背景
前段时间,在用户现场协助进行OceanBase的性能测试时,我注意到用户常常需要运用 insert into select 将上亿行的数据插入到一张大宽表里,这样的批量数据插入操作每次都需要耗时半个小时左右。对这一情况,我提议用户尝试采用旁路导入的方式,结果不到五分钟就就完成了相同数据量的导入。虽然当时我表面保持冷静,但内心却充满喜悦。用户方的DBA同事们也半开玩笑地表示:“看来我们即将失去因导入数据而赢得的咖啡时间红利了。”
昨晚负责旁路导入研发的剑鸣同学分享了一次关于旁路导入的技术讲座。我借此机会写了一篇学习笔记,详细梳理了旁路导入的大致思路,并总结了用户在使用过程中需要注意的要点。
设计思路
目前,OceanBase主流使用三种导入方式:load data、obloader 和 oms,这些方式都使用 insert 语句将数据写入 OceanBase。然而,使用 insert 语句写入数据需要经过 SQL、事务和存储。OceanBase 使用 LSM-Tree 结构进行存储。在这种存储结构中,insert 语句会先将数据写入内存表中,然后经过多轮转储和合并,才能最终存入最底层的 SSTable 中。这些过程消耗了大量的系统资源,特别是 CPU 资源,因此导入数据的速度不够理想。为了加快导入速度,我们采用了一种绕过中间步骤的技术,将需要导入的数据直接写入最底层的 SSTable 中,这种技术称为旁路导入。此外,旁路导入还可以用于加速一些需要大量写入 SQL 的操作,例如背景中提到的 insert into select 语句。旁路导入的语法详见官网中几个相关的语法,例如 load data。
