一、阿里的库存秒杀的实现
阿里有很多业务,几十上百个业务线,各自都有一些需要做抢购、秒杀、热点扣将的场景。他们都用哪些方案呢?
我看了很多资料,也找了很多人做交流,最终得到的结论是啥都有,主要总结几个主流的,在用的一些方案(主要是整体方案的介绍,具体细节就不展开说了,有的是太敏感不方便讲,有的是太复杂了先把主要的说了,后续需要的再展开):
你比如说,一些并发量没那么高,比如只有几千的,基本上是用mysql在抗的。但是你要是以为这个mysql和你用的mysql是一样的,那你会发现热点行更新在几百QPS的时候CPU就直接被拉满了。
那我们的mysql呢,是加了个自研了一个补丁(就是下面这篇文章中的技术方案),这个补丁可以识别出热点行及热点SQL,再给这些SQL分组,然后一个组内的多个SQL就可以减少加锁次数、减少B+树的遍历、以及通过组提交减少事务提交次数。就能扛更高的并发。
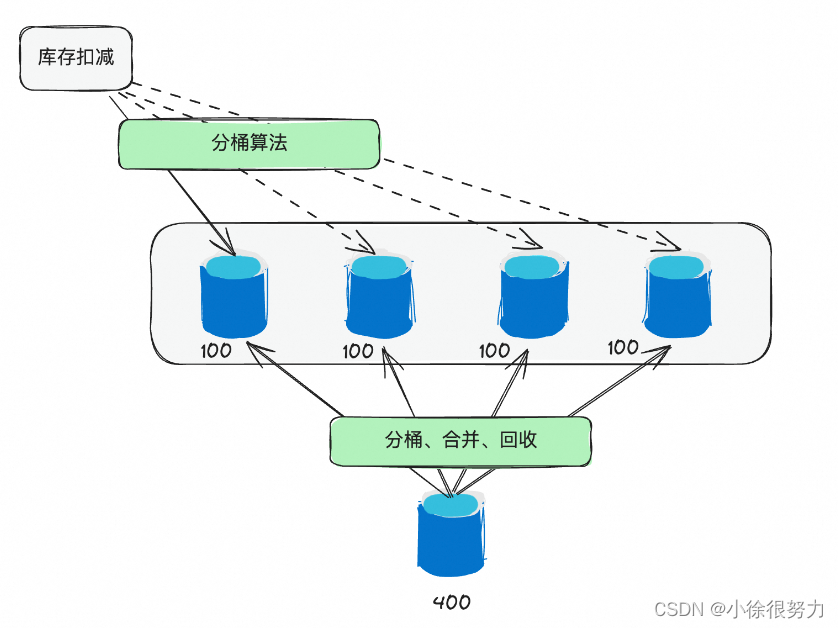
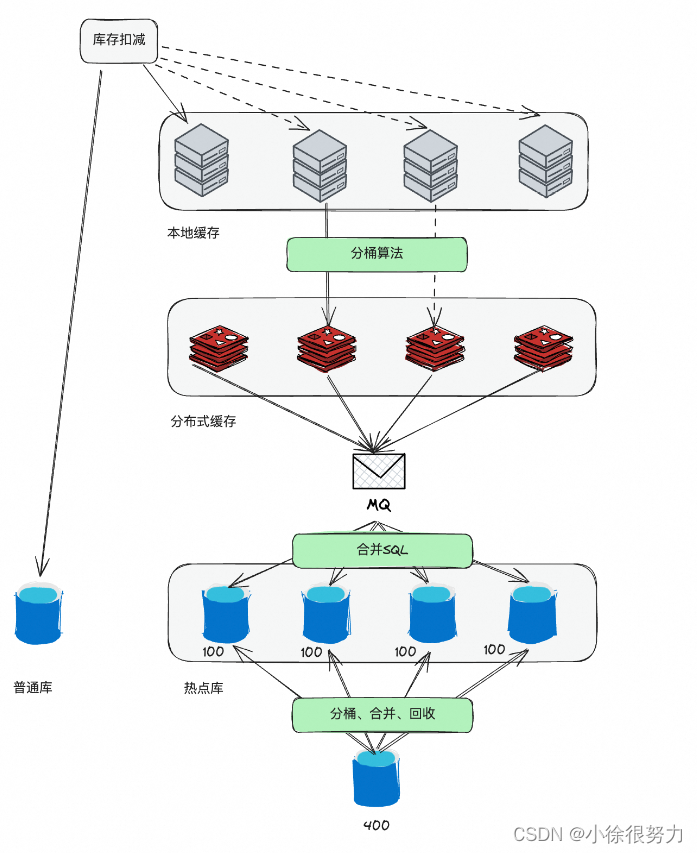
但是如果有些场景的QPS达到数万级别了,只靠数据库肯定是不行了。于是有一些营销平台或者额度系统,就会采用分桶的策略。就是将单个1000的库存拆分成10个100的库存,这样就可以把并发提升10倍。当然,这里还需要考虑如何均匀分配,如何解决碎片,如何做分桶间调度以及如何做动态扩容等问题。然后有些团队就专门研发了库存调度系统来解决这些问题。
