StatisticSlot数据采集的原理
时间窗口
固定窗口
在固定的时间窗口内,可以允许固定数量的请求进入;超过数量就拒绝或者排队,等下一个时间段进入, 如下图
-
时间窗长度划分为1秒
-
单个时间窗的请求阈值为3
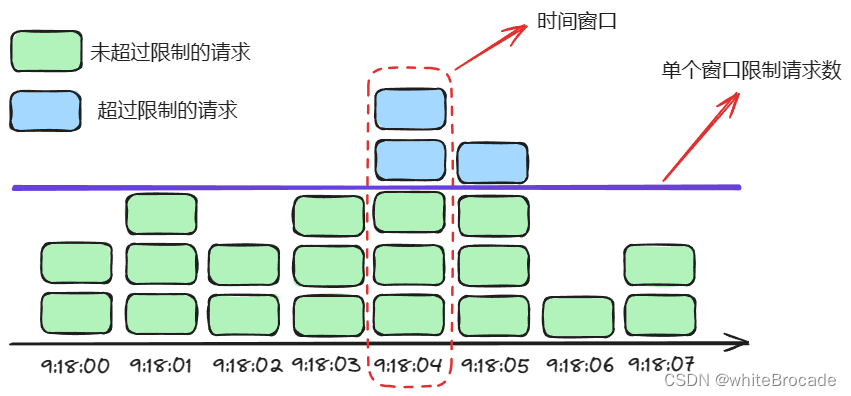
上述存在一个问题, 假如9:18:04:333-9:18:05:000产生了2个请求, 9:18:05:000-9:18:05:333产生了3个请求, 那么也就是说9:18:04:333-9:18:05:333这一秒内产生5个请求, 正常来说这里已经超出了阈值
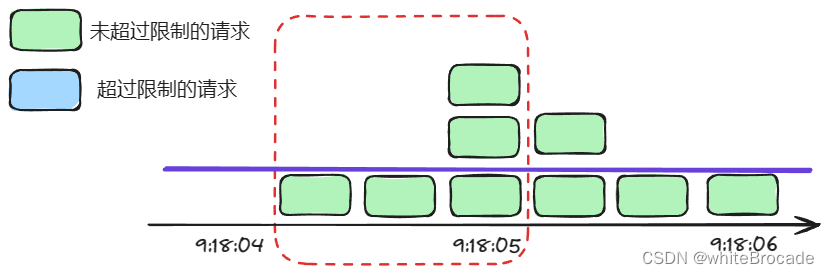
但是由于是固定窗口, 也就是这里只能9:18:04:000-9:18:05:000, 9:18:05:000-9:18:06:000这样子去处理, 所以实际上打达不到我们的要求的
滑动窗口
滑动窗口诞生的原因就在于解决固定窗口那个致命的问题,为什么我说固定窗口的问题是致命的?因为我们系统限流的目的是要在任意时间都能应对突然的流量暴增,也就是说我的系统最大在1s内能够处理请求3,但如果使用固定窗口的算法,就会造成在9:18:04:333-9:18:05:333之间的请求无法限流,从而严重的话会导致服务雪崩
滑动窗口如下图
-
时间窗长度划分为1秒, 并且是滑动的
-
单个时间窗的请求阈值为3
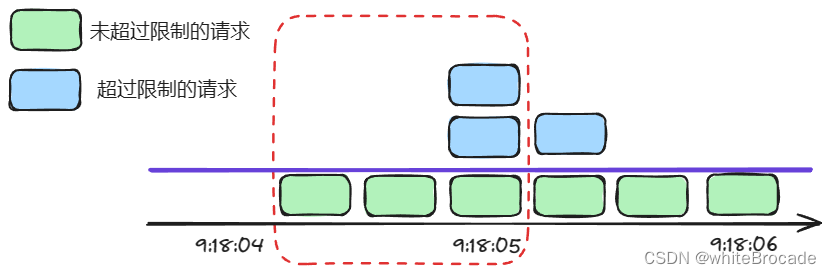
如果要判断请求是否能正常通过, 那么就要把当前时间点作为终点, 统计前1秒内的请求数, 判断请求数是否达到阈值, 如果没有达到阈值就放行, 如果达到阈值了就通过