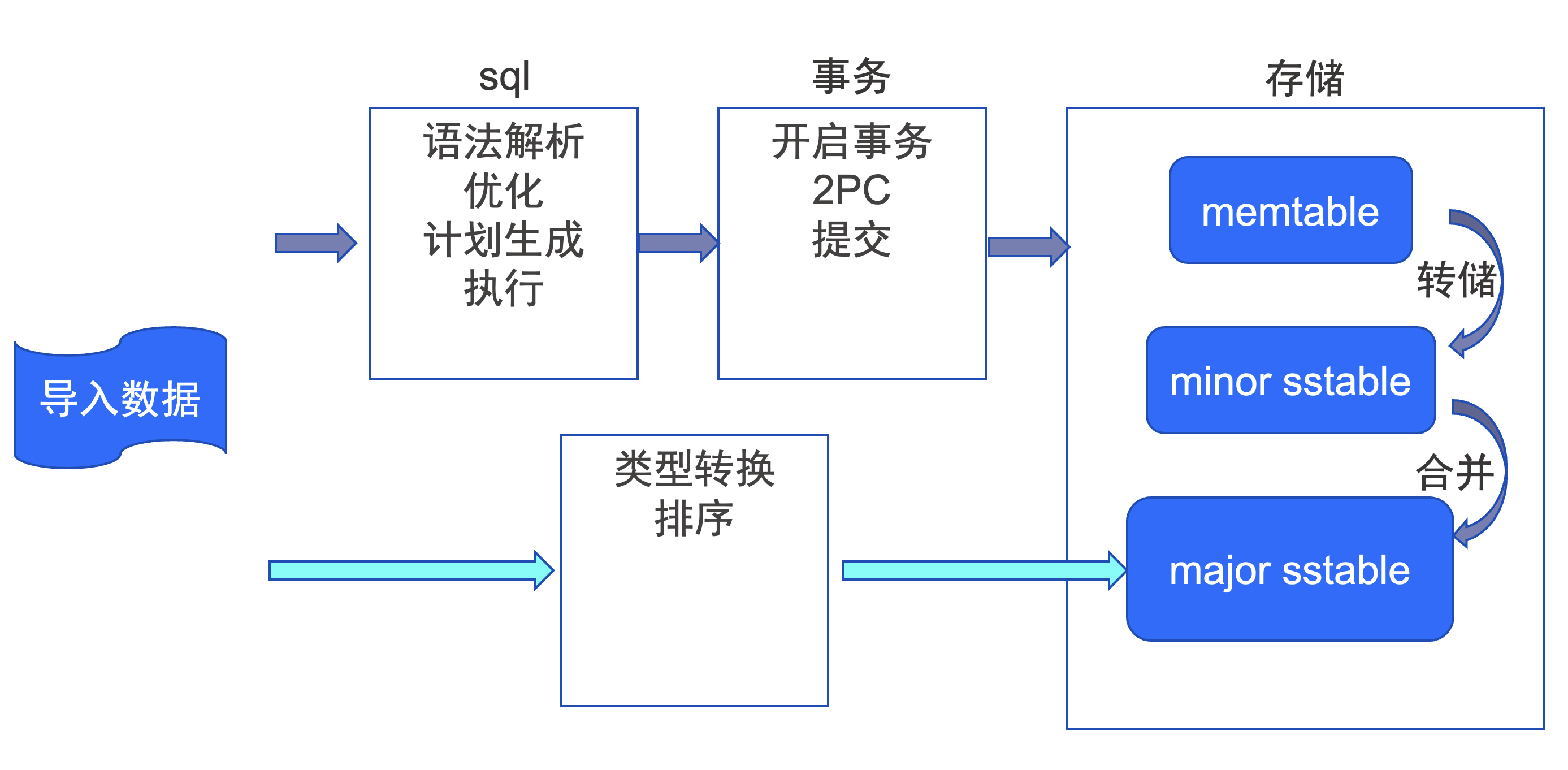
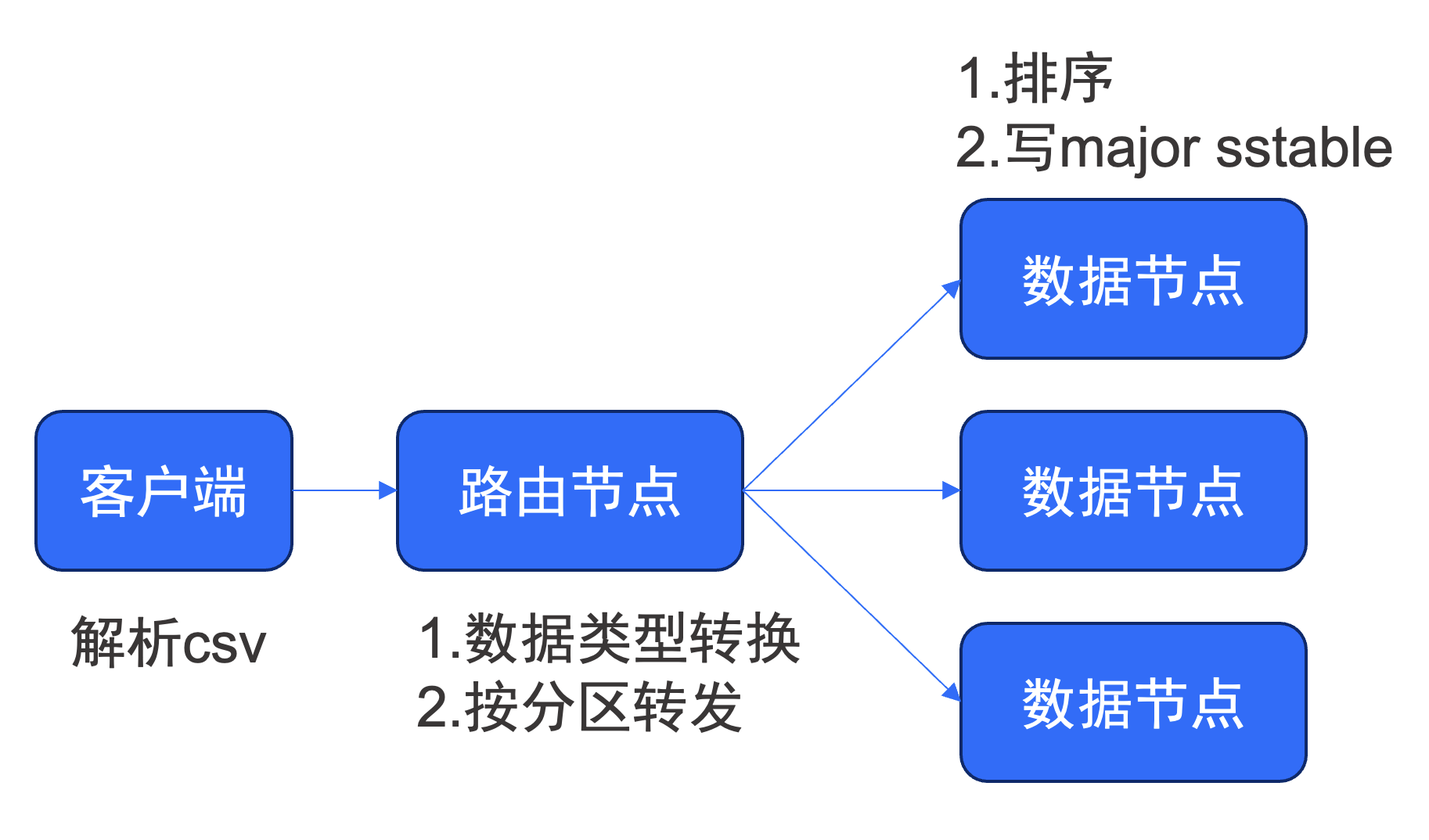
根据上图所示,数据导入可采用两种路径,上方深蓝色箭头所示的传统路径需要经过 SQL查询、事务处理、数据存储等一系列模块。而下方的浅蓝色箭头所示旁路导入路径主要是对导入的数据进行类型转换(按需),然后按照主键进行排序(按需),最后将排序后的数据写入到 major sstable 中。旁路导入是一条短路径,能减少不少系统资源消耗,加快导入速度。(上图中的 LSM-tree 指的是 Log-Structured Merge Tree, 一种基于内存和磁盘的数据结构,用于高效地插入、删除和查询大量数据。SSTable 指的是 Sorted String Table, 一种有序、持久化存储数据的数据结构,可支持高效的读写操作和范围查询。)
实现原理
现在的旁路导入是利用 DDL 来实现的,可以认为是一种特殊类型的 DDL。
所以主要的执行流程和 DDL 类似(DDL 的实现原理可以详见夏进的这篇博客《OceanBase Alter Table 原理介绍》),旁路导入的实现分为了几个步骤:
-
- 创建 hidden table,用于导入
- 给原表和 hidden table 加表锁
- 把原表的数据和新导入的数据合并后写入 hidden table 中
- 在 hidden table 中重建原表的索引和外键
- 交换原表和 hidden table 的 table_id(如果中间任何一步出现错误,不交换 table id 就可以保证原子性,只有当全部步骤都成功,才会交换 table id)
