文章目录
- 1 rlSimulinkEnv
- 1.1 说明
- 1.2 例子
- 1.2.1 使用工作空间Agent创建Simulink环境
- 1.2.2 为Simulink模型创建强化学习环境
- 1.2.3 创建Simulink多Agents环境
- 2 创建Simulink环境和训练Agent
- 2.1 创建环境接口
- 2.2 创建DDPG Agent
- 2.3 训练Agent
- 2.4 验证已训练的Agent
- 3 创建Simulink强化学习环境
- 3.1 Action and Observation信号
- 3.2 定制Simulink环境
- 4 RL Agent
- 5 Deep Deterministic Policy Gradient Agents
- 5.1 Actor and Critic Functions
- 5.2 Agent Creation
- 5.3 Training Algorithm
- 5.4 Target Update Methods
- 参考链接
1 rlSimulinkEnv
1.1 说明
rlSimulinkEnv函数从Simulink®模型中创建强化学习环境对象。环境对象起接口作用,当调用sim或train时,这些函数反过来调用Simulink模型,为智能体生成经验。
- env = rlSimulinkEnv(mdl, agentBlocks)为Simulink模型mdl创建强化学习环境对象env,agentBlocks包含到mdl中一个或多个强化学习agent块的路径。如果使用这种语法,每个agent块必须引用MATLAB®工作空间中已经存在的agent对象。
- env = rlSimulinkEnv(mdl, agentBlocks, obsInfo, actInfo)为模型mdl创建强化学习环境对象env。两个单元数组obsInfo和actInfo必须包含mdl中每个agent块的观测和动作规范,与它们出现在agentBlocks中的阶数相同。
- env = rlSimulinkEnv( _ _ , ‘UseFastRestart’, fastRestartToggle)创建了一个强化学习环境对象env,并支持快速重启。在前面语法中的任何一个输入参数之后使用这个语法。
1.2 例子
1.2.1 使用工作空间Agent创建Simulink环境
在MATLAB®工作空间中加载agent。
load rlWaterTankDDPGAgent
为rlwatertank模型创建环境,其中包含一个RL Agent模块。由于区块所使用的agent已经在工作空间中,因此不需要通过观测和动作规范来创建环境。
env = rlSimulinkEnv('rlwatertank','rlwatertank/RL Agent')
env =
SimulinkEnvWithAgent with properties:Model : rlwatertankAgentBlock : rlwatertank/RL AgentResetFcn : []UseFastRestart : on
通过进行两个样本时间的短暂模拟来验证环境。
validateEnvironment(env)
现在可以分别使用train和sim对环境中的Agent进行训练和仿真。
1.2.2 为Simulink模型创建强化学习环境
打开模型:
mdl = 'rlSimplePendulumModel';
open_system(mdl)
分别创建rlNumericSpec和rlFiniteSetSpec对象用于观察和动作信息。
obsInfo = rlNumericSpec([3 1]) % vector of 3 observations: sin(theta), cos(theta), d(theta)/dt
obsInfo = rlNumericSpec with properties:LowerLimit: -InfUpperLimit: InfName: [0x0 string]Description: [0x0 string]Dimension: [3 1]DataType: "double"