上边的问题是是解决了, 但是存在一些性能问题, 假设请求落在9:18:05:333, 往前移动1s距离, 那么就是以9:18:04:333作为起点, 统计9:18:04:333-9:18:05:333之间的请求数, 当请求落在9:18:05:633, 那么就要统计9:18:04:633-9:18:05:633之间的请求数, 发现9:18:04:633-9:18:05:333之间的数据上一次的时候就出现过了, 但是这里又得重新统计, 也就说每移动一次窗口, 那么都要重新统计重复区域的请求数量, 从而导致浪费大量系统资源, 如下图, 黄色区域为重复统计区域
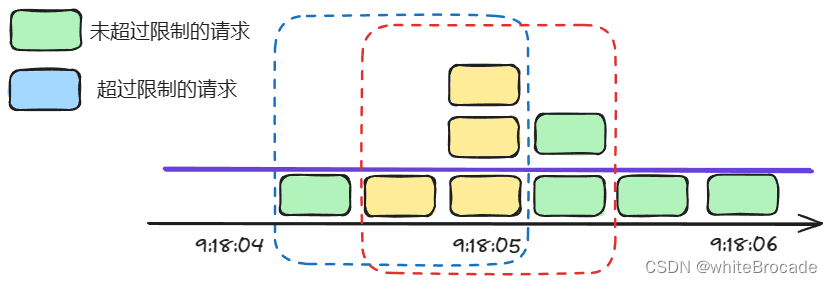
出现了问题, 就要解决
我们需要引入更加细粒度化的计算, 也就是说需要增加子时间窗口, 那么这里引入的子时间窗口, 我们称为样本窗口
- 样本窗口的长度必须
小于滑动窗口长度,因为如果样本窗口等于滑动窗口长度的话,就和固定窗口没啥区别了 - 通常情况下滑动窗口的长度是样本窗口的
整数倍,比如:10 * 样本窗口 = 1 个滑动窗口 - 每个样本窗口在到达终点时间时,会统计本样本窗口中的流量数据并且记录下来,用于复用
- 当一个请求到达时,系统会首先统计当前请求时间点所在的样本窗口内的流量数据。接着,系统会检查在当前请求时间点之前的滑动窗口中的样本窗口,将它们的统计数据进行求和。如果这个求和值没有超出事先设定的阈值,请求将会被允许通过。然而,如果求和值超过了阈值,系统会触发限流措施,拒绝该请求的访问
假设
- 时间窗长度为1s
- 一个时间窗内包含三个样本窗口
- 阈值为30
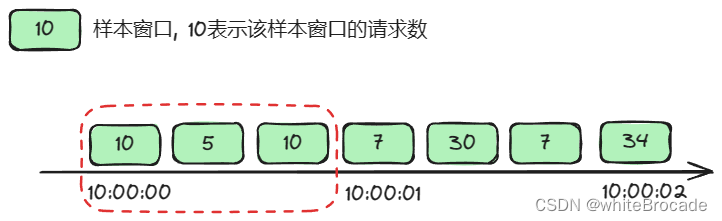
那么10:00:00:000-10:00:01:000内请求数为10 + 5 + 10 = 25 < 30, 所以大胆放行
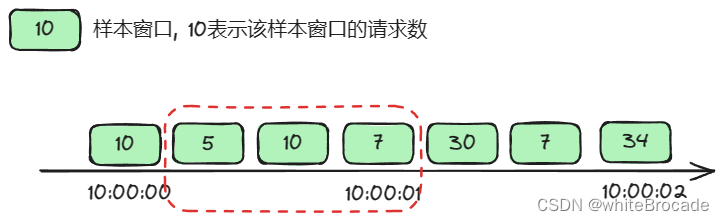
那么10:00:00:333-10:00:01:333内请求数为5 + 10 + 7= 22 < 30, 继续放行
那么10:00:00:666-10:00:01:666内请求数为10 + 7 + 30= 47 > 30, 这里就要限流了
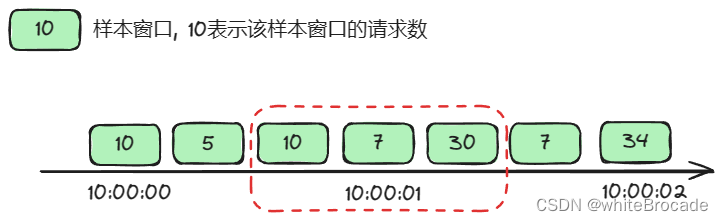
限流
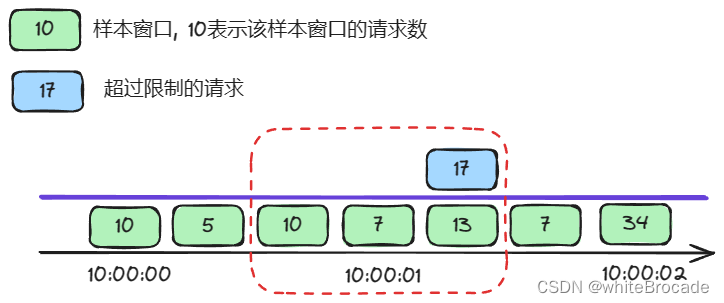
那么10:00:01:000-10:00:02:000内请求数为7 + 30 + 7= 40 > 30, 这里就要限流了
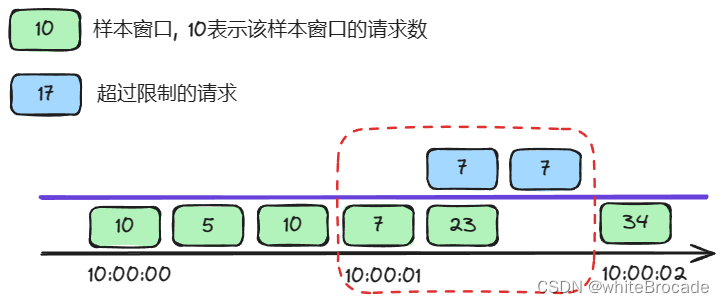
那么10:00:01:333-10:00:02:333内请求数为30 + 7 + 34 = 71 > 30, 这里就要限流了
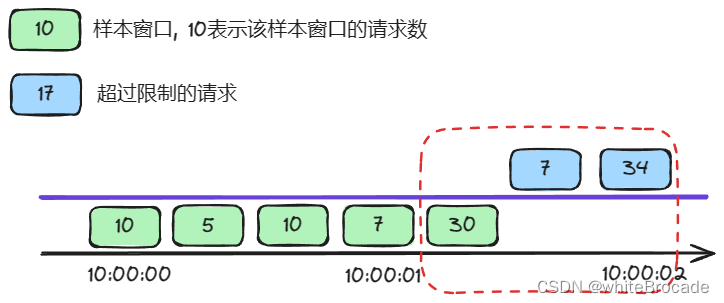
ps: 样本窗口的数量影响着滑动窗口算法的精度,依然有时间片的概念,无法根本解决临界点问题
数据统计
底层数据结构
StatisticSlot.entry() 中的 node.addPassRequest(count)方法
public void addPassRequest(int count) {// 增加当前入口的DefaultNode中的数据super.addPassRequest(count);// 增加当前资源的 ClusterNode 中的全局统计数据this.clusterNode.addPassRequest(count);
}@Override
public void addPassRequest(int count) {// 为滑动计数器增加本次请求rollingCounterInSecond.addPass(count);rollingCounterInMinute.addPass(count);
}
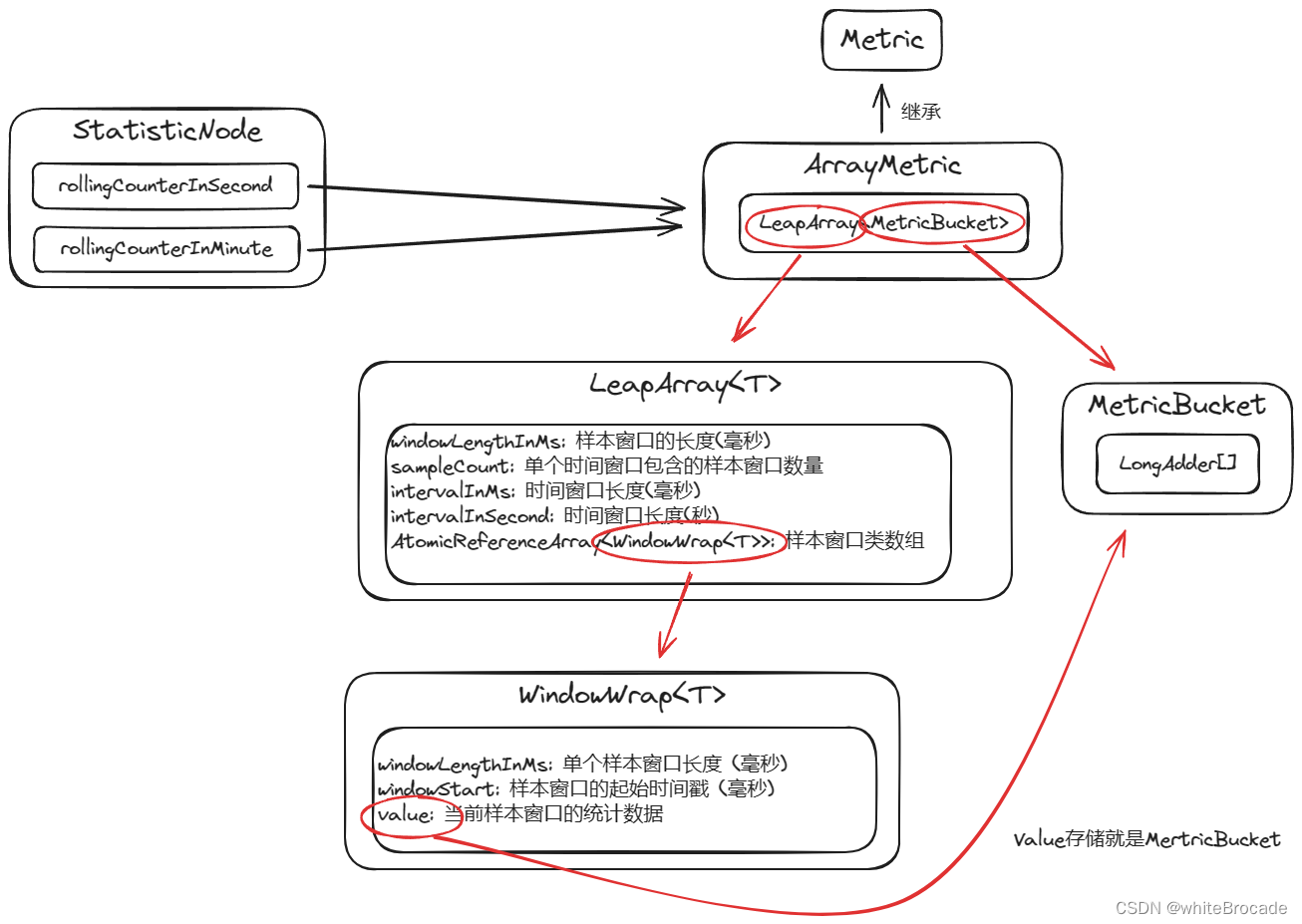
rollingCounterInSecond 就是一个真正保存数据的计量器,数据类型为 ArrayMetric,也就是说 Sentinel 在统计数据上采取的是一个名为 ArrayMetric 的 Java 类,如下
// 定义了一个使用数组保存数据的计量器,样本窗口数量为2(SAMPLE_COUNT),时间窗口长度为1000ms(INTERVAL)
private transient volatile Metric rollingCounterInSecond = new ArrayMetric(SampleCountProperty.SAMPLE_COUNT, IntervalProperty.INTERVAL);
那么 ArrayMetric 类又是如何存储数据的呢?
// 这是一个使用数组保存数据的计量器类,数据就保存在data中
public class ArrayMetric implements Metric {// 真正存储数据的地方private final LeapArray<MetricBucket> data;
}public abstract class LeapArray<T> {// 样本窗口的长度protected int windowLengthInMs;// 一个时间窗口包含的样本窗口数量,公式 intervalInMs / windowLengthInMs,也就是时间窗口长度 / 样本窗口长度protected int sampleCount;// 时间窗口长度protected int intervalInMs;// 也是时间窗口长度,只是单位为sprivate double intervalInSecond;// WindowWrap : 样本窗口类// 这是一个数组// 这里的泛型T实际类型为 MetricBucketprotected final AtomicReferenceArray<WindowWrap<T>> array;
}
LeapArray 类似于一个样本窗口管理类,而真正的样本窗口类是 WindowWrap<T>,对于样本窗口的概念我们肯定不陌生了,其包含:单个样本窗口的长度、样本窗口的开始时间戳,如下所示:
// 样本窗口类,泛型T为MetricBucket
public class WindowWrap<T> {// 单个样本窗口的长度private final long windowLengthInMs;// 样本窗口的起始时间戳private long windowStart;// 当前样本窗口的统计数据,类型为 MetricBucketprivate T value;
}
关于泛型真实类型为 MetricBucket 也很简单,可以从前面代码 ArrayMetric#LeapArray<MetricBucket> 得出。接下来就看真实类型 MetricBucket 是个什么东西
// 统计数据的封装类
public class MetricBucket {// 统计的数据真实存放在LongAdder里// 但是为什么要数组?直接用LongAdder+1不就行了?因为统计的数据是多维度的,这些维度类型在MetricEvent枚举中。private final LongAdder[] counters;private volatile long minRt;
}这里有一个巧妙的设计,就是为什么用LongAdder[]而不是用LongAdder,正是因为统计的数据是多维度的,比如:统计通过的 QPS、统计失败的 QPS 等,因此设计成数组,我们就可以将不同类型放到不同的数组下标里
关系如下图
addPass()方法
@Override
public void addPassRequest(int count) {// 为滑动计数器增加本次请求rollingCounterInSecond.addPass(count);rollingCounterInMinute.addPass(count);
}public void addPass(int count) {// 获取当前时间点所在的样本窗口WindowWrap<MetricBucket> wrap = data.currentWindow();// 将当前请求的计数量添加到当前样本窗口的统计数据中wrap.value().addPass(count);
}
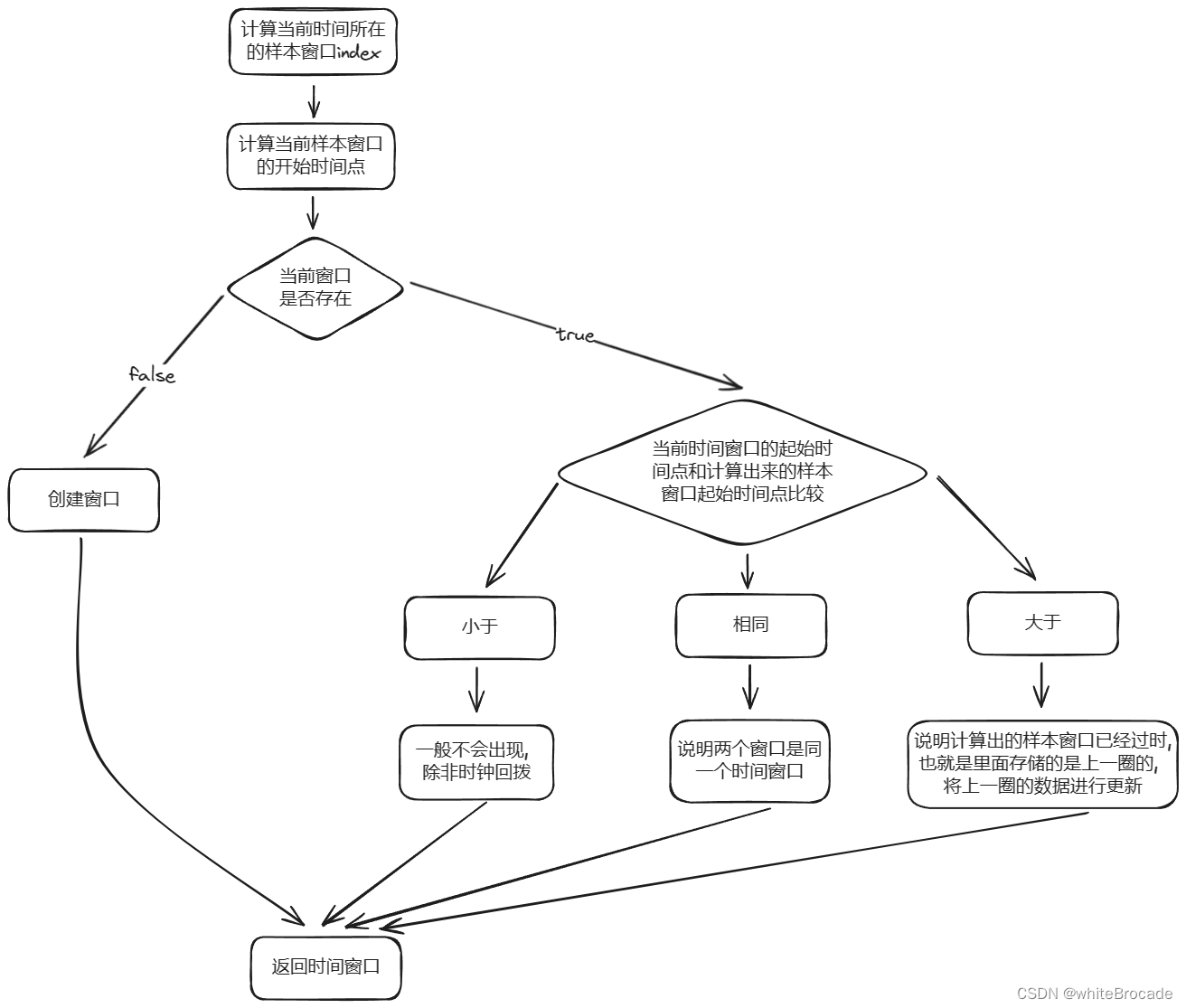
其主要分为三部分:
- 当前时间所在的样本窗口如果还没创建,则需要初始化。
- 若当前样本窗口的起始时间与计算出的样本窗口起始时间相同,则说明这两个是同一个样本窗口,直接获取就行。
- 若当前样本窗口的起始时间大于计算出的样本窗口起始时间,说明计算出来的样本窗口已经过时了,需要将原来的样本窗口替换为新的样本窗口。数组的环形数组,不是无限长的,比如存 1s,1000 个样本窗口,那么下 1s 的 1000 个时间窗口会覆盖上一秒的。
- 若当前样本窗口的起始时间小于计算出的样本窗口起始时间,一般不会出现,因为时间不会倒流,除非人为修改系统时间导致
时钟回拨
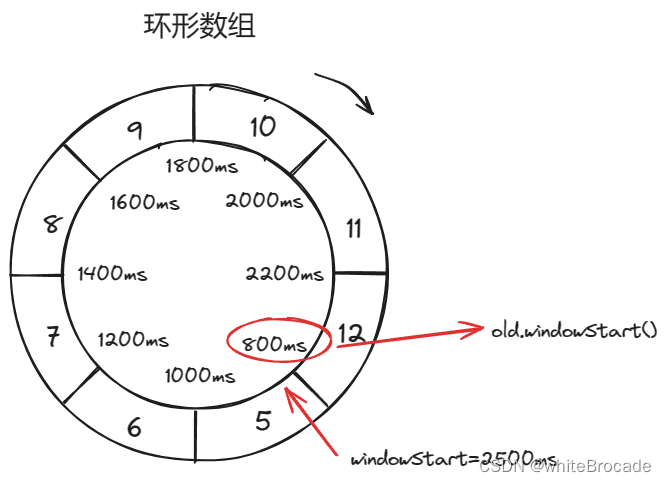
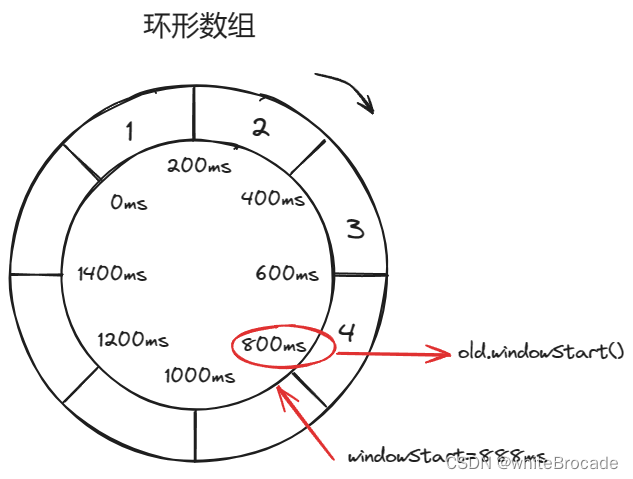
public WindowWrap<T> currentWindow(long timeMillis) {if (timeMillis < 0) {return null;}// 计算当前时间所在的样本窗口index,也就是样本窗口的下标,即在计算数组LeapArray中的下标int idx = calculateTimeIdx(timeMillis);// Calculate current bucket start time.// 计算当前样本窗口的开始时间点long windowStart = calculateWindowStart(timeMillis);while (true) {// 获取到当前时间所在的样本窗口WindowWrap<T> old = array.get(idx);// 代表当前时间所在的样本窗口没有,需要创建if (old == null) {/** B0 B1 B2 NULL B4* ||_______|_______|_______|_______|_______||___* 200 400 600 800 1000 1200 timestamp* ^* time=888* bucket为空, 所以新建并更新** 如果旧的bucket不存在,那么我们在windowStart创建一个新的bucket,然后尝试通过CAS操作* 更新循环数组。只有一个线程可以成功更新,而其他线程争夺这个时间片*/// 创建一个时间窗口WindowWrap<T> window = new WindowWrap<T>(windowLengthInMs, windowStart, newEmptyBucket(timeMillis));// CAS 将新建窗口放入LeapArrayif (array.compareAndSet(idx, null, window)) {// 更新成功,返回创建的bucketreturn window;} else {// 获取锁失败, 线程将放弃其时间片以等待可用的bucketThread.yield();}} else if (windowStart == old.windowStart()) { // 若当前样本窗口的起始时间与计算出的样本窗口起始时间相同,则说明这两个是同一个样本窗口,直接获取就行/** B0 B1 B2 B3 B4* ||_______|_______|_______|_______|_______||___* 200 400 600 800 1000 1200 timestamp* ^* time=888* 桶3的起始时间: 800,所以它是最新的** 如果当前windowStart等于旧bucket的开始时间戳,则表示时间在bucket内,因此直接返回bucket*/return old;} else if (windowStart > old.windowStart()) { // 若当前样本窗口的起始时间大于计算出的样本窗口起始时间。说明计算出来的样本窗口已经过时了,需要将原来的样本窗口替换为新的样本窗口。 数组的环形数组,不是无限长的,比如存1s,1000个样本窗口,那么下1s的1000个时间窗口会覆盖上一秒的/** (old)* B0 B1 B2 NULL B4* |_______||_______|_______|_______|_______|_______||___* ... 1200 1400 1600 1800 2000 2200 timestamp* ^* time=1676* Bucket 2的startTime: 400,已弃用,应重置** 如果旧bucket的开始时间戳落后于当前时间,则表示该bucket已弃用。我们必须将bucket重置为当前的windowStart。