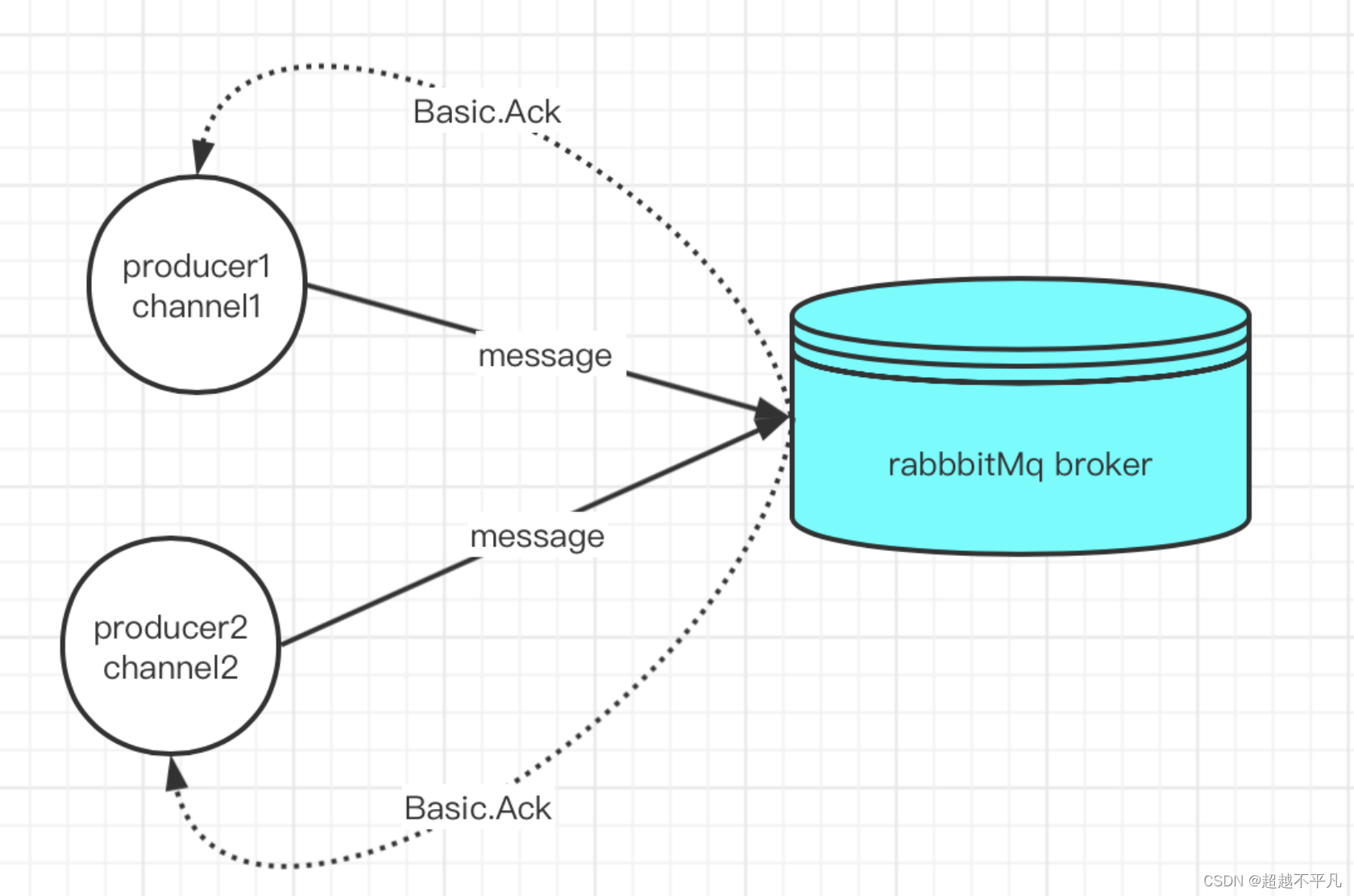
目录
前言
一、什么是线性回归
二、什么是逻辑回归
三、基于Python 和 Scikit-learn 库实现线性回归
示例代码:
使用线性回归来预测房价:
四、基于Python 和 Scikit-learn 库实现逻辑回归
五、总结
线性回归的优缺点总结:
逻辑回归(Logistic Regression)是一种常用的分类算法,具有许多优点和缺点。
博主介绍:✌专注于前后端领域开发的优质创作者、秉着互联网精神开源贡献精神,答疑解惑、坚持优质作品共享。本人是掘金/腾讯云/阿里云等平台优质作者、擅长前后端项目开发和毕业项目实战,深受全网粉丝喜爱与支持✌有需要可以联系作者我哦!
