一、语音识别
针对项目中要求识别的果皮,瓶子,纸箱这些物品我们选择采集以下文字对应的语音数据: 请检测出果皮
请检测出纸箱
请检测出瓶子
请检测出果皮和纸箱
请检测出纸箱和瓶子
请检测出果皮和瓶子
请检测出纸箱、果皮和瓶子
1.语音录制
我们找了许多本专业的同学和朋友使用Audacity软件录制出以上文字对应的单声道音频,并导出为 wav格式文件。
2.人工识别
收集完录音后由人工识别语音,将每个语音文件加入文件夹名为其语音内容的对应文件夹中。
3.生成训练文件
完成数据的收集后,编写python脚本,生成语音模型训练所需的json文件。脚本程序流程如下
遍历语音数据文件夹中的所有文件。
对每个语音文件建立一个字典。
由于之前整理语音文件时已经将语音文件加入其对应文字命名的文件夹中,所以可以直接知道
遍历到每个语音文件时其内部语音所对应的文字内容,将其作为字典中text关键字的值。
使用librosa库计算每段语音的时长作为字典中time关键字对应的值。
将此时的路径作为字典中path关键字的值。
使用json库将字典类型转换为json字符串。
设定训练集和测试集的比例p:q,以(p/(p+q))的概率将该json字符串加入表示训练集的json文件,以(q/(p+q))的概率将该json字符串加入表示测试集的json文件,我们这里划分的比例取了 1:1。 该过程对应的代码如下

4.语音模型训练
我们选择在服务器上搭建训练环境,GPU使用的是Nvidia T4,由于靠手动能收集的数据量有限,我们 把bachsize调小后运行文件开始训练,约一小时以内就能跑完200个epoch。
最后使用预训练模型和我们训练完成的模型对所有验证集中的语音模型计算字错率,经过训练后字错率下降了3个百分点
二、前端设计
本次比赛首次加入了web前端的设计环节,希望参赛者可以在官方提供界面的基础上,通过自己的设计实现出便于用户操作和美观的界面。
我们团队对于本次前端设计主要是“科技,未来,智能“,所以我们采用了Three.js 和 gsap搭建一个3D的太空场景作为我们的UI界面。
- 场景搭建
首先我们使用Three.js搭建一个太空背景,引入银河星空的背景图片作为我们的环境贴图,之后在场景中随机位置,添加圆球形状的几何体,模拟太空的恒星,使用gsap为每个恒星添加一个向后运动的动画,在我们所在的视角看到的就是一个在太空中前行的效果,如图所示:

2.创建机器人模型
之后添加一个未来感的机器人模型,作为我们引导者,在用户的视角彷佛就是有一个机器人在和用户进行互动,使用gsap为机器人添加机器人跟随鼠标转动方向的效果,增加用户的操作感和参与感,如图所示:

3。添加用户操作面板
添加一个用户操作面板来放我们主体的内容,用户主要在这个面板上进行我们的相关操作,面板整体采用了科技感的蓝绿色设计,底色采用了黑绿色的渐变效果,文字主要使用白色外发光的设计,一来和底色形成高度对比,方便用户阅读,而来外放光的效果有助于在深色环境中模拟亮光的效果,体现科技感和未来感。面板如图所示:

4.添加界面动效
为了体现科技和智能的整体感觉,我们需要让界面动起来,我们为面板添加一个后置的环形结构,这个结构的1/4进行填充,其余3/4为空白,之后为整个环形结构添加一个周期旋转的动画效果,实现一个在画面中,实时运动的圆环。现在画面中已经包含了背景的太空,与用户感官交互的机器人以及用户操作的控制面板,整体界面如图所示:

5.交互流程优化
现在我们实现了整体界面的设计,之后是对交互流程进行优化,我们在开始界面新增一个以机器人口吻描述的系统整体功能和操作的介绍,让用户快速了解我们的系统,添加一个加载模型的按钮来开始我们的整体流程。对于我们的整体按钮设计,为了和整套UI相适应,我们采用了蓝绿色的镂空按钮设计,同时在用户将鼠标移动到上方时,将背景颜色和字体颜色互换,实现一个提示性质的动效。
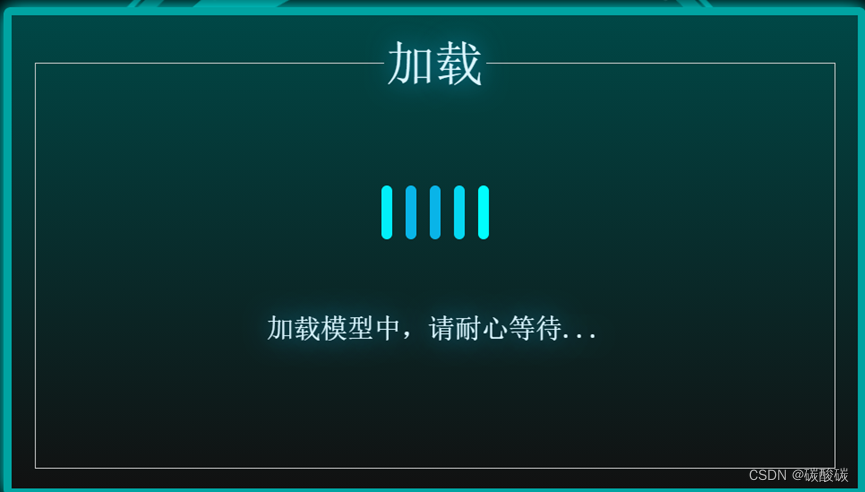
因为加载模型的过程比较冗长,所以我们为整个加载的过程添加了一个加载动画,加载动画采用了一组长度和颜色渐变的蓝绿色线段组成,通过动效与整体的界面风格适配。如图所示:
加载完毕后,为界面添加一个右侧的选项卡,用户可以自己切换我们系统的三项功能,单点识别语音,读取视频识别垃圾,获得FPS和mPA以及识别图片中的垃圾。选项卡初始只显示图标,用户将鼠标移动到指定模块上时,选项卡展开,显示文字内容,其具体效果如下:

6.语音识别过程
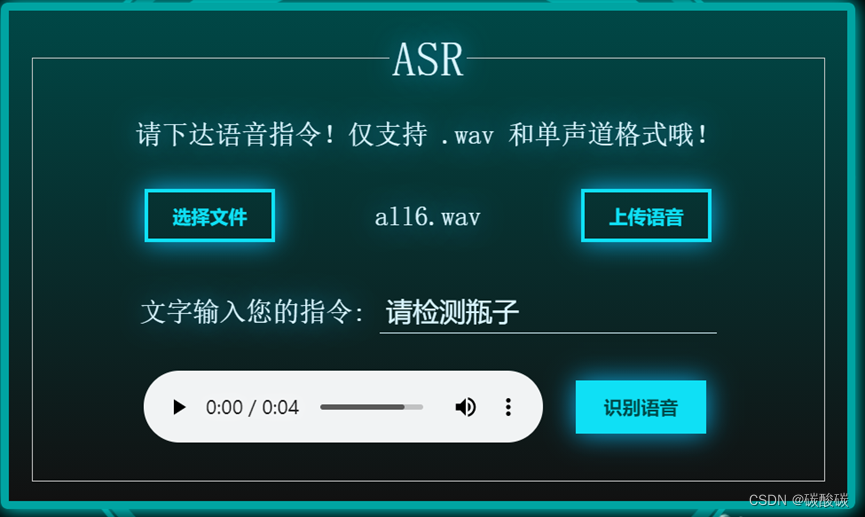
在语音识别中,我们将原始的上传文件组件隐藏,之后重写一个上传文件的组件的UI,当点击按钮时,触发上传文件的组件的点击事件,从而实现文件上传的组件和整体UI风格适配的效果,当用户上传文件后,显示识别的指令,点击识别语音,效果如下:
在其他的界面实现与我们设计相协调的文字,按钮和输入框等效果,实现整体UI风格一致,并且实现界面间的相互切换,所有界面的UI如下图所示: