一种利用句法依赖和词性相关性信息来过滤噪声(无关跨度)的基于span方法。
| 会议 | EMNLP 2023 |
|---|---|
| 作者 | Pan Li, Ping Li, Kai Zhang |
| 团队 | Southwest Petroleum University |
| 论文地址 | https://aclanthology.org/2023.emnlp-main.17/ |
| 代码地址 | https://github.com/bert-ply/Dual_Span/tree/master |
| 简介 | 一种基于span双通道的情感三元组抽取模型 |
Task
方面级情感分析(ABSA)中的一项子任务(情感三元组抽取,ASTE)。

图1. ASTE 任务中带有依存树和词性的句子
Problem
在ASTE任务中采用跨度交互的方式已被证明能为模型带来不错的收益。然而,基于span的方法最大的一个问题是它们通常会枚举句子中所有的span,这样会带来非常大的计算成本和噪声。具体来说,长度为n的句子的枚举跨度数量是 o ( n 2 ) o(n^2) o(n2),而在后期跨度配对阶段,所有意见和方面候选跨度之间可能的交互数量为 o ( n 4 ) o(n^4) o(n4),这意味着绝大多数的跨度都是无效的。此外,大多数现有的基于跨度的方法都对两个跨度之间的直接交互进行建模,而高阶交互作用被忽视。
为了解决以上问题,作者对跨度中的语言现象进行了探讨:
- 在语法依赖树方面,由多个单词组成的aspect或opinion跨度在语法上是依赖的,并且多重依赖关系可以在跨度之间传递高阶交互。
- 在词性方面,aspect和opinion存在一些常见的情况,如:aspect通常是名词(N)或名词短语(NN-NN),而opinion通常是形容词(JJ)。
Contributions
- 提出了一种新的跨度生成方法,通过利用句法依赖关系和词性特征之间的相关性,显著减少了跨度候选的数量,从而降低了计算成本和噪声。
- 通过构建基于句法依赖和词性关系的图注意力网络(RGAT),模型能够捕获跨度/单词之间的高阶语言特征交互,增强了跨度表示。
