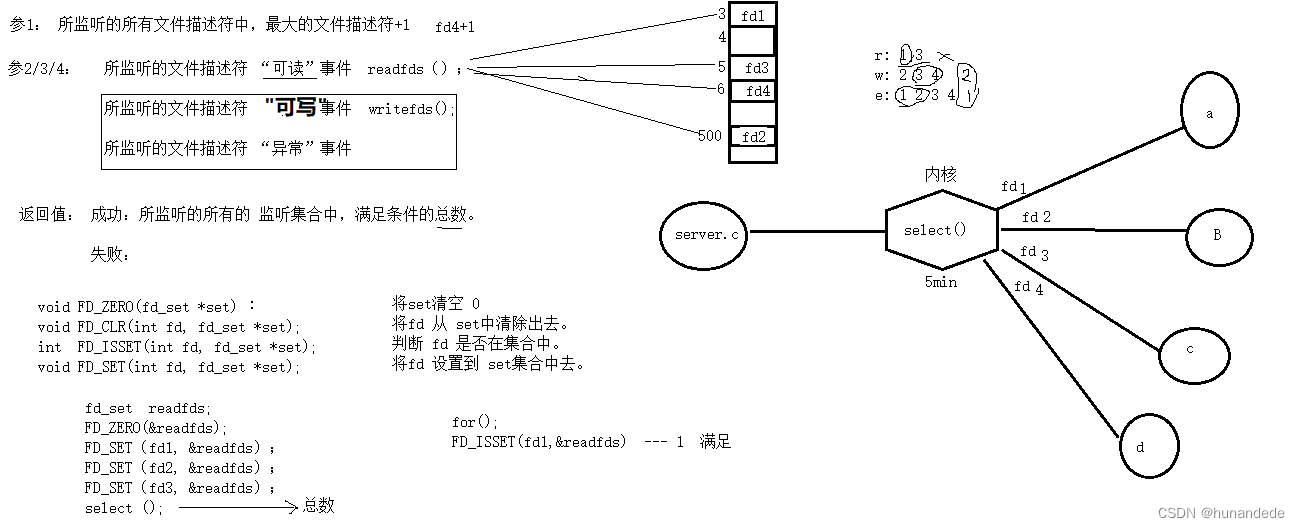
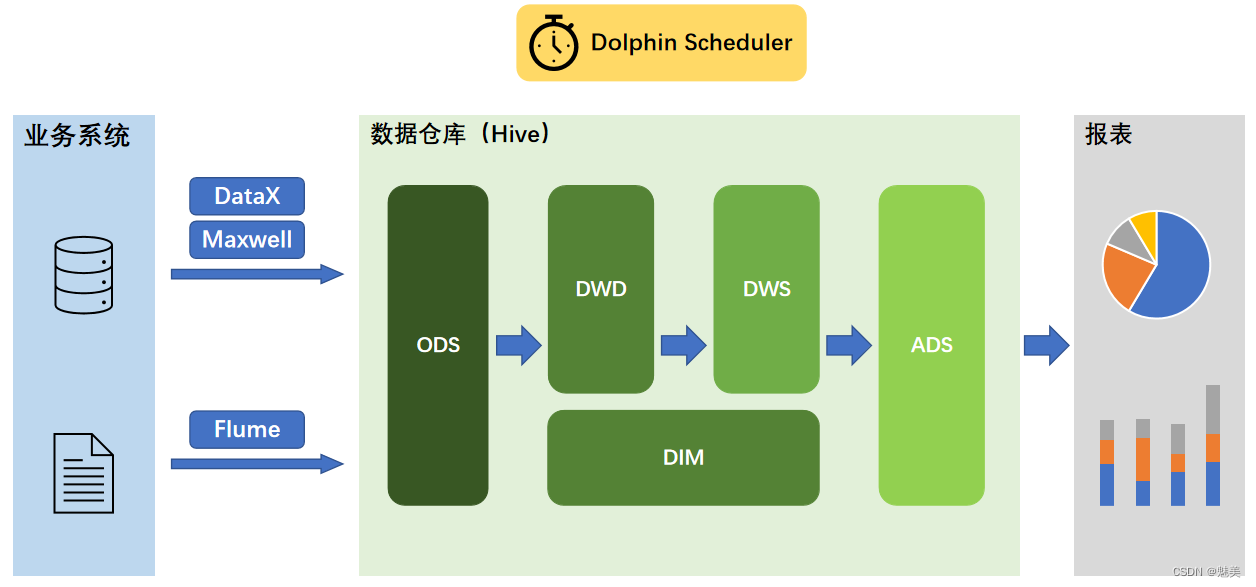
数据仓库概述
数据仓库概念
数据仓库是一个为数据分析而设计的企业级数据管理系统。数据仓库可集中、整合多个信息源的大量数据,借助数据仓库的分析能力,企业可从数据中获得宝贵的信息进而改进决策。同时,随着时间的推移,数据仓库中积累的大量历史数据对于数据科学家和业务分析师也是十分宝贵的。
数据仓库核心架构
数据仓库建模概述
数据仓库建模的意义
数据模型就是数据组织和存储方法,它强调从业务、数据存取和使用角度合理存储数据。只有将数据有序的组织和存储起来之后,数据才能得到高性能、低成本、高效率、高质量的使用。
高性能:良好的数据模型能够帮助我们快速查询所需要的数据。
低成本:良好的数据模型能减少重复计算,实现计算结果的复用,降低计算成本。
高效率:良好的数据模型能极大的改善用户使用数据的体验,提高使用数据的效率。
高质量:良好的数据模型能改善数据统计口径的混乱,减少计算错误的可能性。
数据仓库建模方法论
ER模型
数据仓库之父Bill Inmon提出的建模方法是从全企业的高度,用实体关系(Entity Relationship,ER)模型来描述企业业务,并用规范化的方式表示出来,在范式理论上符合3NF。
- 1)实体关系模型
实体关系模型将复杂的数据抽象为两个概念——实体和关系。实体表示一个对象,例如学生、班级,关系是指两个实体之间的关系,例如学生和班级之间的从属关系。 - 2)数据库规范化
数据库规范化是使用一系列范式设计数据库(通常是关系型数据库)的过程,其目的是减少数据冗余,增强数据的一致性。