actInfo = rlFiniteSetSpec([-2 0 2]) % 3 possible values for torque: -2 Nm, 0 Nm and 2 Nm
actInfo = rlFiniteSetSpec with properties:Elements: [3x1 double]Name: [0x0 string]Description: [0x0 string]Dimension: [1 1]DataType: "double"
对于rlNumericSpec和rlFiniteSetSpec对象,可以使用点数表示法赋值属性值。
obsInfo.Name = 'observations';
actInfo.Name = 'torque';
分配智能体分块路径信息,利用前面步骤提取的信息为Simulink模型创建强化学习环境。
agentBlk = [mdl '/RL Agent'];
env = rlSimulinkEnv(mdl,agentBlk,obsInfo,actInfo)
env =
SimulinkEnvWithAgent with properties:Model : rlSimplePendulumModelAgentBlock : rlSimplePendulumModel/RL AgentResetFcn : []UseFastRestart : on
还可以包括使用点符号的reset功能。对于该实例,在模型工作空间中随机初始化theta0。
env.ResetFcn = @(in) setVariable(in,'theta0',randn,'Workspace',mdl)
env =
SimulinkEnvWithAgent with properties:Model : rlSimplePendulumModelAgentBlock : rlSimplePendulumModel/RL AgentResetFcn : @(in)setVariable(in,'theta0',randn,'Workspace',mdl)UseFastRestart : on1.2.3 创建Simulink多Agents环境
在MATLAB工作空间中加载智能体。
load rlCollaborativeTaskAgents
为rlCollaborativeTask模型创建一个环境,该环境有两个Agent块。由于两个区块( agentA和agentB)所使用的智能体已经在工作空间中,因此不需要通过它们的观察和动作规范来创建环境。
env = rlSimulinkEnv('rlCollaborativeTask',["rlCollaborativeTask/Agent A","rlCollaborativeTask/Agent B"])
env =
SimulinkEnvWithAgent with properties:Model : rlCollaborativeTaskAgentBlock : [rlCollaborativeTask/Agent ArlCollaborativeTask/Agent B]ResetFcn : []UseFastRestart : on
2 创建Simulink环境和训练Agent
该实例的原始模型为水箱模型:
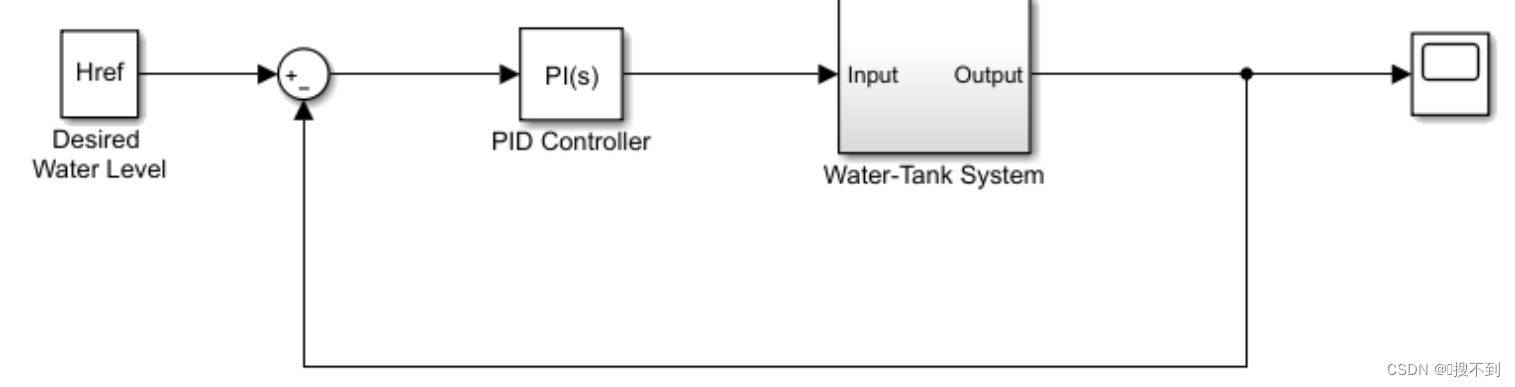
对原模型进行以下修改:
- 删除PID控制器,改由强化学习控制器;
- 插入RL Agent模块
- 串联观测向量 [ ∫ e d t , e , h ] T [\int edt, e, h]^T [∫edt,e,h]T,其中h是水箱高度, e = r − h e=r-h e=r−h,r是参考高度;
- 设置奖励 r e w a r d = 10 ( ∣ e ∣ < 0.1 ) − 1 ( ∣ e ∣ ≥ 0.1 ) − 100 ( h ≤ 0 ∣ ∣ h ≥ 20 ) reward=10(|e|<0.1)-1(|e|\ge0.1)-100(h\le0||h\ge20) reward=10(∣e∣<0.1)−1(∣e∣≥0.1)−100(h