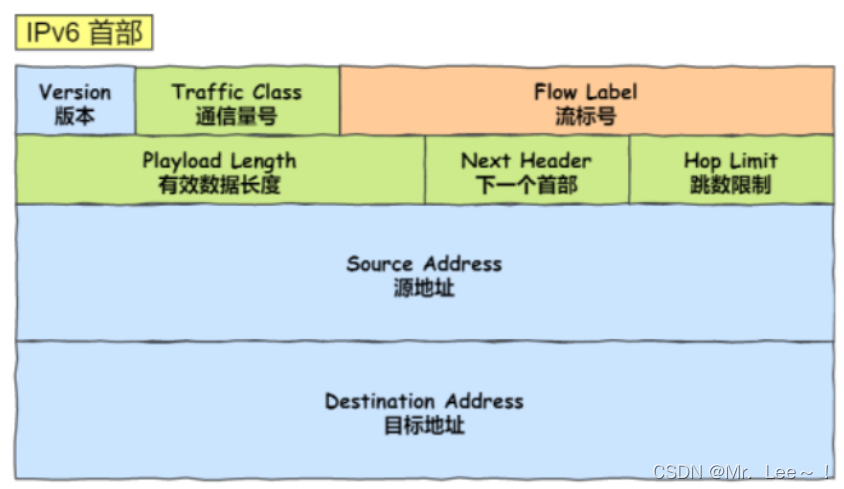
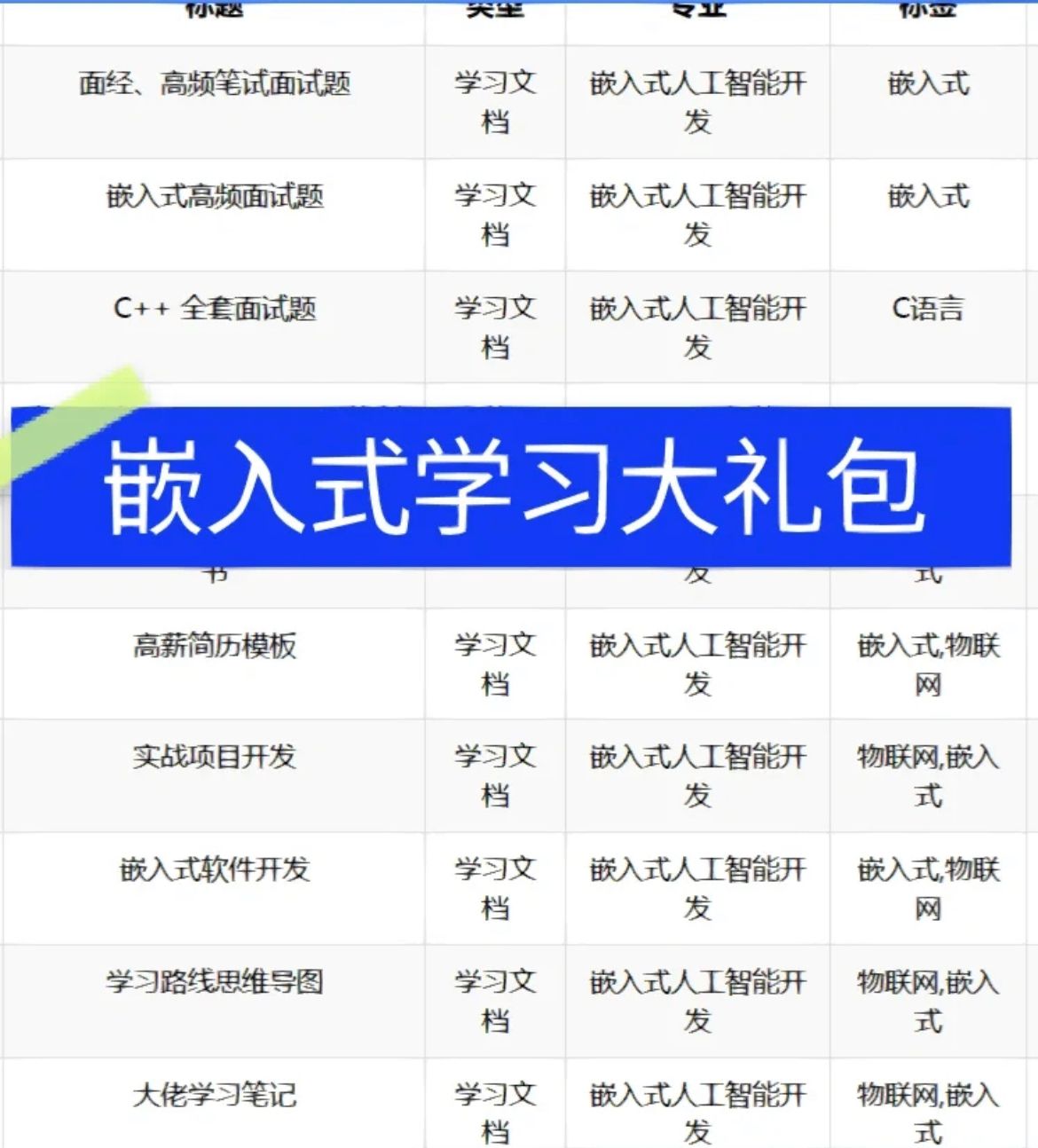
一、注释
代码中包含了几个关于PCI(外围组件互联)设备中断请求(IRQ)向量分配的函数,以及内联函数声明,下面是对这些函数的中文注释:
static inline int
pci_alloc_irq_vectors_affinity(struct pci_dev *dev, unsigned int min_vecs,unsigned int max_vecs, unsigned int flags,const struct irq_affinity *aff_desc)
{// 如果PCI设备需要分配传统的中断且只需要分配一个向量,并且目标设备已经有了分配好的中断向量if ((flags & PCI_IRQ_LEGACY) && min_vecs == 1 && dev->irq)return 1; // 直接返回1,表示已分配一个传统中断向量。return -ENOSPC; // 否则返回错误码-ENOSPC,表示没有足够的空间。
}/*** pci_alloc_irq_vectors_affinity - 为设备分配多个IRQs* @dev: 要操作的PCI设备* @min_vecs: 所需的最小向量数(必须>= 1)* @max_vecs: 所需的最大向量数* @flags: 分配的标志或quirks* @affd: 可选,对亲和性要求的描述** 为@dev分配多达@max_vecs个中断向量,首先尝试使用MSI-X或MSI* 向量(如果可用),如果两者都不可用,则使用单个传统向量作为回退。* 如果成功,返回分配的向量数(可能小于@max_vecs),或者在出错时返回负数错误码。* 如果@dev可用的中断向量少于@min_vecs,函数将以错误码-ENOSPC失败。** 要获取可以传递给request_irq()使用的Linux IRQ号,请使用pci_irq_vector()辅助函数。*/
int pci_alloc_irq_vectors_affinity(struct pci_dev *dev, unsigned int min_vecs,unsigned int max_vecs, unsigned int flags,const struct irq_affinity *affd)
{static const struct irq_affinity msi_default_affd; // 静态的亲和性结构体,默认情况int vecs = -ENOSPC; // 初始化为没有足够空间的错误码// 根据标志设置亲和性指针,要么使用传递的affd参数,要么使用默认的结构体if (flags & PCI_IRQ_AFFINITY) {if (!affd)affd = &msi_default_affd; // 如果affd为空,则使用默认亲和性描述} else {if (WARN_ON(affd)) // 如果affd不为空但没有设置PCI_IRQ_AFFINITY标志,打印警告affd = NULL; // 并将affd设置为空}// 尝试使用MSI-X向量if (flags & PCI_IRQ_MSIX) {vecs = __pci_enable_msix_range(dev, NULL, min_vecs, max_vecs, affd);if (vecs > 0) // 如果成功分配,则直接返回分配的向量数return vecs;}// 尝试使用MSI向量if (flags & PCI_IRQ_MSI) {vecs = __pci_enable_msi_range(dev, min_vecs, max_vecs, affd);if (vecs > 0) // 如果成功分配,则直接返回分配的向量数return vecs;}// 使用传统IRQ向量if (flags & PCI_IRQ_LEGACY) {if (min_vecs == 1 && dev->irq) {pci_intx(dev, 1); // 启用设备的INTx中断return 1; // 返回1表示成功分配了一个传统中断向量}}// 返回向量数或错误码return vecs;
}
EXPORT_SYMBOL(pci_alloc_irq_vectors_affinity); // 导出函数使得其它模块也可以调用static inline int
pci_alloc_irq_vectors(struct pci_dev *dev, unsigned int min_vecs,unsigned int max_vecs, unsigned int flags)
{// 调用pci_alloc_irq_vectors_affinity函数,但不传递affd参数(即为NULL)return pci_alloc_irq_vectors_affinity(dev, min_vecs, max_vecs, flags, NULL);
}这段代码中函数__pci_enable_msix_range`和函数`__pci_enable_msi_range`并没有给出,它们在 Linux 内核中负责实际的 MSI-X 和 MSI 中断分配过程。

二、讲解分析
pci_alloc_irq_vectors() 是 Linux 内核中的一个函数,用于分配中断号(也称为中断向量)给支持消息信号中断(MSI或MSI-X)的 PCI 设备。简单来说,这个函数帮助PCI设备设置所需的中断线路,使其能够处理中断。
每个PCI设备在工作时可能需要处理一些特定的事件,例如数据传输完成或错误发生。这些事件会通过中断的形式通知CPU,中断向量就是这些不同中断类型的唯一标识。
在多中断线路的情况下,设备可以为不同类型的事件分配不同的中断号,从而提高效率。MSI或MSI-X中断是更先进的中断机制,能够提供比传统的线性中断(如PCI的INTx中断)更好的可扩展性和性能。
pci_alloc_irq_vectors() 函数的基本用法如下:
参数
- dev: 指向PCI设备的指针。
- min_vecs: 设备请求的最小中断向量数。
- max_vecs: 设备请求的最大中断向量数。
- flags: 分配中断向量时的标识,通常是 PCI_IRQ_LEGACY(传统中断)、`PCI_IRQ_MSI`(消息信号中断)、`PCI_IRQ_MSIX`(MSI-X中断)中的一个或多个组合。
返回值
成功时返回分配的中断数量(至少等于 min_vecs),错误时返回负值。
示例
struct pci_dev *pdev; // 已经初始化的 PCI 设备结构体指针
int nr_vecs; // 分配的中断向量数量// 假设设备至少需要2个中断向量,最多能支持4个
nr_vecs = pci_alloc_irq_vectors(pdev, 2, 4, PCI_IRQ_ALL_TYPES);
if (nr_vecs < 0) {// 错误处理,例如打印错误日志pr_err("Failed to allocate IRQ vectors\n");
} else {// 分配成功,可以设置中断处理函数
}在调用这个函数以后,应该使用 pci_irq_vector() 来获取每个向量的实际中断号,然后使用这些中断号注册对应的中断处理函数。
请注意,在不再需要中断时,应当调用 pci_free_irq_vectors() 来释放这些中断向量以避免资源泄露。
另外,由于内核API可能会随着内核版本更迭而变动,建议根据实际使用的内核版本查看对应的内核文档或源码,以获得最准确的信息。

这段代码是Linux内核中的一部分,用于分配一个PCI设备的中断向量。
/*** pci_alloc_irq_vectors_affinity - 为设备分配多个IRQ* @dev: 要操作的PCI设备* @min_vecs: 所需的最小向量数量(必须>= 1)* @max_vecs: 最大(期望的)向量数量* @flags: 分配时的标志或特性* @affd: 可选的亲和性需求描述** 为@dev分配多达@max_vecs个中断向量,如果可用,将使用MSI-X或MSI向量,* 如果两者都不可用,则回退到单个传统向量。如果成功,返回分配的向量数量* (可能小于@max_vecs),或者在错误时返回一个负的错误码。* 如果为@dev可用的中断向量少于@min_vecs,函数将失败并返回-ENOSPC。** 要获取可以传递给request_irq()的Linux IRQ号,请使用pci_irq_vector()帮助函数。*/这个函数主要分为几个部分:
1. 检查是否需要特定的亲和性设置,如果`flags`参数中包含`PCI_IRQ_AFFINITY`且没有提供亲和性描述`affd`,则会使用默认的亲和性描述。
2. 尝试分配MSI-X中断向量,如果`flags`中设置了`PCI_IRQ_MSIX`并且成功分配,则返回分配的向量数量。
3. 如果上一步失败,将尝试分配MSI中断向量,如果`flags`中设置了`PCI_IRQ_MSI`并且成功分配,同样会返回分配的向量数量。
4. 如果MSI-X和MSI都无法分配,并且允许使用传统的IRQ(通过`PCI_IRQ_LEGACY`标志),那么如果`min_vecs`为1且设备有传统IRQ,则会启用它并返回1。
5. 如果所有方法都失败,则返回-ENOSPC,表示没有空间。EXPORT_SYMBOL是一个宏,用于将`pci_alloc_irq_vectors_affinity`函数导出到模块外部,这样其他模块也可以调用它。最后是一个辅助函数`pci_alloc_irq_vectors`,这个函数封装了对`pci_alloc_irq_vectors_affinity`的调用,但是不需要传递亲和性描述,是一个更为简单的版本。

pci_alloc_irq_vectors_affinity 函数用于为PCI设备分配一个或多个中断向量(IRQs)。在支持MSI-X或MSI的系统中,这些中断向量使得设备可以触发多个中断处理程序,从而提高系统的性能和可伸缩性。如果这些高级特性不可用,该函数将回退到传统的单一中断向量。现在我会按照您的要求用中文对函数进行解释。
int pci_alloc_irq_vectors_affinity(struct pci_dev *dev, unsigned int min_vecs,unsigned int max_vecs, unsigned int flags,const struct irq_affinity *affd)- dev: 这是一个指向 pci_dev 结构体的指针,表示我们要为其分配中断向量的PCI设备。
- min_vecs: 要求分配的最小中断向量数量。此值必须大于或等于1。
- max_vecs: 期望分配的最大中断向量数量。
- flags: 一系列的标志位,用于指定分配的类型或特性,例如,是否使用MSI或MSI-X。
- affd: 描述CPU亲和性需求的结构体,用于指定哪个处理器应该处理特定的中断。
函数的返回值是分配到的中断向量数量,如果成功的话;如果失败,将返回一个负的错误代码。
函数内部逻辑如下:
1. 如果指定了`PCI_IRQ_LEGACY`标志,并且设备已经有一个分配的中断(`dev->irq`),只需返回1,表示使用这一个已分配的传统中断。
2. 如果设置了`PCI_IRQ_AFFINITY`标志,如果调用者没有提供CPU亲和性描述(`affd`是空的),函数会使用默认的CPU亲和性描述。
3. 如果设置了`PCI_IRQ_MSIX`标志,函数首先尝试为MSI-X分配`min_vecs`到`max_vecs`的范围内的任意数量的中断向量。如果成功,返回分配到的向量数量。
4. 如果设置了`PCI_IRQ_MSI`标志并且MSI-X不可用或者没有分配到足够的中断,函数就尝试分配MSI中断向量。如果成功,同样返回分配的数量。
5. 如果设置了`PCI_IRQ_LEGACY`标志并且前面的方法都不可用或失败了,函数会尝试分配一个传统中断。如果设备已经有一个传统中断,并且`min_vecs`等于1,函数将启用这个传统中断并返回1。
6. 如果所有上述方法都失败了,函数返回错误码`-ENOSPC`,表示没有足够的资源可以分配。
pci_alloc_irq_vectors 函数是 pci_alloc_irq_vectors_affinity 的包装,它调用包装函数,但不设置CPU亲和性描述参数,传递`NULL`作为最后一个参数。
整体而言,这些函数用于在Linux内核中管理PCI设备的中断分配,它们通过尝试利用最先进的中断分配机制来提高设备和系统性能。如果这些方法不可用,将退回到单一的传统中断向量。

在 Linux 内核中,当看到一个函数有多个定义,一个是 static inline 定义在头文件中(如 include/linux/pci.h),另一个是非内联定义在源文件中(如 drivers/pci/msi.c),这是一个常见的实现模式,用于提供内联和非内联版本的函数。
1. 内联(`inline`)版本:这个版本被定义在头文件中,允许编译器在编译时直接将函数体插入到每个调用点,而不是进行函数调用。这样可以减少函数调用的开销,并有时候允许进一步的编译器优化。不过这会增加编译后的代码体积,因为每个调用点都有一个函数体的副本。
2. 非内联(normal / out-of-line)版本:这个版本是在源文件中定义的。非内联函数只有一个函数体副本,无论在哪里调用,都会通过常规的函数调用机制来执行。非内联版本通常用于那些可能在编译期间不可见的模块,或者是为了减少代码膨胀。
至于为什么具体有两个 pci_alloc_irq_vectors_affinity 的定义:
- static inline 定义主要是给那些包含了该头文件的编译单元提供一个内联版本。当这个函数非常小,并且调用频繁时,内联版本可以提高性能。
- EXPORT_SYMBOL 版本是给其他模块使用的,当其他模块需要链接到这个函数时,它们不会使用内联版本,而是使用编译到内核模块中的非内联版本。
在 static inline 定义中,可以看到它包含了一些简单的逻辑,然后返回 -ENOSPC,这看上去像是一种默认或者备份行为。它大概是提供给那些没有实际实施这个函数或者在某些编译配置下不需要完整定义的场景,这样在内联版本中会返回一个错误。
在非内联版本中,可以看到函数是通过一系列的更复杂逻辑来尝试分配中断向量,并且根据参数和系统可用资源的实际情况返回成功或者错误码。
这两个定义看起来是要同步使用的,并且在正常情况下,大多数时间会使用非内联版本(`EXPORT_SYMBOL`)的函数。在某些特殊的环境下,如果内核配置为不包含完整的中断分配器代码,内联版本就会被使用,确保即使功能不完整,代码仍然能够编译通过。

这个 static inline 版本的 pci_alloc_irq_vectors_affinity 函数看上去是一个简化的或者是一个占位符版本。在这种特定的简化实现中,函数似乎只在特定的条件下返回成功值,即当下面的条件为真时:
- flags 参数包含 PCI_IRQ_LEGACY,表示请求分配传统(legacy)的中断。
- min_vecs 参数等于 1,表示只请求分配一个中断向量。
- dev->irq 不为零,表示设备已经有一个分配的传统 IRQ。
如果这些条件都满足,它就返回 1,表示分配了一个传统的 IRQ。如果不满足这些条件,它最终返回 -ENOSPC,这是一个错误码,表示没有空间(no space),通常用于表示无法分配所请求的资源。
这个内联函数的存在可能有几个目的:
1. 占位符:它可能作为在编译时不包括更复杂中断分配逻辑的内核配置提供的一个占位符。
2. 优化:对于某些特定情形下的调用,如果它们满足这种快速检查,那么可能使用这个更简单的版本以降低开销,啊虽然在这个上下文中,这种优化似乎不太可能。
3. 兜底逻辑:在系统只支持传统(legacy)IRQs或者编译条件下没有提供完整实现时,这个内联版本确保函数总是存在,允许编译通过但运行时表现为通常无法分配多个中断向量。
另一方面,非内联版本的 pci_alloc_irq_vectors_affinity(通常在 drivers/pci/msi.c 中定义)将包含实际分配 MSI 或 MSI-X 中断向量的复杂逻辑,并导出给内核或模块以供使用。
所以,这个内联函数不是一个完整实现,而是存在于特定编译条件或为了满足其他编译级要求。在实际的分配操作中,更复杂的非内联函数将会被使用。

在提供的代码中,存在两个不同的 pci_alloc_irq_vectors_affinity 函数的定义:一个可能是实际的实现,另一个是静态内联的版本。通常,在良好编写的代码库中不会看到同一功能的两个不同的定义。所见到的可能是一个真正的实现和一个被设计为存根或兼容性封装的内联版本。
当在一个 .c 文件中包含 pci.h 并调用 pci_alloc_irq_vectors 函数时,会发生什么,依赖于 pci.h 头文件提供 pci_alloc_irq_vectors_affinity 函数的定义(内联的或其它的)还是仅仅声明。
1. 如果头文件仅仅声明了 pci_alloc_irq_vectors_affinity 函数,并且实现在 drivers/pci/msi.c 中,那么链接器会在链接时将调用解析到 msi.c 中的实际函数定义。
2. 如果头文件 pci.h 提供了一个内联定义,那么这个定义将直接使用在调用它的编译单元里(包含 pci.h 的 .c 文件)。
在特定情况中,头文件中的 static inline 版本非常简单,总是返回 1 或 -ENOSPC,这表明它可能是一个后备或存根实现。通常,头文件中的 static inline 函数作为小巧、频繁使用的助手用来内联到代码中,以节省函数调用的开销,或作为兼容性桥梁。
msi.c 中更复杂的、非内联版本的 pci_alloc_irq_vectors_affinity 似乎是实际分配 MSI-X 或 MSI 向量能力的真正实现。通常,这个版本应该是实际使用的版本,因为它包含分配向量所需的实际逻辑。
当一个 .c 文件包含 pci.h 并使用 pci_alloc_irq_vectors 函数时,如果有链接到 msi.c,链接器应该将这个调用解析到 msi.c 文件中的真正实现,因为内联函数只是一个存根,除了返回一个常量值或错误之外,没有提供任何功能。真正的实现具有外部链接(不是静态的),其符号将可供链接器使用。
总的来说,如果调用 pci_alloc_irq_vectors,将使用的 pci_alloc_irq_vectors_affinity 是在 .c 文件中实际定义的,除非在该 .c 文件包含的头文件中提供了一个内联定义以覆盖。如果有内联定义和外部链接定义两者可用,通常会使用外部定义,除非在函数调用发生前包含的头文件中指定了内联定义为覆盖。

函数声明:include\linux\pci.h
函数定义:drivers\pci\msi.c