- 两个公共数据集上的广泛实验表明,Dual-Span模型在ASTE任务上超越了所有现有的最先进方法,证明了其有效性和优越性。
Methodology
Sentence Encoding
本文采用了两种句子编码方法:
- GloVe+BiLSTM
- BERT
其实只做进行BERT版本即可,可能是为了与借鉴的Span-ASTE对比(也采用了这两种编码方法)。
Feature Enhancing Module
如上所述,跨度(或跨度内单词)涉及句法依赖性和词性相关性,因此将这些信息合并到特征表示中可能有利于跨度配对和情感预测。
为了捕获高阶依赖关系,这里我们设计了一种基于图神经网络的方法来对高阶跨度内和跨度的句法依赖关系和词性关系进行编码。具体来说,我们构建了词性关系图(对应于图3(b)所示的多关系矩阵)。然后,我们应用两个关系图注意网络分别学习所讨论句子的句法依存树和构建的词性图上单词之间的高阶交互。
Part-of-speech And Syntactic Dependency Graph Construction
利用斯坦福的CoreNLP来完成句法依赖和词性的标注
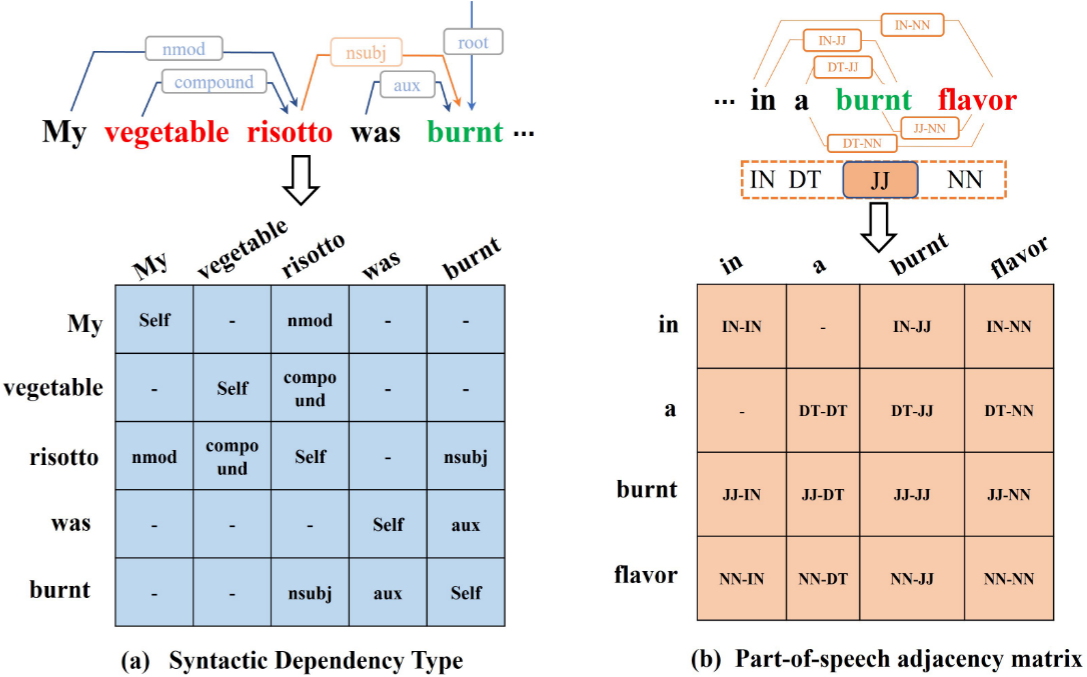
图2. ASTE 任务中一个句法依存树和词性邻接矩阵的例句
G S y n = ( V , R S y n ) G^{Syn}=(V,R^{Syn} ) GSyn=(V,RSyn)和 G P o s = ( V , R P o s ) G^{Pos}=(V,R^{Pos} ) GPos=(V,RPos)分别表示句法依存图和词性图,索引为i的词与索引为j的词之间的关系向量分别为 r i , j s r^{s}_{i,j} ri,js和 r i , j p r^{p}_{i,j} ri,jp。
High-order Feature Learning with Relational Graph Attention Network

图3. Dual-Span的模型架构图
在构建好句法依赖图和词性图之后,作者构建了两个关系图注意力网络(RGAT):SynGAT和PosGAT,分别用来捕获句法依赖图和词性图的语言特征。
对于第 i i i个节点,更新过程如下:
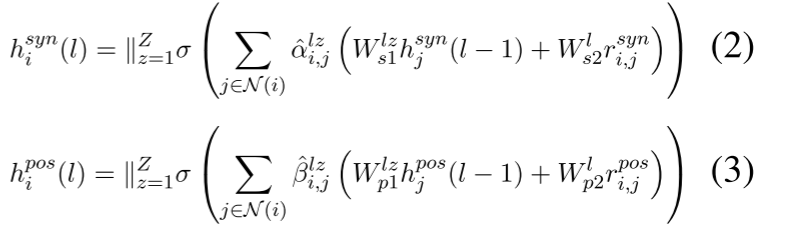
其中 Z Z Z表示注意力头的数量, h i s y n ( l ) h^{syn}_i(l) hisyn(l)和 h i p o s ( l ) h^{pos}_i(l) hipos(l)表示第 l l l层数第 i i i个节点的表示向量, N ( i ) N(i) N(i)表示与 i i i直接相邻的节点集。
为了融合句法依赖和词性关系特征,作者引入了一种门机制:

Dual-Channel Span Generation
前面通过R-GAT完成了句法依存和词性信息的融合,接下来就是进行span的枚举了。这里的span枚举有两种方式。
Syntactic Span Generation
只枚举索引为 i i i的词与索引为 j j j的词之间存在依赖边或关系( e i , j = 1 e_{i,j}=1 ei,j=1),且 i i i与 j j j之间的距离小于 L s L_s Ls,则认为索引 i i i到索引 j j j之间的所有的词是一个span。
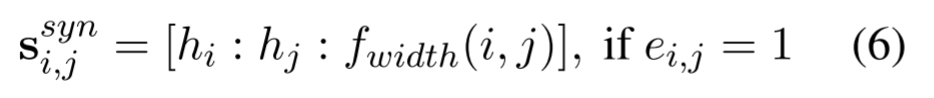
其中, f w i d t h ( i , j ) f_{width}(i,j) fwidth(i,j)是一个可训练的embedding。
Part-of-speech Span Generation
只枚举出所有的名词和形容词, ( k , l ) (k,l) (k,l)中每个词都是NN或者JJ,则 k k k与 l l l之间的所有词是一个span。
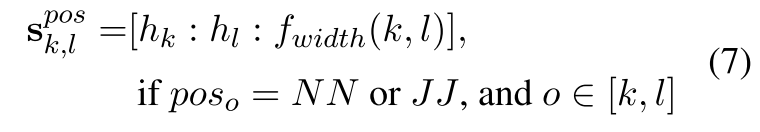
其中, f w i d t h ( k , l ) f_{width}(k,l) fwidth(k,l)是一个可训练的embedding。
最终将两种枚举方案种的span进行取并集,得到最终的span候选集:
S = S i , j s y n ∪ S k , l p o s S = S^{syn}_{i,j}∪S^{pos}_{k,l} S=Si,jsyn∪Sk,lpos