- 解表锁
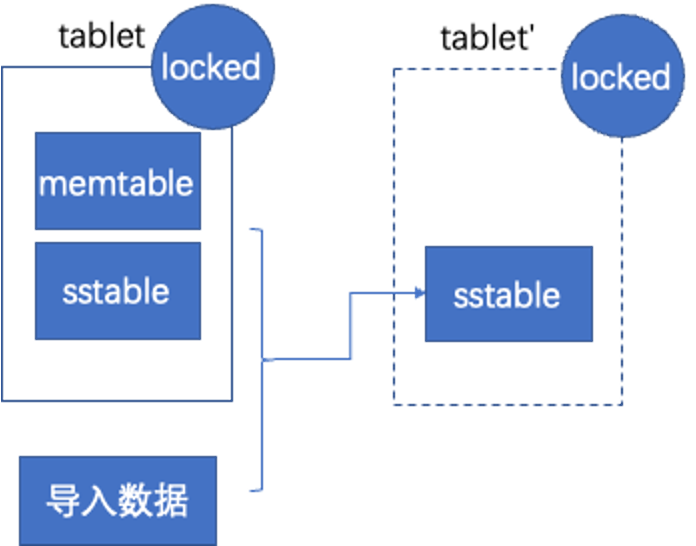
如果原表不是空表,已经有一些数据了,就会把原表里的数据和导入数据一起整合到 hidden table 里面。
例如下图中 tablet 是原表的 tablet,tablet' 是 hidden table 的 tablet,旁路导入会把原表的 memtable、sstale,以及导入的数据一起归并到新的 hidden table 里。
例如通过 load data 命令进行旁路导入,整体的数据流向是:类型转换、根据分区键转发到对应节点、在节点上按需进行排序,最后写入 major sstable。
我们在这里还对数据类型转换的优化、数据排序、解析 csv 等过程都做了大量的优化。
对于数据类型转换:例如 csv 文件里的内容是 string,但是实际的列类型是 number(在 MySQL 模式下相当于 decimal),这时候就需要根据 number format 进行一个非常复杂的隐式类型转换,我们在这里对隐式类型转换中的 to_number 函数最常用的一些 number format 进行了非常极致的短路优化,性能比直接调用 to_number 能提升四五倍的样子。
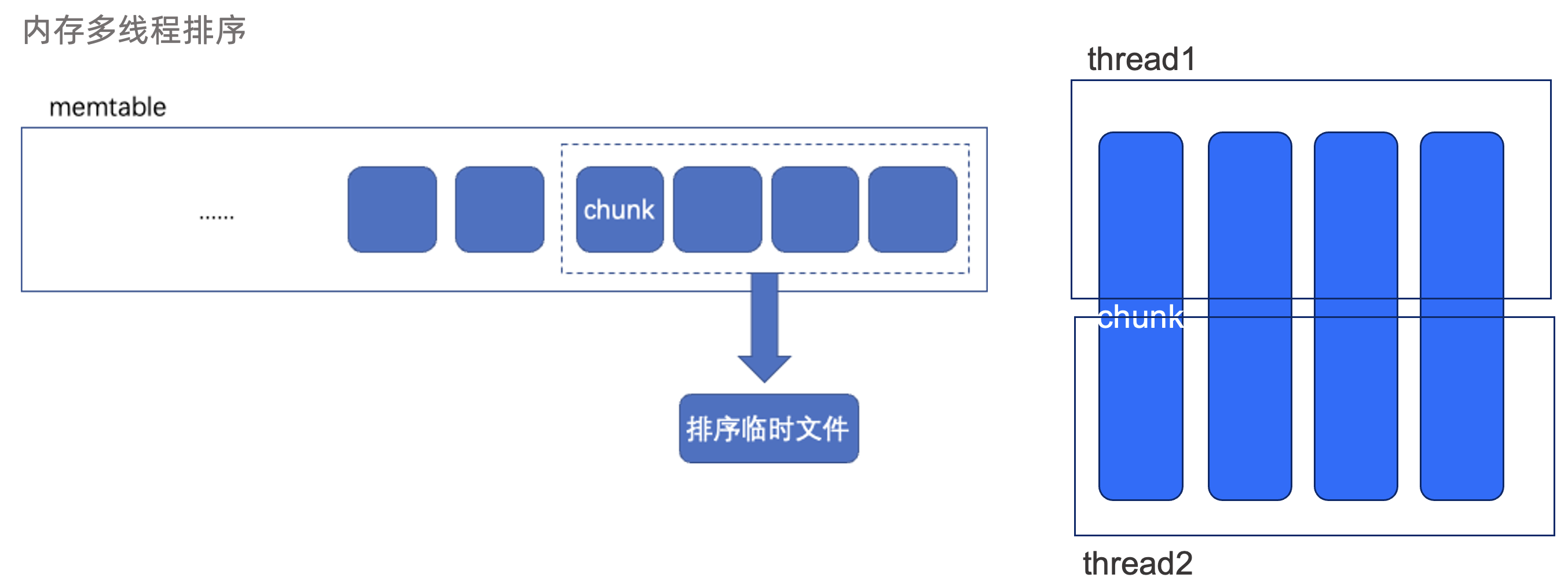