🍅文末三连哦🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
前言
机器学习的起源可以追溯到人工智能的发展历程。虽然人工智能的概念早在20世纪50年代就已经出现,但直到之后几十年里,随着计算机技术的不断发展和数据的日益增多,机器学习才逐渐成为人工智能领域的主流技术之一。
以下是机器学习发展的几个重要时期和里程碑:
-
逻辑理论和符号学习: 20世纪50年代末到60年代初,人工智能研究主要集中在基于逻辑理论和符号推理的方法上。这一时期出现了逻辑推理、专家系统等符号学习方法,但受限于计算机技术和数据量的限制,这些方法的应用受到了很大的局限性。
-
连接主义和神经网络: 20世纪80年代末到90年代初,随着计算机性能的提升和神经科学的研究进展,连接主义和神经网络等基于模拟生物神经系统的方法开始受到关注。这一时期出现了感知机、多层感知机等基础神经网络模型,但由于计算资源有限以及理论上的一些困难,神经网络的发展进展缓慢。
-
统计学习: 20世纪90年代中期以后,随着统计学习方法的兴起,机器学习开始进入了快速发展的时期。统计学习方法将机器学习问题转化为统计推断问题,引入了概率论和统计学的理论基础,并在分类、回归、聚类等领域取得了很大成功。支持向量机、决策树、随机森林等经典机器学习算法相继出现。
-
深度学习: 21世纪初,随着大数据和计算资源的快速增长,深度学习成为了机器学习领域的新热点。深度学习利用多层神经网络模型来学习数据的高级表示,解决了传统神经网络中的一些问题,并在计算机视觉、自然语言处理等领域取得了突破性进展。
一、什么是性回归线
线性回归是一种用于建模输入变量与连续输出变量之间关系的线性方法。它假设输入变量与输出变量之间存在线性关系,即输出变量可以由输入变量的线性组合加上误差项得到。线性回归模型的基本形式可以表示为:

其中, 是输出变量,
是输入变量,
是模型的参数(斜率和截距),
是误差项。
线性回归的目标是找到最佳的模型参数,使得观测值与模型预测值之间的残差平方和最小化。常用的方法是最小二乘法,即通过最小化观测值与模型预测值之间的残差平方和来估计模型参数。
线性回归广泛应用于各种领域,例如经济学、统计学、工程学等,常用于预测和建模。在实践中,线性回归模型可以通过各种优化算法进行求解,例如梯度下降法、正规方程法等。
二、什么是逻辑回归
逻辑回归是一种用于建模输入变量与二元分类输出变量之间关系的线性方法。尽管名字中带有“回归”,但实际上逻辑回归是一种分类模型,而不是回归模型。逻辑回归通过使用逻辑函数(也称为sigmoid函数)将线性组合的结果转换为一个概率值,从而将连续的输出转化为二元的分类结果。
逻辑回归模型的基本形式可以表示为:

其中,是输出变量为1的概率,
是输入变量,
是模型的参数(斜率和截距)。
逻辑回归模型通常使用最大似然估计法来估计参数,目标是最大化观测值属于其真实类别的概率。在训练过程中,逻辑回归模型会输出一个介于0和1之间的概率值,表示观测值属于某一类的概率。然后根据设定的阈值(通常为0.5),将概率值映射到二元分类结果。