这一系列范式就是指在设计关系型数据库时,需要遵从的不同的规范。关系型数据库的范式一共有六种,分别是第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF)。遵循的范式级别越高,数据冗余性就越低。 - 3)三范式
- (1)函数依赖
1、完全函数依赖:
设X,Y是关系R的两个属性集合,X’是X的真子集,存在X→Y,但对每一个X’都有X’!→Y,则称Y完全函数依赖于X。
比如通过(学号,课程) 推出分数 ,但是单独用学号推断不出来分数,那么就可以说:分数 完全依赖于(学号,课程) 。即:通过AB能得出C,但是AB单独得不出C,那么说C完全依赖于AB。
2、部分函数依赖
假如 Y函数依赖于 X,但同时 Y 并不完全函数依赖于 X,那么我们就称 Y 部分函数依赖于 X。
比如通过(学号,课程) 推出姓名,因为其实直接可以通过学号推出姓名,所以**:姓名 部分依赖于 (学号,课程)**。即:通过AB能得出C,通过A也能得出C,或者通过B也能得出C,那么说C部分依赖于AB。
3、传递函数依赖
传递函数依赖:设X,Y,Z是关系R中互不相同的属性集合,存在X→Y(Y !→X),Y→Z,则称Z传递函数依赖于X。
比如:学号 推出 系名 , 系名 推出 系主任, 但是,系主任推不出学号,系主任主要依赖于系名。这种情况可以说:系主任 传递依赖于 学号。即:通过A得到B,通过B得到C,但是C得不到A,那么说C传递依赖于A。 - (2)第一范式
第一范式1NF核心原则就是:属性不可切割。1NF是所有关系型数据库的最基本要求,你在关系型数据库管理系统(RDBMS),例如SQL Server,Oracle,MySQL中创建数据表的时候,如果数据表的设计不符合这个最基本的要求,那么操作一定是不能成功的。也就是说,只要在RDBMS中已经存在的数据表,一定是符合1NF的。 - (3)第二范式
