爬取淘女郎模特图片与相关信息
- (一) 解析淘女郎首页网站地址
- 打开淘女郎首页界面 https://www.taobao.com/markets/mm/mm2017,点击 查看更多,然后 F12 进入网页抓包工具,按 F5观察数据加载变化。审查元素发现,我们想找的图片的链接在网页的源代码里更本找不到,所以这个网页应该不是简单的静态网页。不然那那些妹子图不给我们轻易就得到了。。哈哈。不过不怕。我们进入 NETwork 里面看有没有动态加载的文件是我们想要的。

果然,仔细观察发现,里面加载的内容跟当前页面的人名及其他信息完全吻合。便可以肯定这就是我们要的数据。所以,查看request url获取相关url。https://mm.taobao.com/alive/list.do?scene=all&page=1
而后面的page=1 则就表示,第一页。只要我们把数值改变便可以加载到对应的页码。
个人觉得这个还算简单。所以直接上代码了:
import urllib.request
import re
from user_agent.base import generate_user_agentclass Spider:# 定义需要爬取的页数def __init__(self, page):self.page = int(page)# 获取要爬取的图片的页数def get_pags(self, page):for i in range(1, page+1):url = "https://mm.taobao.com/alive/list.do?scene=all&page=%d"%iyield url# 定义常用的 URL 打开函数def open_url(self, url):user_agent = generate_user_agent()header = {"User-Agent":user_agent}req = urllib.request.Request(url, headers=header)response = urllib.request.urlopen(req).read() # 文件未进行decode解码,此时为response二进制文件return response# 定义获取图片名称的函数def get_name(self, url):response = self.open_url(url).decode('gbk').encode('utf-8').decode('utf-8')name_list = re.compile('darenNick":"(.*?)"').findall(response)return name_list# 定义获取图片链接地址并返回图片内容def get_picture(self, url):response = self.open_url(url).decode('gbk').encode('utf-8').decode('utf-8')link_list = re.compile('avatarUrl":"(.*?)"').findall(response)for link in link_list:if re.compile('http:').match(link):img = self.open_url(link)else:link_ = 'http:'+ linkimg = self.open_url(link_)yield img # 这里一个二进制生成器,方便图片保存# 保存图片def save_picture(self, url):name = self.get_name(url)img = self.get_picture(url)list_zip = list(zip(name, img))for each in list_zip:with open('./首页/%s.jpg'%each[0], 'wb') as f:f.write(each[1])def main(self):links = self.get_pags(self.page)for link in links:print(link)self.get_name(link)self.get_picture(link)self.save_picture(link)print("It's done!!")if __name__ == "__main__":spider = Spider(67)spider.main()都是一些常见的爬虫知识,而我重点要讲的不是这个,而是这中间的这个decode编码问题(纯属个人的看法):这里面获取那些信息的时候那是出现那些编码错误,好像是由于,中文与utf-8的老毛病导致的。我试过在decode()参数中设置忽略ignore,与replace,然而并没有什么用。试来试去发现这种办法最靠谱了。不报错。如果有遇到相同错误的可以参考一下。
结果部分截图:
- (二) 解析淘女郎找模特网址地址
- 相比于首页来说,抓取”找模特”里面模特的信息,才算有点难度。但只要不怕辛苦,慢慢摸索。还是可以找到规律 的。一开始我也是一头雾水,等自己搞出来之后发现感觉蛮爽还。。
1,进入找模特
2,细心找
进入一个网页地址第一件事肯定是,审查元素。发现也不能在网页源码中找到信息。想想我们上面说的,那就是耐细的去网页数据包中找。先看有没有动态加载的XHR,一般都是在这个下面可以找到。没错。这个就是这么找到的。

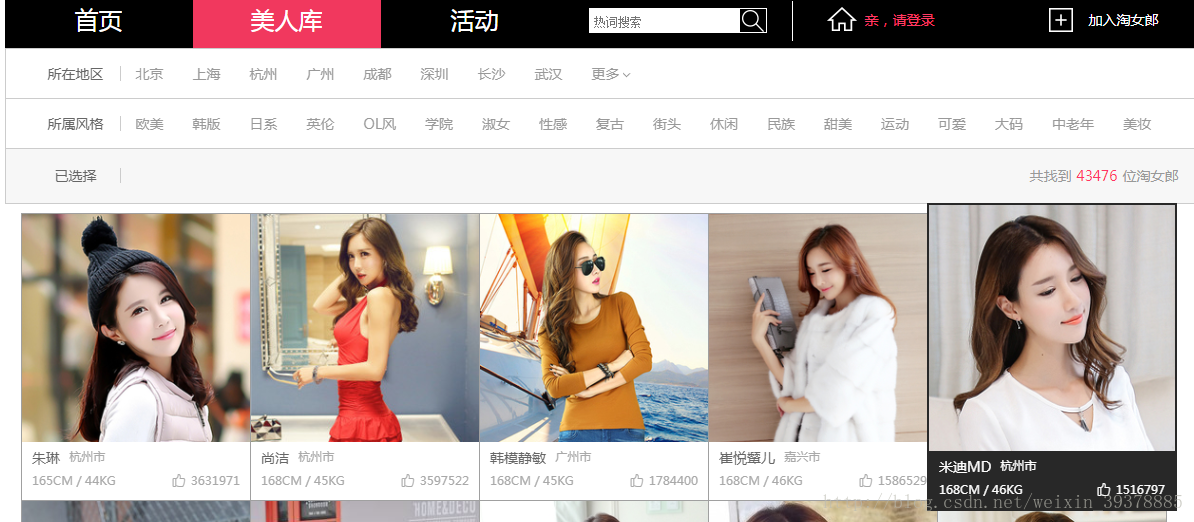
右边的数据仔细一看,发现它是一个像字典一样的东西,里面包含了很多键值对,再网页翻发现最里面那一层包含了30对键值对,分别包含一些用户名,userID ,等。这个时候再看这个网页,发现,刚好有30张照片。初步确定就是这个。
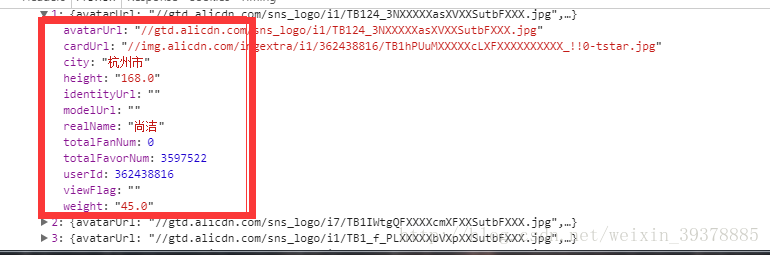
随后,找到request url 的请求网络地址,然后用浏览器打开。发现里面包含了30张照片的基本信息。于是我们就知道,这就是我们要的 真实的 URL。
3,信息获取
我们可以看到,每张图片下方都有对应模特的相关信息:名字,城市,身高,体重,被赞次数。
当我们点进去看,里面还有很多东西,相册里面有很多写真。模特卡里面还有跟多个人简介,三围等
这里呢,我们初步确定先只爬取模特的相关信息:名字,城市,身高,体重,被赞次数,并且每个模特单独使用一个文件夹。
4,分析代码可行度
我们需要编写一个函数从来获取图片
一个用来获取名字,另一个用来获取其他的相关信息。
这个应该容易。因为提取信息,只需要用到很简单的正则表达式即可。
在准备好这一切之后。发现,整个页面只有30张图片,是不是少了点。那么我们怎么翻页呢?首先肯定是去往源代码里找翻页的链接可不可以用。结果显示,是不可以的。那么我么怎么去做?下面来看:

在header里面可以看到,下面有个一个表单。而这个表单就是我们这个网页提交的数据。里面有一项currentpage,当你切换页码的时候,发现这个值跟随页码也在变化。好了。肯定就是这样了。
所有我们可以通过表单提交数据来达到切换到下一页的目的。然后结合我们前面的,大致的思路应该出来了,即:
①编写几个获取相应信息的函数
②然后编写保存这个些信息的函数
③接着通过切换下一页来达到保存更多的信息
5,给出代码参考
# -*- coding : utf-8 -*-
'''
Desc: 抓取淘宝中淘女郎模特的信息:名字,图片,身高,体重以文件夹形式保存信息保存为文本通过观察network 中变化,得出信息网址:https://mm.taobao.com/tstar/search/tstar_model.do?_input_charset=utf-8经过分析发现,无法通过此网站源码中链接实现翻页,于是想到通过提交表单数据实现翻页。request url 不变然后就是如何进入 各位模特的详情页 的问题了。通过观察发现:https://mm.taobao.com/self/aiShow.htm?&userId=268367415 可以进入对应模特的个人界面。https://mm.taobao.com/self/model_info.htm?user_id=268367415 可以进入对应model的模特卡,里面有跟多相关信息。而 userId 正好我们可以从前面那个链接获取到。通过改变ID便可实现对详情页面信息的爬取
'''
import urllib.request
import urllib.parse
import re
from user_agent.base import generate_user_agent
import os.path, os
from datetime import datetime
import threading
# 设立标志位flag 用于判断文件是否已经存在,用来避免重复操作
global flag
class Spider:def __init__(self):pass# 定义常用的 URL 打开函数def open_url(self, url, data):data = urllib.parse.urlencode(data).encode("utf-8")user_agent = generate_user_agent()header = {"User-Agent":user_agent}req = urllib.request.Request(url, data=data, headers=header)response = urllib.request.urlopen(req).read() # 文件未进行decode解码,此时为response二进制文件return response# 获取model的realnamedef get_realname(self, url, data):response = self.open_url(url, data).decode('gbk').encode('utf-8').decode('utf-8')name = re.compile('realName":"(.*?)"').findall(response)return name# 获取model头像地址,并返回图片的二进制信息def get_head(self, url,data):response = self.open_url(url,data).decode('gbk').encode('utf-8').decode('utf-8')link_list = re.compile('avatarUrl":"(.*?)"').findall(response)imgs = []for link in link_list:link_ = 'http:'+ linkimg = urllib.request.urlopen(link_).read()imgs.append(img)return imgs # 直接返回二进制文件,方便图片保存# 保存一张图片def save_img(self, img, folder, picname, i):print("正在保存 %s 的照片..." %picname)with open(folder+'/'+picname+'.jpg', 'wb') as f:f.write(img)print("完成!")# 获取model的 城市,身高,体重,被赞次数def get_desc(self,url, data):response = self.open_url(url,data).decode('gbk').encode('utf-8').decode('utf-8')city = re.compile('city":"(.*?)"').findall(response)height = re.compile('height":"(.*?)"').findall(response)weight = re.compile('weight":"(.*?)"').findall(response)favor = re.compile('totalFavorNum":(.*?),').findall(response)# 建立人物信息对应关系desc = list(zip(city, height, weight, favor))return desc# 保存一个人物信息def save_desc(self, folder, filename, desc, i):print("正在保存 %s 的个人信息" %filename)line = "model:\t\t %s \n\n所在城市:\t\t %s \n\n身高(cm):\t\t %s \n\n体重(kg):\t\t %s \n\n这货被赞过: %d 次" % (filename, desc[i][0], (desc[i][1]), (desc[i][2]), int(desc[i][3]))with open(folder + '/' + filename + '.txt', 'w') as f:f.write(line)print("完成!")# 建立每个模特的文件夹def make_dir(self, folder):#判断model文件夹下是否存在folderif os.path.exists(folder):print("文件夹已存在!")flag = 1return flagelse:os.mkdir(folder)print("已创建文件夹 %s " % folder)flag = 0return flagdef main(self):url = "https://mm.taobao.com/tstar/search/tstar_model.do?_input_charset=utf-8"print(datetime.now().strftime( '%Y-%m-%d %H:%M:%S' ))pages = int(input("程序开始...\n请输入要爬取的页数(1-1450):\n" ))if pages<1:print("太小啦,请输入1-1450之间的整数...")if pages>1450:print("太大啦,请输入1-1450之间的整数...")i = 0# 选择一个文件夹os.chdir("model")# 实现翻页操作for page in range(1,pages+1):data = {'currentPage': page, 'pageSize':100}# 重置i 因为每一页只有30份数据i =0# 获取人物基本信息real_name = self.get_realname(url, data)imgs = self.get_head(url, data)desc = self.get_desc(url, data)# 围绕名字这个关键字来理清思路for name in real_name:flag = self.make_dir(name)if flag == 0:print("正在进行第 %d 页的第 %d 次操作,操作对象是: %s " % (page, i + 1, name))# 保存model头像的二进制文件self.save_img(imgs[i], name, name, i)self.save_desc(name, name, desc, i)else:passi += 1print("It's done!!\n", datetime.now().strftime( '%Y-%m-%d %H:%M:%S' ))if __name__ == "__main__":spider = Spider()spider.main()
6,代码分析
1,上边代码的注释都非常清楚,import user_agent 是用来随机生成可用的user-agent模拟浏览器访问,防止被BAN。
我对部分代码进行了处理,比如利用标志位防止文件夹重复操作,只不过代码太过冗长,因为我没有花时间去优化下它,都是想到什么写什么,所以仅供参考。
2,这个代码的功能及其少,不过如果要爬取跟跟多信息也很简单。如:
https://mm.taobao.com/self/aiShow.htm?&userId=268367415 可以进入对应模特的个人界面。
https://mm.taobao.com/self/model_info.htm?user_id=268367415 可以进入对应model的模特卡,
上面这连个链接可以让我们获得跟更多的信息。而我们可以通过改变 userID的值来获得不同model的不同信息。这些userID我们都可以在上面的代码中获得,只需要多添加一行代码用正则提取相关userID操作即可。这个没啥大问题。
3,代码在执行过程中,可以回比较慢,因为这只是一个单线程,而且还受网路影响,不过单线程才是主要的。所以建议开多个线程来执行这个操作。这样会快很多。由于程序改动会比较麻烦。我就没弄了。。我太懒了。没办法。。。。还有一个就是多线程不太会。。[/尴尬]
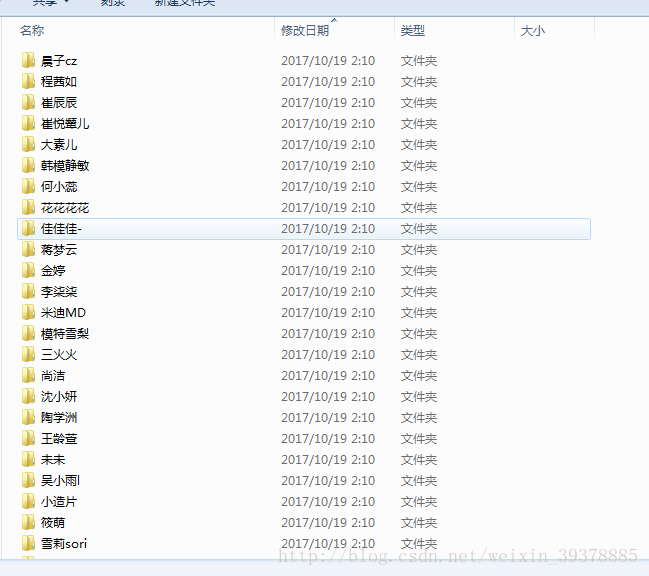
结果部分截图:
好吧,就这么多了..