请注意,重置和清理操作很难是原子的,所以我们需要一个更新锁来保证bucket更新的正确性** 更新锁是有条件的(小范围),只有当桶被弃用时才会生效,所以在大多数情况下它不会导致性能损失*/if (updateLock.tryLock()) {try {// 成功获取更新锁,现在我们重置bucket// 替换老的样本窗口return resetWindowTo(old, windowStart);} finally {updateLock.unlock();}} else {// 获取锁失败,线程将放弃其时间片以等待可用的bucketThread.yield();}} else if (windowStart < old.windowStart()) { // 若当前样本窗口的起始时间小于计算出的样本窗口起始时间,一般不会出现,因为时间不会倒流,除非人为修改系统时间(即时钟回拨)return new WindowWrap<T>(windowLengthInMs, windowStart, newEmptyBucket(timeMillis));}}
}
流程图如下
上述使用到的数组是一个环形数组, 不是我们所谓的普通数组, 目地就是复用, 节省内存
环形数组的工作原理
现有环形数组, 长度为8, 目前已经用了6个位置
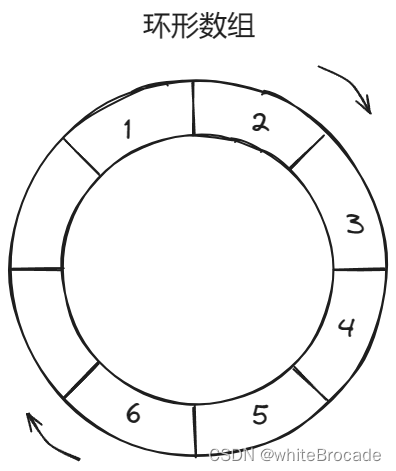
继续添加元素
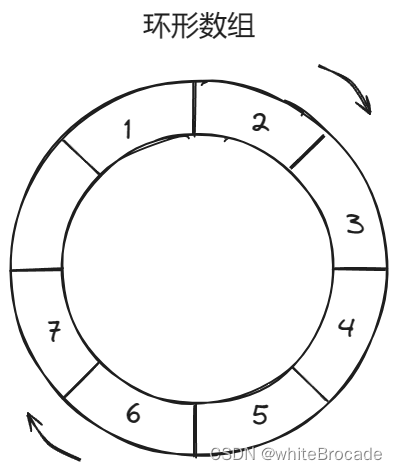
继续添加元素
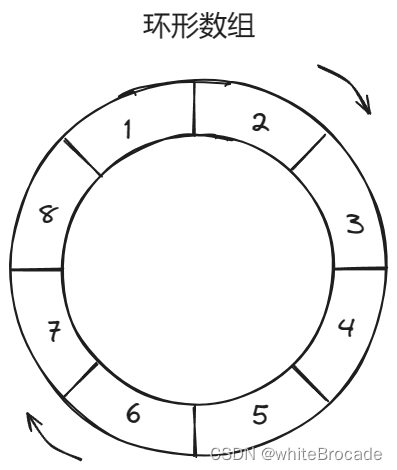
目前元素已经满了, 接着添加, 发现它把原来存在元素1的位置替换了, 换成了9
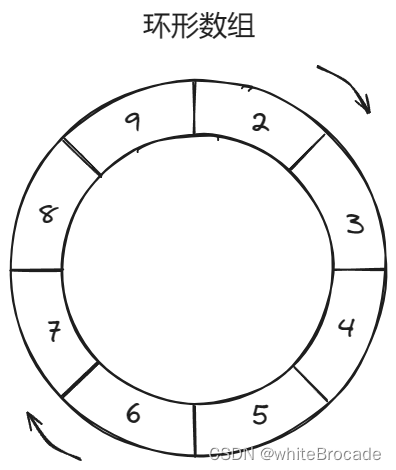
继续添加, 同理可得, 那么元素应该就应该替换到元素2这个位置
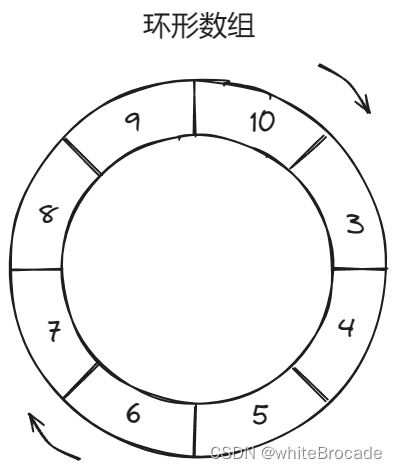
上边就是环形数组的工作原理
currentWindow的图文分析
old == null
这个表示环形数组都没有, 那么就创建一个环形数组, 并将元素设置进去, 这里就不画图了
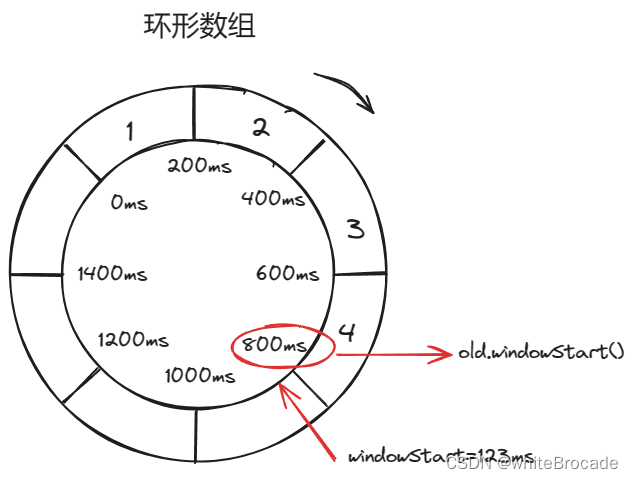
windowStart > old.windowStart()
windowStart == old.windowStart()
windowStart < old.windowStart()
参考资料
通关 Sentinel 流量治理框架 - 编程界的小學生
10张图带你彻底搞懂限流、熔断、服务降级
分布式服务限流实战,已经为你排好坑了
服务限流详解
新来个技术总监,把限流实现的那叫一个优雅,佩服!
接口限流算法总结