对于数据的排序:因为 OB 都是索引组织表,所以如果对于无主键表,是不需要进行排序的(写入时一个隐藏的 increment pk 列会自动保证有序),直接写入 major sstable 就可以了,这也就是无主键表比有主键表的旁路导入速度还能再快上几倍的原因。对于有主键表,那就不得不按照主键进行排序了,如果输入的数据已经是有序的(例如 csv 文件中的数据就有序),我们还提供了一个选项,支持用户通过指定要导入的数据是否有序来决定能否进行优化,如果已经有序,内部就只会做归并排序。完全无序时才会走完整的排序流程,无序时为了充分利用内存资源,我们会对数据进行一个归并的外排,首先先利用最大可用内存对数据进行排序,然后落盘,最后再对磁盘上的各个有序的数据文件进行一个多线程的归并排序,这样不仅可以充分利用内存资源,还可以有效减少落盘的次数。
其他的优化由于篇幅关系,这里就不再详细描述了。
使用时需要注意的一些地方
用户在日常使用中,如果不了解目前旁路导入一些要注意的地方,很可能会遇到各种问题,以下就是使用旁路导入时需要注意的几个点:
1. 旁路导入期间会加表锁,表无法被写入其他数据,整个过程中表是只读的。
2. 旁路导入的实现是 DDL 而非 DML,这点要特别留意!
(1)按理说 insert into select 可以在事务里面的,但是例如 Oracle 的 DDL 如果出现在事务中,就会在 DDL 执行结束之后提交事务,然后再继续处理事务中的后面的内容,DDL 类似于事务中的一个 barrier。因为 DDL 在事务中的特殊表现,所以我们暂时不支持旁路导入出现在多行事务中,只能出现在 autocommit 的单行事务中,否则会报错 not supported。
(2)还有一个要注意的点是 DDL 框架比较重,导入 1 行数据可能就需要 2s,所以不适合用于导入量特别小的数据(例如 100M 以下的数据)。