逻辑回归模型常用于二元分类问题,例如预测患病与否、垃圾邮件分类等。它简单、高效,并且易于理解和实现,是许多机器学习算法中的基础模型之一。
三、基于Python 和 Scikit-learn 库实现线性回归
示例代码:
# 导入必要的库
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt# 生成一些示例数据
np.random.seed(0)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建线性回归模型
model = LinearRegression()# 在训练集上拟合模型
model.fit(X_train, y_train)# 在训练集和测试集上进行预测
y_train_pred = model.predict(X_train)
y_test_pred = model.predict(X_test)# 计算训练集和测试集上的均方误差
train_mse = mean_squared_error(y_train, y_train_pred)
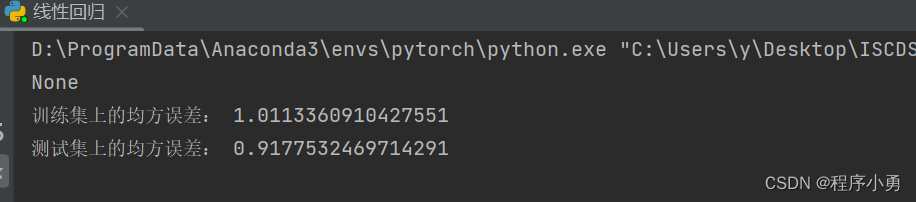
test_mse = mean_squared_error(y_test, y_test_pred)print("训练集上的均方误差:", train_mse)
print("测试集上的均方误差:", test_mse)# 可视化拟合结果
plt.scatter(X_test, y_test, color='black')
plt.plot(X_test, y_test_pred, color='blue', linewidth=3)
plt.xlabel('X')
plt.ylabel('y')
plt.title('Linear Regression')
plt.show()
执行结果:
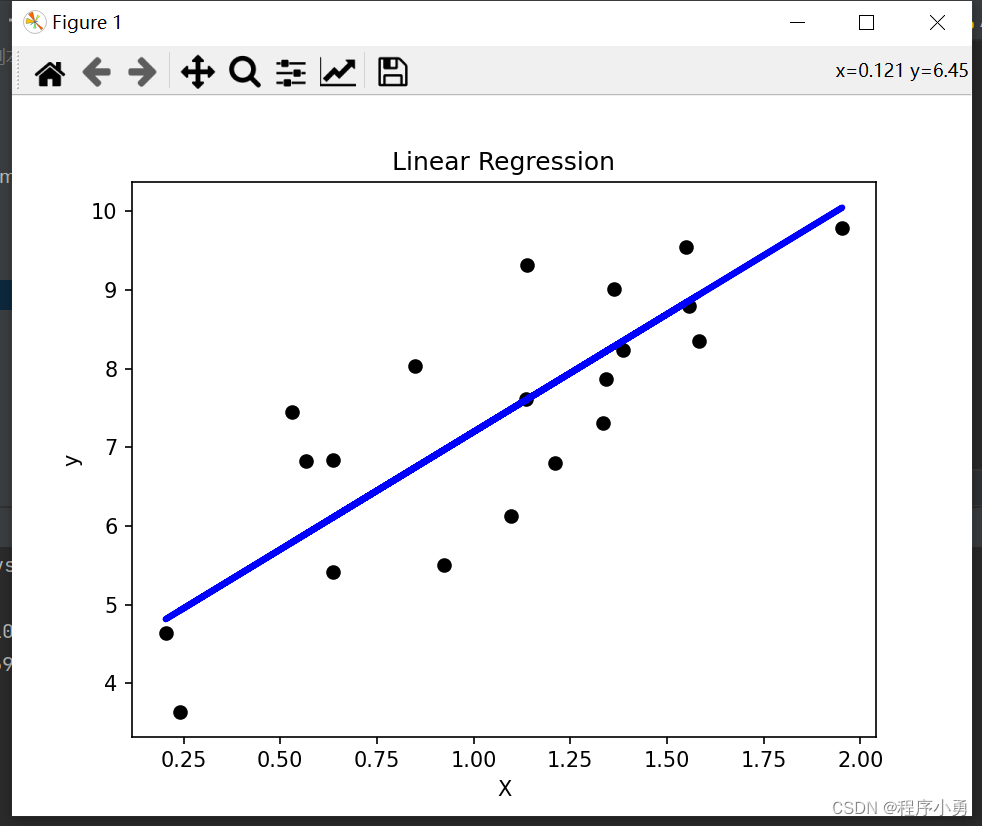
使用线性回归来预测房价:
我们首先加载了一个包含房屋面积和价格的数据集。然后,我们使用线性回归模型来拟合房价与房屋面积之间的关系。接下来,我们将数据分为训练集和测试集,并在训练集上训练模型。最后,我们使用测试集评估模型的性能,并可视化预测结果。
注:波士顿房价预测数据下载(点击即可挑战链接)
# 导入必要的库
import numpy as np
import pandas
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error# 读取数据集
data = pandas.read_csv('C:\\Users\\y\\Desktop\\ISCDS - 副本\\AI\\Imgs\img\\train.csv')# 可视化数据分布
plt.scatter(data['GrLivArea'], data['SalePrice'])
plt.xlabel('Area (sq.ft)')
plt.ylabel('Price ($)')
plt.title('House Prices vs. Area')
plt.show()# 准备数据
X = data['Area'].values.reshape(-1, 1) # 输入特征:房屋面积
y = data['Price'].values # 输出标签:房价# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建线性回归模型
model = LinearRegression()# 在训练集上拟合模型
model.fit(X_train, y_train)# 在测试集上进行预测
y_pred = model.predict(X_test)# 计算模型的均方误差
mse = mean_squared_error(y_test, y_pred)
print("模型的均方误差:", mse)# 可视化预测结果
plt.scatter(X_test, y_test, color='black')
plt.plot(X_test, y_pred, color='blue', linewidth=3)
plt.xlabel('Area (sq.ft)')
plt.ylabel('Price ($)')
plt.title('House Prices Prediction')
plt.show()
执行结果:
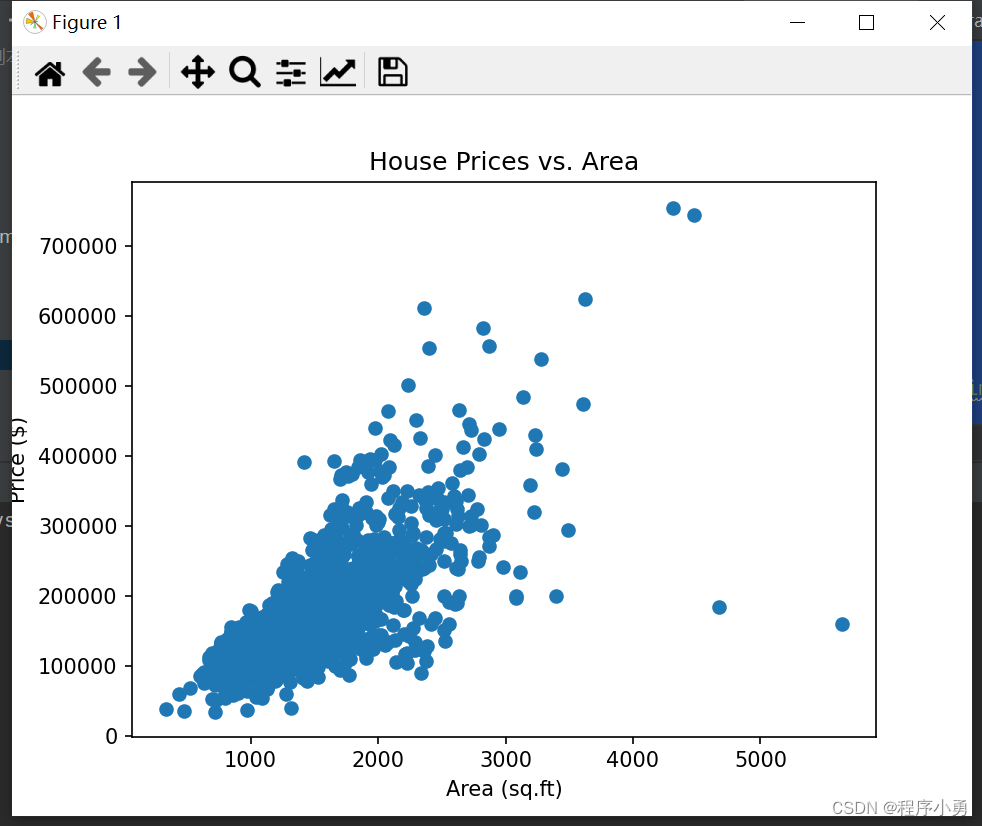
房子面积与价格关系图
四、基于Python 和 Scikit-learn 库实现逻辑回归
在这里,我将使用Scikit-learn库中的一个内置的数据集作为示例。你可以使用
load_iris()函数来加载鸢尾花数据集。首先加载了鸢尾花数据集,并将其分为训练集和测试集。然后,我们创建了一个逻辑回归模型并在训练集上拟合了模型。最后,我们使用测试集评估了模型的性能,并计算了准确率、打印了分类报告和混淆矩阵。
# 导入必要的库
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix# 加载鸢尾花数据集
iris = load_iris()# 准备数据
X = iris.data # 输入特征
y = iris.target # 输出标签# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=40)# 创建逻辑回归模型
model = LogisticRegression()# 在训练集上拟合模型
model.fit(X_train, y_train)# 在测试集上进行预测
y_pred = model.predict(X_test)# 计算模型的准确率
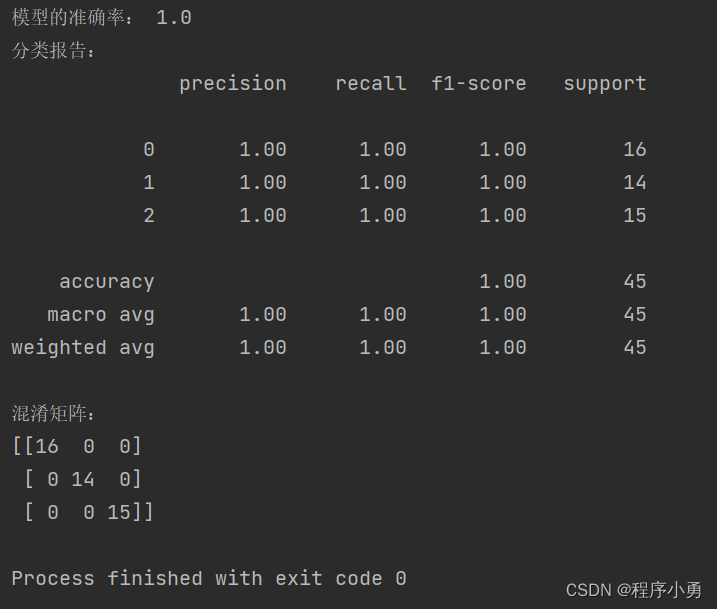
accuracy = accuracy_score(y_test, y_pred)
print("模型的准确率:", accuracy)# 打印分类报告
print("分类报告:")
print(classification_report(y_test, y_pred))# 绘制混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
print("混淆矩阵:")
print(conf_matrix)
执行结果:
五、总结
线性回归的优缺点总结:
优点:
-
简单而直观: 线性回归模型简单易懂,容易解释,适用于初学者入门机器学习。
-
高效: 训练和预测的速度较快,适用于处理大规模数据集。
-
可解释性强: 可以量化输入变量与输出变量之间的线性关系,提供了对数据的直观理解。
-
稳定性好: 对于输入变量之间存在多重共线性的情况,线性回归表现稳定。
-
易于扩展: 可以与其他模型结合使用,如正则化方法(如岭回归、Lasso回归)等。
缺点:
-
对非线性关系拟合能力有限: 无法很好地处理输入变量与输出变量之间的非线性关系,容易出现欠拟合问题。
-
对异常值敏感: 对于数据中的异常值较为敏感,容易受到极端值的影响,需要进行异常值处理。
-
需要满足线性假设: 要求输入变量与输出变量之间存在线性关系,因此无法捕捉到复杂的非线性关系。
-
可能存在欠拟合或过拟合问题: 当模型过于简单或者特征空间较大时,容易出现欠拟合问题;而模型过于复杂或者数据量较小时,又容易出现过拟合问题。
-
无法处理分类问题: 线性回归主要用于解决连续型输出变量的问题,不适用于分类问题。
逻辑回归(Logistic Regression)是一种常用的分类算法,具有许多优点和缺点。
优点:
-
简单和快速: 逻辑回归是一种简单而快速的分类算法,易于实现和理解,适用于处理大规模数据集。
-
可解释性强: 逻辑回归模型的结果易于解释,能够输出特征对分类结果的影响程度,提供了对数据的直观理解。
-
适用于线性可分问题: 当数据集是线性可分的情况下,逻辑回归能够表现出较好的性能。
-
不易过拟合: 逻辑回归在参数调整适当的情况下,很少会出现过拟合的问题,即使数据集的特征空间很大。
-
能够输出概率值: 逻辑回归模型可以输出样本属于某一类的概率值,而不仅仅是类别标签,这对于一些需要概率估计的场景十分有用。
缺点:
-
只能处理线性可分问题: 逻辑回归是一种线性分类算法,只适用于线性可分的问题,无法处理非线性关系。
-
对异常值敏感: 逻辑回归对异常值敏感,容易受到极端值的影响,需要对数据进行预处理或异常值处理。
-
无法处理复杂关系: 逻辑回归不能很好地处理特征之间的复杂非线性关系,对于非线性的分类问题性能较差。
-
需要特征工程: 逻辑回归的性能受特征选择和特征工程的影响较大,需要合适的特征来提高模型性能。
-
可能存在欠拟合问题: 当数据集的特征空间较大且特征之间关系复杂时,逻辑回归容易出现欠拟合的问题,性能较差。