第二范式2NF核心原则:不能存在“部分函数依赖” - (4)第三范式
第三范式 3NF核心原则:不能存在传递函数依赖
下图为一个采用Bill Inmon倡导的建模方法构建的模型,从图中可以看出,较为松散、零碎,物理表数量多。
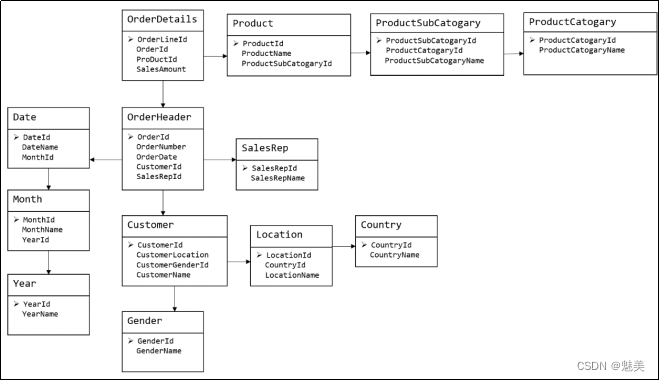
这种建模方法的出发点是整合数据,其目的是将整个企业的数据进行组合和合并,并进行规范处理,减少数据冗余性,保证数据的一致性。这种模型并不适合直接用于分析统计。
- (1)函数依赖
维度模型
数据仓库领域的另一位大师——Ralph Kimball倡导的建模方法为维度建模。维度模型将复杂的业务通过事实和维度两个概念进行呈现。事实通常对应业务过程,而维度通常对应业务过程发生时所处的环境。
注:业务过程可以概括为一个个不可拆分的行为事件,例如电商交易中的下单,取消订单,付款,退单等,都是业务过程。
下图为一个典型的维度模型,其中位于中心的SalesOrder为事实表,其中保存的是下单这个业务过程的所有记录。位于周围每张表都是维度表,包括Date(日期),Customer(顾客),Product(产品),Location(地区)等,这些维度表就组成了每个订单发生时所处的环境,即何人、何时、在何地下单了何种产品。从图中可以看出,模型相对清晰、简洁。
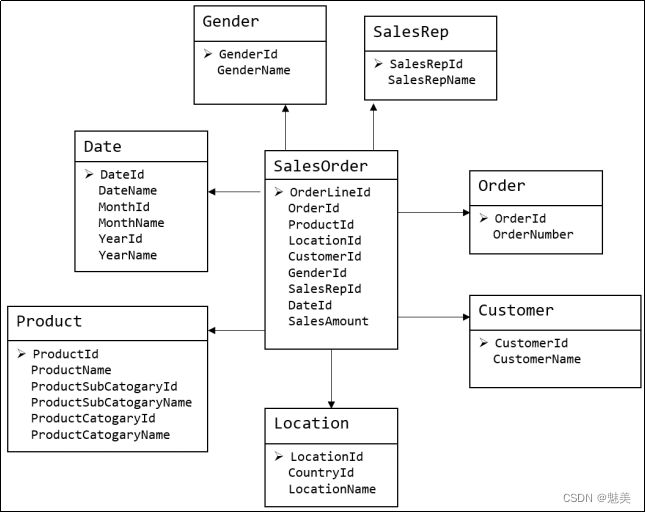
维度建模以数据分析作为出发点,为数据分析服务,因此它关注的重点的用户如何更快的完成需求分析以及如何实现较好的大规模复杂查询的响应性能。