另外,在一些本地生活类的电商场景,比较常用的方案就是缓存+数据库的策略,也就是在缓存做预扣减,然后异缓存的不可用等问题。步通知到数据库再做扣减。这种方案就是需要考虑数据的一致性、
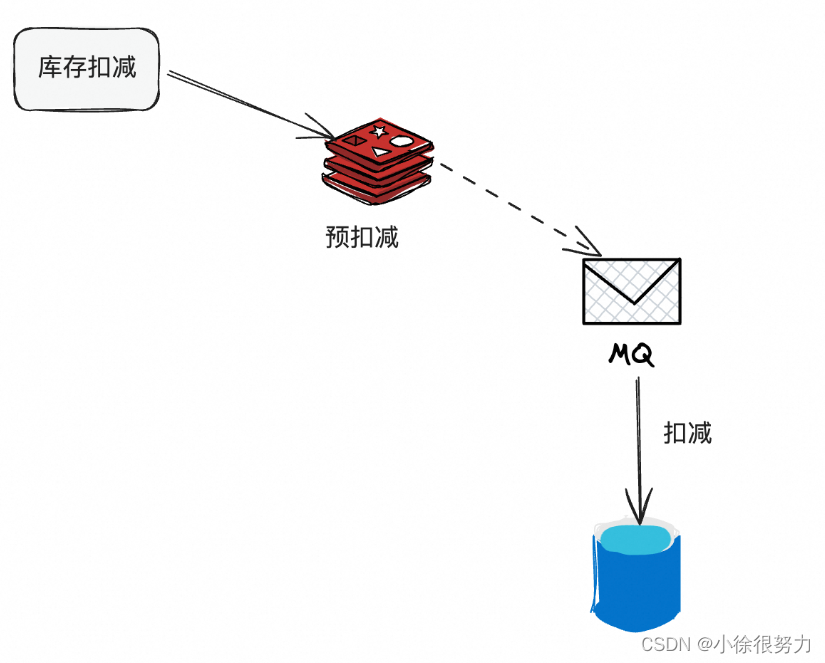
那对于那种需要抗几百万QPS的电商大促场景,基本上就是各种方案的结合了。热点库、SQL合并执行、缓存、以及分桶基本都是结合着来的。而且这里的缓存,又有分布式缓存、本地缓存,以及把分布式缓存和服务器部署在一起搞一个近端缓存。总之就是各种方案每一个抗一点并发,加到一起抗的就多了。
我还了解到还有一些物流的仓库管理场景,设计了自己的分布式事务+应用层排队框架,来减少在数据库层面的热点更新,方案听上去也挺牛逼的。
看了这么多之后,到底哪种方案最好?又经过77四十九天的研究,我终于悟了,适合的才是最好的。
根据具体的业务形态、并发量、团队成员的技术能力、基础建设的情况等等选择相对合适的就行了。但是不管咋说,复杂度和并发量一定是成正比的。
二、阿里的数据库能抗秒杀的原理
其实,在阿里电商的秒杀等(据我了解,淘宝、天猫、猫超、大麦等都是这么干的)场景中,主要还是基于MySQL数据库在做扣减的,主要是因为这样做最可靠了(避免了redis扣减方案中的数据不一致、少卖等问题)
但是我们都知道,数据库是抗不了热点行的并发更新的,于是阿里内部就对MSQL做了patch.