(3)由于 DDL 实现逻辑的限制(在 RS 上会有一段儿逻辑需要串行执行),暂时不能很好地支持大规模多条旁路导入并行。比如并发执行几百个普通的 insert into select 是没问题的,但是并发执行几百个旁路导入的 insert into select,可能就会有一堆 DDL 排队等着 RS 的调度了。
这几个点确实给使用上带来了一些麻烦,不过我们后面会把它的实现方式给改成 DML。
3. 功能上支持增量导入,但是性能上可能不会特别理想。因为旁路导入的目标表如果在导入前已有数据,那么已有数据会被重写一遍。如果导入一个已有数据量很大的表,增量需要把原来的数据重写一遍,这时候可能并不划算。
4.如果租户的内存特别大,或者说数据量比 memtable 还要小,那内存的 memtable 就能兜住全部要导入的数据,旁路导入可能就没啥优势了。因为旁路导入是要写磁盘的,肯定比不过只写内存不需要转储、合并的场景
5. 4.2 版本 lob 列还不支持走旁路导入,不过后面即将发布的 4.3 版本已经支持了。
6. 使用 INSERT INTO SELECT 语句旁路导入数据时,只支持 PDML(Parallel Data Manipulation Language,并行数据操纵语言),非 PDML 不能用旁路导入,详见官网。
总结
最后总结一下,OB 目前的旁路导入功能,最适用于:
- 大表的首次导入场景;
- 10 GB~TB 级别的数据迁移场景;
- 还有就是 CPU 和 内存都不是特别充裕的场景,因为旁路导入的执行路径很短,可以省掉非常多的 CPU 开销。