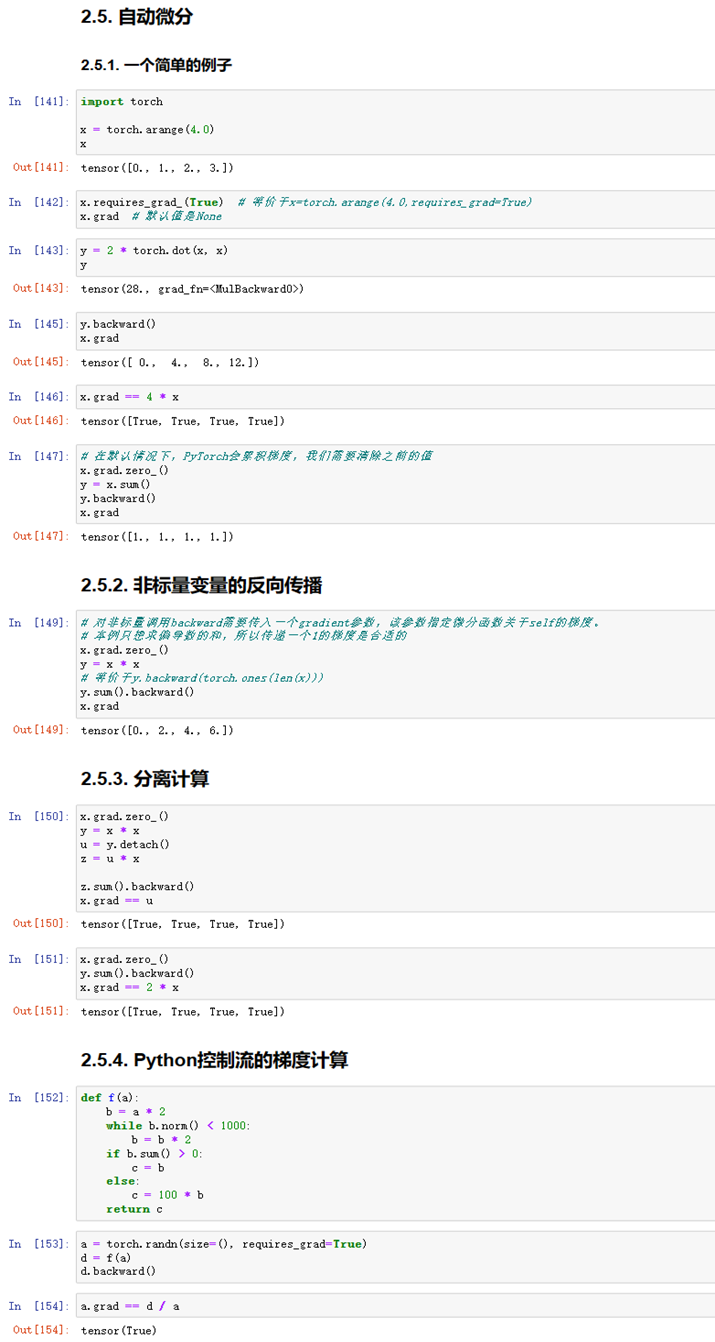
图1-20
练习5:
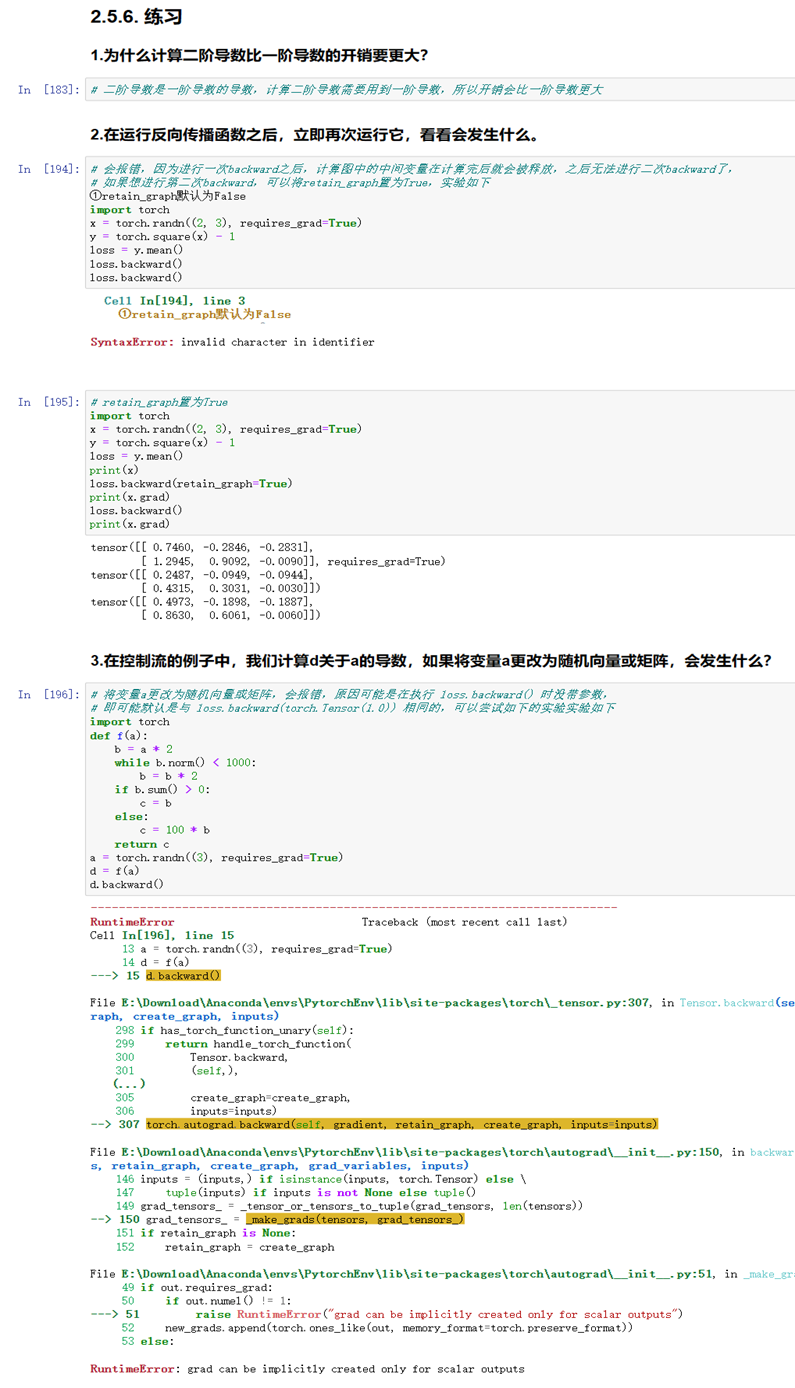
图1-21
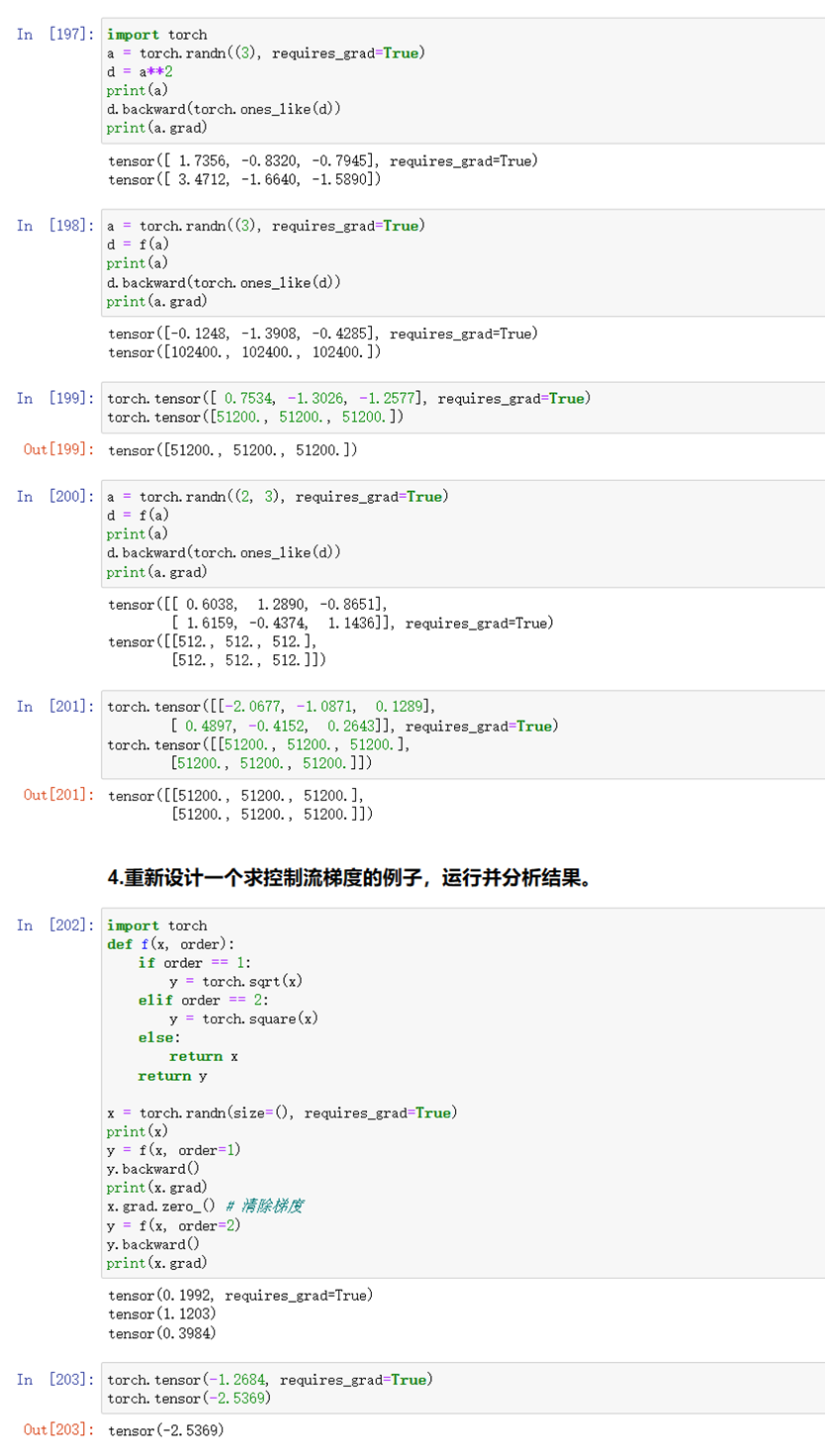
图1-22

图1-23
四、实验心得
通过这次实验,我对深度学习的数据处理知识有了更深入的了解。尽管在安装PyTorch的过程中遇到了一些问题(由于conda默认安装了CPU版本的PyTorch),但在删除numpy库后成功地安装了GPU版本的PyTorch。并且我对以下内容有了更深刻的理解:
1.张量(n维数组)是深度学习存储和操作数据的主要接口。它提供了广泛的功能,包括基本数学运算、广播、索引、切片,还可以实现内存节省和转换其他Python对象。
2.pandas是Python中常用的数据分析工具之一,它与张量兼容,为数据处理提供了便利。
3.在处理缺失数据时,pandas提供了多种方法,根据情况可以选择插值法或删除法进行处理。
4.标量、向量、矩阵和张量是线性代数中的基本数学对象。
5.向量是标量的推广,矩阵是向量的推广。
6.标量、向量、矩阵和张量分别具有零、一、二和任意数量的轴。
7.通过使用sum和mean等操作,可以沿指定的轴降低张量的维度。
8.两个矩阵的按元素乘法被称为Hadamard积,与矩阵乘法不同。
9.在深度学习中,常常使用范数,如L1范数、L2范数和Frobenius范数。
10.微分和积分是微积分的两个分支,其中微分在深度学习的优化问题中得到了广泛应用。
11.导数可以被理解为函数相对于其变量的瞬时变化率,同时是函数曲线的切线斜率。
12.梯度是一个向量,其分量是多变量函数相对于所有变量的偏导数。
13.链式法则可以用于求解复合函数的导数。
14.深度学习框架能够自动计算导数:首先将梯度附加到需要计算偏导数的变量上,然后记录目标值的计算过程,执行反向传播函数,并获得相应的梯度。