这个方案其实云上数据库RDS也支持了,所以我就可以讲了。(没开放的技术确实不敢讲,怕被请喝茶。。。)
这个技术叫做Inventory Hint,其实就是一个补丁。
(官方介绍:https://help,aliyun.com/zh/rds/apsaradb-rds-for-mysql/inventory-hint )
PS:这里主要是介绍通过lnventory Hint来提升热点更新的并发,但是并不意味着内容只用这个方案来抗热点并发,但是这个是基础,先把这个讲清楚。后续其他的方案,我也会挑一些能讲的介绍。
1、使用方法
他的用法很简单,只需要在正常的update语句中增加上特殊的hint语句就行了,如:
UPDATE /*+ COMMIT ON SUCCESS ROLLBACK ON FAIL TARGET AFFECT RON(1)*/ T
SETC=C-1
WHERE id = 1;这里面的 COMMIT ON SUCCESSROLLBACK ON FAIL和TARGET AFFECT ROW 都是一些Hint语法:
- COMMIT ON SUCCESS:当前语句执行成功就提交事务上下文。
- ROLLBACK ON FAIL:当前语句执行失败就回滚事务上下文。
- TARGET AFFECT ROW(NUMBER):如果当前语句影响行数是指定的就成功,否则语句失败。
hint:MySQL 中的"Hint"是一种特殊的语法,允许开发者向数据库引擎提供如何执行特定查询的额外信息或建议。这些提示不改变查询的结果,但可以影响查询的执行路径,比如如何选择索引、是否使用缓存等。使用Hint 的目的是为了优化查询性能。
很显然,前面我们提到的这几个hint是阿里自己支持的。所以只有内部的数据库,或者阿里云的RDS才支持。
2、原理介绍
当我们是使用 COMMIT ON SUCCES5 等hint标记了一条SOL之后,就相当于告诉MySOL内核,这行可能是热点更新。
于是,MySQL的内核层就会自动识别带此类标记的更新操作,在一定的时间间隔内,将收集到的更新操作按照主键或者唯一键进行分组,这样更新相同行的操作就会被分到同一组中。
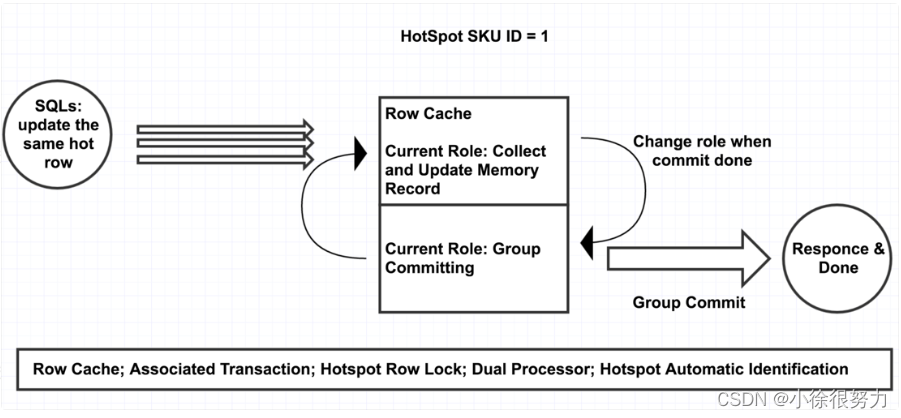
为了进一步提升性能,在实现上,使用两个执行单元。当第一个执行单元收集完毕准备提交时,第二个执行单元立即开始收集更新操作;当第二个执行单元收集完毕准备提交时,第一个执行单元已经提交完毕并开始收集新批的更新操作,两个单元不断切换,并行执行。
根据热点行做了分组之后,就可以作进一步优化了,这个过程主要有3个关键的优化点:
3、关键优化点
3.1、减少行级锁的申请等待
在同一组中,需要更新的都是同一条记录,那么根据SQL的提交顺序,就可以排队了
然后我们只需要在第一条更新SQL(Leader)执行的时候,尝试去获取目标行的锁,如果获取成功,则开始操作。
然后这一组中后续的更新操作(Folower)也会尝试获取锁,但是会先判断是不是已经被第一条更新操作获取到了,如果是的话,那么就不需要等待,直接获取锁。
这样就可以大大降低行级锁的申请的阻塞等待时长,
3.2、减少B+树的索引遍历操作
MySQL是以B+索引的方式管理数据的,每次执行查询时,都需要遍历索引才能定位到目标数据行,数据表越大,系引层级越多,遍历时间就越长。
如果针对热点行更新操作做了分组之后,我们只需要在每组的第一条SQL执行过程中,通过遍历索引定位数据行之后就可以把这些数据行缓存到Row Cache中,并且在Row Cache进行修改。
在同组的后续操作时,也不再需要进行数据索引了,直接从Row Cache获取数据并修改就行了
这样就大大降低了B+树的索引遍历操作的耗时
3.3、减少事务提交次数
如果是没有用这种方式,我们的多条update语句会是多条事务,那么每一个事务都要单独做一次提交。
有了分组、排队、组提交之后,就只需要一组中的并发操作都执行完,然后做一次组提交即可,大大降低提交次
数。
对此,您有什么看法呢?评论区留言讨论哦。