Span Classification
获得span候选集 S S S后,通过利用两个辅助任务(即 ATE 和 OTE 任务)进一步缩小可能的跨度池。相当于对每个span做一个三分类任务:{Aspect, Opinion, Invalid}
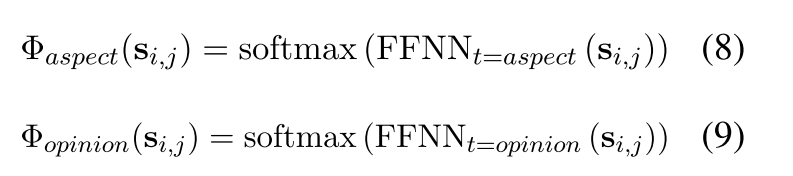
预测为Aspect或Opinion的span并不是全部都作为候选的Aspect或Opinion,而是分别取出tok nz个作为Aspect候选span和Opinion候选span。(做法与Span-ASTE一致)
Triplet Module
对候选的aspect和opinion进行两两配对,配对之后的跨度对的向量表示:
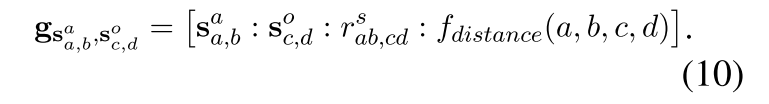
f d i s t a n c e ( a , b , c , d ) f_{distance}(a,b,c,d) fdistance(a,b,c,d)是一个可训练的embedding, r a b , c d s r^{s}_{ab,cd} rab,cds为词a、b与词c、d之间的依赖关系表示向量做一个均值操作。
接下来对每个配对之后的pair进行4分类:{Positive, Negative, Neutral, Invalid}:

Training objective
训练的损失函数定义为跨度分类和三元组模块中跨度对分类的负对数似然之和:

Experiments
Dataset
ASTE-Data-v1和ASTE-Data-v2,所有数据集均基于 SemEval 挑战(Pontiki 等人,2014、2015、2016),并包含笔记本电脑和餐厅领域的评论。

图4. ASTE两个数据集的想详细统计结果
Main Results
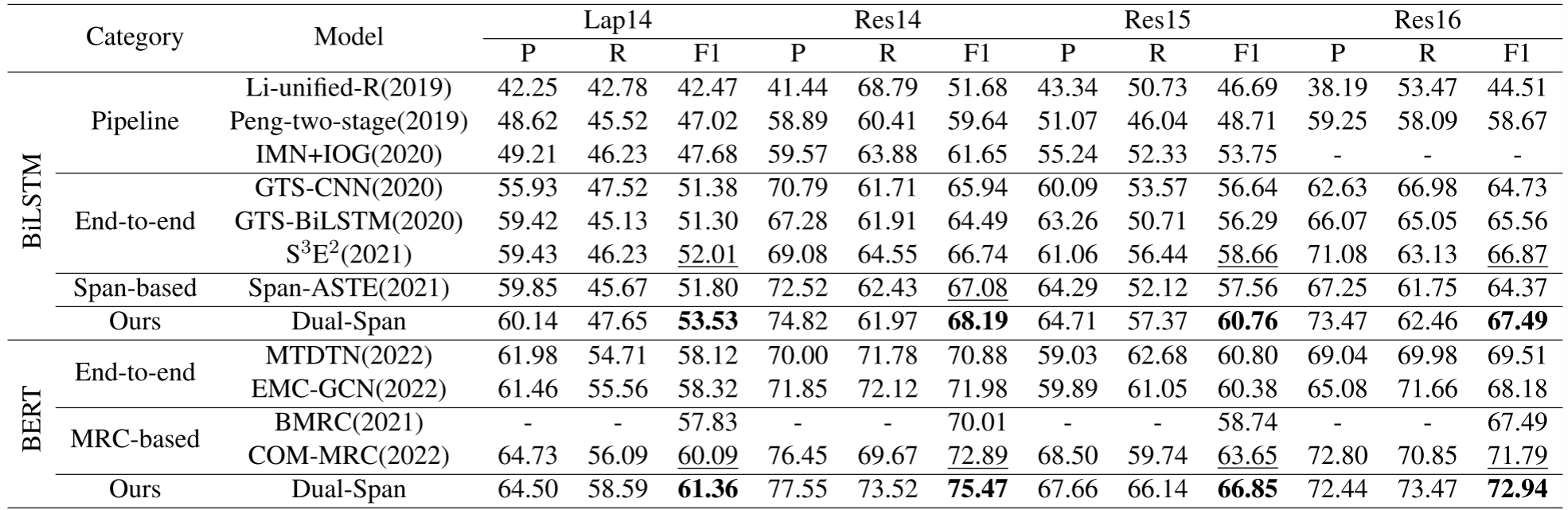
图5. ASTE-Data-v1数据集的主要结果
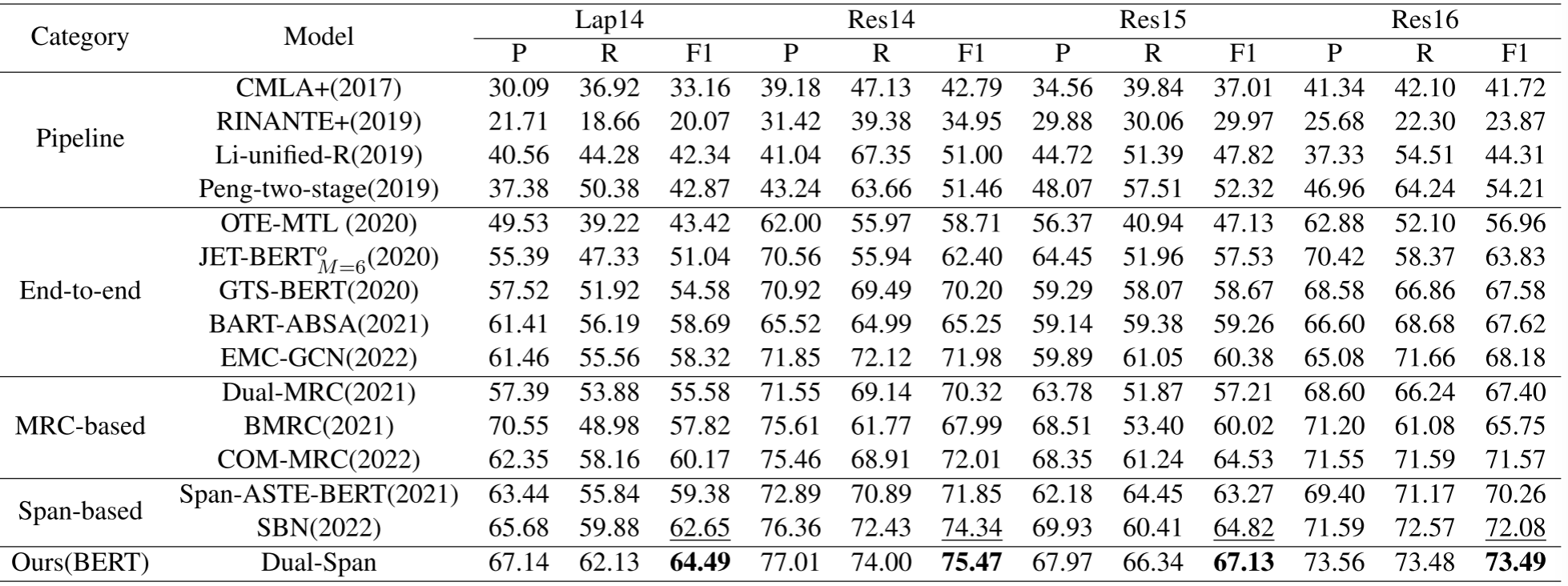
图6. ASTE-Data-v2数据集的主要结果
- 性能提升: Dual-Span模型在四个公共数据集(Lap14, Res14, Res15, Res16)上进行了广泛的实验,实验结果表明,该模型在F1分数上一致超越了所有现有的最先进方法。这证明了Dual-Span在ASTE任务上的有效性和优越性。
- 句法结构的利用: 在基于标签的端到端方法中,那些利用句子句法结构的方法(如S3E2, MTDTN和EMC-GCN)通常比仅学习标签信息的方法(如OTE-MTL, GTS和JET)表现得更好,这表明句法特征对于三元组表示是有意义的。
Ablation Study

图7. 消融实验的结果
通过消融研究,论文进一步验证了Dual-Span中各个组件的有效性。移除句法图注意力网络(SynGAT)、词性图注意力网络(PosGAT)或两者都移除(Dual-RGAT)都会导致性能下降,这表明模型的每个部分都对最终的ASTE任务性能有贡献。
Effectiveness of Dual-Span in Span Generation

图8. ATE和OTE任务在数据集D2上的实验结果
在 ATE 任务上,Dual-Span 始终优于 Span-ASTE 和 GTS,这表明基于句法和词性相关性的候选缩减和表示对于方面术语识别是有效的。然而,在 OTE 任务上,模型在大多数基准数据集上略逊于 Span-ASTE,这是由较低的 P(precision)值引起的。可能是因为作者只考虑涉及用 JJ或NN 标记的单词的跨度。但是,意见术语可以用 VBN 标记,但他们没有被包括在内。
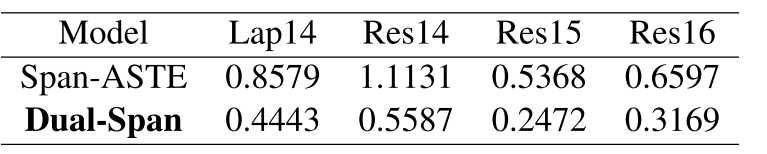
图9. 在D2数据集上生成span耗时(秒)的实验结果
Dual-Span模型通过双通道跨度生成策略显著减少了计算成本,实验结果显示,与Span-ASTE相比,Dual-Span在生成跨度的时间消耗上减少了一半。
Conclusion
- Dual-Span模型通过利用句法关系和词性特征来改进ASTE任务的性能。
- 实验结果表明,该方法在ASTE和ATE任务上相比所有基线方法都有显著提升。
- 论文指出,对于OTE任务,Dual-Span通常不如枚举所有可能跨度的简单跨度基方法。